International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)249
A Combined Matching Function based Evolutionary
Approach for development of Adaptive Information
Retrieval System
Pragati Bhatnagar
1, N.K. Pareek
2,
1 Research Scholar , Department of Computer Science, M.L.S.U. , Udaipur, (Raj.) India 2 Department of Computer Science, M.L.S.U. , Udaipur, (Raj.) India
Abstract— The growth in the volume of the Web and other textual repositories has made Information Retrieval task difficult, costly and in many cases very complex for the end user. In this context search engines became valuable tools to help users find content relevant to their information needs. However finding relevant information based on user's need is still a challenge. Naturally research on information models that can effectively rank search results according to document relevance has become a fundamental subject. This paper proposes a combined matching function for improving efficiency of Information Retrieval System (IRS). The proposed system uses an Evolutionary approach for adapting weights of combined similarity function.
Overall layout of paper is as follows. In Section I and Section II we introduce the concept of Information Retrieval System, Evolutionary algorithm and appropriateness of evolutionary algorithm for retrieving relevant information. In section III we present the proposed model for adaptive IRS and algorithm for implementing proposed system. Section IV deals with experiments and results. Experiments have been performed on CISI data collection. Finally section V concludes the paper.
Keywords— Information Retrieval, Vector Space mode, Genetic Algorithm, Combined Similarity measure,
I. INTRODUCTION TO INFORMATION RETRIEVAL SYSTEMS
Information retrieval (IR) [1,3,11] is a field of study that helps the user to find needed information from a large collection of documents.
Retrieving information means finding a ranked set of documents that is relevant to the user query. The user with information need issues a query to the retrieval system through the query operational module. Information Retrieval System (IRS) deals with documentary bases containing textual, pictorial or vocal information and process user queries trying to allow the users to access the relevant information in an appropriate time interval.
A. Components of IRS:
An IRS consists of three basic components: Documentary Database, Query Subsystem, Matching mechanism [3].
1) The documentary database: This document
database stores document along with the representation of their information content. It is associated with the indexer module which automatically generates a representation of each document by extracting the document contents.
2) The Query Subsystem: It allows the user to specify
their information needs and presents the relevant documents retrieved by the system to them. The efficiency of a IRS system significantly depends upon query formation.
3) The Matching Mechanism: It evaluates the degree
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)250
B. Information Retrieval Models:
Information retrieval models govern how a document and a query are represented and how the relevance of a document to the user query is defined. The main IR models are [2]:
1) Boolean Model:The Boolean model is one of
the earliest and simplest information retrieval model. A document is represented on the basis of indexed terms using a binary indexing techniques. It uses the notion of exact matching to match document to the query.
2) Vector Space Model: VSM is perhaps the widely used and well known model. A document in VSM is represented as a weight vector of terms and each term weight is computed based on some variation of TF or TF-IDF (Term Frequency-Inverse Document Frequency) scheme. The query is also represented in the same way as of documents. 3) Statistical Language Models: Statistical
language model are based on probability and have some foundation in statistical theory. These probabilistic models compute the similarity coefficient between a query and a document as the probability that the document will be relevant to the query. There are two fundamental approaches : first relies on usage pattern to predict relevance and the another uses each term in the query as clues to whether or not a document is relevant[5]. C. Evaluation of IRS:
1) Precision: Precision is a fraction of document that are relevant among all the retrieved document. Practically it gives accuracy of result.
A
R
precision
a(1)
Ra : Set of relevant documents retrieved
A : Set of documents retrieved
2) Recall: Recall is a fraction of documents that are retrieved and relevant among the entire relevant document. Practically it gives coverage of result.
R
R
precision
a (2)Ra : Set of relevant documents retrieved
R : Set of all relevant documents
3) Precision-Recall Curve: This curve is based upon the value of precision and recall where the x-axis is recall and y-axis is precision. Instead of using precision and recall on at each rank position ,the curve is commonly plotted using 11 standard recall level 0%, 10%, 20% ………..100%.
4) F-score: In general, recall and precision of IRS are inversely proportional ie. system that have good recall find all the relevant articles but do so by searching more widely than user requires and so the items located cover too broad a range and precision is low. Another measure is f score that combines both precision and recall. f-score is harmonic mean of precision and recall.
precision
recall
precision
recall
fscore
2
(3)
II. EA`S APPROPRIATENESS FOR INFORMATION RETRIEVAL Evolutionary algorithms [2] are appropriate for Information retrieval problem, due to following reasons:
1) Information Retrieval can be considered as search
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)251
probability of finding false peak is reduced over other methods. Evolutionary algorithms are largely unconstraint (continuity, differentiability etc.) by limitation of many classical methods. Another advantage of using EA`s over others methods is that EA`s use probabilistic transition rules to guide their search.
