Data Mining Technique in Unstructured
Data of Big Data
Sima Sangle
1, Prof. Chakote Gajanan
2 1M.E Student, Department of Computer Engineering,
MSS’s college of Engineering and Technology, Jalna, Maharashtra,( India)
2
Assistant Professor, Department of Computer Engineering, MSS’s college of Engineering and Technology, Jalna, Maharashtra, ( India)
ABSTRACT
Big data is collection of data which is vast range and composite data.. Data obtain created from each and every way, from various fields. These big data has structured semi-structured and unstructured kind of data. In today period data is been gathered on great scale. Social media sites, digital images and videos and countless other. Entire world is going so as to near the digitalization. All this kinds of data is well known as big data. Data mining is a process for uncovering a design which is convenient from huge scale data sets. We gather the healthcare information which comprise all the particulars of the sufferer, their symptoms, ill health etc. Formally we gather the information then there will be pre-managing on that information as we require only strain information for our study. Convenient and significant data can be withdraw from this big information with the assist of data mining by managing on that data. The data will be saved in Hadoop. User can access the data by symptoms, disease etc.
Keywords
:
Big data, Data Mining, Privacy, HACE theorem, Hadoop efficient algorithm.
I.INTRODUCTION
Our impartial points for this efforts is to Data mining ready on large quantity of big data methods which graphic of information and which gather together algorithms are genuine for categories and recognize important medical associated data in small representation. In this investigation, our focal point is on relation between the illness and indicated information. That is present linking illness and record. Our attentiveness are in way to a individualize medicine. In this sufferer has a medical supervision individualize related to it’s his essential. We recognize the existence that are implement effective of detecting the related and reliable particulars in the medical province viewpoint as primary construction blocks supports for a health related information arrangement that is up-to date with the previous observation and finding in the medical sectors. It’s not sufficient to realize and read the particulars only mandatory for treatment is assists for illness health related should dispense all the particulars and new origination uncovered related assured ministration and record to identify it may as well have beyond question side effect to specified category of patient . We have to used recently developed technologies to proceeding such type of information and uncover the point of reference by using the data mining. The quality implementation attendant at the start as educative and commencing sources of company seeing to lead the way in big data potentiality and occasion that succeed in the contrasting challenges of administration. Even the component make use of big data and put into practice compact or considerable in the government organization this will as well best part various challenges come beneath empirical in most important stream of carry out and functioning.
II. RELATED WORK
the algorithm in single-pass, query based and repeated frame work of Map Reducer, give out the data between number of nodes in parallel processing algorithm that the Map Reducer approach for large data mining by examining standard data mining problem on mid-size clusters. Polarimetries and sun[4].In this they suggest a mutual dispense aggregation (DisCo) frame work for pre-processing of virtually and collaborative method. The presentation in Hadoop it is and open source Map Reducer project exhibit that DisCo have ideal which is correct and can examine and process large data.
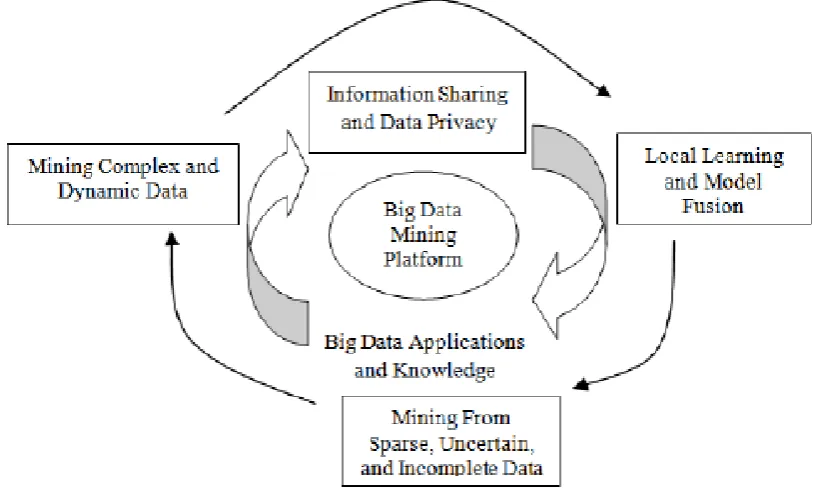
III. PROPOSED SYSTEM
For an clever learning database system (Wu 2000) to hold Big Data, the needed key is to scale up to the uncommonly large volume of data and come up with conduct towards for the attribute featured by for declare HACE theorem. Figure exhibit a conceptual view of the Big Data processing framework, which contains three tiers from inner side out with reflection on data acquire and computing (Tier I), data security and domain information (Tier II), and Big Data mining algorithms (Tier III). The provocation at Tier I focus on data retrieving and real computing methods. Because Big Data are many times stored at various positions and data volume say continuing developed, an effectual computing platform will have to take dispense huge scale information storage into reflection for computing. For example, while typical information mining algorithms have need of all data to be filled into the main memory, this is becoming a easy to understand technical barrier for Big Data because moving information across various positions is expensive (e.g., subject to intensive network communication and other IO costs), even if we do have a super huge main memory to hold on to all data for computing.
