Mining Association Rule Summarization Techniques to prognosis
Diabetic unknown patterns
A. Sangeetha1, Dr. Rajendra Kumar Ganiya2
#1. M.Tech (CSE) in Department of Computer Science Engineering,
#2. Prof, Department of Computer Science and Engineering, Sri Sivani College Of Engineering, Chilakapalem, Srikakulam, A.P, India.
Abstract:
Early detection of patients with lifted danger of creating diabetes mellitus is basic to the enhanced counteractive action and general clinical management of these patients. Data mining now-a-days assumes a critical part in expectation of diseases in human services industry. Data mining is the way toward choosing, investigating, and displaying a lot of data to find obscure examples or connections helpful to the data examiner. Therapeutic data mining has risen perfect with potential for investigating concealed examples from the data sets of medicinal area. These examples can be used for quick and better clinical basic leadership for preventive and suggestive medicine. However crude medicinal data are accessible generally appropriated, heterogeneous in nature and voluminous for common handling. Data mining and Statistics can altogether work better towards finding shrouded examples and structures in data. In this paper, two noteworthy Data Mining strategies v.i.z., FP-Growth and Apriori have been utilized for application to diabetes dataset and association rules are being created by both of these calculations.
Keywords: Diabetic mellitus, Data Mining, Association Summarization Techniques, apriori algorithm.
I. Introduction
Diabetes mellitus is generally alluded to as diabetes, which is a disease of the pancreas, an organ behind the human stomach that delivers the hormone insulin. Diabetes is an across the board disease around the globe that influences 29.1 million Americans [4]. From the overview 21.0 million were analyzed and 8.3 million were undiscovered. Diabetes prompts huge medicinal intricacies or Co-Morbid Conditions including stroke, coronary illness, retinopathy,
between apparently disconnected data in a social database or other data store. An association lead has two sections, a predecessor (if) and a resulting (at that point). A precursor is a thing found in the data. An ensuing is a thing that is found in blend with the forerunner. Association rules are made by examining data for visit if/at that point examples and utilizing the criteria support and certainty to distinguish the most imperative connections. Support means that how much of the time the things show up in the database. In data mining, association rules are valuable for dissecting and anticipating client conduct. They have an imperative influence in shopping wicker container data investigation, item bunching, inventory outline and store design. Software engineers utilize association tenets to assemble programs equipped for machine learning. Machine learning is a kind of counterfeit consciousness (AI) that tries to assemble programs with the capacity to end up noticeably more effective without being expressly modified.
II. Related work
Dr. Zuber khan, shaifali sing, et al., [2] dealt with the idea of Diabetes Mellitus utilizing kNearest Neighbor calculation which is most Important strategy of Artificial Intelligence. The exactness rate is demonstrating that what number of yields of the data of the test dataset are same as the yield of the data of various highlights of the prepared dataset. The blunder rate is locating that what number of yields of the data of the test dataset are not same as the yield of the data of various highlights of the preparation dataset. The outcome they demonstrated that as the estimation of k builds, exactness rate and blunder rate will increment. K-Nearest Neighbor calculation is a standout amongst the most imperative procedures of AI which is utilized generally for demonstrative purposes. Through KNN more Accurate outcomes can be get. This strategy is extremely compelling for the preparation data set which is expansive. Mukesh kumari and Dr. Rajan Vohra [3] took a shot at the idea of data mining is to remove learning from data put away in dataset and create clear and justifiable depiction of examples. The methods are characteristics choice, data standardization and afterward classifier is connected on data set to build Bayesian model. Bayesian system classifier was proposed for the expectation of individual climate diabetic or not. By utilizing Bayesian classifier persistent is experiencing ordered in classes of Pre-diabetic, Non-Pre-diabetic, Diabetic as per the qualities
chose. The procedures they connected as preprocessing characteristic recognizable proof and choice, data standardization. And afterward classifier is connected to the altered data set to develop the Bayesian model. The Bayesian system has an advantage of it encodes all factors, missing data passages can be taken care of effectively. Dr.Pramanand Perumal and Sankaranarayanan [6] proposed a thought regarding diabetes mellitus its conclusion utilizing data mining with least number of credits connected to arrangement calculations. They took a shot at Apriori and FPgrowth systems. In FP-development the novel data structure visit design tree is being executed for putting away packed significant data about continuous example. It is watched that both of the methods create an indistinguishable number of successive sets from a significance same number of tenets for the same known dataset under similar imperatives. with the assistance of data Apriori and FP-development calculations, the calculation cost diminishes and furthermore the grouping execution increments. Satyanarayana Gandi and Amarendra Kothalanka [7] took a shot at the underlying preparing data set to the ideal procedure to remove the ideal data set, on that ideal dataset they connected arrangement with Bayesian classifier. Bayesian classifier strategies is utilizes getting preparing data set and change over it into ordered data. At first they extricate the ideal list of capabilities from existing preparing data and ascertains the positive and negative likelihood, until the point when the new data set if shaped with same size and advances the current produced dataset for characterization their it groups the testing dataset with new component. Sanchita paul and Dilip kumar Choubey [9] proposed an approach for include determination, order and utilized Genetic Algorithm, Multilayer Perceptron Neural system on diabetes data set. With highlights determination procedure utilizing Genetic calculation they enhance the precision however accomplished somewhat less ROC. With include Selection procedure hereditary calculation enhanced precision however accomplished less ROC by applying GA,MLP NN philosophy arrangement ROC is additionally made strides.
