Copyright © 2013 IJECCE, All right reserved
Prediction Structures for Multi-view Video Coding
Heera Narayanan
P.G. Scholar,
Department of Electronics and Communication SCT College of Engineering, Trivandrum
Email: [email protected]
Dr. Sheeja M.K.
HOD and Professor,
Department of Electronics and Communication SCT College of Engineering, Trivandrum
Email: [email protected]
Abstract – Removing statistical redundancies is the key to achieve efficient video compression. Multi-view Video Coding (MVC) uses prediction structures for removing spatial and temporal redundancies. The compression is based on multiple reference frames as in H.264 standard. The reference frames are managed by following the hierarchical prediction structure. Intra frame, inter-frame and inter-view prediction schemes are efficiently combined to achieve compression from video sequences simultaneously generated using multiple camera systems. MATLAB simulation of an IPP hierarchical prediction structure is performed to test the efficiency of temporal and spatial prediction algorithms for MVC.
Keywords – MVC, H.264, Disparity, Motion Compensation.
I.
I
NTRODUCTIONVideo data, in its raw form has incredible size and this makes it impossible to transmit the data in its uncompressed form. Video compression standards are essential for reducing storage and transmission requirements. Many video coding standards have been developed in the past. A video stream has two spatial and a single temporal dimension. Video compression is usually performed independently on the spatial and temporal dimensions. Spatial redundancies were first utilized in JPEG compression standard. By the development of MPEG compression standards, the motion of objects between frames was utilized for achieving compression by the principle of temporal redundancy [1]. H.264/AVC uses both spatial and temporal correlation. The correlation between video frames was used to predict frames from adjacent frames. The difference between the original frames and the predicted ones, i.e., the prediction error was further encoded and transmitted. [2][3]
With the developments in display and camera technology, new applications for three-dimensional viewing have been introduced [4][5][6]. For achieving this, usually multiple video cameras are used to simultaneously acquire various viewpoints of the scene. The data from multiple camera systems thus obtained can be effectively used in 3-D displays and for applications like Teleconferencing, Free Viewpoint Video (FTV) etc. Since a huge amount of data is associated with this technique of multiple videos, MVC was developed and standardized as extension of H.264 compression standard [7][8][9].
MVC makes use of simultaneously captured video streams obtained from multiple cameras that view the same scene. Hence the video frames acquired contain a huge amount of spatio-temporal redundancies. These redundancies can be suitably exploited for
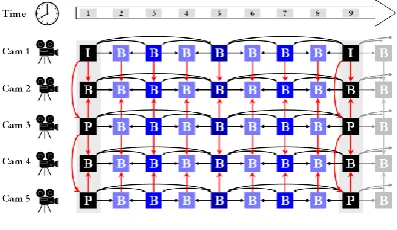
temporal\inter-view predictions. Predictive coding in MVC is performed on block level, i.e., the predictions are performed block by block instead of predicting the entire frame at a time. Hence each frame of the video sequence is divided into blocks called macro blocks. MVC allows variable block sizes, so the macro blocks can be of sizes 4x4 8x8, 16x16 etc. MVC makes use of hierarchical prediction structures as shown in fig1. The video frames are classified as I, P and B frames. I frames or Intra frames are usually the first or initial frames of a video and they usually undergo intra frame prediction. In other words, I frames do not require any reference frames but refer previously encoded blocks of the same frame. [10]
Fig.1. Prediction Structure for MVC
P frames use I frames or previously encoded P frames as reference frames. P frames use a single reference frame while B frames use two (or more) reference frames. Usually I frames require more number of bits that P and B frames. The increase in number of B frames reduces the number of bits but on the other hand increases the complexity of the systems. Hence, an IPPP structure or IBBBP structure is chosen according to the requirement. Prediction structures of MVC can be classified into three- intra, inter-frame and inter-view predictions which are explained in detail in the following sections.
II.