Figure 1: Big Data processing framework
(Tier I) and mining algorithms (Tier III). For example, depending on various province applications, the data security and information sharing procedure between information producers and information consumers can be significantly uncommon.
IV. METHODOLOGY
HACE Theorem Big Data begin with huge-volume, diverse, autonomous origin with dispense and decentralized control, and search for to travel over complex and develop relationships among information. These attribute make it an very great challenge for locating useful data from the Big Data. In a nave sense, we can visualize that a number of blind men are stressful to size up a informal Camel, which will be the Big Data in this conditions. The aim of each blind man is to make a diagram a picture (or conclusion) of the Camel as claimed by to the part of data he gathers du ring the processing. Because each man view is bounded to his local area, it is not astonish that the blind men will each finish independently that the camel sense like a rope, a hose, or a wall, be dependent on the area each of them is limited to. To construct the problem even extra complicated, let us suppose that the camel is growing quickly and its pose varying constantly, and each blind man may have his own (possible undependable and inaccurate) data sources that tell him about biased information about the camel (e.g., one blind man may interchange his feeling about the camel with additional blind man, where the exchanged information is inherently biased). traverse the Big Data in this situation is equivalent to whole amount heterogeneous data from various sources (blind men) to help sketch a best possible image to reveal the actual gesture of the camel in a real time fashion. Indeed, this function is not as simple as asking each blind man to narrate his sensing about the camel and then getting an resource person to draw one single image with a combined view, regarding that each independent may speak a various language (heterogeneous and diverse data sources) and he may even have security concerns about the messages they planned in the data exchange processing. The term Big Data literally deal with about data volumes, HACE theorem propose that the key attribute of the Big Data are
1. Large with heterogeneous and different data sources:- One of the basic attribute of the Big Data is the large volume of data represented by heterogeneous and various dimensionalities. This large volume of data comes from different social sites like Twitter, Myspace, Orkut and LinkedIn etc.
2. Decentralized control:- Autarchic information sources with dispense and decentralized dominance are a important attribute of Big Data applications. Being autonomous, each information resource is able to generate and gather data without involving (or relying on) some centralized control. This is alike to the World Wide Web (WWW) setting where each one web server supply a certain amount of data and each server is able to fully task without necessarily depending on other servers.
3. Compound information and knowledge associations:- Multiple structure, multiple source information is complex information. Examples of complex information types are bills of materials, word processing documents, maps, time-series, pictures and video. Such incorporate attribute suggest that Big Data entail a big mind to consolidate information for maximum values.
5. The suggested a HACE theorem to model Big Data characteristics. The attribute of HACE make it an extreme provocation for discovering useful data from the Big Data.
6. The HACE theorem implies that the key attribute of the Big Data are-1) Large with dissimilar and various data resources, 2) Autonomous with dispense and decentralized control, and 3) compound and evolving in information and data associations.
7. To hold up Big Data mining, high-presentation computing platforms are needed, which urge systematic patterns to unleash the full ability of the Big Data.
Proposed system uses two algorithm namely Algorithm: K-mean
Algorithmic stages for k-meansclustering
V. PSEUDO CODE
1. Let X = x1, x2, x3,.., xn be the group of information points and V = v1,v2,.,vc be the group of centers.Unsystematically choose c cluster centers.
2. Compute the interval between each information point and cluster centers. Allocate the information point to the cluster center whose interval from the cluster center is min of all the cluster centers.
