Estimating Permanent Income
Using Indicator Variables
B.D. Ferguson, A. Tandon, E. Gakidou, and C.J.L. Murray
Evidence and Information for Policy Cluster
World Health Organization, Geneva
February 19, 2003
Abstract
Household surveys in developing countries often lack modules on income and ex-penditure. When included, the resulting estimates show substantial measurement error and are subject to systematic reporting biases. Indicator-based indices proposed by several analysts show much promise in circumventing these difficulties but nonetheless exhibit certain limitations. We present an alternative based on a variant of the probit model, which produces a series of indicator-specific cut-points on a latent scale (per-manent income). These cut-points represent values above which respondents are more likely to respond affirmatively than not, and allow estimation of household permanent income when combined with an individual household’s responses. This analysis com-pares estimates of permanent income using the above approach with estimates resulting from principal components analysis using household survey data from Greece, Peru and Pakistan. This new approach yields estimates of permanent income that are compara-ble with those of other methods in terms of rank correlation with reported income or expenditure, and offers the potential for substantially enhanced comparability across populations and greater precision and efficiency through item reduction methods.
1
Introduction
The empirical examination of the impact of economic and social policy on the objective of poverty alleviation — especially at the micro level — requires appropriate instruments and other mechanisms to measure poverty. This has become especially relevant in recent years given the increasing use of household survey data in research. Although economists have traditionally relied on reported income and expenditure as the preferred indicators of poverty and living standards, the use of such indicators is problematic. Not only does their measurement require lengthy modules and detailed questions which are not practical for household surveys with other priorities such as health, but the data resulting from such modules are fraught with substantial measurement error and are subject to systematic reporting biases [23]. Recent research into these reporting biases reveals that respondents often have differing interpretations of income and expenditure questions and demonstrates
the cognitive complexity of such questions for the typical respondent [7],[30],[2]. For these reasons, a number of analysts have developed methods to estimate household wealth or permanent income using information on the ownership of selected assets or on the use of certain services that correlate with permanent income. In addition to being consistent with a broader definition of poverty which has become increasingly prominent, such indices have enabled the analysis of poverty and inequality using otherwise rich household surveys that do not include income or expenditure modules. Such methods have been applied using the Demographic and Health Surveys (DHS) which provide consistent instruments and sampling frames as well as information on durable goods and dwelling characteristics [10],[15],[28].
Often developed by means of principal components or factor analysis, these asset and permanent income indices have a number of limitations. First, if the principal components or factor analysis is performed on a country by country basis using data from different survey instruments, it is not possible to compare the results across countries. An index of household wealth estimated in such a manner can neither be compared across populations nor over a period of time in the same population. Even when the same survey instrument is used, the tendency to acquire an asset such as a boat or air conditioning unit is certain to differ among households of different cultural backgrounds living in different environments. Similarly, supply and demand for assets such as electronic devices can change rapidly in the same setting over even a few years time, rendering inter-temporal comparisons invalid. Second, principal components and factor analysis do not provide information on the level of income at which different assets or goods and services will be purchased. Finally, these two approaches do not provide prospective guidance on the best assets or goods and services to include in future surveys to obtain more refined estimates of household permanent income.
In this paper, we use a variant of the hierarchical ordered probit (DIHOPIT) model to develop an indicator of permanent income using household survey data from Greece, Peru and Pakistan. The HOPIT model was originally developed to enhance the cross-population comparability of self-report survey data [32]. We apply the model in order to estimate the cut-points for different indicator variables for each of the three surveys, which are combined with the household’s responses to each question to calculate an estimate of permanent income for that household. We then validate these estimates against reported household income and expenditure. Further analysis will demonstrate that the permanent income for each household can be estimated using different subsets of indicators and that systematic analysis of the indicator variable cut-points will enable more parsimonious design of future questionnaires. Only those indicators that are relevant for mapping the range of permanent income for a given country need then be included in the survey questionnaire.
2
Background
Modelling unobservables, such as permanent income and permanent consumption, is a long-standing issue in economics and econometrics. Friedman’s (1957) permanent income hy-pothesis states that consumption is a function of permanent income. The central argument is that consumption decisions are made in a forward-looking manner and that current (mea-sured) income is a poor determinant of consumption patterns. This, combined with the fact
that observed income shows considerable measurement error and is a poor proxy of per-manent income since it does not incorporate expectations, has spawned a large literature on the measurement of permanent income. Though permanent income is not directly ob-servable, there is general agreement that it is determined by physical and human resources, such as property, education, or experience which enable income generation. Standard eco-nomic theory would argue for specifications in which permanent income (Y) is a function of household characteristics, education, the stock of physical assets, and community and environmental characteristics [29]. For a variety of reasons, such definitions cannot be used to derive estimates of permanent income in cross-country settings. Arguably, one problem is that the stock of physical assets is not simply a causal determinant of permanent in-come, but rather also an observed indicator of permanent income. This is especially true in less-developed economies characterized by poorly developed financial sectors — which makes household physical asset ownership more of a correlate of permanent income than a determinant. A second problem is that the same bundle of physical assets may map to different levels of permanent income in different countries. Due to norms, expectations, price distortion, and other environmental factors, the same level of permanent income in two countries may imply a different probability of ownership of any given physical asset. Hence, the use of physical asset ownership as a determinant of permanent income may lead to estimates that are simply not comparable across populations.
Due to the abundance of household survey data on asset ownership and the considerable biases and measurement error associated with reported income, a substantial literature has developed on asset-based measures of income. Several approaches, ranging from very simple to fairly complex, have been employed to approximate permanent income using asset, hous-ing quality and other indicators from household surveys that do not include information on income or expenditure. One of the more simple approaches is that utilized by Townsend [33] who proposed a set offive simple indicators to distinguish among households: the ratio of household rooms to persons; car ownership; number of economically active persons seeking work; children aged 5 to 15 who receive school meals free and number of times the household experienced disconnection of electricity in the previous 12 months. Townsendfinds a high consistency of ranking across these five indicators. Another approach by Montgomery et. al. [22] aims to control for the effect of permanent income by including a series of separate indicator variables for durable goods and housing quality measures in a multivariate regres-sion. While this method allows the researcher to test whether consumption’s effect on the dependent variable is statistically different from zero, it is not possible to isolate the direct effect of each indicator variable on the dependent variable from its indirect effect through household income.
