Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 97–102 Vancouver, Canada, July 30 - August 4, 2017. c2017 Association for Computational Linguistics
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 97–102 Vancouver, Canada, July 30 - August 4, 2017. c2017 Association for Computational Linguistics
Sentence Alignment Methods for Improving Text Simplification Systems
Sanja ˇStajner1, Marc Franco-Salvador2,3,
Simone Paolo Ponzetto1,Paolo Rosso3,Heiner Stuckenschmidt1
1 DWS Research Group, University of Mannheim, Germany 2Symanto Research, Nuremberg, Germany
3 PRHLT Research Center, Universitat Polit`ecnica de Val`encia, Spain
{sanja,simone,heiner}@informatik.uni-mannheim.de [email protected], [email protected]
Abstract
We provide several methods for sentence-alignment of texts with different complex-ity levels. Using the best of them, we sentence-align the Newsela corpora, thus providing large training materials for au-tomatic text simplification (ATS) systems. We show that using this dataset, even the standard phrase-based statistical machine translation models for ATS can outper-form the state-of-the-art ATS systems.
1 Introduction
Automated text simplification (ATS) tries to auto-matically transform (syntactically, lexically and/or semantically) complex sentences into their simpler variants without significantly altering the original meaning. It has attracted much attention recently as it could make texts more accessible to wider audiences (Alu´ısio and Gasperin, 2010; Saggion et al., 2015), and used as a pre-processing step, improve performances of various NLP tasks and systems (Vickrey and Koller, 2008; Evans, 2011;
ˇStajner and Popovi´c, 2016).
However, the state-of-the-art ATS systems still do not reach satisfying performances and require some human post-editing (ˇStajner and Popovi´c, 2016). While the best supervised approaches gen-erally lead to grammatical output with preserved original meaning, they are overcautious, making almost no changes to the input sentences (Spe-cia, 2010; ˇStajner et al., 2015), probably due to the limited size or bad quality of parallel TS corpora used for training. The largest existing sentence-aligned TS dataset for English is the English Wikipedia – Simple English Wikipedia
(EW–SEW) dataset, which contains 160-280,000 sentence pairs, depending on whether we want to model only traditional sentence rewritings or also to model content reduction and stronger para-phrasing (Hwang et al., 2015). For Spanish, the largest existing parallel TS corpus contains only 1,000 sentence pairs thus impeding the use of fully supervised approaches. The best unsuper-vised lexical simplification (LS) systems for En-glish which leverage word-embeddings (Glavaˇs and ˇStajner, 2015; Paetzold and Specia, 2016) seem to perform more lexical substitutions but at the cost of having less grammatical output and more often changed meaning. However, there have been no direct comparisons of supervised and unsupervised state-of-the-art approaches so far.
The Newsela corpora1offers over 2,000 original news articles in English and around 250 in Span-ish, manually simplified to 3–4 different complex-ity levels following strict guidelines (Xu et al., 2015). Although it was suggested that it has bet-ter quality than the EW–SEW corpus (Xu et al., 2015), Newsela has not yet been used for train-ing end-to-end ATS systems, due to the lack of its sentence (and paragraph) alignments. Such align-ments, between various text complexity levels, would offer large training datasets for modelling different levels of simplification, i.e. ‘mild’ sim-plifications (using the alignments from the neigh-bouring levels) and ‘heavy’ simplifications (using the alignments of level pairs: 0–3, 0–4, 1–4).
Contributions. We: (1) provide several meth-ods for paragraph- and sentence alignment of parallel texts, and for assessing similarity level between pairs of text snippets, as freely
avail-1Freely available: https://newsela.com/data/
able software;2 (2) compare the performances of lexically- and semantically-based alignment meth-ods across various text complexity levels; (3) test the hypothesis that the original order of infor-mation is preserved during manual simplification (Bott and Saggion, 2011) by offering customized MST-LIS alignment strategy (Section 3.1); and (4) show that the new sentence-alignments lead to the state-of-the-art ATS systems even in a basic phrase-based statistical machine translation (PB-SMT) approach to text simplifications.
2 Related Work
The current state-of-the-art systems for automatic sentence-alignment of original and manually sim-plified texts are the GSWN method (Hwang et al., 2015) used for sentence-alignment of original and simple English Wikipedia, and the HMM-based method (Bott and Saggion, 2011) used for sentence-alignment of the Spanish Simplext cor-pus (Saggion et al., 2015).
