LOGIC-BASEDTECHNIQUES IN DATA INTEGRATION
AlonY. Levy
DepartmentofComputerScienceandEngineering
UniversityofWashington
Seattle,WA,98195
Abstract
Thedataintegrationproblemistoprovideuniformaccesstomultiple
heterogeneous information sources availableonline (e.g., databases on
theWWW).Thisproblemhasrecentlyreceivedconsiderableattention
from researchers in the elds of Articial Intelligence and Database
Systems. The data integration problem is complicated by the facts
that(1)sourcescontainclosely relatedand overlappingdata,(2)data
is stored in multiple data models and schemas, and (3) datasources
havedieringqueryprocessingcapabilities.
Akeyelementinadataintegrationsystem isthelanguageusedto
describethecontentsandcapabilitiesofthedatasources. Whilesucha
languageneedsto beas expressiveaspossible,itshouldalsoenableto
eÆcientlyaddressthemaininferenceproblemthatarisesinthiscontext:
totranslateauserquerythatisformulatedoveramediatedschemainto
aqueryonthelocalschemas. Thispaperdescribesseverallanaguages
fordescribingcontentsofdatasources,thetradeosbetweenthem,and
theassociatedreformulationalgorithms.
Keywords:
Dataintegration,descriptionlogics,views.
1. INTRODUCTION
Thegoalofadataintegrationsystemistoprovideauniforminterface
toamultitudeofdatasources. Asanexample,considerthetaskof
pro-vidinginformationaboutmovies from data sourceson the World-Wide
Web (WWW). There are numerous sources on the WWW concerning
listingsof movies, their casts, directors, genres, etc.), MovieLink
(pro-viding playing times of movies in US cities), and several sites
provid-ingreviews of selected movies. Supposewe want to nd which movies,
directed by Woody Allen, are playing tonight in Seattle, and their
re-spective reviews. None of these data sources in isolation can answer
thisquery. However, by combining data from multiple sources, we can
answer queries like thisone, and even more complex ones. To answer
ourquery,we wouldrstsearchtheInternetMovieDatabaseforthelist
of movies directed by Woody Allen, and then feed the result into the
MovieLinkdatabaseto checkwhichonesareplayinginSeattle. Finally,
we would nd reviews for the relevant movies using any of the movie
reviewsites.
Themostimportantadvantageofadataintegrationsystemisthatit
enablesuserstofocusonspecifyingwhattheywant,ratherthanthinking
abouthow toobtaintheanswers. Asaresult,itfreestheusersfromthe
tedioustasks ofndingtherelevant datasources, interactingwitheach
sourceinisolationusingaparticularinterface,andcombiningdatafrom
multiplesources.
Themaincharacteristic distinguishingdataintegration systems from
distributedand parallel database systems is that the data sources
un-derlying the system are autonomous. In particular, a data integration
systemprovidesaccesstopre-existing sources,whichwerecreated
inde-pendently. Unlike multidatabase systems (see Litwin etal., 1990 for a
survey)adataintegrationsystemmustdealwithalargeandconstantly
changing set of data sources. These characteristics raise the need for
richer mechanisms for describing our data, and hence the opportunity
toapplytechniquesfromknowledgerepresentation. Inparticular,adata
integrationsystemrequiresa exiblemechanismfordescribingcontents
of sources that may have overlapping contents, whose contents are
de-scribed by complexconstraints, and sources thatmaybeincomplete or
onlypartially complete.
This paper describes the main languages considered for describing
datasourcesindataintegrationsystems(Section4.),whicharebasedon
extensionsofdatabasequerylanguages. We thendiscussthenovel
chal-lenges arising in designing the appropriate reasoning algorithms
(Sec-tion5.). Finally,weconsidertheadvantagesandchallengesof
accompa-nyingtheselanguageswitharicherknowledge representationformalism
basedon DescriptionLogics(Section 6.).
Thispaperisnotmeant tobeacomprehensivesurveyoftheworkon
dataintegrationorevenonlanguagesfordescribingsourcedescriptions.
thesolutionsthathavebeenproposed. Pointersto moredetailedpapers
areprovidedthroughout.
2. NOTATION
Our discussion will use the terminology of relational databases. A
schema isa set of relations. Columnsof relations arecalled attributes,
and theirnames are partof the schema (traditionally, thetype of each
attributeisalso part oftheschema butwewillignoretypinghere).
Queries can be specied in a variety of languages. For simplicity,
we consider the language of conjunctive queries (i.e., single Horn rule
queries),andseveral variantson it. Aconjunctive query hastheform:
q( X) :-e 1 ( X 1 );:::;e n ( X n ); where e 1 ;:::;e n
are database relations, and X 1 ;:::; X n are tuples of
variables or constants. The atom q(
X) is the head of the query, and
theresultofthequery isaset oftuples,eachgiving abindingforevery
variable in
X. We assume the query is safe, i.e., X X 1 [:::[ X n .
Interpretedpredicatessuchas<;;6=aresometimesusedinthequery.
Querieswithunionsareexpressedbymultipleruleswiththesamehead
predicate. A view refers to a named query, and itis said to be
materi-alized ifits resultsarestoredinthe database.
The notions of query containment and query equivalence are
impor-tant in order to enable comparison between dierent formulations of
queries.
Denition1 : Query containment and equivalence. A query Q
1
is said to be contained in a query Q
2 , denoted by Q 1 v Q 2 , iffor any databaseD,Q 1 (D)Q 2
(D). Thetwoqueriesaresaidto beequivalent
ifQ 1 vQ 2 and Q 2 vQ 1 .
Theproblemsofquerycontainmentandequivalencehavebeenstudied
extensivelyintheliterature. Someof thecases whicharemostrelevant
toourdiscussioninclude: containmentofconjunctivequeriesandunions
thereofChandraandMerlin,1977;SagivandYannakakis,1981,
conjunc-tivequerieswithbuilt-incomparisonpredicatesKlug,1988,anddatalog
queries Shmueli, 1993; Sagiv, 1988; Levy and Sagiv, 1993; Chaudhuri
and Vardi, 1993;Chaudhuri and Vardi, 1994.
3. CHALLENGES IN DATA INTEGRATION
Asdescribedintheintroduction,thetaskofadataintegrationsystem
relational,object-oriented, etc.), legacysystems, orstructuredles
hid-denbehindsome interfaceprogram. Forthepurposesof our discussion
wemodeldatasourcesascontainingrelations. Inthispaper(asinmost
oftheresearch) we onlyconsider dataintegrationsystems whosegoal is
to querythedata, and notto performupdateson thesources.
