Genetic Algorithm approach to Operating
system process scheduling problem
Dr.Rakesh Kumar1
Reader Department of Computer Science and Application ,Kurkshetra university, Haryana,INDIA Er.Rajiv Kumar2
Assistant Professor,Department of Computer Science & Engineering,NC College of Engineering, Israna (Panipat), Kurukshetra University ,Haryana , INDIA
Er Sanjeev Gill3
Lecturer Department of Civil Engineering. Global research Institute of Management & Technology Radaur Yamuna Nagar
, Kurukshetra University ,Haryana , INDIA Er. Ashwani Kaushik4
Lecturer ,Department of Mechanical Engineering,NC College of Engineering ,Israna (Panipat),Kurukshetra University ,Haryana , INDIA
Abstract :
This paper present the implementation of genetic algorithm for operating system process scheduling. Scheduling in operating systems has a significant role in overall system performance and throughput. An efficient scheduling is vital for system performance. The scheduling is considered as NP hard problem .In this paper , we use the power of genetic algorithm to provide the efficient process scheduling. the aim is to obtain an efficient scheduler to allocate and schedule the process to CPU. we will evaluate the performance and efficiency of the proposed algorithm using simulation results.
Keywords: Genetic algorithm, NP-hard, CPU, Sequencing and Scheduling.
1. Introduction
Scheduling in the operating system is a critical factor in the overall system efficiency[1]. Process scheduling in an operating system can be stated as allocating processes to the processor so that throughput & efficiency of the system will be maximized. Typically scheduling problems are NP Hard [2] problems. There is necessity to find out robust & flexible solution for the real world scheduling problem. Genetic algorithms (GAs) were first proposed by the John Holland[3] in the 1960s. The GA is a heuristic search technique that simulates the processes of natural selection and evolution. Genetic algorithm (GA) is a promising global optimization technique [4]. It works by emulating the natural process of evolution as a means of progressing towards the optimal solution. A genetic algorithm has the capability to find out the optimal job sequence which is to be allocated to the CPU. This paper proposes the genetic algorithm based technique to find out the optimal job sequence. We will examine that whether genetic algorithm based scheduling will maximize the operating system performance. The algorithm starts with a population which is consists of several solution to the optimization problem. A member of population is called an individual. A fitness value is associated with each individual. Each solution in the population or an individual is encoded as a string of symbols. These symbols are known as genes & the solution string is called a chromosome. The values taken by genes are called alleles. Several pair of individual (parents) in the population mate to produce offspring by applying the genetic operator crossover. Selection of parents is done by repeated use of a choice function. A number of individuals & off springs are passed to a new generation such that the number of individual in the new population is the same as old population. A selection function determines which string forms the population in the next generation. Each serving string undergoes inversion with a specified probability
.
2. Problem description
In order to schedule the process in a uniprocessor operating system ,Let us suppose that there are N
single CPU at a time. The aim is to find out optimal processes sequence[5] by which the processes can be schedule[6] for the allocation of CPU in such a way that total waiting time should be minimum.
2.1 Assumption for process scheduling problem
1. There is a pool of ready processes waiting for the allocation of CPU. 2. The processes are independent and compete for the allocation of resources.
3. The job of the proposed scheduler is to distribute the resource i.e. CPU to different processes fairly so that performance criteria must be optimize i.e. minimum average waiting time.
The initial population of individual solutions are randomly generated so that reproduction takes place .successive generations of reproduction and by the application of GA operator i.e. crossover producing the no. of individual solutions.
3. The proposed GA-Based Algorithm
Genetic algorithm, a powerful & broadly applicable stochastic research techniques, are the most widely known type of evolutionary computation method today. In general, a genetic algorithm has five basic components as follows [3]:
1. An encoding method that is a genetic representation (genotype) of solutions to the program. 2. A way to create an initial population of individuals (chromosome).
3. An evaluation function, rating solution in terms of their fitness, & a selection mechanism.
4. The genetic operators (crossover & inversion) that alter the genetic composition of offspring during reproduction.
5. Values for the parameter of genetic algorithm.
3.1 Genotype
In the GA based algorithms each chromosome corresponds to a solution to the problem. The genetic representation of the individual is called Genotype .Many Genotypes have been proposed in [3]. In this paper we represent a chromosome with the combination of five decimal numbers , here sequence of five decimal number is the number of jobs. E.g. (2,4,1,3,5) sequence of five jobs or processes.
3.2 Initial Population
A genetic algorithm starts with a set of individuals called initial population. Most GA based algorithms generate initial population randomly. Here individual solutions are randomly generated with function Evpop (popcurrent) to form an initial population. In the simulation initial population with size of POPSIZE is generated with function.
