1
Chapter 1 INTRODUCTION
1.1 Introduction
With the advent of internet the world of computer and communication has been revolutionized. The internet can be defined as a mechanism for information dispersal with world-wide transmission proficiency which acts as a medium for coactions and intercommunication between individuals and their computers without regard of geographic location. Internet has played very important role in research and development of information infrastructure. Evolution of internet began with early research on packet switching and the ARPANET and the research continues to expand along several areas such as performance, scale and higher level functionality.
In late 1966 DARPA (Defense Advanced Research Projects Agency) developed the computer network concept and this concept was published as ARPANET in 1967. In 1968 DARPA released an RFQ for the development of one of the key components, the packet
switches called interface message processors (IMP’s). The Bolt Beranek and Newman (BBN) team worked on IMP’s which lead to overall development of ARPANET architectural design and the network topology. In 1969 BBN installed the first IMP at UCLA which resulted in first host computer being connected. By the end of 1969, four host computers were connected together into the initial ARPANET and thus began the internet. In such an early stage stress was laid on networking research which integrated work on elementary network and how to employ the network. This rule is being followed even today also.
The original ARPANET transformed into the internet. Internet was based on idea that there would be multiple independent networks of rather random design, beginning with ARPANET which will include other networks to increase the functionality. This lead to the development of open architecture network, in which individual networks are designed and developed separately and each may have its own unique interface. Such types of networks were designed according to the user requirements in some specific environment. No constraints were applied on them such as geographic scope. The idea of open-architecture networking was introduced by Kahn at DARPA in 1972. Kahn also developed a new the protocol which could meet the requirements of open-architecture network environment. This protocol was
2
Transmission Control Protocol/ Internet Protocol (TCP/IP). Kahn expected that TCP protocol support a range of transport services, from reliable sequenced delivery of data to a datagram service, but TCP worked only with virtual circuits. This leads to the development of an alternative protocol which was named User Datagram Protocol (UDP).
Large scale development of LANs, PCs and workstations in 1980s allowed the developing internet to flourish. This leads to the development of many new concepts and changes to underlying technology. First, it resulted in the definition of three network classes (A, B, and C) to accommodate the range of networks. Class A represented small number of networks with large number of hosts, Class B represented regional scale networks and Class C represented local area networks i.e. large number of networks with relatively few hosts. For the ease of the users, hosts were assigned names. Earlier there were very less number of hosts, so it was easy and feasible to maintain a single table of all hosts and their associated names and addresses. But as the usage of the Internet increased, the number of hosts also increased. So having a single table to maintain hosts was not feasible option. This resulted in development of Domain Name System (DNS). It was invented by Paul Mockapetris of USC/ISI. The DNS permitted scalable distributed mechanism for resolving hierarchical host names into an internet addresses.
The increase in the size of the Internet also challenged the capabilities of the routers. Originally, there was a single distributed algorithm for routing that was implemented uniformly by all the routers in the Internet. As the number of networks in the Internet exploded, this initial design could not expand as necessary, so it was replaced by a hierarchical model of routing, with an Interior Gateway Protocol (IGP) [46] used inside each region of the Internet, and an Exterior Gateway Protocol (EGP) used to tie the regions together. This design permitted different regions to use a different IGP, so that different requirements for cost, rapid reconfiguration, robustness and scale could be accommodated. Not only the routing algorithm, but the size of the addressing tables, stressed the capacity of the routers. New approaches for address aggregation, in particular classless inter-domain routing (CIDR), have recently introduced to control the size of router tables.
1.2 Routing in the Internet
The basic function of the router in a network is to determine the best route for a packet to travel across a network from its source to its destination. Routers accomplish this task by
3
storing information in tables and referring to these tables to determine the best path. Various routing protocols have been developed to assist the router in mapping the network and create routing tables.
Networks within the internet can be divided into domains. The network under each domain falls under the same administrative authority but they differ in terms of scale, autonomy and privacy which are applied to routing within a domain and routing between domains. Based on domains routing can be broadly classified in to two types which are discussed in following sections.
1.2.1 Intradomain Routing
Intradomain routing is performed on a single domain or a single network and the administrator of the domain has full control and information about network topology, load, and configuration.