Even though this paper focuses on the problem of modeling data
sourcesandqueryreformulation,itisworthwhileto rsthighlightsome
ofthechallengesinvolvedinbuildingdataintegrationsystems. Todoso,
we briey compare data integration systems with traditional database
management systems.
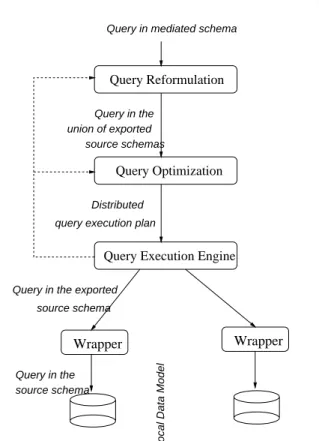
Figure1.1illustratesthedierentstagesinprocessingaqueryinadata
integration system.
Query Reformulation
Query Execution Engine
Wrapper
Wrapper
Query in the
Query in mediated schema
query execution plan
Distributed
union of exported
source schemas
source schema
Query in the exported
Query Optimization
source schema
Query in the
Global Data Model
Local Data Model
Data modeling:. inatraditionaldatabaseapplicationone beginsby
modelingtherequirementsof theapplication,and designinga database
schema that appropriately supports the application. As noted earlier,
a data integration application begins from a set of pre-existing data
sources. Hence, the rst step of the application designer is to develop
amediated schema (oftenreferred to asaglobal schema) thatdescribes
thedatathatexistsinthesources,and exposes theaspects ofthisdata
that may be of interest to users. Note that the mediated schema does
notnecessarily contain all therelations and attributes modeled ineach
of the sources. Users pose queries in terms of the mediated schema,
rather than directly in terms of the source schemas. As such, the
me-diated schema is a set of virtual relations, in the sense that they are
not actually stored anywhere. For example, in the movie domain, the
mediated schema may contain the relation Movie(title, year,
di-rector, genre) describing the dierent properties of a movie, the
relationMovieActor(title, name),representingthecastofamovie,
MovieReview(title, review) representing reviews of movies, and
American(director)storing which directorsare American.
Along with the mediated schema, the application designer needs to
supply descriptions of the data sources. The descriptions specify the
relationshipbetweentherelations inthemediatedschema and those in
thelocalschemasat thesources. The descriptionof adatasource
spec-ies its contents (e.g., contains movies), attributes (e.g., genre, cast),
constraintson its contents (e.g., containsonly Americanmovies),
com-pleteness and reliability, and nally, its query processing capabilities
(e.g., can performselections, orcan answerarbitrary SQLqueries).
The fact that data sources are pre-existing requires that we be able
tohandlethefollowingcharacteristicsinthelanguagefordescribingthe
sources:
1. Overlapping andeven contradictory dataamong dierentsources.
2. Semanticmismatchesamongsources: sinceeachofthedatasources
hasbeendesignedbyadierentorganizationfordierentpurposes,
thedataismodeledindierentways. Forexample,onesourcemay
storearelationaldatabaseinwhichalltheattributesofa
particu-larmoviearestoredinone table,whileanothersourcemayspread
theattributesacross several relations. Furthermore,thenames of
theattributes and of the tables will be dierent from one source
to another,as willthechoice of what shouldbea table and what
shouldbe anattribute.
cludevarious conventions forspecifyingaddressesordates. Cases
in which persons are named dierently in the sources are harder
to deal with (e.g., one source contains the full name, while
an-othercontainsonlytheinitialsoftherstname). Arecentelegant
treatment of thisproblemispresented inCohen,1998.
Query reformulation:. a user of a data integration system poses
queries in terms of the mediated schema, rather than directly in the
schema in which the data is stored. As a consequence, a data
integra-tionsystem mustcontain a module thatuses the sourcedescriptionsin
order to reformulate a user query into a query that refers directly to
the schemas of the sources. Such a reformulation step does not exist
intraditionaldatabasesystems. Clearly,as thelanguagefor describing
data sources becomes more expressive,the reformulation step becomes
harder. Clearly,we would like the reformulation to be sound,(i.e., the
answers to the reformulated query shouldall be correct answers to the
inputquery), and complete (i.e., all the answers that can be extracted
from the data sources should be in the result of applying the
reformu-lated query). In addition, we want the reformulation to produce an
eÆcient query, e.g., to ensure that we do not access irrelevant sources
(i.e.,sourcesthatcannotcontributeanyanswerorpartialanswertothe
query).
Wrappers:. theotherlayerofadataintegrationsystemthatdoesnot
exist in a traditional system is the wrapper layer. Unlike a traditional
queryexecutionenginethatcommunicateswithalocalstoragemanager
tofetch thedata,thequeryexecutionplaninadataintegration system
must obtaindata from remote sources. A wrapperis a program which
is specic to a data source, whose task is to translate data from the
source to a form that is usable by the query processor of the system.
For example, if the data source is a web site, the task of the wrapper
isto translate thequeryto thesource'sinterface, and when theanswer
is returned as an HTML document, it needs to extract a set of tuples
fromthatdocument. (Clearly,theemergence of XML asastandardfor
dataexchangeontheWWWwillalleviatemuchofthewrapperbuilding
problem).
Queryoptimizationandexecution:. atraditionalrelationaldatabase
system accepts a declarative SQL query. The query is rst parsedand
thenpassedtothequery optimizer. The roleof theoptimizeristo
species the order in which to perform the dierent operations in the
query (join, selection, projection), a specic algorithm to use for each
operation (e.g., sort-merge join, hash-join), and the scheduling of the
dierent operators. Typically, the optimizer selects a query execution
plan by searching a space of possible plans, and comparing their
esti-matedcost. Toevaluatethecostofaqueryexecutionplantheoptimizer
relieson extensive statistics abouttheunderlyingdata, such assizes of
relations, sizes of domains and the selectivity of predicates. Finally,
thequeryexecution planispassedto the queryexecutionenginewhich
evaluatesthequery.
The main dierences between the traditional database context and
thatof dataintegration arethe following:
Since the sources are autonomous, the optimizer may have no
statistics about the sources, or unreliableones. Hence, the
opti-mizercannotcomparebetweendierentplans,becausetheircosts
cannotbeestimated.
Since the data sources are not necessarily database systems, the
sources may appear to have dierent processing capabilities. For
example,onedatasourcemaybeawebinterfacetoalegacy
infor-mationsystem, whileanother may be a program that scans data
storedin a structured le (e.g., bibliographyentries). Hence, the
queryoptimizerneedsto considerthe possibilityof exploitingthe
queryprocessingcapabilitiesofadatasource. Notethatquery
op-timizersindistributeddatabasesystems alsoevaluatewhereparts
of the query shouldbe executed, but in a context where the
dif-ferent processors have identical capabilities.