Adams et al. [1] and Takasaki et al. [31] adopt and validate a qualitative approach for stratifying households into wealth groups. Their method, consistent with the general approach known as Rapid Rural Appraisal (RRA), involves training interviewers in wealth ranking who then assign households to a wealth group according to pre-identified criteria. The key informant interviewers must reach consensus on the wealth group assigned to each household. The studies conclude that key informants can accurately differentiate households according to an array of culturally appropriate criteria of wealth. However, it is difficult to establish the content validity of the wealth ranking technique, as it is unknown the extent to
which one criterion might have predominated over others in the process of decision making (i.e., implicit weighting of criteria) and the extent to which these wealth groups might be comparable across populations.
A more common approach in the literature is to construct an index using the indicator variables available in a particular survey. The indices that have been proposed range from the seemingly simple to the computationally more complex. Muhuri [24] uses an indicator of whether the household owns at least one offive durable goods or receives remittances. Jensen [17] and Havanon et al. [16] construct indices by equally weighting items such as durable goods and housing quality variables. Several researchers have constructed an index based on the sum of the number of consumer durable goods and other indicator variables for land ownership, quality of drinking water and sanitation facilities ([14],[5],[13],[27]).
Additional approaches involve weighting the indicator variables used in the estimation of the index. Some researchers have tried to approximate household consumption using indices where each item owned by the household is weighted by its value [21]; however, a significant limitation of this approach is that information on the value of indicator variables is not widely available from surveys or other sources of information. Layte et al. [18] have constructed a relative deprivation index in which each individual item is weighted by the proportion of households possessing that item in each country. As a consequence, not possessing an item is considered a more substantial deprivation in a country where a higher proportion of the population own one. As pointed out by the authors, this relative deprivation index is not suitable for comparisons of absolute levels of deprivation across countries.
Similarly, Morris et al.[20] propose an index where they assign to each item in the list of assets (g) a weight equal to the reciprocal of the proportion of the households who own one or more of that item (wg), then multiplying that weight by the number of units of asset g owned by the household (fg), and summing the product over all possible assets. The resulting index proposed by Morris et al. for a householdj would then be:
score=
G X g=1
fgjwg
In addition to the asset score, the total value of household assets owned can be calculated by summing - over all assets owned- the reported current values of those assets (Vg). This approach is based on the assumption that households with greater resources will purchase and own a greater number of durable goods. This weighting of the household assets assumes that households are progressively less likely to own a particular item the higher its monetary value, as pointed out by Morris et al. The authors also found that the household asset score is correlated highly with household asset values, indicating that the two measures classify households in a similar manner.
Principal components analysis and principal factors analysis are two methods which have been used to derive individual weights for items in the construction of a wealth in-dex. The principal components analysis approach to deriving weights employed by Filmer and Pritchett has been widely used by the World Bank in their analyses of socioeconomic
inequalities in health based on the DHS surveys [34]. Gakidou and King apply a similar approach based on principal factors analysis to the DHS in order to analyze the compo-nents of inequality in child survival [12]. Sahn and Stifel also use factor analysis in their multi-country study of poverty in Africa, and note that there is a high rank correlation between the index created from this method with that resulting from principal components analysis [28]. It is interesting to note that Bollen et al. [3]find that simple proxies, such as the sum of durable goods and housing quality indicators, perform almost as well as these more complex data reduction methods, and that indices incorporating information on asset values seem to perform worse. They alsofind that adding more consumer durable questions to the core set available in most surveys does not substantially improve the estimates of permanent income. Unfortunately these methods provide little guidance with respect to the number of questions which should be used as well as how questions appropriate for a specific country might be selected.
In a subsequent section, we elaborate a model which combines information from indi-cator variables such as assets with other determinants to derive estimates of permanent income. The model assumes permanent income to be a function of household composition (such as household size and number of dependents), household characteristics (such as age and education of the household head), environmental factors (such as urban or rural resi-dence), plus an unobserved component (or random effect) the magnitude of which is derived from the multiplicity of indicator variables available per household. Hence, the model uses information on asset ownership or access to services in order to estimate the magnitude of other unobserved factors that may help determine permanent income. Subsequently, using Bayes’ theorem, this information on the magnitude of unobserved determinants is incorporated to yield posterior estimates of permanent income. This approach builds on several of the existing measures mentioned earlier, such as the asset index proposed by Filmer and Pritchett. Analysis will show that the approach performs comparably with existing approaches while offering the potential for substantially enhanced comparability across populations. A further advantage is the capability of achieving more parsimonious survey instruments and more refined estimates of permanent income through item reduction methods.
3
Methods
The statistical model utilized in this analysis is developed in terms of a latent variable, y∗
i, which denotes the permanent income of household i. This variable is, by definition, unobserved. What are observed are a series of asset and other indicator variables for each household i: These dichotomous variables take the value of 0 if the household does not possess or have access to the good or service, and 1 if it does. Examples of these indicators include whether the household has a separate kitchen, hot running water, a television, an automobile, and so on. In addition, we utilize a series of socio-demographic covariates that are expected to be correlated with permanent income such as education, age, sex, household size, or the number of adults in the household. The model can be formulated in terms of the latent variable, along with an observation mechanism for each of the assets and indicator variables. In mathematical terms, we assume that the latent variable yi∗ is a function of
a vector of covariates Xi0, a household-level random effect ºi with mean 0 and variance ¾2
v which captures other systematic unobserved factors that affect permanent income for a given household, plus an error term with mean 0 and variance set to 1.1
y∗
i = Xi0¯+ºi+²i i= 1; :::; N ºi ∼ N(0; ¾2v)
²i ∼ N(0;1)
The observation mechanism is specified for each indicator variablea= 1; :::; Asuch that the indicator variableyia:
ya
i = 0 if − ∞< yi∗≤¿a yia = 1 if ¿a< y∗i ≤+∞
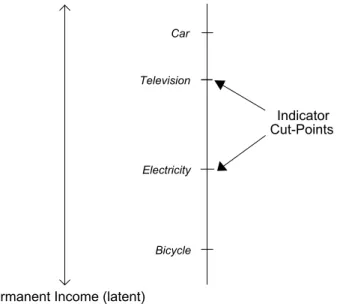
where ¿a is an indicator-specific cut-point. The model specifies that there is some indicator-specific threshold¿asuch that a household is more likely to respond affirmatively than not when its permanent income exceeds this threshold. Figure 1 visualizes the model. The solid line on the left of the graph represents the latent variable, while the line to the right shows the estimated cut-points for certain indicators such as ownership of a car, television or bicycle, or having electricity in the household. These indicator cut-points represent “ownership thresholds” on the underlying latent variable of permanent income.
