Licensing of Negative Polarity Items: An Eye Tracking Study
B.L.M. Janssen Stud.nr. 9929797
Supervisor: Frank Wijnen August 2008
1 Introduction
In this thesis I present the results of two psycholinguistic experiments looking into the processing of negative polarity items (NPIs). In the introduction I will first discuss a bit of theory concerning NPIs: how they are defined, their distribution and the different theories put forward to explain it. Then I will look at the few studies that have been done so far which address the processing of these items.
In the next section I will discuss the results of an off-line experiment that was performed to find out whether readers discriminate between NPIs in combination with different licensers. Readers were asked to judge the felicity of a set of sentences with varying NPI/licenser combinations in a web-based questionnaire. This experiment served as a validation of concepts put forward in the theoretical literature and as preparation for the eye tracking experiment that followed it.
The final section deals with the results obtained from the eye tracking experiment, which looked primarily at a possible word order effect in the processing of NPIs.
1.1 Negative polarity items
1.1.1 Overview
Negative polarity items (NPIs) are expressions that seem to require negative environments to be grammatical (e.g. Zwarts, 1981; de Swart, 1998; Hoeksema, 2000). Compare the following examples (de Swart, 1998)1:
(1) Susan did not say anything. (2) *Susan said anything.
Example 1 is grammatical, because the NPI anything occurs in a negative environment; or in other words, sentence negation licenses the occurrence of the NPI (through the licenser not). Absence of a negative environment in an affirmative sentence like (2) leads to ungrammaticality; the occurrence of the NPI is not licensed.
Indefinites like anything or any are not the only type of NPI. In fact, NPIs are a very heterogeneous group of words. They occur in a variety of word classes, e.g. verbs (3), adverbs ((4); Linebarger, 1987), but also in bigger constituents like NPs ((5); Krifka, 1991) and verb phrase idioms ((6); Hoeksema, 1998).
(3) You needn't have done that. (4) I haven't ever met Mr. Smith. (5) It's not worth a red cent.
(6) Confidentially, I don't give a ragged rats ass.
Nor are NPIs restricted to English. They can be found in many languages, as shown in (7) (Dutch; Hoeksema, 1998), (8) (German; Falkenberg, 2001), (9) (Greek; Giannakidou, 1997), (10) (Serbo-Croatian; Progovac, 2000), (11) (Hindi; Lahiri, 2001). It looks like they are a general phenomenon in all natural languages (Hoeksema, 2000).
(7) De politie was niet in het minst verbaasd. (The police weren't in the least surprised.)
(8) Er braucht nicht zu kommen. (He need not come.)
(9) I Ilektra dhen enekrine kanena sxedhio. (Electra didn't approve any plan.) (10) Marija ne vidi nikoga.
(Mary doesn't see anybody.)
(11) maiN-ne ek bhii aadmii nahiiN dekhaa. (I didn't see any men/man.)
The licensing of NPIs is not as straightforward as suggested at the start of this section, i.e. solely through sentence negation. Negative quantifiers like nobody can also act as licensers, as in (12) (de Swart, 1998).
(12) Nobody lifted a finger to help us.
Things get even more complicated, though. Whereas negative quantifiers can clearly take on the role of negation in the absence of sentence negation – as in the above example – this would be very difficult to maintain for other elements that can act as licensers. These include a number of adverbs (seldom in (13); de Swart, 1998), certain determiners (few in (14); de Swart, 1998), the antecedent of conditionals ((15); Linebarger, 1987), comparatives ((16); Linebarger, 1987), and questions ((17); Linebarger, 1987).
(13) Susan seldom says anything.
(14) Few people lifted a finger to help us. (15) If you steal any food, they'll arrest you.
(16) He was taller than we ever thought he would be. (17) Have you ever met George?
1.1.2 NPI theories
A variety of theories has been proposed to explain the heterogeneous ditribution of NPIs. Semantic as well as syntactic principles have been cited, often in combination.
Among these theories decreasing monotonicity or downward entailment has received most attention. it is defined as follows (de Swart 1998; Barwise and Cooper, 1981; Zwarts, 1981):
● A quantifier Q is monotone decreasing if: Q(A,B) and B'⊆B implies Q(A,B')2
In other words, if a certain assertion holds for a particular set it also holds for all of its subsets as can be gleaned from (18) for the monotone decreasing quantifier at most (de Swart, 1998):
(18) At most five children came home → At most five children came home late3
If it is true in (18) that the set of children who came home has no more than five members, then it must also be true that the subset of children who came home late has no more than five members.
That decreasing monotonicity indeed provides a licensing environment for NPIs can be seen in (12), repeated here as (19), with the monotone decreasing quantifier nobody:
(19) Nobody lifted a finger to help us.
A quantifier that is not monotone decreasing does not license NPIs, however:
(20) Many children came home ↛ Many children came home late4
(21) *Many people lifted a finger to help us.
There are also theories that rely on both semantic and syntactic principles to explain the distribution of NPIs, notably Progovac (1992/1994). She uses the following binding approach with a syntactic principle and a semantic filter:
● NPIs are subject to Principle A of the Binding Theory.
● UE Filter: *Polarity operator in an upward-entailing5 (UE) clause.
The binding principle means that NPIs must be locally bound by a licenser like anaphora by their antecedents. This explains why (22) is ungrammatical, unlike (23), even though a licenser (no one) is present.
(22) [No one [who saw the man] said anything.] (23) *[The man [who saw no one] said anything.]
Progovac introduces the polarity operator to provide a licenser that can bind the NPI when no negation is present. It solves a few problems with the decreasing monotonicity account, e.g. 4 Many is in fact monotone increasing, the opposite of monotone decreasing, and therefore: Many children came home
late → Many children came home. There are also quantifiers that are neither monotone decreasing nor increasing,
which cannot license NPIs either, e.g. exactly X: *Exactly five children said anything. 5 Or monotone increasing, see previous footnote.
yes-no questions. These allow NPIs even though they are not monotone decreasing ((24); Progovac, 1992).
(24) Did Mary talk to anybody last night?
The semantic filter makes sure that not any sentence can be rescued by the presence of a polarity operator, which would be undesirable. (24) is not upward entailing, so the filter allows the operator and the sentence is grammatical. (25) on the other hand, is not. it is handled correctly by the filter, which rules out the presence of a polarity operator, because the sentence is upward entailing (26).
(25) *John saw anyone.
(26) John saw a pigeon → John saw a bird
1.2 Weak and strong NPIs/licensers
Not all combinations of licensers and NPIs are possible. Take for instance (27):
(27) *It's seldom worth a red cent.
It turns out there are environments that are more restrictive than decreasing monotone ones. They are antimultiplicative and anti-additive (van der Wouden, 1997; Hoeksema, 1998):
● a quantifier Q is antimultiplicative if: Q(A and B) implies Q(A) or Q(B) ● a quantifier Q is anti-additive if: Q(A or B) implies Q(A) and Q(B)
This is illustrated for the antimultiplicative not every and the anti-additive nobody (van der Wouden, 1997):
(28) Not every girl sings and dances → Not every girl sings or not every girl dances
(29) Nobody sings and dances → Nobody sings or nobody dances
Antimorphic environments are even more restrictive; they are a combination of antimultiplicativity and anti-additivity (van der Wouden, 1997; Hoeksema, 1998), illustrated in (30) and (31) for not (van der Wouden, 1997).
● a quantifier Q is antimorphic if: Q(A and B) implies Q(A) or Q(B), and Q(A or B) implies Q(A) and Q(B)
(30) John doesn't smoke and drink → John doesn't smoke or John doesn't drink
(31) John doesn't smoke or drink → John doesn't smoke and John doesn't drink
We end up, then, with the following hierarchy with a few examples of each category (van der Wouden, 1997):
DOWNWARDMONOTONE
few, seldom, hardly
ANTIMULTIPLICATIVE ANTI-ADDITIVE
not every, not always nobody, never, nothing
ANTIMORPHIC
The relevance of this hierarchy for NPI licensing can be shown with a few examples (from Dutch). Monotone decreasing (weak) dikwijls (often) cannot license all types of NPI (van der Wouden, 1997):
(32) *De kinderen kunnen de schoolmeester dikwijls uitstaan. (*The children can often stand the teacher.)
(33) *De abt heeft het geheim dikwijls aan ook maar iemand willen vertellen. (*The abbot has often wanted to tell the secret to anyone at all.)
(34) *Zijn oordeel was dikwijls mals. (*His judgement was often 'tender'.)
Anti-additive (medium) niemand (nobody), though, can license more types of NPI, but not all (van der Wouden, 1997):
(35) Niemand kan de schoolmeester uitstaan. (Nobody can stand the teacher.)
(36) Niemand zal ook maar iets bereiken. (Nobody will achieve anything at all.)
(37) *Je kunt van niemand een mals oordeel verwachten. (*You can't expect a 'tender' judgement from anyone.)
Antimorphic (strong) niet (not) can license all three of the examples (van der Wouden, 1997):
(38) De kinderen kunnen de schoolmeester niet uitstaan. (The children can't stand the teacher.)
(39) De abt heeft het geheim niet aan ook maar iemand verteld. (The abbot hasn't told the secret to anyone at all.)
(40) Zijn oordeel was niet mals. (His judgement wasn't 'tender'.)
