A Progressive Technique for Duplicate Detection Evaluating Multiple
Data Using Genetic Algorithm with Real World Objects
K. Sai Mallikarjuna1, N. Sushma2
1
M.Tech Scholar, Department of Computer Science & Engineering,
2Assosc.Professor, Department of CSE, BVC Institute of Technology & Science, Batlapalem, Amalapuram, AP,
India.
Abstract
Here in this paper we discuss about an analysis on progressive duplicate record detection in real world data have at least two redundancy in database. Duplicate detection is strategy for recognizing all instances of various delineation of some genuine items, case client relationship administration or data mining. An agent case client relationship administration, where an organization loses cash by sending different inventories to a similar individual that would bring down consumer loyalty. Another application is Data Mining i.e to rectify input data is important to build valuable reports that from the premise of components. In this paper to learn about the progressive duplication calculation with the assistance of guide lessen to recognize the duplicates data and erase those duplicate records.
Keywords - Data Duplicity Detection, Progressive
de duplication, PSNM, Data Mining, Data Cleaning.
I. Introduction
Today databases assume a critical part in IT based economy. Numerous businesses and frameworks rely upon the efficiency of databases to complete all activities. Consequently, the nature of the records that are put away in the databases, can have critical cost signs to a framework that depends on data to lead business. With this regularly expanding greater part of data, the data quality issues emerge. Duplicate records detection can be separated into three stages or stages. Applicant depiction or definition, to choose which objects are to be contrasted and each other. Furthermore, besides duplicate definition, the criteria in light of which two duplicate competitors are as a general rule duplicates. Thirdly real duplicate detection, which is determining how to recognize duplicate applicants and how to distinguish genuine duplicates from hopeful duplicates. Initial two stages should be possible disconnected simultaneously with framework setup. Third step happens when the genuine detection is performed
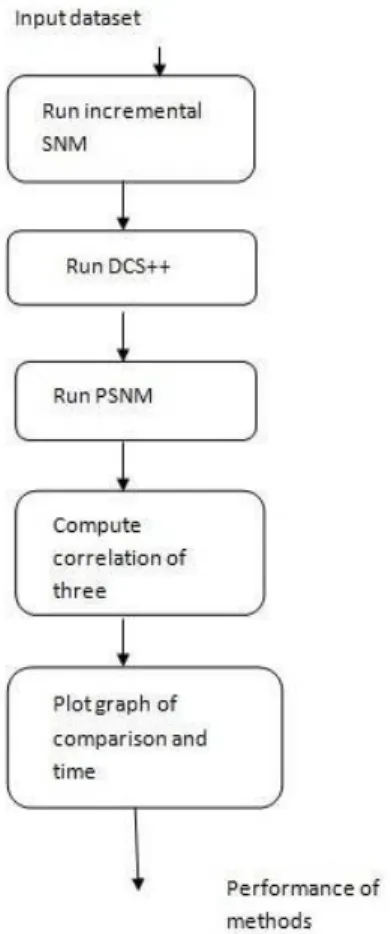
and the calculation is run. Various, or distinctive portrayals of a similar genuine protests in data, duplicates, are a standout amongst the most exciting data quality issues. The impacts of such duplicates are unfriendly; for example, bank clients may acquire duplicate personalities, stock levels are directed erroneously, same lists are sent various circumstances to similar areas and furthermore the presentation of same item portfolio. Progressive duplicate detection utilizing versatile window calculation decreases the normal time and discovers more number of duplicate combines more productively and quicker than the current frameworks. Furthermore, we know distinguishing duplicates consequently is a troublesome method: Firstly, duplicate portrayals are normally not proprium but rather may marginally contrast in their qualities. Besides, in essential all sets of records ought to be thought about, which is infeasible for tremendous volumes of data. Nonetheless, the tremendous size of the present datasets render duplicate detection forms more costly. Progressive duplicate detection utilizing versatile window calculation adjusts the progressive arranged neighborhood strategy and dcs++ technique. In this manner our proposed framework gives properties of both somewhat to give preferred outcomes over the current. Our new framework, versatile progressive snm will be speedier than the dcs++ calculation [2] and discovers a bigger number of duplicates than the progressive arranged neighborhood technique [1]. So we have a framework which gives more productive and exact outcomes than the current frameworks. The correlation of these three calculations are appeared in fig 2. Our technique does not utilize the idea of window amplification, it rather utilizes the parcel measure idea. In psnm in spite of the fact that its handling speed is high it doesn't locate all duplicate present in the dataset. Also, in dcs++ technique despite the fact that it discovers more duplicate its preparing speed is low.