I
NTRAF
RAMEP
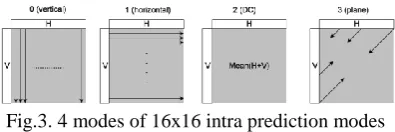
REDICTIONCopyright © 2013 IJECCE, All right reserved Fig.2. 9 modes of 4x4 intra prediction modes
Fig.3. 4 modes of 16x16 intra prediction modes
The main steps of intra prediction algorithm are given below-
1. Generate the predicted block according to modes shown in fig (2) or fig (3) depending on the block size. 2. Calculate the cost of prediction by determining the sum
of absolute difference b/w the original block and predicted block.
3. Repeat the above steps for all modes of prediction and determine the mode that minimizes the prediction cost. The block predicted by the mode that gives minimum cost is chosen. The process is repeated for every block in the frame and the predicted blocks, when combined, gives the predicted frame.
III.
I
NTERF
RAMEP
REDICTIONInter frame prediction is used to remove the temporal redundancies between the frames of a video sequence. The principle is to track the motion objects between two frames obtained at two different instants of time. Block matching algorithm is used to determine the motion of objects in the form of motion vectors and then interpolate these vectors to form the predicted frame. The process of determining motion vectors is called Motion Estimation and the process of predicting the frame using motion vectors is called Motion Compensation. For the first inter prediction, the coded intra frame is used as the reference frame. For further predictions, previously coded frames are used as reference. Depending on whether the frame is P or B, the number of reference frames may vary from one to two (or more) [25]-[28].
In motion estimation, the blocks in the current frame are compared with the corresponding block and its adjacent neighbours in the previous frame to create a vector that stipulates the movement of a macro block from one location to another in the previous frame. The search area for a good macro block match is constrained up to p pixels on all fours sides of the corresponding macro block in previous frame. This „p‟ is called as the search parameter.
Usually the macro block is taken as a square of side 16 pixels, and the search parameter p is 7 pixels. The matching of one macro block with another is based on a cost function. The macro block that results in the least cost is the one that matches closest to the current block. The cost is calculated by Mean Squared Error (MSE), Mean Absolute Difference (MAD), Sum of Absolute Difference (SAD) or Sum of Squared Error (SSE) of the pixels in each macro block.
The algorithm does not calculate the cost for all the pixels in the block as in Exhaustive Search algorithm. Instead, it makes use of two diamond shaped kernels, usually of sizes 4x4 and 2x2. The smaller diagonal is usually half the size of the larger one. At a time, the larger kernel touches 9 pixels in a block. The estimation begins from the centre by placing the larger kernel such that its centre falls on the centre pixel of the frame. The algorithm can be summarised in four steps as follows:
Step 1: Calculate the cost at the pixels in the block that fall on the points on the kernel and determine the pixel position where the cost is minimum.
Step 2: Shift the kernel such that it is centred at the point of minimum cost. Repeat Step 1 until the minimum cost is achieved at the centre pixel itself.
Step 3: Replace larger kernel with the smaller one and repeat Step 1.
Step 4: The pixel with minimum cost gives the best match and is assigned as the motion vector.
The next step is motion compensation. The motion vectors are interpolated using the reference frame to generate the predicted frame.
IV.
I
NTER-V
IEWP
REDICTIONThe aim of inter-view prediction is to predict the frame from i+1th camera with the help of frame from ith camera.