Given this set-up, we can derive the probability of an affirmative response conditional on covariates as follows: Pr(yi = 0 |Xi; ºi) = A Y a=1 Pr(−∞< yi∗ ≤¿a) = A Y a=1 Pr(−∞< Xi0¯+ºi+²i ≤¿a) Pr(yi = 1 |Xi; ºi) = A Y a=1 Pr(¿a < y∗i ≤+∞) = A Y a=1 Pr(¿a< Xi0¯+ºi+²i≤+∞)
Given the normal distribution assumption for error term², Pr(yi = 0 |Xi; ºi) = A Y a=1 [Φ(¿a−Xi0¯−ºi)] Pr(yi = 1 |Xi; ºi) = A Y a=1 [1−Φ(¿a−Xi0¯−ºi)] 1
Since this is a latent variable model, the variance is unobserved. The assumption of variance set to 1 is one of mathematical convenience. The coefficients on the covariates adjust in response to differences in variance of the error term in the underlying data generating mechanism.
Figure 1: Hypothetical Indicator Cut-Points on the Permanent Income Latent Variable
Permanent Income (latent)
Indicator Bicycle Electricity Television Car Cut-Points
where Φ(·) is the cumulative normal distribution. Conditioning out the random effect ºi, the probabilities can be written as:
Pr(yi = 0 |Xi) = Z +∞ −∞ ' (ºi) A Y a=1 [Φ(¿a−Xi0¯−ºi)]dºi Pr(yi = 1 |Xi) = Z +∞ −∞ ' (ºi) A Y a=1 [1−Φ(¿a−Xi0¯−ºi)]dºi
where'(·) is the normal probability density function. Rewriting, we have Pr(yi = 0 |Xi) = Z +∞ −∞ e−º2 i=2¾2º p 2¼¾2 º ( A Y a=1 [Φ(¿a−Xi0¯−ºi)] ) dºi Pr(yi = 1 |Xi) = Z +∞ −∞ e−º2 i=2¾2º p 2¼¾2 º ( A Y a=1 [1−Φ(¿a−Xi0¯−ºi)] ) dºi
The integral can be approximated usingM-point Gauss-Hermite quadrature, Z +∞ −∞ e −x2f(x)dx≈ M X m=1 $∗ mf(a∗m)
where the$∗mdenote the quadrature weights and thea∗mdenote the quadrature abscis-sas. Estimation of parameters can be done using standard maximum likelihood methods.
The likelihood is simply the product of all the individual probabilities since these are inde-pendent after conditioning on the covariates and the random effect.
If there is a household-level random effect in the data — i.e., when covariates in the model do not capture all the systematic variation in the latent variable permanent income — then there remains information content in the set of responses across indicators for each household that has not been fully exploited. In order to exploit the information content in the set of responses we can make use of Bayes’ theorem to obtain estimates of the mean level of permanent income conditional on the observed set of responses for a given household. Let¹i ≡Xi0¯+ºi be the mean level of permanent income predicted by the model. Then Pr(¹i |yi) can be estimated using Bayes’ formula:
Pr(¹i |yi)=R Pr(yi |¹i)Pr(¹i)
Pr(yi |¹i)Pr(¹i)d¹i (1) where yi represents the vector of categorical responses on all indicator questions for household i. The way this is implemented is as follows. First, using the model with the random effect, all parameters are estimated including the variance of the random effect¾2
º. This estimate of the variance of the random effect is then used to simulate one hundred different values of ¹i around the predicted Xi0¯ of the latent variable for each individual in the sample. Hence, for each simulated value of¹i, Pr(¹i) can be calculated. Pr(yi |¹i) can be derived using the probability specifications as elaborated earlier. Integrating over all simulated values of¹i for each individual yields the denominator of equation (1).
We contrast the results obtained using the above model with those obtained by calcu-lating a weighted index using principal components analysis (PCA). PCA is an exploratory multivariate statistical technique for simplifying complex datasets [19],[4]. The defining characteristic that distinguishes PCA from principal factors analysis is that in PCA it is assumed that all of the variability in an item should be used in the analysis, while in prin-cipal factors analysis the concern is only the variability in an item which is shared with other items. While the two methods generally yield similar results, PCA is often preferred as a method for data reduction, while principal factors analysis is preferred where there is a need to detect structure. Given mobservations on n variables, the goal of PCA is to reduce the dimensionality of the data matrix byfindingrnew variables, whereris less than n. Termed principal components, these new r variables together account for as much of the variance in the originaln variables as possible while remaining mutually uncorrelated and orthogonal. Each principal component is a linear combination of the original variables, such that researchers often ascribe meaning to what the variables represent. PCA has been applied to asset questions in household surveys under the assumption that it is long-run wealth or permanent income that is the phenomenon attributable to the linear index of variables with the largest amount of information common to all of the variables. The result of such application of PCA is an asset index for each household according to the formula:
Ai =f1(ai1−a1)=(s1) +:::+fN(aiA−aA)=(sA)
is the i-th household’s value for the first asset and ai and si are the mean and standard deviation of thefirst asset variable over all households. In a subsequent section, we provide the results of our assessment of the degree of correlation of the PCA and latent variable approaches with reported household income and expenditure.
4
Data
Data for this analysis come from nationally representative surveys carried out in three coun-tries with considerably different socioeconomic characteristics: Greece, Peru and Pakistan. The surveys were selected based on their inclusion of questions or modules on either income or expenditure, or both, as well as a number of indicator variables covering items such as household ownership of durable goods, characteristics of the neighborhood and dwelling, and access to services such as water, sanitation and electricity.
The data for Greece form part of the European Community Household Panel Survey (ECHP). In 1991, Eurostat, the Statistical Office of the European Communities, completed a comprehensive review of existing data on income at the household and individual levels among EU Member States. One of the outcomes of this review was the decision to launch the ECHP survey, which was intended to allowflexibility for adaptation to national specificities despite being designed centrally at Eurostat [8],[9]. The ECHP contains a wide range of comparable social statistics on income including social transfers, labour, poverty and social exclusion, housing and health, as well as several other indicators of living conditions. The longitudinal design of the ECHP (a total of three waves were carried out in 1994, 1995, and 1996) makes it possible to study relationships and transitions in these indicators over time at the micro level. A total of 16 countries participated in the ECHP, from which we have selected Greece for analysis. In addition to information on living conditions and durable goods, the ECHP data for Greece contains reported household income, which can be analyzed for a particular household over the three year period for approximately 4,400 households.
The data for Peru come from the National Living Standards Measurement Survey (LSMS) carried out in 2000, based on the methodology developed by the World Bank to measure the well-being and quality of life of households in developing countries. Six such surveys have been carried out in Peru: in 1985-86, 1991, 1994, 1996, 1997 as well as 2000. The most recent national LSMS collected data on the levels of education, health, labor activity and migration for approximately 4,000 households, from which estimates of total household income and expenditure can be derived [26].