1.3 Processing of NPIs
A lot of theoretical work has been done on NPIs. In the previous section I have only presented a few of the most important theories and a fraction of the available literature on the issue. Not much is known about the processing of NPIs, however. To my knowledge, only a couple of studies have been done using event related potentials (ERPs). A study by Saddy et al. (2004) looked at negative polarity items and positive polarity items (PPIs) in German. They compared sentences with licensed and unlicensed polarity items (i.e. a licenser was present (41) or not present (42) in the sentence). For the unlicensed NPIs they found an N400 effect, which is generally considered to reflect the processing of a semantic violation6.
(41) Kein Mann, der einen Bart hatte, war jemals glücklich. (No man who had a beard was ever happy.)
(42) *Ein Mann, der einen Bart hatte, war jemals glücklich. (*A man who had a beard was ever happy.)
A reanalysis of the data with a more sophisticated statistical technique by Drenhaus et al. (2006) also revealed a P600 effect, which was only detected for PPIs in the original study. A P600 effect is thought to indicate a syntactic violation7. In addition to violations where a 6 An N400 is a negative voltage which shows up roughly 400 ms after the onset of the stimulus it is associated with. 7 A P600 is a positive voltage after roughly 600 ms.
licenser was absent, Drenhaus et al. (2005) looked at sentences with a licenser, but the NPI outside its scope and therefore not properly licensed (43).
(43) *Ein Mann, der keinen Bart hatte, war jemals glücklich. (*A man who had no beard was ever happy.)
They again found N400 and P600 effects, i.e. both semantic and syntactic violations. The data from this study were also reanalysed in Drenhaus et al. (2006) which showed that the syntactic effect was both weaker and earlier for sentences with an inaccesible licenser compared to those without a licenser.
What these cognitive studies seem to show, then, is that the licensing of NPIs relies on both semantic and syntactic processes. Drenhaus et al. (2006) conclude that their observed N400 effect reflects a semantic integration problem in the unlicensed and inaccesible conditions. The earlier, weaker positivity for the inaccesible licenser indicates the availability of an alternative, though un grammatical, syntactic representation. This alternative is unavailable for the unlicensed NPIs, leading to a stronger P600.
1.4 A psycholinguistic study
In the next two sections I will present the results of the two NPI experiments we performed. The aim of the first experiment was to see if the predictions in the linguistic literature regarding NPIs are borne out in the judgements of naïve readers. Theory predicts that utterances with unlicensed NPIs are ungrammatical, which should be reflected in much lower acceptability judgements. We also compared the NPI with a non-polar equivalent with again the NPI expected to show lower acceptability judgements in the unlicensed cases. There is also
the question of different types of licenser: do readers differentiate between weak and strong licensers?
The first experiment was also used as a pilot for the second experiment; it gave us an opportunity to check the materials that were going to be used. This was especially important for the weak and strong licensers: in order to decrease the number of conditions, if possible, the idea was to drop the weak licensers from the second experiment if they were not judged to be any more or less acceptable than the strong licensers. Two different word orders were also included, because these were going to be used in the second experiment.
The second experiment was an eye tracking experiment. We wanted to find out whether the predicted differences between NPIs and non-NPIs, and between licensers would not only show up in off-line acceptability judgements, but also in on-line reading measures. We also wanted to look at a possible word order effect (NPI first or licenser first). The rationale behind this was that it could hopefully tell us something about how the licensing of NPIs actually takes place, how a connection is made between NPI and licenser. One could imagine for instance that upon encountering an NPI first the need for a licenser would be flagged, with an associated processing cost, leading to longer reading times in the main clause (NPI first) condition.
2 Pilot experiment
2.1 Introduction
In this experiment subjects were asked to give acceptability judgements for sentences containing either the verb hoeven or moeten. These sentences also contained the weak NPI
licenser zelden (seldom), the strong licenser niet (not) or the non-licenser altijd (always). Although a distinction between weak and strong NPI licensers is made in the theoretical literature, this may not show up in psycholinguistic measures. Our main aim therefore, as mentioned in the introduction, was to assess whether we could distinguish between a weak and a strong NPI licenser (zelden vs. niet). If not, the weak licenser would be omitted from the main eye tracking experiment so as not to overcomplicate it with a distinction we could not pick up in a simpler experiment and which may not exist.
The verbs hoeven and moeten were chosen because they are semantically similar, but only hoeven is an NPI (compare (44) and (45)) (Koster and van der Wal, 1996). This allows us to look at differences in the interaction of the licensers with NPIs and items that are not polarity sensitive.
(44) *Frank hoefde het eten te koken. (*Frank had to cook supper.) (45) Frank moest het eten koken.
(Frank had to cook supper.)
2.2 Materials and methods
2.2.1 Participants
30 members of the public volunteered to take part in our study. 17 of them were male and 13 female, with a mean age of 27 (range 20-66 years). They were recruited among fellow students, lecturers, friends and family. All of them were native speakers of Dutch.
2.2.2 Method
Participants were asked to give acceptability ratings using a web-based questionnaire. They were allowed to use any computer with a working internet connection; they could also pause the questionnaire and complete it at a later time if they so wished (4 out of 30 participants did). Stimuli were presented and responses recorded with the CGI script WWStim (version 1.4.4: Veenker, 2003). The order in which stimuli appeared was fully randomized for each participant.
In eliciting acceptability judgements the technique of magnitude estimation was applied (Bard et al., 1996). This technique allows for a more sensitive measurement of fine distinctions. Participants are not restricted in their levels of judgement as they are with a conventional Likert type scale (in which 5 or 7 levels are most commonly used), but they are entirely free to choose their own scale. For example, in our experiment one participant gave acceptability judgements with numerical values ranging from 2 to 15 and someone else used values ranging from 0 to 100. This freedom of choice was emphasized at the start of the questionnaire to avoid participants restricting themselves to a Likert type scale of their own, with which they may be more familiar.
The first stimulus presented in the experiment was a reference sentence, called the modulus. Participants were asked to judge its acceptability and assign a numerical value to it. They would then make acceptability judgements for the experimental sentences relative to this modulus. To be able to compare judgements from different participants (who all used different scales) the values assigned to the experimental sentences are normalized by dividing them by the value for the modulus (Bard et al., 1996).
2.2.3 Materials
Three different variables were manipulated: verb, licenser and type of clause. There were two instances of the variable verb (the NPI hoeven and the non-NPI moeten), three of licenser (altijd, zelden, niet) and two of type of clause (main clause and subordinate clause), resulting in twelve experimental conditions. For each condition four sentences were constructed and distributed over two lists. Each list therefore comprised 24 experimental sentences (two for each of the twelve conditions) to which 72 fillers with a similar sentence structure were added, leading to a total of 96 acceptability judgements from each participant. Participants were randomly assigned to one of the lists.
Sentences were constructed starting with a short statement about a named person followed by a phrase indicating a cause. This phrase contained both the verb of interest and the (non)-licenser, as in example (46)8. The reason we used the causal phrases is that in Dutch they can be introduced by one of the conjunctions want (because) or omdat (because); these are very similar in meaning, but lead to a difference in word order, as can be seen when comparing (46) to (47)9.
(46) Frank kon op de bank blijven zitten, want hij hoefde het eten niet te koken. Frank could on the sofa remain sitting, because he needed the food not to cook (Frank could stay on the sofa, because he didn't need to cook supper.)
(47) Frank kon op de bank blijven zitten, omdat hij niet het eten hoefde te koken. Frank could on the sofa remain sitting, because he not the food needed to cook (Frank could stay on the sofa, because he didn't need to cook supper.)
Notice that in the want sentences the verb precedes the licenser in the linear order (hoefde (needed to) precedes niet in (46)), whereas in the omdat sentences it is the licenser that precedes the verb (niet precedes hoefde in (47)). Matching pairs like these were also constructed for the other (non-)licensers altijd and zelden and the verb moeten. Sentences were not matched however between (non-)licensers and verbs. It is not expected that the word order difference will affect the acceptability judgements in this pilot experiment, but we are interested in its possible effect in the eye tracking experiment.
2.3 Results
Of the three independent variables in this experiment only one showed a significant main effect: sentences with the non-licenser altijd were judged to be less acceptable (mean = 0.77) than sentences with either of the licensers zelden (0.91) or niet (0.94) (F1(1.27,35.41) = 6.47, p = .011; F2(2,24) = 15.56, p < .0001)10. There were no main effects for the type of clause (main clause vs. subordinate clause) or verb (non-NPI moeten vs. NPI hoeven) (all p's > .05).
