Available Online at www.ijpret.com 1342
INTERNATIONAL JOURNAL OF PURE AND
APPLIED RESEARCH IN ENGINEERING AND
TECHNOLOGY
A PATH FOR HORIZING YOUR INNOVATIVE WORK
APRIORI ALGORITHM USED FOR DATA MINING
PRANJALI SAWARKAR1, PROF. PRATIK AGRAWAL2
1. ME 1st year, (Computer Science and engineering), Prof. Ram Meghe Institute of Technology, & Research, Badnera. 2. Assistant Professor, (Computer Science and engineering), Prof. Ram Meghe Institute of Technology, & Research, Badnera.
Accepted Date: 05/03/2015; Published Date: 01/05/2015
Abstract: This paper illustrates the use of Apriori Algorithm in one of the most important domains in the Computer Science and Engineering field, i.e. Data Mining. With the help of this Apriori Algorithm, we can efficiently manage the data items in the data warehouse and retrieve the required data in a reasonable time. Otherwise, dealing with such a large data is not an easy task. The algorithm proposed in this paper is easy to implement and use. This algorithm is among the most influential data mining algorithms in the research community. Along with the algorithm, description, steps, effect of the algorithm as well as current and further research is also provided in this paper.
Keywords:Data Mining, Algorithms, Apriori Algorithm, Association Rules, Dataset, Itemset.
Corresponding Author: MISS. PRANJALI SAWARKAR
Access Online On:
www.ijpret.com
How to Cite This Article:
Available Online at www.ijpret.com 1343 INTRODUCTION
The Apriori Algorithm is used in the Data Mining. In this era of information, the large amount of data is available to process. Basically, data mining includes exploration and analysis of huge quantities of data so that one can discover valid, novel, particularly useful and understandable patterns in the available data. Data mining is the process which extracts predictive information, discovers the relevant knowledge from large amounts of data stored in databases, data warehouses or other information repositories.
2. LITERATURE REVIEW
Earlier, in the field of data mining algorithms, much work is accomplished. Many authors have provided their algorithms on data mining. A survey paper ‘Top 10 Algorithms in Data Mining’ is given by Xindong Wu and Vipin Kumar presents the top 10 algorithms identified by the IEEE International Conference on Data Mining (ICDM) in December 2006: C4.5,k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART. ‘An Efficient k-Means Clustering Algorithm: Analysis and Implementation’ proposed by Tapas Kanungo and David M. Mount, presents a simple and easy implementation of Lloyd’d k-means clustering algorithm, which is also known as the filtering algorithm, is also very useful in data retrieval and manipulation. Vaishali Ganganwar in ‘An overview of classification algorithms for imbalanced Dataset’ has proposed the common approaches which are helpful in dealing with the classification algorithms that contain imbalanced data items in its database.
3. PROPOSED WORK
The Apriori algorithm—
1.1theory of the algorithm
One of the most popular data mining approaches is to find frequent itemsets from a transaction dataset and derive association rules. Finding frequent itemsets (itemsets with frequency larger than or equal to a user specified minimum support) is not trivial because of its combinatorial explosion. Once frequent itemsets are obtained, it is straightforward to generate association rules with confidence larger than or equal to a user specified minimum confidence.
Available Online at www.ijpret.com 1344
assumes that items within a transaction or itemset are sorted in lexicographic order. Let the set of frequent
itemsets of size k be Fk and their candidates be Ck. Apriori first scans the database and searches for frequent itemsets of size 1 by accumulating the count for each item and collecting those that satisfy the minimum support requirement
1.2 steps
The loop iterates on the following three steps and extracts all the frequent itemsets.
1. GenerateCk+1, candidates of frequent itemsets of size k+1, from the frequent itemsets of size k.
2. Scan the database and calculate the support of each candidate of frequent itemsets.
3. Add those itemsets that satisfies the minimum support requirement to Fk+1.
The Apriori algorithm is shown in Fig.1.
