International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 10, October 2012)576
Maintaining File Storage Security in Cloud Computing
Punyada M. Deshmukh
1, Achyut S. Gughane
2, Priyanka L. Hasija
3, Supriya P. Katpale
41,2,3,4 Department of IT VACOE Ahmednagar University of Pune
Abstract - IT enterprise is looking forward Cloud Computing as its next generation architecture. Services provided by this new emerging technology are dynamically scalable. Cloud Service Providers CSP facilitate users to work on different platforms as per their requirement. Pay-per-use feature of Cloud Computing has always been the dream of thousands of Internet users. Using the services of CSP users data is stored at some unknown machine in their large data centers. This makes users having some confidential data on cloud feel insecure. Focusing on this aspect, in this paper we have proposed a system which ensures the data storage security using a distributed scheme. A set of Master servers are used which are responsible for processing the users requests. File chunking operation is performed in order to store replicas of file at Slave server providing backup for file recovery. Unlike the previously proposed systems, efficient and dynamic data operations are performed by users. This efficiency is achieved by imparting the data blocks for different users. The functionality is extended to the Android users and the chatting application is included to add ease and comfort to the working environment of users.
General Terms - The users data in the cloud will be stored in the form of tokens on Master server and chunks on Slave server for recovery. So here we are using Token generation algorithm with use of homomorphic token. And the chunk creation and merging algorithm for chunks.
Keywords - Let S be the system that represents the cloud architecture where S = { A,S,F,U,C| s } where
A => {A} Administrator, Se=> {S0,S1} Set of servers S0 => Master Server S1 => Slave Server
F => {F0,F1,….Fn- f } Set of Files
U => {U0,U1,….Un-C => {{U0,U1,….Un-C0,{U0,U1,….Un-C1,…{U0,U1,….Un-Cn-
{C0,C1,…Cn-I. INTRODUCTION
Cloud Computing is a new emerging technology which provides dynamically scalable and virtualized resources to supplement the current consumption of IT based services. Cloud services avails users for storage of their data, thus reducing their cost and requirement for additional hardware. This uses virtualized resources over the internet and transforming data centers into the pool of computing services on a huge scale. There are no. of vendors in the market who provide cloud service vendors like Amazon, Yahoo, Salesforce, etc.
Storage details of data are abstracted from users as data is placed and processed somewhere else on some remote machine. This introduced some security challenges for CSPs. As the direct management of data is not done by users, there are many chances of data being lost. This is the biggest barrier in adoption of cloud services. The proposed system, hence, is organized in such a way that to store the replica of data everytime a file is uploaded, thus overcoming data loss. Secondly, when for every transaction, main servers were being approached there was a possibility of attackers damaging server which may result into huge amount of data loss. So, the solution for it is implemented in this paper by breaking the direct link of communication between the slave server and users. The users’ access has been limited upto the master server and so denied from storage place of replicas. Also cloud computing is not just a third party warehouse, updation of data is required consistently. The insertion, deletion, modification of data blocks on a dynamic basis is a basic requirement of cloud service users. The paper provides with an absolutely efficient way for this dynamic operations. Each user has been allocated a different set or data block so that the access to unauthorized data will not affect the original data.
The use of distributed scheme for Master server is to distribute the load on master servers and decrease communication overhead. Classifying the architecture into Master and Slave server has decreased possibility of introducing errors.
II. PROBLEM STATEMENT
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 10, October 2012)577
For example, when multiple clients will access the data stored on the cloud data redundancy is achieved and the chunks of data are maintained by the slave servers and multiple access to the data are possible.In the corruption of data, chunks stored on slave servers play an important role in data recovery.
For example, whenever data corruption has been detected during the storage correctness verification, our scheme can almost guarantee the simultaneous localization of data errors, i.e., the identification of the misbehaving server(s).
The high network bandwidth and reliable yet flexible network connections make it possible that users can subscribe high quality services from data and software that reside solely on remote data centers. With extension of functionality to android based phones and use of chat application amongst users the scope of the proposed scheme is enhanced.
III. PROPOSED SYSTEM
3.1 Design Goals
To ensure the data storage security and to allay users’ concerns , we aim to design a efficient mechanism which will give highly secure services and will achieve the following goals:
Storage Correctness – The users’ data on the cloud should remain consistent and must be at the cloud all the time.
Availabilty of data- The data stored on the cloud must be always available to the users .
Dynamic updations- The data should be updated dynamically with proper storage without violating contents of data.
Data Recovery- The Chunks of data stored at slave server must be placed efficiently for easy retrieval.
Light-Weight - To satisfy users about the storage correctness and make its verification with minimum overhead.
