2018 International Conference on Computer, Communication and Network Technology (CCNT 2018) ISBN: 978-1-60595-561-2
Similarity Code File Detection Model Based on Frequent Itemsets
Jian-hong JIANG and Ke WANG
*College of Business, Guilin University of Electronic Technology, Guilin 541004, China
*
Corresponding author
Keywords: Source code similarity, Frequent itemset, Association rule.
Abstract. In order to improve the efficiency and accuracy of program source code similarity detection, an improvement on the method of code detection is made according to some deficiencies of the current research. A similar code detection model based on frequent item sets is proposed. The model constructs frequent items set data to discover repetitive code collections and automatically divide file similarity attribution. The algorithm model does not need to consider the type of the code in the detection process, and has wide applicability, not only can detect the code files of different programming languages and grammars, but also can mark out similar codes and statistic the results. Simultaneously, through experimental comparison, it is proved that the model has high accuracy and processing efficiency.
Introduction
The source code of a program is a text file made up of an expression that conforms to a particular grammar, and it is also the product of human intelligence processing. With the increasing openness of Internet and the convenience of programming, code copying and plagiarism are becoming increasingly easier. For example, the present open source project platform and community has provided convenient conditions for the reference and replication of the code. From the perspective of education and teaching, Computer programming courses is also a microcosm of the plagiarism, in these courses, there are also more widespread plagiarism in more course design work or topics. Compared with the traditional programming development industry, although the code is smaller in scale, the functional requirements of the program code are relatively simple, the possibility of code similarity is correspondingly higher, and the difficulty of copying and changing the code is not high. Additionally, for the same reason, different code files are more likely to be judged as a high degree of similarity.
The existing research of code repetitiveness or similarity detection can generally be divided into two categories, attribute statistics and structure-based analysis[1]. The former mainly refers to statistical discrimination of metrics related to code text, the latter refers to the structure of the code is extracted to identify the transformed program logic structure. At present, the commonly used similarity detection software are MOSS, JPlag[2], Sim[3] and so on, different kinds of methods are used.
the replication relationship[10]. G. Cosma et al. used self organization mapping method to compare similar codes based on an algorithm of fuzzy logic, the advantage lies in its independence from program languages[11].
Based on the analysis of program structure, such as JPlag is to analyze the code lexical (token), SIM also uses the lexical analyzer to transform code into token for similarity computation. Cui Shuning et al. established a code evaluation model through the abstract syntax tree of the source code[12]. Liu Chenglong et al. used an abstract syntax tree to extract the similar parts of the program, and performed similarity detection by clustering analysis space vector[13]. Li Siyu proposed an intermediate representation code similarity detection method[14]. Michel Chilowicz et al. combined function call graph with word sequence matching to detect code similarity[15,16]. Tokenization analysis also has literature[17].
There are also combined two methods of text classification and structure discrimination to analyze, such as the use of text similarity, structural similarity, and similarity of variables (attribute counting)[18]. synthesize these similarities and setting the weights, as a reference index to calculate the overall similarity of the two programs.
At present, most of the researches are focused on the above two aspects. The method based on program structure needs specific grammar or lexical analysis tools, and needs targeted optimization to achieve good results. The method based on code text analysis has wide applicability, and the similarity of code is judged from the feature of text, however, for the code that realizes the same target and function, there is a great misjudgment possibility to analyze such documents. From the perspective of solving the code of different programming languages and reducing the misjudgment rate of similar file detection, this paper proposes a computing framework with certain efficiency and convenience of use.
Duplicate Code Detection Model
In order to solve the problem of automatic detection of code files and improve the efficiency of detection, a common code text duplication detection model is proposed in this study. The model is divided into four stages of analysis and processing. Firstly, the text is preprocessed to remove some non-essential elements in the source code. Then the classification method is used to classify the code that implements different functions, perform similarity evaluation on the basis of classification and construct frequent item set data. Finally, a highly similar code is marked out by a duplicate file search algorithm.