Finally,inatraditionalsystem,theoptimizercanreliablyestimate
thetimetotransfer datafrom thediscto mainmemory. Butin a
dataintegrationsystem,dataisoftentransferredoverawide-area
network, and hence delays may occur for a multitude of reasons.
Therefore, even a plan that appears to be the best based on cost
estimates may turn out to be ineÆcient if there are unexpected
delays in transferringdata from one of the sources accessed early
oninthe plan.
4. MODELING DATA SOURCES AND
QUERY REFORMULATION
As described in theprevious section, one of the maindierences
ever,isstoredinthedatasources,organizedunderlocalschemas. Hence,
in order for the data integration system to answer queries, there must
besome descriptionoftherelationshipbetweenthesourcerelationsand
the mediated schema. The query processor of the integration system
mustbe abletoreformulateaqueryposedonthemediatedschemainto
aquery againstthesourceschemas.
In principle, one could use arbitrary formulas in rst-order logic to
describe the data sources. But in such a case, sound and complete
re-formulation would be practically impossible. Hence,several approaches
havebeenexploredinwhichrestrictedformsofrst-orderformulashave
beenusedinsourcedescriptions,andeectiveaccompanying
reformula-tionalgorithmshavebeenpresented. We describetwo suchapproaches:
the Global as view approach (GAV) Garcia-Molina et al., 1997;
Pa-pakonstantinou et al., 1996; Adali et al., 1996; Florescu et al., 1996,
and the Local as view approach (LAV) Levy et al., 1996b; Kwok and
Weld,1996; Duschka and Genesereth, 1997a; Duschka and Genesereth,
1997b;Friedmanand Weld,1997;Ives etal.,1999.
Global As View:. In theGAV approach, for each relation R in the
mediatedschema, we writea query overthe sourcerelations specifying
how to obtainR 'stuplesfrom thesources.
Forexample, supposewehave two sources DB
1
and DB
2
containing
titles, actors and years of movies. We can describe the relationship
betweenthesourcesandthemediatedschemarelationMovieActoras
follows:
DB
1
(id;title;actor;year) ) MovieActor(title;actor)
DB
2
(id;title;actor;year) ) MovieActor(title;actor).
Ifwe have a thirdsource thatsharesmovieidentierswithDB
1 and
provides movie reviews, thefollowingsentence describeshow to obtain
tuplesfortheMovieReview relation:
DB
1
(id;title;actor;year)^DB
3
(id;review))
MovieReview(title;review)
In general, GAV descriptions are Horn rules that have a relation in
themediatedschemaintheconsequent,andaconjunctionofatomsover
thesourcerelationsin theantecedent.
Query reformulation in GAV is relatively straightforward. Since the
relations in the mediated schema are dened in terms of the source
relations, we need only unfold the denitions of the mediated schema
q(title;review) : MovieActor(title,`Brando'),
MovieReview(title, review).
Unfolding the descriptions of MovieActor and MovieReview will
yieldthefollowingqueriesoverthesourcerelations: (thesecondofwhich
willobviously bedeemedredundant)
q(title;review) : DB
1
(id;title;`Brando 0 ;year);DB 3 (id;review) q(title;review) : DB 1
(id;title;`Brando 0 ;year); DB 2 (id;`Brando 0 ;year);DB 3 (id;review)
Local As View:. The LAV approach the descriptions of the sources
aregivenintheoppositedirection. Thatis,thecontentsofadatasource
aredescribedasa query over themediatedschema relation.
Supposewe have two sources: (1)V
1
,containing titles,years and
di-rectorsofAmericancomediesproducedafter1960,and(2)V
2
containing
movie reviews produced after 1990. In LAV, we would describe these
sources by the following formulas (variables that appear only on the
righthandsidesare assumedto be existentiallyquantied):
S
1 :V
1
(title;year;director)) Movie(title,year, director,genre) ^
American(director)^ year 1960 ^genre=Comedy. S 2 :V 2
(title;review)) Movie(title, year, director,genre) ^ year1990 ^
MovieReview(title, review).
Query reformulation in LAV is more tricky than in GAV, because it
is not possible to simply unfold the denitions of the relations in the
mediatedschema. Forexample, supposeour query asksfor reviewsfor
comediesproducedafter 1950:
q(title;review) : Movie(title;year;director;Comedy);year1950;
MovieReview(title;review).
Thereformulatedqueryon thesources wouldbe:
q 0
(title;review): V
1
(title;year;director);V
2
(title;review).
Notethatinthiscase,thereformulatedqueryisnotequivalenttothe
originalquery,because itonlyreturns movies that were produced after
1990. However, given that we only have the sources S
1 and S
2
, this is
thebest reformulation possible. In the next section we dene precisely
A Comparison of the Approaches:. The main advantage of the
GAV approach is that query reformulation is very simple, because it
reducesto ruleunfolding. However, adding sourcesto thedata
integra-tion system is non-trivial. In particular, given a new source, we need
to gure out all the ways in which it can be used to obtain tuples for
eachoftherelationsinthemediatedschema. Therefore,weneedto
con-siderthepossibleinteractionofthenewsourcewitheachoftheexisting
sources, and this limits the ability of the GAV approach to scale to a
largecollectionof sources.
Incontrast,intheLAVapproacheachsourceisdescribedinisolation.
It is the system's task to gure out (at query time) how the sources
interactand howtheir datacan be combined to answerthe query. The
downside,however,isthatqueryreformulationisharder,andsometimes
requires recursivequeries over thesources. An additional advantage of
theLAV approach is that it is easier to specify rich constraints on the
contentsofasource(simplybyspecifyingmore conditionsinthesource
descriptions). Specifying complex constraints on sources is essential if
thedataintegrationsystemistodistinguishbetweensourceswithclosely
related and overlapping data. Finally, Friedman etal., 1999 described
the GLAV language that combines the expressive power of GAV and
LAV, andquery reformulation complexityisthe same asforLAV.
5. ANSWERING QUERIES USING VIEWS
The reformulation problem for LAV can be intuitively explained as
follows. BecauseoftheformoftheLAVdescriptions,eachofthesources
can be viewed as containing an answer to a query over the mediated
schema(ananswer tothequery expressedbytheright handsideof the
source description). Hence, sources represent materialized answers to
queries over the virtual mediated schema. A user query is also posed
over the mediated schema. The problem is therefore to nd a way of
answeringtheuserqueryusingonlytheanswerstothequeriesdescribing
thesources.
