2017 3rd International Conference on Computer Science and Mechanical Automation (CSMA 2017) ISBN: 978-1-60595-506-3
Spectrum-Based and Program Slicing Statistical Fault Localization
Jia-Yi LI
1,a, Hai-Hua YAN
2,band Xu-Chen WANG
3,cDept. of Computer Science Beihang University Beijing China a
Email: [email protected], bEmail: [email protected], cEmail: [email protected]
Keywords: Fault localization, Program spectrum technology, Program slicing technology, Test case selection.
Abstract. Software fault localization is a necessary and time-consuming process in program debugging. An effective fault location method can help developers quickly locate faults and improve debug efficiency .In this paper, a new SIFL (Spectrum-Based Improved Fault Localization) method is proposed to improve the accuracy of fault location, by adding program slicing technology and test case selection technology to traditional spectrum-based fault localization. In the experimental section, this paper uses the public fault data set SIEMENT[1] to test the accuracy of the SIFL method. According to the experimental results, the SIFL method significantly improves the accuracy of fault location compared to SFL method. And using the SIFL method, the average fault location ratio is 3.076% of the program, which showing SIFL method can greatly narrow the scope of fault and improve debug efficiency.
Introduction
Software fault localization has always been an important and time-consuming process in software debugging. In the recent years, the number of test cases is more and more as the software scale is getting larger and larger. As a result, the efficiency of the traditional artificial fault localization method is getting lower. An effective automatic fault localization method can greatly improve the efficiency of fault localization, narrow the scope of fault, and liberate people from the boring and monotonous manual debugging.
In recent years, the program spectrum technique is widely used in software fault localization[2]. The core idea of that is by analyzing the successful and unsuccessful test cases execution paths. The program spectrum-base technique execution process is as follows: firstly, the technique dynamic obtains the program successful and the unsuccessful test case execution statement. Then, statistically analyze the total number of successful and unsuccessful test cases are executed by each statement. And based on the evaluation formula, calculate suspicion that each statement causes the program fault. Although program spectrum technology is widely used in software fault location, however program spectrum-based technology has a large shortcoming, its localization accuracy is largely dependent on the program pattern. If the program statement is primarily sequential, then the statement of the program executes sequentially, whether the test cases are successful or unsuccessful. In this way, many statements of suspicion will be same, and the localization accuracy will be rather rough.
Aiming at the problem of program spectrum technology, this paper adopts the combination of program slicing and spectrum technology to solve and improve the problem of the locating accuracy. Software slicing technology[3] is aimed at variable state to simplify the program, which is only retaining program statements related to the special variable state changes. Unlike the program spectrum technology, the program slicing technique is to fault localization from the angle of the variable state. The introduction of program slicing technology, on the one hand, can further simplify the program execution of the statement and improve the localization accuracy. On the other hand, it can solve the problem, which spectrum technology cannot further locate statements in the code block.
results. However, in fault localization, the more test cases do not imply the more accurate of fault localization. It is important to find out the test cases related to software faults, which will make the next step locate more accurate and effective. This paper preserves all unsuccessful test cases and retains successful test cases that are similar to the unsuccessful test cases in path execution, as these successful test cases with high correlation of fault in the program.
In order to demonstrate that SIFL method can improve the accuracy of fault localization, this paper adopts Siement dataset provided by the official institutions Software-artifact Infrastructure Repository for the experiment. And comparing the results with the traditional spectrum-based technology, the location accuracy have a greater improvement.Fig1 is a schematic of the execution of the SIFL method, which shows the execution process of the method and the schematic of some intermediate results.
The main contribution of this paper can be summarized as follows:
1) Combined with program spectrum technology and program slicing technology, which improve the shortcoming of spectrum technology, and simplify the execution path. Also, it improves the fault localization accuracy.
2) Improve existing program slice technology. This paper not only concerned about modifying the statement of function return variables, but also combining the features of C language program, considering the state of global variables and address variables.
[image:2.612.87.527.352.487.2]3) Simplify the successful test cases, retain successful test cases with high correlation of fault, and eliminate other unrelated successful test cases to improve the accuracy and efficiency of fault localization.