The similarity of the file is usually calculated by the edit distance, such as Levenshtein Distance edit distance algorithm[19], edit distance algorithm, which refers to the minimum number of edits (increase, delete, and insert) required to convert a string A into a string B . The algorithm is as
follows:
Algorithm 1: Similar Distance Algorithm Input: string str1, string str2
Output: Edit distance d
(1) if(str1.length==0) return str2.length; //The length of str1 or str2 is 0 to return the length of another string
(2) if(str2.length==0) return str1.length;
(3) d = array[n+1, m+1] // Initialize the matrix d of (n+1)*(m+1), and let the value of the first row and column increase from 0;
(4) Scan two strings (n*m level), if str1[i]==str2[j], temp=0, otherwise temp=1. Then the matrix d[i,j] takes the minimum of d[i-1,j]+1, d[i,j-1]+1, d[i-1,j-1]+temp;
(
)
(
)
( )
( )
(
len a len b)
b a lev b
a
similarity ab
, max , 1 , , − = (1)
This method is easy to implement, but the source code file analyzed in this system, the main feature is that they all have the same function, the system needs to achieve a collection of similar code files, using the above methods need to compare the similarity of two files and then reclassify, and there is a problem that the amount of calculation increases exponentially with the number of files, so it is necessary to use an improved method to calculate.
In this study, a similar duplicate code file detection method is proposed. First, calculate the comparison similarity between two files and construct a similar distance matrix. Then, convert the matrix into frequent itemsets with similar distance, by using frequent itemset to find the list of similar files. The specific principle is to use algorithm 1 similarity distance algorithm to calculate the similarity degree that belonging to the same set, and build a similar distance matrix. where the row
icolumn j
is the file edit distance between the code file and the file set. So the value in the matrix is Vij=leb ( i, j). After this matrix is obtained, frequent itemsets can be constructed for further processing. By constructing and numbering each file, get items consisting of edit distances and file numbers, like (Vij,Ij). Therefore, the transaction set converted by the file i is Ti, so we can obtain
that, T1is consisted by (I1,V11), (I2,V12), …(IK,V 1K)
, T2 is consisted by (I1,V21) ,(I2,V22) ,… )
,
(IK V2K , and Ti =
{
(
Vi1,I1) (
, Vi2,I2)
,…,(
Vik,Ik)
}
.
Where k∈the total number of files, Ik is the file number. The obtained item sets still contain too
much information, and if the number of documents is large, the Ti collection will be very
complicated, so it is necessary to optimize the computational complexity and efficiency. Let C be the
interception threshold of the irrelevant item, then the value of C is:
k k V C k i k j ij × =
∑ ∑
=1 =1
(2) First of all, we need to sort each row of data according to the edit distance. After sorting, we need to traverse every row by using formula 2 to intercept the document with a short edit distance so as to form a frequent item set. Through this set, a project collection I can be constructed. Set I contains comparison data where all the two files are compared with each other and the shortest edit distance is less than C . The set that compares each file with the shortest edit distance of other files is regarded as
a transaction T , and all transactions make up a transaction set D.The characteristic of these transactions is that if two items exist in one transaction, the two items are similar, and if the number of times between the items appearing in transactions is more, these projects can be regarded as similar sets. Therefore, this problem can be solved by using frequent pattern mining methods. By introducing an association rule algorithm to find all the similar item sets, then the code files with high similarity can be detected. The two criteria of association rules are support degree and confidence degree, and the support degree calculation formula is as follows:
( )
X{
t TTX t}
Support = ∈ ; ∈
(3) The formula for calculating confidence degree is as follows:
(
)
(
)
( )
X Support Y X Support Y XConfidence ⇒ = ∪
is to remove redundant items by using formula 2 before calculating frequent itemsets according to a specific threshold. The algorithm is shown as follows:
Algorithm 2: Repeated Code Detection Algorithm
Input: code file collection C, minimum support SUPPORT Output: similar file collection S
(1) Calculate the similarity between the file c and other files respectively, and save the result in a two-dimensional array.