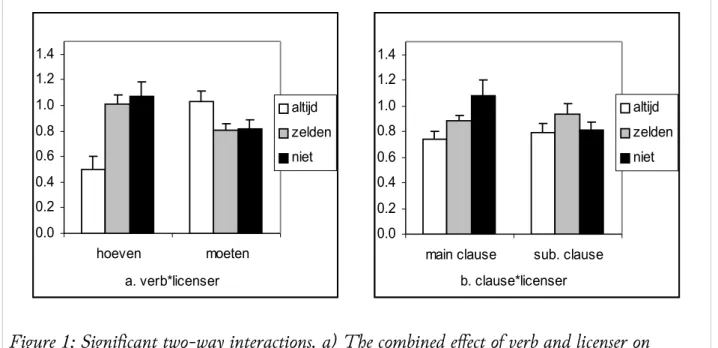
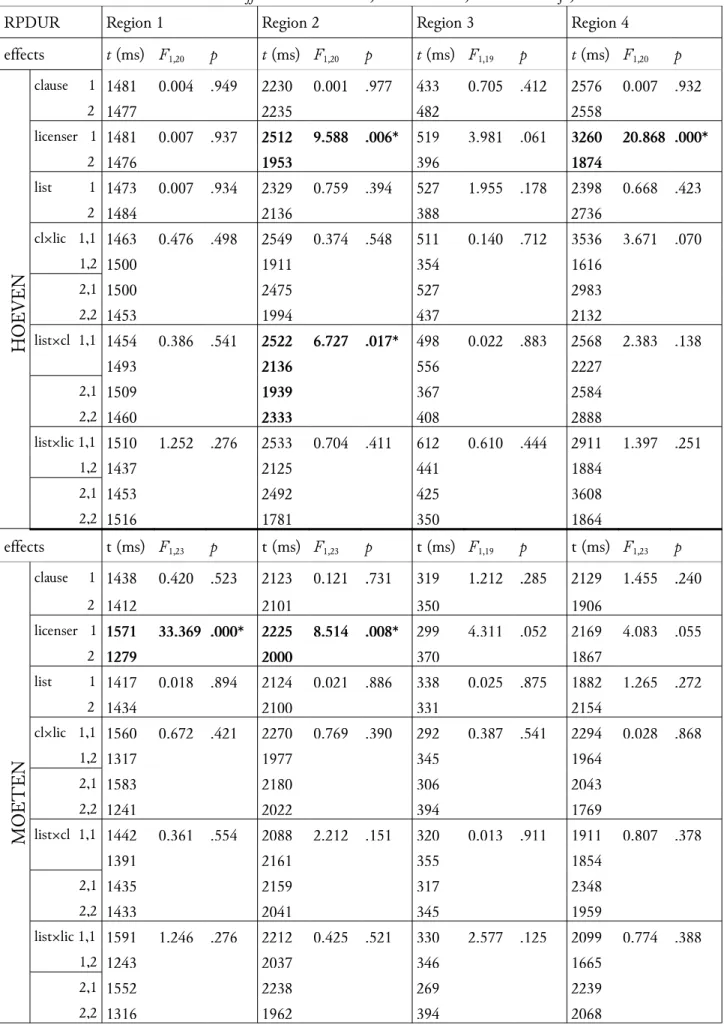
There were two two-way interactions: an interaction between verb and licenser (F1(1.10,30.78) = 16.94, p < .0001; F2(2,24) = 80.86, p < .0001) and an interaction between type of clause and licenser (F1(1.12,31.25) = 6.02, p = .017; F2(2,24) = 14.92, p < .0001). If we look at Figure 1a we see that the verb-licenser interaction is mainly due to a much lower acceptability of the unlicensed hoeven items – i.e. sentences with the verb hoeven and the non-licenser altijd – (mean = 0.50) as compared to the licensed hoeven items – the sentences with hoeven and one of the licensers zelden or niet – which have an acceptability rating of 1.01 and 1.07 respectively. There is also an effect in the moeten items (see Figure 1a), although it seems
10 Because the condition of sphericity was not met, degrees of freedom and p-values have been corrected using Greenhouse-Geisser estimates.
to be a bit weaker. The sentences with the verb moeten and the non-licenser altijd are judged more acceptable (mean = 1.03) than the sentences with moeten that contain either licenser (zelden 0.81, niet 0.82).
Figure 1b indicates that the type of clause-licenser interaction derives mainly from the main clause items. The stronger the licenser – with niet a stronger licenser than zelden and altijd not a licenser at all – the more acceptable the sentences (means of 1.08, 0.88, and 0.74 respectively for niet, zelden and altijd).
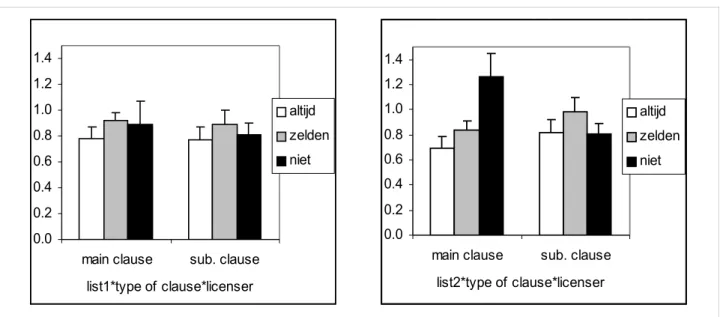
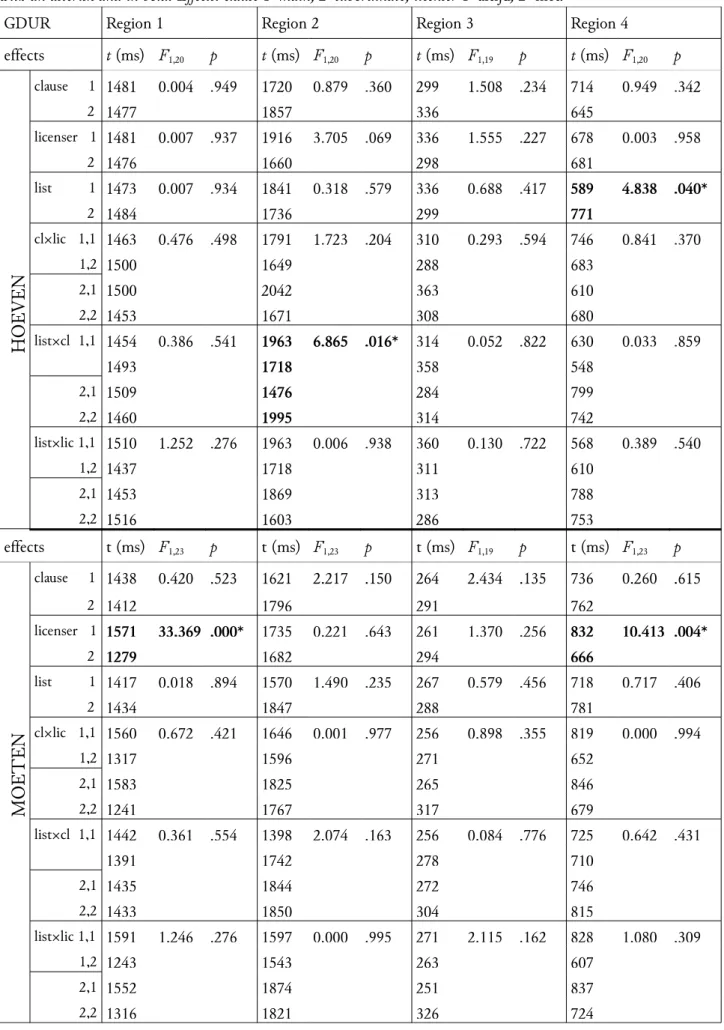
Of the three-way interactions there was one that reached significance: the interaction between list, type of clause and licenser (F1(1.12,31.25) = 4.07, p = .048; F2(2,24) = 10.10, p = .001) (Figure 2). In list 2 main clauses with the strong licenser niet have a markedly higher acceptability than any of the other conditions.
Figure 1: Significant two-way interactions. a) The combined effect of verb and licenser on acceptability ratings. b) The combined effect of type of clause and licenser on acceptability ratings.Error bars indicate standard errors.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 hoeven moeten a. verb*licenser altijd zelden niet 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4
main clause sub. clause b. clause*licenser
altijd zelden niet
2.4 Discussion
The verb hoeven, being an NPI, needs the presence of a licenser to yield a grammatically correct sentence. It was therefore hypothesized that sentences with altijd would be judged less acceptable compared to sentences with zelden or niet, because unlike the latter two altijd cannot act as a licenser. This prediction was indeed borne out: a main effect of licenser was found. The effect is perhaps not very pronounced, but bearing in mind that it also includes moeten items, that does not come as a surprise. Moeten does not need to be licensed, so the absence of a licenser should not influence acceptability.
If we look at the verb-licenser interaction in Figure 1a we see that the hoeven items without licenser are clearly worse than the ones with a licenser. Here, with hoeven and moeten not taken together, the effect is much more obvious, as expected. There is also an effect in the moeten items, though (Figure 1a). The sentences with either of the licensers are judged a little less acceptable than the ones without a licenser. This cannot be due to ungrammaticality of the
Figure 2: Significant three-way interaction between list, type of clause and licenser.Error bars indicate standard errors.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4
main clause sub. clause list1*type of clause*licenser altijd zelden niet 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4
main clause sub. clause list2*type of clause*licenser
altijd zelden niet
'licensed' moeten items: since moeten is not an NPI (nor indeed a positive polarity item) the presence or absence of a licenser does not influence the grammaticality of these sentences. The observed effect can however be attributed to the fact that the 'licensed' moeten items are slightly marked: with a licenser present hoeven would be the preferred alternative.