3.3 Fitness function
The main objective of GA is to find an optimal solution. In order to find the optimal solution a fitness function must be devised for the problem under consideration i.e. Fit (Popcurrent). For a particular chromosome, the fitness function returns a single numerical ”fitness”, or “figure of merit”, which is supposed to be proportional to the “utility” or “ability” of the individual which that chromosome represent. In this paper the fitness of the individual is find out on the basis of minimum average waiting time, those individual who has minimum average waiting time is fittest as compared to other. The fittest individuals have the capability to participate in the reproduction cycle. The fitness function of a Schedule Sj is given by (1)
N i i = 1 j
Wt
Fitness(S ) =
(1)
N
(i = 1, 2, 3...N)
3.4 Selection
The selection process used here is based on spinning the roulette wheel, which each chromosome in the population has slot size in proportion to its fitness. Each time we require an offspring, a simple spin of the weighted roulette wheel gives a parent chromosome. Pickchroms(popcurrent) function is used for selection of individual. The probability Pi that a parent Si is given by (2):
i i POPSIZE
j j = 1
F(S )
P
=
(2)
F(S )
Where F (Si ) is the fitness of chromosome Si .
3.5 Crossover
Crossover is generally used to exchange portions between strings. Several crossover operators are described in the literature [7]. Crossover is not always affected; the invocation of the crossover depends on the probability of the crossover (Pc). Modified crossover [8] is used in this simulation. Modified crossover operator i..e. (
Mcrossover (popcurrent) ) is an extension of the one point crossover for permutation problems. A cut position is chosen at random on the first parent chromosome. Then an offspring (as shown in Fig. 1) is created by appending the second chromosome to the initial part of the first parent(before the cut point) and eliminating the duplicates
Parent 1 : 1 2 | 5 3 4
parent 2 : 1 4 2 5 3 Offspring : 1 2 4 5 3
Figure 1. Modified Crossover
3.6 Inversion
Inversion is a process in which the order of two gene position swapped with respect to each other. In inversion operator i.e. Inversion(popcurrent) , two points are selected along the length of the chromosome, the chromosome is cut at those points and the end points of the section cut, gets reversed(swapped).To make it clear ,we consider a chromosome of length 5 , where two inverse points are selected randomly( the points are 2 and 4 denoted by _character as shown in Fig. 2)
Offspring 2 3 4 1 5
Offspring 2 1 4 3 5
Figure 2. Inversion
3.7 Replacement Strategy
When genetic operators (Modified crossover, inversion) are applied on the selected parents S1,S2 one new chromosome is generated. This chromosome is added to the existing population . After that fitter chromosomes are selected from the new population .This process remain continue until we not get optimal solution.
3.8 Termination Condition
There are multiple choices for termination condition: Max number of generation, algorithm convergence, equal fitness for fittest selected chromosomes in respective iteration. In this paper we use algorithm convergence termination condition.
4. Structure of Proposed GA-Based Algorithm
Initialize Population (randomly generated); Fitness Evaluation;
Repeat
Selection( Roullete wheel Selection) ; Modified crossover;
Inversion(); Fitness Evaluation;
Elitism replacement with Filtration; Until the end condition is satisfied;
Return the fittest solution found; End
Our proposed GA-Based algorithm starts with a generation of individuals. A certain fitness function is used to evaluate the fitness of each individual. Good individuals survive after selection according to the fitness of individuals. Then the survived individuals reproduce offspring through crossover and inversion operators. This process iterates until termination condition is satisfied.
4.1 Pseudo-code of GA Based Scheduling
(1) Begin /* MCGA Algorithm*/
(2) Generate random population using Evop(Popcurrent) function
(3) Evaluate each individual using fitness function Fit(Popcurrent)
(4) WHILE NOT finished Do
BEGIN /* Produce New generation */ (5) FOR Population_size / 2 DO
BEGIN /* reproduction cycle */ (7) Select two individual from the old population
For mating using Pickchrom(Popcurrent) function
(8) Recombine the two individuals by apply
Modified crossover Mcrossover(Popcurrent)
and inversion operator Inversion(Popcurrent) to give offspring
(9) Compute the fitness of offspring and insert the offspring into the new Population END
(10) IF Population has converged THEN Finished:= TRUE
END END
5. Experimental Description
Individual solutions are randomly generated to form an initial population. Successive generations of reproduction and crossover produce increasing numbers of individuals .The algorithm favors the fittest individuals, as parents will have more offspring in the nest generation. To achieve minimum waiting time the fitness function defined here is based on first come first serve algorithm.
There are 5 jobs which are to be consider. The number of possible sequences are 5!. The total 10 sequence is selected out of 120 for the 5 jobs. Considering the number of jobs as 5 and the crossover point is 2 . let us consider following two individuals which are marked as fit to generate next generation.
3 1 2 4 5 and 4 3 5 1 2 After cross over 3 1 5 1 2
This offspring is not a valid sequence because 4 is not there in new individual and job 1 appears twice such individual is discarded .So to avoid this type of individual after crossover, we are using
the modified cross over . In the modified crossover we get proper sequence order individual . let assume two individual which are marked as fit and use for the next generation .
5 1 2 4 3 and 3 4 2 1 5 After modified crossover 5 1 3 4 2
this individual is accepted because there is no repetition of any job in this sequence.