Papenbrock, Heiseand Neumann [1] presents two novel methodologies, progressive duplicate detection calculations that altogether increment the effectiveness of discovering duplicates if the execution time is constrained. They expand the pick up of the general procedure inside the time accessible by detailing most outcomes considerably sooner than customary methodologies. Extensive trials demonstrate that progressive calculations can twofold the proficiency after some time of customary duplicate detection and essentially enhance related work. Progressive duplicate detection distinguishes most duplicate combines ahead of schedule in the detection process.Instead of lessening the general time expected to complete the whole procedure, progressive methodologies attempt to decrease the normal time after which a duplicate is found. Early terminations, specifically, at that point yields more total outcomes on a progressive calculation than on any conventional approach. Whang et.al. [2] Proposed a sort of progressive duplicate detection calculation. Element determination is the issue of distinguishing which records in a database alludes to a similar element. By and by, numerous applications need to determine vast data sets proficiently, yet don't require the ER result to be correct. For instance, individuals data from the Web may basically be too huge to totally resolve with a sensible measure of work. For instance, constant applications will most likely be unable to endure any ER handling that takes longer than a specific measure of time. This examines how we can amplify the advance of ER with a constrained measure of work utilizing "insights," which give data on records that are probably going to allude to a similar certifiable substance. An indication can be spoken to in different arrangements. It presents methods for building indications proficiently and systems for utilizing the insights to amplify the quantity of coordinating records recognized utilizing a constrained measure of work. By utilizing genuine data sets, the potential increases Pay-as-you-go approach contrasted with running ER without utilizing indications. Here the novel idea of clues, this can manage an ER calculation to center around settling the more probable coordinating, records. Our procedures are viable when there are either an excessive number of records to determine inside a sensible measure of time or when there is a period constrain. Three kinds of clues that are good with various ER calculations: an arranged rundown of record matches, a pecking order of record segments, and an arranged rundown of records. In this work assessed the overhead of developing indications and in addition the runtime benefits for
utilizing clues. The outcomes propose that the advantages of utilizing clues can be certainly justified regardless of the overhead required for building and utilizing indications and a general direction for developing and refreshing the "best" clue for any given ER calculation.
III. Duplicate Count Strategy ++
This method is the extension of DCS Duplicate Count Strategy. It is a strategy which dynamically adapts the window size. That is it varies the window size based on the number of duplicates detected. Adaptation will sometimes increase or decrease the number of comparisons If more duplicates of a record are found within a window, the larger the window should be If no such duplicate of a record within its neighborhood is found, assume that there are no duplicates or the duplicates are very far away in the sorting order. Each tuple ti is once at the beginning of a window w it is then Compare with w 1 successors If no duplicate for ti is found, continue as normal else increase window.
DCS+ for finding original source is describes as follows: i
• Sorts the given data set
• specify the window w
• Compare the first record in the window
with that of all of the records in the window which is shown in Fig.2
• Increase window size while duplicate
detected / comparison ≥ φ where φ is a threshold
• Slide the window if no duplicates found
within the window
• If duplicates found, for each detected
duplicate the next w-1 records of that duplicate are added to the window.
• Duplicates are detected.
Fig. 1. Window Sliding Example
Fig. 2. Comparing records in DCS++
Fig. 3. Flow Chart for performing the detection
IV. PROGRESSIVE TECHNIQUES
The progressive techniques helps to satisfy the economic needs of the user. Some of the progressive techniques are discussed below.
A. Top k-set similarity Joins
It helps the user to eliminate the guess work that
the user have to perform when the user don’t know
the similarity threshold value. The top-k similarity metric is based on the Prefix filtering principle. Without prior similarity threshold, the proposed algorithm can progressively compute join results. By exploiting the monotonicity of maximum possible scores of unseen pairs, several new pruning and optimization techniques for top-k similarity join is developed. The experimental results shows that the algorithm outperforms in most cases and is applicable to the interactive applications. ER uses the hints as a guideline to compare the record pairs. With limited number of hints maximum number of record pair are identified. In this paper, we get partial results gradually, so we can get some results faster. Our goal is to get better intermediate ER result.
B. Progressive duplicate detection
Maintaining the quality of the dataset is difficult when processing the large dataset. With limited amount of time the algorithm increases the efficiency in finding the duplicate. They will increase the gain of the process and reports most results than traditional approaches within the available time. In Progressive Sorted Neighbourhood Method, The input data uses the predefined sorting key and in sorted order it compares the records inside a window. The algorithm iteratively vary the window size, by starting with small window size and finds the most promising record pairs quickly. The algorithm differs from traditional approach by dynamically changing the order of comparison in execution order based on the intermediate results by look ahead. It integrates progressive sorting phase and process large data sets. In look ahead after sorting the input data set, we find the areas of high and low duplicate density. It adjusts the ranking comparisons at runtime. If record pairs (i,j) is duplicate then there is high chance that (i+1,j) and (i,j+1) can be duplicates of the same clusters. Instead of waiting for the next iteration, it compares immediately
V. Duplicate Detection Tools
information institutionalization and the second plays out the genuine copy recognition.
