34 | International Journal of Computer Systems, ISSN-(2394-1065), Vol. 06, Issue 02, May, 2019
Improvement in performance of k-means clustering algorithm using genetic
algorithm based centroid selection
Surbhi Patel, Neha Sehta Department of Computer Science and Engineering
Sushila Devi Bansal College of Technology Indore, Madhya Pradesh, India
Abstract
The data mining techniques are classified into the supervised and unsupervised learning techniques In this presented work the unsupervised learning is the main area of investigation and algorithm design. Therefore a traditional algorithm namely k-means clustering is selected for study and their improvement. The k-means algorithm includes two key deficiencies first selection of random centroids, additionally the long running time for producing the stable solution. In this context the proposed work is intended to design a new algorithm that helps to find a fixed centroid for processing fast the data. In order to select the effective centroid for performing clustering the proposed work includes the employment of genetic algorithm for finding the equally distributed centeroids. After selection of centroids using the genetic algorithm the centroids are produced over the traditional k-means clustering algorithm. The k-means clustering algorithm evaluates the data points with respect to the selected centroids using genetic algorithm. Additionally if required the algorithm make small adjustment on the selected centroids. Using the proposed approach the amount of time consumed for processing the datasets using the k-means algorithm is successfully reduce. In addition of that the improvement on the accuracy of clustering is also observed. Using the proposed technique k-means algorithm produces much consistent outcomes as compared to traditional k-means algorithm. The experimental comparative study of the proposed approach is also conducted that shows the superiority of proposed work.
Keywords: Unsupervised Learning, K-Means Clustering, Genetic Algorithm, Improvements, Implementation.
I. INTRODUCTION
Data mining techniques are one of the essential tool, that offers the automated data analysis and pattern recovery form bulky data. According to the data analysis points of view the data mining algorithms are categorized into supervised and unsupervised techniques. The supervised learning techniques are accurate and efficient, which can be used for classification and prediction task. The supervised learning accepts the pre-labeled data to learn on the patterns, after learning these algorithms are able to classify or recognize the similar patterns. [1]. In order to make enable for classification and prediction, it is required to learn the algorithms with some predefined data samples or patterns. Additionally on the basis of learned patterns the system classifies the data or predicts the similar patterns. On the other hand the unsupervised learning algorithms are directly applicable on the data. . The unsupervised learning techniques work directly on raw data and according to user input (number of classes) it categorizes the patterns based on internal similarity of data objects. These algorithms estimate the internal similarity or distance for making clusters or groups of similar kinds of data instances [2].
But with respect to the supervised learning techniques the unsupervised learning algorithms are less accurate. In this presented work the main aim is to analyze and study the different unsupervised learning techniques more specifically the K-means clustering technique. The k-means clustering is a partition based clustering approach
which evaluates data instances based on the distance function [3]. The less distance means the similarity in the target pattern. In addition of that the k-means algorithm are working on the basis of objective function. When the objective of the clustering is reached the algorithm stops and the results are omitted. The proposed work is dedicated to study the traditional k-means clustering algorithm, additionally addressing of the core issues and challenges to improve the performance of clustering. Finally a modified algorithm is proposed for design and implementation that outperform with respect to the existing k-means clustering algorithm.
II. PROPOSED WORK
This chapter provides the details about the proposed cluster analysis algorithm. The proposed algorithm is modified approach of traditional K-means algorithm. Therefore the methodology and proposed algorithm is reported in this chapter.
A. System Overview
which are evaluating the data according to the available instances of dataset. Additionally for recovering the patterns the distance or similarity matrix are used. The main aim of the proposed work is to improve a classical clustering approach namely k-means clustering technique. The k-means clustering technique is improved for two major motives first the improvement of their accuracy and stability on the pattern categorization. Second the reduction on the algorithms running time. In this context the proposed solution involve the pre-identification of the centroids which can provide the solution for both the aims. The fixed centroid can helps us for efficient clustering in less number of optimization cycles additionally offers the stable accuracy during the cluster performance evaluation. Therefore to select the optimal centroids the proposed work involves the genetic algorithm. The genetic algorithm is heuristic search approach which is employed for finding the centroids in such manner by which the cluster computation becomes equally distributed. After the election of effective centroids the traditional k-means is used for labeling of the cluster points. The proposed technique is a promising technique for cluster computation and it enabled us for providing efficient and accurate clusters. This section provides the overview of the proposed work, in next section proposed methodology is explained in detail.