The HMM-based method can be applied to any language as it does not require any language-specific resources. It is based on two hypotheses: (H1) that the original order of information is pre-served, and (H2) that every ‘simple’ sentence has at least one corresponding ‘original’ sentence (it can have more than one in the case of 1’ or ‘n-m’ alignments).
As Simple Wikipedia does not represent direct simplification of the ‘original’ Wikipedia articles (‘simple’ articles were written independently of the ‘original’ ones), GSWN method does not as-sume H1 or H2. The main limitations of this method are that it only allows for ‘1-1’ sentence alignments – which is very restricting for TS as it does not allow for sentence splitting (‘1-n’), and summarisation and compression (‘n-1’ and ‘n-m’) alignments – and it is language-dependent as it re-quires English Wiktionary.
Unlike the GSWN method, all the methods we apply are language-independent, resource-light and allow for ‘1-n’, ‘n-1’, and ‘n-m’ alignments. Similar to the HMM-method, our methods assume the hypothesis H2. We provide them in both vari-ants, using the hypothesis H1 and without it (Sec-tion 3.1).
2https://github.com/neosyon/
SimpTextAlign
3 Approach
Having a set of ‘simple’ text snippetsS and a set
of ‘complex’ text snippetsC, we offer two
strate-gies (Section 3.1) to obtain the alignments(si, cj),
wheresi ∈ S, cj ∈ C. Each alignment strategy,
in turn, can use one of the three methods (Sec-tion 3.2) to calculate similarity scores between text snippets (either paragraphs or sentences).
3.1 Alignment strategies
Most Similar Text (MST):Given one of the ilarity methods (Section 3.2), MST compares sim-ilarity scores of all possible pairs (si, cj), and
aligns eachsi∈Swith the closest one inC. MST with Longest Increasing Sequence (MST-LIS): MST-LIS uses the hypothesis H1. It first uses the MST strategy, and then postprocess the output by extracting – from all obtained align-ments – only those alignalign-mentsli ∈L, which
con-tain the longest increasing sequence of offsetsjk
inC. In order to allow for ‘1–n’ alignments (i.e.
sentence splitting), we allow for repeated offsets ofC(‘complex’ text snippets) inL. The ‘simple’ text snippets not contained inLare included in the
setUof unaligned snippets. Finally, we align each um ∈ U by restricting the search space in C to
those offsets of ‘complex’ text snippets that corre-spond to the previous and the next aligned ‘simple’ snippets. For instance, ifL = {(s1, c4),(s3, c7)}
andU ={s2}, then the search space for the align-ments of s2 is reduced to {c4...c7}. We denote
this strategy with an ‘*’ in the results (Table 2), e.g. C3G*.
3.2 Similarity Methods
C3G: We employ the Character N-Gram
(CNG) (Mcnamee and Mayfield, 2004) similarity model (for n = 3) with log TF-IDF weight-ing (Salton and McGill, 1986) and compare vectors using the cosine similarity.
WAVG: We use the continuous skip-gram model (Mikolov et al., 2013b) of the TensorFlow toolkit3 to process the whole English Wikipedia and generate continuous representations of its words.4 For each text snippet, we average its word vectors to obtain a single representation of its content as this setting has shown good results
3https://www.tensorflow.org/
4We use 300-dimensional vectors, context windows of
Match Transformation Original Simple Full syntactic simplification;
reordering of sentence constituents
During the 13th century, gingerbread was brought to Sweden by German immi-grants.
German immigrants brought it to Sweden during the 13th century.
Full lexical paraphrasing During the 13th century, gingerbread was brought to Sweden by German immi-grants.
German immigrants brought it to Sweden during the 13th century.
Partial strong paraphrasing Gingerbread foods vary, ranging from a soft, moist loaf cake to something close to a ginger biscuit.
Gingerbread is a word which describes different sweet food products from soft cakes to a ginger biscuit.
Partial adding explanations Humidity is the amount of water vapor in
the air. Humidity (adjective: humid) refers towater vapor in the air, but not to liquid droplets in fog, clouds, or rain.
Partial sentence compression Falaj irrigation is an ancient system dat-ing back thousands of years and is used widely in Oman, the UAE, China, Iran and other countries.