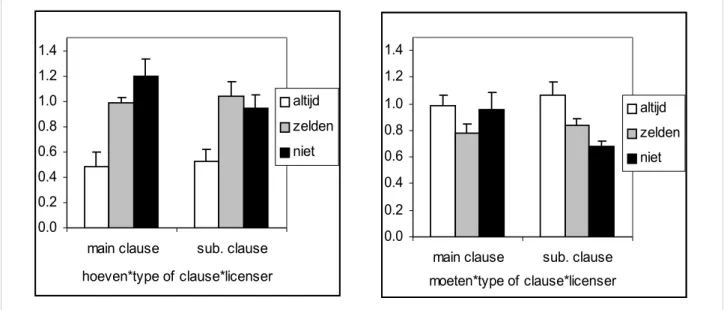
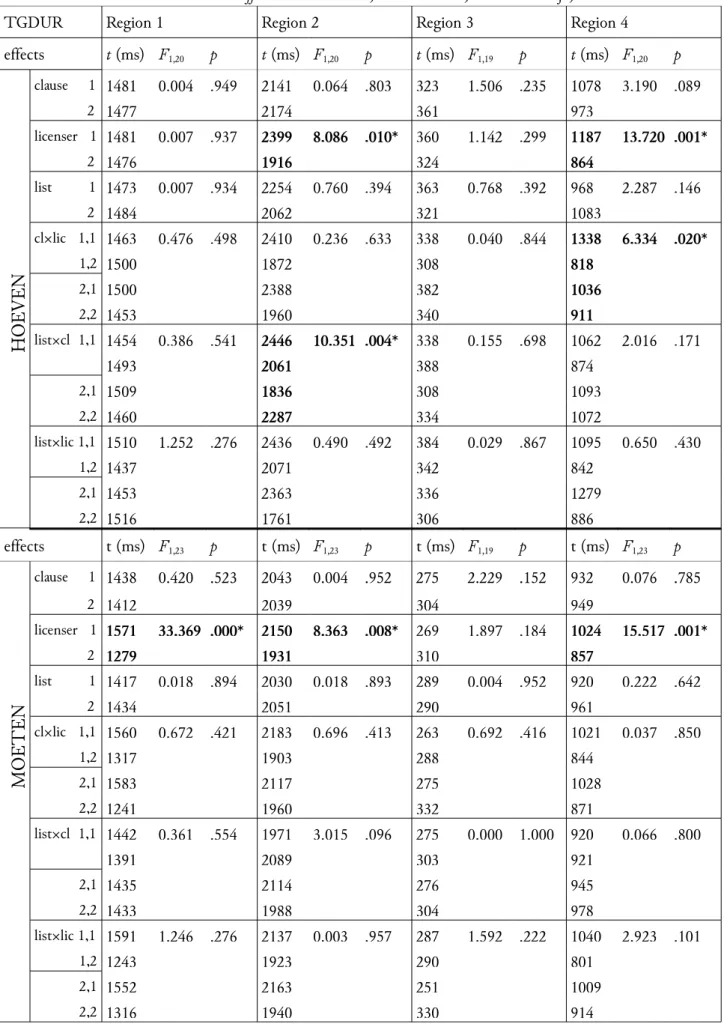
The second significant two-way interaction is also very interesting. We see in Figure 1b that type of clause interacts with licenser. Whereas nothing much seems to happen in the subordinate clauses, in the main clauses an increasing strength of licenser leads to an increased acceptability. Remember that in these main clauses the verb precedes the licenser. Thus, when hoeven is encountered it is not yet clear whether it will be licensed at all, yielding a grammatical sentence. Perhaps a stronger licenser is better able to redeem it when it is encountered later on in the sentence. However, if we split the combined clausal effect into separate effects for hoeven and moeten, we see that there is not really a word order effect for hoeven. Figure 3 suggests the subordinate clause moeten items are responsible for the word order effect.
Figure 3: Clause*licenser interaction separated for each verb: a) hoeven; b) moeten.Error bars indicate standard errors.
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4
main clause sub. clause hoeven*type of clause*licenser altijd zelden niet 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4
main clause sub. clause moeten*type of clause*licenser
altijd zelden niet
The three-way interaction of type of clause and licenser with list (see Figure 2) is obviously an unwanted effect. It seems to be caused by an unusually high acceptability of the main clause niet items in list 2. If we look at the items in question (11, 12, 35, 36 in Appendix A) however, they do not seem to stand out in any way.
The most important conclusion to draw from this experiment though, is that we could not distinguish between the weak licenser zelden and the strong licenser niet. Although this is an important distinction in the theoretical literature, it does not show up here. As long as a licenser is present to make the sentence grammatical it is judged acceptable, regardless of the type of licenser. It is therefore doubtful whether we would find a difference between the two licensers in an eye-tracking experiment, so we have decided to drop the zelden items. This will ensure that the eye-tracking experiment does not become unnecessarily complicated and enable us to focus on the distinction between licensed and non-licensed sentences and a possible word order effect with the main and subordinate clauses.
3 Eye tracking
3.1 Materials and methods
3.1.1 Participants
32 members of the Utrecht University community were paid to take part in our study. 4 of them were male and 28 female, with a mean age of 22 (range 18-43 years). All of them had normal or corrected to normal vision. They were all native speakers of Dutch.
3.1.2 Method
Stimuli were presented on a 19" Nokia Multigraph 446X Pro CRT screen. Participants were seated at an approximate viewing distance of 70 cm. To monitor eye movements we used a head-mounted SMI EyeLink I (SensoMotoric Instruments) with an angular resolution of 20 seconds of arc and a sampling frequency of 250 Hz. Although viewing was binocular eye movements were only recorded for the right eye.
Participants received on oral instruction of the experimental procedure and they were encouraged to read in their own tempo, after which the eye tracker was calibrated. Calibration comprised a random sequence of dots on the screen which the participants were asked to fixate. Upon successful calibration participants were presented with three practice stimuli; one of these was followed by a comprehension question. Halfway through the experiment the calibration procedure was repeated. Before each stimulus a dot appeared on the left of the screen at the position of the first word to make sure the first fixation was always on the first word of the sentence. It was also used for drift correction. When the dot was fixated correctly, the stimulus would appear automatically. The participants pressed a button when they had finished reading a sentence. The whole procedure was completed in approximately half an hour.
3.1.3 Materials
The materials used for the eye tracking experiment were adapted from the stimuli in the pilot experiment. Firstly, the zelden items were omitted, because we could not distinguish between these and the niet items in the acceptability judgements as discussed in section 2.4. We therefore concluded that in the current set-up the zelden items would not offer any additional
insight into NPI processing and only complicate the design. Secondly, a few words were inserted into each sentence between the NPI and the licenser for two reasons: to avoid an overlap of the effects on the NPI and the licenser; and to ensure the regions of interest did not appear near the edge of the screen to avoid spurious effects like reverse sweep preparation and sentence wrap-up. Example (48)/(49) shows the difference between the pilot and eye tracking experiments for one of the stimuli (The full list can be found in appendix B):
(48) Bas is op tijd thuis, want hij hoeft de drukte niet te omzeilen. Bas is on time home, because he need the 'busy traffic' not to avoid (Bas is home on time, because he doesn't need to avoid the busy traffic.)
(49) Bas is op tijd thuis, want hij hoeft de vakantiedrukte op de snelweg Bas is on time home, because he need the 'busy holiday traffic' on the motorway naar huis niet te omzeilen in de avondspits.
to home not to avoid in the evening rush hour
(Bas is home on time, because he doesn't need to avoid the busy holiday traffic on the motorway on his way home in the evening rush hour.)
With the zelden items omitted, there were two instances of the variable verb (the NPI hoeven and the non-NPI moeten), two of licenser (non-licenser altijd, licenser niet) and two of type of clause (main clause and subordinate clause), resulting in a total of eight conditions.
For each condition there were again four sentences distributed over two lists. Remember that the two different word orders appeared in matching sentences (see 2.2.3); each of these was included in a different list. The lists therefore comprised 16 experimental sentences (two for each of the eight conditions) with each of them matched to a sentence in the other list with (non-)licenser and verb switched. To the experimental sentences 32 fillers with a similar
sentence structure were added for a total of 48 stimuli; four pseudo-random sequences were constructed for each list. Participants were randomly assigned to one of the lists.
A third of the stimuli was followed by a comprehension question. These were yes-no questions which the participants answered using a button box. 'Yes' and 'no' appeared in a coloured box on the screen to ensure the participants did not look away from it, possibly leading to tracker loss. Due to a software error the responses of 29 out of the 32 participants were not recorded. Of the remaining three participants two answered correctly on all occasions and one made a single mistake.
3.1.4 Data analysis
For the analysis of reading times the sentences were divided into four regions, as shown in example 50.
(50) Bas is op tijd thuis, want hij // hoeft de vakantiedrukte
Region 1 Region 2
op de snelweg naar huis niet // te omzeilen // in de avondspits. Region 2 Region 3 Region 4
The first region introduces the sentence. The second region is our main region of interest: it contains both the (non-)NPI (moeten or hoeven) and its (non-)licenser (niet or altijd). The third region comprises only a verb (and te in case of hoeven) and region 4 everything after the verb.
It was decided to include NPI and licenser in one big region for two important reasons: firstly, because they are probably too small to constitute a region of their own, leading to a lot
of missing data points when they were not fixated; secondly, because of the word order manipulation. The two different word orders would be impossible to compare with the NPI and the licenser in different regions. This would lead to a comparison of NPIs with licensers, e.g. hoeven with niet in (51)/(52); region B has hoeft in (51) and niet in (52) and vice versa for region D.
(51) Bas is op tijd thuis, want hij // hoeft // de vakantiedrukte Region A Region B Region C
op de snelweg naar huis // niet // te omzeilen // in de avondspits. Region C Region D Region E Region F (52) Bas is op tijd thuis, omdat hij // niet // de vakantiedrukte
Region A Region B Region C
op de snelweg naar huis // hoeft // te omzeilen // in de avondspits. Region C Region D Region E Region F
Region 3 was chosen as a spill-over region to capture possible delayed effects from the previous region.
