1145
Multilevel Heuristics for Rationale-Based Entity Relation Classification in
Sentences
Shiou Tian Hsu, Mandar Chaudhary and Nagiza F. Samatova
North Carolina State University
[email protected], [email protected], [email protected]
Abstract
Rationale-based models provide a unique way to provide justifiable results for relation classifi-cation models by identifying rationales (key words and phrases that a person can use to justify the relation in the sentence) during the process. However, existing generative networks used to extract rationales come with a trade-off between extracting diversified rationales and achieving good classification results. In this paper, we propose a multilevel heuristic approach to regulate rationale extraction to avoid extracting monotonous rationales without compromising classifica-tion performance. In our model, raclassifica-tionale selecclassifica-tion is regularized by a semi-supervised process and features from different levels: word, syntax, sentence, and corpus. We evaluate our approach on the SemEval 2010 dataset that includes 19 relation classes and the quality of extracted ra-tionales with our manually-labeled rara-tionales. Experiments show a significant improvement in classification performance and a 20% gain in rationale interpretability compared to state-of-the-art approaches.
1 Introduction
The goal of sentence-level entity relation classification is to infer how two target entities are semantically associated in a sentence. It is a core NLP function that supports many high level tasks such as information extraction and knowledge graph population (Hendrickx et al., 2009; Niu et al., 2012). Recent advances in generative models facilitate improved classification performance along with justifiable results which improves model interpretability. A generative model will first extract the most representative fragments in the sentence that expresses the relation first, and augments the classifier with the rationales (Hsu et al., 2018) . These representative fragments are called rationales as per (Zhang et al., 2016; Lei et al., 2016; Hsu et al., 2018), and can be used to justify the results. We illustrate an example of rationale-based models using an example sentence which expresses a Instrument-Agency(e2,e1) relationship between the given target entitiese1= “attacker” ande2= “instrument”:
Rationale based models: She had struggled violently with her [attacker]e1, who killedher witha
blunt [instrument]e2.
(words marked in bold and the entities are the major sources to infer the relation)
The most commonly used structure in generative models consists of two components: a Generator and a Discriminator. The Generator extracts rationales from an input sentence in an unsupervised fashion; the Discriminator, which is supervised, predicts the relation class utilizing the rationales. However, training a good Generator can be essentially hard due to the mode collapse problem (Chen et al., 2016; Che et al., 2017; Duhyeon and Hyunjung, 2018). Mode collapse is a commonly observed paradox where the Generator attempts to extract varied rationales, but converges to select monotonous rationales because the Discriminator failed to model diversified rationales. A collapsed Generator is not capable of providing
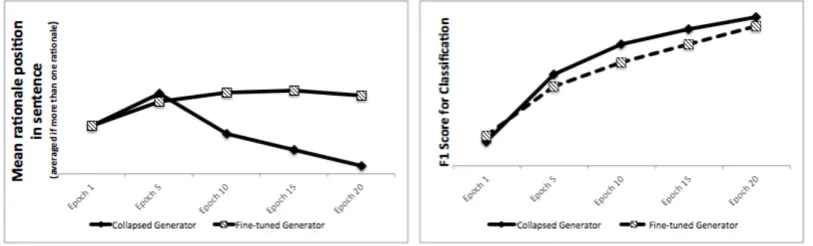
meaningful rationales since it extracts the same rationales repeatedly regardless of the context. However, as shown in Figure 1, a collapsed Generator does not always lead to poor classification performance when compared to a finely converged Generator.
Figure 1: A Generator can converge at collapsed rationales but still lead to good classification results. Figure on the left shows the rationale distribution of a collapsed and a well-converged Generator that uses a recurrent neural net . The well-converged Generator evenly selects rationales from a sentence, while the collapsed Generator selects rationales close to the beginning of the sentence. This is because the best scenario for Discriminator is that some rationales are repetitively selected and optimized in every training iteration, which is difficult for the Generator. Eventually, the Generator learns to exploit position features since it is less diversified than words. Figure on the right shows that a collapsed Generator does not necessarily deteriorate the classification performance.