B. Methodology
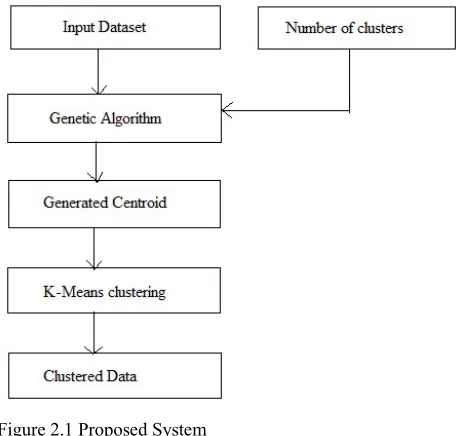
The proposed working methodology is demonstrated in the figure 2.1. This diagram contains the essential components of the proposed system. The details of the components are given in this section.
Input dataset: the key element of any machine
learning and data mining technique is Dataset. Therefore in this presented work the data set is used from the UCI repository. It is a web based platform and provide free machine learning and data mining datasets. The data set is obtained from this source for experimental study.
Number of clusters: as the supervised learning algorithms are trained over the predefined patterns and class labels. But the unsupervised learning techniques are not usages the class labels for performing the clustering. Therefore to produce the clustering, the algorithm needs to provide input as number of clusters.
Genetic algorithm: Genetic algorithm is genetically inspired search process that finds the optimum solution in huge search space. The available resources are genetically treated to find the fittest response among a number of solutions, which is basically an iterative process for discovering more appropriate solution. This search technique guarantees to find the best solution, but intermediate solution is also produces in each progressive steps. Therefore before use of this algorithm the primary functioning of the genetic algorithm is required to learn. The genetic algorithms use the three main concepts for solution discovery: reproduction, natural selection and diversity of the genes. [15]
Figure 2.1 Proposed System
Genetic Algorithms processes a pair of individuals these individuals are the sequence of symbols that are participating in solution space. The new generation is produced using the selection process and genetically inspired operators. The brief description of the overall search process is given as.
Generate initial population– initially the genetic algorithms are initiated with the randomly generated sequences, with the allowed alphabets for the genes. For simplifying the computational process all the generated population sequences have the same number of symbols in each sequence.
Check for termination of the algorithm– for stop the genetic algorithm a stopping criterion is required to fix for finding the optimum solution. It is possible to stop the genetic optimization process by using
1.value of the fitness function, 2.Maximal number of iterations 3.and fixing the number of generation
Selection – that is a process of selecting the optimum symbols among all individuals, in this situation for deciding the new population two operators are used namely crossover and mutation. In this state the scaling of sequences is performed and using these best n individuals is transferred to the new generation. The elitism guarantees, that the value of the optimization function cannot produces the worst results.
Crossover – the crossover is basically the process of recombination the individuals are chosen by selection and recombined with each other. Using this new sequence is obtained. The aim is to get new population individuals, which inherit the best possible characteristics (genes) of their parent’s individuals.
New generation – the selected individuals from the selection process combined with those genes that are processed with the crossover and mutation for next generation development.
According to the found description in [16] the classical genetic algorithm can described using the below given genetic pseudo code.
Input: instance ,
size of population, rate of elitism, rate of mutation, number of iterations Output: solution // initialization
1.generate feasible solutions randomly; 2.save them in the population OP; //Loop until the terminal condition
3.for = 1 to do //Elitism based selection
4.number of elitism e = ∙ ;
5.select the best e solutions in o and save them in o 1;
//Crossover
6.number of crossover c = ( − e)/2 ; 7.for = 1 to c do
a. randomly select two solutions and from o ;
b. generate and by one-point crossover to and ;
c. save and to o 2 ; 8.end for
//Mutation
9.for = 1 to c do
a. select a solution from o 2;
b. mutate each bit of under the rate and generate a new solution ′ ;
c. if ′ is unfeasible
i.update ′ with a feasible solution by repairing ′ ;
d. end if
e. update with ′ in o 2; 10. end for
//Updating
11. update o = o 1 + o 2 ; 12. end for
13. Returning the best solution
14. return the best solution in o ; Table 2.1 genetic algorithm
Generated centroids: the genetic algorithm process the input dataset and after processing of data it return the similar number of solutions as the number of clusters are provided as input. The genetic algorithm stops in this conditions when the total number of solutions remains equals to the number of centroids required.