Data for Pakistan were collected through the 1991 Pakistan Integrated Household Survey (PIHS) which was conducted jointly by the Federal Bureau of Statistics (FBS), Government of Pakistan, and the World Bank [25]. This nationwide survey gathered individual and household level data on topics including housing conditions, education, employment charac-teristics, health, consumption, and household energy consumption for approximately 4,800 households. Community level and price data were also collected during the course of the survey, and estimates of total monthly income and expenditure have been calculated for each household.
5
Empirical Assessment
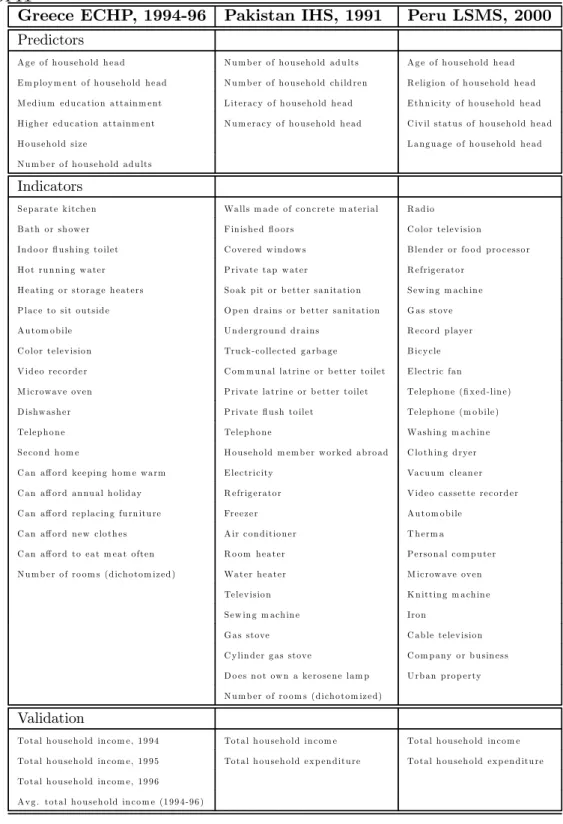
In this section, we validate the use of the DIHOPIT model to calculate an estimate of household permanent income in three different economic contexts: a high-income country, Greece, a low-income country, Pakistan and a middle-income country, Peru. Household sur-veys from these countries were selected because they included items on a range of consumer durables and household services or physical attributes plus full-scale modules on income as well as modules on expenditure in the case of Pakistan and Peru (see Table 1 for a complete list of variables used). For each country, we have analyzed the validity of the estimates of household permanent income through comparisons to reported income or expenditure of the household. For comparison, we have also examined the results of principal components analysis. As part of the analysis of the Peru household survey data, we demonstrate that reasonably comparable results for household permanent income can be obtained using two completely different sets of consumer durables or household services.
Greece (ECHP, 1994-96)
Household permanent income has been estimated for the ECHP sample for 1995 in Greece using responses for 23 different consumer durables, household services or household attributes. The ECHP dataset includes three waves for 1994, 1995 and 1996. Income between waves is highly correlated reflecting the combination of small measurement error and relatively stable income for most households. Reported income for 1995 has a correlation coefficient with the average for households over the three waves of 0.90. In the analysis below, we make use of the average reported income for the three waves of the panel as an indicator that is likely to be more highly correlated with permanent income than income reported in any one year.
Table 2 shows the output of the DIHOPIT model applied to the data for 4,413 households in Greece. For this initial assessment, we have omitted the covariates on the latent variable and used only the random effect outlined above. More specifically, the model we estimate is:
y∗
i = ºi+²i i= 1; :::; N
ºi ∼ N(0; ¾2v) ²i ∼ N(0;1)
The observation mechanism remains as described earlier. The cutpoint on the latent variable of permanent income for each indicator variable was statistically significant for all except indicators 3 (indoorflushing toilet) and 12 (telephone). ln(¾º) is the log of the estimated standard deviation of the household-level random effect. Figure 2 shows for Greece the name of each indicator variable on the latent variable at its estimated cut-point. The vertical line represents the permanent income latent variable while the horizontal dashes are the estimated cut-points. These cut-points represent points on the underlying scale above which the household is more likely than not to respond affirmatively to the question
Table 1: Variables Used in the Estimation and Validation of Permanent Income Using DIHOPIT
Greece ECHP, 1994-96 Pakistan IHS, 1991 Peru LSMS, 2000
Predictors
A g e o f h o u se h o ld h e a d N u m b e r o f h o u s e h o ld a d u lts A g e o f h o u se h o ld h e a d E m p loy m e nt o f h o u se h o ld h e a d N u m b e r o f h o u s e h o ld ch ild re n R e lig io n o f h o u se h o ld h e a d M e d iu m e d u c a tio n a tta in m e nt L ite ra c y o f h o u s e h o ld h e a d E th n ic ity o f h o u se h o ld h e a d H ig h e r e d u c a tio n a tta in m e nt N u m e ra c y o f h o u s e h o ld h e a d C iv il s ta tu s o f h o u se h o ld h e a d H o u s e h o ld siz e L a n g u a g e o f h o u s e h o ld h e a d N u m b e r o f h o u s e h o ld a d u lts Indicators S e p a ra te k itch e n Wa lls m a d e o f c o n c re te m a te ria l R a d io B a th o r sh ow e r F in is h e dflo o rs C o lo r te le v isio n In d o o rflu sh in g to ile t C ove re d w in d ow s B le n d e r o r fo o d p ro c e sso r H o t ru n n in g w a te r P riva te ta p w a te r R e frig e ra to r
H e a tin g o r s to ra g e h e a te rs S o a k p it o r b e tte r s a n ita tio n S e w in g m a ch in e P la c e to sit o u ts id e O p e n d ra in s o r b e tte r sa n ita tio n G a s stove A u to m o b ile U n d e rg ro u n d d ra in s R e c o rd p laye r C o lo r te le v isio n Tru ck -c o lle c te d g a rb a g e B ic y c le V id e o re c o rd e r C o m m u n a l la trin e o r b e tte r to ile t E le c tric fa n M ic row ave ove n P riva te la trin e o r b e tte r to ile t Te le p h o n e (fix e d -lin e ) D ishw a s h e r P riva teflu sh to ile t Te le p h o n e (m o b ile ) Te le p h o n e Te le p h o n e Wa sh in g m a ch in e S e c o n d h o m e H o u s e h o ld m e m b e r w o rke d a b ro a d C lo th in g d rye r C a n affo rd ke e p in g h o m e w a rm E le c tric ity Va c u u m c le a n e r C a n affo rd a n nu a l h o lid ay R e frig e ra to r V id e o c a s se tte re c o rd e r C a n affo rd re p la c in g fu rn itu re Fre e z e r A u to m o b ile
C a n affo rd n e w c lo th e s A ir c o n d itio n e r T h e rm a
C a n affo rd to e a t m e a t o fte n R o o m h e a te r P e rso n a l c o m p u te r N u m b e r o f ro o m s (d ich o to m iz e d ) Wa te r h e a te r M ic row ave ove n
Te le v isio n K n ittin g m a ch in e S e w in g m a ch in e Iro n
