S t r u c t u r a l D i s a m b i g u a t i o n B a s e d on R e l i a b l e
E s t i m a t i o n o f S t r e n g t h o f A s s o c i a t i o n
H a o d o n g W u E d u a r d o d e P a i v a Alves Teiji F u r u g o r i
D e p a r t m e n t o f C o m p u t e r Science U n i v e r s i t y of E l e c t r o - C o m m u n i c a t i o n s 1-5-1, C h o f u g a o k a , C h o f u , T o k y o 1828585, J A P A N
{wu, e a l v e s , f u r u g o r i } @ p h a e t o n . c s . u e c . a c . j p
A b s t r a c t
This paper proposes a new class-based m e t h o d to estimate the strength of association in word co-occurrence for the purpose of structural dis- ambiguation. To deal with sparseness of data, we use a conceptual dictionary as the source for acquiring u p p e r classes of the words related in t h e co-occurrence, and then use t-scores to determine a pair of classes to be employed for calculating the strength of association. We have applied our m e t h o d to determining dependency relations in Japanese and prepositional phrase a t t a c h m e n t s in English. The experimental re- sults show that the m e t h o d is sound, effective and useful in resolving structural ambiguities.
1
I n t r o d u c t i o n
T h e strength of association between words pro- vides lexical preferences for ambiguity resolu- tion. It is usually estimated from statistics on word co-occurrences in large corpora (Hindle and Rooth, 1993). A problem with this ap- proach is how to estimate the probability of word co-occurrences t h a t are not observed in the training corpus. There are two main ap- proaches to estimate the probability: smoothing m e t h o d s (e.g., Church and Gale, 1991; Jelinek and Mercer, 1985; Katz, 1987) and class-based m e t h o d s (e.g., Brown
et al.,
1992; Pereira and Tishby, 1992; Resnik, 1992; Yarowsky, 1992).Smoothing m e t h o d s estimate the probabil- ity of the unobserved co-occurrences by using frequencies of the individual words. For exam-
pie, when
eat
andbread
do not co-occur, the probability of(eat, bread)
would be estimated by using the frequency of(eat) and (bread).
A problem with this approach is t h a t it pays no attention to the distributional characteris- tics of the individual words in question. Using this m e t h o d , the probability of(eat, bread>
and(eat, cars)
would become the same whenbread
andcars
have the same frequency. It is unac- ceptable from the linguistic point of view.Class-based methods, on the other hand, es- timate the probabihties by associating a class with each word and collecting statistics on word class co-occurrences. For instance, instead of calculating the probability of
(eat, bread)
di- rectly, these m e t h o d s associateeat
with the class[ingest]
andbread
with tile class[food]
and collect statistics on the classes[ingest]
and[food].
T h e accuracy of the estimation depends on the choice of classes, however. Some class- based m e t h o d s (e.g., Yarowsky, 1992) associate each word with a single class without considcr- ing the other words in the co-occurrence. How- ever, a word m a y need to be replaced by differ- ent class depending on the co-occurrence. Some classes m a y not have enough occurrences to al- low a reliable estimation, while other classes m a y be too general and include too m a n y words not relevant to the estimation. An alternative is to obtain various classes associated in a taxon- o m y with the words in question and select the classes according to a certain criteria.for which the association for the co-occurrence can b e e s t i m a t e d . This a p p r o a c h m a y result in unreliable estimates, since some of the class co- occurrences used m a y be a t t r i b u t e d to chance. Resnik (1993) selected all pairs of classes corre- s p o n d i n g to the head of a prepositional phrase and weighted t h e m to bias the c o m p u t a t i o n of the association in favor of higher-frequency co-occurrences which he considered "more reli- able." C o n t r a r y to this assumption, high fre- q u e n c y co-occurrences axe unreliable when the p r o b a b i l i t y t h a t the co-occurrence m a y b e at- t r i b u t e d to chance is high.
