Tight Bounds for k -Set Agreement
Soma Chaudhuri
Maurice Herlihy
Nancy A. Lynch
Mark R. Tuttle
CRL 98/4
Cambridge Research Laboratory
The Cambridge Research Laboratory was founded in 1987 to advance the state of the art in both core computing and human-computer interaction, and to use the knowledge so gained to support the Company’s corporate objectives. We believe this is best accomplished through interconnected pur-suits in technology creation, advanced systems engineering, and business development. We are ac-tively investigating scalable computing; mobile computing; vision-based human and scene sensing; speech interaction; computer-animated synthetic persona; intelligent information appliances; and the capture, coding, storage, indexing, retrieval, decoding, and rendering of multimedia data. We recognize and embrace a technology creation model which is characterized by three major phases:
Freedom: The life blood of the Laboratory comes from the observations and imaginations of our research staff. It is here that challenging research problems are uncovered (through discussions with customers, through interactions with others in the Corporation, through other professional interac-tions, through reading, and the like) or that new ideas are born. For any such problem or idea, this phase culminates in the nucleation of a project team around a well articulated central research question and the outlining of a research plan.
Focus: Once a team is formed, we aggressively pursue the creation of new technology based on the plan. This may involve direct collaboration with other technical professionals inside and outside the Corporation. This phase culminates in the demonstrable creation of new technology which may take any of a number of forms - a journal article, a technical talk, a working prototype, a patent application, or some combination of these. The research team is typically augmented with other resident professionals—engineering and business development—who work as integral members of the core team to prepare preliminary plans for how best to leverage this new knowledge, either through internal transfer of technology or through other means.
Follow-through: We actively pursue taking the best technologies to the marketplace. For those opportunities which are not immediately transferred internally and where the team has identified a significant opportunity, the business development and engineering staff will lead early-stage com-mercial development, often in conjunction with members of the research staff. While the value to the Corporation of taking these new ideas to the market is clear, it also has a significant positive im-pact on our future research work by providing the means to understand intimately the problems and opportunities in the market and to more fully exercise our ideas and concepts in real-world settings.
Throughout this process, communicating our understanding is a critical part of what we do, and participating in the larger technical community—through the publication of refereed journal articles and the presentation of our ideas at conferences–is essential. Our technical report series supports and facilitates broad and early dissemination of our work. We welcome your feedback on its effec-tiveness.
Soma Chaudhuri
Department of Computer Science Iowa State University
Ames, IA 50011 [email protected]
Maurice Herlihy
Computer Science Department Brown University Providence, RI 02912 [email protected]
Nancy A. Lynch
MIT Lab for Computer Science 545 Technology Square Cambridge, MA 02139 [email protected]
Mark R. Tuttle
DEC Cambridge Research Lab One Kendall Square, Bldg 700
Cambridge, MA 02139 [email protected]
May 1998
Abstract
We prove tight bounds on the time needed to solve
k
-set agreement. In thisprob-lem, each processor starts with an arbitrary input value taken from a fixed set, and halts after choosing an output value. In every execution, at most
k
distinct output values may be chosen, and every processor’s output value must be some processor’s input value. We analyze this problem in a synchronous, message-passing model where processors fail by crashing. We prove a lower bound ofbf=k
c+ 1
rounds of communication forc Digital Equipment Corporation, 1998
This work may not be copied or reproduced in whole or in part for any commercial purpose. Per-mission to copy in whole or in part without payment of fee is granted for nonprofit educational and research purposes provided that all such whole or partial copies include the following: a notice that such copying is by permission of the Cambridge Research Laboratory of Digital Equipment Corpo-ration in Cambridge, Massachusetts; an acknowledgment of the authors and individual contributors to the work; and all applicable portions of the copyright notice. Copying, reproducing, or repub-lishing for any other purpose shall require a license with payment of fee to the Cambridge Research Laboratory. All rights reserved.
CRL Technical reports are available on the CRL’s web page at http://www.crl.research.digital.com.
1
Introduction
Most interesting problems in concurrent and distributed computing require processors to coordinate their actions in some way. It can also be important for protocols solv-ing these problems to tolerate processor failures, and to execute quickly. Ideally, one would like to optimize all three properties—degree of coordination, fault-tolerance, and efficiency—but in practice, of course, it is usually necessary to make tradeoffs among them. In this paper, we give a precise characterization of the tradeoffs required by studying a family of basic coordination problems called
k
-set agreement.In
k
-set agreement [Cha91], each processor starts with an arbitrary input value andhalts after choosing an output value. These output values must satisfy two conditions: each output value must be some processor’s input value, and the set of output val-ues chosen must contain at most
k
distinct values. The first condition rules out trivial solutions in which a single value is hard-wired into the protocol and chosen by all processors in all executions, and the second condition requires that the processors co-ordinate their choices to some degree. This problem is interesting because it defines a family of coordination problems of increasing difficulty. At one extreme, ifn
is the number of processors in the system, thenn
-set agreement is trivial: each processor simply chooses its own input value. At the other extreme,1
-set agreement requires that all processors choose the same output value, a problem equivalent to the consensus problem [LSP82, PSL80, FL82, FLP85, Dol82, Fis83]. Consensus is well-known to be the “hardest” problem, in the sense that all other decision problems can be reduced to it. Consensus arises in applications as diverse as on-board aircraft control [W+78], database transaction commit [BHG87], and concurrent object design [Her91]. Between these extremes, as we vary the value of
k
fromn
to1
, we gradually increase the degree of processor coordination required.We consider this family of problems in a synchronous, message-passing model with
crash failures. In this model,
n
processors communicate by sending messages over acompletely connected network. Computation in this model proceeds in a sequence of rounds. In each round, processors send messages to other processors, then receive messages sent to them in the same round, and then perform some local computation and change state. This means that all processors take steps at the same rate, and that all messages take the same amount of time to be delivered. Communication is reliable, but up to
f
processors can fail by stopping in the middle of the protocol.The primary contribution of this paper is a lower bound on the amount of time required to solve
k
-set agreement, together with a protocol fork
-set agreement that proves a matching upper bound. Specifically, we prove that any protocol solvingk
-set agreement in this model and toleratingf
failures requires bf=k
c+ 1
rounds ofcommunication in the worst case—assuming
n
f + k + 1
, meaning that there are atleast
k+1
nonfaulty processors—and we prove a matching upper bound by exhibiting a protocol that solvesk
-set agreement inbf=k
c+1
rounds. Since consensus is just1
-setagreement, our lower bound implies the well-known lower bound of
f + 1
rounds for consensus whenn
f + 2
[FL82]. More important, the running timer =
bf=k
c+ 1
2 1 INTRODUCTION
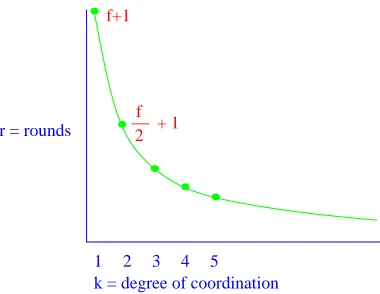
1 2 3 4 5
f+1
__ + 1f 2
[image:6.612.237.427.123.270.2]k = degree of coordination r = rounds
Figure 1: Tradeoff between rounds and degree of coordination.
in half the time needed to achieve consensus. In addition, the lower bound proof itself is interesting because of the geometric proof technique we use, combining ideas due to Chaudhuri [Cha91, Cha93], Fischer and Lynch [FL82], Herlihy and Shavit [HS93], and Dwork, Moses, and Tuttle [DM90, MT88].
