© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 827
Analysis of Multiple Classification algorithms using Real Time
Twitter Data
Sharmila Bhargava
1,
Dr. Rachna Dubey
2,
Priyanka Gupta
31
M.Tech Scholar, Department of Computer Science & Engineering, Lakshmi Narain College of Technology&
Excellence Bhopal (M.P), India.
2
Professor & Head, Department of CSE, Lakshmi Narain College of Technology& Excellence, Bhopal (M.P), India.
3Assistant Professor, Department of CSE, Lakshmi Narain College of Technology& Excellence, Bhopal (M.P), India.
---***---ABSTRACT:- The spreading amount of data usuallygenerates interesting demand for the data analysis tools that spot regularities in these data. Data mining has turned up as great domain that contributes mechanism for data analysis, to find out the hidden knowledge, and self-ruling decision making in many operation domains. Supervised machine learning is using to find out the search for algorithms that reason from clearly supplied instances to produce general interpretation, which then makes predictions about future scenario or events. In other words, the goal of supervised learning is to make a small model of the distribution of class labels (distribution or classification) in terms of finding (predictor) features. The resulting classifier is then used to assign class labels (attributes) to the testing instances where the values of the predictor (attributes or properties) features are known, but the value of the class label is unknown. This paper explains various supervised machine learning classification techniques.
In this paper, we have discussed the about the classification algorithm which are available today, how they works, and what are their advantages and disadvantages. The algorithms which we will discuss are Naïve Bayes, SVM, random forest, decision tree and logistic regression.
Keywords: Classification, Naïve Bayes, Random forest,
Multiple regression dependent variable, independent variables, predictor variable, response variable
I. INTRODUCTION
Social Predictive modelling can be explained in terms of mathematics to find out the goal there is relationship between a target, response, or “dependent” variable and various predictor (attributes) or “independent” variables with the goal in mind of measuring future (attributes) values of those predictors and inserting them into the mathematical relationship to predict future values of the target variable, it is mandatory to give some measure of mistrust for the predictions, typically a prediction interval that gives some assigned level of confidence like some percentage value i.e (95%).Regression analysis establishes a relationship between a dependent o r outcome variable and a set of predictors. Regression, as a data mining technique, is supervised learning. Supervised learning
partitions the database into training and validation data. The techniques used in this research were simple linear regression and multiple linear regressions. Some divergence between the uses of regression in statistics verses data mining are: in statistics the data is a sample from a (Data Storage) population, but in Data Mining the data is taken from a large database (e.g. 1 million records). Also in stats the regression model is created from a given sample, but in Data Mining the regression model is created from a part of the data (training data). Predictive (To guess) analytics enclose a number of mechanism from stats, data mining and game theory that find out current and historical facts to make guesses about future events. The variety of techniques is sometimes divided in three ways: predictive models, descriptive models and decision models.
Predictive models explain for sure relationships and some patterns that usually edge to a certain behaviour, point to fraud, predict system failures, and so many. By explaining the explanatory variables, we can find out or predict results in the dependent variables.
Descriptive models explain for creating partition or segment; generally it is used to classify (find out) customers based on for instance (behaviour of customers in different locations) socio-demographic characteristics, life cycle, profits, required product and many more. Where predictive models focus on a specific (individual) event or behaviour, descriptive models identify as many different (general) relationships as possible.
Decision models explain to find out optimization ways to predict (find out) results of decisions. This branch of predictive analytics apply in operations research, including areas such as resource optimization in networking & many places, route planning in many industries .
1.1 Data Mining Techniques
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 828
applied on various industries like retail, finance, health care, aerospace, education etc. Knowledge is extracted from the historical data by applying pattern recognition, statistical and mathematical techniques those results in the knowledge the form of facts, trends, association, patterns, anomalies and exceptions. There are some areas where data mining will be applied.
Data Pre-processing: Data pre-processing make ready the real world data for mining process.
Data Mining: data mining is the process of extracting some important patterns from a large amount of data.
Pattern Evaluation: This process evaluates the pattern that is generated by the data mining. The patterns are evaluated according to the interestingness measure given by user or system.