In this p a p e r we propose a class-based m e t h o d t h a t selects the lowest classes in a tax- o n o m y for which the co-occurrence confidence is above a threshold. We subsequently apply the m e t h o d to solving s t r u c t u r a l ambiguities in J a p a n e s e d e p e n d e n c y structures and English prepositional phrase a t t a c h m e n t s .
2
C l a s s - b a s e d
E s t i m a t i o n
o f
S t r e n g t h o f A s s o c i a t i o n
T h e s t r e n g t h of association (SA) m a y b e m e a s u r e d using the frequencies of word co- occurrences in large corpora. For instance, Church and Hanks (1990) calculated SA in terms of m u t u a l information b e t w e e n two words wl and w2:
N * f(wl,w2)
I(wl,
w2) =log2
(1)f(wl)f(w2)
here N is the size of the corpus used in the es- timation, f ( W l , w2) is the frequency of the co- occurrence,
f(wl)
andf(w2)
t h a t of each word. W h e n no co-occurrence is observed, SA m a y b e e s t i m a t e d using the frequencies of w o r d classes t h a t contain the words in question. T h e m u t u a l information in this case is e s t i m a t e d by:I(CI, C2) = log2 N * f(Cl, C2) (2) f(Cl )f(C2)
here Cl and C2 are the word classes that respec- tively contain Wl and w2, f ( C 1 ) and f ( C 2 ) the n u m b e r s of occurrences of all the words included in the w o r d classes C1 and C2, and
f(C1,
C2) isthe n u m b e r of co-occurrences of the word classes C1 and C2.
Normally, the e s t i m a t i o n using word classes needs to select classes, from a taxonomy, for which co-occurrences are
significant.
We use t- scores for this purpose 1 .For a class co-occurrence (C1,C2), the t- score m a y be a p p r o x i m a t e d by:
~ f(C,,C2) - -~f(Cl)f(C2) (3)
J/(c,,c2)
We use the lowest class co-occurrence for which the confidence m e a s u r e d with t-scores is above a threshold 2. Given a co-occurrence con- taining the word w, our m e t h o d selects a class for w in the following way:
Step 1: Obtain the classes C 1, C 2 .... , C n associ- ated with w in a taxonomy.
Step 2: Set i to 0. Step 3: Set i to i q- 1.
Step 4: Compute t using formula (3). Step 5: If t <
threshold.
If i ~ n goto step 3. Otherwise exit.
Step 6: Select the class C i to replace w.
Let us see w h a t this means with an ex- ample. S u p p o s e we try to estimate SA for
(produce, telephone) 3.
See Table 1. Here f ( v ) ,f(n)
andf(vn)
axe the frequencies for the verbproduce,
classes for the n o u ntelephone,
and co- occurrences b e t w e e n the verb and the classes fortelephone,
respectively; and t is the t-score 4.' T h e t-score (Church and Mercer, 1993) compares the hypothesis that a co-occurrence is significan~ against the
null hypothesis that the co-occurrence can be attributed to chance.
2The default threshold for t-score is 1.28 which cor- responds to a confidence level of 90%. t-scores are often inflated due to certain violations of assumptions.
aThe d a t a was obtained from 68,623 verb-noun pairs in E D R Corpus (EDR, 1993).
verb classes for telephone f(v) f(n) f(vn) t-score p r o d u c e concrete thing 671 18926 100 -4.6 p r o d u c e inanimate o b j e c t 671 5593 69 0.83 p r o d u c e i m p l e m e n t / t o o l 671 2138 35 1.91
p r o d u c e machine 671 664 19 2.86
p r o d u c e c o m m u n i c a t i o n machine 671 83 1 0.25
p r o d u c e telephone 671 24 0 -
Table 1 E s t i m a t i o n of (produce telephone)
T h e lowest class co-occurrence (produce, communication machine) has a low t-score and produces a b a d estimation. T h e m o s t frequent co-occurrence (produce, concrete thing) has a low t-score also reflecting the fact t h a t it m a y be a t t r i b u t e d to chance. The t-scores for (produce, machine) and (produce, implement/tooO are high and show t h a t these co-occurrences are sig- nificant. A m o n g them, our m e t h o d selects the lowest class co-occurrence for which the t-score is above the threshold: (produce, machine).