In the past few years, researchers have developed powerful new tools based on classical algebraic topology for analyzing tasks in asynchronous models (e.g., [AR96, BG93, GK96, HR94, HR95, HS93, HS94, SZ93]).
The principal innovation of these papers is to model computations as simplicial complexes (rather than graphs) and to derive connections between computations and the topological properties of their complexes. This paper extends this topological ap-proach in several new ways: it is the first to derive results in the synchronous model, it derives lower bounds rather than computability results, and it uses explicit construc-tions instead of existential arguments.
Although the synchronous model makes some strong (and possibly unrealistic) as-sumptions, it is well-suited for proving lower bounds. The synchronous model is a special case of almost every realistic model of a concurrent system we can imagine, and therefore any lower bound for
k
-set agreement in this simple model translates into a lower bound in any more complex model. For example, our lower bound holds for models that permit messages to be lost, failed processors to restart, or processor speeds to vary. Moreover, our techniques may be helpful in understanding how to prove (pos-sibly) stricter lower bounds in more complex models. Naturally, our protocol fork
-set agreement in the synchronous model does not work in more general models, but it is still useful because it shows that our lower bound is the best possible in the synchronous model.2
Overview
We start with an informal overview of the ideas used in the lower bound proof. For the remainder of this paper, suppose
P
is a protocol that solvesk
-set agreement and tolerates the failure off
out ofn
processors, and supposeP
halts inr <
bf=k
c+ 1
rounds. This means that all nonfaulty processors have chosen an output value at time
r
in every execution ofP
. In addition, supposen
f + k + 1
, which means that atleast
k + 1
processors never fail. Our goal is to consider the global states that occur at timer
in executions ofP
, and to show that in one of these states there arek + 1
pro-cessors that have chosenk + 1
distinct values, violatingk
-set agreement. Our strategy is to consider the local states of processors that occur at timer
in executions ofP
, and to investigate the combinations of these local states that occur in global states. This investigation depends on the construction of a geometric object. In this section, we use a simplified version of this object to illustrate the general ideas in our proof.Since consensus is a special case of
k
-set agreement, it is helpful to review the stan-dard proof of thef +1
round lower bound for consensus [FL82, DS83, Mer85, DM90] to see why new ideas are needed fork
-set agreement. Suppose that the protocolP
is a consensus protocol, which means that in all executions ofP
all nonfaulty processors have chosen the same output value at timer
. Two global statesg
1andg
2at timer
aresaid to be similar if some nonfaulty processor
p
has the same local state in both global states. The crucial property of similarity is that the decision value of any processor in one global state completely determines the decision value for any processor in all similar global states. For example, if all processors decidev
ing
1, then certainlyp
de-cides
v
ing
1. Sincep
has the same local state ing
1andg
2, and sincep
’s decision valueis a function of its local state, processor
p
also decidesv
ing
2. Since all processorsagree with
p
ing
2, all processors decidev
ing
2, and it follows that the decision valuein
g
1determines the decision value ing
2. A similarity chain is a sequence of globalstates,
g
1:::g`
, such thatgi
is similar togi
+1. A simple inductive argument showsthat the decision value in
g
1determines the decision value ing`
. The lower bound proofconsists of showing that all time
r
global states ofP
lie on a single similarity chain. It follows that all processors choose the same value in all executions ofP
, independent of the input values, violating the definition of consensus.The problem with
k
-set agreement is that the decision values in one global state do not determine the decision values in similar global states. Ifp
has the same local state ing
1 andg
2, thenp
must choose the same value in both states, but the values chosenby the other processors are not determined. Even if
n
;1
processors have the samelocal state in
g
1andg
2, the decision value of the last processor is still not determined.The fundamental insight in this paper is that
k
-set agreement requires considering all “degrees” of similarity at once, focusing on the number and identity of local states common to two global states. While this seems difficult—if not impossible—to do us-ing conventional graph theoretic techniques like similarity chains, there is a geometric generalization of similarity chains that provides a compact way of capturing all degrees of similarity simultaneously, and it is the basis of our proof.4 2 OVERVIEW
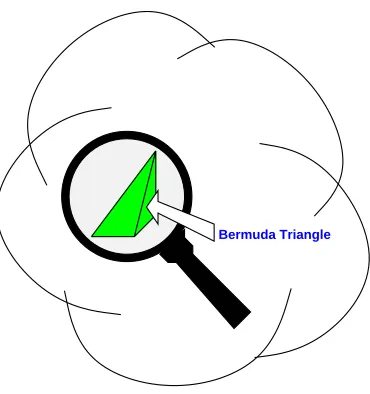
Bermuda Triangle
Figure 3: Global states for an
r
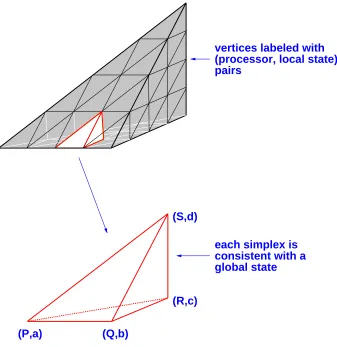
-round protocol (showing the embedded Bermuda Tri-angle).is a solid tetrahedron. We can represent a global state for an
n
-processor protocol as an(n
;1)
-dimensional simplex [Cha93, HS93], where each vertex is labeled with aprocessor id and local state. If
g
1 andg
2are global states in whichp
1has the samelocal state, then we “glue together” the vertices of
g
1andg
2labeled withp
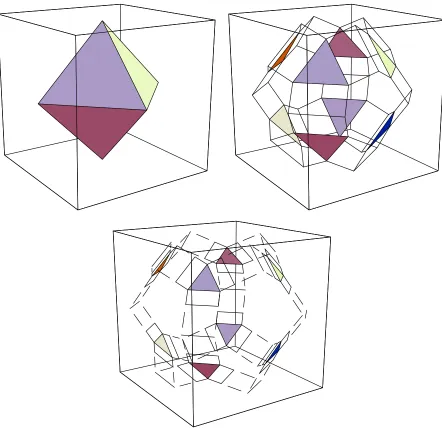
1. Figure 2shows how these global states glue together in a simple protocol in which each of three processors repeatedly sends its state to the others. Each process begins with a binary input. The first picture shows the possible global states after zero rounds: since no communication has occurred, each processor’s state consists only of its input. It is easy to check that the simplices corresponding to these global states form an octahedron. The next picture shows the complex after one round. Each triangle corresponds to a failure-free execution, each free-standing edge to a single-failure execution, and so on. The third picture shows the possible global states after three rounds.
