Map Reduce Algorithm based Fast Detection of
Connected Components in Large Scale Graph Processing
Sangeeta
[email protected]
ABSTRACT
Detection of Connected Components of a diagram is a basic issue in graph hypothesis which emerges in various applications including information mining and system examination. By expanding prominence of interpersonal organizations and data frameworks, size of genuine graphs has expanded to billions of hubs and edges. Along these lines, finding associated parts of substantial scale graphs swung to be a computationally difficult assignment. Along these lines, as of late, there has been a few works tending to this issue utilizing the notable MapReduce disseminated substantial scale information handling system. Be that as it may, they don't have adequate execution and still there is awesome potential for improvements. In this paper, we present another approach for Detection of Connected Components of huge scale graphs utilizing Map Reduce structure. In view of the aftereffects of the examinations on genuine datasets, we demonstrate that, by utilizing the new calculation, huge execution enhancements have been picked up. We likewise clarify that the primary thought of our calculation depends on a general hypothesis for compelling usage of computational assets gave by hubs in a Map Reduce group to diminish correspondence and IO stack.
Keywords: Large Scale Graph Processing; Connected Components; Map Reduce.
I INTRODUCTION
Extensive scale diagrams are prominent in present day data frameworks, for example, informal communities, logical systems, online business frameworks, web graphs, and so on which contain diagrams of billion scales. Such diagrams ought to be examined utilizing graph processing information mining strategies keeping in mind the end goal to remove profitable data, for example, group structure of an interpersonal organization, incline expectation in a scholarly research field, and positioning pages to name a few. One of the fundamental calculations utilized as a part of graph mining is Detection of Connected Components of a diagram which likewise has some different structures, for example, S-T Connectivity. There have been numerous consecutive calculations to discover associated segments of diagrams, yet Detection of Connected Components of genuine graphs has turned into a testing errand as of late because of their substantial scale estimate. One way to deal with handle this test is to utilize parallel and appropriated figuring.
PEGASUS, a prevalent MapReduce calculation for finding associated parts of substantial scale diagrams. The new calculation decreases measure of middle MapReduce information and the quantity of emphasess that PEGASUS takes to finish. As indicated by tests, the new calculation fundamentally beats the cutting edge calculations.
II
MAPREDUCE
FRAMEWORK
MapReduce has risen as another worldview in appropriated expansive scale information handling lately [2]. Versatility, stack adjusting, and adaptation to internal failure are its most vital qualities. It has been utilized to take care of computationally difficult issues in numerous fields, for instance, extensive scale diagram handling issues, for example, PageRank and most extreme faction issue [4], [9]. MapReduce system builds scale by utilizing vast number of inexactly synchronized machines each handling a small amount of information in parallel.
MapReduce comprises of two capacities, Map and Reduce. The Map work gets some key esteem matches as info and procedures them to produces new key esteem combines as middle of the road yield. At that point the Reduce work forms the middle of the road key esteem sets to produces yield key esteem sets. Amongst Map and Reduce stages the rearrange stage sends all qualities related with a key to a same reducer. The rearrange stage is the main synchronization required amongst Map and Reduce stages and all undertakings amid each stage work freely.
The MapReduce structure expect that info information is part finished a disseminated group document framework and after that executes the Map work on each split. Measure of middle information produced amongst delineate decrease stages is a bottleneck for execution and versatility. Basically, on the grounds that it ought to be arranged utilizing an outside arranging calculation and afterward sent to the correct reducer through the system. As the measure of halfway information expands, I/O and correspondence stack likewise increment. In this manner, decreasing measure of middle information would bring about huge execution changes. What's more, Detection of Connected Components utilizing MapReduce is an iterative undertaking and diminishing number of emphasess additionally would bring about execution change. In the following area we exhibit our approach which diminishes measure of moderate information and number of cycles [2].
IIIRELATEDWORKS
There have been a few works which created MapReduce calculations to discover associated segments of vast scale diagrams [3]. Among them, two calculations are best and prominent and we will portray them in detail. These calculations depend on some sort of name spread. They allocate a numerical segment ID to every hub and neighbor hubs of the diagram trade their part IDs until the point when every hub gets its correct segment ID. Our new calculation likewise depends on this name proliferation approach and really our work will be a change on computational parts of this approach. Before depicting our calculation, first we present two specified calculations.