[image:3.595.74.524.59.262.2]The ancient falaj system of irrigation is still in use in some areas.
Table 1: Examples of full and partial matches from the EW–SEW dataset (Hwang et al., 2015).
in other NLP tasks (e.g. for selecting out-of-the-list words (Mikolov et al., 2013a)). Finally, the similarity between text snippets is estimated using the cosine similarity.
CWASA: We employ the Continuous Word Alignment-based Similarity Analysis (CWASA) model (Franco-Salvador et al., 2016), which finds the optimal word alignment by computing cosine similarity between continuous representations of all words (instead of averaging word vectors as in the case of WAVG). It was originally proposed for plagiarism detection with excellent results, espe-cially for longer text snippets.
4 Manual Evaluation
To compare the performances of different align-ment methods, we randomly selected 10 original texts (Level 0) and their corresponding simpler versions at Levels 1, 3 and 4. Instead of creating a ‘gold standard’ and then automatically evaluating the performances, we asked two annotators to rate each pair of automatically aligned paragraphs and sentences – by each of the possible six alignment methods and the HMM-based method (Bott and Saggion, 2011) – for three pairs of text complexity levels (0–1, 0–4, and 3–4) on a 0–2 scale, where:0
– no semantic overlap in the content;1– partial se-mantic overlap (partial matches);2– same seman-tic content (good matches). This resulted in a total of 1526 paragraph- and 1086 sentence-alignments for the 0–1 pairs, and 1218 paragraph- and 1266 sentence-alignments for the 0–4 and 3–4 pairs. In the context of TS, both good- and partial matches
are important. While full semantic overlap models full paraphrases (‘1-1’ alignments), partial over-lap models sentence splitting (“1-n” alignments), deleting irrelevant sentence parts, adding explana-tions, or summarizing (‘n-m’ alignments). Sev-eral examples of full and partial matches from the EW–SEW dataset (Hwang et al., 2015) are given in Table 1.
We expect that the automatic-alignment task is the easiest between the 0–1 text complexity lev-els, and much more difficult between the 0-4 levels (Level 4 is obtained after four stages of simplifi-cation and thus contains stronger paraphrases and less lexical overlap with Level 0 than Level 1 has). We also explore whether the task is equally diffi-cult whenever we align two neighbouring levels, or the difficulty of the task depends on the level complexity (0–1 vs. 3–4). The obtained inter-annotator agreement, weighted Cohen’sκ(on 400
double-annotated instances) was between 0.71 and 0.74 depending on the task and levels.
The results of the manual analysis (Table 2) showed that: (1) all applied methods significantly (p < 0.001) outperformed the HMM method on both paragraph- and sentence-alignment tasks;5 (2) the methods which do not assume hypothe-sis H1 (C3G, CWASA, and WAVG) led to (not significantly) higher percentage of correct align-ments than their counterparts which do assume
5Although some of our methods share the same
Method 0–1 0–4 3–4 0–1 0–4 3–4Sentence Paragraph C3G 98.3 56.1 81.1 98.6 86.8 95.2
[image:4.595.79.286.61.187.2]C3G* 96.7 54.7 78.8 95.4 77.0 92.3 CWASA 98.3 45.3 79.7 98.2 83.3 94.1 CWASA* 96.1 42.1 76.4 95.4 74.1 90.5 WAVG 97.8 56.1 79.7 96.8 75.9 91.7 WAVG* 96.1 50.0 79.7 96.8 69.5 89.3 C3G-2s 98.5 57.8 83.5 / / / HMM 86.2 25.2 65.6 96.8 41.2 65.5
Table 2: Percentage of good+partial sentence- and paragraph-alignments on the English Newsela cor-pus. All results are significantly better (p <0.001, Wilcoxon’s signed rank test) than those obtained by the HMM method (Bott and Saggion, 2011). The best scores are in bold.
H1 (C3G*, CWASA*, WAVG*); (3) the differ-ence in the performances of the lexical approach (C3G) and semantic approaches (CWASA and WAVG) was significant only in the 0–4 sentence-alignment task, where CWASA performed sig-nificantly worse (p < 0.001) than the other two methods, and in the 0–4 paragraph-alignment task, where WAVG performed significantly worse than C3G; (4) the 2-step C3G alignment-method (C3G-2s), which first aligns paragraphs using the best paragraph-alignment method (C3G) and then within each paragraph align sentences with the best sentence-alignment method (C3G), led to more good+partial alignments than the ‘direct’ sentence-alignment C3G method.
