2017 2nd International Conference on Computer, Network Security and Communication Engineering (CNSCE 2017) ISBN: 978-1-60595-439-4
Light-field Image Super-resolution Using Convolutional Neural Network
Xiang-xiang ZHENG
*and Xu-dong ZHANG
School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230009, China
*Corresponding author
Keywords: Super-resolution, Light-field, Convolutional neural network, Spatial resolution.
Abstract. Light-field cameras can capture 2D spatial and 2D angular information in a single shot. Nevertheless, light-field cameras usually have a trade-off between the spatial and angular resolution in a restricted sensor resolution. The low spatial resolution of light-field cameras limits the application of light-field cameras. In this paper, we present a novel light-field super-resolution method based on convolutional neural network (CNN). With low-resolution light-field multiview images as input, we directly learn the mapping between low-resolution images and high-resolution images by developing an end-to-end CNN. Experimental results demonstrate that in terms of visual effects and evaluation metrics, the reconstruction results of the proposed methods is superior to those of state-of-the-art methods. The proposed approach takes advantage of useful information among the multiple views of light fields for super-resolution reconstruction.
Introduction
As a new imaging technique, light field imaging records the spatial and angular information of light distribution in space. Thus it can capture a multi-view scene in a single photographic exposure. Light field imaging has become one of the research hotpots in imaging field and has been widely used in computer vision, such as saliency detection [1] and depth estimation [2].
In order to captures LF image in a hand-held devices, a micro-lens array is placed in front of the camera sensor. The micro-lens array encodes angular information of the light rays, but results in a trade-off between spatial and angular resolutions in a restricted sensor resolution. This limitation makes it difficult to exploit the advantages of the LF cameras. Therefore, enhancing LF image resolutions is crucial to take full advantage of LF imaging.
Bishop and Favaro [3] present a Bayesian inference technique based on depth map for light field super-resolution(LFSR) for the first time. Mitra and Veeraraghvan [4] propose a patch-based approach using a Gaussian Mixture Model prior and an inference model according to disparity of a scene. Wanner and Goldluecke [5] introduce a variational LFSR framework by utilizing the estimated depth map from Epipolar plane image. However, the low quality LF images captured by commercial LF cameras limits the application of above method.
Recently, the deep learning approach has been successfully applied to the image restoration problems such as super-resolution (SR)[6] and image deblurring[7]. Dong et al [6] relate the sparse representation to the stacked nonlinear operations to design a CNN for a single image SR. Liao et al[8] tackle video super-resolution(VSR) with the help of draft-ensembles and CNN. Yoon et al[9] first applies the CNN framework to the domain of LF images. Yoon’s network can be divided into spatial SR network and angular SR network. The SR network is similar to the [6], which do not take advantage of the useful information from adjacent sub-aperture images.
Light field SR Network
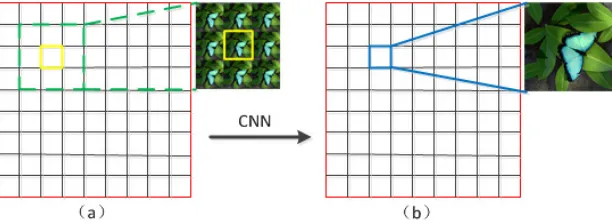
Figure 1 illustrates the framework of the proposed method. Figure 1(a) represents low-resolution sub-aperture images captured by light field camera. We use the adjacent sub-aperture images of the objective perspective as the input of the our CNN to reconstruct the high-resolution sub-aperture image. Each of the low-resolution sub-aperture image can be super-resolved in such a way.
Figure 1. The schematic diagram of light-field super-resolution reconstruction.
Figure 2 illustrates the Architecture of our light field SR network. We use sub-aperture images that already upscaled using bicubic interpolation as the input. The ouput of the l−th layer is expressed as
( )
l
F X =X l=0 (1)
1
( ) tanh( )
l l l l
F X = W ∗F − +B 1≤ ≤l L−1 (2)
1( )
l l l l
F =W ∗F − X +B l=L (3) Here the input sequence X is of size h w c× × , where h and w are the height and width and c
denotes the channel number. Wl is the concatenation of nl convolutional filters in the l−th layer
and is of size fl× fl×nl−1×nl. Here fl is the spatial size of the filter, nl−1 is the number of filters in
the last layer and Bl is the vector of bias with length nl. The size of output of the l−th layer is
l
h w n× × . We use a tanh function as our nonlinear unit. In our network, the number of hidden layers is
4
L= . The filter sizes are set as f1=11, f2 =1, f3=3 and f4 =25. And the numbers of filters are
1 128
[image:2.612.153.459.145.257.2]n = ,n2 =25,n3=1 and n4 =1.