In the results section we report six different eye tracking measures. They are: first fixation duration (ffdur), first gaze duration (gdur), regression path duration (rpdur), total first gaze duration (tgdur), second pass reading time (secpass) and total reading time (totfix). First fixation duration is simply the duration of the first fixation in a particular region. First gaze duration is the sum of all fixations in a region until the region is left either progressively or regressively . Regression path duration is the time it takes the reader from first entering a region to moving out of the region in a forward direction. This measure also includes fixations in previous regions to which the reader may have regressed before moving forward. Total first
gaze duration includes all fixations in a region before it is left progressively. It differs from regression path duration in that it does not include fixations from previous regions. Second pass reading time comprises fixations made in a region when it is read for a second time, i.e. after it has been left in either direction11. Total reading time is the sum of all fixations in a region.
3.2 Results
Table 1-6 report the six reading time measures discussed in the data analysis section. Main effects of clause (main vs. subordinate, i.e. NPI first vs. licenser first), licenser (altijd vs. niet), and list, as well as their interactions are reported. The two verbs hoeven and moeten were analysed separately and their results can be found underneath each other in each table. F ratios are from a by-subjects analysis. A by-items analysis was not performed; in our set-up each condition had only two different items, making it impossible to do a meaningful by-items analysis. Extensive tracker loss and blinks – which prevented us from properly determining which words were fixated – led to the loss of 23% of data, where whole items had to be discarded. This is reflected in the F ratios with less degrees of freedom.
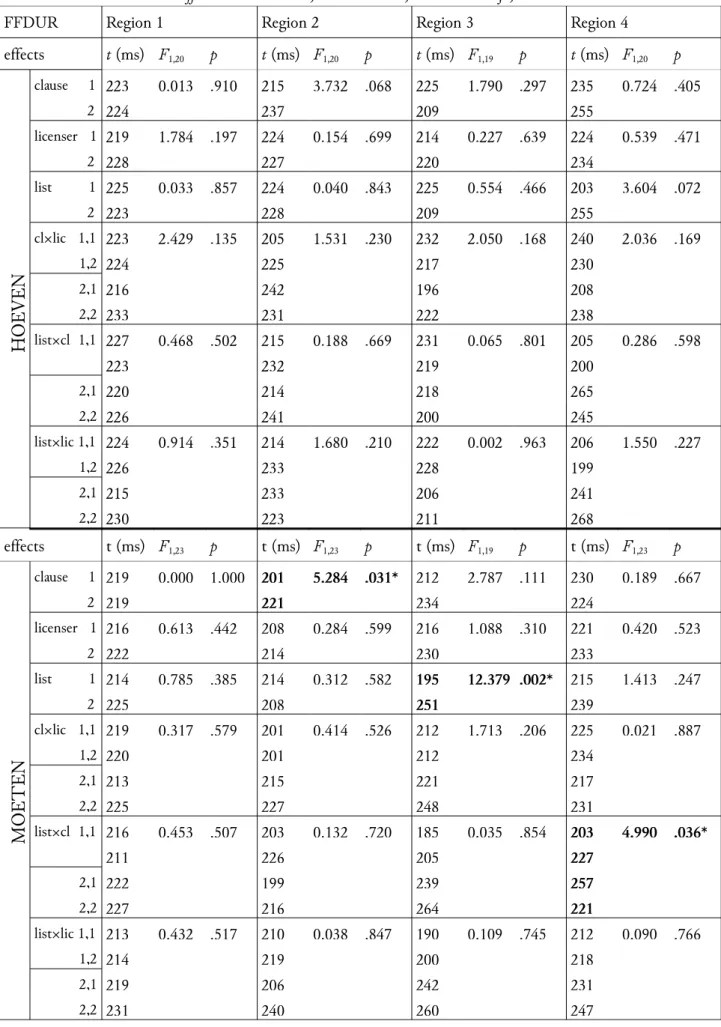
For first fixation durations (Table 1) there were no significant effects in the hoeven items; in the moeten items of clause (main 201ms < subordinate 221ms; F(1,23) = 5.284, p = . 031) in region 2, list (list1 195ms < list2 251ms; F(1,19) = 12.379, p = .002) in region 3, and listclause (list1/main 203ms, list1/subordinate 227ms, list2/main 257ms, list2/subordinate 221ms; F(1,23) = 4.990, p = .036) in region 4.
Regression path durations (Table 2) had in the hoeven items significant effects of licenser (altijd 2512ms > niet 1953ms; F(1,20) = 9.588, p = .006) and listclause (list1/main
2522 ms, list1/subordinate 2136ms, list2/main 1939ms, list2/subordinate 2333ms; F(1,20) = 6.727, p = .017) in region 2 and licenser (altijd 3260ms > niet 1874ms; F(1,20) = 20.868, p < . 001) in region 4; for moeten effects of licenser (altijd 1571ms > niet 1279ms; F(1,23) = 33.369, p < .001) in region 1, and licenser (altijd 2225ms > niet 2000ms; F(1,23) = 8.514, p = .008) in region 2.
For first gaze durations (Table 3) there were significant effects in the hoeven items of listclause (list1/main 1963ms, list1/subordinate 1718ms, list2/main 1576ms, list2/subordinate 1995ms; F(1,20) = 6.865, p = .016) in region 2, and list (list1 589ms, list2 771ms; F(1,20) = 4.838, p = .040) in region 4; in the moeten items effects of licenser (altijd 1571ms > niet 1279ms; F(1,23) = 33.369, p < .001) in region 1 and licenser (altijd 832ms > niet 666ms; F(1,23) = 10.413, p = .004) in region 4.
For total first gaze durations (Table 4) there were significant effects in the hoeven items of licenser (altijd 2399ms > niet 1916ms; F(1,20) = 8.086, p = .010) and listclause (list1/main 2446ms, list1/subordinate 2061ms, list2/main 1826ms, list2/subordinate 2287ms; F(1,20) = 10.351, p = .004) in region 2, and licenser (altijd 1187ms > niet 864ms; F(1,20) = 13.720, p = . 001) and clauselicenser (main/altijd 1338ms, main/niet 818ms, subordinate/altijd 1036ms, subordinate/niet 911ms; F(1,20) = 6.334, p = .020) in region 4; in the moeten items effects of licenser (altijd 1571ms > niet 1279ms; F(1,23) = 33.369, p < .001) in region 1, licenser (altijd 2150ms > niet 1931ms; F(1,23) = 8.363, p = .008) in region 2, and licenser (altijd 1024ms > niet 857ms; F(1,23) = 15.517, p = .001) in region 4.
For second pass reading times (Table 5) there were significant effects in the hoeven items of licenser (altijd 842ms > niet 484ms; F(1,20) = 12.063, p = .002) in region 1, licenser (altijd 1396ms > niet 564ms; F(1,20) = 13.130, p = .002) and clauselicenser (main/altijd 1664ms, main/niet 406ms, subordinate/altijd 1127ms, subordinate/niet 723ms; F(1,20) = 6.990, p = . 016) in region 2, and licenser (altijd 463ms > niet 174ms; F(1,20) = 11.632, p = .003) in region
4; there were no significant effects in the moeten items.
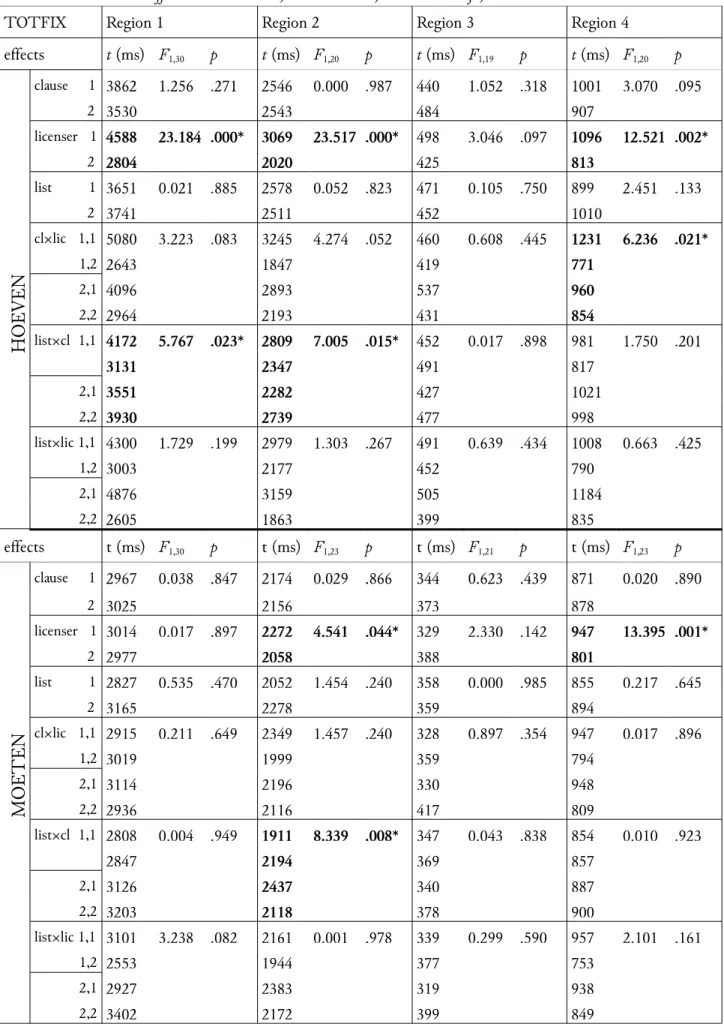
For total reading times (Table 6) there were significant effects in the hoeven items of licenser (altijd 4588ms > niet 2804ms; F(1,30) = 23.184, p < .001) and listclause (list1/main 4172ms, list1/subordinate 3131ms, list2/main 3551ms, list2/subordinate 3930ms; F(1,30) = 5.767, p = .023) in region 1, licenser (altijd 3069ms > niet 2020ms; F(1,20) = 23.517, p < .001) and listclause (list1/main 2809ms, list1/subordinate 2347ms, list2/main 2282ms, list2/subordinate 2739ms; F(1,20) = 7.005, p = .015) in region 2, and licenser (altijd 1096ms > niet 813ms; F(1,20) = 12.521, p = .002) and clauselicenser (main/altijd 1231ms, main/niet 771ms, subordinate/altijd 960ms, subordinate/niet 854ms; F(1,20) = 6.236, p = .021) in region 4; in the moeten items effects of licenser (altijd 2272ms > niet 2058ms; F(1,23) = 4.541, p = . 044) and listclause (list1/main 1911ms, list1/subordinate 2194ms, list2/main 2437ms, list2/subordinate 2118ms; F(1,23) = 8.339, p = .008) in region 2, and licenser (altijd 947ms > niet 801ms; F(1,23) = 13.395, p = .001) in region 4.