III. Association Rule Mining
is a binary covariate matrix with rows representing patients and the columns representing things. Associate degree itemset may be a set of items: it indicates whether or not the corresponding risk factors are all present within the patient. If they're, the patient is claimed to be covered by the itemset (or the itemset applies to a patient). An association rule is of kind I→ J, wherever I and J are both itemsets. The rule represents associate degree implication that J is likely to use to a patient only if I applies. The itemset I is that the antecedent and J is that the resulting of the rule. The strength and “significance” of the association is traditionally quantified through the support and confidence measures. The support of associate degree itemset is that the variety of patients lined by that itemset and therefore the confidence of a rule R:I→ J, is that the fraction of patients lined by J among those who are lined by I. In association rule mining, things don't play specific roles: there aren't any selected predictor variables or outcome variables. In alternative words, any item will seem within the antecedent of 1 rule and within the resulting of another. Predictive association rule mining, diagrammatical the first departure from this paradigm by designating a specific item as AN outcome. the ensuing of the prophetical association rules is often the selected outcome item. Regressive association rules and quantitative association rules more swollen this paradigm permitting a continuous outcome variable y to function the “consequent” of a rule. Let y(I) denote the end result within the subpopulation of patients that's lined by I; there's one y(I) worth for each patient. Further, let ˉy(I) denote the subpopulation mean outcome, the mean of y(I) values across patients to whom I applies. Analogously to the first association rule formulation, regressive association rules also are implications: they state that patients World Health Organization gift condition(s) I (antecedent) have outcome ¯ y(I) on the average. Suppose that y denotes never-ending variable that quantifies the chance of polygenic disease. By examination the population mean outcome ¯ y(I) for the affected population (patients who gift the antecedent I) to the mean outcome ¯ y(¬I) of the unaffected population (patients missing a minimum of one condition from I), we will assess the importance of I as a risk issue. as an example, if y denotes the quantity of diabetes events then the metric RR = ¯ y(I)/¯ y(¬I) is named the relative risk and it signifies that patients with condition(s) I are RR times additional probably to get to polygenic disease than patients missing a minimum of one
condition from I. Unfortunately, in some cases, the distinction within the outcome between these two subpopulations can't be sufficiently captured victimization the mean outcome, sometimes the spatial arrangement kind of the result conjointly plays a task. Distributional association rule will capture such variations.
IV. Proposed Methodology
In the clinical application of association rule data mining, we find item sets of health conditions that show the consequent quantity of increased risk amount of diabetes mellitus. The data extracting process using Association Rule in data mining used to describe an extensive variable set of items that result in an exponentially huge set of association rules formed. The main contribution is a comparative calculation of these summarization techniques that gives guidance to practitioners about Observed patients in datasets for choosing a relevant algorithm for a similar problem in the domain.