1.3 algorithm
Algorithm 1 Apriori
Fl =(Frequent Itemsets of Cardinality 1);
for(k=1;Fk≠Ø;k++)do begin
Ck+1=Apriori_gen(Fk);// New Candidates
for all transactions t ϵ Database do begin
C’t=subset(Ck+1,t);// Candidates Contained in t
for all candidates c ϵ C’t do
c.count++;
end
Fk+1={C ϵ Ck+1 |c.count>= minimum support}
Available Online at www.ijpret.com 1345
end
Answer UkFk;
Fig. 1.1 Apriori Algorithm
Function apriori-gen in line 3 generates Ck+1 from Fk in the following two step process:
1. Join step: Generate Rk+1, the initial candidates of frequent itemsets of size k+1 by taking the union of the two frequent itemsets of size k, Pk and Qk that have the first k−1 elements in common.
Rk+1=Pk∪Qk={item1,...,itemk1,itemk,itemk’}
Pk ={item1,item2,...,itemk-1,itemk}
Qk ={item1,item2,...,itemk-1,itemk’}
where,item1<item2<···<itemk-1 <itemk’}
2. Prune step: Check if all the itemsets of size k in Rk+1 are frequent and generate Ck+1 by removing those that do not pass this requirement from Rk+1. This is because any subset of size k of Ck+1 that is not frequent cannot be a subset of a frequent itemset of size k+1.
Function subset in line 5 finds all the candidates of the frequent itemsets included in trans-action t. Apriori, then, calculates frequency only for those candidates generated this way by scanning the database.
It is evident that Apriori scans the database at most kmax+1 times when the maximum size of frequent itemsets is set at kmax.
The Apriori achieves good performance by reducing the size of candidate sets (Fig.1).
However, in situations with very many frequent itemsets, large itemsets, or very low minimum support, it still suffers from the cost of generating a table. In fact, it is necessary to generate 2100 candidate itemsets to obtain frequent itemsets of size 100.
1.4. Effect of the algorithm with example
Available Online at www.ijpret.com 1346
to this tradition. The introduction of this technique boosted data mining research and its effect is tremendous. The algorithm is quite simple and easy to implement. Experimenting with Apriori-like algorithm is the first thing that data miners try to do.
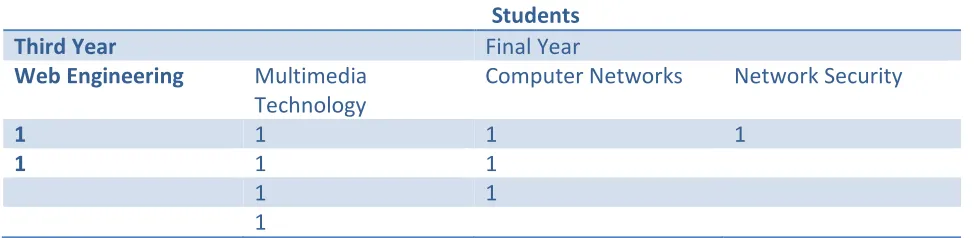
Suppose we have to find out answers of the queries directly without accessing the whole database, we will have to arrange the database in a systematic manner. Consider there is a group of 10 students and each one must select a subject from the 4 choices available to them as an elective in their academics. When each student will select an elective, first of all candidate generation will be carried out. Counter of each subject will be incremented by 1, when it will be chosen by any student. Hence the finally generated table will look as table I. With the help of this table, answering of queries will be easier and it will save the required time also.