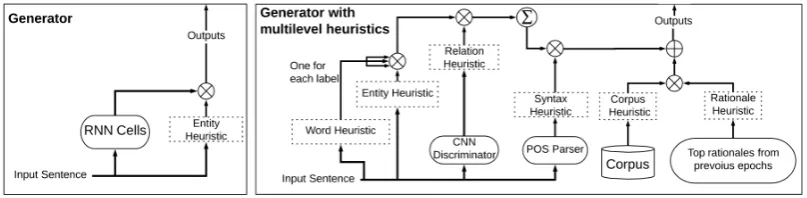
One of the major causes of mode collapse is the lack of regularizing terms to smooth out the Genera-tor(Chen et al., 2016; Arjovsky and Bottou, 2017; Salimans et al., 2016). In this paper, we aim to improve the rationale-based models for relation classification by introducing semi-supervised capacity and addi-tion regularizing force to the Generator to prevent mode collapsing. In our Generator, we develop a multilevel heuristic to replace the context-focused recurrent neural net used by existing approach(Hsu et al., 2018). Our Generator jointly considers features from different levels of the dataset such as contextual words, target entities, sentence syntax features, rationale-relation closeness, and global word distribution in corpus. The details of our improved Generator are shown in Figure 2.
Our Generator jointly considers several aspects such as contextual words, target entities, word distri-bution in corpus, sentence grammatical features, and selected rationale-relation closeness to regularize rationale selection.
We evaluate our model on the SemEval 2010 Task 8 dataset which includes 19 relation classes. Specif-ically, we use F1 score to measure the quality of extracted rationales and the classification performance. Given the absence of ground-truth of rationales in the dataset, we manually label the test set and make it publicly available1. We empirically demonstrate an improvement in interpretability of the rationales by 20% compared to Hsu et al. (2018), and also an improvement in the F1 score of 90.7 compared to 89.5 in the state-of-the-art model. We summarize the contributions of our approach as follows:
• We propose a multilevel heuristics approach to avoid mode collapse in rationale-based relation classification models.
• We empirically demonstrate our model produces improved relation classification performance and more interpretable rationales compared to other models
• We provide a labeled set of rationales that can be used for evaluation in future rationale research.
2 Related Work
Research for improving generative neural networks have gained much interest in the research community due to the effectiveness and versatility of these models. These improvements can be divided into two categories: architecture-oriented and divergence-oriented.
Figure 2: Figure on the left and the right shows the Generator in Hsu et al. (2018) and our proposed multilevel heuristics Generator respectively. The Word heuristic measures the relative closeness of each word in the sentence to every relation class. The Entity heuristic uses the target entities to regulate the Word heuristic. The Relation heuristic contains predictions of the relation from a standalone convolu-tional neural net model and is also used used to regulate the Word heuristic. The Word heuristic is then summed and weighted by the Syntax heuristic, which considers both, the word distance to entities, and Part-of-Speech labels. The Corpus heuristic is obtained by word-relation distribution in the corpus. The Rationale heuristic is the semi-supervised component which is based on rationales from the previous training iteration.
The Generative Adversarial Network (GAN) (Goodfellow et al., 2014) is the one of most representa-tive model in the architecture-oriented group. Goodfellow et al. (2014) proposed a modified generarepresenta-tive model using an adversarial minimax-game formulation. The objective of GAN is to jointly train a Gen-erator and Discriminator, where the loss for Discriminator and the reward for GenGen-erator comes from failed attempts to determine ground-truths from the emulated results created by Generator. However, the adversary process in GAN is the major source of mode collapse, hence further extensions of GAN aimed towards addressing this issue. For example, InfoGan (Chen et al., 2016) proposed to maximize the mutual information between a subset of the noise variables with the observations to produce disen-tangled unsupervised representations. Salimans et al. (2016) proposed to use semi-supervised training and label-smoothing to help GAN converge to Nash Equilibrium between the Generator and the Dis-criminator. Duhyeon and Hyunjung (2018) proposed RFGAN to implicitly regularize the discriminator using representative features extracted from the data distribution. In VEEGAN (Srivastava et al., 2017), the authors suggested to jointly train an extra Reconstructor with the Generator which is an approximate reverse action of the Generator to encode noise.