3.2 System Model
As per our proposed scheme four different network entities can be identified as follows:
User: users, who have data to be stored in the cloud and rely on the cloud for data computation and also rely on admin for authentication of users.
Cloud Service Provider (CSP): a CSP, who has significant master server and slave server which assures the storage on data and dynamic operations on data.
• Master server: a trusted party, which have distributed scheme of slave servers has expertise and capabilities which ensures data storage and dynamic data, the data uploaded in form of files is stored on master server.
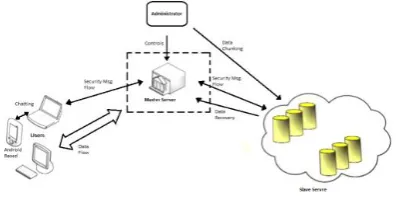
[image:2.595.332.531.191.292.2]Slave server: It plays a major role in forming chunks of the data being uploaded on the master server. It is mainly useful for data recovery in case of server compromise and misbehavior.
Fig 1.1 cloud data storage architecture
Our scheme provides no direct communication between the clients(users) and the slave servers. clients will communicate with the master server for dynamic updates and operations on file. The file uploaded by the client will be stored on the master server and the chunks of the file will be stored on slave servers and in case of server compromise or master server misbehavior the data recovery will be done through the chunks stored on slave servers.
Admin will authenticate the clients and will communicate with master and slave servers .
The system to be developed will help to help user to to perform operations on data and ensure data storage security by providing necessary requirements.
The product functionality as per specific entity is as follows-
User – master server : User will perform file operations(insert, append, delete, modify) and upload or download the file through master server,
Admin - Master server: Admin will have a control over user authentication and data access permission to user through master server.
Admin - Slave server : Admin will perform chunking of data files (specified up to a file size limit)and store it on slave server,
Master server- Slave server: Master server will communicate slave server at the time of data recovery and data chunking.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 10, October 2012)578
The assumption of point to point communication between the user and cloud server compromised of master server and slave server and the user is authenticated and reliable will give the assurance of correctness of working of scheme.Scheme ensures user(client) to perform dynamic operations on data and data storage correctness and ease of storage and retrieval of large pools of data. It does not provide the binary results about the storage correctness of the data but the denial of direct communication between users and the slave servers and challenge response protocol provides localization of data errors. It also supports dynamic and efficient operations on data blocks like: update ,append , delete. In case that users do not necessarily have the time, feasibility or resources to monitor their data, they can delegate the tasks to an master server.
3.3 Notations and Preliminaries
F-> let F be the file stored on the cloud
n-> let m be the vectors of equal size
l-> let l be the blocks of m sized vectors
the data blocks are represented in the elements of Galois field ,where
G.F=2p where p=2or 8.
r-> r be the no of rows of the matrix.
G-> the encoded matrix that Include n=m+k vectors of l blocks.
Ψkey(.)-> pseudorandom permutation (PRP), which is defined as Ψ : {0, 1}log2(l) × key → {0, 1}log2(l).
3.4 File Distribution Preparation
The matrix is dispersed across a set of distributed m=n+k distributed slave servers. (n+k,k) is erasure correcting code used to create k parity vectors from the data vectors.
The original data vectors can be reconstructed from n+k data parity vectors. By placing n+k parity vectors on the slave servers .The original data
File can survive and the backup or recovery can be requested from slave server whenever required. For sequential I/O of original data files our file layout and distribution is systematic.
The m-data vectors combined together with k parity vectors are distributed across slave servers .The original file is stored on master server and the chunks are stored on slave servers.
Let F= {f1,f2,…..fn} and fi= {f1i,f2i,…fli}T
i£{1,….n} where l<2p-1 . The m*(m+k) vandermonde matrix can be-
1 1 . . . 1 1 . . . 1
β1 β2 . . . βn βn+1 . . . βm
. . . . . . . . . .
. . . . . . . . . . βn−1 βn−1 βn−1 βn−1 βn−1
1 2 n n+1 m
1 2 n n+1 m
where αj(j € {1,…m}) are distinct elements picked from Galois field.
The matrix A is derived from vandermonde matrix by dividing the identity matrix and parity generation matrix of m*k size.
1 0 . . . 0 p11 p12 . . . p1k
0 1 . . . 0 p21 p22 . . . p2k . . . . . . . . . . . . . . . . . .
0 0 . . . 1 pn1 pn2 . . . pnk
By multiplying F by A the encoded file can be obtained as-
G=F*A=(G1,G2,…,Gn,Gn+1,…,Gm)
F=(F1,F2,…,Fm,Gn+1,Gm)
Where Gj=(g1j,g2j,……,glj)T where j£(1,….m).
Here the part (Gn+1,…Gm) are parity vectors generated based on F.