The goal of Intradomain routing is to establish network connectivity even as network topology keeps on changing due to link additions, hardware failures and to avoid congestion by load balancing. Intradomain routing forms a set of uniform, best routes at every router to each Intradomain destination. One of the most common intradomain routing protocol are link state protocols. In link state routing protocol, routers collect information about the state of links according to which routers can update their view of network topology. From this information the routers construct a weighted graph. From this graph shortest paths are selected and traffic is routed to that path. If routers find multiple shortest paths then traffic is evenly distributed on all those paths (Load balancing). Changes to the network topology initiate new link state packets which in turn reinitiate re-computations of network topology and best routes. Link state routing protocols [45] does not provide flexibility because it only allows distributing the traffic on paths of the same minimal cost and if same link weights are used before and after link failure, the performance can degrade.
1.2.2 Interdomain Routing
In Interdomain routing traffic is exchanged between different domains which are controlled
by different administrators which do not have full knowledge about other’s domain. Unlike Intra domain routing, paths are calculated across the domains that the traffic needs to traverse to reach destination. Once the packet is forwarded to another domain, that domain has total control over it & its next path.
4
In 1984, EGP (Exterior gateway protocol) became formalized in RFC 904. EGP are path vector protocols in which when information about router is exchanged, then entire path (Called path vector) is included in it. From this information Nodes/Stations can check whether they already appear in path vector and if so they discard that route. Routes are maintained at the autonomous system (AS) / domain level. EGP message do not contain information about routes which are used within a domain, which results in the privacy of network topology from other domains.
EGP Route-selection Procedure: Each router maintains a routing table with AS paths to various IP prefixes. If more than one router is available at the destination then selection of
best route is done on the basis of router’s local policy configuration. These local policies
directly influence the setting of attribute values which the information about a route stored in routing table entry. To gain knowledge about destination advertisements are broadcasted from neighbouring routes. Once a path has been established between AS, they exchange reach ability information with its neighbours. This allows the AS to gain information about destination. Paths are established by repeating the following three step process: (i) Routes are imported through neighboring routes which contains information about established routes. This route information depends upon update message & import policy. (ii) For each
destination the protocol’s best route selection procedure is used to choose best routes. (iii) These selected best routes are then exported by advertising them to neighboring routes through update message.
The routes which exchange this information with inter-AS connections are called border routers. The EGP establishes connectivity & share reach ability information across inter-domain links and it also distributes information of inter-inter-domain routes to non-border routes. EGP uses autonomous system number (ASN). ASN is represented by a unique 2-byte or recently introduce due to ASN pool exhaustion, 4-byte identifier associated with AS. ASN’s
are assigned in blocks by the internet assigned numbers authority (IANA) to regional Internet
registries (RIR’s). Recursively, RIR’s assign ASN from their IANA allocated blocks within
its designated area.
1.2.3 BGP (Border Gateway Protocol)
To overcome the problems of EGP, in 1989 the new protocol was introduced BGP [46] (Border Gateway Protocol). BGP no longer let routers find neighbours on their own; it required them to be configured manually and ran over TCP. BGP version (RFC 1105) - June
5
1989 still had the notion of up, down or horizontal relationships as in EGP. This limitation was removed in BGP-2 (RFC1163) June 1990 along with major changes to the message formats BGP-3 (RFC 1267). In 1991 BGP identifier field was introduced in the open message and defined how to use this field to decide which connection is terminated when two BGP neighbours each initiate a TCP session at the same time.
In 1994, BGP-4 (RFC1654, later RFC 1771) added CIDR (Classless Interdomain routing), aggregation support, the local preference attributes and a per-connection hold time.
In BGP every router receives reach ability information from its neighbours and then router chooses the route with the shortest path for inclusion in the routing table and announces this path to other neighbours, if the routing policy permits it.
The path is a list of every Autonomous System (AS) between the router & the destination. The idea behind AS is that network don’t care about the inner details of other networks. Thus
instead of listening every router along the way, BGP groups network together within ASes (Autonomous Systems) [55] so they may be viewed as a single entity, whether an AS contains only a single BGP-speaking router or hundreds of BGP and non-BGP speaking routers.