Another group of methods have aimed to reduce mode collapse in generative models by modifying the joint loss functions used between the Generator and Discriminator. In Arjovsky et al. (2017), the authors theoretically showed that the KullbackLeibler (KL) divergence often used in GAN was one of the source of instability. Based on this discovery, Arjovsky and Bottou (2017) proposed Wasserstein distance to measure the similarity between the fake and real data to make stabler Generator. Gulrajani et al. (2017) introduce the gradient penalty for regularizing the divergence as an alternative to gradient clipping used in Arjovsky and Bottou (2017) to capture stronger movements in gradients . In DRAGAN (Kodali et al., 2017), they proposed to regulate sharp gradients in the Discriminator, which often happens at some undesiredlocal equilibriabetween Generator and Discriminator. Roth et al. (2017) proposed another type of regularization that breaks down the divergence into different Discriminator output to achieve stability.
On a final note, we would like to mention that this work shares some resemblance with (Giuliano et al., 2006) and can be potentially considered as its extension. In Giuliano et al. (2006), the authors utilize several shallow linguistic information for relation classification, such as word-relation frequency or POS to avoid dependent syntactic information. In this work, the fundamental difference is that all token-based computations are replaced by embeddings which are more generalizable when considering words of semantic relatedness. Additionally, the training phase is carried out by the adversarial process.
3 Rationale Generation Framework
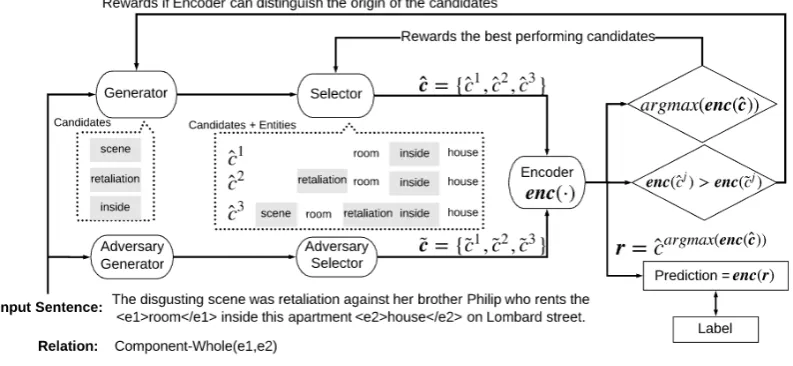
We describe the framework for rationale-based approach in the following. Consider an input sentencex ={xt}Tt=1, where e1 ande2 are given target entities of interest ande1 ande2 ⊂ {x1, x2, ..., xT}. The goal of relation classification is thus to use (x,e1,e2) to predict the relationshipybetweene1ande2. We
call this prediction process as encoding and denote it asenc(x,e1,e2).
Following Hsu et al. (2018), we consider this rationale based model as an adversarial problem the goal of the Generator is to generate rationalesrthatenc(r,x,e1,e2) can outperform all other sets of rationales
inenc(˜r,x,e1,e2). In Hsu et al. (2018), they split the Generator into two steps: the Generator and the
Selector. The Generator first generates candidatesgen(x,e1,e2), which samplesc ={ct}Tt=1 from the
input wherect∈[0,1]and it represents whetherxtshould be considered as a rationale ; the Selector then samples rationalesrfromcand is represented assel(c,e1,e2). We illustrate the framework in Figure 3.
[image:4.595.102.499.429.612.2]A difference against other generative works is worth noting: in Lei et al. (2016), rationales are defined as a sequence of words in a customer review that are directly related to different rating aspects. This is because in Lei et al. (2016), the assumption is that the reviews contain convoluted sentiments, and the goal of a rationale is to disentangle the sentiments. In effect, the goal ofrin Lei et al. (2016) is to serve as a proxy ofxthat makesenc(r)approximate toenc(x). while our goal is to findrthat outperform all possible short enumerations ofxinenc(r,x,e1,e2).
4 Model
In this section, we describe each component of the framework. We begin by explaining the Encoder to formalize the goal of relation classification.