K-means clustering: in previous chapter we provided the details about the k-means clustering. The k-means algorithm accepts the selected centroids from the genetic algorithm. Additionally using these centroids each available pattern is evaluated and the distance matrix is prepared. This matrix is used to decide the cluster labels to the evaluated data points. In addition of that if solution is not found effective the re-computation of centroid is performed and the again clustering operation is conducted.
Clustered data: it is the final outcome of the proposed methodology, in this stage the final clusters centroid and their relevant cluster data is reported as outcome of the system. Using this outcome the system also provides the clustering accuracy and other performance parameters.
III. PROPOSED ALGORITHM
This section provides the summarized process steps that are used for performing clustering using the proposed technique. The table 2.2 contains the required process steps:
Input: dataset D, number of clusters N Output: clustered data C
Process: 1. 2. 3. 4.
a. b. 5.Else
a. C=
b. Exit clustering 6.End if
7.Return C
IV. RESULT ANALYSIS
This chapter provides the details about the experimental observations of the proposed clustering algorithm. In this context different performance parameters are measured and reported in this chapter.
A.Accuracy
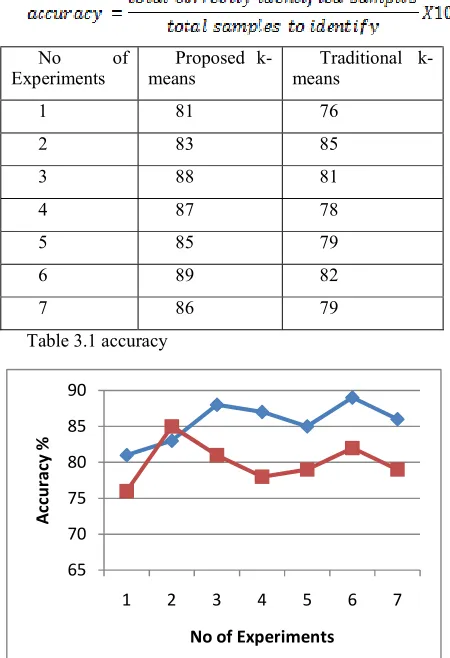
The accuracy of a data mining algorithm is the measurement of delivering correct outcomes during recognition of data instances. In this context the ratio of correctly recognized data samples over the total samples to recognized can used as the accuracy of data mining algorithm. The following formula can be used for this purpose.
No of
Experiments means Proposed k- means Traditional
k-1 81 76
2 83 85
3 88 81
4 87 78
5 85 79
6 89 82
7 86 79
Table 3.1 accuracy
65 70 75 80 85 90
1 2 3 4 5 6 7
Ac
cu
ra
cy
%
No of Experiments
Proposed k-means Traditional k-means
Figure 3.1 accuracy
The comparative performance of the proposed modified k-means clustering algorithm and the traditional k-means algorithm is demonstrated using table 3.1 and table 3.1. The table contains the obtained performance of the clustering algorithm additionally their graphical representation is given in figure 3.1. In order to visualize the performance of the algorithm the X-axis includes the different datasets and the Y-axis consist of the obtained accuracy of the algorithms. According to the given outcomes the proposed algorithm demonstrates the consistent and accurate results as compared to the
traditional clustering algorithm. Therefore the proposed technique provides accurate outcomes and acceptable for real world applications usages.
B.Error Rate
The misrecognition of the data samples can be termed as the error rate of the data mining algorithms. Thus it can be the ratio of total misidentified samples and the total samples provided for recognition. That can be calculated using the following equation.
Or
0 5 10 15 20 25
1 2 3 4 5 6 7
Er
ro
r R
at
e
%
No of Experiments
Proposed k-means Traditional k-means
Figure 3.2 error rate
No of
Experiments k-means Proposed k-means Traditional
1 19 14
2 17 15
3 12 19
4 13 22
5 15 21
6 11 18
7 14 21
Table 3.2 error rate
produces less error rate as compared to the traditional k-means algorithm.