3
Disambiguation
Using
Class-Based Estimation
We now apply our m e t h o d to e s t i m a t e SA for two different t y p e s of syntactic constructions and use the results in resolving s t r u c t u r a l am- biguities.
3 . 1 D i s a m b i g u a t i o n o f D e p e n d e n c y R e l a t i o n s i n J a p a n e s e
Identifying the d e p e n d e n c y s t r u c t u r e of a J a p a n e s e sentence is a difficult p r o b l e m since the language allows relatively free w o r d or- ders. A typical d e p e n d e n c y relation in J a p a n e s e a p p e a r s in the form of modifier- particle-modificand triplets. W h e n a modifier is followed b y a n u m b e r of possible modificands, verb, the verb itself or, when it does not give us a good
result, only the lowest class of the verb in calculating the strength of association (SA). Thus, for an example, the
verb eat has a sequence of eat ~ ingest ~ put something into body --%... --" event -" concept in the class hierarchy,
but we use only e a t and ingest for the verb eat when calculating SA for (eat, apple).
there arise situations in which syntactic roles m a y be unable to d e t e r m i n e the d e p e n d e n c y re- lation or the modifier-modificand relation. For instance, in
' ~ 0 '(vigorous) m a y m o d i f y either ' q~ ~ ' (middle aged) o r ' t l l ~ ' ( health care). B u t which one is the modiflcand o f ' ~ ~ ~ 0 ' ? We solve the a m b i g u i t y c o m p a r i n g the strength of association for the two or more possible de- p e n d e n c y relations.
Calculation of Strength of Association We cal- culate the S t r e n g t h of Association (SA) score for m o d i f i e r - particle - m o d i f i c a n d by:
SA(rn / ; p . . . m.) = log2 \ / ( C . , l i . r ) / ( p . . t r n . ) ]
(a)
where C m f i e r s t a n d s for the classes t h a t in- clude the modifier word, Part is the particle fol- lowing the modifier, mc the content word in the modificand phrase, and f the frequency.
Let us see the process of obtaining SA score in an example ( ~ - ¢)~- ~ ( ) (literally: profes- sor - s u b j e c t . m a r k e r - work). To calculate the frequencies for the classes associated with ' ~ ', we o b t a i n from the Co-occurrence Dictionary ( C O D ) 5 the n u m b e r of occurrences for (w- 3 ¢- SCOD and CD are provided by Japan Electronic Dic- tionary Research Institute (EDR, 1993). COD contains
[image:3.612.146.480.66.165.2]< ), where w can be any modifier. We t h e n obtain from the C o n c e p t Dictionary (CD) 6 the c l o s e s t h a t include ' $ ~ ' a n d t h e n s u m up all the occurrences of words included in the classes. T h e relevant portion of CD for ' $ ~ ' in ( ~
- $ ~ - ~ < ) is shown in Figure 1. T h e n u m b e r s
in parenthesis here indicate the s u m m e d - u p fre- quencies.
We t h e n calculate the t-score b e t w e e n ' $~- < ' and all the classes t h a t i n c l u d e ' ~ '. See Table 2.
Classes for the t- particle-
modifier ~ score modificand
A ~ ~ $ # ~ 4.57 h¢~<
A ~ 5.14 $ ~ <
~ O ~ A ~ 1.74 ~ <
~ ~ A ~ 0.74 ~ <
Table 2 t-scores for ( ~ - ~ - ~ < )
T h e t-score for the co-occurrence of the modifier and particle-modificand pair, ' ~ } ~ ' and ' ~ ) ~ - ~ < ', is higher t h a n the threshold when ' ~ ' is replaced with [ ~ J ~ C ~ _ t ~ ) k r ~ ] . Using (4), the s t r e n g t h of ~ s o c i a t i o n for the co- occurrence of ( ~ - ~)~ - ~ < ) is calculated from the SA between the c l ~ s [~R~lJ'C~_?cgk~] and , ~ _ ~ < . '
W h e n the word in question has more t h a n one sense, we e s t i m a t e SA corresponding to each sense and choose the one t h a t results in the highest SA score. For instance, we e s t i m a t e SA between ' ~ ' and the various senses of ' ~ < ', a n d choose the highest value: in this case the one corresponding to the sense 'to be employed.'