4.1 Encoder
Given an input training tuple (x,e1,e2,y), wherex={xt}Tt=1, andyis the one-hotLdimensional vector representing the relation class. The goal of the Encoder enc(r,x,e1,e2) is to produce a probability
distributionyˆthat approximates toyas formulated as follows (N is the size of the training set):
loss= |N|
X
i=1
−yi·log(ˆyi) (1)
The Encoder producesyˆby encoding (r,x,e1,e2) as a vector representation and then projects it to they
space. This vector representation can further break down to a sentence vectorVx and a rationale vector
Vr. We produce Vx through CNN using the same model as Kim (2014) which encodes the sentence through a continuous window approach, where K are the set of sizes for the windows. To produceVr, we implement a RNN model using GRU cells that reads the rationales and target entities. Since RNN is order sensitive, the rationales and the entities are sorted based on their position in the sentence before applying the RNN model.
Vx=CN N(x)
Vr=RN N([r, e1, e2])
ˆ
y=enc(r,x, e1, e2)
=sof tmax(Wenc·[Vr, Vx, e1, e2] +benc) (2)
4.2 Generator
The goal of the Generatorgen(x) is to derive a set of binary variablesc ={ct}Tt=1 by sampling from
probability scoress={st}Ts=1, wherect∈[0,1]indicates whetherxtis chosen as a candidate rationale andstis computed by the multilevel heuristics. We represent it asc∼gen(x).
In contrast to Hsu et al. (2018) which uses an RNN model for Generator, we adopted a set of logistic regression models with several feed-forward networks to facilitate the Generator. The reason being, an RNN model can be difficult to train and might be susceptible to mode collapse if not carefully tuned. In the Generator, the number of logistic regression models is equal toLwhich is the number of classes iny. Each word in the sentence is first moderated by the Entity heuristiche, which is obtained from the target entities and fed through the logistic regression models to obtain the Word heuristic hw =
{hwlt}Ll=1 tT=1. Each hwtl can be considered as a probability ofxt being chosen as a rationale if the
given sentence is of relation classl. The second step is to compute the Relation heuristichr={hrl}L l=1
and the Syntax heuristichstthat are applied to the Word heuristic. The Relation heuristic initializes the relation with a random guess using the whole sentence. The heuristic is then trained through a CNN model which similar to the CNN model we used to computeV x. The Syntax heuristichstis obtained from a feed forward neural network that takes as input (1) word distance to target entities, and (2) Part of Speech (POS) tags. The output,slocalt , is obtained by combining the Word, Entity, Syntax and Relation heuristics, and it represents local sentence information score.
The final score stis then computed by applying the Corpus and Rationale heuristics to slocalt . The Corpus heuristichc= {hcl}Ll=1 contains binary values computed by sorting and selecting the frequent
Kwords in each relation class in the training set. The Rationale heuristichra={hral}L
l=1also contains
Accordingly,sglobalt will not be used in testing and will only be included after several training iterations have completed. Finally, before applyingsglobalt to the final scorestwe apply a dynamically computed weight factorCRtoslocal
t ands global
t . We formulate all the heuristics in the following equation,
he=sigmoid(Whe·[e1, e2] +bhe)
hwt=sigmoid(Whw ·(xthe) +bhe)
hr=CN N(x)
hst=sigmoid(Whs·[P OSt, positiont])
CR=sigomid(WCR·hr0+bCR)
slocalt =hwt· T(hr)·hs
(Tstands for transpose function)
sglobalt =hchra
st=st·(1−CR) +sglobalt CR
(3)
In the most simplistic Generator, the probability thatxtis chosen is conditionally independent of all otherx. In other words, we can sample candidatec from a uniform distribution using the probability scores,s. However, we observe that the target rationales in the dataset often consist of few words - for example “roominsideapartment”. Therefore, we added the following Equation (4) to limit the number of rationales selected,c, to be at mostJ.