Figure 1. Schematic diagram of SIFL method. Figure 2. Program spectrum technology example display.
Background Knowledge
Program Spectrum-Based Technology
The study of J.A. Jones and M.J. Harrold in 2005 [4] firstly proposed the program spectrum-based technology. In this paper, the authors obtain the statements that are executed from the successful and unsuccessful test cases. And through formula (1), compute the suspicion of each statement. Sort statements from high to low based on the suspicion of the statement. In the formula, N(e) represents that when executing statement e, the number of failed test cases, N(e) represents that when executing statement e, the number of successful test cases, N represents the number of successful test cases, N represents the number of failed test cases. This method differs from the previous fault localization method, which considers each statement unsuccessful test case and success test case. And combine both to carry on the suspicion analysis to further locate the faulty statement.
e =
+
Below, a simple example is showed to explain the process of program spectrum-based techniques in Figure 2. The example program is to get the median of three digits, but the 7th row has a fault, it should be m=x, but written in m=y. Figure 2 enumerates some test cases, and get statements executed by each test case, According to the formula (1), calculate the suspicion and the final rank of each statement. The final result shows the highest suspicion is statement 7, which is actually the wrong statement.
Table1. Common evaluation formulas.
Name Formula
Ochiai
× +
Jaccard
+ +
Rogot1 1
2 2+ + +
2+ +
Rogot2 1
4 + +
+ +
+ +
+
Wong3
− ℎ, $ℎ%&% ℎ = '
, ( ≤ 2
2 + 0.1− 2, ( 2 < ≤ 10 2.8 + 0.001− 10, ( > 10
Mountford
0.5 × × + × + ×
M2
+ + 2+
Pearson × × − × 0
× × ×
In recent years, there have been many improvements to the spectrum-based technology. In particular, there are many improvements aimed at the evaluation formula. Now, there has been more than 20 common formula and Table 1 lists some of the common used evaluation formulae, in
which Ochiai 123
13×1234125[5] and Jaccard
123
12341634125[6] formula are generally considered as have
a relative good effect.
Program Slicing Technology
Program slicing technique is aimed at program-specific variables to simplify the program. Through the variable data flow and control flow information, the technique decomposes, simplifies the program, and only reverses statements that have effect on the status of specific variables. The program slices can be divided into forward slices and backward slices according to the slice orientation. As for a point in the program P, forward slice means to get all the statements are affected by P. Backward slice means to get all the statements affecting P. As slicing technology is more concerned with the effect of statements, the backward slice is more widely used.
SIFL Method Introduction
[image:4.612.89.524.191.274.2]As the introduction explains, SIFL method combines program spectrum and program slicing technique. And before the location, the test cases have been filtered and optimized, all of which improve the accuracy and efficiency of fault localization. The overall process of fault localization in this paper is illustrated in Figure3, the four parts of the process including: test case selection, program slicing analysis, program spectrum analysis and fault localization. The SIFL method ultimately gives the suspicion of each statement, locating the statement most likely to cause faults. In this section, the principle and improvement of SIFL method will be introduced.
Figure 3. SIFL method implementation process diagram.
The Weakness of Previous Method
Program spectrum-based technology is one of the most effective and widely used methods for fault localization. However, the localization accuracy of spectrum-based technology is greatly dependent on the structure of the program. If the program is executed only sequentially, with few branches, conditions, and judgment, then the suspicion of most statements will be the same and is difficult to locate fault accurately. As in the following pattern:
if(judgement){ Statement1; Statement2; …..
Statement n;}
For the statements in the code block, if use spectrum-based technology locating, whether successful test cases or unsuccessful test cases, as long as the criteria to meet the judgement will be executed. This causes the statement Statement1-Statement N to have the same suspicion, which makes location accuracy fairly rough. If the entire program is sequential execution, or the block of code is large, then we will be very difficult to get the fault statement by spectrum-based technology. The disadvantage of using program slicing technique is also obvious, it cannot accurately give each statement the probability of faults. It can only give a set of sub statements may cause faults. Such location accuracy is obviously not enough. Therefore, this paper combines the spectrum-based technology and slicing technology. The problem of statements’ suspicion in code blocks is same, can also be reduced by fusing program slicing technology and spectrum-based technology. At the same time, adding program slice technology can greatly simplify program, and reduce unnecessary statements, and increase the accuracy of fault localization.