Inter-view prediction mainly depends on the determining the depth of objects in the frame. Different methods have been proposed to determine the depth/disparity of multi view images. Depth determination for Depth image based rendering methods (DIBR) are described in [12][14][21].Other methods include determining the global disparity, dense disparity and view interpolations from camera parameters as described in[15]-[17],[18]-[20], [24]. This algorithm determines the pixel disparity by calculating the similarity measure between multi–view video frames using Normalized cost correlation function. MVC supports block matching prediction, hence the aggregate cost or average cost per block of the video frame is calculated by summing or averaging the per pixel cost calculated in the previous step for every pixel in the block. Initializing the minimum and maximum values of disparity, dmin and dmax the aggregate or average cost is
calculated for each block of the frame shifted in the horizontal direction through length „d‟ where dmin<d<dmax
and is as shown in eqn.(1). Sn and Sn-1 are the pixel
intensities of the current frame and reference frames respectively. Usually dmin is taken as zero and dmax
Copyright © 2013 IJECCE, All right reserved CostNCC =
𝑥 ,𝑦 ∈𝑊 𝑆𝑛 𝑥,𝑦 .𝑆𝑛 −1 𝑥+𝑑,𝑦
𝑥 ,𝑦 ∈𝑊𝑆𝑛 −12 𝑥+𝑑,𝑦 𝑥 ,𝑦 ∈𝑊𝑆𝑛2 𝑥,𝑦
(1)
Optimization process follows this step and involves determining the optimum value for „d‟ which minimizes the cost function. The Langrangean cost function shown in eqn. (4) is used to determine the optimum value of d for every block of the video frame. Here d is the optimum value of „d‟ that minimizes the cross correlation function C. The entire set of optimum disparity values generates the disparity map. This process of determining the disparity vectors is called Disparity Estimation. Disparity compensation involves interpolating the disparity vectors from the disparity map with the reference frame to form the inter-view predicted frame.
C (𝑑 ) = min {C (d)}, dmin<d<dmax (4)
V.
E
XPERIMENTALR
ESULTSThe prediction structures mentioned in sections II to IV are combined to analyze the predictive coding of MVC. The results obtained on simulation in MATLAB are described in this section. The algorithms are simulated using a standard multi-view sequence „Flamenco‟ with
pixel resolution 640x480 and 30fps. The standard sequences are obtained from [29]-[31]. Fig (4) shows the input frame used for intra prediction. The 4x4 block intra predicted frame is shown fig (5). A psnr value of 36.64 is achieved on reconstructing the intra coded frame and this is shown in fig (6). The prediction error determined is transform quantized for entropy coding. For the purpose of predicting the future frames form I frame, the frame has to be reconstructed at the encoder side. For this the residual data undergoes inverse transform quantization. This data is further used for reconstruction. The reconstructed frame of intra coding is used as the reference image for inter-frame prediction. The input image for inter inter-frame is shown in fig (7). The frame predicted through motion estimation is shown in fig (8). Fig (9) shows the motion vectors. Reconstruction of inter- frame prediction is achieved with a psnr value of 37.82 and the reconstructed frame is shown in fig (10). The input image for inter-view prediction, i.e., frame from second camera is shown in fig (11). Fig (12)
shows the disparity map generated through disparity estimation. The predicted frame and reconstructed frame are shown in fig (13) and fig (14). Reconstruction is achieved with a psnr value of 38.63.
Fig.4. Input Frame of „Flamenco‟ from Camera 1
Fig.5. Predicted frame obtained by 4x4 block Intra prediction
Fig.6. Reconstructed frame obtained from the inverse transform quantization of intra prediction error.
Fig.7. Input frame for inter frame prediction
Fig.8. Predicted frame obtained by Motion estimation of Inter frame prediction
original frame
Intra Predicted Image
Reconstructed Image
Input image
Copyright © 2013 IJECCE, All right reserved Fig.9. Motion vectors obtained by motion estimation
Fig.10. Reconstructed frame inter frame prediction
Fig.11. Input frame from camera 2 for inter-view prediction
Fig.12. Disparity Map obtained by Disparity estimation
Fig.13. Predicted frame obtained by disparity compensation
Fig.14. Reconstructed frame of Inter-view prediction
VI.