G a s stove C a b le te le v isio n C y lin d e r g a s stove C o m p a ny o r b u sin e s s D o e s n o t ow n a ke ro se n e la m p U rb a n p ro p e rty N u m b e r o f ro o m s (d ich o to m iz e d ) Validation To ta l h o u se h o ld in c o m e , 1 9 9 4 To ta l h o u se h o ld in c o m e To ta l h o u se h o ld in c o m e To ta l h o u se h o ld in c o m e , 1 9 9 5 To ta l h o u se h o ld e x p e n d itu re To ta l h o u se h o ld e x p e n d itu re To ta l h o u se h o ld in c o m e , 1 9 9 6 A v g . to ta l h o u s e h o ld in c o m e (1 9 9 4 -9 6 )
Table 2: Results of Application of Random-Effect DIHOPIT to Greece ECHP (1995)
Variable Coefficient Std. Error
Cut-Points
Separate kitchen -1.800 0.034
Bath or shower -0.263 0.049
Indoor flushing toilet -0.078 0.046
Hot running water 2.489 0.039
Heating or storage heaters 1.752 0.038
Place to sit outside -0.188 0.047
Automobile 1.541 0.038 Color television 0.113 0.044 Video recorder 2.182 0.039 Microwave oven 3.949 0.051 Dishwasher 3.036 0.042 Telephone 0.071 0.044 Second home 3.112 0.042
Afford keeping home warm 1.675 0.038
Afford annual holiday 2.018 0.039
Afford replacing furniture 2.823 0.041
Afford new clothes 1.277 0.039
Afford meat often 1.371 0.038
Home has 2+ rooms -0.394 0.051
Home has 3+ rooms 1.010 0.039
Home has 4+ rooms 2.482 0.039
Home has 5+ rooms 3.601 0.046
Home has 6+ rooms 4.522 0.065
ln(¾º) -0.450 0.027
rho 0.389 0.007
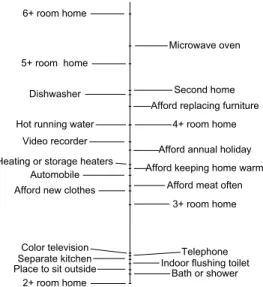
regarding ownership of a good or access to a service. In other terms, if the predicted permanent income is greater than the cut-point for a given asset, then the probability that that household responds affirmatively is greater than 0.5. In Figure 2, we see that the cut-points for the number of rooms in the house increases with permanent income. Ownership of a dishwasher or microwave occurs at a higher level of household permanent income than a television or telephone. Living in a home with 2 rooms or less, having an indoorflushing toilet, having a bath or shower, and having a separate kitchen are relatively low on the indicator ladder.
The next step in this analysis is to validate the estimation of permanent income from the model. Using the ECHP data for Greece, this can be done by comparing the correlations of the estimated permanent income (using indicator responses from 1995) with household income for the individual years 1994-96, as well as with the average household income over this period. Table 3 shows these correlations as well as the correlation of estimated permanent income with total household income per adult consumption equivalent and total
Table 3: Correlation of Estimated Permanent Income with Reported Income Measures, Greece ECHP (1995)
Variable Pearson’s r Spearman’s rho
Household income (1994) 0.50 0.61
Household income (1995) 0.57 0.65
Household income (1996) 0.55 0.62
Average household income (1994-96) 0.60 0.67
Average household income per capita (1994-96) 0.41 0.47
Average household income per adult equivalent (1994-96) 0.56 0.63
household income per capita.
As can be seen from the table, the highest correlation of estimated permanent income with household income for any of the three individual years of data is 0.57 in 1995. If we instead compare the permanent income estimate with the average reported household income over the three year period, the correlation improves to 0.60. In all cases, the rank (Spearman) correlation is considerably higher than the Pearson’s correlation suggesting that the relationship between estimated permanent income and reported household income is somewhat non-linear. The rather high degree of correlation between the permanent income estimate and reported household income and the observation that this correlation increases as income is averaged over a period of time would support the assumption that it is permanent income or long-term wealth that is being measured. The higher correla-tion of estimated permanent income on the latent variable with household income rather than total household income per capita or per adult consumption equivalent confirms the theoretical premise of the model that consumer durables and household services are a func-tion of household permanent income rather than attributes of particular individuals in the household.
It is also worth noting that the estimated cut-points are highly stable over the three years of data. The correlation of the indicator cut-points using data from 1994 with those using data from 1995 is 1.00, as is the correlation for estimates using data from the years 1995 and 1996. The correlation between estimates from 1994 and 1996 is 0.99. Another comparison of interest would be how well the DIHOPIT model performs relative to a similar and commonly used approach based on principal components analysis. The correlation coefficient and Spearman’s rho values of the rank correlation between average reported income and the principal component analysis give nearly identical results, 0.61 and 0.68 respectively.
The results above were obtained from application of DIHOPIT without including any covariates on the latent variable thereby allowing the random effect to capture as much of the systematic variance as possible. When additional variables such as age, employment status, educational attainment and household size (see Table 1) are included as predictors, the resulting correlations of the estimated permanent income with reported income in 1995 or average income for 1994-1996 are only slightly improved. While the addition of such information presumably increases validity, the increase is so slight that the results can be
Figure 2: Indicator Variable Ladder for 23 Indicators, Greece ECHP (1995).
-Separate kitchen
- Bath or shower - Indoor flushing toilet
-Hot running water
-Heating or storage heaters
-Place to sit outside
-Automobile -Color television -Video recorder - Microwave oven -Dishwasher - Telephone - Second home
- Afford keeping home warm - Afford annual holiday - Afford replacing furniture
-Afford new clothes - Afford meat often
-2+ room home - 3+ room home - 4+ room home -5+ room home -6+ room home
interpreted as being basically robust to the specification of covariates on the latent variable.