The set of global states after an
r
-round protocol is quite complicated (Figure 3), but it contains a well-behaved subset of global states which we call the BermudaTrian-gle
B
, since all fast protocols vanish somewhere in its interior. The Bermuda Triangle (Figure 4) is constructed by starting with a largek
-dimensional simplex, andtriangu-lating it into a collection of smaller
k
-dimensional simplexes. We then label each vertex with an ordered pair(ps)
consisting of a processor identifierp
and a local states
in such a way that for each simplexT
in the triangulation there is a global stateg
con-sistent with the labeling of the simplex: for each ordered pair(ps)
labeling a corner ofT
, processorp
has local states
in global stateg
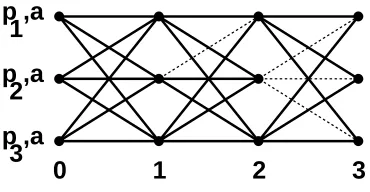
.6 2 OVERVIEW
(P,a)
(Q,b)
(R,c)
(S,d)
each simplex is
consistent with a
global state
[image:10.612.164.501.210.557.2]vertices labeled with
(processor, local state)
pairs
ccccc
cccc?
ccccb
ccc?b
cc?bb
ccbbb c?bbb
cbbbb cccbb
?bbbb
bbbbb cccc?
cccca
ccc?a
cccaa
cc?aa
ccaaa
c?aaa
caaaa
?aaaa
aaaaa ?aaaa
baaaab?aaabbaaabb?aabbbaabbb?abbbbabbbb?
cccaa
bbbaa bb?aa
cc?aa
?bbaa cbbaa c?baa ccbaa cc?aa
[image:11.612.108.451.98.352.2]?b?aa cb?aa c??aa cc?aa
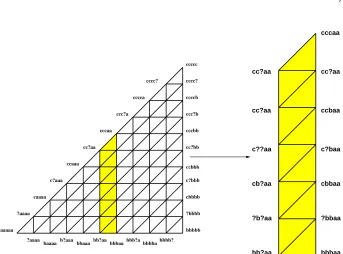
Figure 5: The Bermuda Triangle for 5 processors and a 1-round protocol for 2-set agreement.
a protocol
P
for5
processors solving2
-set agreement in1
round. We have labeled grid points with local states, but we have omitted processor ids and many intermediate nodes for clarity. The local states in the figure are represented by expressions such asbb?aa
. Given3
distinct input valuesabc
, we writebb?aa
to denote the local state of a processorp
at the end of a round in which the first two processors have input valueb
and send messages top
, the middle processor fails to send a message top
, and the last two processors have input valuea
and send messages top
. In Figure 5, following any horizontal line from left to right acrossB
, the input values are changed froma
tob
. The input value of each processor is changed—one after another—by first silencing the processor, and then reviving the processor with the input valueb
. Similarly, moving along any vertical line from bottom to top, processors’ input values change fromb
toc
. The complete labeling of the Bermuda TriangleB
shown in Figure 5—which would include processor ids—has the following property. Let(ps)
be the label of a grid pointx
. Ifx
is a corner ofB
, thens
specifies that each processor starts with the same input value, sop
must choose this value if it finishes protocolP
in local states
. Ifx
is on an edge ofB
, thens
specifies that each processor starts with one of the two input values labeling the ends of the edge, sop
must choose one of these values if it halts in states
. Similarly, ifx
is in the interior ofB
, thens
specifies that each processor starts with one of the three values labeling the corners ofB
, sop
must choose one of these three values if it halts in states
.8 2 OVERVIEW
Figure 6: Sperner’s Lemma.
at the end of
P
. This coloring ofB
has the property that the color of each of the cor-ners is determined uniquely, the color of each point on an edge between two corcor-ners is forced to be the color of one of the corners, and the color of each interior point can be the color of any corner. Colorings with this property are called Sperner colorings, and have been studied extensively in the field of algebraic topology. At this point, we ex-ploit a remarkable combinatorial result first proved in 1928: Sperner’s Lemma [Spa66, p.151] states that any Sperner coloring of any triangulatedk
-dimensional simplex must include at least one simplex whose corners are colored with allk + 1
colors. In our case, however, this simplex corresponds to a global state in whichk + 1
processors choosek+1
distinct values, which contradicts the definition ofk
-set agreement. Thus, in the case illustrated above, there is no protocol for2
-set agreement halting in1
round. We note that the basic structure of the Bermuda Triangle and the idea of coloring the vertices with decision values and applying Sperner’s Lemma have appeared in previous work by Chaudhuri [Cha91, Cha93]. In that work, she also proved a lower bound ofbf=k
c+ 1
rounds fork
-set agreement, but for a very restricted class of protocols.In particular, a protocol’s decision function can depend only on vectors giving partial information about which processors started with which input values, but cannot depend on any other information in a processor’s local state, such as processor identities or message histories. The technical challenge in this paper is to construct a labeling of vertices with processor ids and local states that will allow us to prove a lower bound for
k
-set agreement for arbitrary protocols.a long sequence of global states that begins with a global state in which all processors start with
a
, ends with a global state in which all processors start withb
, and in between systematically changes input values froma
tob
. These changes are made so gradually, however, that for any two adjacent global states in the sequence, at most one processor can distinguish them. Second, we label each remaining point using a combination of the global states on the edges. Third, we assign nonfaulty processors to points in such a way that the processor labeling a point has the same local state in the global states labeling all adjacent points. Finally, we project each global state onto the associated nonfaulty processor’s local state, and label the point with the resulting processor-state pair.3
The Model
We use a synchronous, message-passing model with crash failures. The system con-sists of
n
processors,p
1:::pn
. Processors share a global clock that starts at0
andadvances in increments of
1
. Computation proceeds in a sequence of rounds, with roundr
lasting from timer
;1
to timer
. Computation in a round consists of threephases: first each processor
p
sends messages to some of the processors in the sys-tem, possibly including itself, then it receives the messages sent to it during the round, and finally it performs some local computation and changes state. We assume that the communication network is totally connected: every processor is able to send distinct messages to every other processor in every round. We also assume that communication is reliable (although processors can fail): ifp
sends a message toq
in roundr
, then the message is delivered toq
in roundr
.Processors follow a deterministic protocol that determines what messages a pro-cessor should send and what output a propro-cessor should generate. A protocol has two components: a message component that maps a processor’s local state to the list of messages it should send in the next round, and an output component that maps a pro-cessor’s local state to the output value (if any) that it should choose. Processors can be faulty, however, and any processor
p
can simply stop in any roundr
. In this case, pro-cessorp
follows its protocol and sends all messages the protocol requires in rounds 1 throughr
;1
, sends some subset of the messages it is required to send in roundr
, andsends no messages in rounds after
r
. We say thatp
is silent from roundr
ifp
sends no messages in roundr
or later. We say thatp
is active through roundr
ifp
sends all messages in roundr
and earlier.A full-information protocol is one in which every processor broadcasts its en-tire local state to every processor, including itself, in every round [PSL80, FL82, Had83]. One nice property of full-information protocols is that every execution of a full-information protocol
P
has a compact representation called a communicationgraph [MT88]. The communication graphGfor an
r
-round execution ofP
is atwo-dimensional two-colored graph. The vertices form an
n
r
grid, with processornames
1
throughn
labeling the vertical axis and times0
throughr
labeling the hor-izontal axis. The node representing processorp
at timei
is labeled with the pairhpi
i.Given any pair of processors
p
andq
and any roundi
, there is an edge betweenhpi
;1
i10 3 THE MODEL
0
1
2
3
red
green
1
p ,a
2
p ,a
[image:14.612.162.347.129.225.2]3
p ,a
Figure 7: A three-round communication graph.
round
i
: the edge is green ifp
succeeds, and red otherwise. In addition, each nodehp0
iis labeled with
p
’s input value. Figure 7 illustrates a three round communication graph. In this figure, green edges are denoted by solid lines and red edges by dashed lines. We refer to the edge betweenhpi
;1
iandhqi
ias the roundi
edge fromp
toq
, andwe refer to the nodeh
pi
;1
ias the roundi
node forp
since it represents the pointat which
p
sends its roundi
messages. We define what it means for a processor to besilent or active in terms of communication graphs in the obvious way.