C
ONCLUSIONThe prediction structures for multi-view video coding are based on the fact showing the same scene from different camera perspectives show significant inter-view statistical dependencies. These correlations can be exploited for efficient coding of multi-view video data. The combined temporal and inter-view prediction structures are based on the idea that inter-view prediction is supported a different degrees, without losing the advantages of temporal prediction with hierarchical B pictures. The resulting multiview prediction structures achieve significant coding gains. These structures are very similar to H.264/AVC and require only very minor syntax changes.
A
CKNOWLEDGMENTWe express our sincere gratitude to Mrs. Subha Varrier, (Scientist, DSG/AVC, Vikram Sarabhai Space Center, Trivandrum) for her valuable help and guidance for the conduct of this work.
0 50
100 150
0
20
40
60
80
100
120
140 mo
tio
n v ec
to
rs
Input Image
Disparity Map by Normalized Correlation
Predicted Frame by NCC
Copyright © 2013 IJECCE, All right reserved
R
EFERENCES[1] Michael A. Isnardi. “Historical Overview of Video Compression in Consumer Electronic Devices”, In Consumer Electronics, 2007. ICCE 2007. Digest of Technical Papers. International Conference, pages 1-2, Jan 2007.
[2] Gary J. Sullivan, Pankaj Topiwala, and Ajay Luthra, „The H.264/AVC Advanced Video Coding Standard: Overview and Introduction to the Fidelity Range Extensions‟, SPIE Conference on Applications of Digital Image Processing XXVII, August, 2004
[3] John R. Smith, „The H.264 Video Coding Standard‟, IEEE, 2006 [4] Yuhua Zhu, Tong Zhen, „3D Multi-View Auto stereoscopic Display and Its Key Technology‟, Asia-Pacific Conference on Information Processing, 2009
[5] Sid Ahmed FEZZA, Mohamed-Chaker LARABI, Kamel Mohamed FARAOUN, „Stereoscopic Video Coding Based on the H.264/AVC Standard‟, IEEE, 2010
[6] Yo-Sung Ho and Kwan-Jung Oh. “Overview of Multi-view Video Coding”, in IEEE Conference Publications, pages 5 -12, June 2002.
[7] Thomas Wiegand, Philipp Merkle, Karsten Muller, “Efficient prediction structure for Multi View Video Coding”, IEEE Transactions on Circuits and Systems for Video Technology, 17(11):1461-1465, Nov 2011.
[8] Markus Flierl and Bernd Girod, “Multi-view video compression” in IEEE Signal Processing Magazine, pages 66 -76, November 2007.
[9] Smolic P. Merkle, K. M•uller and T. Wiegand, “Efficient compression of Multi View Video exploiting inter-view dependencies based on H.264/MPEG4-AVC”, In IEEE Conference Publications, pages 1717 – 1720, 2006.
[10] Yo-Sung Ho and Kwan-Jung Oh. “Overview of Multi-view Video Coding”., In IEEE Conference Publications, pages 5 -12, 02.3June 2002.
[11] White Paper:H.264 / AVC Intra Prediction, by Iain Richardson [12] Derek Pang, Xiaoyu Xiu and Jie Liang, “Rectification-based
view interpolation and extrapolation for Multiview Video Coding”, IEEE Transactions on Circuits and Systems for Video technology, 21(6):693{707, June 2011.
[13] Gary J. Sullivan Anthony Vetro, Thomas Wiegand. “Overview of the Stereo and Multi view Video Coding extensions of the H.264/MPEG-4 AVC Standard”, Proceedings of the IEEE, 99(4):626{642, April 2011.
[14] Christoph Fehn ,“A 3d-tv approach using Depth-image-based Rendering (DIBR)”, Image Processing, Proceedings of IEEE 2011.
[15] Rong Pan, Zheng-xin Hou And Yu Liu, “Fast algorithms for Inter-view Prediction Of Multiview Video Coding”, Journal Of Multimedia, Vol. 6, No. 2, April 2011
[16] Thomas Wiegand Philipp Merkle, Karsten Muller, “3D Video: Acquisition, Coding, and Display”, IEEE Transactions on Consumer Electronics, 56(2):946-950, May 2010.