Determination of Most Strongly Associated Structure After calculating SA for each possible construction, we choose the construction with highest SA score as the most probable struc-
pm-ticle-modificand triplets in a corpus t h a t includes 220,000 parsed Japanese sentences.
6 CD provides a hierarchical structure of concepts cor- responding to all the words in COD. T h e number of con- cepts in CD is about 400,000.
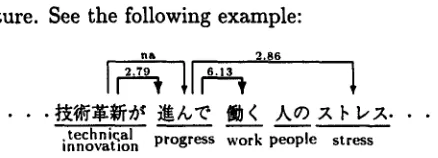
ture. See the following example:
• • . ~ ¢ ) ~ ~ ' C ~ < ) k c ) ~ b ~ : ~ . • •
[image:4.612.312.531.55.134.2].technic:al progress work people stress |nnovatlon
Here, the arrows show possible d e p e n d e n c y relations, the n u m b e r s on the arrows the esti- m a t e d SA, and t h e thick arrows t h e d e p e n d e n c y with highest m u t u a l information t h a t m e a n s the most probable d e p e n d e n c y relation. In t h e ex- ample, ' ~ d : ~ ~' modifies ' j~A.'C ' a n d ' ~ < ' m o d i f e s ' A '. T h e e s t i m a t e d m u t u a l informa- tion for ( ~ g ~ # ~ , ~A,~C ) is 2.79 a n d t h a t for ( ff~ i , A ) is 6.13. Thus, we choose ' ~_/,~C ' as the modificand for ' ~ $ ¢ ' a n d ' ,k ' as t h a t for ' ~ i '
In the example shown in Figure 2, our m e t h o d selects the most likely modifier- modificand relation.
Experiment Disambiguation of d e p e n d e n c y re- lations was done using 75 anlbiguous con- structions from F u k u m o t o (1992). Solving the ambiguity in the constructions involves choosing among two or more modifier-particle- modificand relations. T h e training d a t a con- sists of all 568,000 modifier-particle-modificand triplets in COD.
Evaluation We evaluated the p e r f o r m a n c e of our m e t h o d comparing its results with those of o t h e r m e t h o d s using the same test a n d training data. Table 3 shows the various results (suc- cess rates). Here, (1) indicates the p e r f o r m a n c e obtained using the principle of Closest A t t a c h - m e n t (Kimball, 1973); (2) shows the perfor- m a n c e obtained using the lowest observed class co-occurrence (Weischedel et al., 1993); (3) is the result from the m a x i m u m m u t u a l informa- tion over all pairs of classes corresponding to the words in the co-occurrence (Resnik, 1993; Alves, 1996); and (4) shows the p e r f o r m a n c e of our m e t h o d 7.
(3) person (3)
I human or similar (42)
I
A M
(39) human
defined by race or origin
(3) Japanese (2) worker
(5) person defined by role
(I) person defined by position
..°. ...
(I) slave (0) professor
Figure 1 An Extract of CD
[~ 9.19 [ 4.48 F - ' ) I t
national investigation based cause prompt study expect Figure 2 An example of parsing a Japanese sentence
m e t h o d precision
(1) closest a t t a c h m e n t 70.6% (2) lowest classes 81.2% (3) m a x i m u m MI 82.6% (4) our m e t h o d 87.0%
Table 3 Results for determining dependency relations
Closest a t t a c h m e n t (1) has a low perfor- mance since it fails to take into consideration the identity of the words involved in the deci- sion. Selecting the lowest classes (2) often pro- duces unreliable estimates and wrong decisions due to d a t a sparseness. Selecting the classes with highest m u t u a l information (3) results in overgeneralization that m a y lead to incorrect at- tachments. Our m e t h o d avoids b o t h estimating from unreliable classes and overgeneralization and results in b e t t e r estimates and a better per- formance.