In the crash failure model, a processor is silent in all rounds following the round in which it stops. This means that all communication graphs representing executions in this model have the property that if a round
i
edge fromp
is red, then all roundj
i+1
edges from
p
are red, which means thatp
is silent from roundi+1
. We assume that all communication graphs in this paper have this property, and we note that everyr
-round graph with this property corresponds to anr
-round execution ofP
.Since a communication graphG describes an execution of
P
, it also determinesthe global state at the end of
P
, so we sometimes refer toGas a globalcommunica-tion graph. In addicommunica-tion, for each processor
p
and timet
, there is a subgraph ofGthatcorresponds to the local state of
p
at the end roundt
, and we refer to this subgraph as a local communication graph. The local communication graph forp
at timet
is the subgraphG(pt)
ofGcontaining all the information visible top
at the end of roundt
.Namely,G
(pt)
is the subgraph induced by the nodehpt
iand all earlier nodesreach-able fromh
pt
iby a sequence (directed backwards in time) of green edges followed byat most one red edge. In the remainder of this paper, we use graphs to represent states. Wherever we used “state” in the informal overview of Section 2, we now substitute the word “graph.” Furthermore, we defined a full-information protocol to be a protocol in which processors broadcast their local states in every round, but we now assume that processors broadcast their local communication graphs instead. In addition, we assume that all executions of a full-information protocol run for exactly
r
rounds and produce output at exactly timer
. All local and global communication graphs are graphs at timer
, unless otherwise specified.The crucial property of a full-information protocol is that every protocol can be simulated by a full-information protocol, and hence that we can restrict attention to full-information protocols when proving the lower bound in this paper:
fail-ures in
r
rounds, then there is ann
-processor full-information protocol solvingk
-set agreement withf
failures inr
rounds.4
The
k-set Agreement Problem
The
k
-set agreement problem [Cha91] is defined as follows. We assume that eachprocessor
pi
has two private registers in its local state, a read-only input register and a write-only output register. Initially,pi
’s input register contains an arbitrary input value from a setV
containing at leastk+1
valuesv
0:::vk
, and its output register is empty.A protocol solves the problem if it causes each processor to halt after writing an output value to its output register in such a way that
1. every processor’s output value is some processor’s input value, and
2. the set of output values chosen has size at most
k
.5
Bermuda Triangle
In this section, we define the basic geometric constructs used in our proof that every protocol
P
solvingk
-set agreement and toleratingf
failures requires at leastbf=k
c+1
rounds of communication, assuming
n
f + k + 1:
We start with some preliminary definitions. A simplex
S
is the convex hull ofk + 1
affinely-independent1 pointsx
0
:::xk
in Euclidean space. It is ak
-dimensionalvolume, the
k
-dimensional analogue of a solid triangle or tetrahedron. The pointsx
0:::xk
are called the vertices ofS
, andk
is the dimension ofS
. We sometimescall
S
ak
-simplex when we wish to emphasize its dimension. A simplexF
is a faceof
S
if the vertices ofF
form a subset of the vertices ofS
(which means that the di-mension ofF
is at most the dimension ofS
). A set ofk
-simplexesS
1:::S`
is atriangulation of
S
ifS = S
1S`
and the intersection ofSi
andSj
is a face ofeach2for all pairs
i
andj
. The vertices of a triangulation are the vertices of theS
i
. Anytriangulation of
S
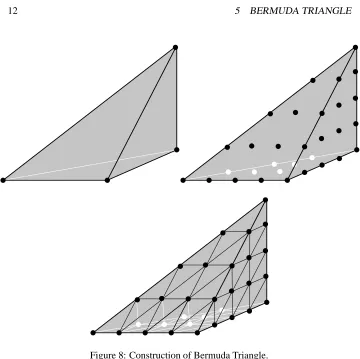
induces triangulations of its faces in the obvious way.The construction of the Bermuda Triangle is illustrated in Figure 8. LetBbe the
k
-simplex in
k
-dimensional Euclidean space with vertices(0:::0)(N0:::0)(NN0:::0):::(N:::N)
where
N
is a huge integer defined later in Section 6.3. The Bermuda TriangleB
is a triangulation ofBdefined as follows. The vertices ofB
are the grid points containedinB: these are the points of the form
x = (x
1
:::xk)
, where thexi
are integersbetween
0
andN
satisfyingx
1x
2
xk
.Informally, the simplexes of the triangulation are defined as follows: pick any grid point and walk one step in the positive direction along each dimension (Figure 9).
1Points
x 0
::: x
kare affinely independent if x
1 ;x
0 ::: x
k ;x
0are linearly independent.
2Notice that the intersection of two arbitrary
k-dimensional simplexesS iand
S
12 5 BERMUDA TRIANGLE
Figure 8: Construction of Bermuda Triangle.
[image:16.612.163.507.465.647.2]The
k + 1
points visited by this walk define the vertices of a simplex, and the trian-gulationB
consists of all simplexes determined by such walks. For example, the 2-dimensional Bermuda Triangle is illustrated in Figure 5. This triangulation, known asKuhn’s triangulation, is defined formally as follows [Cha93]. Let
e
1:::ek
be theunit vectors; that is,
ei
is the vector(0:::1:::0)
with a single 1 in thei
th coordi-nate. A simplex is determined by a pointy
0and an arbitrary permutationf
1:::fk
ofthe unit vectors
e
1:::ek
: the vertices of the simplex are the pointsy
i
=
yi
;1+
fi
for all
i > 0
. When we list the vertices of a simplex, we always write them in the ordery
0:::yk
in which they are visited by the walk.For brevity, we refer to the vertices ofBas the corners of
B
. The “edges” ofBarepartitioned to form the edges of
B
. More formally, the triangulationB
induces triangu-lations of the one-dimensional faces (line segments connecting the vertices) ofB, andthese induced triangulations are called the edges of
B
. The simplexes ofB
are calledprimitive simplexes.