2) In case of IR search space is of high dimension EA`s can naturally deal with such solution space rather than analytical methods.
3) In many cases multiple solutions exist , For example each one of the multiple sets of web pages can represent a satisfactory result.
4) Exploration and Exploitation: Finding a good
solution in IR requires exploration and exploitation in each direction of search space. Operators like crossover and mutation perform such operations really well.
EAs have been applied to solve many important IR problems including: automatic indexing, clustering, query learning, automatic document indexing, ranking, query definition, image retrieval, design of user profiles for IR on internet, design of agents for internet searching.
Indexing is basically a data structure that holds the key terms that represent a document. Taking a user query as input, IRS searches it through the indexes to find relevant documents. Gordon [4] was the first to use genetic algorithm for document indexing. He has proposed the idea to attach more than one description with each document and then let them adapt throughout time as a good solution to the problem of the different forms that different user queries searching for the same document can present.
In [7] Vrajitoru presented a different approach for the same problem. In which each document is associated with just one description which leads to encode the whole collection in the single chromosome. The problem with this model is that the fitness function considers only one query and not the set of queries as the Gordon`s model. Fan et al. [8] proposed an algorithm for indexing function learning based on Genetic Programming, whose aim is to obtain an indexing function for the key term weighting for a documentary collection to improve the IR process.
The aim to using EA is to generate a similarity measure for a vector space IRS to improve its retrieval efficacy for a specific user.
This constitutes a new relevance feedback philosophy since matching function is adapted instead of queries. In [9] Pathak et al. have proposed the idea of combined similarity measure in which they have proposed a linear combination of various similarity measures and then optimize the weight of each similarity measure using GA.
A GP algorithm to automatically learn a matching function with relevance feedback is introduced in [10]. The similarity functions are represented as trees, and a classical generational scheme and the usual GP crossover is considered.
In [12], Chen et al. used a GA as an IQBE technique to learn query terms that better represent a relevant document set provided by user. In [13] the author has used a GA to adapt the query term weights in order to get the closest query vector to the optimal one. Gordon [6] suggested use of GA for user based document clustering.
In [14] Rocio L.Cecchini et al. have used GA‘s for tuning topical queries for effective information retrieval. They have used GA as an optimization technique to evolve ―good query terms‖ in context of a given topic. They have discuss the use of mutation pool to allow the generation of queries with new terms and study the effect of different mutation rates on the exploration of query space. Consequently they came with the semantic framework [15] for evaluating topical search methods. López-Herrera [16] applied multiobjective Evolutionary algorithm for automatic learning of Boolean queries. Rocio et. el.[17] suggested us of multi objective evolutionary algorithm for context based search.
III. PROPOSED APPROACH FOR ADAPTIVE INFORMATION
RETRIEVAL SYSTEM VECTOR SPACE MODEL
A. Vector Space Model
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)252
Some of the important similarity measures are : cosine, jaccard, okapi etc, each having its own pros and cons.
1) Cosine: - Cosine is normalized dot product. It measures Cosine of the angle between the query and document vector is given: -
t j j i t j j q t j j i j q id
w
d
w
D
Q
Cos
1 2 , 1 2 , 1 , ,)
(
)
(
)
,
(
(4)t is number of terms in the document. The numerator represents the dot product (also known as the inner product) of the vectors q and d, while the denominator is the product of their Euclidean lengths. The effect of the denominator is thus to length-normalize the vectors. As the angle between the vectors shortens, the Cosine angle approaches 1, meaning that the two vectors are getting closer and the similarity between document and query increases.
2) Jaccard Coefficient: - The Jaccard coefficient is defined as the size of the intersection divided by the size of the union of the document and query vectors. Unlike Cosine measure this measure does not consider frequency of terms in documents
t j t
j i j
d j q w j q w t
j i j d
t
j i j
d j q w i D Q Jac
1 1 , ,
2 ) , ( 1 2 ) , (
1 , , )
, (
(5) 3) Okapi: - The Okapi similarity measurement is
comparatively a new and one of the most popularly methods used in the IR field. Unlike Cosine measure, the Okapi method not only considers the frequency of the query terms, but also the average length of the whole collection and the length of the document under evaluation.
qtf
k
qtf
k
tf
K
tf
k
w
D
Q
okapi
Q T i
3 3 11
)
(
1
)
(
)
,
(
(6)
Q is a query that contains the words T
k1 (between 1.0-2.0), b (usually 0.75), and k3 (between 1-1000) are constant parameters
K is
k
1((
1
b
)
(
b
dl
/
avdl
)
qtf is the term frequency in the queryw is
)
5
.
0
(
)
5
.