BGP 4 is the de-facto routing protocol in Internet. The reason BGP has achieved its status in the Internet today is because it has following characteristics:
1. Reliability:BGP’s reliability can be examined from following perspectives:
a) BGP uses TCP (Transmission Control protocol) on port 179 for communication between neighbours. This eliminates the need in BGP to implement update fragmentation, retransmission, Ack and sequencing because TCP takes care of these functions.
b) BGP also uses regular keepalives and update messages to maintain session integrity. A BGP session is closed if three consecutive keepalives are missed and no update messages are received.
c) BGP uses various measures to transmit accurate routing information. For e.g., (i) When updates are received, AS-PATH (a BGP attribute that lists the Ases the route has transferred) is check to detect loops. (ii) Inbound filters can be applied to all updates that ensure conformance to local policies. (iii) Unreachable routes are removed from time to time.
6
2. Stability: In order to achieve stability in large network, BGP uses various
mechanisms such as Minimal Route Advertisement Interval (MRAI), along with filters to avoid synchronization of updates. Route dampening is another BGP feature that suppresses instability by penalizing the unstable routes.
3. Scalability: Scalability of BGP can be evaluated in two ways: (i) Number of peer
sessions (ii) Number of routes. Depending on the configuration, Hardware platforms and Cisco IOS release, BGP has been proven to support hundreds of peer sessions and maintain well over 100,000 routes. To increase the scalability of BGP, the number of routes to be maintained or the number of updates generated can be reduced. BGP also uses route reflection and confederation to increase the scalability. Aggregation of routes is another tool that BGP uses to reduce the number of prefixes to be advertised and increase scalability.
4. Flexibility: The protocol can connect together any internetwork of autonomous
system using an arbitrary topology. The only requirement is that each ASes have at least one router that is able to run BGP and that this router connects to at least one
other ASes’s BGP router. BGP can handle a set of ASes connected in full mesh
topology, a partial mesh; a chain of ASes linked one to the next or any other configuration. It also handles changes to topology that may occur over time.
1.2.3.1 BGP Path Selection Process
BGP assigns the first valid path as the current best path. BGP then compares the best path with the next path in the list, until BGP reaches the end of the list of valid paths. Various BGP attributes used during the path selection are:
1. AS_PATH 2. NEXT_HOP 3. ORIGIN
4. MED (Multi Exit Discriminator) 5. LOCAL_PREF (Local preference) 6. WEIGHT
7. CLUSTER LIST 8. Community. 9. Aggregator. 10.Metric.
Following flowchart shows the BGP path selection algorithm [99] using the above mentioned attributes.
7
Select a path with the highest weight which is a local
parameter
Select the path with highest LOCAL_PREF whose default
value is 100.
Select a path that is originated locally
Select the path with the shortest AS_PATH
Select path with the lowest origin type. IGP is lower than EGP.
Select path with lowest MED (Multi –Exit Discriminator)
Prefer eBGP over iBGP paths
Is best path selected?
Select path with lowest IGP metric to the BGP next hop
A B
Yes
8
1.3 MPLS
(Multiprotocol label switching)
MPLS [26] is a routing protocol that is used to forward IP packets along “explicit routes”- pre-calculated routes that don’t necessarily match those that normal IP routing protocol
would select. MPLS performs the following functions: A
Determine if multiple paths
required?
Minimize RFD by selecting a path that was received first if both
paths are external
Prefer route that comes from BGP router with lowest router
ID
If the originator or router ID is same for multiple paths, prefer
the path with the minimum cluster list length
Select the path that comes from lowest neighbour address.
Best path selected B
Yes
9
Ø Specifies mechanisms to manage traffic flows of various granularities, such as flows between different hardware, machines, or even flow between different applications. Ø Remains independent of the Layer-2 and Layer-3 protocols.