The problem of answering a query using a set of previously
ma-terialized views has received signicant attention because of its
rele-vancetootherdatabaseproblems,suchasqueryoptimizationChaudhuri
etal., 1995, maintaining physicaldata independence Yang and Larson,
1987;Tsatalos etal.,1996, and datawarehousedesign.
Formally,supposewearegivenaqueryQandasetofviewdenitions
V
1 ;:::;V
m
. Arewritingofthequeryusingtheviewsisaqueryexpression
Q 0
distinguishbetweentwo typesofqueryrewritings: equivalentrewritings
and maximally-contained rewritings.
Denition2: (Equivalent rewritings). Let Q be a query and V =
V
1 ;:::;V
m
be a set of view denitions. The query Q 0
is an equivalent
rewritingofQ usingVif:
Q 0
refersonlyto the viewsinV,and
Q 0
is equivalentto Q.
Denition3: (Maximally-containedrewritings). LetQbeaquery
and V =V
1 ;:::;V
m
be a set of view denitions ina query language L.
Thequery Q 0
is a maximally-containedrewriting of QusingV w.r.t. L
if:
Q 0
refersonlythe viewsinV,
Q 0 is contained inQ, and there is no rewriting Q 1 , such that Q 0 Q 1 Q and Q 1 is not equivalentto Q 0 .
Equivalent rewritings of aquery are neededwhen materialized views
are used for query optimization and physical data independence. In
the data integration context, we usually need to settle for
maximally-contained rewritings, because, as we saw in the previous section, the
sourcesdonotnecessarilycontain alltheinformationneededto provide
anequivalent answerto the query.
Recent research has considered many variants of the problem of
an-swering queriesusingviews(see Levy,1999 forasurvey). The problem
hasbeenshowntobeNP-completeevenwhenthequeriesdescribingthe
sourcesandtheuserqueryareconjunctiveanddon'tcontaininterpreted
predicatesLevyetal.,1995. Infact, Levyetal.,1995showsthatinthe
case of conjunctive queries, we can limit the candidate rewritings that
we considerto those that have at most the number of subgoals in the
query. Importantly,the complexityof theproblemispolynomialinthe
numberofviews(i.e.,thenumberofdatasourcesinthecontext ofdata
integration).
Inwhatfollowswedescribetwoalgorithmsforansweringqueriesusing
viewsthatweredevelopedspecicallyforthecontextofdataintegration.
These algorithms are the bucket algorithm developed in thecontext of
the Information Manifold system Levy et al., 1996b, and the
inverse-rules algorithm Qian, 1996; Duschka and Genesereth, 1997b; Duschka
5.1 THE BUCKET ALGORITHM
Thegoal of the bucketalgorithm is to reformulate a user query that
is posed on a mediated (virtual) schema into a query that refers
di-rectlyto theavailabledatasources. Boththequeryand thesourcesare
describedbyselect-project-joinqueriesthatmayincludeatomsof
arith-meticcomparisonpredicates(hereafterreferredtosimplyaspredicates).
Thebucket algorithmreturns themaximallycontainedrewritingof the
queryusingtheviews.
Themain idea underlyingthebucket algorithm isthat the (possibly
exponential)numberof queryrewritingsthatneedtobeconsideredcan
be drasticallyreduced if we rst consider each subgoal in the query in
isolation, and determine which views may be relevant to each subgoal.
GivenaqueryQ,thebucketalgorithmproceedsintwosteps. Intherst
step,thealgorithmcreatesabucketforeachsubgoalinQ,containingthe
views (i.e., data sources) that are relevant to answeringthe particular
subgoal. More formally,aview V isputinthebucket ofa subgoalg in
thequeryifthedenitionof V contains asubgoalg
1
such that
gand g
1
can be unied,and
afterapplying theunierto the queryand to thevariablesof the
view that appear in the head, the predicates in Q and in V are
mutuallysatisable.
TheactualbucketcontainstheheadoftheviewV after applyingthe
unierto the head of the view. Note that a subgoal g may unify with
morethanone subgoalinaviewV,andinthatcasethebucketofgwill
containmultipleoccurrencesof V.
Inthesecond step,thealgorithm considersquery rewritingsthat are
conjunctive queries, each consisting of one conjunct from every bucket.
Specically, for each possible choice of element from each bucket, the
algorithm checks whether the resulting conjunction is contained in the
queryQ, or whetherit can bemade to be containedifadditional
pred-icates are added to the rewriting. If so, the rewriting is added to the
answer. Hence,theresultofthebucketalgorithmisaunionof
conjunc-tive rewritings.
Example5..1: Consideranexampleincludingviewsoverthefollowing
schema:
Enrolled(student,dept) Registered(student, course, year)
Course(course,number),
number500, year1992.
V2(student,dept,course) :-Registered(student,course,year),
Enrolled(student,dept)
V3(student,course):- Registered(student,course,year), year1990.
V4(student,course,number) :- Registered(student,course,year),
Course(course,number),
Enrolled(student,dept),number100
Supposeourqueryis:
q(S,D):-Enrolled(S,D), Registered(S,C,Y), Course(C,N),N300, Y1995.
In the rst step of the algorithm we create a bucket for each of the
relationalsubgoals in the query in turn. The resulting contents of the
bucketsareshowninTable1.1. The bucketofEnrolled(S,D)willinclude
theviewsV2andV4,sincethefollowingmappingmapstheatominthe
queryintothecorresponding Enrolled atomin theviews:
fS ! student,D !dept g.
Note that the view head inthe bucket onlyincludesthe variablesin
thedomain of the mapping,and fresh variables (primed) forthe other
headvariables oftheview.
ThebucketofthesubgoalRegistered(S,C,Y)willcontaintheviewsV1,
V2andV4sincethefollowingmappingmapstheatominthequeryinto
thecorresponding Registeredatom intheviews:
fS ! student,C ! course, Y! yearg.
Enrolled(S,D) Registered(S,C,Y) Course(C,N)
V2(S,D,C') V1(S,N',Y) V1(S',N,Y')
V4(S,C',N') V2(S,D',C)
V4(S,C,N')
Table1.1 Contentsofthe buckets. Theprimedvariablesare thosethatare notin
thedomainoftheunifyingmapping.
TheviewV3isnotincludedinthebucketofRegistered(S,C,Y)because
thepredicatesY1995 and year1990 aremutuallyinconsistent. On
mutuallyinconsistent. However, the point to note is that the mapping
fromthequery to theview does notmapthevariableD to thevariable
numberinV4. Hence,thecontradiction doesnotarise. 1
Next, consider the bucket of the subgoal Course(C,N). The view V1
willbe includedinthe bucketbecauseof themapping
fC ! course, N! numberg.