Figure 2. The architecture of our CNN framework.
Training
[image:2.612.78.532.329.605.2]for the first convolutional layer and 10−5for the other layers. With an Euclidean cost, we train our model for approximately 3 10× 7back-propagations.
Experimental Results
In this section, We perform quantitative and qualitative evaluations to demonstrate the validity of the proposed method. We train and test the proposed network on an Intel Core i7-4770 CPU with GTX Titan X. To super-resolve a sub-aperture image, our method takes about average of 17 minutes for 434 632× images taken from a Lytroillum camera and takes about 5 days to train the network until convergence.
We use EPEL light field dataset[11] for quantitative and qualitative evaluation. EPEL light field dataset contain 118 LF images captured by a Lytroillum camera, whose spatial and angular resolution is 434 632× and 15 15× . We use 98 LF images as the training set and the rest 20 LF images as test set.
[image:3.612.93.519.335.682.2]As shown in Figure 3, we compare the proposed method against the method of Ref.[4],Ref.[9]and bicubic interpolation. The bicubic interpolation blurs image details. Ref.[4] is based on EPIs and is sensitive to the disparity pattern. There is difficulty in handling LF images captured by LF cameras since the EPIs are noisy and inaccurate. Our method is similar to Ref.[9] but takes adjacent sub-aperture images as input. Our method can excavate useful information from adjacent sub-aperture images. Thus, recover more high frequency details.
In Table 1, We report peak signal-to-noise (PSNR) and the gray-scale structural similarity (SSIM) values to numerically compared the state-of-the art methods to proposed method. As show in Table 1, Our method consistently yields higher PSNR and SSIM scores than the other three mothods.
Table 1. Quantitative evaluation on the EPEL light-field dataset of different super-resolution results (Bold: the best; Underline: the second best).
bicubic ref[4] ref[9] ours
PSNR(dB) SSIM PSNR(dB) SSIM PSNR(dB) SSIM PSNR(dB) SSIM Car 30.55 0.9596 31.34 0.9599 33.48 0.9692 34.21 0.9739 Iso_chart 32.02 0.8819 32.40 0.8828 34.10 0.8963 34.90 0.9069 Graffiti 32.70 0.8694 33.47 0.8776 34.03 0.9033 34.62 0.9056 Palais 26.50 0.8533 26.66 0.8525 28.19 0.9047 28.86 0.9122
Conclusion
We propose a light field super-resolution method based on CNN. Due to the fact that there exists subpixel displacement between low-resolution sub-aperture images. We design a CNN to excavate useful information from sub-aperture images for light field super-resolution. The experimental results demonstrate that our method outperforms the state-of-the-art methods. In order to make better use of the light field image, next step we will discuss how to improve the angular resolution. At the same time, as there are too many parameters in our CNN model, it takes about 17 minutes to super-resolve a sub-aperture which is time-consuming. Therefore, it is necessary to improve the efficiency of super-resolution by optimizing the network structure in the future.
References
[1] Li N, Sun B, Yu J. A weighted sparse coding framework for saliency detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5216-5223.
[2] Jeon H G, Park J, Choe G, et al. Accurate depth map estimation from a lens let light field camera[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015: 1547-1555.
[3] Bishop T E, Zanetti S, Favaro P. Light field super resolution[C]//Computational Photography (ICCP), 2009 IEEE International Conference on. IEEE, 2009: 1-9.
[4] Wanner S, Goldluecke B. Spatial and angular variational super-resolution of 4D light fields[C] //European Conference on Computer Vision. Springer Berlin Heidelberg, 2012: 608-621.
[5] Mitra K, Veeraraghavan A. Light field denoising, light field super resolution and stereo camera based refocusing using a GMM light field patch prior[C]// Computer Vision and Pattern Recognition Workshops. IEEE, 2012:22-28.
[6] Dong C, Loy C C, He K, et al. Learning a deep convolutional network for image super-resolution[C] //European Conference on Computer Vision. Springer International Publishing, 2014: 184-199.
[7] Hradiš M, Kotera J, Zemcík P, et al. Convolutional neural networks for direct text deblurring[C]//Proceedings of BMVC. 2015: 2015-10.09.
[8] Liao R, Tao X, Li R, et al. Video super-resolution via deep draft-ensemble learning[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 531-539.
![Figure 3. Qualitative comparisons on EPEL light-field datasets at a magnification factor of 2.(a) Bicubic interpolation; (b) Mitra[4];(c) Yoon[9];(d) Ours;(e) Ground truth](https://thumb-us.123doks.com/thumbv2/123dok_us/286930.1029429/3.612.93.519.335.682/figure-qualitative-comparisons-datasets-magnification-bicubic-interpolation-ground.webp)