Each vertex of
B
is labeled with an ordered pair(p
L)
consisting of a processor idp
and a local communication graphL. As illustrated in the overview in Section 2, the
cru-cial property of this labeling is that if
S
is a primitive simplex with verticesy
0:::yk
,and if each vertex
yi
is labeled with a pair(qi
Li)
, then there is a globalcommunica-tion graphGsuch that each
qi
is nonfaulty inGand has local communication graphLi
inG. Constructing this labeling is the subject of the next three sections. We first assign
global communication graphsGto vertices in Section 6, then we assign processors
p
tovertices in Section 7, and then we assign ordered pairs
(p
L)
to vertices in Section 8,whereLis the local communication graph of
p
inG.6
Graph Assignment
In this section, we label each vertex of
B
with a global communication graph. Actually, for expository reasons, we augment the definition of a communication graph and label vertices ofB
with these augmented communication graphs instead. Constructing this labeling involves several steps. We define operations on augmented communication graphs that make minor changes in the graphs, and we use these operations to construct long sequences of graphs. Then we label vertices along edges ofB
with graphs from these sequences, and we label interior vertices ofB
by performing a merge of the graphs labeling the edges.6.1
Augmented Communication Graphs
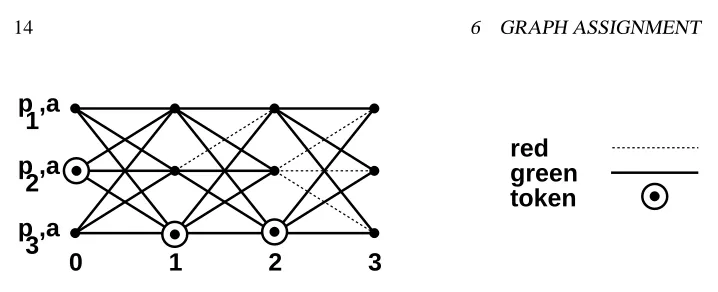
We extend the definition of a communication graph to make the processor assignment in Section 7 easier to describe. We augment communication graphs with tokens, and place tokens on the graph so that if processor
p
fails in roundi
, then there is a token on the nodehpj
;1
ifor processorp
in some earlier roundj
i
(Figure 10). In this14 6 GRAPH ASSIGNMENT
0
1
2
3
red
green
token
1
p ,a
2
p ,a
[image:18.612.154.513.83.229.2]3
p ,a
Figure 10: Three-round communication graph with one token per round.
in adjacent graphs change in a orderly fashion. For every value of
`
, we define graphs with exactly`
tokens placed on nodes in each round, but we will be most interested in the two cases with`
equal to1
andk
.For each value
` > 0
, we define an`
-graphGto be a communication graph withtokens placed on the nodes of the graph that satisfies the following conditions for each round
i
,1
i
r
:1. The total number of tokens on round
i
nodes is exactly`
.2. If a round
i
edge fromp
is red, then there is a token on a roundj
i
node forp
.3. If a round
i
edge fromp
is red, thenp
is silent from roundi + 1
.We say that
p
is covered by a roundi
token if there is a token on the roundi
node forp
, we say thatp
is covered in roundi
ifp
is covered by a roundj
i
token, and wesay that
p
is covered in a graph ifp
is covered in any round. Similarly, we say that a roundi
edge fromp
is covered ifp
is covered in roundi
. The second condition says every red edge is covered by a token, and this together with the first condition implies that at most`r
processors fail in an`
-graph. We often refer to an`
-graph as a graph when the value of`
is clear from context or unimportant. We emphasize that the tokens are simply an accounting trick, and have no meaning as part of the global or local state in the underlying communication graph.We define a failure-free
`
-graph to be an`
-graph in which all edges are green, and all roundi
tokens are on processorp
1in all roundsi
.6.2
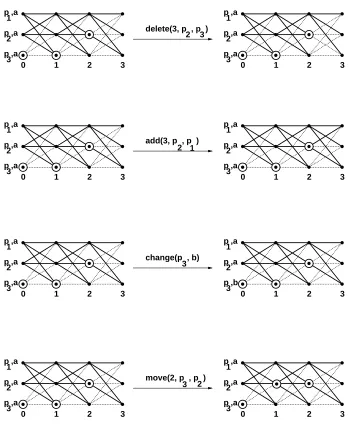
Graph operations
We now define four operations on augmented graphs that make only minor changes to a graph. In particular, the only change an operation makes is to change the color of a single edge, to change the value of a single processor’s input, or to move a single token between adjacent processors within the same round. The operations are defined as follows (see Figure 11):
0 1 2 3 2 p ,a 3 p ,a 1 p ,a
delete(3, p , p )
2 3
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
add(3, p , p )
2 1
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
0 1 2 3
2 p ,a 3 p ,b 1 p ,a
change(p , b) 3
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
0 1 2 3
2 p ,a 3 p ,a 1 p ,a
[image:19.612.105.454.174.604.2]move(2, p , p ) 2 3
16 6 GRAPH ASSIGNMENT
round
i
message fromp
toq
unsuccessful. It can only be applied to a graph ifp
andq
are silent from roundi + 1
, andp
is covered in roundi
.2. add
(ipq)
: This operation changes the color of the roundi
edge fromp
toq
to green, and has no effect if the edge is already green. This makes the delivery of the roundi
message fromp
toq
successful. It can only be applied to a graph ifp
andq
are silent from roundi+1
, processorp
is active through roundi
;1
, andp
is covered in round
i
.3. change
(pv)
: This operation changes the input value for processorp
tov
, and has no effect if the value is alreadyv
. It can only be applied to a graph ifp
is silent from round1
, andp
is covered in round1
.4. move
(ipq)
: This operation moves a roundi
token fromhpi
;1
itohqi
;1
i,and is defined only for adjacent processors
p
andq
(that is,fpq
g=
fp
j
p
j
+1g
for some
j
). It can only be applied to a graph ifp
is covered by a roundi
token, and all red edges are covered by other tokens.It is obvious from the definition of these operations that they preserve the property of being an
`
-graph: ifGis an`
-graph and is a graph operation, then(
G)
is an`
-graph.We define delete, add, and change operations on communication graphs in exactly the same way, except that the condition “
p
is covered in roundi
” is omitted.6.3
Graph sequences
We now define a sequence
v]
of graph operations that can be applied to any failure-free graph G to transform it into the failure-free graphGv]
in which all processorshave input
v
. We want to emphasize that the sequencesv]
differ only in the valuev
. For this reason, we define a parameterized sequenceV]
with the property that for all valuesv
and all graphsG, the sequencev]
transformsGtoGv]
. In general, we definea parameterized sequence
X1:::
X`
]
to be a sequence of graph operations with freevariablesX1
:::
X`
appearing as parameters to the graph operations in the sequence.Given a graphG, let red
(
Gpm)
and green(
Gpm)
be graphs identical toGex-cept that all edges from
p
in roundsm:::r
are red and green, respectively. We define these graphs only if1.
p
is covered in roundm
inG,2. all faulty processors are silent from round
m
(or earlier) inG, and3. and all tokens are on
p
1in roundsm + 1:::r
in G.In addition, we define the graph green
(
Gpm)
only if4.
p
is active through roundm
;1
inG.These restrictions guarantee that ifGis an
`
-graph and red(
Gpm)
and green(
Gpm)
In the case of ordinary communication graphs, a result by Moses and Tuttle [MT88] implies that there is a “similarity chain” of graphs betweenGand red
(
Gpm)
andbe-tweenGand green
(
Gpm)
. In their proof—a refinement of similar proofs by Dworkand Moses [DM90] and others—the sequence of graphs they construct has the property that each graph in the chain can be obtained from the preceding graph by applying a sequence of the add, delete, and change graph operations defined above. The same proof works for augmented communication graphs, provided we insert move opera-tions between the add, delete, and change operaopera-tions to move tokens between nodes appropriately. With this modification, we can prove the following. Let faulty
(
G)
be theset of processors that fail inG.