Pakistan Integrated Household Survey, 1991
For the second validation study, we examine how estimates of permanent income based on the application of the DIHOPIT model function in a low-income setting. Household surveys in populations with lower levels of education, less formal sector employment and in some cases less interaction with the monetized market often have much higher levels of measurement error especially for reported income [6]. The challenges of income and expenditure surveys are illustrated by the 1991 Pakistan Integrated Household Survey in which the correlation of reported income and expenditure was only 0.15. The Spearman’s rho was 0.46 reflecting the non-linear relationship in the data between reported income and expenditure. Not surprisingly, average income was 94% of average reported expenditure. Given the presumed high level of measurement error in both reported income and expendi-ture, we would expect estimates of permanent income to have lower correlations with these two variables than in Greece or Peru.
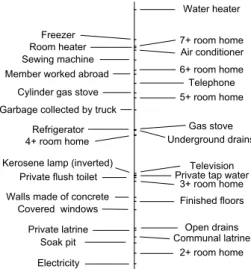
Table 4 provides the results from the application of random effect DIHOPIT without covariates on the latent variable for 4,752 households. We see that the cutpoints are statistically significant for all 30 indicator variables on the latent variable permanent income. Figure 4 shows each consumer durable, household service or household attribute shown on the latent variable. In addition to the statistical significance of the cutpoints, their ordering has face validity - households with low levels of permanent income are more likely to have a home with a soak pit or communal latrine than a privateflush toilet. At the other end of the spectrum, only those households with the highest levels of permanent income in this survey are likely to have an air conditioner, freezer or telephone.
Table 4: Results of Application of Random-Effect DIHOPIT to Pakistan IHS (1991)
Variable Coefficient Std. Error
Cut-Points
Walls made of concrete material 0.133 0.025
Finishedfloors -0.072 0.030
Covered windows -0.220 0.030
Home has 2+ rooms -0.994 0.031
Home has 3+ rooms 0.289 0.030
Home has 4+ rooms 1.104 0.033
Home has 5+ rooms 1.773 0.038
Home has 6+ rooms 2.270 0.045
Home has 7+ rooms 2.701 0.055
Private tap water 0.388 0.030
Soak pit or better sanitation -0.808 0.031
Open drains or better sanitation -0.543 0.031
Underground drains 1.114 0.033
Garbage collected by truck 1.562 0.036
Private flush toilet 0.354 0.031
Private latrine -0.585 0.031
Communal latrine -0.708 0.031
Telephone 2.036 0.042
Household member has worked abroad 2.200 0.043
Electricity -1.179 0.039 Refrigerator 1.201 0.034 Freezer 2.812 0.059 Air conditioner 2.630 0.054 Room heater 2.670 0.054 Water heater 3.346 0.084 Television 0.430 0.031 Sewing machine 2.451 0.049 Gas stove 1.210 0.034
Cylinder gas stove 1.866 0.038
Kerosene lamp (inverted) 0.400 0.030
ln(¾º) -0.027 0.021
Figure 3: Indicator Variable Ladder for 30 Indicators, Pakistan IHS (1991).
-Walls made of concrete - Finished floors -Covered windows - 2+ room home - 3+ room home -4+ room home - 5+ room home - 6+ room home - 7+ room home
- Private tap water
-Soak pit
- Open drains - Underground drains
-Garbage collected by truck
-Private flush toilet
-Private latrine
- Communal latrine
- Telephone
-Member worked abroad
-Electricity -Refrigerator -Freezer - Air conditioner -Room heater - Water heater - Television -Sewing machine - Gas stove
-Cylinder gas stove
-Kerosene lamp (inverted)
Pakistan based on the application of the DIHOPIT model. The correlation with reported household income is 0.17 which is much lower than in Greece but consistent with the low correlation between reported income and expenditure. The relationship is quite non-linear so that the Spearman’s rho for reported income and estimated permanent income is 0.53. Notably, estimated permanent income has a closer relationship to reported income than reported total household expenditure. Simultaneously, estimated permanent income has a correlation coefficient with total household expenditure of 0.33 and a Spearman’s rho of 0.53. In other words, the estimated household permanent income is more closely related both to reported income and expenditure than they are to each other. This is consistent with a hypothesis that both are in truth related to permanent income but measured in the survey with substantial error. As for Greece, the results in Table 5 illustrate that the latent variable appears to be measuring household permanent income rather than permanent income per capita or per adult consumption equivalent.
As before, we have rerun the DIHOPIT model to determine the effect of including certain predictors of household permanent income as covariates on the latent variable (see Table 1). As expected, the addition of covariates leads to a negligible increase in the Pearson’s correlation of estimated permanent income and reported income and expenditure, equal to 0.17 and 0.34, respectively). In general, we believe that adding covariates that are re-lated to permanent income to the model will improve estimation of household permanent income but the improvement is relatively small in the cases we have investigated. Esti-mates of household permanent income or wealth using principal components analysis yields very similar correlations coefficients (0.16 for reported household income and 0.34 for total household expenditure). Both the DIHOPIT model and the PCA model in this case are capturing similar information about household permanent income or wealth.
Table 5: Correlation of Permanent Income Estimates with Reported Household Income and Expenditure, Pakistan IHS (1991)
Variable Pearson’s r Spearman’s rho
Household income 0.17 0.53
Household expenditure 0.33 0.53
Household income per capita 0.18 0.47
Household income per adult equivalent 0.18 0.52
Household expenditure per capita 0.30 0.43
Household expenditure per adult equivalent (1994-96) 0.34 0.52
Figure 4: Indicator Variable Ladder for 24 Indicators, Peru LSMS (2000).
-Radio - Color television - Blender -Refrigerator -Sewing machine -Gas stove -Record player - Bicycle -Electric fan - Telephone (fixed-line) - Telephone (mobile) -Washing machine - Clothes dryer -Vacuum cleaner
- Video cassette recorder - Automobile
- Therma
-Personal computerMicrowave -Knitting machine -Iron - Cable television - Company - Urban property
Ourfinal validation study included in this paper is Peru. Income and expenditure in this LSMS survey are strongly related (correlation coefficient of 0.79), suggesting that there is a combination of more stable income for many households and lower levels of measurement error. Reported household income is 121% of total household expenditure on average. Table 6 shows the output of the model when applied without covariates to the Peru LSMS data using 24 indicator variables. The full list of indicator variables can also be found in Table 1 as well as in Figure 4, which shows the indicator variable ladder resulting from the cut-points predicted by the model.