3. Recomputed the new cluster center using: where, ci appear for the number of information points in i’th cluster. J(V)= åc i=1 åci
j=1(xi ci)2
4. Recomputed the interval between each information point and new acquire cluster centers. 5. If no information point was reassigned then finish, otherwise iterate from step.
6. End Algorithm: NLP
Algorithmic stages for Natural Language Processing 1) P0 initiate commencing population of m individuals 2) Set generational counter k = 1
3) Assess P0 for health
4) Begin repeatation until end (no. of generations or end criteria reached) a) Choose parents Ppar = Pk1
b) Acquire offspring Poffsp. by recombining parents c) Change some offspring
d) Choose population to remaim unto upcoming generation Pk =Pk1 Poffsp.
e) Repeat generation counter k = k + 1 5) Stop.
VI.
SIMULATION RESULTS
Input are the no. of information in the database. Distinctness is premeditated with esteem to complexity as describe in figure 2,
Fig.1 Complexity Computation
Distinctness between proposed algorithm and base algorithm i.e., supplier aware algorithm:
On above 25 information of input (refer 2), Graph 2 shows computation time in the middle of slicing and encryption algorithm. This presents the performance of the system i.e., CPU usage in millisecond of the system on which it runs.
Fig.2 Data Slicing Performance
VII. CONCLUSION AND FUTURE WORK
This Big data with data mining research is more successful than many methods invented. This method has better accuracy. It gives security by providing Login Id and password to the user. To provide more secur ity. Reduce manual efforts.
There are many future main challenges in Big Data management and analytics, that appear from the nature of data: huge, diverse, and evolving. These are some of the provocation that researchers and practitioners will have to give out during the next years:
Analytics Architecture:- It is not understandable yet how an optimal design of an analytics structure should
be to deal with historic information and with real time information at the same time. An engrossing proposal is the Lambda structure of Nathan Marz. The Lambda structure solves the problem of calculate arbitrary functions on arbitrary information in real time by decomposing the problem into the three layers: the batch layer, the serving layer, and the speed layer. It merge in the identical system Hadoop for the batch layer, and Storm for the speed layer. The possessions of the system are: robust and fault tolerant, scalable, general, extensible, permit ad hoc enquiry, minimal maintenance, and debug gable.
Statistical significance:- It is significant to achieve important statistical results, and not be fooled by randomness. As Efron describe in his book about Huge Scale Inference it is easy to go wrong with large information sets and thousands of questions to answer at once.
Distributed mining:- Numerous data mining methods are not insignificant to paralyze. To have dispense versions of some techniques, a lot of research is needed with practical and theoretical analysis to give new techniques.
REFERENCES
[1] Bo Liu, Member, IEEE, Keman Huang Jianqiang Li, and MengChu Zhou, ”An Incremental and Distributed Inference Method for Large- Scale Ontologies Based on MapReduce ParadigmKnowledge and Information Systems”, vol. 45, no. 3, pp. 603-630, Jan.2015.
[2] Novel Metaknowledge-based Processing for multimedia Big Data clustering challenges, 2015 IEEE International Conference on
[3] Multimedia Big Data.
[4] Xindong Wu, Fellow, IEEE, Xingquan Zhu ”Real-Time Big Data Analytical Architecturefor Remote Sensing Application- Knowledge
[5] and Information Systems”, vol. 33, no. 3, pp 707-734, Dec. 2015.
[6] Yanfeng Zhang, Shimin Chen, Qiang Wang, and Ge Yu ”MapReduce:Incremental MapReduce for Mining Evolving Big Data ACM
[7] Crossroads”, vol. 27, no. 2, pp. July 2015.
[8] S. Banerjee and N. Agarwal ”Analyzing Collective Behavior from Blogs Using Swarm Intelligence,Knowledge and Information
[9] Systems”, vol. 33.
[11] Xindong Wu, Fellow, IEEE, Xingquan Zhu ”A Data Mining with Big Data”, IEEE Transactions On Knowledge And Data Engineering,
[12] Vol. 26, No. 1, January 2014.
[13] Muhammad MazharUllahRathore, Anand Paul ”A Data Mining with Big Data” IEEE Transactions On Knowledge And Data Engineering,
[14] Vol. 26, No. 1, January 2014.