ct=
(
1, sort({(st> rand(0,1))·st}Tt=1)[1 :J]
0, otherwise (4)
c={ct}Tt=1
4.3 Selector
The last component of the model is the Selectorsel(c), where the goal of the Selector is to decide the number of rationales best suited for the prediction. The Selector is facilitated by a simple feed-forward network that outputs a number from1∼J by scoring rationale sets of length ranging from1∼J based on the top rankedst∗ct. During training, all rationale sets will be forwarded to the Encoder, and the training label for Selector will be the size of the set that obtains the least training loss in Encoder. This Selector is identical to the one in Hsu et al. (2018) and is defined as follows:
ˆ
cjt =
(
1, sort({ct·st}Tt=1)[1 :j], j∈[1 :J]
0, otherwise
ˆ
cj ={ˆcjt}Tt=1,wherecˆjt = 1
score(cˆj) =Wc·enc(cˆj,x, e1, e2)
scoresj =sof tmax({score(cˆj)}Jj=1)j
ˆ
scoresj =
(
1 , j=argmax(scores)
0 , otherwise
r={xt},wherecˆjt = 1, j=argmax(scores) (5)
4.4 Joint Objective and Adversarial Training
We formulate the joint loss function in the following to bind the components.
As described earlier, the goal of the Generator and the Selector is not to emulatexwithrdue to the nature of this research. In effect, the Generator and the Selector are not competing against the Encoder, but instead with an adversary Generator, for which we use a randomized approach. The adversary Gen-erator will sample˜crandomly fromx. The adversary rationales˜rwill then be selected using˜cas per Equation (4). r˜will be passed to the Encoder to generate a projectiony˜onto the target dimension. We compare y˜with yˆin terms of their similarity to y and is denoted byD ∈ {0,1}. D = 1 when yˆis closer toycompared toy˜, and is noted as a ‘model success case’, meanwhile1− D= 1for the opposite situation and is noted as an ‘adversary success case’. The objective for the Generator and Encoder reacts differently to the two different cases, where the Encoder optimize whichever rationales that performs better, and the Generator rewards the selected rationales in model success case and penalize in the other case. We further splityˆ,y˜andDintoyˆj,y˜j,Dj andj∈[1 :J], whereDj represents thatyˆjoutperforms ˜
f(s0tjl) =−log(st0jl)·cjt ·yi+
−log(1−s0tjl)·cjt·(1−yi)
f(cjt) =−log(st)·ctj−log(1−st)·(1−cjt)
fy(ˆyji) =−yi·log(ˆyji)
Lenc= J
X
j=1 Pj
Djfy(ˆyj) + (1− Dj)fy(˜yj)
Lsel= J
X
j=1
−Dj ∗scoresˆ j∗log(scoresj)
Lgen= J X j=1 T X t=1
Djf(ˆcjt)−(1− Dj)f(˜cjt)
+ J X j=1 T X t=1 L X l=1
Djf(ˆsjlt)−(1− Dj)f(˜sjlt )
(6) The final joint objective and the expected cost is defined as:
L(r,x, e1, e2, y) =Lgen+Lsel+Lenc
min
θeθgθs
X
(x,e1,e2,y)∈N
Er∼sel(c),c∼gen(x)L(r,x, e1, e2, y) (7)
whereθe,θg,θsare the parameters used in the Encoder, Generator and Selector respectively.
5 Experiments
5.1 Dataset
We evaluate our approach by performing experiments on the SemEval 2010 Task 8 dataset. A collection of sentences is provided with marked target entities and ground-truth for the relation between the entities. The dataset contains 10,717 sentences, where 8000 entries are used in training. There are 9 types of relationships plus an “Other” class (Table 1). Relationship types (except for “Other”) are expressed bi-directionally, making 19 classes in total. Following SemEval 2010’s protocol, we used the macro-F1 metric in the experiment, excluding all cases of the “Other” class.
Besides the original SemEval 2010 Task 8 data, we asked 3 human annotators to label rationales used in the test set. Annotators were asked to choose 0-3 rationales for each test sentence based on their intuition. Each annotator is asked to roughly annotate one-third of the test set. Distribution of rationales are as follows: no-rationales:2%, 1-rationale:57%, 2-rationales:38% and 3-rationales:2%. Note that we did not annotated the training set.