Estimated permanent income using the DIHOPIT model show a strong relationship to reported income (correlation coefficient of 0.59) and to reported expenditure (correlation coefficient of 0.61). The corresponding Spearman’s rho are 0.72 and 0.73 for income and expenditure respectively. Results from application of principal components analysis to the Peru dataset are again similar to the results using the DIHOPIT approach, with Spearman correlation coefficients of 0.72 for household income and 0.73 for household expenditure. The analysis for Peru has been rerun with covariates on the latent variable in addition to the household random effect. Results from this application of the model made no difference
Table 6: Results of Application of Random-Effect DIHOPIT to Peru LSMS (2000)
Variable Coefficient Std. Error
Cut-Points
Radio -1.500 0.033
Color television 1.660 0.037
Blender or food processor 1.601 0.037
Refrigerator 1.877 0.038 Sewing machine 2.197 0.038 Gas stove 1.603 0.037 Record player 2.590 0.040 Bicycle 2.315 0.038 Electric fan 2.939 0.042
Telephone (fixed line) 2.614 0.040
Telephone (mobile) 3.883 0.055
Washing machine 3.501 0.049
Clothing dryer 4.596 0.078
Vacuum cleaner 3.687 0.051
Video cassette recorder 3.274 0.046
Automobile 3.545 0.049 Therma 3.931 0.056 Personal computer 3.916 0.056 Microwave oven 4.076 0.060 Knitting machine 4.539 0.075 Iron 1.164 0.037 Cable television 4.128 0.060 Company or business 2.073 0.037 Urban property 0.847 0.037 ln(¾º) -0.133 0.0028 rho 0.467 0.007
Table 7: Correlation of Permanent Income Estimates with Reported Household Income and Expenditure, Peru LSMS (2000)
Variable Pearson’s r Spearman’s rho
Household income 0.59 0.72
Household expenditure 0.61 0.73
Household income per capita 0.52 0.69
Household income per adult equivalent 0.58 0.73
Household expenditure per capita 0.48 0.66
Household expenditure per adult equivalent (1994-96) 0.59 0.73
to the correlation of estimated permanent income with reported income or total household expenditure.
Using the Peru survey, we can illustrate one of the main advantages of this approach to the estimation of permanent income using indicator variables on ownership of consumer durables, household services and household attributes. From the 24 original indicator vari-ables used, we have created two non-overlapping sets of 12. The two sets, shown in Table 7, have been created by assigning each indicator in an alternating fashion as one moves of the indicator ladder in Figure 4 to one group or the other. The DIHOPIT model has been rerun for each set of indicator variables separately as if only that set of variables was avail-able. The resulting estimates of household permanent income can be compared both to the original estimation using 24 indicator variables and to reported income and total household expenditure. Remarkably, both estimates based on only 12 indicator variables are highly correlated with the estimation based on 24 variables, with an average correlation coefficient of 0.94 for the two subsets. This shows the potential to undertake item reduction in surveys and obtain similar estimates of household permanent income or wealth using many fewer variables. Table 8 shows that both sets of 12 indicator variables yield estimates of perma-nent income that are equally highly correlated with reported income and expenditure. In other words, estimates of household permanent income do not seem to be biased by the particular set of indicator variables that are used in the analysis. The combination of the potential for item reduction illustrated in moving from 24 indicators to 12 with minimal loss of information and the robustness of the estimation of permanent income to changing the set of indicator variables used provides substantialflexibility in both survey design and analysis overtime.
6
Discussion
This paper has demonstrated the use of the DIHOPIT model to estimate permanent income from household surveys where information on dwelling characteristics, durable goods and other indicator variables is routinely collected. The implications of this analysis are that, with appropriate data, the indicator variables for a particular country can be mapped onto a latent variable which is a measure of permanent income. The model is able to identify
Table 8: Item Reduction Subsets, Peru LSMS (2000)
Item Subset #1 Item Subset #2
Radio Urban property
Iron Blender or food processor
Gas stove Color television
Refrigerator Company or business
Sewing machine Bicycle
Record player Telephone (fixed line)
Electric fan Video cassette recorder
Washing machine Automobile
Vacuum cleaner Telephone (mobile)
Personal computer Therma
Microwave oven Cable television
Knitting machine Clothing dryer
Table 9: Spearman Rank Correlation of Permanent Income Estimated from Indicator Sub-sets with Full-Set Permanent Income, Household Income and Household Expenditure, Peru LSMS (2000)
Variable Subset #1 Subset #2
Household income 0.67 0.66
Household expenditure 0.68 0.67
indicator-specific points on the latent variable scale that mark the transition such that at values of the latent variable that are higher than the cut-point, the household is more likely to have access to the good or service than not. Given that we let the data tell us the extent to which any given indicator variable maps to the latent variable, one major advantage of this approach is that the set of indicator variables need not be the same across countries. Designers of future surveys can choose the most appropriate set of indicator variables based on this analysis to better understand the role of the indicator and its relation to permanent income in any given country. In this sense, the approach is analogous to adaptive testing in educational surveys where items are allowed to vary by specific criteria such as respondent ability.
In addition, our analysis shows that there is significant potential for item reduction in that similar results are obtained using fewer questions. This also has implications for questionnaire design: if preliminary analysis suggests that certain items are redundant — in that they do not have a significant marginal contribution in the (posterior) estimation of permanent income — then these items may be removed from future rounds of the survey. In the case of Peru, reduction of the number of indicator variables by half yields unbiased estimates of permanent income which show a high degree of correlation with those of the full set. It is likely that discrimination between the permanent income of different households depends on the location on the latent variable of the various indicator variables used. The high correlation achieved with two distinct sets of indicator variables may in part be due to the fact that each set of 12 was spaced from low levels of permanent income to high levels. This type of consideration will be important in the prospective design of surveys that want to include a short list of these indicator variables.
Furthermore, the comparison with estimates produced using principal components anal-ysis shows that our approach is at least as good as this method in terms of estimating per-manent income. Due to norms, price distortion and other factors, however, the same level of permanent income in two countries is likely to imply a different probability of ownership of any given physical asset. Hence, one of the key limitations of the principal components analysis approach is that use of physical asset ownership as a determinant of permanent income may lead to estimates that are not comparable across populations. This analysis has not explicitly addressed the problem of cross-population comparability; however, the DIHOPIT model used to estimate permanent income has the potential to be modified so that estimates of permanent income can be directly compared across countries. There are three potential paths that could be pursued to enhance the comparability of permanent income estimates: 1) an exogenous estimate of the average level (mean) and variance of the permanent income distribution by country can be used to adjust the latent scale of perma-nent income to a comparable scale across countries, in the units of income; 2) the level on the permanent income scale for two or more of the indicator variables can be fixed across countries; or 3) the cut-points on the permanent income scale for the indicator variables can be allowed to vary across socioeconomic variables but not across countries. Any of these three methods would place the permanent income estimates on the same scale across countries, thus enhancing the cross-population comparability of the estimates.