[17] Xiaoming Li, Debin Zhao, Siwei Ma, and Wen Gao, “Fast Disparity and Motion Estimation Based on Correlations for Multiview Video Coding” pp 20137-2043, IEEE 2008. [18] Daniel Scharstein, “A Taxonomy and Evaluation of Dense
Two-Frame Stereo Correspondence Algorithms” in International Journal of Computer Vision 47(1/2/3), 7–42, 2002
[19] Daribo, M. Kaaniche, W. Miled, M. Cagnazzo, B. Pesquet-Popescu, “Dense Disparity Estimation in Multiview Video Coding”,IEEE,2009
[20] Steven Lansel, Nandhini Nandiwada Santhanam “Dense Disparity Estimation in Multiview Video Coding”, Unpublished [21] P.Merkle , Y.Morvan , A.Smolic , D.Farin , K.Muller ,
P.H.N.deWith , T.Wiegand, “The effects of multiview depth video compression on multiview rendering”, Elsevier, Signal Processing :ImageCommunication24(2009)73–88 74
[22] Iain Richardson, “H.264 and MPEG-4 Video Compression” Wiley Publications, ISBN 0-470-84837-5.
[23] Takeo Kanade, Robert T Collins, Omead Amidi, “An active camera system for acquiring multiview video” .In Image Processing. Proceedings. 2002, International Conference, pages-512-520 vol.1, 2002.
[24] Yo-Sung Ho and Yun-Suk Kang.”Multi-View Depth Generation using Multi-Depth Camera System”, in International Conference on 3D Systems and Applications.
[25] Borko Furht, Joshua Greenberg, Raymond Westwater, Motion Estimation Algorithms For Video Compression. Massachusetts: Kluwer Academic Publishers, 1997. Ch. 2 & 3.
[26] Renxiang Li, Bing Zeng, and Ming L. Liou, “A New Three-Step Search Algorithm for Block Motion Estimation”, IEEE Trans. Circuits And Systems For Video Technology, vol 4., no. 4, pp. 438-442, August 1994.
[27] Jianhua Lu, and Ming L. Liou, “A Simple and Efficent Search Algorithm for Block-Matching Motion Estimation”, IEEE Trans. Circuits And Systems For Video Technology, vol 7, no. 2, pp. 429-433, April 1997
[28] Lai-Man Po, and Wing-Chung Ma, “A Novel Four-Step Search Algorithm for Fast Block Motion Estimation”, IEEE Trans. Circuits And Systems For Video Technology, vol 6, no. 3, pp. 313-317, June 1996.
[29] http://www.merl.com/pub/avetro/mvc-testseq/orig-yuv/exit [30] ftp://ftp.merl.com/pub/avetro/mvc-testseq/stereo-interlaced [31] ftp://ftp.ne.jp/KDDI/multiview
A
UTHOR’
SP
ROFILEHeera Narayanan
is pursuing her M.Tech (Master of Technology) in Digital Signal Processing (Electronics and Communication Department) from SCT College of Engineering, Trivandrum, and Kerala, India. She obtained her Engineering Bachelor‟s degree in Applied Electronics and Instrumentation from LBS Institute of Technology for Women, Trivandrum, Kerala, India in the year 2010. Her research works are in the field of image and video processing.
Dr. Sheeja M. K.
is currently the Head of the Department of Electronics and Communication department of SCT College of Engineering, Trivandrum, Kerala, India. She received her P.HD by her work in the field of Holographic data storage. She did her masters (M.Tech) in Digital Signal Processing and her bachelor‟s degree in Electronics and Communication Engineering from TKM College of Engineering, Kollam, Kerala, India. Her present research works are in the fields of Computerized Holography, Image processing and Video Processing.