Lemma 2: For every processor
p
, roundm
, and set of processors, there are se-quences silence(pm)
and revive(pm)
such that for all graphsG:1. If red
(
Gpm)
is defined and=
faulty(
G)
, thensilence
(pm)(
G) =
red(
Gpm):
2. If green
(
Gpm)
is defined and=
faulty(
G)
, thenrevive
(pm)(
G) =
green(
Gpm):
Proof: We proceed by reverse induction on
m
. Supposem = r
. Definesilence
(pr) =
delete(rpp
1)
delete
(rppn
)
revive
(pr) =
add(rpp
1)
add
(rppn):
For part 1, let G be any graph and suppose red
(
Gpr)
is defined. For eachi
with0
i
n
, letGi
be the graph identical toG except that the roundr
edges fromp
to
p
1:::pi
are red. Since red(
G
pr)
is defined, condition 1 implies thatp
is coveredin round
r
inG. For eachi
with1
i
n
, it follows thatGi
;1 is really a graph,
and delete
(rppi)
can be applied to Gi
;1 and transforms it to
G
i
. Since G=
G 0andG
n
=
red(
Gpr)
, it follows that silence(pr)
transformsGto red(
Gpr)
. Forpart 2, letGbe any graph and suppose green
(
Gpr)
is defined. The proof of this partis the direct analogue of the proof of part 1. The only difference is that since we are coloring round
r
edges fromp
green instead of red, we must verify thatp
is active through roundr
;1
inG, but this follows immediately from condition 4.Suppose
m < r
and the induction hypothesis holds form+1
. Define0=
fp
gand define
set
(m + 1pi) =
move(m + 1p
1p
2)
move
(m + 1pi
;1pi)
reset
(m + 1p
i
) =
move(m + 1p
i
p
i
;1)
move
(m + 1p
2p
1):
The set function moves the token from
p
1topi
and the reset function moves the token18 6 GRAPH ASSIGNMENT
Define block
(mpp
i
)
to be delete(mpp
i
)
ifp
i
2 0, and otherwise
set
(m + 1pi)
silence
0(pim + 1)
delete(mppi)
revive0f
p
ig(pim + 1)
reset
(m + 1pi):
Define unblock
(mpp
i
)
to be add(mpp
i
)
ifp
i
2 0, and otherwise
set
(m + 1pi)
silence
0(pim + 1)
add(mppi)
revive0f
p
ig(pim + 1)
reset
(m + 1pi):
Finally, define
block
(mp) =
block(mpp
1)
block
(mppn)
unblock
(mp) =
unblock(mpp
1)
unblock
(mpp
n
)
and define
silence
(pm) =
silence(pm + 1)
block(mp)
revive
(pm) =
silence(pm + 1)
unblock(mp)
revive0(pm + 1):
For part 1, let G be any graph, and suppose red
(
Gpm)
is defined and=
faulty
(
G)
. Since red(
Gpm)
is defined, the graph red(
Gpm + 1)
is also defined,and the induction hypothesis for
m + 1
states that silence(pm + 1)
transformsGto red
(
Gpm + 1)
. We now show that block(mp)
transforms red(
Gpm + 1)
to red
(
Gpm)
, and we will be done. For eachi
with0
i
n
, let Gi
be thegraph identical toG except that
p
is silent from roundm + 1
and the edges fromp
to
p
1:::pi
are red inG
i
. Since red(
Gpm)
is defined, condition 1 implies thatp
iscovered in round
m
inG. For eachi
with0
i
n
, it follows thatGi
really is a graphand that
0=
faulty
(
Gi
)
. Since red(
Gpm + 1) =
G 0andG
n
=
red(
Gpm)
, it isenough to show that block
(mpp
i
)
transformsGi
;1toG
i
for eachi
with1
i
n
.The proof of this fact depends on whether
p
i
2 0, so we consider two cases. Consider the easy case with
pi
20
. We know that
p
is covered in roundm
inGi
;1since it is covered inGby condition 1. We know that
p
is silent from roundm + 1
inG
i
;1 since it is silent in G
0
=
red(
G
pm + 1)
. We know thatpi
is silent fromround
m+1
inGi
;1since
pi
20
implies (assuming that
pi
is not justp
again) thatpi
fails inG, and hence is silent from roundm + 1
inG by condition 2. This meansthat block
(mppi) =
delete(mppi)
can be applied toGi
;1to transform G
i
;1to G
i
.Now consider the difficult case when
pi
62 0. LetH
i
;1andH
i
be graphs identicaltoG
i
;1 andG
i
, except that a single roundm + 1
token is onpi
inHi
;1 andH
i
.Condition 3 guarantees that all round
m + 1
tokens are onp
1inG, and hence inG
i
;1andG
i
, soHi
;1andH
i
really are graphs. In addition, set(m + 1pi)
transformsGi
;1toH
i
;1, and reset
(m+1pi)
transformsH
i
toGi
. LetIi
;1andI
i
be identical toHi
;1andH
i
except thatpi
is silent from roundm+1
inIi
;1andI
i
. Processorpi
is coveredin round
m + 1
inHi
;1 andH
i
, so Ii
;1 andI
i
really are graphs. In fact,pi
doesnot fail inGsince
pi
62 0, so
pi
is active through roundm
inIi
;1 andI
i
, soIi
;1=
red
(
Hi
;1
p
i
m+1)
andstates that silence
0(p
i
m+1)
transforms Hi
;1to I
i
;1, and revive
0f
p
ig(p
i
m+1)
transformsI
i
toHi
. Finally, notice that the only difference betweenIi
;1andI
i
is thecolor of the round
m
edge fromp
topi
. Sincep
is covered in roundm
andp
andpi
are silent from roundm+1
in both graphs, we know that delete(mpp
i)
transformsIi
;1
toI
i
. It follows that block(mppi)
transformsGi
;1toG
i
, and we are done.For part 2, let G be any graph and suppose green
(
Gpm)
is defined and=
faulty
(
G)
. Since green(
Gpm)
is defined, letG 0=
green
(
Gpm)
. Now letHandH0
be graphs identical toGandG 0
except that
p
is silent from roundm + 1
inHandH 0. Since green
(
Gpm)
is defined, processorp
is covered in roundm
inGby condition 1and hence inG 0
, soHandH 0
really are graphs. In addition, since green
(
Gpm)
isdefined, processor
p
is active through roundm
;1
inGby condition 4, so processorp
is active through round
m
inG 0andH 0
. This means that green
(
H0
pm + 1)
is de-fined, and in fact we haveH
=
red(
Gpm + 1)
andG0
=
green
(
H0
pm + 1)
. The induction hypothesis for
m + 1
states that silence(pm + 1)
transformsGtoHandthat revive
0(pm+1)
transforms H0
toG 0
. To complete the proof, we need only show that unblock
(mp)
transformsHtoH0
. The proof of this fact is the direct analogue of the proof in part 1 that block
(mp)
transforms red(
Gpm + 1)
to red(
Gpm)
. Theonly difference is that since we are coloring round
m
edges fromp
with green instead of red, we must verify thatp
is active through roundm
;1
in the graphsHi
analogoustoG
i
in the proof of part 1, but this follows immediately from condition 4.Given a graphG, letG
iv]
be a graph identical toG, except that processorpi
hasinput
v
. Using the preceding result, we can transformGtoGi
v]
.Lemma 3: For each
i
, there is a parameterized sequencei
V]
with the property that for all valuesv
and failure-free graphsG, the sequenceiv]
transformsGtoGiv]
.Proof: Define
set
(1pi) =
move(1p
1p
2)
move
(1pi
;1pi)
reset
(1pi
) =
move(1pipi
;1)
move
(1p
2p
1)
and define
i
V] =
set(1pi)
silence(pi1)
change(pi
V)