TempS = [] for c in C:
C’ {C-c} // Take all file sets without file c sarray = calculate_similarity(c, C’)
TempS.append(sarray) //
(2) Intercept high edit distance data and construct transaction set. I = filter_transaction(Temps )
(3) Traverse each column in the transaction set, invert the item and transaction number. {item: TID_set}
for t in T: for item in t.items: if item not in data: data[item] = [] data[item].add(t.tid)
temp_data = reverse_sort(data.items()) S = []
call step4(S, temp_data) //Call the function defined in step 4
(4) Receive parameter frequent itemsets S and lists temp _data , and obtain the K+1 item set by finding the intersection of the frequent K set of items.
t,ids = temp_data.pop() // take a row from the queue if len(ids) >= SUPPORT:
S += t TS = []
for i, tids in items: nids = ids & tids
if len(nids) >= SUPPORT: TS.append((i, nids))
call step4(S, sort(TS)) //Recursive call step4
(5) Intercept the collection that contains most of the transaction items. remove_set = []
for i=0; i<=len(S); i++: for c in S[i+1, ]: if S[i] in c or c in S[i]:
remove_set.append(len(S[i]) >= len(c) ? c:S[i]) continue
S = S - remove_set Return similar result set S
Experimental Test
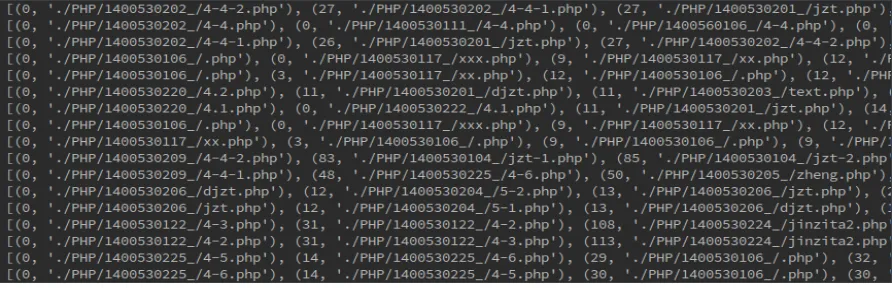
[image:5.612.81.538.168.485.2]Using the above-mentioned source code file to analysis, the total number of files is 296, all of them are PHP code files, including different function implementations. Before the test, the similar code is annotated and saved in file information by artificial way. The experimental platform is Intel Core i7-6770HQ processor, 16G DDR4-2133 memory, and a Linux 64-bit system, and Python programming language is used to write test program. Analysis by applying the duplicate code model of this study, we first construct the similarity matrix as shown in figure 1.
Figure 1. Similarity distance matrix (partial).
After constructing the matrix, convert the similarity distance into a transaction set, and extract the set with the file number 1 as shown in the following code:
T1: [(1, 0), (2, 86), (3, 27), (4, 40), (5, 45), (6, 35), (7, 28), (8, 40), (9, 45), (10, 122), (11, 62), (12, 53), (13, 56), (14, 141), (15, 149), (16, 56), (17, 54), (18, 84), (19, 69), (20, 83), (21, 50), (22, 48), (23, 84), (24, 84), (25, 70), (26, 69), (27, 53), (28, 55), (29, 242), (30, 232), (31, 60), (32, 58), (33, 28), (34, 34), (35, 27), (36, 89), (37, 91), (38, 79), (39, 93), (40, 33), (41, 93), (42, 361), (43, 31), (44, 181), (45, 56), (46, 74), (47, 211), (48, 145), (49, 51), (50, 52), (51, 28), (52, 34), (53, 175), (54, 170), (55, 86), (56, 48), (57, 48), (58, 59), (59, 86), (60, 86), (61, 113), (62, 79), (63, 79), (64, 95), (65, 123), (66, 228), (67, 226), (68, 86), (69, 49), (70, 87), (71, 62), (72, 64), (73, 86), (74, 42), (75, 59), (76, 32), (77, 86), (78, 35), (79, 381), (80, 379), (81, 86), (82, 84), (83, 84), (84, 46), (85, 56), (86, 34), (87, 34), (88, 64), (89, 62), (90, 76), (91, 91), (92, 91), (93, 69), (94, 65), (95, 86), (96, 84), (97, 72), (98, 43), (99, 44), (100, 74), (101, 69), (102, 81), (103, 189), (104, 202), (105, 95), (106, 123), (107, 95), (108, 75)]
Figure 2. Sorted file data collection.