[image:2.595.30.269.375.555.2]Knowledge presentation: To show your Knowledge Presentation of your data uses visualization mechanism that can explore the important patterns (behaviour) and help the user to understand and interpret the resultant patterns.
Figure 1: Different Machine Learning Methods [1]
1.2 Overview of data mining
Data mining is really attracted many industries to explore information or required data i.e. it provides a great deal of attention in the information industry and in society in upcoming years, due to availability of large amount of data and required need for turning such data into useful information and knowledge. Data mining is the process of data and looking for meaningful and important trending patterns. The information extracted from previous knowledge can be used for future applications for analysis of market, detecting much fraud in industries, and how to retain our customers. It follows (Data mining) iterative process.
Data cleaning: It is a process of removing noise and inconsistent data.
Data integration: In this step data from multiple sources are combined.
Data selection: In this step data relevant for mining task is selected.
Data transformation: In this step data will be transformed into form that is appropriate for mining.
Data mining: In this step some intelligent methods are applied for extracting data patterns.
Pattern evaluation: In this step we concentrate upon important patterns representing knowledge based on some measure are identified.
Knowledge presentation: In this step visualization and knowledge representation techniques are used to present the mined knowledge to the user.
1.3 Data Mining Algorithms & Techniques
Various algorithms and techniques like Classification, Clustering, Regression, Artificial Intelligence, Neural Networks, Association Rules, Decision Trees, Genetic Algorithm (Adaptive Procedure), Nearest Neighbour method etc., are used for knowledge discovery from databases.
1.4 Classification
Classification is the frequently (most commonly) applied data mining mechanism, which explains a set of pre- classified examples to develop a (procedure) model that can (identifies or categories) classify the population (Dataset) of records at large. During Fraud detection in network and Transactional (credit) risk applications are particularly well suited to this type of analysis. This way frequently applies by decision tree or neural network- based classification algorithms. The data (categorization) classification process involves learning (Trained previously) and then classification will apply on given data. Learning process can be done by analyzing data using classification Mechanism. In classification test data are used to find out (estimate) the accuracy of the classification rules which we applied. If the accuracy is acceptable the rules can be applied to the new data tuples.
o Classification by decision tree induction
o Bayesian Classification
o Neural Networks
o Support Vector Machines (SVM)
o Classification Based on Associations
Support Vector Machine
It is a supervised machine learning algorithm which can be utilizes for both classification and regression (Linearly) challenges. However, it is mostly used in classification problems. Here, we are explaining points (plot) each and every point (data item) as a point in n-dimensional space (where n is number of features you have) with the value of each and every points (plot) feature being the value of a particular coordinate system in given system.
Input Data
(NLS-KDD)
Process our Data
Logistic
Regression
SVM Naive
Bayes
RBF
LR Model SVM
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 829
Figure 2: A linear Support Vector Machine [8]1.5 Clustering
Clustering can be said as to find out of similar classes of objects. By using clustering mechanism we can further find out dense and sparse (n Dimensional Space) regions in object space and can discover overall distribution trends (pattern) and relation among many coordinate points (correlations) among data attributes. Classification by decision tree induction
o Partitioning Method
o Hierarchical Agglomerative methods
o Density based methods
o Grid-based methods
o Model-based methods
1.6 Prediction
Clustering Regression technique can be fitting for predication. Regression analysis can be used to create (procedure) model the relationship between one or more independent variables and dependent variables. In data mining independent (self-sufficient) variables are attributes already known and response (return) variables are what we want to determine. But when we see in real- world problems are not simply (judge) prediction. For instance, data of sales, data of stock market prices, and many product failure rates in any industries or domain are very difficult to judge (predict) because they may depend on complex (or many variables) interactions of multiple predictor variables. Therefore, more composite ways (e.g., logistic regression, decision trees, or neural nets) may be required to forecast
Future values. The same model types can usually be used for both regression and classification mechanism. For example, the CART (Classification and Regression Trees) decision tree algorithm can be used to build both classification trees (to classify categorical response variables) and regression trees. By using Neural networks we can explain both classification and regression models. Types of regression methods:
o Linear Regression
o Multivariate Linear Regression
o Nonlinear Regression
o Multivariate Nonlinear Regression
Simple Linear Regression: Simple linear regression is stats that allow us to encapsulate and read the
relationships between two (steady) continuous
(quantitative) variables:
1) First variable, denoted by x, is regarded as the predictor (judging elements), explanatory, or independent variable.