A qualitative analysis of our results shows two causes of errors, however. Some errors oc- curred when there were n o t enough occurrences of the particle-modificand p a t t e r n to estimate
any of the strength of association necessary for resolving ambiguity. Other errors occurred when the decision could not be made without surrounding context.
3 . 2 P r e p o s i t i o n a l P h r a s e A t t a c h m e n t i n E n g l i s h
Prepositional phrase (PP) a t t a c h m e n t is a paradigm case of syntactic ambiguity. The most probable a t t a c h m e n t m a y be chosen comparing the SA between the P P and the various attach- m e n t elements. Here SA is measured by:
S A( v_attachlv, p,
n2)= log2 \ - ] - ( C ~ ~',2 ) )
(5)
SA(n_attachln,,p, n,) -- log, \ 7-(C-~,~-C,--~2 ) ]
(6)
where Cw stands for the class that includes the word w and f is the frequency in a training d a t a containing
verb-nounl-preposition-noun2
constructions. [image:5.612.89.504.68.339.2] [image:5.612.98.276.365.436.2]then chooses the attachment with highest SA score as the most probable.
Experiment
We performed a P P attachment experiment on the d a t a that consists of all the 21,046 semantically annotatedverb-noun-
preposition-noun
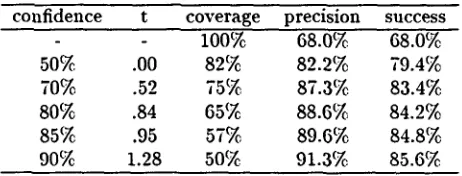
constructions found in EDR English Corpus. We set aside 500 constructions for test and used the remaining 20,546 as train- ing data. We first performed the experiment using various values for the threshold. Table 4 shows the results. The first line here shows the default which corresponds to the most likely attachment for each preposition. For instance, the prepositionof
is attached to the noun, re- flecting the fact that PP's led byof
are mostly attached to nouns in the training data. The 'confidence' values correspond to a binomial dis- tribution and are given only as a reference s.confidence t coverage precision success
100% 68.0% 68.0%
50% .00 82% 82.2% 79.4%
70% .52 75% 87.3% 83.4%
80% .84 65% 88.6% 84.2%
85% .95 57% 89.6% 84.8%
90% 1.28 50% 91.3% 85.6%
Table 4 Results for P P attachment with various thresholds for t-score
The precision grows with t-scores, while coverage decreases. In order to improve cov- erage, when the m e t h o d cannot find a class co-occurrence for which the t-score is above the threshold, we recursivcly tried to find a co-occurrence using the threshold immediately smaller (see Table 4). When the method could not find co-occurrences with t-score above the smallest threshold, the default was used. The overall success rates are shown in "success" col- umn in Table 4.
SAs another way of reducing the sparse data problem, we clustered prepositions using the method described in "~Vu and Furugori (1996). Prepositions like synonyms
a n d a n t o n y m s are clustered into groups and replaced by a representative preposition (e.g., till and pending are replaced by until; amongst, amid and amidst are replaced by among.).
Evaluation
We evaluated the performance of our m e t h o d comparing its results with those of other methods with the same test and training data. The results are given in Table 5. Here, (5) shows the performance of two native speakers who were just presented quadruples of four head words without surrounding contexts.Method Success Rate
(1)closest Attachment 59.6%
(2)lowest classes 80.2%
(3)maximum MI 79.0%
(4)our m e t h o d 85.6%
(5)human (head words only) 87.0%
Table 5 Comparison with other methods
The lower bound and the upper bound on the performance of our m e t h o d seem to be 59.6% scored by the simple heuristic of closest attachment (1) and 87.0% by human beings (4). Obviously, the success rate of closest attach- ment (1) is low as it always attaches a word to the noun without considering the words in ques- tion. The unanticipated low success rate of hu- man judges is partly due to the fact that some- times constructions were inherently ambiguous so that their choices differed from the annota- tion in the corpus.