NotethatinthiscasetheviewV4isnot includedinthebucketbecause
theunierdoesmapNtonumber,andhencethepredicatesonthecourse
numberwouldbemutuallyinconsistent.
In the second step of the algorithm, we combine elements from the
buckets. Inourexample, theonlycombination thatwould yielda
solu-tionis joiningV1and V2 asfollows:
q'(S,D):- V1(S,N, Y),V2(S,D,C),Y1995.
Theonlyother option thatwouldnot involve a redundant view
sub-goal in the rewriting, would involve a join between V1 and V4 and is
dismissed because the two views contain disjoint numbers of courses
(greater than 500 for V1 and less than 100 for V4). In this case, the
views V1 and V4 are relevant to the query in isolation, but, if joined,
producethe empty answer. Finally,thereader shouldalso notethat in
this example, as usually happens in the data integration context, the
algorithmproduceda maximally-contained rewritingofthequeryusing
theviews,and not anequivalent rewriting.
5.2 THE INVERSE-RULES ALGORITHM
Like the bucket algorithm, the inverse-rules algorithm was also
de-veloped inthecontext ofa dataintegration system Duschka and
Gene-sereth, 1997b. The key idea underlyingthe algorithm is to construct a
setof rulesthatinvert theview denitions,i.e., rulesthat showhowto
computetuplesfor thedatabaserelations from tuplesof theviews. We
illustrateinverse ruleswith anexample.
Supposewe have thefollowingview:
V3(dept,c-name) :- Enrolled(s-name,dept), Registered(s-name,c-name).
Weconstructoneinverseruleforeveryconjunctinthebodyoftheview:
Enrolled(f
1
(dept,X),dept) :-V3(dept,X)
Registered(f
1
(Y,c-name), c-name) :-V3(Y,c-name)
tuples in the relations Enrolled and Registered. The witness provides
onlypartialinformation,andhidestherest. Inparticular,ittellsustwo
things:
the relation Enrolled contains a tuple of the form (Z, dept), for
some value ofZ.
therelationRegisteredcontains atupleof the form(Z, name), for
thesame value ofZ.
In order to express the information that the unknown value of Z is
the same in the two atoms, we refer to it using the functional term
f
1
(dept,name). NotethattheremaybeseveralvaluesofZinthedatabase
thatcausethetuple(dept,name)to beinthejoinof Enrolledand
Regis-tered,butall thatmattersis thatthere existsat least one suchvalue.
Ingeneral,wecreateonefunctionsymbolforeveryexistentialvariable
thatappearsintheviewdenitions,andthesefunctionsymbolsareused
intheheadsof theinverserules.
The rewriting of a query Q using the set of views V is the datalog
programthat includes
theinverse rulesforV, and
thequeryQ.
As shown inDuschka and Genesereth, 1997a, the inverse-rules
algo-rithmreturns the maximallycontainedrewriting ofQ usingV. Infact,
the algorithm returns the maximally contained query even if Q is an
arbitrarydatalogprogram.
Example5..2 : Supposeourquery asksforthe departmentsinwhich
thestudentsof the\Database" courseareenrolled,
q(dept):- Enrolled(s-name,dept), Registered(s-name,\Database")
and theviewV3 includesthetuples:
f(CS, \Database"),(EE, \Database"),(CS, \AI") g
Theinverserules wouldcompute thefollowingtuples:
Registered: f (f 1 (CS,\Database"), CS), (f 1 (EE,\Database"), EE), (f 1 (CS,\AI"), CS)g Enrolled: f (f 1 (CS,\Database"),\Database"), (f 1 (EE,\Database"),\Database",), (f 1 (CS,\AI"),\AI") g
Inthisexampleweshowedhowfunctionaltermsaregeneratedaspart
of the evaluation of the inverse rules. However, the resulting rewriting
can actually be rewritten in such a way that no functional terms
ap-pear Duschka and Genesereth,1997a.
5.3 COMPARISON OF THE ALGORITHMS
Thereare several interestingsimilarities and dierences between the
bucketandinverserulesalgorithmsthatareworthnoting. Inparticular,
thestep of computing buckets is similar in spiritto that of computing
theinverserules,becausebothofthemcomputetheviewsthatare
rele-vantto singleatomsofthedatabaserelations. Thedierenceisthatthe
bucketalgorithmcomputes therelevant viewsbytaking into
considera-tionthecontext inwhichtheatomappearsinthequery,whiletheinverse
rules algorithm does not. Hence, if the predicates in a view denition
entail thatthe view cannot providetuplesrelevant to a query(because
they are mutuallyunsatisable with thepredicates inthe query), then
the view will not end up in a bucket. In contrast, the query rewriting
obtained by the inverse rules algorithm may result in containing views
that are not relevant to the query. However, the inverse rules can be
computed once, and be applicable to any query. In order to remove
irrelevant views from therewriting produced by the inverse-rules
algo-rithm we needto apply a subsequent constraint propagation phase (as
inLevyetal.,1997; Srivastava and Ramakrishnan,1992).
Thestrengthofthebucketalgorithmisthatitexploitsthepredicates
inthequeryto prunesignicantlythenumberof candidateconjunctive
rewritingsthat needto beconsidered. Checkingwhether aview should
belong to a bucket can be done in time polynomial in the size of the
query and view denitionswhen thepredicates involved are arithmetic
comparisons. Hence,ifthe datasources (i.e.,theviews) areindeed
dis-tinguishedbyhavingdierentcomparisonpredicates,thentheresulting
bucketswillberelativelysmall. In thesecond step,thealgorithm needs
toperformaquerycontainment testforevery candidaterewriting. The
testing problem is p
2
-complete, but only in the size of the query and
theviewdenition,and hencequiteeÆcientinpractice. Thebucket
al-gorithmalso extends naturally to unionsof conjunctive queries, and to
otherformsofpredicates inthequerysuchasclass hierarchies. Finally,
thebucketalgorithm alsomakesitpossibleto identifyopportunitiesfor
interleavingoptimization and executionina dataintegration systemin
cases where one of the buckets contains an especially large number of
The inverse-rulesalgorithmhastheadvantageofbeingmodular. The
inverse rules can be computed ahead of time, independent of a specic
query. AsshowninDuschkaandGenesereth,1997a; Duschkaand Levy,
1997,extendingthealgorithmtohandlefunctionaldependencies onthe
database schema, recursive queries or the existence of binding pattern
limitationscan be doneby adding another set of rules to the resulting
rewriting. Unfortunately,thealgorithmdoesnothandlearithmetic
com-parisonpredicates,andextendingittohandlesuchpredicatesturnsout
to be quite subtle. The algorithm produces the maximally-contained
rewriting in time that is polynomial in the size of the query and the
views(butthe complexityof removingirrelevant viewshasexponential
timecomplexityLevyetal., 1997).