The approach proposed in this paper is similar to previously proposed asset indices in that it has the potential to provide a more accurate measurement of permanent income
than values of reported current income from survey questionnaires, as it is likely that the measurement error in these indicator variables is much less than the error associated with reported income. More research is required to further validate this approach in a larger number of countries, enhance the item-reduction analysis to come up with the optimal set of indicator questions to ask in each country, and finally to make estimates of permanent income directly comparable across countries.
References
[1] Adams, A., Evans, T., Mohammed, R., & Farnsworth, J. (1997). Socioeconomic strat-ification by wealth ranking: is it valid? World Development, 25(7):1165-1172.
[2] Bogen, K. (1995). Results of the Third Round of SIPP CAPI Cognitive Interviews. Unpublished U.S. Bureau of the Census memorandum, June 13, 1994.
[3] Bollen, K., Glanville, J., & Stecklov, G. (2001). Economic status proxies in studies of fertility in developing countries: does the measure matter? MEASURE Evaluation Working Paper. WP-01-38. Carolina Population Center, Chapel Hill, NC.
[4] Basilevsky, A. (1994). Statistical Factor Analysis and Related Methods: Theory and Applications, New York, NY: John Wiley & Sons.
[5] Bollen, K., Guilkey, D., & Mroz, T. (1995). Binary outcomes and endogenous explana-tory variables — tests and solutions with an application to the demand for contraceptive use in Tunisia. Demography, 32(1):111-131.
[6] Deaton, A. (1997).The Analysis of Household Surveys: A Microeconometric Approach to Development Policy, Baltimore, MD: Johns Hopkins University Press.
[7] Dippo, C. & Norwood, J. (1994). A Review of Research at the Bureau of Labor Statis-tics. InQuestions about Questions(J. Tanur, ed.), New York: Russell Sage Foundation.
[8] European Community Household Panel (ECHP) (1996). Volume 1 — Survey Method-ology and Implementation, Theme 3, Series E, Eurostat, OPOCE, Luxembourg. [9] European Community Household Panel (ECHP) (1996),Volume 1 — Survey
Question-naires: Waves 1-3, Theme 3, Series E, Eurostat, OPOCE, Luxembourg.
[10] Filmer, D., & Pritchett, L. (2001). Estimating wealth effects without expenditure data — or tears: an application to educational enrollments in states of India. Demography, 38:115-132.
[11] Friedman, M. (1957). A Theory of the Consumption Function, Princeton: Princeton University Press.
[12] Gakidou, E., & King, G. (2002). Measuring total health inequality: adding individual variation to group-level differences.International Journal for Equity in Health, 1:3.
[13] Gorabach, P., Hoa, D., Nhan, V., & Tsui, A. (1998). Contraception and abortion in two Vietnamese communes. American Journal of Public Health, 88(4):660-663.
[14] Guilkey, D., & Jayne, S. (1997). Fertility transition in Zimbabwe: Determinants of contraceptive use and method choice.Population Studies, 51(2):173-190.
[15] Hammer, J. (1998). Health Outcomes Across Wealth Groups in Brazil and India. DE-CRG, The World Bank. Washington, DC.
[16] Havanon, N., Knodel, J., & Werasit, S. (1992). The impact of family size on wealth accumulation in rural Thailand.Population Studies, 46:37-51.
[17] Jensen, E. (1996). The fertility impact of alternative family planning distribution chan-nels in Indonesia. Demography, 33(2):153-165.
[18] Layte, R., Maitre, B., Nolan,B.,Whelan, C. (2001). Persistent and consistent poverty in the 1994 and 1995 waves of the European Community Household Panel.Review of Income and Wealth, 47(4):427-450.
[19] Lawley, D., & Maxwell, A. (1971). Factor Analysis as a Statistical Method, London: Butterworth.
[20] Morris, S., Carletto, C., Hoddinott, J., Christiaensen, L. (2000). Validity of rapid estimates of household wealth and income for health surveys in rural Africa. Journal of Epidemiology and Community health, 54(5):381-387.
[21] Dargent-Molina, P., James, S., Strpoatz, D., & Savitz, D. (1994). Association between maternal education and infant diarrhea in different household and community environ-ments. Social Science and Medicine, 38(2):343-350.
[22] Montgomery, M., Grangnolati, M., Burke, K., & Paredes, E. (2000). Measuring living standards with proxy variables. Demography, 37(2):155-174.
[23] Moore, J., Stinson, L., & Welniak, E. (2000) Income measurement error in surveys: a review.Journal of Official Statistics, 16(4):331-361.
[24] Muhuri, P. (1996). Estimating seasonality effects on child mortality in Bangladesh. Demography, 33(1):98-110.
[25] Pakistan Integrated Household Survey (PIHS) (1991). PIHS Section, Federal Bureau of Statistics, G - 8 Markaz, Islamabad, Pakistan.
[26] Peru National Living Standards Measurement Survey (LSMS) (2000). LSMS Data Manager, DECRG, The World Bank, Washington DC, USA.
[27] Razzaque, A., Alam, N., Wai, L., & Foster A. (1990). Sustained effects of the 1974-75 famine on infant and child mortality in rural area of Bangladesh. Population Studies, 44(1):145-54.
[28] Sahn, D., & Stifel, D. (2000). Poverty comparisons over time and across countries in Africa. World Development, 28(1), 2123-2155.
[29] Singh, I., Squire, L., & Strauss, J. (1986).Agricultural Household Models: Extensions, Applications and Policy, Baltimore: Johns Hopkins University Press.
[30] Stinson, L. (1997). The Subjective Assessment of Income and Expenses: Cognitive Test Results. Unpublished U.S. Bureau of Labor Statistics report. Washington, DC.
[31] Takasaki, Y., Barham, B., & Goomes, O. (2000). Rapid-rural appraisal in humid trop-ical forests: an asset possession-based approach and validation methods for wealth assessment among forest peasant households. World Development, 28(11)1961-1977.
[32] Tandon, A., Murray, C., Salomon, J., & King, G. (2001). Statistical Models for En-hancing Cross-Population Comparability. Global Programme on Evidence for Health Policy Discussion Paper No. 42, Geneva: World Health Organization.
[33] Townsend, P., Simpson, D., Tibbs, N., (1985). Inequalities in health in the city of Bristol: a preliminary review of statistical evidence. International Journal of Health Services, 15(4):637-663.
[34] World Bank. (2000) Country Reports on Health, Nutrition, Population and Poverty. Available: http://www.worldbank.org/poverty/health/data/intro.htm.