Table 1: Mean first fixation durations for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
FFDUR Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,20 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 223 0.013 .910 215 3.732 .068 225 1.790 .297 235 0.724 .405 2 224 237 209 255 licenser 1 219 1.784 .197 224 0.154 .699 214 0.227 .639 224 0.539 .471 2 228 227 220 234 list 1 225 0.033 .857 224 0.040 .843 225 0.554 .466 203 3.604 .072 2 223 228 209 255 cllic 1,1 223 2.429 .135 205 1.531 .230 232 2.050 .168 240 2.036 .169 1,2 224 225 217 230 2,1 216 242 196 208 2,2 233 231 222 238 listcl 1,1 227 0.468 .502 215 0.188 .669 231 0.065 .801 205 0.286 .598 223 232 219 200 2,1 220 214 218 265 2,2 226 241 200 245 listlic 1,1 224 0.914 .351 214 1.680 .210 222 0.002 .963 206 1.550 .227 1,2 226 233 228 199 2,1 215 233 206 241 2,2 230 223 211 268 effects t (ms) F1,23 p t (ms) F1,23 p t (ms) F1,19 p t (ms) F1,23 p M O ET EN clause 1 219 0.000 1.000 201 5.284 .031* 212 2.787 .111 230 0.189 .667 2 219 221 234 224 licenser 1 216 0.613 .442 208 0.284 .599 216 1.088 .310 221 0.420 .523 2 222 214 230 233 list 1 214 0.785 .385 214 0.312 .582 195 12.379 .002* 215 1.413 .247 2 225 208 251 239 cllic 1,1 219 0.317 .579 201 0.414 .526 212 1.713 .206 225 0.021 .887 1,2 220 201 212 234 2,1 213 215 221 217 2,2 225 227 248 231 listcl 1,1 216 0.453 .507 203 0.132 .720 185 0.035 .854 203 4.990 .036* 211 226 205 227 2,1 222 199 239 257 2,2 227 216 264 221 listlic 1,1 213 0.432 .517 210 0.038 .847 190 0.109 .745 212 0.090 .766 1,2 214 219 200 218 2,1 219 206 242 231 2,2 231 240 260 247
Table 2: Mean regression path durations for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
RPDUR Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,20 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 1481 0.004 .949 2230 0.001 .977 433 0.705 .412 2576 0.007 .932 2 1477 2235 482 2558 licenser 1 1481 0.007 .937 2512 9.588 .006* 519 3.981 .061 3260 20.868 .000* 2 1476 1953 396 1874 list 1 1473 0.007 .934 2329 0.759 .394 527 1.955 .178 2398 0.668 .423 2 1484 2136 388 2736 cllic 1,1 1463 0.476 .498 2549 0.374 .548 511 0.140 .712 3536 3.671 .070 1,2 1500 1911 354 1616 2,1 1500 2475 527 2983 2,2 1453 1994 437 2132 listcl 1,1 1454 0.386 .541 2522 6.727 .017* 498 0.022 .883 2568 2.383 .138 1493 2136 556 2227 2,1 1509 1939 367 2584 2,2 1460 2333 408 2888 listlic 1,1 1510 1.252 .276 2533 0.704 .411 612 0.610 .444 2911 1.397 .251 1,2 1437 2125 441 1884 2,1 1453 2492 425 3608 2,2 1516 1781 350 1864 effects t (ms) F1,23 p t (ms) F1,23 p t (ms) F1,19 p t (ms) F1,23 p M O ET EN clause 1 1438 0.420 .523 2123 0.121 .731 319 1.212 .285 2129 1.455 .240 2 1412 2101 350 1906 licenser 1 1571 33.369 .000* 2225 8.514 .008* 299 4.311 .052 2169 4.083 .055 2 1279 2000 370 1867 list 1 1417 0.018 .894 2124 0.021 .886 338 0.025 .875 1882 1.265 .272 2 1434 2100 331 2154 cllic 1,1 1560 0.672 .421 2270 0.769 .390 292 0.387 .541 2294 0.028 .868 1,2 1317 1977 345 1964 2,1 1583 2180 306 2043 2,2 1241 2022 394 1769 listcl 1,1 1442 0.361 .554 2088 2.212 .151 320 0.013 .911 1911 0.807 .378 1391 2161 355 1854 2,1 1435 2159 317 2348 2,2 1433 2041 345 1959 listlic 1,1 1591 1.246 .276 2212 0.425 .521 330 2.577 .125 2099 0.774 .388 1,2 1243 2037 346 1665 2,1 1552 2238 269 2239
Table 3: Mean first gaze durations for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
GDUR Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,20 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 1481 0.004 .949 1720 0.879 .360 299 1.508 .234 714 0.949 .342 2 1477 1857 336 645 licenser 1 1481 0.007 .937 1916 3.705 .069 336 1.555 .227 678 0.003 .958 2 1476 1660 298 681 list 1 1473 0.007 .934 1841 0.318 .579 336 0.688 .417 589 4.838 .040* 2 1484 1736 299 771 cllic 1,1 1463 0.476 .498 1791 1.723 .204 310 0.293 .594 746 0.841 .370 1,2 1500 1649 288 683 2,1 1500 2042 363 610 2,2 1453 1671 308 680 listcl 1,1 1454 0.386 .541 1963 6.865 .016* 314 0.052 .822 630 0.033 .859 1493 1718 358 548 2,1 1509 1476 284 799 2,2 1460 1995 314 742 listlic 1,1 1510 1.252 .276 1963 0.006 .938 360 0.130 .722 568 0.389 .540 1,2 1437 1718 311 610 2,1 1453 1869 313 788 2,2 1516 1603 286 753 effects t (ms) F1,23 p t (ms) F1,23 p t (ms) F1,19 p t (ms) F1,23 p M O ET EN clause 1 1438 0.420 .523 1621 2.217 .150 264 2.434 .135 736 0.260 .615 2 1412 1796 291 762 licenser 1 1571 33.369 .000* 1735 0.221 .643 261 1.370 .256 832 10.413 .004* 2 1279 1682 294 666 list 1 1417 0.018 .894 1570 1.490 .235 267 0.579 .456 718 0.717 .406 2 1434 1847 288 781 cllic 1,1 1560 0.672 .421 1646 0.001 .977 256 0.898 .355 819 0.000 .994 1,2 1317 1596 271 652 2,1 1583 1825 265 846 2,2 1241 1767 317 679 listcl 1,1 1442 0.361 .554 1398 2.074 .163 256 0.084 .776 725 0.642 .431 1391 1742 278 710 2,1 1435 1844 272 746 2,2 1433 1850 304 815 listlic 1,1 1591 1.246 .276 1597 0.000 .995 271 2.115 .162 828 1.080 .309 1,2 1243 1543 263 607 2,1 1552 1874 251 837 2,2 1316 1821 326 724
Table 4: Mean total first gaze durations for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
TGDUR Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,20 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 1481 0.004 .949 2141 0.064 .803 323 1.506 .235 1078 3.190 .089 2 1477 2174 361 973 licenser 1 1481 0.007 .937 2399 8.086 .010* 360 1.142 .299 1187 13.720 .001* 2 1476 1916 324 864 list 1 1473 0.007 .934 2254 0.760 .394 363 0.768 .392 968 2.287 .146 2 1484 2062 321 1083 cllic 1,1 1463 0.476 .498 2410 0.236 .633 338 0.040 .844 1338 6.334 .020* 1,2 1500 1872 308 818 2,1 1500 2388 382 1036 2,2 1453 1960 340 911 listcl 1,1 1454 0.386 .541 2446 10.351 .004* 338 0.155 .698 1062 2.016 .171 1493 2061 388 874 2,1 1509 1836 308 1093 2,2 1460 2287 334 1072 listlic 1,1 1510 1.252 .276 2436 0.490 .492 384 0.029 .867 1095 0.650 .430 1,2 1437 2071 342 842 2,1 1453 2363 336 1279 2,2 1516 1761 306 886 effects t (ms) F1,23 p t (ms) F1,23 p t (ms) F1,19 p t (ms) F1,23 p M O ET EN clause 1 1438 0.420 .523 2043 0.004 .952 275 2.229 .152 932 0.076 .785 2 1412 2039 304 949 licenser 1 1571 33.369 .000* 2150 8.363 .008* 269 1.897 .184 1024 15.517 .001* 2 1279 1931 310 857 list 1 1417 0.018 .894 2030 0.018 .893 289 0.004 .952 920 0.222 .642 2 1434 2051 290 961 cllic 1,1 1560 0.672 .421 2183 0.696 .413 263 0.692 .416 1021 0.037 .850 1,2 1317 1903 288 844 2,1 1583 2117 275 1028 2,2 1241 1960 332 871 listcl 1,1 1442 0.361 .554 1971 3.015 .096 275 0.000 1.000 920 0.066 .800 1391 2089 303 921 2,1 1435 2114 276 945 2,2 1433 1988 304 978 listlic 1,1 1591 1.246 .276 2137 0.003 .957 287 1.592 .222 1040 2.923 .101 1,2 1243 1923 290 801 2,1 1552 2163 251 1009
Table 5: Mean second pass reading times for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
SECDUR Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,20 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 629 0.592 .451 1035 0.306 .586 160 0.041 .842 334 0.255 .619 2 698 925 168 302 licenser 1 842 12.063 .002* 1396 13.130 .002* 182 1.021 .325 463 11.632 .003* 2 484 564 146 174 list 1 679 0.061 .808 956 0.036 .852 155 0.143 .710 348 0.495 .490 2 648 1004 173 289 cllic 1,1 835 0.390 .539 1664 6.990 .016* 172 0.116 .738 538 3.790 .066 1,2 422 406 149 131 2,1 850 1127 192 388 2,2 546 723 144 216 listcl 1,1 720 2.831 .108 1069 0.328 .573 147 0.057 .814 397 1.028 .323 638 844 163 300 2,1 537 1002 174 272 2,2 758 1006 172 305 listlic 1,1 838 0.153 .700 1248 1.178 .291 147 2.121 .162 479 0.112 .741 1,2 521 665 163 218 2,1 847 1544 217 447 2,2 448 463 129 130 effects t (ms) F1,23 p t (ms) F1,23 p t (ms) F1,19 p t (ms) F1,23 p M O ET EN clause 1 574 4.177 .053 816 3.315 .082 91 0.026 .874 187 0.033 .857 2 456 616 86 177 licenser 1 567 2.442 .132 771 0.987 .331 67 3.884 .064 180 0.003 .958 2 464 661 109 183 list 1 523 0.027 .872 767 0.269 .609 103 0.589 .452 192 0.135 .717 2 508 665 74 171 cllic 1,1 621 0.021 .885 942 1.395 .250 76 0.253 .621 189 0.024 .879 1,2 528 691 106 184 2,1 513 599 59 172 2,2 399 632 112 182 listcl 1,1 561 0.495 .489 808 1.159 .293 108 0.018 .894 184 0.257 .617 484 725 98 201 2,1 588 825 75 190 2,2 429 506 74 153 listlic 1,1 585 0.112 .741 800 0.154 .698 82 0.000 .984 198 0.086 .772 1,2 460 733 123 186 2,1 549 742 53 163 2,2 468 589 95 180
Table 6: Mean total reading times for hoeven and moeten items. Effects significant at the 5% level are indicated with an asterisk and in bold. Effects: clause 1=main, 2=subordinate; licenser 1=altijd, 2=niet.