Our m e t h o d (4) performed better than the lowest classes method (2) and maximum MI m e t h o d (3). It owes mainly to the fact that our m e t h o d makes the estimation from class co- occurrences that are more reliable.
4
C o n c l u d i n g R e m a r k s
[image:6.612.311.537.164.250.2] [image:6.612.66.297.322.410.2]overcame the shortcomings from other meth- ods: overgeneralization and employment of un- reliable class co-occurrences.
We applied our method to two structural disambiguation experiments. In both exper- iments the performance is significantly better than those of others.
R e f e r e n c e s
[1] Alves, E. 1996. "The Selection of the Most Probable Dependency Structure in Japanese Using Mutual Information." In
Proc. of the
34th ACL,
pages 372-374.[2] Brown, P., Della Pietra, V. and Mercer, R. (1992). "Word Sense Disambiguation Us- ing Statistical Methods."
Proceedings of the
30th ACL,
pages 264-270.[3] Church, K., and Mercer, R. 1993. "Introduc- tion to the Special Issue on Computational Linguistics Using Large Corpora."
Compu-
tational Linguistics,
19 (1): 1-24.[4] Church, K., and Hanks, P. 1990. "Word As- sociation Norms, Mutual Information and Lexicography."
Computational Linguistics,
16(1):22-29.
[5] Church, K., and Gale, W. 1991. "A Com- parison of the Enhanced Good-Turing and Deleted Estimation Methods for Estimat- ing Probabilities of English Bigrams."
Com-
puter Speech
andLanguage,
5:19-54.[6] Fukumoto, F., Sano, H., Saitoh, Y. and Fukumoto J. 1992. "A Framework for De- pendency Grammar Based on the Word's Modifiability Level - Restricted Dependency Grammar." Trans.
IPS Japan,
33(10):1211- 1223 (in Japanese).[7] Hindle, D., and Rooth, M. 1993. "Structural Ambiguity and Lexical Relations."
Compu-
tational Linguistics,
19(1):103-120.[8] Japan Electronic Dictionary Research Insti- tute, Ltd. 1993.
EDR Electronic Dictionary
Specifications Guide
(in Japanese).[9] Jelinek, F., and Mercer, R. 1985. "Proba- bility Distribution Estimation from Sparse Data."
IBM Technical Disclosure Bulletin,
28:2591-2594.
[10] Katz, S. 1987. "Estimation of Probabili- ties from Sparse Data for Language Model Component of a Speech Recognizer."
IEEE
Transactions on Acoustics, Speech and Sig-
nal Processing,
ASSP-35(3):400-401.[11] Kimball, J. 1973. "Seven Principles of Surface Structure Parsing in Natural Lan- guage."
Cognition,
2:15-47.[12] Pereira, F. and Tishby, N. 1992. "Distribu- tional Similarity, Phrase Transitions and Hi- erarchical Clustering." In
Proc. of the 30th
ACL,
pages 183-190.[13] Resnik, P. 1992. "Wordnet and Distribu- tional Analysis: A Class-Based Approach to Lexical Discovery."
A A A I Workshop on
Statistically-based Natural Language Pro-
cessing Techniques,
pages 56-64.[14] Resnik, P. 1993. "Selection and Informa- tion: A Class-Based Approach to Lexical Relationships." PhD. thesis, University of Pennsylvania.
[15] Weischedel, R., Meteer, M., Schwartz, R., Ramshaw, L., and Palmucci, J. 1993. "Cop- ing with Ambiguity and Unknown Words Through Probabilistic Models."
Computa-
tional Linguistics,
19(2):359-382.[16] Wu, H. and Furugori, T. 1996. "A Hy- brid Disambiguation Model for Preposi- tional Phrase Attachment."
Literary and
Linguistic Computing.
11(4):187-192.[17] Yarowsky, D. 1992. "Word Sense Disam- biguation using Statistical Models of Roget's Categories Trained on Large Corpora."
Pro-