5 Extrinsic Evaluation
Finally, we test our new English Newsela (C3G-2s) sentence-alignments (both for the neighbour-ing levels – neighb. and for all levels –all) and Newsela sentence-alignments for neighboring lev-els obtained with HMM-method6 (Bott and Sag-gion, 2011) in the ATS task using standard PB-SMT models7 in the Moses toolkit (Koehn et al., 2007). We vary the training dataset and the cor-pus used to build language models (LMs), while keeping always the same 2,000 sentence pairs for tuning (Xu et al., 2016) and the first 70 sentence
6Given that the performance of the HMM-method was
poor for non-neighboring levels (Table 2).
7GIZA++ implementation of the IBM word alignment
model 4 (Och and Ney, 2003), refinement and phrase-extraction heuristics (Koehn et al., 2003), the minimum error rate training (Och, 2003) for tuning, and 5-gram LMs with Kneser-Ney smoothing trained with SRILM (Stolcke, 2002).
pairs of their test set8 for our human evaluation. Using that particular test set allow us to compare our (PBSMT) systems with the output of the state-of-the-art syntax-based MT (SBMT) system for TS (Xu et al., 2016) which is not freely available. We compare: (1) the performance of the standard PBSMT model which uses only the already avail-able EW–SEW dataset (Hwang et al., 2015) with the performances of the same PBSMT models but this time using the combination of the EW–SEW dataset and our newly-created Newsela datasets; (2) the latter PBSMT models (which use both EW–SEW and new Newsela datasets) against the state-of-the-art supervised ATS system (Xu et al., 2016), and one of the recently proposed unsuper-vised lexical simplification systems, the LightLS system (Glavaˇs and ˇStajner, 2015).9
We perform three types of human evaluation on the outputs of all systems. First, we count the total number of changes made by each system (Total), counting the change of a whole phrase (e.g. “ be-come defunct”→“was dissolved”) as one change.
We mark asCorrect those changes that preserve the original meaning and grammaticality of the sentence (assessed by two native English speak-ers) and, at the same time, make the sentence easier to understand (assessed by two non-native fluent English speakers).10 Second, three native English speakers rate the grammaticality (G) and meaning preservation (M) of each sentence with at least one change on a 1–5 Likert scale (1 – very bad; 5 – very good). Third, the three non-native fluent English speakers were shown original (reference) sentences and target (output) sentences (one pair at the time) and asked whether the target sentence is: +2 – much simpler; +1 – somewhat simpler; 0 – equally difficult; -1 – somewhat more difficult; -2 – much more difficult, than the refer-ence sentrefer-ence. While the correctness of changes takes into account the influence of each individual change on grammaticality, meaning and simplic-ity of a sentence, theScores (G and M)andRank (S) take into account the mutual influence of all changes within a sentence.
Adding our sentence-aligned Newsela corpus
8Both freely available from:https://github.com/
cocoxu/simplification/
9We use the output of the original SBMT (Xu et al., 2016)
and LightLS (Glavaˇs and ˇStajner, 2015) systems, obtained from the authors.
10Those cases in which the two annotators did not agree are
Approach Dataset Training Size (sent) Corpus LMSize (sent) TotalChangesCorrect GScoresM RankS PBSMT Wiki(Good+Partial) 284,499 Wiki 391,572 76 27 (35.5%) 4.09 3.31 0.26 PBSMT Newsela(neighb. C3G-2s)+Wiki 593,947 Newsela+Wiki 766,446 81 38 (46.9%) 4.40 3.84 0.30 PBSMT Newsela(all C3G-2s)+Wiki 764,572 Newsela+Wiki 766,446 87 42 (48.3%) 4.25 3.73 0.30 PBSMT Newsela(neighb.-HMM)+Wiki 584,106 Newsela+Wiki 766,446 75 33 (44.0%) 4.20 3.65 0.20 s.o.t.a. supervised SBMT (PPDB+SARI) (Xu et al., 2016)unsupervised (LightLS) (Glavaˇs and ˇStajner, 2015) 143132 35 (26.6%)49 (34.3%) 4.28 3.57 0.03 4.47 2.67 -0.01
Table 3: Extrinsic evaluation (PBSMT-based automatic text simplification systems vs. state of the art).