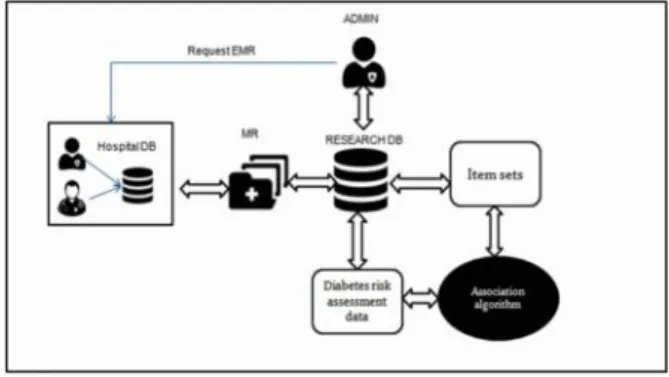
Fig. 1: System Architecture
A. Association Rule Mining
I→ J, where I and J are both thing sets.
The decide speaks to a suggestion that if J is probably going to apply to a patient given that I likewise applies. The thing set I is said to be the predecessor and J is the subsequent of the run the show.
One component of affiliation decide mining is that, things don't assume a specific parts, i.e. there are no assigned indicator factors or result factors. At the end of the day, any thing can show up in the precursor of one administer and in the resulting of another.
B. Distributional Association Rule
The distributional affiliation control can be characterized concerning a nonstop result y, a thing set I with an appropriation between the influenced and the unaffected subpopulations are measurably essentially not quite the same as each other. For instance, the control {htn, bmi } shows that the patients both exhibiting (hypertension) and a high weight list tally have an altogether higher shot of movement to diabetes than the patients who are either not having hypertension or don't have a high weight record check. Since each manage is characterized by an itemset we utilize the words 'itemset' and 'govern' conversely.
The distributional affiliation rules revelation comprises of two stages, in the initial step appropriate itemsets are found and in the second step the officially found itemsets are sifted to return just the measurably noteworthy standards.
C. Information Pre-preparing
Crude information that is acquired from the source is normally uproarious, conflicting and might miss esteems. The nature of information influences the information mining comes about. Pre-preparing of crude information is performed in order to help in enhancing mining comes about and additionally the nature of information. It additionally enhances the simplicity of the mining procedure. Change and handling of crude information can altogether impact the proficiency of the entire information.
D. Information Cleaning
Information purging is the system of distinguishing and redressing loud or mistaken information in datasets. It includes finding off base, fragmented or insignificant parts of the dataset and after that performing operations, for example, changing,
supplanting or erasing the boisterous information with the goal that it ends up noticeably reliable. When information cleaning has been played out, the information ends up noticeably less demanding to process since it is free from inaccuracies and inconsistencies.
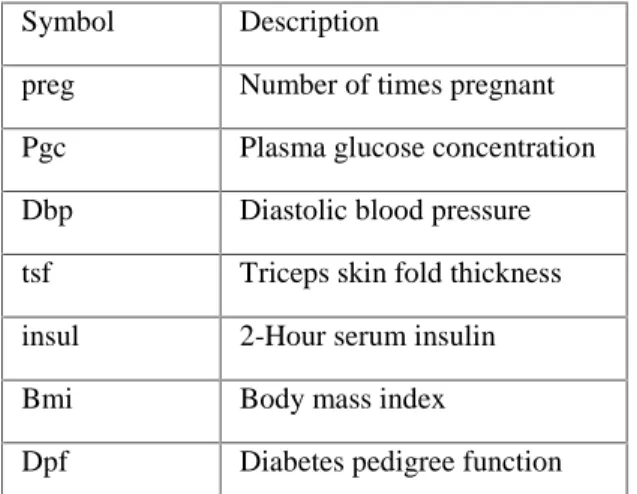
Table I: Symbol Specification
Symbol Description
preg Number of times pregnant
Pgc Plasma glucose concentration
Dbp Diastolic blood pressure
tsf Triceps skin fold thickness
insul 2-Hour serum insulin
Bmi Body mass index
Dpf Diabetes pedigree function
Table II: Continuous dataset
E. Continuous to Discrete Variable.
equal width discretization, or Entropy-MDL discretization etc. A class variable is defined which provides training data for the rules.