C.Memory Usages
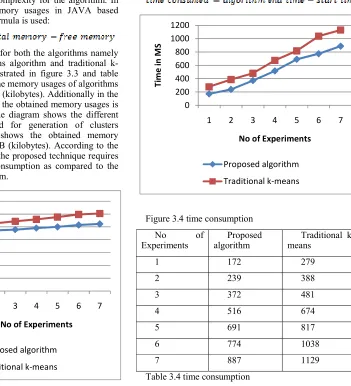
The execution of any computational algorithm requires an amount of memory space to hold the data and instructions. This amount of main memory is known as memory usages or space complexity for the algorithm. In order to measure the memory usages in JAVA based algorithms the following formula is used:
The measured memory for both the algorithms namely proposed improved means algorithm and traditional k-means algorithm is demonstrated in figure 3.3 and table 3.3. In the given table 3.3 the memory usages of algorithms are reported in terms of KB (kilobytes). Additionally in the figure 3.3 using line graphs the obtained memory usages is reported. The X axis of the diagram shows the different size of datasets produced for generation of clusters additionally the Y axis shows the obtained memory consumption in terms of KB (kilobytes). According to the visualized memory usages the proposed technique requires less amount of memory consumption as compared to the traditional k-means algorithm.
0 5000 10000 15000 20000 25000 30000 35000
1 2 3 4 5 6 7
M
em
or
y U
sa
ge
in
K
B
No of Experiments
Proposed algorithm Traditional k-means
Figure 3.3 memory usages No of
experiments algorithm Proposed means Traditional
k-1 22748 25371
2 23615 26351
3 23918 27162
4 24527 27928
5 24991 28817
6 25731 29813
7 26154 30183
Table 3.3 memory usages
D.Time Consumption
The processing of data using some algorithm required an amount of time to process data. The utilized amount of time for producing the outcomes is termed here as the time consumption of algorithm. The amount of time consumed is measured using the following formula:
0 200 400 600 800 1000 1200
1 2 3 4 5 6 7
Ti
m
e
in
M
S
No of Experiments
Proposed algorithm Traditional k-means
Figure 3.4 time consumption
No of
Experiments algorithm Proposed means Traditional
k-1 172 279
2 239 388
3 372 481
4 516 674
5 691 817
6 774 1038
7 887 1129
Table 3.4 time consumption
The measured time consumption of both the algorithms is reported in this section. The table 3.4 contains observed time requirements of the algorithms in terms of milliseconds (MS). The obtained values from table 3.4 are visualized using line graph as given in figure 3.4. In the diagram the X axis includes the different sizes of datasets which are used in experimentation. Additionally the Y axis contains the time requirements of algorithms. According to obtained performance outcomes the proposed technique need less time to provide fixed solution as compared to the traditional k-means clustering algorithm.
V. CONCLUSION
additionally the future extension of the work is also reported.
A. Conclusion
The tools and techniques of data mining helping us to empower the decision making, pattern recognition and forecasting services. All these applications are feasible by analyzing the data and by extraction of hidden patterns in raw data. According to their applications and nature of data analysis the data mining algorithms are classified into supervised and unsupervised learning techniques. In this presented work the main focuses on unsupervised learning is placed. In this context the k-mean algorithm is explored and detailed analysis is derived. During investigation of k-means algorithm there are two key issues are identified. The algorithm initially select the random centroid after that it works to satisfy the objective functions due to this the two issues are common first long running time of algorithm secondly the fluctuating accuracy of the algorithm.
In order to rectify the addressed issues a new solution is introduced in this presented work. According to the proposed concept the centroid selection can help to improve both the aspects of study. Therefore to search the valued centroids among the given dataset a genetic algorithm is employed first. That includes a distance function as a fitness function for the evaluation of population available in dataset. The minimum distance based constrains are satisfied with approach a tried to find centroids which can cover entire dataset with equally distributed data points. In addition of that remaining steps of distance matrix calculation and their clustering is remains similar as the traditional k-means algorithm. The benefit of this scenario is to improve the selection of centroid and reduce the steps of optimization in k-means clustering. When we get the fixed and reliable centroid partitioning of dataset becomes faster and accurate.