Ø Provides a mean to map IP addresses to simple, fixed-length labels used by different packet-forwarding and packet-switching technologies
Ø Interfaces to existing routing protocols such as resource reservation protocol(RSVP) and open shortest path first(OSPF)
Ø Supports the IP, ATM and frame-relay Layer-2 protocols
In MPLS, data transmission occurs on label-switched paths (LSPs). LSPs are a sequence of labels at each and every node along the path from the source to the destination. LSPs are established either prior to data transmission (Control-driven) or upon detection of a certain flow of data (data-driven). The labels, which are underlying protocol-specific identifier, are distributed using label distribution protocol (LDP) or RSVP [76] or piggybacked on routing protocols like border gateway protocol (BGP) [46] and OSPF [45]. Each data packet encapsulates and carries the label during their journey from source to destination. High-speed switching of data is possible because the fixed-length labels are inserted at the very beginning of the packet or cell and can be used by hardware to switch packets quickly between links. MPLS Operation
The following steps must be taken for a data packet to travel through an MPLS domain. 1. Label creation and distribution
2. Table creation at each router 3. Label-switched path creation 4. Label insertion/table lookup 5. Packet forwarding
The source sends its data to the destination. In an MPLS domain, not all of the source traffic is necessarily transported through the same path. Depending on the traffic characteristics, different LSPs could be created for packets with different CoS requirements.
1.4 Justification of Problem
This thesis discusses three significant challenges that network operators must deal to provide reliable service and the respective solutions that are proposed in this thesis.
10 1. Safety of Interdomain Routing
BGP protocol is based on trust; therefore it does not certify the route update messages. This can result in announcement of any route into system and AS cannot verify that announcement. Such types of announcements are known as malicious attack that leads to traffic interference or loss of connectivity. Example of malicious attack:
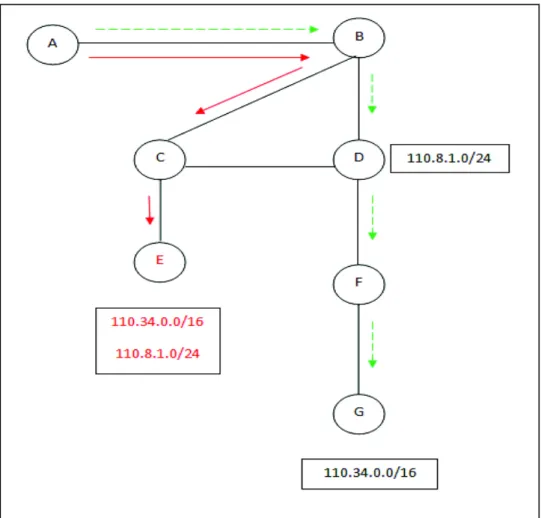
Fig 1.1 Malicious attack using address prefix
Address block 110.8.1.0/24 and 110.34.0.0/16 belong to nodes E and D respectively. Node E is a bogus/malicious and it advertises two address blocks which it does not own. Some nodes on the network will believe these bogus route announcements and will transmit data to the adversary. For example: If Node A sends data to an address in address block 110.34.0.0/16, it will reach node E instead of valid and authenticated node G.
11
Hackers announce incorrect prefixes in order to get hold of sensitive data moving on network. Many BGP attacks have been occurring in the internet. One such case occurred in Feb 2008 [67] when Pakistan telecom brought down YouTube worldwide for several hours when they tried to block local access to the service. They, by mistake propagated new routing information to PCCW, an ISP in Hongkong that propagated the route further. Another such kind of incident happened on April 8, 2010 [78] when Chinese Telecom rerouted traffic destined to about 15% of the address space through servers in china. This also affected traffic destined to US govt and military sites [8].
To achieve privacy several cryptographic measures have been proposed. But such security measure does not work on small scale deployments i.e. for 6-11 participating ASes. Security benefits can be achieved through a combination of several mechanisms.