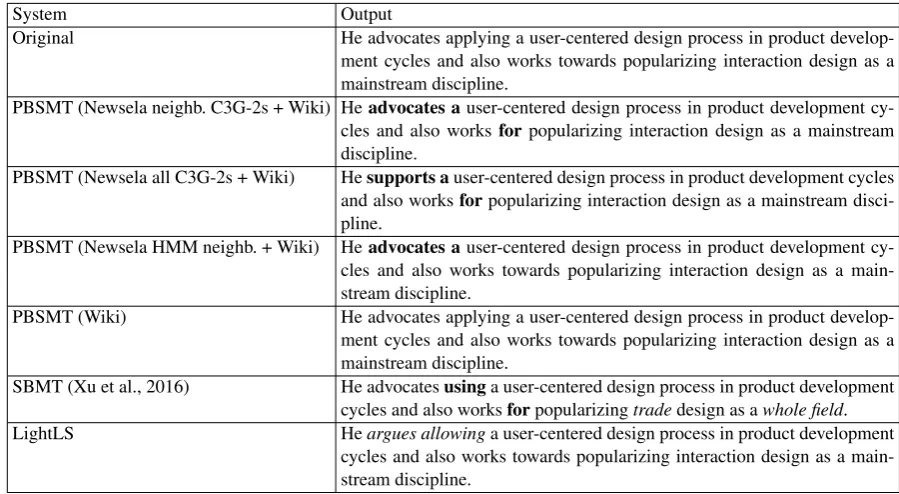
System Output
Original He advocates applying a user-centered design process in product develop-ment cycles and also works towards popularizing interaction design as a mainstream discipline.
PBSMT (Newsela neighb. C3G-2s + Wiki) Headvocates auser-centered design process in product development cy-cles and also works forpopularizing interaction design as a mainstream discipline.
PBSMT (Newsela all C3G-2s + Wiki) Hesupports auser-centered design process in product development cycles and also worksforpopularizing interaction design as a mainstream disci-pline.
PBSMT (Newsela HMM neighb. + Wiki) Headvocates auser-centered design process in product development cy-cles and also works towards popularizing interaction design as a main-stream discipline.
PBSMT (Wiki) He advocates applying a user-centered design process in product develop-ment cycles and also works towards popularizing interaction design as a mainstream discipline.
SBMT (Xu et al., 2016) He advocatesusinga user-centered design process in product development cycles and also worksforpopularizingtradedesign as awhole field. LightLS Heargues allowinga user-centered design process in product development
cycles and also works towards popularizing interaction design as a main-stream discipline.
Table 4: Outputs of different ATS systems (the correct changes/simplifications are shown in bold and the incorrect ones in italics).
(eitherneighb. C3G-2lorall C3G-2l) to the cur-rently best sentence-aligned Wiki corpus (Hwang et al., 2015) in a standard PBSMT setup signifi-cantly11 improves grammaticality (G) and mean-ing preservation (M), and increases the percent-age of correct changes (Table 3). It also signif-icantly outperforms the state-of-the-art ATS sys-tems by simplicity rankings (S), meaning preser-vation (M), and number of correct changes ( Cor-rect), while achieving almost equally good gram-maticality (G).
The level of simplification applied in the train-ing dataset (Newsela neighb. C3G-2svs.Newsela all C3G-2s) significantly influences G and M scores.
The use of the HMM-method for aligning Newsela (instead of ours) lead to significantly worse simplifications by all five criteria.
11Wilcoxon’s signed rank test,p <0.001.
An example of the outputs of different ATS sys-tems is presented in Table 4.
6 Conclusions
[image:5.595.73.523.192.439.2]Acknowledgments
This work has been partially supported by the SFB 884 on the Political Economy of Reforms at the University of Mannheim (project C4), funded by the German Research Foundation (DFG), and also by the SomEMBED TIN2015-71147-C2-1-P MINECO research project.
References
Sandra Maria Alu´ısio and Caroline Gasperin. 2010. Fostering Digital Inclusion and Accessibility: The PorSimples project for Simplification of Portuguese Texts. In Proceedings of YIWCALA Workshop at NAACL-HLT 2010. pages 46–53.