3.5 Ensuring Data Storage Security
Whenever user stores the data on cloud the data needs to be stored with correctness and availability of the data files to be stored on master server. For the unavailability, storage incorrectness of the data, byzantine failures and server compromise our proposed scheme distributed scheme deletes such inconsistencies successfully.
Because of denial of communication between users and the slave server the problem of localization of data errors and correctness verification gets solved.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 10, October 2012)579
The first part of this section is devoted to the file distribution across the cloud and the second part to the computation of the homomorphic token which belongs to the universal family of hash function.A.Algorithm 1: Token Generation
1.procedure
2.choose l, n parameters and function fi ,Ψi. 3.choose t -> no of tokens.
4.Choose r no. of indices.
5.Generate key Kprp. 6.For Gi,j<-1,m do
7.For i<-1,t do
8. Derive αi = Kiprp From Kprp
9.Compute vi(j) = ∑q=1r αqi * Gj [Ψkprp is identified (i) (q)]
10.End for 11.End for
12.End procedure.
B.Algorithm 2: File Recovery
1. Assume the file corruption amongst blocks have detected amongst specified rows. Let us assume that master server has been identified misbehaving.
2. Download chunks consisting r rows of blocks from slave server
3. Recover blocks through the backup from slave. 4. Resend the recovery to master server.
5. End procedure.
In algorithm 1 the tokens are generated on the file distribution and the chunks of the file are generated. These chunks are stored on the slave server as the backup of the data. When the master server is identified misbehaving the back up of the data files is taken from the slave server and the error recovery is done by the process shown in algorithm 2.
Thus the proposed scheme effectively deletes the storage incorrectness, unavailability of the data and server compromise and byzantine failures.
IV. WORKING OF SYSTEM
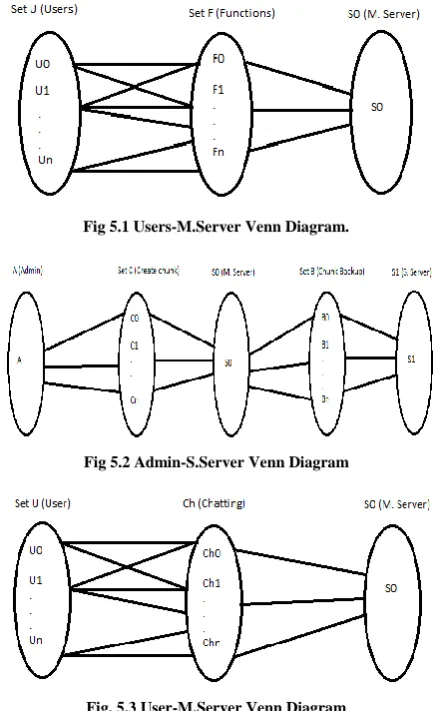
[image:4.595.320.537.142.498.2]The administrator has the control over the whole system. The responsibility of administrator includes maintaining master and slave servers, allowing chunking of files, responding to users request. The following diagrams shows relation between users and server.
Fig 5.1 Users-M.Server Venn Diagram.
Fig 5.2 Admin-S.Server Venn Diagram
Fig. 5.3 User-M.Server Venn Diagram
Fig 5.1 shows the flow of execution of functions performed by users. Users or clients should make request to S0 whenever there is requirement of any execution of any function.
Fig 5.2 specifies the flow required for creation of chunks in order to achieve goal of data recovery. Admin has the authority to make chunks of the file of limited size. So, it contacts with the S0 server for it. Further using chunk backup, file chunks are handovered to S1(Slave server).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 10, October 2012)580
Acknowledgments
Our thanks to Mr. Santosh Gore for his guidance and support for this paper.
REFERENCES
[1] Bowman, M., Debray, S. K., and Peterson, L. L. 1993. Reasoning about naming systems.
[2] Ding, W. and Marchionini, G. 1997 A Study on Video Browsing Strategies. Technical Report. University of Maryland at College Park.
[3] Fröhlich, B. and Plate, J. 2000. The cubic mouse: a new device for three-dimensional input. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems [4] Tavel, P. 2007 Modeling and Simulation Design. AK Peters Ltd.
[5] Sannella, M. J. 1994 Constraint Satisfaction and Debugging for Interactive User Interfaces. Doctoral Thesis. UMI Order Number: UMI Order No. GAX95-09398., University of Washington.
[6] Forman, G. 2003. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 3 (Mar. 2003), 1289-1305.
[7] Brown, L. D., Hua, H., and Gao, C. 2003. A widget framework for augmented interaction in SCAPE.
[8] Y.T. Yu, M.F. Lau, "A comparison of MC/DC, MUMCUT and several other coverage criteria for logical decisions", Journal of Systems and Software, 2005, in press.