2. Routing Policies of BGP leading to cycles
ASes (Autonomous systems) uses BGP to communicate with each other. Although each AS is independent to select their route preferences and path export policies, but certain policy combinations can lead to permanent cycles in routing system. In these cycles, Routers interchange control plane messages in a cyclical fashion endlessly. This can result in BGP divergence & an unstable BGP. Example of cycle can be shown as follows:
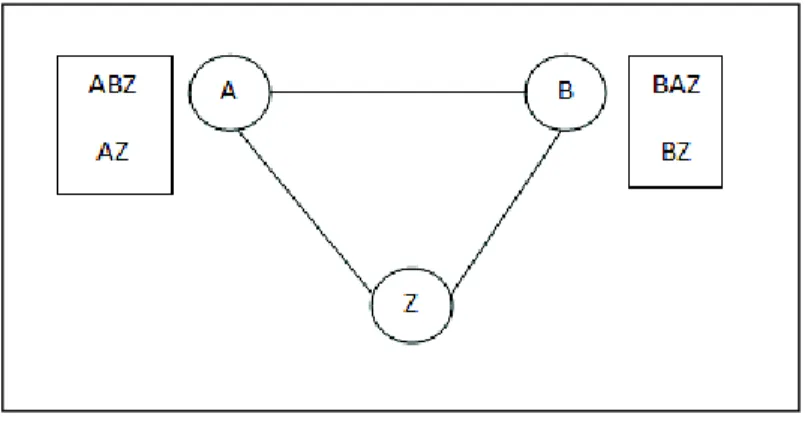
Fig 1.2 Conflicting routing policies
There are two nodes- Node A and Node B. Both want to reach destination Node ‘Z’. To reach node ‘Z’, Node ‘A’ prefers the indirect route through node ‘B’ over the direct route. Similarly Node ‘B’ prefers the indirect route through Node ‘A’. This situation can lead to cycle as follows:
12
1. Originally, node A & B select direct route ‘AZ’ and ‘BZ’ respectively. Nodes
simultaneously inform each other about the path they are using.
2. After some time both nodes switch to indirect routes ‘ABZ’ and ‘BAZ’, which creates a temporary cycle between nodes ‘A’ and‘B’. This cycle is removed as soon as nodes
inform each other about their new paths and routers update this information.
3. But if this update is once again performed simultaneously, the routes ‘AZ’ and ‘BZ’
will be selected and the entire process can repeat itself resulting in cycle. With drawing BGP cycles is critical as cycles can have negative effect on both control plane and data plane. Control plane are routing messages interchanged by the routers where as data plane are data packets roaming on networks.
In control plane, cycle increase the number of route renewals which increases load on routers because they are capable enough to process messages at such high speed. Routers on internet are already processing approx 350,000 address prefixes, which causes heavy load even without cycles. Cycles also cause unwanted hindrance or packet drops in the data plane. So cycles may lead to stern performance degeneration for the user.
Simple Path Vector Protocol (SPVP) [90] which is proposed by Griffin, Shepherd and Wilfong is a theoretical model of BGP that provides framework to study BGP stability. The most well known result in that framework is a structure known as dispute wheel. Absence of dispute wheel is a sufficient condition to prevent cycles, but there exist other network configurations where BGP protocol cycles but the SPVP model does not. Furthermore, the SPVP model abstracts many implementation details of BGP protocol.
3) Traffic Organization after failure
Load balancing on network is one of the important tasks for the network operator. Further they need to handle planned equipment maintenance and unplanned failures smoothly so that users do not get distracted by these problems.
Network operators work burden further increases because of the changing bgp traffic patterns during the day and they need to satisfy strict service level agreements (SLAs) which specify for example: the maximum average delay that the network traffic can experience. There are two possible techniques that can be used to protect against failures:-1) local Path preservation. 2) Global Path preservation
13
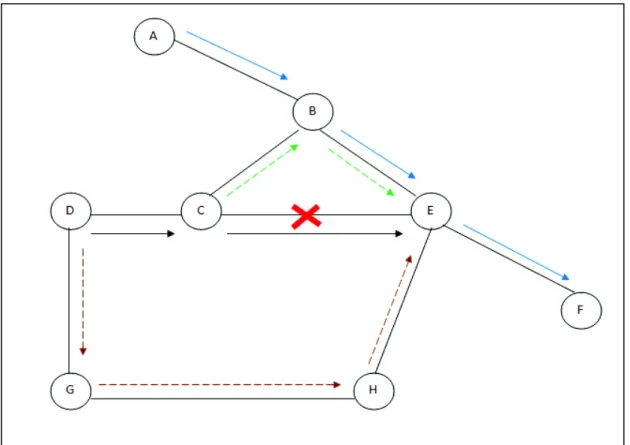
In Local path preservation, failure is repaired locally by sending traffic on alternate path between the two endpoints of the failed link. In fig Node D was sending traffic to Node E via Node C but link between Node c and E crashed, so that Node C used local path preservation and start sending data via Node B to E.