[image:7.595.96.521.72.333.2]Cause-Effect Component-Whole Content-Container Entity-Destination Entity-Origin Instrument-Agency Member-Collection Message-Topic Product-Producer
Table 1: Relation classes in SemEval 2010 task 8
5.2 Experimental Setup
We now describe in detail the parameters used in our experiments. We initialize the word vectors with the GoogleNews2corpus. The CNN filter size was initialized to 50. We use at most 3 rationales and set the penalizing factorPjto 0.1 based on our analysis of the training set. Due to the lack of sufficient sam-ples in certain relation classes, we ignored the relationship directionality while computing the Relation heuristic. Finally, the dimensionality of the POS tag vectors and the position vectors is set to 25, and the Generator is set to ignore nouns, articles and adjectives.
Finally, after training for 10 iterations, the Generator includes the output from the Corpus and Ratio-nale heuristics. TheKfrequently used words in the Corpus heuristic are computed for each relation class, where the threshold forKlis 10% of number of sentences of the givenl relation class. The Rationale heuristic selects the top 25% of words,hwl, output by the Word heuristic.
We used the Adagrad optimizer in our experiments and the learning rate is initialized to 0.01, and reduces by 10% after every iteration. During each training iteration, we sample 25 times from the Generator, and re-sample 25 times when training the Selector and the Encoder.
5.3 Results
We present a comparison of relation classification between our model and the state-of-the-art models in Table 2. Dependency tree models are neural network models that work with word dependency tree parsed by a grammar parser. Each model utilizes the dependency tree differently. For instance MVRNN (Socher et al., 2012) uses the whole dependency tree, while SPTree (Miwa and Bansal, 2016) experiments using the entire tree and the nodes on the path that connect the target entities. We refer to the models that do not use a dependency tree as independent models.
Classifier F1
Manually Engineered Models
SVM(Rink and Harabagiu, 2010) 82.2 Dependency Tree Models
RNN (Socher et al., 2012) 77.6 MVRNN (Socher et al., 2012) 82.4 FCM (Yu et al., 2014) 83.0 Hybrid FCM (Gormley et al., 2015) 83.4 DepNN (Liu et al., 2015) 83.6 DRNNs (Xu et al., 2015) 85.6 SPTree (Miwa and Bansal, 2016) 84.5
Classifier F1
Independent Models
CNN & softmax (Zeng et al., 2014) 82.7 Stackforward(Nguyen and Grishman, 2015) 83.4 Vote-bidirect (Nguyen and Grishman, 2015) 84.1 Vote-backward (Nguyen and Grishman, 2015) 84.1 ATT-Input-CNN (Wang et al., 2016) 87.5 ATT-Pooling-CNN (Wang et al., 2016) 88.0 Rationale Models
Proxy-Rationale-1(Hsu et al., 2018) 84.5 Proxy-Rationale-2(Hsu et al., 2018) 85.3 Proxy-Rationale-3(Hsu et al., 2018) 87.8 GAN(Hsu et al., 2018) 89.5
Our Model 90.7
Table 2: Comparisons with benchmarking models
Table 3, presents a detailed comparison between the different variations of our model and other rationale-based models. We evaluate the rationale quality using macro-F1, where precision and recall are computed by taking the intersection between the generated and the manually labeled rationales.