MiniCon Algorithm Pottinger and Levy, 1999 builds on the ideas of
both the bucket algorithm and the inverse rules algorithm. Extensive
experimentsdescribedinPottinger and Levy,1999 show thatthe
Mini-Con algorithm signicantly outperforms both of its predecessors, and
scalesup gracefullyto hundredsand even thousands ofviews.
5.4 THE NEED FOR RECURSIVE
REWRITINGS
An interestingphenomenoninseveral variantsof LAV descriptionsis
thatthe reformulatedquery may actuallyhave to berecursive inorder
to provide themaximal answer. The most interesting of these variants
is the common case in which data sources can only be accessed with
particularpatterns.
Considerthefollowingexample,wheretherstsourceprovidespapers
(for simplicity,identiedby their title) publishedin AAAI, thesecond
source records citations among papers,and the third source stores
pa-pers that have won signicant awards. The superscripts in the source
descriptionsdepicttheaccesspatternsthat areavailabletothesources.
Thesuperscriptscontainstringsoverthealphabetfb;fg. Ifa bappears
in the i'th position, then the source requires a binding for the i'th
at-tributeinorder to produceprovideanswers. Ifan f appears inthei'th
position, thenthei'th attributemay be either boundor not. From the
rst source we can obtainall the AAAIpapers (no bindingsrequired);
to obtaindata from the second source, we rst mustprovidea binding
forapaperandthenreceivethesetofpapersthatitcites;withthethird
sourcewecan onlyquerywhethera given paperwonan award,butnot
askforall theawardwinningpapers.
AAAIdb f
(X))AAAIPapers(X)
AwardDB b
(X))AwardPaper(X)
Supposeourqueryis to ndalltheaward winningpapers:
Q(X): AwardPaper(X)
Asthe following queries show, there is no nite numberof conjunctive
queriesoverthesourcesthatisguaranteedto provideall theanswersto
thequery. In each query,we can start from theAAAI database, follow
citationchainsoflengthn, andfeedtheresultsintotheawarddatabase.
Since we cannot limit the length of a citation chain we need to follow
apriori(withoutexaminingthedata), wecannotputaboundonthesize
ofthereformulatedquery.
Q 0 (X): AAAIdb(X);AwardDB(X) Q 0 (X): AAAIdb(V);CitationDB(V;X 1 );:::;CitationDB(X n ;X); AwardDB(X):
However,ifweconsiderrecursivequeriesoverthesources,wecanobtain
aniteconcisequerythatprovidesalltheanswers,asfollows(notethat
the newly invented relation papers is meant to represent the set of all
papersreachable from theAAAIdatabase):
papers(X): AAAIdb(X)
papers(X): papers(Y);CitationDB(Y;X)
Q 0
(X): papers(X);AwardDB(X).
Othercases inwhich recursion may be necessary are inthe presence
of functionaldependencieson themediated schema Duschka and Levy,
1997,when theuser query isrecursive Duschka and Genesereth,1997a,
and,asweshowinthenextsection,whenthedescriptionsofthesources
areenrichedbydescriptionlogicsBeeri et al.,1997.
Finally,itturnsoutthatslightchanges totheformofsource
descrip-tions in LAV can cause the problem of answering queries to become
NP-hardin thesize of thedata in thesources Abitebouland Duschka,
1998. One exampleof such a case iswhen thequery containsthe
pred-icate 6=. Other examples include cases in whichthe sources areknown
to becomplete w.r.t. theirdescriptions (i.e.,wherethe ) inthesource
descriptionis replaced by,).
6. THE USE OF DESCRIPTION LOGICS
Thusfar,wehavedescribedthemediatedschemaandthelocalschemas
as at sets of relations. However, in many applications we would like
un-amodel. Furthermore,providing themappingbetweensource relations
andamediatedschemaisconsiderablyfacilitatedwhenthethemediated
schema is part of a rich domain model. Several works have considered
theuseofaricherrepresentationbasedondescriptionlogicsinthe
medi-atedschemaArensetal.,1996;CatarciandLenzerini,1993;Levyetal.,
1996a; Lattesand Rousset, 1998.
Description logics are a family of logics for modeling complex
hier-archical structures. In a descriptionlogic it is possibleto intensionally
dene sets of objects, called concepts, using descriptions built from a
setofconstructors. Forexample,thesetPerson u(3child) u(8 child
smart)describesthesetofobjectsbelongingtotheclasspersonwhohave
atmost3children,andalloftheirchildrenbelongto theclasssmart. In
additionto deningconcepts, it is also possibleto state that an object
belongs to a concept. In fact, it is possible to say that Fred belongs
to theabove concept,without specifyingwho his childrenare, and how
manythere are.
As originally suggested in Catarci and Lenzerini, 1993, when the
source descriptions and mediated schema both use description logics,
itis possibleto use thereasoning service of the underlyinglogicto
de-tect when a source is relevant to a query. However, desciption logics
in themselves are not expressive enough to model arbitrary relational
data. In particular, they are unableto express arbitrary joins of
rela-tions. Hence,several hybrid languages combining the expressive power
of Horn rules and description logics have been investigated Levy and
Rousset,1998; Doninietal.,1991; MacGregor,1994; Cadoliet al.,1997
withassociatedreasoningalgorithms.
Answeringqueriesusingviewsinthecontextofthesehybridlanguages
isstilllargelyanopen problem. Asthefollowingexampleshows,inthe
presence the rewriting of a query using a set of views may need to be
recursive.
Example6..1: Consider thefollowingtwo views:
v
1
(X;Y): child(X;Y);child (X;Z);( 1child)(Z)
v
2
(X): ( 3child )(X).
The atom ( 1child)(X) denotes the set of objects that have at most
one child. Similarly,( 3child)(X) denotes theobjectswith 3 children
ormore. SupposethequeryQistondallindividualswhohaveatleast
Foranyn,thefollowingconjunctivequeryisarewritingthatiscontained inQ: q 0 n (X) : v 1 (X;Y 1 );v 1 (Y 1 ;Y 2 );v 1 (Y n ;U);v 2 (U):
To see why, consider the variable Y
n
. The view v
1
entails that it has
one ller for the role child that has less than one child (the variable Z
in the denition of v
1
) while the view v
2
says that its child U has at
least 3 children. Therefore, Y
n
has at least 2 children. The same line
of reasoning can be used to see that Y
n 1
has at least 2 children, and
continuinginthesame way,wegetthatXhasat leasttwochildren,i.e.,
q(X)holds. Thepointisthatinferringq(X)requiredachainofinference
that involved an arbitrary number of constants, and the length of the
chain doesnotdependonthe queryortheviews. Furthermore,forany
value of n, we can builda database such that the unionof q 0 1 ;:::;q 0 n is
not the maximally-containedrewriting, and therefore we cannot nd a
maximally-containedrewritingthatis aunion of conjunctivequeries.