The SIFL Method Introduction
Test Case Selection
For a large number of test cases, simplifies successful test cases, retaining only successful test cases with high correlation retention of fault, which can improve the efficiency and accuracy of fault localization. This paper compares the similarity between each failed test case and successful test cases, where the similarity is based on the coincidence rate of the execution path for the test case.Set
Program Slicing Technology
Program slice is used to obtain the effect statement for an interesting variable.This paper set a slicing criterion <n,V>, where n represents the variable of interest,and V represents the set of statements that are affected by variable n.This paper set interesting variables are function return variables, address variables, and global variables.In this way, all the variable states of the program can be obtained, which can better analyze the faults of the program.To obtain the program slices, first of all, get the program control diagram and data flow diagram. And then through the graph node dependencies, return the node-related statements to interesting variables.For the two node
<,0 of the control flow graph, if the following three conditions are met,then 0 control dependent
on<,defined as COD(<, 0.
(1)There is an executable path between node n< and node n0. (2)On the graph, except <and 0, every a node n must be posted by. (3)Node 0is not must be posted by node <.
As for the two-node <,0 of the data flow graph, v is a variable, also three conditions are met,is called 0about variable v data dependent on<,defined ad DAD(<, 0.
(1)Node < defines the variable v. (2)Node 0 is used for variable v.
(3) There is an executable path A from <to 0 and there is no statement on A to redefine v. Through the definition of the two graphs node dependencies, we can find statements that affect the related variables.Retain these statements, and cut down other statements,especially for the program output information, irrelevant auxiliary variables, and non-centric business code.This is helpful for locating the fault. The algorithm implement process can be seen below
Combination of Spectrum-Based Technology and Slicing Technology
For the combination of these two techniques, this paper first obtains the path @ABC after the slice of the program.Then, execute test cases and get the execution path DEC for every test case, Then the path of the test case iis DB = DEC∩ @ABC.According to the above process, get the total number of successful and unsuccessful test cases executed per statement e.Through the
formula e =
FG F FG
F 4FGF
,every statement is evaluated and sort by suspicion. Then
higher suspect's statement is more likely to be the faulty statements.
Adding slicing technology to spectrum technology can reduce the statements in the code block, and decrease the suspicion of a lot of statements in block is same .Also, adding program slicing technology can further simplify the program and improve the accuracy of locating. The algorithm implement process can be seen below.
Algorithm Program Slicing Algorithm Count Suspiciousness Input: Program CFG, Program CDG
Output: Program slice statements Begin
1. Output [Node] = Ø
2. Select variables[Node] as function return variables, address variables and global variables
3. for nodeVariable in varibles do 4. get the stateC meets
COD(9H9%I,J%KH&HLM%) 5. get the stateD meets
DAD(9H9%N,J%KH&HLM%) 6. add stateC,stateD to Output
7. End for
End
Input: Test cases, The program slice result
M %
The number of failed and successful test case
O, D
Output: The suspicion rank for each statement
Begin
1.for i = 0 to n do
2. get the executive path D%7% 3. D=D%7% ∩M %
4. End for
5. for e = 1 to m do
6. count the num of successful test case for line e :ID(%)
7. count the num of failed test case for line e :
8. [%] =
FG F FG
F 4FGF
9. End for
10. rank the suspicion for statements END
Experimental Results and Analysis
Experimental Data
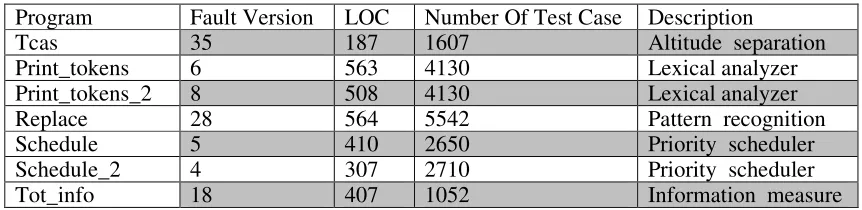
[image:6.612.90.521.315.420.2]This paper select the experimental data provided by the SIR(Software-artifact Infrastructure Repository) platform. SIR is a platform related to program analysis, software testing and it provides a lot of source programs, source programs with different version of injection faults and test cases. This paper uses the common fault localization test dataset, named Siement, which includes the Tcas, Schedule, Schedule2, Print_tokens, Print_tokens2, Replace, Tot_info, totally seven C language programs, and details of each program are described in Table 2. This paper eliminates the fault without unsuccessful test cases, and the defined fault, which are not suitable for fault location.