But here problem of congestion arises because Node B is already used by Node A to send data to Node F. So load on Node B increases which lead to congestion and hence dropping of packets.
Fig 1.3 Path preservation techniques
In Global path preservation, traffic is transmitted on an alternate end-to-end path, which allows spreading load in the network more evenly. Consider same figure, If Node D selects a new path via Node G and H to reach e instead from C-B-E, then load is evenly distributed on links.
Today’s Network handles recovery from failure and traffic engineering independently. This
leads to increase complexity in routers and selection of less efficient paths after failure. There is no architecture to optimize load balancing under wide range of failure scenarios that does not require re-optimization after a failure.
14
1.5 Aim of Study
In the Internet, BGP is de-facto Interdomain routing protocol. BGP allows the autonomous systems (ASes) to exchange reachability information with each other. Each AS has its own independent routing decisions and export policies. AS trusts it neighbour and believes that whatever information about routes announcements is done by its neighbors is true and authentic. Due to this BGP becomes vulnerable to attacks, steady cycles and improper load balancing during failures of channels. The aim of study is to make BGP more stable and reliable. It is to make best-effort services better. The study is done in three areas:
1. Security of Interdomain routing will be analyzed. During this study it will be established that small groups of cooperating system will form the basis of solution for secure Interdomain routing. As present proposals of secure Interdomain routing does not provide significant security benefits in small scale implementations. Moreover implementation of present secure solutions is not viable from economic point of view and also it requires coordination among large number of autonomous systems (ASes). In addition current mechanisms offer very little help to non-cooperating ASes which becomes soft target for hijackers. During this study a combination of mechanisms will be analyzed which will provide security gains to both cooperating and non-cooperating ASes alike. The solutions proposed during this study does not aim to remove the adversary completely but it raises bar for them so that it is not easy for them to attack on network and make it unstable.
2. Previous studies of Interdomain routing considered that routers select and advertise the most-favoured available route. But in practice routers may temporarily advertise other recently available routes or they remove routes when destination is not available. Due to these unexpected announcements cycles can occur which were not captured by the previous models which lead to unstable network. A new theoretical model will be proposed which will capture the effect of various local operational features of BGP (like RFD, MRAI timer etc) which can result in cycles. In this work an algorithm will be proposed which will provide combination of necessary and sufficient conditions for safety of routing policies in practice.
3. Today’s network handle failure restoration and traffic engineering separately which
lead to increased complexity in routers and selection of less efficient paths after failure. Due to this load balancing was not properly done and hence an unstable
15
network. In this work a framework will be proposed which will integrate traffic engineering and failure restoration for safe delivery of data even in presence of link failures. The proposed framework will reduce burden from routers and will move functionality to mainframe organization which will compute routes offline after failures so that load balancing can be done properly. This will result in selection of stable routes after failures.
1.6 Organization of Thesis
Introduction of the subject is covered in Chapter 1 and rest of the thesis is organized as follows:
Chapter 2 gives the background and reviews of related work. A survey is provided on various mechanisms used in securing Interdomain routing, removing cycles caused by conflicting routing policies and traffic engineering with failure restoration. Various proposed techniques are reviewed and compared.
Chapter 3 discusses the formulation of problem and various general concepts and models that are required in solving the problem areas discussed in this research work. This chapter gives insight to various challenges and issues that causes network instability.
In Chapter 4 simulations are performed to show that how partial implementation of soBGP on small groups does not offer significant security gains. Based on these results two approaches are proposed which are evaluated on realistic AS topology.
Chapter 5 discusses safety criterion for BGP with pseudo renewals and also combination of necessary and sufficient conditions are proposed. The algorithms proposed in this chapter are evaluated using theorems.
Chapter 6 provides an integrated framework for traffic engineering and failure restoration. Various optimization equations show the working of proposed framework which is simulated using realistic as well as synthetic topologies.
Finally Chapter 7 concludes the contribution of the research work. Various directions have been described for the future research on the proposed work.