2) The other one, determine as y, is regarded as the outcome variable.
Multivariate Linear Regression: Here, we will judge ( predict ) the value of one or more outcomes from a set of attributes or properties (Predictors). It can also be used to find out the linear association between the predictors and outcomes. Predictors can be continuous or categorical or a combination of both.
II. LITERATURE SURVEY
2.1 Forecasting is analysing and predicting the future behaviour
In this paper Author concludes that forecasting (Future Analysis) is figure out and finding the future behaviour of the selected data set. We will used past data to predict future data. It help in many ways in various domains such as controlling load balancing in network management, to explore future marketing campaigns in any industries like share market & FMCG, allocating or de-allocating resources and caching in networks and operating system , perfecting web pages for improve performance. There are limited number of researches have been done on Web site related forecasting.
III. PROBLEM IDENTIFICATION
A lot of research work has been done in the field. Authors have learned several things from this study (work). First, we will introduce some terms that are related with our topic such as, some brief description of Big Data, Data Warehouses, Data Mining and their classification and finally also will do the particular analysis.
Decision Boundary Negative Training
Examples
Negative Training
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 830
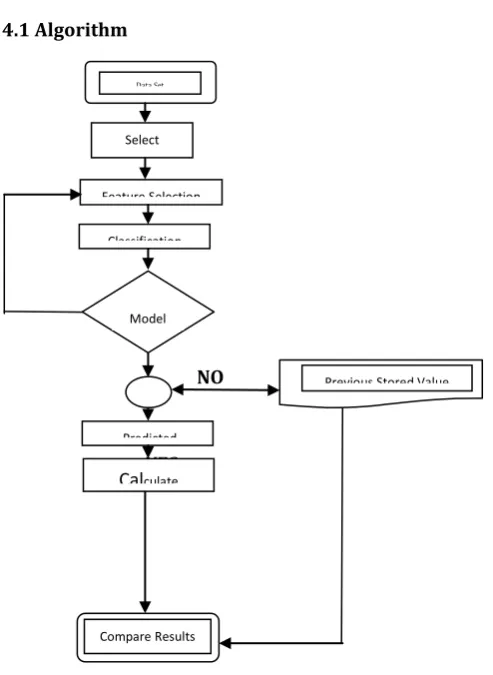
IV. Block Diagram & Methodology4.1 Algorithm
NO
[image:4.595.34.565.57.520.2]YES
Figure 3: Block Diagram of Flow of Operation
1. Input / Load data set
2. Apply feature extraction
3. Received Extracted data as output
4. Generate Training and Testing data set (By applying techniques: )
5. Apply any classification algorithm to training dataset
6. Build the Reduction Explanatory Predictor
7. Building Model using any machine learning model
8. Perform / Obtain validity check
9. Utilize the “test” set predictions to calculate all the performance metrics (Measure Accuracy and other parameters)
V. Experimental Result
We used python programming Language to implement our logic we are giving some snap shot below:
[image:4.595.35.282.104.442.2]We can show our result in tabular form:
Figure 4: Twitter App to create Authentication
[image:4.595.298.562.202.582.2]Figure 5: Tweeter Key & Tokens
Figure 6: Results of Tweeter in terms of positive & Negative
Figure 7: Dynamic Tweet Extraction (Input 1) Data Set
Select Sample
Feature Selection
Classification
>
Predicted
Result Calculate Accuracy
Compare Results
[image:4.595.306.580.626.752.2]© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 831
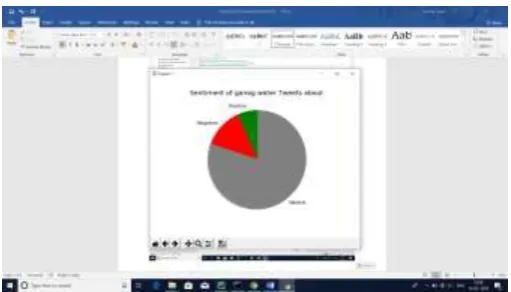
Figure 8: Line chart Result positive and NegativeFigure 9: Pie Chart Result positive and Negative Analysis
VI. CONCLUSION
We studied many machine learning algorithms and we found that in day to day life or in internet era classification algorithm play vital roles to define and describe many things.