Table 2. Test Program Description.
Program Fault Version LOC Number Of Test Case Description
Tcas 35 187 1607 Altitude separation Print_tokens 6 563 4130 Lexical analyzer Print_tokens_2 8 508 4130 Lexical analyzer Replace 28 564 5542 Pattern recognition Schedule 5 410 2650 Priority scheduler Schedule_2 4 307 2710 Priority scheduler Tot_info 18 407 1052 Information measure
Experimental Evaluation Criteria
The evaluation criterion is according to the statement of fault suspected ranking percentage in the total number of program statements,as formula (2).And the lower the location ratio is, the higher location accuracy is.
M H9 &H9 =&HR ( (HM9: 9H9%8%9M% ( &S&H8 2
In the analysis that follows, this papernot only analyzes the best, worst and average location ratio. Further statistical analysis for the location of different proportions, the number of faults can be covered by. This statistical analysis combines a lot of fault results, not only simple analyze the single fault location, which can better reflect the effect of SIFL method.
Test Case Selection Experiment
The experiment firstly chooses the successful test cases with high similarity of the unsuccessful cases, which are more associated with the program's faults and more suitable for fault localization.In the third chapter, this paper has proposed to measure their similarity
standard&789: = ;<∩0
<∪0;.In this chapter, we through experiments to determine the number of
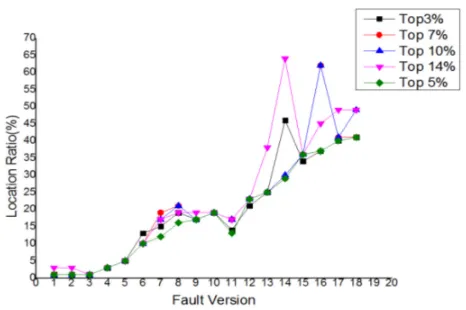
each version fault has many unsuccessful test cases, so choose the most similar 5% of each unsuccessful test case, the final selected test cases can also account for the average of 47.98% of the total test cases, which achieve better localization accuracy.
The proportion of the filter test cases is provided by a series of experiments, here as illustrated in Fig 4.In the figure, the horizontal axis represents the fault version number, ordinate indicates the location ratio of fault location. The location ratio is larger, indicating the effect of the worse locating. Here, in order to better display the impact of the number of test case selections, the fault localization results sorted from good to poor. It can be seen from the figure that the top 5% of the successful test case selection is better than others. And it can also be observed in the diagram, select too many unrelated success cases, or even affect the final sorting results.
Figure 4. Location effects withtest case selection scale.
Fault Localization Results and Analysis
[image:7.612.190.423.203.358.2]This section analyzes the fault localization results through the Siementdata set and the total of 104 versions of faults. The result concludes that the improved SIFL fault localization method achieves better fault localization than before method. For the 39.42% fault, the fault locates the position ranked in the top 1% parts of the program. And in the fault locating the top 10% parts of the entire program, covering the 95.19%fault versions. It can be explained that for most programs, just based on the fault location rank results, query the entire program 10% code, almost can find out the fault. This provides great convenience for locating large programs, and also reduces a lot of unnecessary work. The basic average localization can find the fault in the top 3.076% of the program, and realize the wellfault localization effect. The worst case is to see the first 20% part of the entire program, and can find out where is the fault of the program. The best, worst, and average location ratio for each program can be viewed in Table3.