TABLE 1.1
Students
Third Year Final Year
Web Engineering Multimedia
Technology
Computer Networks Network Security
1 1 1 1
1 1 1
1 1
1
1.5. Current and further research
Available Online at www.ijpret.com 1347
subset of the entire data. Since there is no guarantee that we can find all the frequent itemsets, normal practice is to use a lower support threshold. Trade off has to be made between accuracy and efficiency. Apriori uses a horizontal data format, i.e. frequent itemsets are associated with each transaction. Using vertical data format is to use a different format in which transaction IDs (TIDs) are associated with each itemset. With this format, mining can be performed by taking the intersection of TIDs. The support count is simply the length of the TID set for the itemset. There is no need to scan the database because TID set carries the complete information required for computing support. The most outstanding improvement over Apriori would be a method called FP-growth (frequent pattern growth) that succeeded in eliminating candidate generation [4]. It adopts a divide and conquer strategy by (1) compressing the database representing frequent items into a structure called FP-tree (frequent pattern tree) that retains all the essential information and (2) dividing the compressed database into a set of conditional databases, each associated with one frequent itemset and mining each one separately. It scans the database only twice. In the first scan, all the frequent items and their support counts (frequencies) are derived and they are sorted in the order of descending support count in each transaction. In the second scan, items in each transaction are merged into a prefix tree and items (nodes) that appear in common in different transactions are counted. Each node is associated with an item and its count. Nodes with the same label are linked by a pointer called node-link. Since items are sorted in the descending order of frequency, nodes closer to the root of the prefix tree are shared by more transactions, thus resulting in a very compact representation that stores all the necessary information. Pattern growth algorithm works on FP-tree by choosing an item in the order of increasing frequency and extracting frequent itemsets that contain the chosen item by recursively calling itself on the conditional FP-tree. FP-growth is an order of magnitude faster than the original Apriori algorithm.
Available Online at www.ijpret.com 1348
information gain or x2 value: These measures are useful in finding discriminativepatterns but unfortunately do not satisfy anti-monotonicity property. However, these measures have a nice property of being convex with respect to their arguments and it is possibleto estimate their upper bound for supersets of a pattern and thus prune unpromising patternsefficiently. Apriori SMP uses this principle [7]. (5) Using richer expressions than itemset:Many algorithms have been proposed for sequences, tree and graphs to enable mining from more complex data structure. (6) Closed itemsets: A frequent itemset is closed if it is not included in any other frequent itemsets. Thus, once the closed itemsets are found, all thefrequent itemsets can be derived from them. LCM is the most efficient algorithm to find theclosed itemsets.
4. CONCLUSION
Many algorithms have been developed for Data Mining that tried to overcome various problems associated in it. Apriori Algorithm proposed in this paper has added a significant contribution to assist in the optimization of the time constraint required in the data mining. We used the concept of candidate generation in the frequent itemsets to arrange the data in the database or the data warehouse and used that data as the required output of the queries. Our algorithm can obtain better performance if we reduce the size of candidate sets.
As future work we intend to develop more efficient algorithms that uses hash-based technique that reduces the candidate sets size. Currently, we are using horizontal data format in this paper.
5. REFERENCES
1. Xindong Wu, Vipin Kumar,J. Ross Quinlan, Joydeep Ghosh, Qiang Yang, Hiroshi Motoda, Geoffrey J. Mclachlan, Angus Ng, Bing Liu, Philip S. Yu, Zhi-Hua Zhou, Michael Steinbach, David J. Hand, Dan Steinberg, Top 10 algorithms in Data Mining Knowl Inf Syst (2008) 14:1–37 DOI 10.1007/s10115-007-0-1114-2.
2. Tapas Kanungo, Senior Member, IEEE, David M. Mount, Member, IEEE, Nathan S. Netanyahu,
Member, IEEE, Christine D. Piatko, Ruth Silverman, and Angela Y. Wu, Senior Member, IEEE, An Efficient k- Means Clustering Algorithm: Analysis and Implementation Vol.24, N0.7, July 2002.
Available Online at www.ijpret.com 1349
4. Han J, Pei J, Yin Y (2000) Mining frequent patterns without candidate generation. In: Proceedings of ACM SIGMOD international conference on management of data, pp 1–12.
5. Srikant R, Agrawal R (1995) Mining generalized association rules. In: Proceedings of the 21st VLDBconference. pp. 407–419.
6. Cheung DW, Han J, Ng V, Wong CY (1996) Maintenance of discovered association rules in large databases: an incremental updating technique. In: Proceedings of the ACM SIGMOD international conference on management of data, pp. 13–23.
![Di μ sulfato κ4O:O′ bis[diaqua(1H imidazo[4,5 f][1,10]phenanthroline)manganese(II)] dihydrate](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)