[image:6.612.87.524.265.436.2]In the following process, the detection model uses formula 3 to simplify the file data information, and the streamlined file data set is shown in Figure 3.
Figure 3. Reduced file data collection.
Convert the above file data set into a transaction item set, take the experimental data as an example, and intercept a number of previous transactions we can see the relevant information:
T1: [1, 24, 34, 46, 59, 65, 81, 17, 62, 97]
T2: [2, 25, 43, 47, 49, 57, 60, 66, 71, 82, 85, 18, 38, 69] T3: [3, 35, 58, 61, 68, 80, 83, 19, 50, 75]
T4: [4, 14, 30, 8]
T5: [5, 29, 15, 44, 79, 89, 91, 9, 52] T6: [6, 16, 92, 11, 53]
T7: [7, 20, 31, 54] T8: [8, 51, 14, 30, 4]
T9: [9, 52, 5, 29, 15, 44, 79, 89, 91]
[image:6.612.136.474.660.734.2]Currently, frequent itemsets mining algorithms also have Apriori and Fp-growth. Through experimental tests the research compared the frequent item sets mining method proposed in this paper. Using the above data set to test and calculate the running time cost under different support degrees, and get the comparison results, as shown in Table 1.
Table 1. Algorithm comparison.
Support(%) 0.1 0.5 0.7
Apriori 128.1 2.35 1.66
Fp-growth 96.3 0.71 0.25
After comparing and testing the algorithms, the time efficiency of Eclat's algorithm is higher than Apriori and Fp-growth. Because each transaction contains fewer items, the Eclat method based on the backset algorithm reflects its efficiency, it is more applicable to the data set of this study, the calculation speed is faster and takes less time. Finally, by applying the frequent itemset mining algorithm to process, the minimum support degree set is 3. Finally, the following calculation results (part) can be obtained:
['1', '24', '34', '46', '59', '65', '81'] : 3 ['37', '45', '56', '70', '90'] : 3 ['20', '54', '7'] : 3
['14', '30', '8'] : 3 ['41', '62', '73', '97'] : 3
['15', '29', '44', '5', '79', '89', '9', '91'] : 3 ['11', '16', '53', '92'] : 4
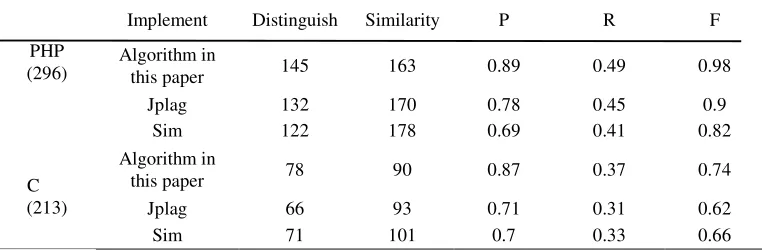
[image:7.612.115.496.343.468.2]From the results, we can see that each line is a code set with a very high degree of similarity, and can efficiently and clearly separate highly similar code sets. The algorithm framework of this paper is compared with the existing similarity detection tools Jplag and Sim,The two programs used for comparison use the default similarity threshold. In addition, 213 copies of code files for C program design were collected and sorted, by the way of labeling, and three different programs were also tested and compared in order to test the detection effect. Through the data items that have been labeled, the accuracy rate, recall rate, and F value are calculated, and the obtained data is shown in Table 2 below.
Table 2. Comparison of test results.