REFERENCES
[1] Manisha rathi Regression modeling technique on data mining for prediction of CRM CCIS 101, pp.195-200, 2010Springer–Verlag Heidelberg 2010.
[2] Jiawei Han and Micheline Kamber (2006), Data Mining Concepts and Techniques, published by Morgan Kauffman, 2nd ed.
[3] Giudici Paolo, “Applied Data Mining-Statistical methods for business and industry” wiley, (2003) [5] Dash, M., and H. Liu, "Feature Selection for Classification," Intelligent Data Analysis. 1:3 (1997) pp. 131-156. [6] Rencher C. Alvin, “Methods of Multivariate Analysis” 2nd Edition, Wiley Interscience, (2002).
[4] Burges, C. (1998). A tutorial on Support Vector Machines for Pattern Recognition. Data Mining and Knowledge Discovery, 2(2):955–974.
[5] CiteSeer (2002). CiteSeer Scientific Digital Library. http://www.citeseer.com.
[6] Duda, R. O. and Hart, P. E. (1973). Pattern Classification and Scene Analysis. John Wiley & Sons.
[7] Greenbaum, A. (1997). Iterative Methods for Solving Linear Systems, volume 17 of Frontiers in Applied Mathematics. SIAM.
[8] GLIM (2004). Generalised Linear Interactive Modelingpackage.http://www.nag.co.uk/stats/GDGE soft.asp, http://lib.stat.cmu.edu/glim/.
[9] Kubica, J., Goldenberg, A., Komarek, P., Moore, A., and Schneider, J. (2003). A comparison of statistical and machine learning algorithms on the task of link completion. In KDD Workshop on Link Analysis for Detecting Complex Behavior, page 8.
[10] Lay, D. C. (1994). Linear Algebra and Its Applications. Addison-Wesley.
[11] G. Rätsch, T. Onoda, and K. R. Müller, “Soft margins for AdaBoost,” Mach. Learn., vol. 42, no. 3, pp. 287–320, 2001.
[12] K. Ting, “Precision and Recall,” in Encyclopedia of Machine Learning, 2011, p. 1031.
[13] Z. C. Lipton, C. Elkan, and B. Naryanaswamy, “Optimal thresholding of classifiers to maximize F1 measure,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2014, vol. 8725 LNAI,
[14] F. Iqbal, H. Binsalleeh, B. C. M. Fung, and M. Debbabi, "A unified data mining solution for authorship analysis in anonymous textual communications," Information Sciences, vol. 231, pp. 98–112, May 2013 2013.
[15] T. Kucukyilmaz, B. B. Cambazoglu, C. Aykanat, and F. Can, "Chat mining: Predicting user and message attributes in computer-mediated communication," Information Processing & Management, vol. 44, pp. 1448–1466, July 2008 2008.
[16] M. Verdone, "Python Twitter Tools (PTT)," 1.9.4 ed, 2013. [13] K. Toutanova. (2000). Stanford Log-linear Part-OfSpeech Tagger. Available:
http://nlp.stanford.edu/software/tagger.shtml
[17] A. Mudinas, D. Zhang, and M. Levene, “Combining lexicon and learning based approaches for concept-level sentiment analysis,” Proc. First Int. Work. Issues Sentim. Discov. Opin. Min. - WISDOM ’12, pp. 1–8, 2012.
[image:5.595.35.291.262.408.2]© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal
| Page 832
[19] Akshi Kumar and Teeja Mary Sebastian, on "Sentiment Analysis on Twitter", dated July 2012
![Figure 1: Different Machine Learning Methods [1] Results](https://thumb-us.123doks.com/thumbv2/123dok_us/9411373.442377/2.595.30.269.375.555/figure-different-machine-learning-methods-results.webp)
![Figure 2: A linear Support Vector Machine [8]](https://thumb-us.123doks.com/thumbv2/123dok_us/9411373.442377/3.595.45.287.93.194/figure-linear-support-vector-machine.webp)