revivefp
ig
(pi
1)
reset(1pi)
where denotes the empty set. Now consider any value
v
and any failure-free graphG,and letG 0
=
G
i
v]
. SinceGandG 0are failure-free graphs, all round 1 tokens are on
p
1,so letHandH 0
be graphs identical toG andG 0
except that a single round 1 token is on
pi
inHandH0
. We know thatHandH 0
are graphs, and that set
(1pi)
transformsGtoH and reset
(1pi)
transforms H 0toG 0
. Since
pi
is covered in HandH 0, let I
andI 0
be identical toHandH 0
except that
pi
is silent from round 1. We know thatIandI 0
are graphs, and it follows by Lemma 2 that silence
(pi1)
transforms HtoIand that revivef
p
ig
(pi1)
transforms I0
toH 0
. Finally, notice thatIandI 0
differ only in the input value for
pi
. Sincepi
is covered and silent from round 1 in both graphs, the operation change(piv)
can be applied toIand transforms it toI0
. Stringing all of this together, it follows that
iv]
transformsGtoG0
=
Giv]
.By concatenating such operation sequences, we can transformGintoG
v]
by20 6 GRAPH ASSIGNMENT
Lemma 4: Let
V] =
1V]
n
V]
. For every valuev
and failure-free graphG, thesequence
v]
transformsGtoGv]
.Now we can define the parameter
N
used in defining the shape ofB
:N
is the length of the sequenceV]
, which is exponential inr
.6.4
Graph merge
Speaking informally, we will use each sequence
vi]
of graph operations to generate a sequence of graphs, and we will use this sequence of graphs to label vertices along the edge ofB
in thei
th dimension. Then we will label vertices in the interior ofB
by performing a “merge” of the graphs on the edges in the different dimensions.The merge of a sequenceH 1
:::
H
k
of graphs is a graph defined as follows:1. an edge
e
is colored red if it is red in any of the graphsH 1:::
H
k
, and greenotherwise, and
2. an initial nodeh
p0
iis labeled with the valuev
i
wherei
is the maximum indexsuch thath
p0
iis labeled withvi
inHi
, orv
0if no such
i
exists, and3. the number of tokens on a nodeh
pi
iis the sum of the number of tokens on thenode in the graphsH 1
:::
H
k
.The first condition says that a message is missing in the resulting graph if and only if it is missing in any of the merged graphs. To understand the second condition, notice that for each processor
p
j
there is a integers
j
with the property thatp
j
’s input value in changed tov
i
by thes
j
th operation appearing inv
i
]
. Now choose a vertexx = (x
1:::x
k
)
ofB
, and imagine walking from the origin tox
by walking along thefirst dimension to
(x
10:::0)
, then along the second dimension to(x
1x
20:::0)
,and so forth. In each dimension
i
, processorpj
’s input is changed fromvi
;1 tovi
after
sj
steps in this dimension. Sincex
1x
2
xk
, there is a final dimensioni
in which
pj
’s input is changed tovi
, and never changed again. The second condition above is just a compact way of identifying this final valuevi
.Lemma 5: LetHbe the merge of the graphsH 1
:::
H
k
. IfH 1:::
H
k
are1
-graphs,thenHis a
k
-graph.Proof: We consider the three conditions required of a
k
-graph in turn. First, there arek
tokens in each round ofHsince there is1
token in each round of each graphH1
:::
Hk
.Second, every red edge inHis covered by a token since every red edge inH
corre-sponds to a red edge in one of the graphsH
j
, and this edge is covered by a token inHj
.Third, if there is a red edge from
p
in roundi
inH, then there is a red fromp
in roundi
of one of the graphsH
j
. In this graph,p
is silent from roundi + 1
, so the same is true6.5
Graph assignments
Now we can define the assignment of graphs to vertices of
B
. For each valuev
i
, letFi
be the failure-free
1
-graph in which all processors have inputv
i
. Letx = (x
1:::xk)
be an arbitrary vertex of
B
. For each coordinatex
j
, letj
be the prefix ofvj]
consist-ing of the firstxj
operations, and letHj
be the1
-graph resulting from the applicationof
j
toFj
;1. This means that in
H
j
, some setp
1
:::pi
of adjacent processors havehad their inputs changed from
vj
;1tovj
. The graphGlabeling
x
is defined to be themerge ofH 1
:::
H
k
. We know thatG is ak
-graph by Lemma 5, and hence that atmost
rk
f
processors fail inG.Remember that we always write the vertices of a primitive simplex in a canonical order
y
0:::yk
. In the same way, we always write the graphs labeling the vertices] ofa primitive simplex in the canonical orderG 0
:::
G
k
, whereGi
is the graph labelingyi
.6.6
Graphs on a simplex
The graphs labeling the vertices of a primitive simplex have some convenient proper-ties. For this section, fix a primitive simplex
S
, and lety
0:::yk
be the vertices ofS
and letG 0
:::
G
k
be the graphs labeling the corresponding vertices ofS
. Our firstre-sult says that any processor that is uncovered at a vertex of
S
is nonfaulty at all vertices ofS
.Lemma 6: If processor
q
is not covered in the graph labeling a vertex ofS
, thenq
is nonfaulty in the graph labeling every vertex ofS
.Proof: Let
y
0= (a
1:::ak
)
be the first vertex ofS
. For eachi
, leti
andii
be theprefixes of
vi]
consisting of the firstai
andai
+1
operations, and letHi
andH 0i
be the result of applyingi
andii
toFi
;1. For each
i
, we know that the graphG
i
labelingthe vertex
yi
ofS
is the merge of graphsIi
1:::
I
ik
whereIij
is eitherHj
or H 0j
. Supposeq
is faulty inGi
. Thenq
must be faulty in some graphIij
in the sequence ofgraphsI
i
1:::
I
in
merged to formGi
, soq
must fail in one of the graphsHj
orH 0j
. Sincej
andjj
are prefixes ofvj]
, it is easy to see from the definition ofvj
]
that the fact thatq
fails in one of the graphsHj
andH0
j
implies thatq
is covered in both graphs. Since one of these graphs is contained in the sequence of graphs merged to formGa
for eacha
, it follows thatq
is covered in eachGa
. This contradicts the factthat
q
is uncovered in a graph labeling a vertex ofS
.Our next result shows that we can use the bound on the number of tokens to bound the number of processors failing at any vertex of
S
.Lemma 7: If
Fi
is the set of processors failing inGi
andF =
iFi
, thenjF
jrk
f
.Proof: If
q
2F
, thenq
2Fi
for somei
andq
fails inGi
, soq
is covered in every graph22 6 GRAPH ASSIGNMENT
We have assigned graphs to
S
, and now we must assign processors toS