Table 3. SIFL fault location Result.
Program Avg Best Worst
Tcas 1.681% 0.535% 4.278% Print_tokens 5.329% 0.178% 15.986% Print_tokens_2 3.962% 0.197% 11.417% Replace 2.379% 0.178% 20.819% Schedule 1.878% 0.732% 9.024% Schedule_2 9.935% 6.189% 19.870% Tot_info 3.481% 0.245% 8.354% Avg 3.076% 0.572% 11.490%
[image:7.612.156.453.576.705.2]and SIFL method. SIFL method is combined with slicing improvement method and test case improvement method. Fig.5 shows the average localization of the four ways of each program, which is compared with the histogram analysis. Most of the SIFL fault localization effect is much better than the previous localization effect. In particular for Schedule2 and Tcas program, average location ratio is improved from 23.61% to 9.93%, and 6.82% to 1.68%.However, as for the schedule program, because the selected test case localization effect is poor, resulting in SIFL fault localization effect compared to the previous accuracy is a slight decline. Fig6 also shows the comparisons between four methods, where in the horizontal axis represents percentage of executable statements that need to be examined, the ordinate indicates the percentage of faulty versions has been found. By the illustration 6, it can be seen that the SIFL fault localization method has better localization accuracy than the previous localization method, especially for the spectrum-based technology. Using the spectrum-spectrum-based fault localization method, when the fault locates the whole program first 10%, only the fault version of 73.08% is detected. While, SIFL is covering 95.19% of the fault versions in the same proportion, the accuracy rate of fault localization is improved greatly.
Figure 5. The average location ratio of four methods Figure 6. The fault coverage ratio of four methods.
Conclusion
Program fault localization is a necessary and time-consuming process in software development, so it is very meaningful to research an efficient fault localization method. This paper improves the traditional program spectrum-based technology through adding program slicing technology and test case selection. And this paper carries out the experimental test using the data set Siement. The result rank given by SIFL method accounted for the top 10% of the entire program, covering 95.19% of the faulty versions. Compared to the previous spectrum-based fault localization method only covering 73.08% of the faulty versions, the new method SIFL has a 22.11% increase and using the improved SIFL method, the average location ratio is in the 3.076% of the program. The SIFL method can greatly improve the accuracy of the automatic fault location, and can help the developers to locate the fault quickly and easily.
In recent years, there have been many studies in fault location[8][9][10]. However, there are still many areas worthy of further research, such as code missing and concurrency error. As for these two kinds of faults, the existing fault location methods cannot be better locating, and there are still many problems need to continue to study and research.
References
[1]http://sir.unl.edu/portal/index.php
[3]V. Dallmeier, C. Lindig, and A. Zeller, “Lightweight defect localization for Java,” inProc. Eur. Conf. Object-Oriented Program., Glasgow, U.K., Jul. 2012, pp. 528–550.
[4]J. A. Jones, and M. J. Harrold, “Empirical evaluation of the tarantula automatic fault-localization technique,” in Proc. Int. Conf. Autom. Softw. Eng., Long Beach, CA, USA, Nov. 2005, pp. 273– 282.
[5]Wong, W.E., Qi, Y., Zhao, L., Cai, K.-Y., 2007. Effective fault localization using code coverage. In: Pro of the 31st AICSAC, vol. 1.
[6]Everitt, B.S. Graphical Techniques for Multivariate Data. North-Holland, 2010, New York.
[7]D. Weiser and M. Harman, “A survey of empirical results on program slicing,”Adv. Comput., vol. 62, pp. 105–178, Jan. 2004.
[8]R. K. Saha, M. Lease, S. Khurshid, and D. E. Perry. Improving bug localization using structured information retrieval. In 28th IEEE/ACM Int. Conference on Automated Software Engineering, 2013.
[9]L. C. Briand, Y. Labiche, and X. Liu, “Using machine learning to support debugging with tarantula,” in Proc. IEEE Int. Symp. Softw. Rel., Trolhattan, Sweden, Nov. 2007, pp. 137–146.