Implement Distinguish Similarity P R F
PHP (296)
Algorithm in
this paper 145 163 0.89 0.49 0.98
Jplag 132 170 0.78 0.45 0.9
Sim 122 178 0.69 0.41 0.82
C (213)
Algorithm in
this paper 78 90 0.87 0.37 0.74
Jplag 66 93 0.71 0.31 0.62
Sim 71 101 0.7 0.33 0.66
The first two columns in the table are the number of files that identified as correct and the number of files the program judges to be similar. From the experimental results, the accuracy of the framework in this paper is slightly better than the other two detection tools. The number of similar documents detected by the two commonly used detection tools is higher than this calculation model, but the number of documents with correct identification is less than this model. Experiments show that the accuracy of this calculation model is higher than the existing two code analysis and detection tools, and it is more suitable for the application of code similarity detection on specific topics. At the same time, the marked result set is also relatively clear.
Summary
Acknowledgement
This research was financially supported by Ministry of Education Humanities and Social Science Fund Youth Project (17YJCZH074) and Guangxi Education Department General Project (KY2015YB114).
References
[1]Tian Zhenzhou, Liu Huju, Zheng Qinghua, et al, Review of research on software plagiarism detection. Journal of Information Security, 03(2016) 52-76.
[2]L. Prechelt, G. Malpohl, M. Philippsen, Finding plagiarisms among a set of programs with Jplag. Journal of Universal Computer Science, 8(2002) 1016-1038.
[3]D. Gitchell, N. Tran, SIM: A utility for detecting similarity in computer programs. In SIG -CSE technical symposium on Computer science education (SIGCSE'99), 1999, 266-270.
[4]Ďuračík M, et al, Current trends in source code analysis plagiarism detection and issues of analysis big datasets. Procedia Engineering, 192(2017) 136–141.
[5]Deng Aiping, Research on similarity measure algorithm of program code. Computer Engineering and Design, 29(2008) 4636 - 4639.
[6]Wang Xiaoying, Zang Li, Wang Xiaoqing, et al, Job matching system based on sequence matching. Computer Engineering, 38(2012) 53-56+61.
[7]Yu Haiying. Research and implementation of similarity measure of program code. Computer Engineering, 36(2010) 45-46+49.
[8]Xiong Hao, Qi Haihua, Huang Yonggang, et al, A similarity detection method based on BP neural network. Computer Science, 37(2010) 159-164.
[9]Yu Shiying, Yuan Xuemei, Lu Haitao, et al, Similarity code detection algorithm based on sequence clustering. Journal of Intelligent Systems, 8(2013) 52-57.
[10]Xu Yajing, Li Tong, Liu Yutao, Implicit Student Behavior Pattern Mining Based on Code Similarity. Computer Education, 6 (2017) 90-94.
[11]G. Cosma, G. Acampora, A fuzzy-based approach to programming language independent source - code plagiarism detection. IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul. 2015, 1-8.
[12]Cui Shuning, Wu Ning, Ye Dan, Establishing an abstract syntax tree model to assess C++ code. Computer Applications, 35(2015) 183-185+191.
[13]Liu Chenglong, Jia Shengying, Zhang Liping, et al, Research on code plagiarism detection based on AST. Computer Engineering and Design, 33(2012) 1660- 1664.
[14]Li Siyu, Code similarity detection method based on intermediate representation. Electronic Technology and Software Engineering, 19(2016) 71.
[15]Chilowicz M, Duris É, Roussel G, Viewing functions as token sequences to highlight similarities in source code. Science of Computer Programming,78( 2013) 1871–1891.
[16]Chilowicz M, Duris É, Roussel G, Finding similarities in source code through factorization. Electronic Notes in Theoretical Computer Science, 238(2009) 47–62.
[18]Yang Chao, Hybrid plagiarism detection based on multiple technologies. Computer Engineering and Applications, 52(2016) 222-227.
[19]Levenshtein V I, Binary codes capable of correcting spurious insertions and deletions of ones. Problems of Information Transmission, 1(1965) 8-17.