A. Related Works
actualize their calculation, however their execution strategy isn't our worry at this work. PEGASUS at first sets segment ID of every hub to be the hub's ID. At that point in delineate of the accompanying emphases, every hub sends its segment ID to its neighbors. In the lessen stage every hub sets its part ID to littlest segment ID among those IDs it got and its ID set in the past emphasis. The calculation repeats until part ID of none of the hubs changes.
In [6] two new calculations are presented which go for diminishing the quantity of rounds in Detection of Connected Components utilizing MapReduce. In light of the tests displayed in their paper, one of their calculations, named as Hash-to-Min, has the best execution with respect to run time. In the introduction step, the calculation expects that every hub and its neighbors constitute an associated segment. In delineate of the accompanying emphases, every hub sends IDs of all individuals from the part connected with it to the part with littlest ID and sends the littlest hub ID to different hubs. At that point in the decrease stage, every hub gets the individuals related with it and stores it. The calculation ends when all hubs are related with the hub with littlest ID in the part which they have a place with. Along these lines, at every emphasis, all hubs of a part ought to be sent to the reducer which forms the individual from the segment with littlest ID. This would cause unequal computational and correspondence load to be coordinated to a few reducers. On account of presence of gigantic parts, which is well known in true diagrams [6], there would be huge absence of execution and versatility. Be that as it may, they additionally have formulated a few answers for smooth this issue.
Figure 1: The PEGASUS algorithm for fiinding connected components of a graph using MapReduce
Seidl et al [7] likewise have presented a calculation called CC-MR which is basically in light of an indistinguishable approach from of Hash-to-Min. They have likewise formulated a rich answer for counter the inborn lopsided load circulation related with the approach. Besides, they have discharged an open-source rendition of their execution. In any case, this approach still does not have fulfilling execution if there should arise an occurrence of expansive scale graphs.
B. Inspirations
over CC-MR and Hash-to-Min.First we indicate how PEGASUS works on a graph. For instance of the calculation's method, we depict its task over the diagram exhibited in fig 2.
Figure 2: graph with two connected components
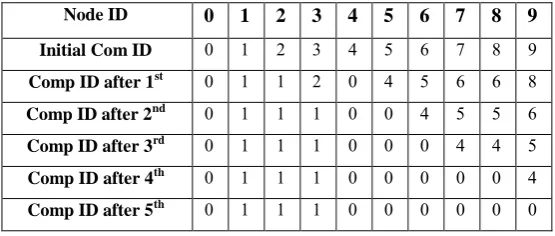
Table 1: Running PEGASUS on the Graph in Fig. 2
Node ID 0 1 2 3 4 5 6 7 8 9
Initial Com ID 0 1 2 3 4 5 6 7 8 9 Comp ID after 1st 0 1 1 2 0 4 5 6 6 8 Comp ID after 2nd 0 1 1 1 0 0 4 5 5 6 Comp ID after 3rd 0 1 1 1 0 0 0 4 4 5 Comp ID after 4th 0 1 1 1 0 0 0 0 0 4 Comp ID after 5th 0 1 1 1 0 0 0 0 0 0
Assume that at every cycle there are two mapers and one reducer and hubs 0 to 4 will be handled by first maper and alternate hubs by the second maper. As exhibited in Table 1, PEGASUS at first sets the part ID of every hub to be same as its hub ID [9]. At that point in delineate of the primary emphasis hub 6, for instance, sends its segment ID to all its neighbor hubs, which is 3, 5, and 8. In the lessen stage, hub 6 additionally gets part ID of its neighbors and sets its segment ID to be 5 which is the littlest ID among those it got and its present segment ID. Segment IDs of different hubs after the main emphasis are exhibited in Table 1.
IV
DISCUSSION
AND
ANALYSIS
A. Memory Usage
As depicted, each maper of MemoryCC loads the sub graph related with it into memory. At first this might be appeared to be hazardous because of its high memory use, however even in groups made up of product equipment, every hub as a rule has up to numerous gigabytes of memory per handling center. What's more, true informational indexes for the most part are of gigabytes in size and entire of them could be stacked even into memory related with one maper. For instance, the biggest informational index we have utilized is com-Orkut which is 1.7 gigabytes. Considering that two gigabytes of memory is accessible for each maper in our bunch, even entire of com-Orkut informational index could be stack into memory of one maper. Also, since we would separate informational indexes into sub graphs, unmistakably size of sub diagrams would be considerably less than size of the informational collection itself. For instance, in our bunch, we can separate every datum set among 52 mapers each with to up to two gigabytes of memory which implies we can process informational indexes as expansive as 100 gigabytes. Moreover, as size of genuine informational collections develops, memory innovation is likewise advances to help bigger measures of memory per preparing center. So it appears to be neither today nor would later on accessible memory be a hazardous issue for execution of MemoryCC [10].