0
(
log
n
n
N
N is the number of documents, n is the number containing the term
dl and avdl are the document length and average document length
It has been suggested that different similarity measures if combined appropriately can improve efficiency of an IRS. While combining these similarity measures it is important that proper weights be given to individual similarity measures. Since these weights have to be determined based on nature and type of query and document corpus, an adaptive IRS is required to cater to the needs of user. Though this model does not take into account user interaction, it uses the pseudo relevance feedback information to improve retrieval efficiency. Our adaptive IRS uses a combined similarity measure to match query and document. In order to find appropriate weights of these measures, evolutionary approach has been used. Combined matching function can adapt weights of matching functions to improve its retrieval efficiency.
B. Problem Formulation
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)253
Our combined similarity measure is a weighted sum of the scores returned by different matching measures.
Mi
i
i
SM
D
Q
wt
Q
D
CSM
1
))
,
(
(
)
,
(
(7)Where SMi (D,Q) signifies the similarity measure that is used to calculate the score of document D for given query Q, wti signifies the weight for the ith similarity measure and M is total number of standard similarity measures considered. We have used three similarity measures: cos(SM1), jaccard(SM2), okapi(SM3). Weights wt1 and wt2 range from 0.0 to 1.0. A less weight signifies that associated similarity measure is less significant.
1) Representing IR Problem using GA
A problem to be solved through GA requires encoding the solution in form of chromosomes, identifying a fitness function and defining suitable crossover and mutation operator. For our problem a real coded chromosome representation is chosen. The GA based representation of our problem is discussed below.
(1) Encoding
The chromosome is represented in the following way: Wt1 Wt2 Wt3
Where Wti = weight of ith similarity measure. We have used a real-valued chromosome, because it is more natural representation for our problem and it decreases dramatically the number of genes required to specify a design, thus making the solution space easier to search.
(2) Fitness Function Evaluation
Fitness function is a performance measure that is used to evaluate how good each solution is. We have used following fitness function which is based on recall and precision :
precision
recall
precision
recall
fitness
2
(8)(3) GA operators
Selection, Crossover and Mutation are the GA operators that are applied to the above chromosomes. Selection embodies the principle of ‗survival of the fittest‘. Chromosomes having higher fitness were selected for crossover. The roulette wheel reproduction process [8] was used to select individuals. Crossover is the genetic operator that combines two chromosomes together to form a new chromosome. We have used single point crossover where a locus position is selected within two parent chromosomes and the genes are swapped from that position to the end of parent. Following is an example for our crossover operation
ParentA ChildA
ParentB ChildB
Mutation involves the modification of the values of each gene of a solution with some probability
After mutation
Where muted gene is gene no.2
C. Algorithm
Overall steps of our algorithm are as follows :- Step 1: Extract all the words from each document. Step 2: Eliminate stop-words
Step 3: Perform stemming.
Step4: Assign weights (tf-idf) to the terms that describe the documents of the collection.
Step5: Generate initial population with p individuals (where p=population size). The members of the population consist of randomly generated values of wt1 and wt2.
Step6:For each member of population perform
Step6(a): Compare the query with all of the documents in the document collection, using the standard similarity measures (eqn4,5,6). This gives a list of the similarity scores of the query with all the collection‘s documents for all similarity measures.
0.3 0.9 0.6
00.6
0.2
0.2 0.4 0.5 00.6
0.2
0.3 0.4 0.5
00.6
0.2
0.3 0.9 0.6 00.60.60.6 00.6
0.2
0.2 0.4 0.5
00.6
0.2
0.2 0.3 0.5
00.6
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)254
Step6(b): Calculate the value of combined similarity measure for all the documents using eqn 7. Step6(c): Sort the documents on the combined
similarity measure score calculated in previous step.
Step 6(d): Select top N documents (where N is document cutoff)
Step 6(e): Find recall and precision values for the combined similarity measure.
Step6(f):Calculate the fitness value using eqn 8 Step7:Sort the members of population in decreasing
order of degree of fitness value.
Step8:Select q individuals based on selection algorithm (Roulette wheel)
Step9:Use these q individuals to generate p children (using crossover and mutation)
Step10:Add new children to the current population. Step11:Generate new population by selecting best p individuals (Rank based selection)
Step12:Go to step6, until the terminating condition is satisfied (The termination condition was a maximum of 75 generation or when no improvement was there for at least 10 generations.)
IV. EXPERIMENTS AND RESULTS
We tested the algorithm on three datasets adi , lisa and cisi. These data sets provide benchmark for testing efficiency of an Information Retrieval System. .Adi has 82 documents and 35 queries .Lisa dataset contains the titles and abstracts of the 6,004 documents that formed the input to the 1982 issues of Library and Information Science Abstracts (LISA) database. Associated with these documents is a set of 35 natural language queries. CISI data consist of 1460 abstracts from information retrieval papers and 112 queries. We have used cos, jaccard and okapi as individual similarity measures. Experiments were run for 80 generations. Crossover rate was 0.7 and mutation rate was set to 0.01.Document cutoff was 10 for adi, 80 for Lisa and CISI dataset. These parameters were selected empirically.
