caretakers were instructed and understood how to operate, interrupt and recharge the
device. After the recording sessions were completed, DLP was sent back to the
experimenters and the device was connected with a computer of LENA system
software which automatically uploaded and processed the audio file (Figure 2) and
developed the reports (Figure 3).
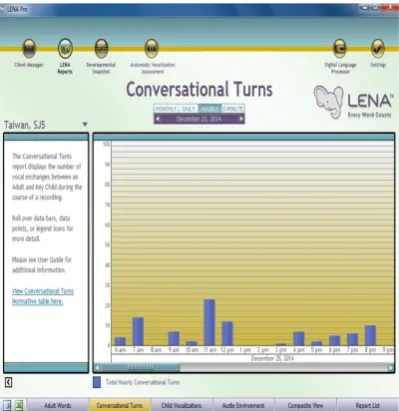
The adult word counts measure the total number of adult words the child hears
per hour, per day and per month. The conversational turns display the total number of
conversational turns the child engages in with an adult per hour, per day and per
month. The child vocalizations array the total number of vocalizations the child
produces per hour, per day and per month.
The core design of LENA system is the algorithmic models which is capable to
segment and identify sounds of different amplitude and intensity. The audio data were
categorized into eight categories with different sources: the key child (wearing LENA
DLP), other child, adult male and adult female, overlapping sounds, noise, electronic
sounds (e.g., TV), and silence. Each category is further identified as clear and unclear
(or quiet and distant) subcategories. In order to identify a variety of audio signals
efficiently and accurately, LENA audio processing models are trained by audio
transcriptions of each category first. For example, the speech processing algorithms
need to recognize the differences between adult speech and child speech, and between
the key child and other children [13].
Figure 1. The LENA digital language processor (DLP) placed in the pocket of LENA
Figure 3. Reports from LENA system software
In order to answer the research questions, two statistical measures were
performed, First, three one-way repeated measures ANOVAs were performed to
explore if there were any changes of the three variables, (adult word counts,
conversational turns, and child vocalizations) along the time. Next, multiple
regressions were performed at the ages of 10, 20 and 30 months to examine how
much AWC and CT contribute to CV at each age.
3. Results and Discussion
Figure 4 shows the average number of child vocalizations (CV), adult word
counts (AWC), and conversational turns (CT) from the recordings made at 10, 20, and
30 months. The average number of CV gradually increased from 10, 20, and 30
months. The average number of CT also showed a gradual increase from 10, 20, and
30 months although the increase was small. However, the average number of AWC
showed a decrease from 10, 20, and 30 months. Results of the three one-way repeated
measures ANOVAs did not show significant differences among the three ages (AWC:
F(2, 10)=1.89, p = 0.20; CT: F(2,10)=0.43, p = 0.67; CV: F(2,10)=1.03, p = 0.39) ,
suggesting that the results of the mean of AWC, CT, CV were similar across the three
ages.
The results of multiple regressions showed that CT and CV were highly
[9] N. Akhtar, J. Jipson and M. Callanan, "Learning Words Through
Overhearing", Child Development, vol. 72, no. 2, pp. 416-430, 2001.
[10] A. Weisleder and A. Fernald, "Talking to Children Matters: Early language
experience strengthens processing and builds vocabulary", Psychological Science,
vol. 24, no. 11, pp. 2143-2152, 2013.
[11] D. Oller, P. Niyogi, S. Gray, J. Richards, J. Gilkerson, D. Xu, U. Yapanel and S.
Warren, "Automated Vocal Analysis of Naturalistic Recordings from Children
With Autism, Language Delay, and Typical Development", Proceedings of the
National Academy of Sciences, vol. 107, no. 30, pp. 13354-13359, 2010.
[12] J. Gilkerson, Y. Zhang, D. Xu, J. Richards, X. Xu, F. Jiang, J. Harnsberger and K.
Topping, "Evaluating Language Environment Analysis System Performance for
Chinese: A pilot study in Shanghai", Journal of Speech Language and Hearing
Research, vol. 58, no. 2, p. 445, 2015.
[13] M. Ford, C. T. Baer, D. Xu, U. Yapanel and S. Gray, “The LENA Language
Environment Analysis System: Audio specifications of the DLP-0121, LTR-03-2”,