The implementation of the proposed concept is performed using JAVA technology. In addition of that for experimentations the dataset is collected from the UCI repository. During the experimentations the obtained performance is measured and based on the experimental outcomes the performance summary is prepared which is reported using table 4.1.
S.
No. Parameters Proposed k-means Traditional means
k-1 Accuracy 81- 89% 76-85%
2 Error rate 11-19% 14-22%
3 Memory
22748-26154 KB KB 25371-30183
4 Time 172-887
MS 279-1129 MS
Table 4.1 performance summary
According to the obtained performance of both the algorithms the proposed clustering algorithm is efficient and accurate as compared to the traditional k-means algorithm. Therefore the proposed work is acceptable for utilizing in applications where the accurate and efficient cluster formation is required.
B. Future Work
The main aim of the work is intended to improve the traditional k-means algorithm for accuracy and the time consumption for performing clusters. Both the aspects of the proposed work are accomplished successfully. In near future the following extension and experimental studies are proposed to work.
1.Evaluation of different centroid selection techniques for the data mining clustering
2.Exploring the techniques of distance calculation among two data patterns for improving the accuracy
Exploring the techniques to obtain multiple data source clustering using big data environment
REFERENCES
[1] Jiawei Han, Micheline Kamber, “Data Mining: Concepts And Techniques Second Edition”, Library Of Congress Cataloging-In-Publication Data, Application Submitted, ISBN 13: 978-1-55860-901-3, ISBN 10: 1-55860-901-6
[2] S. B. Kotsiantis, “Supervised Machine Learning: A Review Of Classification Techniques”, Informatica 31 (2007) 249-268 249 [3] Tapas Kanungo, David M. Mount, Nathan S. Netanyahu, Christine
D. Piatko, Ruth Silverman, And Angela Y. Wu, “An Efficient K-Means Clustering Algorithm: Analysis And Implementation”, IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 24, No. 7, July 2002
[4] Ganesh Krishnasamy, Anand J. Kulkarni, Raveendran Paramesran, “A Hybrid Approach For Data Clustering Based On Modified Cohort Intelligence And K-Means”, Expert Systems With Applications 41 (2014) 6009–6016
[5] Gurjit Kaur, Lolita Singh, “Data Mining: An Overview”, IJCST Vol. 2, Issue 2, June 2011, ISSN: 2229-4333(Print) | ISSN: 0976-8491(Online)
[6] “An Introduction To Data Mining: Discovering Hidden Value In
Your Data Warehouse”,
Http://Www.Thearling.Com/Text/Dmwhite/Dmwhite.Htm [7] Manoj And Jatinder Singh, “Applications Of Data Mining For
Intrusion Detection”, International Journal Of Educational Planning & Administration. Volume 1, Number 1 (2011), Pp. 37-42 [8] M. Rajalakshmi, M. Sakthi, “Max-Miner Algorithm Using
Knowledge Discovery Process In Data Mining”, International Journal Of Innovative Research In Computer And Communication Engineering, Vol. 3, Issue 11, November 2015
[9] SMRITI SRIVASTAVA & ANCHAL GARG, “DATA MINING FOR CREDIT CARD RISK ANALYSIS: A REVIEW”, International Journal Of Computer Science Engineering And Information Technology Research (IJCSEITR), Vol. 3, Issue 2, Jun 2013, 193-200
[10] Dipti Verma And Rakesh Nashine, “Data Mining: Next Generation Challenges And Future Directions”, International Journal Of Modeling And Optimization, Vol. 2, No. 5, October 2012 [11] M Ashish Naidu; K Radha, “Prediction Of Loan Status Using
Clustering Technique In Machine Learning”, IJCSN - International Journal Of Computer Science And Network, Volume 8, Issue 1, February 2019
[12] Ye Ren, Le Zhang, And P. N. Suganthan, “Ensemble Classification And Regression – Recent Developments, Applications And Future Directions’, IEEE Computational Intelligence Magazine ( Volume: 11 , Issue: 1 , Feb. 2016 )
[13] Guojun Gana, Michael Kwok-Po Ng, “K-Means Clustering With Outlier Removal”, Pattern Recognition Letters 90 (2017) 8–14, © 2017 Elsevier B.V