The information institutionalization depends fundamentally on Hidden Markov Models (HMMs) along these lines Febrl ordinarily expects preparing to accurately parse the database passages. For copy discovery Febrl executes an assortment of string comparability measurements, for example, Jaro, alter separation and q-gram remove. At last Febrl bolsters phonetic encoding (Soundex, NYSIIS and Double Metaphone) to distinguish comparative names.
Since phonetic closeness is delicate to mistakes in the principal letter of a name Febrl additionally registers phonetic comparability utilizing the switched adaptation of the name string, evading the "main letter" affectability issue. [2] Is an adaptable record coordinating tool kit which enables the clients to apply distinctive copy discovery techniques on the informational collections? The adaptability of utilizing different models is valuable when the clients don't know which copy discovery model will perform most viably on their specific information. Takes after a layered plan isolating correlation capacities from the copy recognition rationale. Moreover the execution procedures which enhance the effectiveness are actualized in a different layer making the framework more extensible than frameworks that depend on solid outlines. At last reports insights, for example, assessed precision and culmination which can enable the clients to better comprehend the nature of a given copy recognition execution over another informational collection. Spin is a copy record recognition framework accessible for nothing for scholarly and inquire about utilize. Spin utilizes the tf.idf token based comparability metric to recognize comparative strings inside two records. The Flamingo Project is a comparable device that gives a basic string coordinating instrument that takes as information two string records and returns the strings combines that are inside a pre-determined alter remove edge. WizSame by WizSoft is likewise an item that permits the disclosure of copy records in a database. The coordinating calculation is fundamentally the same as Soft TF.IDF. Two records coordinate on the off chance that they contain a noteworthy portion of indistinguishable or comparative words where comparative are the words that is inside alter remove one. Bigmatch [2] is the copy recognition program utilized by the US Census Bureau. It depends on blocking systems to recognize potential matches between the records of two relations and scales well for expansive informational indexes. The main prerequisite is that
one of the two relations should fit in memory and it is conceivable to fit in memory even relations with 100 million records. The principle objective of Bigmatch isn't to perform modern copy location, but instead to produce an arrangement of competitor matches that ought to be at that point handled by more complex copy recognition calculations.
At long last, we should take note of that at present numerous database merchants (Oracle, IBM, and Microsoft) don't give adequate instruments to copy record recognition. The greater part of the endeavors as of recently have concentrated on making simple to-utilize ETL apparatuses that can institutionalize database records and fix minor blunders primarily with regards to address information.
Another commonplace capacity of the devices that are given today is the capacity to utilize reference tables and institutionalize the portrayal of substances that are outstanding to have different portrayals.
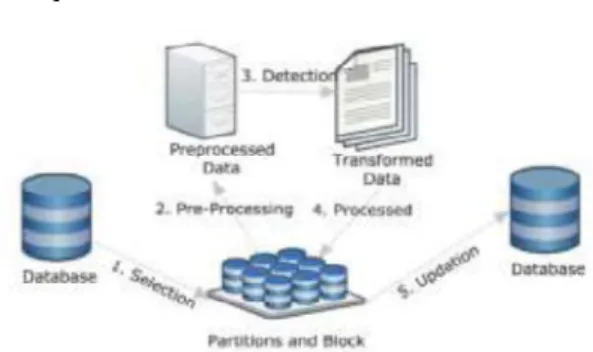
VI. Proposed Methodology
In a blunder free framework with superbly clean information, the development of a far reaching perspective of the information comprises of connecting in social terms, joining at least two tables on their key fields. Lamentably, information regularly do not have a special, worldwide identifier that would allow such an activity. Besides, the information are neither painstakingly controlled for quality nor characterized reliably crosswise over various information sources.
Two calculations are proposed, in particular dynamic arranged neighborhood strategy (PSNM), which performs best on little and clean datasets.
Dynamic blocking (PB), which performs best on substantial and extremely filthy datasets. Both improve the proficiency of copy location even on extensive datasets.