TOTFIX Region 1 Region 2 Region 3 Region 4
effects t (ms) F1,30 p t (ms) F1,20 p t (ms) F1,19 p t (ms) F1,20 p H O EV EN clause 1 3862 1.256 .271 2546 0.000 .987 440 1.052 .318 1001 3.070 .095 2 3530 2543 484 907 licenser 1 4588 23.184 .000* 3069 23.517 .000* 498 3.046 .097 1096 12.521 .002* 2 2804 2020 425 813 list 1 3651 0.021 .885 2578 0.052 .823 471 0.105 .750 899 2.451 .133 2 3741 2511 452 1010 cllic 1,1 5080 3.223 .083 3245 4.274 .052 460 0.608 .445 1231 6.236 .021* 1,2 2643 1847 419 771 2,1 4096 2893 537 960 2,2 2964 2193 431 854 listcl 1,1 4172 5.767 .023* 2809 7.005 .015* 452 0.017 .898 981 1.750 .201 3131 2347 491 817 2,1 3551 2282 427 1021 2,2 3930 2739 477 998 listlic 1,1 4300 1.729 .199 2979 1.303 .267 491 0.639 .434 1008 0.663 .425 1,2 3003 2177 452 790 2,1 4876 3159 505 1184 2,2 2605 1863 399 835 effects t (ms) F1,30 p t (ms) F1,23 p t (ms) F1,21 p t (ms) F1,23 p M O ET EN clause 1 2967 0.038 .847 2174 0.029 .866 344 0.623 .439 871 0.020 .890 2 3025 2156 373 878 licenser 1 3014 0.017 .897 2272 4.541 .044* 329 2.330 .142 947 13.395 .001* 2 2977 2058 388 801 list 1 2827 0.535 .470 2052 1.454 .240 358 0.000 .985 855 0.217 .645 2 3165 2278 359 894 cllic 1,1 2915 0.211 .649 2349 1.457 .240 328 0.897 .354 947 0.017 .896 1,2 3019 1999 359 794 2,1 3114 2196 330 948 2,2 2936 2116 417 809 listcl 1,1 2808 0.004 .949 1911 8.339 .008* 347 0.043 .838 854 0.010 .923 2847 2194 369 857 2,1 3126 2437 340 887 2,2 3203 2118 378 900 listlic 1,1 3101 3.238 .082 2161 0.001 .978 339 0.299 .590 957 2.101 .161 1,2 2553 1944 377 753 2,1 2927 2383 319 938
3.3 Discussion
In our main region of interest, region 2 with both licenser and NPI, there is one significant effect that shows up consistently in all eye tracking measures: for the hoeven items altijd has longer reading times compared with niet. Altijd cannot license the occurrence of the NPI hoeven, which seems to incur a processing penalty. However, in the same region moeten also shows an effect for licenser, although not in all measures. Again, there are longer reading times for altijd, but the difference between altijd and niet is smaller than for hoeven.
Similar effects are found in region 4, the sentence final region (although there does not seem to be an effect for hoeven in the first gaze duration). These are possibly spill over effects from region 2, which would confirm the results from that region. That the intervening region 3 does not show any effects is probably due to the fact that it is rather small. It only contains a verb (plus te in the hoeven items) and may therefore not have been fixated often enough to yield any results.
The licenser effect for hoeven in region 2 is most pronounced in the second pass and total reading times (Table 5 and Table 6). It also shows up in region 4 and even in the very first region of the sentences. For moeten it is much weaker in the total reading time and absent in the second pass reading time. This strongly suggests that unlicensed hoeven leads to rereads with readers apparently trying to find a licenser to fix an unlicensed NPI situation.
Our experiment did not yield a word order effect (the clause condition), which does not necessarily mean that it does not exist. Remember that we had to include licenser and NPI in a single region. Subtle effects on either licenser or NPI were therefore possibly missed. This is something to look into in a future experiment.
When they encounter an NPI readers possibly anticipate a licenser. They could then adopt something similar to an active filler strategy (Clifton and Frazier, 1989) for dislocated
elements. Take for example the sentence in (53) (Clifton and Frazier, 1989):
(53) Whoi did Susan want _i to sing?
The filler who, an argument of the verb sing, has to be associated with the gap (the underscore in (53)). In an active filler strategy the filler remains activated until it can be integrated into the syntactic structure at the gap position. Fiebach et al. (2001 and 2002) for example show in ERP experiments that this leads to a sustained left anterior negative (LAN) for wh-questions similar to (53), which they interpret as the filler remaining active in working memory. Fiebach et al. (2001) also detect a late ERP positivity at the gap position, suggesting the establishment of a filler-gap dependency and integration into the phrase structure. An active filler strategy for NPIs, with the NPI as filler and its licenser instead of a gap, would predict a similar sustained LAN effect and late positivity at the licenser. This could be investigated with our hoeven/moeten paradigm with a predicted LAN and late positivity for hoeven compared to moeten. Alternatively, readers could reactivate the NPI at the position of the licenser (Fodor, 1989; Nicol and Swinney, 1989). A lexical decision task could then be used to investigate whether there is a priming effect of the NPI.
According to the various theories NPIs must be licensed to yield grammatical utterances. Our study confirms this in that unlicensed NPIs incur a reading penalty. As mentioned, the non-polar equivalent we used showed a weak effect too, though. The longer reading times may therefore not be completely attributable to the presence of the NPI; the licenser/non-licenser could contribute to the effect by the sheer fact that they are different words. Another complication arises from the set-up of our experiment. The items with either altijd or niet were not matched (only the two word orders were). So comparing the two licensing conditions means comparing two different sets of sentences. Even though the licenser
effect we found looks pretty solid, this leaves some room for doubt, as we could be looking at an effect of lexical items instead of a licensing effect. A follow-up experiment incorporating a traditional latin square design should fix this.
A second problem this would solve is the by-items analysis. In the current experiment we had two lists: one contained the main clause version of a sentence and the other the equivalent subordinate clause version. The other conditions, viz. verb and licenser, were varied within a list. This limited the number of items per condition to two as the lists could not be too long. A latin square design would distribute the different conditions over the same number of lists, increasing the number of items per condition (equal to the number of items in a list). We would then be able to perform a by-items analysis and draw stronger conclusions from it.
We conclude, then, that the licensing requirement of NPIs is reflected in longer reading times and rereading of unlicensed NPIs, confirming theory. An improved follow-up experiment should be able to shed more light on this issue and also address the question of how the licensing works.
4 References
Bard, E.G., Robertson, D., Sorace, A. Magnitude Estimation of Linguistic Acceptability. Language 72(1) (1996): 32-68
Barwise, J., Cooper, R. Generalized Quantifiers and Natural Language. Linguistics and Philosophy4 (1981): 159-219
Clifton, C., Frazier, L. Comprehending Sentences with Long-Distance Dependencies. In: G. N. Carlson & M. K. Tanenhaus (Eds.) Linguistic Structure in Language Processing (1989).