Rationale Models Relation F1 Rationale F1 Proxy-Rationale-1(Hsu et al., 2018) 84.5 6.3 Proxy-Rationale-2(Hsu et al., 2018) 85.3 22.2 Proxy-Rationale-3(Hsu et al., 2018) 87.8 26.1
GAN(Hsu et al., 2018) 89.5 33.2
Our Model prior global heuristicssglobal 89.5 37.1 Our Model after global heuristicssglobal 90.7 53.2
Table 3: Comparisons between variations and with rationale models
Relation Class Selected rationales with target entities
Cause-Effect dipse1caused by ... y-rayse2, livere1... cause ... hypertensione2
plaintiffse1...resulting from ... explosione2, storme1generated by ... colde2
Component-Whole sitee1is part of ... networke2 , cabinete1 encloses ... woofere2, laddere1comprises ... stepse2, crocodilee1has ... snoute2
Content-Container gunse1 are locked in safee2, grenadee1hidden inside canistere2 spidere1was contained in ... boxe2, suitcasee1full ... bookse2
Entity-Destination weaponse1... delivered to ... navye2, moneye1... into ... custodye1
childrene1were handed over to relativese2, watere1... been poured into ... rivere2
Entity-Origin squirrele1popped out of ... shirte2, robberse1... away from scenee2 gasese1emanated from ... sourcese2, starche1is source of sugarse2
Instrument-Agency mechanice1tightens ... with spannere2, intellecte1wields pene2
projecte1uses arte2as instrument, gives ... best practicese1for programmerse2
Member-Collection bloate1of hippopotamusese2, formatione1comprised of ... dragoonse2 surgeone1is part of the teame2, sergeante1in armye2
Message-Topic caveatse1outlined ... e-maile2, speeche1... about conversatione2 speeche1was summary of ... problemse2, parameterse1described texte2
[image:9.595.74.536.61.327.2]Product-Producer production materialse1by industriese2, productse1grown by ... defendante2 engineerse1... devised ... methode2, investment firme1co-founded by ... heade2
Table 4: List of words/phrases that are selected as rationales in test set by our model. Additional words are denoted as ... if they are located between entities and rationales but are not selected as rationales.
6 Discussion and Future Goals
6.1 Logistic Regressions and RNN
The major difference between this work and the previous rationale-based research is that we designed the Generator without a sequential RNN model. Specifically, we developed a layer by layer process that considers different levels of text information for three reasons. First, in relation classification, the excess sequential modeling power from RNN is not required since rationales are often an extremely small span of words. Also, rationales are often strongly-related to POS tags which can be used to replace the sequence information. Second, the purpose of rationales in relation classification is to augment features and illuminate how the model derives the answer. This is different from other tasks like aspect-level sentiment classification in Lei et al. (2016) where the rationales are treated as a compression of the input. Although more empirical experiments are required, we hypothesize that this simpler multilevel heuristic approach suits better for tasks with simpler rationales. Finally, dropping RNN can help the model parallelize and also less prone to mode collapse and gradient vanishing.
6.2 Axillary Information
The improvement in rationale interpretability comes from regularizing the Generator through a wide set of knowledge sources, like the Relation, the Corpus and the Rationale heuristic, and we believe this can be further improved by including more knowledge sources. For example, the Entity heuristic can be improved by annotating entities through a large open source data such Wikipedia, or the Corpus heuristic can be more diverse with distant supervision tricks. However, the amount of axillary information to include and to what degree is a challenge in itself.
Component-Whole relations. This can be unfavorable for the Word heuristic since our approach assumes rationales are more heterogeneous than homogeneous between different relations. A potential solution is to cluster or introduce hierarchical structures to the relations thereby reducing diversity.
6.3 Potential Applications: Noise-Reduction in Distant Supervision
A potential application of this work, besides classifying relations and providing interpretable results, is to help reduce noise in distant supervision for relation classification. Distant supervision is a commonly used approach in relation classification where producing ground-truth data is expensive. Distant super-vision exploits a simple assumption: if a sentencescontains an entity-relation pair (e1, relation, e2) that exists in a trustworthy knowledge source, thenscan be a training data for therelation. As a result, distant supervision often contains many noisy false-negative training samples and degrades the result. To reduce the noise, one can penalize sentences that do not contain commonly used rationales for the relation.
7 Conclusion
In this paper, we have proposed an improved rationale-based model for entity relation classification. In our model, besides context word information, we also moderate rationale generation with multiple heuristics computed from different text level features. With multilevel heuristics, we successfully reduce the variability in the Generator to achieve meaningful rationales. Quantitative analysis demonstrates that our model improves both classification performance and the rationale quality. Finally, we provide an annotated test set for rationales, which can be used in future related research to evaluate rationales.
Acknowledgments
We thank the COLING reviewers for their detailed and insightful feedback, and also thank the annotators for their intensive efforts for developing the annotated set. This material is based upon work supported in whole or in part with funding from LAS. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the LAS and/or any agency or entity of the United States Government.