6. Simulation Results
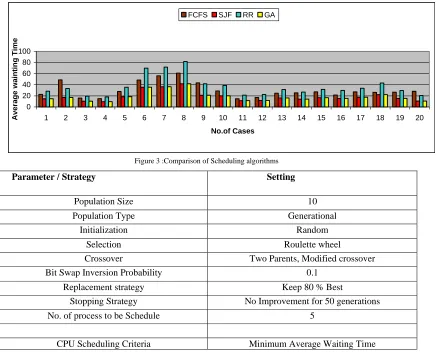
There are four jobs (1,2,3,4,5) which requires processing time ( 5,15,12,25,5). So the sequence of the jobs may vary and also we analyze the GA by changing the process time of different jobs as shown in the Table 2. we are comparing FCFS,SJF,RR and GA, By apply the genetic operator’s crossover, fitness function and inversion, we get the final population. out of the final population we get the job schedule, who have the minimum average waiting time Figure 3 focus on comparison based average waiting time algorithms.
0 20 40 60 80 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
No.of Cases
A
v
e
ra
g
e
w
a
in
ti
ng
Ti
me
FCFS SJF RR GA
Figure 3 :Comparison of Scheduling algorithms
Parameter / Strategy Setting
Population Size 10
Population Type Generational
Initialization Random
Selection Roulette wheel
Crossover Two Parents, Modified crossover
Bit Swap Inversion Probability 0.1
Replacement strategy Keep 80 % Best
Stopping Strategy No Improvement for 50 generations
No. of process to be Schedule 5
Table 2 : Comparison of Results
7. Conclusion and Future work
The simplicity of the methods used supports the assumption that GA’s can provide a highly flexible and user-friendly, near optimal solution to the general job sequencing problem. The genetic algorithms perform well to solve optimization problems. The Experiemnt results clearly show that the proposed approach is able to find optimized solution. The experiment carried out is efficient to find best sequence. The work can be extended so that technique can be implemented for dynamic process scheduling and sequencing. The performance can also increase by apply diploidy operator on this problem.
8. References
[1] M.Nikravan,M.H. Kashani,”A Genetic algorithm for process scheduling in distributed operating systems considering load balancing”, Proceedings 21st European Conference on Modelling and Simulation Ivan Zelinka, Zuzana Oplatková, Alessandra Orsoni ©ECMS 2007
[2] Blazewicz, J., Domschke, W., and Pesch, E. (1996). The job shop-scheduling problem: Conventional and new solution techniques. European Journal of Operational Research, 93:1-30.
[3] Holland, J.H., 1975. “Adaptations in natural and artificial systems”, Ann Arbor: The Universit0 of Michigan Press.
[4] David E.Goldberg, Genetic Algorithms in Search Optimization & Machine learning, Second Reprint, Pearson Education Asia pte. Ltd., 2000.
[5] S. Ashour. Sequencing Theory. Springer-Verlag, New York, 1972.
[6] K. R. Baker. Introduction to Sequencing and Scheduling. John Wiley and Sons, Inc., New York, 1974.
[7] L.M.Schmitt, “Fundamental Study Theory of Genetic Algorithms” , International Journal of Modelling and Simulation Theoretical Computer Science 259, 2001, 1 – 61.
[8] L. Davis, "Applying Adaptive Algorithms to Epistactic Domains", in Proceedings of the Int. Joint Conf. on Artificial Intelligence (IJCAI'85), Los Angeles, CA, pp. 162-164.
Sr. No. Burst Time of Process GA
FCFS SJF RR
P1 P2 P3 P4 P5
1 5 15 12 25 5 14.8000 22.7999 14.8000 28.4000
2 10 50 25 4 8 17.0000 48.7999 17.0000 33.4000
3 2 10 15 12 4 10.4000 16.0000 10.400 19.6000
4 4 2 25 3 23 9.6000 15.000 9.6000 18.0000
5 8 11 35 4 30 18.4000 27.7999 18.4000 35.5999
6 20 25 40 8 36 35.5999 48.5999 35.5999 70.0000
7 22 40 35 2 38 36.4000 56.0000 36.4000 71.8000
8 35 30 36 3 39 41.5999 61.0000 41.5999 82.0000
9 36 10 20 4 20 21.2000 43.5999 21.2000 41.5999
10 2 25 28 5 32 20.2000 28.7999 20.2000 38.7999
11 8 2 15 6 35 11.4000 14.8000 11.4000 21.4000
12 9 4 17 3 50 11.8000 17.0000 11.8000 22.4000
13 15 8 19 2 40 16.2000 24.79999 16.2000 31.2000
14 20 2 20 1 35 14.0000 25.4000 14.0000 26.7999
15 21 2 21 4 32 16.6000 27.2000 16.6000 31.79999
16 16 2 15 8 15 15.4000 21.6000 15.4000 29.7999
17 17 2 26 10 16 17.4000 27.2000 17.4000 33.7999
18 18 3 18 15 18 22.2000 26.4000 22.2000 43.0000
19 19 4 19 2 19 15.4000 26.6000 15.4000 29.6000
20 20 6 20 3 3 10.6000 28.2000 10.6000 20.6000
Total Avg. Waiting Time 376.1998 607.5994 376.1998 729.5994