. Alo-cal processor labeling of
S
is an assignment of distinct processorsq
0:::q
k
to thevertices
y
0:::yk
ofS
so thatqi
is uncovered inG
i
for eachyi
. A global processorlabeling of
B
is an assignment of processors to vertices ofB
that induces a local pro-cessor labeling at each primitive simplex. The final important property of the graphs labelingS
is that if we use a processor labeling to labelS
with processors, thenS
is consistent with a single global communication graph. The proof of this requires a few preliminary results.Lemma 8: If G
i
;1 andG
i
differ inp
’s input value, thenp
is silent from round1
inG 0
:::
G
k
. IfGi
;1 andG
i
differ in the color of an edge fromq
top
in roundt
,then
p
andq
are silent from roundt + 1
inG 0:::
G
k
.Proof: Suppose the two graphsG
i
;1 andG
i
labeling verticesyi
;1 and
yi
differ inthe input to
p
at timet = 0
or in the color of an edge fromq
top
in roundt
. The vertices differ in exactly one coordinatej
, soy
i
;1= (a
1:::aj:::ak)
andyi
= (a
1:::aj
+ 1:::ak)
. For each`
, let`
be the prefix ofv`]
consisting ofthe first
a`
operations, and letH 0`
be the result of applying`
toF`
;1. Furthermore,
in the special case of
` = j
, letjj
be the prefix ofvj
]
consisting of the firstaj
+ 1
operations, and letH1
j
be the result of applyingj
j
toFj
;1.We know thatG
i
;1is the merge of H
0 1
:::
H 0
j
:::
H 0k
, and thatGi
is the mergeofH 0 1
:::
H 1
j
:::
H 0k
. IfH 0j
andH 1j
are equal, thenGi
;1andG
i
are equal. Thus,H 0j
andH1
j
must differ in the input top
at timet = 0
or in the color of an edge betweenq
andp
in roundt
, exactly asGi
;1 and
G
i
differ. SinceH 0j
andH 1j
are the result of applyingj
andj
j
toFj
;1, this change at time
t
must be caused by the operationj
.It is easy to see from the definition a graph operation like
j
that (1) ifj
changesp
’s input value, thenp
is silent from round1
inH0
j
andH 1j
, and (2) ifj
changes the color of an edge fromq
top
in roundt
, thenp
andq
are silent from roundt+1
inH0
j
andH 1j
. Consequently, the same is true in the merged graphsGi
;1and G
i
.Lemma 9: IfG
i
;1andG
i
differ in the local communication graph ofp
at timet
, thenp
is silent from round
t + 1
inG 0:::
G
k
.Proof: We proceed by induction on
t
. Ift = 0
, then the two graphs must differ in the input top
at time0
, and Lemma 8 implies thatp
is silent from round1
in the graphsG0
:::
G
k
labeling the simplex. Supposet > 0
and the inductive hypothesisholds for
t
;1
. Processorp
’s local communication graph at timet
can differ in thetwo graphs for one of two reasons: either
p
hears from some processorq
in roundt
in one graph and not in the other, orp
hears from some processorq
in both graphs butq
has different local communication graphs at timet
;1
in the two graphs. In the firstcase, Lemma 8 implies that
p
is silent from roundt+1
in the graphsG 0:::
G
k
. In thesecond case, the induction hypothesis for
t
;1
implies thatq
is silent from roundt
inthe graphsG 0
:::
G
k
. In particular,q
is silent in roundt
inGi
;1andG
i
, contradictingLemma 10: If
p
sends a message in roundr
in any of the graphsG 0:::
G
k
, thenp
has the same local communication graph at time
r
;1
in all of the graphsG 0:::
G
k
.Proof: If
p
has different local communication graphs at timer
;1
in two of thegraphs G 0
:::
G
k
, then there are two adjacent graphsGi
;1 andG
i
in whichp
hasdifferent local communication graphs at time
r
;1
. By Lemma 9,p
is silent in roundr
in all of the graphs G 0
:::
G
k
, contradicting the assumption thatp
sent a roundr
message in one of them.
Finally, we can prove the crucial property of primitive simplexes in the Bermuda Triangle:
Lemma 11: Given a local processor labeling, let
q
0:::qk
be the processors labelingthe vertices of
S
, and letLi
be the local communication graph ofqi
inGi
. There is aglobal communication graphGwith the property that each
q
i
is nonfaulty inGand hasthe local communication graphL
i
inG.Proof: Let
Q
be the set of processors that send a roundr
message in any of the graphsG0
:::
G
k
. Notice that this set includes the uncovered processorsq
0
:::qk
,since Lemma 6 says that these processors are nonfaulty in each of these graphs. For each processor
q
2Q
, Lemma 10 says thatq
has the same local communication graphat time
r
;1
in each graphG 0:::
G
k
.LetH be the global communication graph underlying any one of these graphs.
Notice that each processor
q
2Q
is active through roundr
;1
inH. To see this, noticethat since
q
sends a message in roundr
in one of the graphs labelingS
, it sends all messages in roundr
;1
in that graph. On the other hand, ifq
fails to send a message inround
r
;1
inH, then the same is true for the corresponding graph labelingS
. Thus,there are adjacent graphsG
i
;1andG
i
labelingS
wherep
sends a roundr
;1
messagein one and not in the other. Consequently, Lemma 8 says
q
is silent in roundr
in all graphs labelingS
, but this contradicts the fact thatq
does send a roundr
message in one of these graphs.Now letGbe the global communication graph obtained fromHby coloring green
each round
r
edge from each processorq
2Q
, unless the edge is red in one of the localcommunication graphsL 0
:::
L
k
in which case we color it red inGas well. Noticethat since the processors
q
2Q
are active through roundr
;1
inH, changing the colorof a round
r
edge from a processorq
2Q
to either red or green is acceptable, providedwe do not cause more that
f
processors to fail in the process. Fortunately, Lemma 7 implies that there are at leastn
;rk
n
;f
processors that do not fail in any of thegraphsG 0
:::
G
k
. This means that there is a set ofn
;f
processors that send to everyprocessor in round
r
of every graphGi
, and in particular that the roundr
edges fromthese processors are green in every local communication graphL
i
. It follows that forat least
n
;f
processors, all roundr
edges from these processors are green inG, so atmost
f
processors fail inG.Each processor
qi
is nonfaulty inG, sinceqi
is nonfaulty in eachG 0:::
G
k
,mean-ing each edge from
qi
is green in eachG 0:::
G
k
andL 0:::
L
k
, and therefore inG.In addition, each processor
qi
has the local communication graphLi
inG. To see this,notice thatL