B.Discussion
Our primary approach in building up another MapReduce calculation was decreasing measure of moderate information and number of emphasess. For instance, if there should arise an occurrence of the graph appeared in Fig. 1, MemoryCC finished into equal parts the cycles PEGASUS took to end. What's more by stacking the sub diagrams into memory of mapers the hubs inside mapers do no need to communicate through the diminish stage and they straightforwardly share their part ID with each other at the guide stage.
Map
Hashmap subgraph<key,value>
Input <Key, Value> : <(node n, Comp IDn), adjacency list of n>
subgraph.put(node n, <Comp IDn , adjacency list of n>)
while(any component ID updates) do foreach node n in subgraph do foreach node i which is neighbor of ndo ifi is in subgraph&
Comp IDi is smaller than Com IDn do
replaceComp IDiwith Com IDn
foreach node i in subgraph do emit<i, Com IDi>
emit<i, adjacency list of i>
foreach node i not in subgraph
& has at least a neighbor in subgraph do
emit<i, smallest Com ID of i’s neighbors in subgraph>
Reduce
Input<Key, Value> = <node n, received IDs and adjacency list of n>
component IDn = smallest id received
emit< (n, component IDn) , adjacency list of n>
VI
CONCLUSION
AND
FUTURE
WORK
DIRECTIONS
In this paper, another calculation with accelerate expansive scale associated segment discovery utilizing MapReduce system has been discussed. This approach depended on dividing a graph into sub diagrams and afterward iteratively Detection of Connected Components of each sub graph independently in outline and combining them in decrease stage. The new calculation is named as MemoryCC. MemoryCC depends on the possibility of PEGASUS calculation to finding associated parts and enhances it through lessening measure of middle of the road information and number of cycles it take to finish. MemoryCC do this by finding associated parts of each sub diagram in a maper and as opposed to PEGASUS, does not trade information among inner hubs of a maper through the decrease stage. In the mean while, this approach lessens the quantity of cycles. In view of test comes about, our calculation beats the cutting edge calculations by working up to ten times quicker than them.
Particularly, time and space multifaceted nature of MemoryCC could be precisely dissected and contrasted and that of different calculations. Likewise MemoryCC appears to be considerably more adaptable than different calculations however it is important to demonstrate this reality in view of hypothesis and greater examination. Besides, it appears that dividing input graphs among mapers might be valuable if connected to numerous other diagram preparing calculations. In this manner, as the future work we focus on probability of enhancing other MapReduce based diagram handling calculations utilizing the approach utilized here in outlining MemoryCC.
REFERENCES
[1].B. Wu, et al., "A distributed algorithm to enumerate all maximal cliques in mapreduce," in Frontier of Computer Science
and Technology, 2009. FCST'09. Fourth International Conference on, 2009, pp. 45-51.
[2].T. Seidl, et al., "CC-MR–Finding Connected Components in Huge Graphs with MapReduce," in Machine Learning and
Knowledge Discovery in Databases, ed: Springer, 2012, pp. 458-473.
[3].U. Kang, et al., "Pegasus: A peta-scale graph mining system implementation and observations," in Data Mining, 2009.
ICDM'09. Ninth IEEE International Conference on, 2009, pp. 229-238.
[4].K. Kambatla, et al., "Asynchronous algorithms in MapReduce," in Cluster Computing (CLUSTER), 2010 IEEE
International Conference on, 2010, pp. 245-254.
[5].U. Kang, et al., "Pegasus: mining peta-scale graphs," Knowledge and Information Systems, vol. 27, pp. 303-325, 2011.
[6].B. Wu and Y. Du, "Cloud-based connected component algorithm," in Artificial Intelligence and Computational
Intelligence (AICI), 2010 International Conference on, 2010, pp. 122-126.
[7].J. Lin and M. Schatz, "Design patterns for efficient graph algorithms in MapReduce," in Proceedings of the Eighth
Workshop on Mining and Learning with Graphs, 2010, pp. 78-85.
[8].J. Cohen, "Graph twiddling in a MapReduce world," Computing in Science & Engineering, vol. 11, pp. 29-41, 2009.
[9].J. Dean and S. Ghemawat, "MapReduce: simplified data processing on large clusters," Communications of the ACM, vol.
51, pp. 107-113, 2008.
[10].V. Rastogi, et al., "Finding connected components on map-reduce in logarithmic rounds," arXiv preprint