Stefan Bott and Horacio Saggion. 2011. An Unsu-pervised Alignment Algorithm for Text Simplifica-tion Corpus ConstrucSimplifica-tion. In Proceedings of the Workshop on Monolingual Text-To-Text Generation. ACL, pages 20–26.
Richard J. Evans. 2011. Comparing methods for the syntactic simplification of sentences in informa-tion extracinforma-tion. Literary and Linguistic Computing
26(4):371–388.
Marc Franco-Salvador, Parth Gupta, Paolo Rosso, and Rafael E. Banchs. 2016. Cross-language plagiarism detection over continuous-space- and knowledge graph-based representations of language.
Knowledge-Based Systems111:87 – 99.
Goran Glavaˇs and Sanja ˇStajner. 2015. Simplifying Lexical Simplification: Do We Need Simplified Cor-pora? In Proceedings of the ACL&IJCNLP 2015 (Volume 2: Short Papers). pages 63–68.
William Hwang, Hannaneh Hajishirzi, Mari Ostendorf, and Wei Wu. 2015. Aligning Sentences from Stan-dard Wikipedia to Simple Wikipedia. In Proceed-ings of NAACL&HLT. pages 211–217.
Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, and Evan Herbst. 2007. Moses: Open source toolkit for statistical machine translation. In
Proceedings of the ACL. pages 177–180.
Philipp Koehn, Franz Josef Och, and Daniel Marcu. 2003. Statistical phrase-based translation. In Pro-ceedings of the NAACL&HLT, Vol. 1. pages 48–54.
Paul Mcnamee and James Mayfield. 2004. Character n-gram tokenization for European language text re-trieval. Information Retrieval7(1):73–97.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013a. Efficient estimation of word represen-tations in vector space. InProceedings of Workshop
at International Conference on Learning Represen-tations.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor-rado, and Jeff Dean. 2013b. Distributed representa-tions of words and phrases and their compositional-ity. InAdvances in Neural Information Processing Systems 26. pages 3111–3119.
Franz Och. 2003. Minimum Error Rate Training in Sta-tistical Machine Translation. InProceedings of the ACL. pages 160–167.
Franz Josef Och and Hermann Ney. 2003. A systematic comparison of various statistical alignment models.
Computational Linguistics29(1):19–51.
Gustavo Henrique Paetzold and Lucia Specia. 2016. Unsupervised lexical simplification for non-native speakers. InProceedings of the 30th AAAI.
Horacio Saggion, Sanja ˇStajner, Stefan Bott, Simon Mille, Luz Rello, and Biljana Drndarevic. 2015. Making It Simplext: Implementation and Evaluation of a Text Simplification System for Spanish. ACM Transactions on Accessible Computing 6(4):14:1– 14:36.
Gerard Salton and Michael J. McGill. 1986. Intro-duction to Modern Information Retrieval. McGraw-Hill, Inc.
Lucia Specia. 2010. Translating from complex to sim-plified sentences. InProceedings of the 9th PRO-POR. Springer Berlin Heidelberg, volume 6001 of
Lecture Notes in Computer Science, pages 30–39. Andreas Stolcke. 2002. SRILM - an Extensible
Lan-guage Modeling Toolkit. InProceedings of the In-ternational Conference on Spoken Language Pro-cessing (ICSLP). pages 901–904.
David Vickrey and Daphne Koller. 2008. Sentence simplification for semantic role labeling. In Pro-ceedings of ACL&HLT. volume 344–352.
Sanja ˇStajner, Hannah Bechara, and Horacio Saggion. 2015. A Deeper Exploration of the Standard PB-SMT Approach to Text Simplification and its Eval-uation. InProceedings of ACL&IJCNLP (Volume 2: Short Papers). pages 823–828.
Sanja ˇStajner and Maja Popovi´c. 2016. Can Text Sim-plification Help Machine Translation? Baltic Jour-nal of Modern Computing4(2):230–242.
Wei Xu, Chris Callison-Burch, and Courtney Napoles. 2015. Problems in Current Text Simplification Re-search: New Data Can Help. Transactions of the Association for Computational Linguistics (TACL)
3:283–297.
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze Chen, and Chris Callison-Burch. 2016. Optimizing statistical machine translation for text simplification.