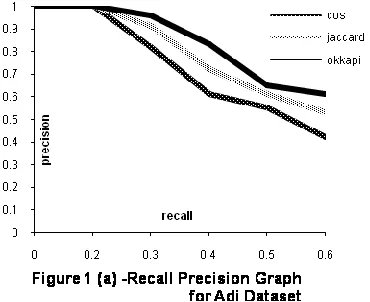
Figure 1(a), (b), (c) show average recall precision curve for cosine, jaccard and okapi measure for adi, lisa and cisi dataset respectively. Figure (2) shows variation of average fitness with generation number for adi, lisa and cisi dataset. As shown the average fitness increases with generation number. On the basis of our experiment we observed that for 90%,80% and 50% of the queries of adi, lisa, cisi dataset respectively have increased average fitness in successive generations. We compared the results of our experiments with the recall and precision values obtained by any individual similarity measure without any modification. For almost all the queries our experiment gave better results. For some queries we were able to obtain the recall value 1 indicating that all relevant documents have been retrieved. Figure 3 shows recall precision graph for GA based experiment for the adi, lisa and cisi dataset for the combined similarity measure
[image:6.612.344.529.549.700.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)255
V. CONCLUSION
GA can play an important role in information retrieval. In this paper we have discussed the applications of GA for improving retrieval efficiency of IRS. GA has been used to find an optimal set of weights for components of combined similarity measure consisting of different standard similarity measures that are used for ranking the documents. We have tested our experiment on adi, lisa and Cisi datasets and results are very encouraging. As a future line of research, we shall continue investigating into the design of fitness functions, laying particular emphasis on functions which also take the order into account.
REFERENCES
[1] G. Salton, M.H. McGill, 1983. Introduction to Modern Information Retrieval,.McGraw-Hill. USA.
[2] T.Bach, D.B. Fogel, Z. Michalewicz, 1997. Handbook of Evolutionary Computation. IOP Publishing and Oxford University
Press. NewYork.
[3] David, Grossman and Frieder, 1998. Information Retrieval: Algorithm and Heuristic. Kulwar Academic Press. USA
[4] Gordan, M., 1998. Probabilistic and Genetic Algorithms for Document Retrieval, Communication of ACM 31(120) 1208-1218.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 6, June 2012)256 [6] M. Gordon, 1991.User-based document clustering by re-describing
subject description with a genetic algorithm. Journal of the American Society for Information Science 42 (5), pp. 311–322.
[7] D. Vrajitoru, 1998. Crossover improvement for genetic algorithm in information retrieval. Information Processing and Management 34 (4) pp. 405–415.
[8] W. Fan, M.D. Gordon, P. Pathak, 2000. Personalization of search engine services for effective retrieval and knowledge management In Proc. Of International Conference on Information Systems (ICIS), Brisbane, Australia.
[9] P. Pathak, M. Gordon, W. Fan, 2000. Effective information retrieval using genetic algorithms based matching functions adaption, In Proc. 33rd Hawaii International Conference on Science (HICS), Hawaii, USA, 2000.
[10] W. Fan, M. Gordon, P. Pathak,1999. Automatic generation of a matching function by genetic programming for effective information retrieval. America‘s Conference on Information System, Milwaukee, USA.
[11] C.J. Van Rijsbergen. 1979 Information Retrieval. Second ed. Butterworth..
[12] H. Chen et al., 1998. A machine learning approach to inductive query by examples: an experiment using relevance feedback, ID3, genetic algorithms, and simulated annealing. , Journal of the American Society for Information Science 49 (8) pp. 693–705.
[13] J. Horng, C. Yeh,, 2000. Applying genetic algorithms to query optimization in document retrieval. Information Processing and Management 36 pp. 737–759.
[14] Rocio L. Cecchini, Carlos M. Lorenzzetti, Ana G.Maguitman, Nelida Beatriz Brignole, 2008. Using genetic algorithm to evolve a population of topical queries. Information Processing and Management 44, pp. 1863-1878.
[15] Rocio L. Cecchini, Carlos M. Lorenzzetti, Ana G.Maguitman. 2011 A Semantic Framework for Evaluating Topical Search Methods. CLEI Electronic Journal vol. 14 number 1 paper 2.
[16] A.G. López-Herrera, E. Herrera-Viedma, F. Herrera, 2009. Applying multi-objective evolutionary algorithms to the automatic learning of extended Boolean queries in fuzzy ordinal linguistic information retrieval systems. Fuzzy Sets & Systems 160 ,pp. 2192 – 2205. Elesevier Publication.