Dordrecht: Kluwer Academic.
de Swart, H. Introduction to Natural Language Semantics (1998). CSLI Publications: Stanford, California
Drenhaus, H., Frisch, S., Saddy, D. Processing Negative Polarity Items: When Negation Comes Through the Backdoor. In: Kepser, S., Reis, M. (Eds.) Linguistic Evidence: Empirical, Theoretical and Computational Perspectives (2005). Berlin, New York: Mouton de Gruyter
Drenhaus, H., beim Graben, P., Saddy, D., Frisch, S. Diagnosis and Repair of Negative Polarity Constructions in the Light of Symbolic Resonance Analysis. Brain and Language 96 (2006): 255-68
Falkenberg, G. Lexical Sensitivity in Negative Polarity Verbs. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Fiebach, C.J., Schlesewsky, M., Friederici, A.D. Syntactic Working Memory and the Establishment of Filler-Gap Dependencies: Insights from ERPs and fMRI .Journal of Psycholinguistic Research 30(3) (2001): 321-38
Fiebach, C.J., Schlesewsky, M., Friederici, A.D. Separating Syntactic Memory Costs and Syntactic Integration Costs During Parsing: the Processing of German WH-Questions . Journal of Memory and Language 47 (2002): 250-72
Fodor, J.D. Empty Categories in Sentence Processing. Language and Cognitive Processes 4
(1989): 155–209
Giannakidou, A. The Landscape of Polarity Items (1997). PhD Dissertation: Groningen
Giannakidou, A. Varieties of Polarity Items and the (Non)Veridicality Hypothesis. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Hoeksema, J. Corpusonderzoek naar negatief-polaire uitdrukkingen. TABU28 (1998): 1-52
Hoeksema, J. Negative Polarity Items: Triggering, Scope, and C-Command. In: Horn, L., Kato, Y. (Eds.) Negation and Polarity: Syntactic and Semantic Perspectives (2000). Oxford, New York: Oxford University Press
Hoeksema, J., Rullmann, H. Scalarity and Polarity: A Study of Scalar Adverbs As Polarity Items. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Jackson, E.G. Negative Polarity, Definites Under Quantification and General Statements (1994). PhD Dissertation: Stanford University
Kennedy, C. On the Monotonicity of Polar Adjectives. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Klein, H. Polarity Sensitivity and Collocational Restrictions of Adverbs of Degree. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Koster, C., van der Wal, S. Acquisition of Negative Polarity Items. In: Aldridge, M. (Ed.) Child Language (1996). Clevedon: Multilingual Matters
Krifka, M. Some Remarks on Polarity items. In: Zaefferer, D. (Ed.) Semantic Universals and Universal Semantics (1991). Walter de Gruyter
Lahiri, U. Even-incorporated NPIs in Hindi Definites and Correlatives. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Linebarger, M.C. Negative Polarity and Grammatical Representation. Linguistics and Philosophy
10 (1987): 325-87
Nicol, J., Swinney, D. The Role of Structure in Coreference Assignment During Sentence Comprehension. Journal of Psycholinguistic Research18 (1989): 5–19
Postma, G. Negative Polarity and the Syntax of Taboo. In: Hoeksema, J., Rullmann, H., Sanchez-Valencia, V., van der Wouden, T. (Eds.) Perspectives on Negation and Polarity Items (2001). Amsterdam, Philadelphia: John Benjamins
Progovac, L. Negative and Positive Polarity: A Binding Approach (1994). Cambridge University Press: Cambridge, New York, Melbourne
Progovac, L. Coordination, C-Command, and 'Logophoric' N-Words. In: Horn, L., Kato, Y. (Eds.) Negation and Polarity: Syntactic and Semantic Perspectives (2000). Oxford, New York: Oxford University Press
Saddy, D., Drenhaus, H., Frisch, S. Processing Polarity Items: Contrastive Licensing Costs. Brain and Language 90 (2004): 495-502
van der Wouden, T. Negative Contexts: Collocation, Polarity and Multiple Negation (1997). London: Routledge
Veenker, T.J.G. WWStim A CGI Script for Presenting Web-based Questionnaires and Experiments (2003). http://www.let.uu.nl/~Theo.Veenker/personal/projects/wwstim/doc/en/
Appendix A Experimental Items Pilot Experiment NPI (hoeven), main clause (want), non-licenser (altijd)
1a Jan was elke zaterdag druk, want hij hoefde z’n auto altijd te wassen. 2a Eric verslijt veel tandenborstels, want hij hoeft z’n tanden altijd te poetsen. 3a Anna heeft een hekel aan tuinieren, want ze hoeft het gazon altijd te maaien. 4a Nel hield de donderdag vrij, want ze hoefde de kamer altijd te stofzuigen. NPI (hoeven), main clause (want), weak licenser (zelden)
5a Piet was blij met de baby, want hij hoefde de luiers zelden te verschonen. 6a Frans kan veel tv kijken, want hij hoeft z’n huiswerk zelden te maken. 7a Ellen doet lang met een zeem, want ze hoeft de ramen zelden te lappen. 8a Paula is ’s ochtends snel weg, want ze hoeft haar haren zelden te kammen. NPI (hoeven), main clause (want), strong licenser (niet)
9a Frank kon op de bank blijven zitten, want hij hoefde het eten niet te koken. 10a Bas is op tijd thuis, want hij hoeft de drukte niet te omzeilen.
11a Janneke kan op tijd weg, want ze hoeft de afwas niet te doen.
12a Chantal vond de agent aardig, want ze hoefde de boete niet te betalen. NPI (hoeven), subordinate clause (omdat), non-licenser (altijd)
1b Jan was elke zaterdag druk, omdat hij altijd z’n auto hoefde te wassen. 2b Eric verslijt veel tandenborstels, omdat hij altijd z’n tanden hoeft te poetsen. 3b Anna heeft een hekel aan tuinieren, omdat ze altijd het gazon hoeft te maaien. 4b Nel hield de donderdag vrij, omdat ze altijd de kamer hoefde te stofzuigen. NPI (hoeven), subordinate clause (omdat), weak licenser (zelden)
5b Piet was blij met de baby, omdat hij zelden de luiers hoefde te verschonen. 6b Frans kan veel tv kijken, omdat hij zelden z’n huiswerk hoeft te maken. 7b Ellen doet lang met een zeem, omdat ze zelden de ramen hoeft te lappen. 8b Paula is ’s ochtends snel weg, omdat ze zelden haar haren hoeft te kammen. NPI (hoeven), subordinate clause (omdat), strong licenser (niet)
9b Frank kon op de bank blijven zitten, omdat hij niet het eten hoefde te koken. 10b Bas is op tijd thuis, omdat hij niet de drukte hoeft te omzeilen.
11b Janneke kan op tijd weg, omdat ze niet de afwas hoeft te doen.
Non-NPI (moeten), main clause (want), non-licenser (altijd)
13a Gerard had last van z’n knieën, want hij moest de vloeren altijd boenen. 14a Harry koopt veel pinda’s, want hij moet de vogels altijd voeren.
15a Emmy pakt de borden uit de kast, want ze moet de tafel altijd dekken. 16a Iris had een hoop cd’s, want ze moest de muziek altijd verzorgen. Non-NPI (moeten), main clause (want), weak licenser (zelden)
17a Theo kende het rampenplan niet, want hij moest het gebouw zelden ontruimen. 18a Fred heeft geen geweer, want hij moet de duiven zelden verjagen.
19a Cindy weet niet waar de gieter is, want ze moet de planten zelden water geven. 20a Wendy kon de dweil niet vinden, want ze moest de keuken zelden schoonmaken. Non-NPI (moeten), main clause (want), strong licenser (niet)
21a Wim ging stilletjes weg, want hij moest de buren niet wakker maken. 22a Edwin pakt z’n agenda, want hij moet de afspraak niet vergeten. 23a Karin krijgt strafwerk, want ze moet de leraar niet tegenspreken. 24a Simone zette de wekker, want ze moest haar vliegtuig niet missen. Non-NPI (moeten), subordinate clause (omdat), non-licenser (altijd)
13b Gerard had last van z’n knieën, omdat hij altijd de vloeren moest boenen. 14b Harry koopt veel pinda’s, omdat hij altijd de vogels moet voeren.
15b Emmy pakt de borden uit de kast, omdat ze altijd de tafel moet dekken. 16b Iris had een hoop cd’s, omdat ze altijd de muziek moest verzorgen. Non-NPI (moeten), subordinate clause (omdat), weak licenser (zelden)
17b Theo kende het rampenplan niet, omdat hij zelden het gebouw moest ontruimen. 18b Fred heeft geen geweer, omdat hij zelden de duiven moet verjagen.
19b Cindy weet niet waar de gieter is, omdat ze zelden de planten moet water geven. 20b Wendy kon de dweil niet vinden, omdat ze zelden de keuken moest schoonmaken. Non-NPI (moeten), subordinate clause (omdat), strong licenser (niet)
21b Wim ging stilletjes weg, omdat hij niet de buren moest wakker maken. 22b Edwin pakt z’n agenda, omdat hij niet de afspraak moet vergeten. 23b Karin krijgt strafwerk, omdat ze niet de leraar moet tegenspreken. 24b Simone zette de wekker, omdat ze niet haar vliegtuig moest missen.