We can still nda maximally-contained rewriting in thisexample if
weallowtherewritingto bearecursivedatalogprogram. Thefollowing
isa maximally-containedrewriting: q 0 (X): v 2 (X) q 0 (X): v 1 (X;Y);q 0 (Y).
This recursive program essentially mimics the lineof reasoning we
de-scribed above.
The problem of answering queries using views in the context of
de-scriptionlogicsisfurtherdiscussedinBeerietal.,1997;Calvaneseetal.,
1999. InBeerietal.,1997itisshownthatunderverytightrestrictions,it
isalways possibleto nda maximally-containedrewritingof the query
using a set of views, and otherwise, it may not be possible to nd a
maximallycontainedrewritingindatalog.
7. CONCLUDING REMARKS
InthisarticleItoucheduponsomeoftheproblemsofdataintegration
inwhich logic-basedmethodsprovidedusefulsolutions. In particular,I
showedhowsemanticrelationshipsbetweenthecontentsofdatasources
andrelationsinamediatedschemacan bespeciedusinglimitedforms
of logic, and illustrated theassociated reasoning algorithms. There are
additionalareas inwhich logicbased techniques have beenapplied,
in-cluding descriptions of source completeness Etzioni et al., 1994; Levy,
There are two areas in which I believe signicant future research is
required. The rst area concernstherole of more expressive knowledge
representation languages in data integration. Currently, relatively
lit-tle isknownaboutthe queryreformulation problemincases where the
mediatedschemaand/or thedatasourceschemasare described usinga
richerknowledgerepresentationlanguage. In addition,weneedto
care-fully study which extensions to the expressive power are really needed
inpractice.
The second area, which is of wider applicability than the problem
of data integration, concerns extending logicalreasoning techniques to
dealwithnon-logicalextensions thathavebeenneededindatabase
sys-tems. Inordertodealwithrealworldapplications,commercialdatabase
systems provide support for dealing with issues such as bag (multiset)
semantics, grouping and aggregation, and nested structures. In order
to deal with many real world domains, we need to develop reasoning
techniques(extensionsofquery containment algorithmsand algorithms
foransweringqueriesusingviews) to settingswhere thequeriesinvolve
bags,groupingandaggregation,andnestedstructures(seeCohenetal.,
1999; Levy and Suciu, 1997; Chaudhuri and Vardi, 1993; Srivastava
etal.,1996 forsome workin theseareas). Anotherinterestingquestion
is whether some of these features can be incorporated into knowledge
representation languages.
Notes
1. However,ifwealsoknew that thecoursenamefunctionallydeterminesits number,
Abiteboul,S.and Duschka,O. (1998). Complexityof answeringqueries
using materialized views. In Proc. of the ACM
SIGACT-SIGMOD-SIGARTSymposiumonPrinciplesofDatabaseSystems(PODS),
Seat-tle, WA.
Adali, S., Candan, K., Papakonstantinou, Y., and Subrahmanian, V.
(1996). Query caching and optimization indistributedmediator
sys-tems. In Proc. of ACM SIGMOD Conf. on Management of Data,
Montreal, Canada.
Arens, Y., Knoblock, C. A., and Shen, W.-M. (1996). Query
reformu-lation for dynamicinformationintegration. International Journal on
Intelligent and Cooperative Information Systems, (6) 2/3:99{130.
Beeri, C., Levy, A. Y., and Rousset, M.-C. (1997). Rewriting queries
using views in description logics. In Proc. of the ACM
SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems
(PODS), Tucson, Arizona.
Cadoli, M., Palopoli, L., and Lenzerini, M. (1997). Datalog and
de-scriptionlogics:Expressivepower.InProceedings of theInternational
Workshop on Database Programming Languages.
Calvanese, D., Giacomo, G. D., and Lenzerini, M. (1999). Answering
queries using views in description logics. In Working notes of the
KRDB Workshop.
Catarci, T. and Lenzerini, M. (1993). Representing and using
inter-schemaknowledgeincooperativeinformationsystems.Journal of
In-telligent and Cooperative Information Systems.
Chandra, A. and Merlin, P. (1977). Optimal implementation of
con-junctive queries in relational databases. In Proceedings of the Ninth
Chaudhuri,S.,Krishnamurthy,R.,Potamianos,S.,andShim,K.(1995).
Optimizingquerieswithmaterialized views.InProc.of Int.Conf. on
Data Engineering (ICDE),Taipei, Taiwan.
Chaudhuri,S.andVardi,M.(1993).Optimizingrealconjunctivequeries.
InProc.oftheACMSIGACT-SIGMOD-SIGARTSymposiumon
Prin-ciples of Database Systems(PODS), pages 59{70, Washington D.C.
Chaudhuri,S. and Vardi, M. (1994). On the complexity of equivalence
between recursive and nonrecursive datalog programs. In Proc. of
the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of
DatabaseSystems (PODS), pages55{66, Minneapolis, Minnesota.
Cohen, S., Nutt, W., and Serebrenik, A. (1999). Rewriting aggregate
queriesusingviews.InProc.oftheACMSIGACT-SIGMOD-SIGART
Symposium on Principles of Database Systems (PODS), pages 155{
166.
Cohen,W.(1998).Integrationofheterogeneousdatabaseswithout
com-mon domains using queries based on textual similarity. In Proc. of
ACM SIGMODConf. on Management of Data, Seattle, WA.
Donini,F.M.,Lenzerini,M.,Nardi,D.,andSchaerf,A.(1991).Ahybrid
systemwithdatalogandconcept languages.InArdizzone,E.,Gaglio,
S.,and Sorbello,F.,editors, Trends in Articial Intelligence, volume
LNAI549,pages 88{97. SpringerVerlag.
Duschka, O. (1997). Query optimization using local completeness. In
ProceedingsoftheAAAIFourteenth NationalConferenceonArticial
Intelligence.
Duschka,O.,Genesereth,M.,andLevy,A.(1999).Recursivequeryplans
fordata integration. Journal of Logic Programming, special issue on
Logic Based Heterogeneous Information Systems.