PSNM sorts the information utilizing a predefined arranging key and just thinks about records that are inside a window of records in the arranged request. The PSNM calculation varies by powerfully changing the execution request of the examinations in view of middle of the road comes about.
blocking procedure and the progressive expansion of squares
Fig 4. Proposed System Architecture
Proposed Algorithms
PSNM:
Step 1: procedure PSNM(D, K, W, I, N)
Step 2: pSize← calcPartitionSize(D)
Step 3: pNum←[N/pSize-W + 1)]
Step 4: array order size N
Step 5: array recs size pSize as Record
Step 6: order ←sortProgressive(D, K, I, pSize,
pNum)
Step 7: for currentI← 2 to[W/I]do
Step 8: for currentP←1to pNum do
Step 9: recs← loadPartition(D, currentP)
Step 10: for dist belongs to range(currentI, I, W) do
Step 11: for i←0 to |recs|_ dist do
Step 12: pair← <recs[i],recs[i+dist]>
Step 13: if compare(pair) then
Step 14: emit(pair) Step 15: lookAhead(pair)
PB:
Step 1: procedure PB(D, K, R, S, N)
Step 2: pSize← calcPartitionSize(D)
Step 3: bPerP← [pSize/S]
Step 4: bNum← [N/S]
Step 5: pNum← [bNum/bPerP]
Step 6: array order size N as Integer
Step 7: array blocks size bPerP as
Step8: priority queue bPairs as<integer;integer;integer>
Step 9: bPairs ←{<1,1,->, . . . ,<bNum,bNum,->} Step 10: order ←sortProgressive(D, K, S, bPerP,
bPairs)
Step 11: for i←0 to pNum- 1 do
Step 12: pBPs ← get(bPairs, i . bPerP, (i+1) .
bPerP)
Step 13: blocks← loadBlocks(pBPs, S, order)
Step 14: compare(blocks, pBPs, order) Step 15: while bPairs is not empty do Step 16: pBPs← {}
Step 17: bestBPs← takeBest([bPerP/4], bPairs, R)
Step 18: for bestBP€ bestBPs do
Step 19: if bestBP[1]− bestBP[0] < R then
Step 20: pBPs← pBPs U extend(bestBP)
Step 21: blocks←loadBlocks(pBPs, S, order)
Step 22: compare(blocks, pBPs, order)
Step 23: bPairs←bPairs U pBPs
Step 24: procedure compare(blocks, pBPs, order)
Step 25: for pBP€ pBPs do
Step 26: comp(pBP, blocks, order)
Step 27: emit(dPairs)
Step 28: pBP[2]←|dPairs|/ cNum
VII. Conclusion
References
[1] Thorsten Papenbrock, ArvidHeise, and Felix Naumann,‟ Progressive Duplicate Detection‟ IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 25, no. 5, 2014.
[2] S. Yan, D. Lee, M. yen Kan, and C. L. Giles,
“Adaptive sorted neighborhood methods for
efficient record linkage,” in International
Conference on Digital Libraries (ICDL), 2007.
[3] M. A. Hernández and S. J. Stolfo, “Real-world data is dirty: Data cleansing and the merge/purge
problem,” Data Mining and Knowledge Discovery,
vol. 2, no. 1, 1998.
[4] X.Dong, A.Halevy, and J.Madhavan,
“Reference reconciliation in complexinformation spaces,” in Proceedings of the International
Conference on Management of Data (SIGMOD), 2005.
[5] S.E.Whang, D.Marmaros, and
H.Garcia-Molina, “Pay-as-yougo entity resolution” IEEE
Transactions on Knowledge and Data Engineering (TKDE), vol. 25, no. 5, 2012.
[6] A. K. Elmagarmid, P. G. Ipeirotis, and V. S.
Verykios, “Duplicat record detection: A survey,”
IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 19, no. 1, 2007.
[7] U.Draisbach, F.Naumann, S.Szott, and O.
Wonneberg, “Adaptive windows for duplicate detection,” in Proceedings of the International
Conference on Data Engineering (ICDE), 2012.
[8] U.Draisbach and F. Naumann, “A
generalization of blocking and windowing
algorithms for duplicate detection.” in International
Conference on Data and Knowledge Engineering (ICDKE), 2011.
[9] L. Kolb, A. Thor, and E. Rahm, “Parallel sorted neighbourhoodblockingwithmapreduce,” in
Proceedings of the Conference Datenbank system in Büro, Technik und Wissenschaft(BTW
[10] U. Draisbach and F. Naumann, “A
generalization of blocking and windowing
algorithms for duplicate detection,” in Proc. Int.
Conf. Data Knowl. Eng., 2011, pp. 18–24.
Authors
K. Sai Mallikarjuna is pursing
M.TECH (CSE) in the Department of Computer Science and Engineering from BVC Institute of Technology & Science, Batlapalem, Amalapuram, AP, India.
N. Sushma is working as Associate