Shrinkage Estimation For Penalised Regression, Loss Estimation And Topics On Largest Eigenvalue Distributions.
147
0
0
Full text
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
(15)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
Figure
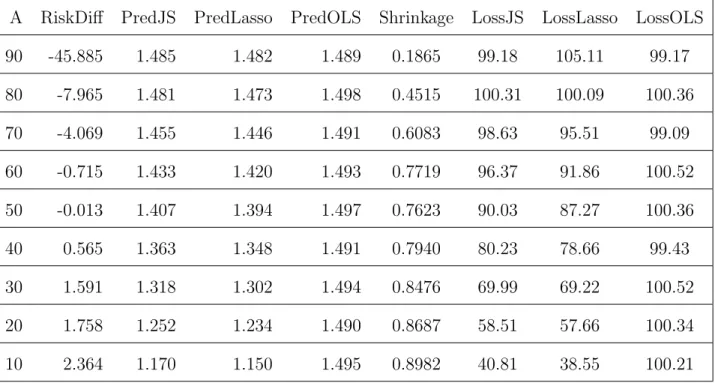
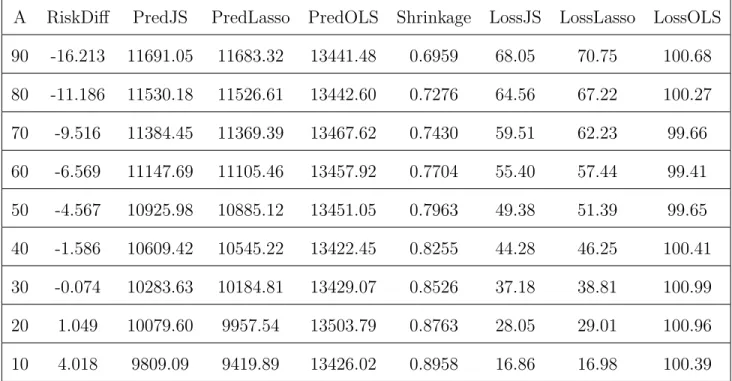
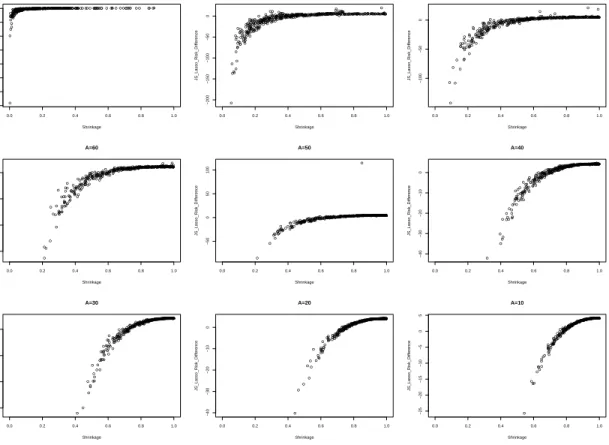
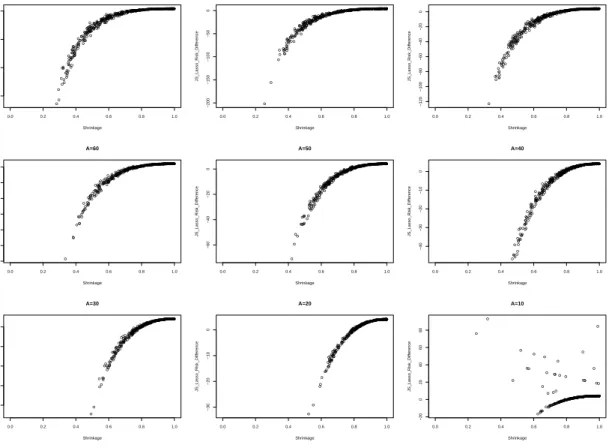
+7

Related documents
Insurance; environment; pollution; environmental insurance; first-party insurance; third-party insurance; first-party insurance for the benefit of a third party; statutory
This research study focuses upon the theoretical construct of self-efficacy, the improvement of college and career readiness as it relates to high school students, the importance
Croix County has a number of completed and ongoing land information improvement projects including Public Land Survey System remonumentation, geodetic control, parcel mapping,
The % removal of fluoride ion increased with the increase in added cationic surfactants concentration and decreased with the increasing [anionic surfactant], nonionic
Although the actual correlation level between L1/L5 channels should be validated during the next solar maximum, Figure 7 parametrically illustrates the expected availability
However, very small quantities of several organic acids are produced during primary fermentation, and under adverse conditions, bacteria in wine can produce enough
Although income protection is a higher priority in 2010, only one in four business owners – 24 percent -- has an individual disability insurance (IDI) policy, and only 4