Duschka, O. M. and Genesereth, M. R. (1997a). Answering recursive
queriesusingviews.InProc.oftheACMSIGACT-SIGMOD-SIGART
Symposium on Principles of Database Systems (PODS),Tucson,
Ari-zona.
Duschka,O.M.andGenesereth,M.R.(1997b).Queryplanningin
info-master.InProceedingsoftheACMSymposiumonAppliedComputing,
SanJose, CA.
Duschka,O.M.and Levy,A.Y.(1997).Recursiveplansforinformation
gathering.In Proceedings of the 15th International Joint Conference
on Articial Intelligence.
Etzioni, O., Golden, K., and Weld, D. (1994). Tractable closed world
reasoningwith updates.In Proceedings of the Conference on
Princi-ples of Knowledge Representation and Reasoning, KR-94. Extended
Florescu, D., Raschid, L., and Valduriez, P. (1996). Answering queries
usingOQL viewexpressions.In Workshop on Materialized Views, in
cooperation with ACM SIGMOD, Montreal,Canada.
Friedman, M., Levy, A., and Millstein, T. (1999). Navigational plans
for data integration. In Proceedings of the National Conference on
Articial Intelligence.
Friedman, M. and Weld, D. (1997). EÆcient execution of information
gathering plans.InProceedings of the International JointConference
on Articial Intelligence,Nagoya, Japan.
Garcia-Molina, H., Papakonstantinou, Y., Quass, D., Rajaraman, A.,
Sagiv, Y., Ullman,J., andWidom,J. (1997). The TSIMMISproject:
Integration of heterogeneous information sources. Journal of
Intelli-gent Information Systems,8(2):117{132.
Ives,Z.,Florescu, D., Friedman,M.,Levy,A.,and Weld,D.(1999). An
adaptivequeryexecutionenginefordataintegration.InProc.ofACM
SIGMOD Conf. on Management of Data.
Klug,A.(1988).Onconjunctivequeriescontaininginequalities.Journal
of the ACM,pages 35(1): 146{160.
Kwok,C.T.andWeld,D.S.(1996). Planningto gatherinformation.In
ProceedingsoftheAAAIThirteenthNationalConferenceonArticial
Intelligence.
Lattes, V.and Rousset, M.-C.(1998). The use ofthe CARIN language
and algorithms for information integration: the PICSEL project. In
Proceedings of the ECAI-98Workshop on IntelligentInformation
In-tegration.
Levy,A.andRousset, M.-C.(1998). CombiningHornrulesand
descrip-tion logics incarin.Articial Intelligence, 104:165{209.
Levy,A.Y.(1996).Obtainingcompleteanswersfromincompletedatabases.
In Proc. of the Int. Conf. on Very Large Data Bases (VLDB),
Bom-bay, India.
Levy,A.Y.(1999).Answeringqueriesusingviews:Asurvey.Submitted
for publication.
Levy, A.Y., Fikes, R. E., and Sagiv, S. (1997). Speedingup inferences
usingrelevancereasoning:A formalismand algorithms. Articial
In-telligence,97(1-2).
Levy,A.Y.,Mendelzon,A.O.,Sagiv,Y.,andSrivastava,D.(1995).
An-sweringqueriesusingviews.InProc.of theACM
SIGACT-SIGMOD-SIGARTSymposiumonPrinciples ofDatabaseSystems(PODS),San
Jose, CA.
Levy,A.Y.,Rajaraman,A.,andOrdille,J.J.(1996a).Queryanswering
Levy, A. Y., Rajaraman, A., and Ordille, J. J. (1996b). Querying
het-erogeneousinformationsources usingsourcedescriptions.InProc.of
the Int.Conf. on Very Large Data Bases (VLDB), Bombay, India.
Levy, A. Y., Rajaraman, A., and Ullman, J. D. (1996c). Answering
queriesusinglimitedexternalprocessors.InProc.oftheACM
SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems
(PODS),Montreal, Canada.
Levy, A. Y. and Sagiv, Y. (1993). Queries independent of updates. In
Proc. of the Int. Conf. on Very Large Data Bases (VLDB), pages
171{181, Dublin,Ireland.
Levy,A.Y.andSuciu,D.(1997).Decidingcontainmentforquerieswith
complex objects and aggregations. In Proc. of the ACM
SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems
(PODS),Tucson,Arizona.
Litwin, W., Mark, L., and Roussopoulos,N. (1990). Interoperability of
multipleautonomousdatabases.ACMComputingSurveys,22(3):267{
293.
MacGregor, R.M. (1994). A descriptionclassier forthepredicate
cal-culus.InProceedingsof theTwelfth NationalConferenceon Articial
Intelligence, pages213{220.
Papakonstantinou,Y.,Abiteboul,S.,andGarcia-Molina,H.(1996).
Ob-ject fusion in mediator systems. In Proc. of the Int. Conf. on Very
Large Data Bases(VLDB), Bombay,India.
Pottinger, R. and Levy, A. (1999). A scalable algorithm for answering
queriesusingviews.Submittedforpublication.
Qian,X.(1996).Queryfolding.InProc.ofInt.Conf.onData Engine
er-ing(ICDE), pages 48{55, NewOrleans, LA.
Sagiv, Y. (1988). Optimizing datalog programs. In Minker, J., editor,
Foundations of Deductive Databases and Logic Programming, pages
659{698. MorganKaufmann,Los Altos, CA.
Sagiv, Y. and Yannakakis, M. (1981). Equivalence among relational
expressions with the union and dierence operators. Journal of the
ACM,27(4):633{655.
Shmueli,O.(1993).Equivalenceofdatalogqueriesisundecidable.
Jour-nalof Logic Programming, 15:231{241.
Srivastava,D.,Dar,S.,Jagadish,H.V.,andLevy,A.Y.(1996).
Answer-ing SQL queries usingmaterialized views. In Proc. of the Int. Conf.
on Very Large Data Bases (VLDB), Bombay, India.
Srivastava, D. and Ramakrishnan, R. (1992). Pushing constraint
selec-tions. In Proc. of the ACM SIGACT-SIGMOD-SIGARTSymposium
Tsatalos, O. G., Solomon, M. H., and Ioannidis, Y. E. (1996). The
GMAP:Aversatiletoolforphysicaldataindependence.VLDB
Jour-nal, 5(2):101{118.
Vassalos, V. and Papakonstantinou, Y. (1997). Describing and using
query capabilitiesofheterogeneoussources.InProc.of the Int.Conf.
on Very Large Data Bases (VLDB), pages256{265, Athens, Greece.
Yang, H. Z. and Larson, P. A. (1987). Query transformation for
PSJ-queries.InProc.oftheInt.Conf.on VeryLargeData Bases(VLDB),