Table III: Discrete dataset
F. Apriori Algorithm
The Apriori algorithm is a groundbreaking algorithm developed by Srikant et al in 1994[2]. The association rule mining is an implication of the form A=>B where A and B both belongs to an itemset I where A∩B = . The rule A=>B holds in the transaction set Z with support s, where s is the fraction of transactions in D that contain AB i.e. P(AB). The rule A=>B has confidence c in the transaction set D, where c is the fraction of transactions in Z containing A that also contain B i.e. P(B|A). Rules that satisfy both a minimum support threshold and minimum confidence threshold are called strong. The set of frequent k-itemsets is commonly denoted Lk. Association rule mining can be performed in the following steps: 1. Finding all frequent itemsets: All of these itemsets will occur at least as frequently as a preset minimum support count, min_sup. 2. Generating strong association rules from the frequent itemsets: The generated rules must satisfy minimum support and minimum confidence. Join Step: To find Lk, Generate k-itemsets by joining Lk-1 with itself. Prune Step: Any (k-1)-itemset that are not frequent cannot be a subset of a frequent k-itemset.
V. Conclusion
In healthcare, data mining is becoming increasingly more essential. Data mining has come into existence
in the mid of 1990 and widely used in the fields of biomedical, healthcare and engineering. Using data mining technologies, we can predict the diseases earlier. This paper provides an idea about diabetes mellitus, the life-threatening disease and about its diagnosis using data mining with minimum number of attributes applied to classification algorithms. With the help of data mining algorithms, the computation cost decreases and also the classification performance increases. This study has included two algorithms of association rule mining technique, v.i.z Apriori and FP-Growth techniques. In FP-Growth a novel data structure, frequent pattern tree (FP-tree), is being implemented for storing compressed, crucial information about frequent pattern. There are several advantages of FP-growth over other Apriori approach: 1) It constructs a highly compact FP-tree, which is usually substantially smaller than the original database and thus saves the costly database scans in the subsequent mining processes 2) It applies a pattern growth method which avoids costly candidate generation and test by successively concatenating frequent 1-itemset found in conditional FP-trees 3) It applies a partitioning-based divide-and-conquer method which dramatically reduces the size of the subsequent conditional pattern bases and conditional FP-trees. It is observed that both the techniques generate the same number of frequent sets as a consequence same number of rules for the same known dataset under the same constraints. These rules have the potential to improve the expert system and to make better clinical decision making. In a thickly populated country with scarce resources such as India, public awareness can also be achieved through the dissemination of the above knowledge.
References
[1] Jiawei Han, Jian Pei and Yiwen Yin, “ Mining Frequent Patterns without Candidate Generation, International Conference on Management of Data, 2000 ACM SIGMOD international conference on Management of data
[2]Christian Borge, “An Implementation of The FP-growth Algorithm, Conference on Knowledge Discovery in Data mining: frequent pattern mining implementations, 2005
[4] Agrawal and R. Srikant, “Fast Algorithms for mining association rules”, Sept. 1994.
[5] Carlos Ordonnez, “Comparing Association Rules and Decision Trees for Disease Prediction”, HIKM’06, November 11, 2006,
[6] Ruoming Jin, Yuri Breitbart, Chibuike Muoh, "Data Discretization Unification," icdm, pp. 183-192, Seventh IEEE International Conference on Data Mining, 2007.
[7] Khiops, “A Statistical Discretization Method of Continuous Attributes. Marc Boullé. Journal Title: Machine Learning,, 2004.
[8] D.Shanthi,,Dr.G.Sahoo,,Dr.N.Saravanan,2008, “Designing an Artificial Neural Network Model for the Prediction of Thromboembolic Stroke” (IJBB), Volume 3, pp.10-18.
[9] ShantakumarB.Patil,Y.S.Kumaraswamy , “Predictive data mining for medical diagnosis of heart disease”, 2011.
[10] Duen-Yian Yeh a, Ching-Hsue Cheng b, Yen-Wen Chen 2011 “A predictive model for cerebrovascular disease using data mining” Vol. 8970-8977.
Authors
A. Sangeetha completed her
B.Tech (CSE), MVGR College of Engineering, Chintalavalasa, vijayanagaram, AP, India. She is pursuing M.tech in Sri Sivani College of engineering chilakapalem. Her areas of Interests are Data mining, Networking and mining techniques.
Dr. RAJENDRA KUMAR GANIYA did his Ph.D in Computer Science and Engineering from Andhra University in 2015, Visakhapatnam, received his M.Tech degree in Computer Science and Engineering from Acharya Nagarjuna University in 2005, Guntur, M.Sc degree in Computer Science from Andhra University in 2000