References
Martin Arjovsky and Leon. Bottou. 2017. Towards principled methods for training generative adversarial net-works. InarXiv preprint arXiv:1701.04862.
Martin Arjovsky, Soumith Chintala, and Leon. Bottou. 2017. Wasserstein gan. In arXiv preprint arXiv:1701.07875, 2017.
Tong Che, Yanran Li, Athul Paul Jacob, Yoshua Bengio, and Wenjie. Li. 2017. Mode regularized generative adversarial networks. InICLR.
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. 2016. Infogan: Inter-pretable representation learning by information maximizing generative adversarial nets. InNIPS.
Bang Duhyeon and Shim Hyunjung. 2018. Improved training of generative adversarial networks using represen-tative features. Inarxiv: preprint arXiv:1801.09195.
Claudio Giuliano, Alberto Lavelli, and Lorenza Romano. 2006. Exploiting shallow linguistic information for relation extraction from biomedical literature. In11th Conference of the European Chapter of the Association for Computational Linguistics.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. InNIPS, pages 2672–2680.
Matthew R Gormley, Mo Yu, and Mark Dredze. 2015. Improved relation extraction with feature-rich composi-tional embedding models. InEMNLP, pages 1774–1784.
Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid ´O S´eaghdha, Sebastian Pad´o, Marco Pennacchiotti, Lorenza Romano, and Stan Szpakowicz. 2009. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. InNAACL HLT, pages 94–99.
Shiou Tian Hsu, Changsung Moon, Paul Jones, and Nagiza Samatova. 2018. An interpretable generative adver-sarial approach to classification of latent entity relations from unstructured sentences. InAAAI.
Yoon Kim. 2014. Convolutional neural networks for sentence classification. InEMNLP, pages 1746–1751.
Naveen Kodali, Jacob Abernethy, James Hays, and Zsolt. Kira. 2017. On convergence and stability of gans. In
arXiv preprint arXiv:1705.07215.
Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016. Rationalizing neural predictions. InEMNLP, pages 107– 117.
Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou, and Houfeng Wang. 2015. A dependency-based neural network for relation classification. InACL, pages 285–290.
Makoto Miwa and Mohit Bansal. 2016. End-to-end relation extraction using lstms on sequences and tree struc-tures. InACL, pages 1105–1116.
Thien Huu Nguyen and Ralph Grishman. 2015. Combining neural networks and log-linear models to improve relation extraction. InIJCAI Workshop on Deep Learning for Artificial Intelligence (DLAI).
Feng Niu, Ce Zhang, Christopher R´e, and Jude W Shavlik. 2012. Deepdive: Web-scale knowledge-base construc-tion using statistical learning and inference.VLDS, 12:25–28.
Bryan Rink and Sanda Harabagiu. 2010. Utd: Classifying semantic relations by combining lexical and semantic resources. InSemEval, pages 256–259.
Kevin Roth, Aurelien Lucchi, Sebastian Nowozin, and Thomas Hofmann. 2017. Stabilizing training of generative adversarial networks through regularization. InNIPS.
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved techniques for training gans. InAdvances in Neural Information Processing Systems (NIPS), pages 2234–2242.
Richard Socher, Brody Huval, Christopher D Manning, and Andrew Y Ng. 2012. Semantic compositionality through recursive matrix-vector spaces. InEMNLP, pages 1201–1211.
Akash Srivastava, Lazar Valkov, Chris Russell, Michael U. Gutmann, and Charles Sutton. 2017. Veegan: Reduc-ing mode collapse in gans usReduc-ing implicit variational learnReduc-ing. InNIPS.
Linlin Wang, Zhu Cao, Gerard de Melo, and Zhiyuan Liu. 2016. Relation classification via multi-level attention cnns. InACL, pages 1298–1307.
Kun Xu, Yansong Feng, Songfang Huang, and Dongyan Zhao. 2015. Semantic relation classification via convo-lutional neural networks with simple negative sampling. InEMNLP, pages 536–540.
Mo Yu, Matthew Gormley, and Mark Dredze. 2014. Factor-based compositional embedding models. InNIPS, pages 95–101.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolu-tional deep neural network. InCOLING, pages 2335–2344.