3456
Redesigning Database Management Course
Syllabus: A Predictive Approach Using Data
Mining Technique
Devine Grace D. Funcion
Abstract : Data mining for over a decade has significantly helped the education sector in mining data that is helpful for both teachers and students in the teaching and learning process. Promising results show that data mining is practical at unraveling useful information from the known large databases. It is in this premise that the data mining technique is used in the field to distinguish the essential issues in the DBMS that support the enhancement of student competency in the database. Moreover, the study is anchored on the KDD process to analyze the result generated through the use of the survey questionnaire. There were only 42 out of 45 fourth-year students who participated in the conduct of the study. As produced by the J48 algorithm result that data storage, data integration, and data modeling are the essential topics in the DBMS, more teaching hours is required. Hence, it has a significant effect that will make the student highly competent, competent, or uncertain in the database. Nevertheless, it that advanced items like data mining, data warehouse, and data analytics to analyses should in redesigning the DBMS course syllabus be included and recommended.
Index Terms: Curriculum, Redesign, Information Technology, Data Mining, J48 Algorithm, Database Management, Competency
————————————————————
1 INTRODUCTION
Masses in all walks of life depend on much of their work with technology. As time evolves, technology innovation becomes evident in the way people communicate, search for information, and create a business (online and offline). Constellations of computer data are marching around the cyberspace, and quintillion bytes of data are processed every day that the demand for a better and greater database is high. One of the enormous milestones of the database provides a centralized storage system that end-user can update, retrieve, and write information anywhere while maintaining data integrity. The use Database Management System (DBMS) is software in creating the database. In the early days were database is built on the flat - file model, which saved the records in text format was retrieving and updating of data undergoes a rigorous process of sequential search. Hence, it provides the user with a systematic approach to create, read, delete, update the database (Rouse, n.d.). The DBMS is most significant in giving unified access of data to multiple users, multiple locations in a manipulated way. The database is composed of three elements data, schema, and database engine; these elements support data concurrency, data integrity, and security. These uphold that security and data integrity are the primary concern of database administrators. The administrator should develop a concrete database scheme to protect the information from hackers. Once the hacker gets hold of this information, data integrity will be compromised because the hackers can easily change the data if it is not adequately secured. Moreover, information technology (IT) students of the Leyte Normal University are being taught to become competent in DBMS as part of their curriculum in IT. The main objective of offering DBMS as part of the main course deals with features of error correction, debugging, and Structured Query Language (SQL).
The student will acquire proficiency in SQL coding through the exercise of extensive hands-on workshop exercises utilizing SQL in an interactive environment. Constitute of the learning outcome of the student is to demonstrate knowledge in the database structure, conceptualize database design in actual-world set-up, and discuss structured query language (SQL). Hence, for the past decade, a stunning result has been put down on the effectiveness of Data Mining (DM) in making accurate prediction and interpretation of large databases. As a definition, DM is the process of finding unknown patterns and trends in databases and generate predictive models to create new information (Koh, 2011). In education, data mining is becoming more popular in predicting student performance vis-à-vis to faculty performance. Also, DM is used to predict student behavior, study habits, and also improved the teaching and learning process of the student (Algarni, 2016). Hence, the study of Ali (2013) mentioned successful uses of DM as predicting student profile, student complaint, library facility, student dropouts, student course selection, and more. Another, of Hsia (2008) and Baker (2010) which mining was utilized to predict the pedagogical support provided by the learning software in scaffolding student learning. Also, the use of data mining in the curriculum development completion rates and profession of enrollees by using data mining algorithms such as decision tree, link analysis, and decision forest. Hence DM can also be used in the process of redesigning the course syllabus to identify the required topic that needs more teaching hours effectively. However, in the current procedure of designing the course outline, teachers usually download the curriculum from different prestigious universities in local and international. In the process, evaluation of the downloaded program is conducted for the teacher to have a guide in designing the curriculum that is suitable for the IT students. However, no model is used to determine the arrangement of the topic according to its importance. In this study, data mining is used to predict issues in DBMS that are significant in redesigning the content in the course syllabus that is useful to enhance student learning in the DBMS course.
2. MATERIALS AND METHOD SECTION
__________________________________3457
The study is anchored on knowledge discovery in database (KDD) using a data mining technique that is used to discover hidden information from large databases. The procedure of obtaining and interpreting patterns from data involves the repeated application of the following steps presented in figure 1 (Transformation, 2019).
Figure 1: Steps in Data Mining
Define the problem – the main objective of the study is to used data mining to identify the topic in DBMS that requires more teaching hour, that will help improve the competency level of the IT student in DBMS.
Identify the required data – using the google form the fourth year IT students answer the survey question. There were only forty-two (42) IT students out of forty-five (45) IT students enrolled in DBMS who participated in answering the questionnaire. The other three (3) students were absent during the gathering of data. Table 1 below shows the sample data generated in the google form.
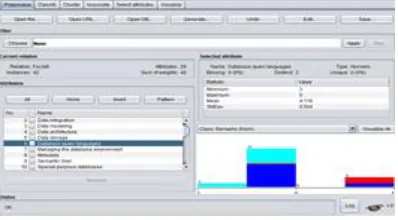
Prepare and Pre-process – the Competency.csv file as loaded into the Weka Application. The first generation of data visualization for each instance.
Figure 2. Pre-process
Model the data – in the mining of the data, the J48 algorithm as deployed to unravel the answer to the problem about the DBMS topic that is useful to enhanced student competency in DBMS. J48 C4.5 is a classification decision tree model. It builds a binary tree model for the classification process. Once the algorithm established tree, J48 ignores the missing values, i.e., the amount of that item can be predicted based on attribute values for the other records is known. The basic idea is to separate the data into range based on the attribute values for that item in the training sample are found. J48 allows classification via either decision trees or rules generated (Patil, 2013).
Train and Test – the model has been tested using the different test options for data mining. The result using Training Set has generated (97.619%) accuracy rate while using the option Supplied Test Set has an accuracy rate of (97.0588%). Also, Cross-Validation 10-folds have an accuracy rate (88.2353%), and lastly, Percentage Split has an accuracy rate of (85.7123%). In this case, the researchers used the result generated in the Training Set because of its high accuracy rate.
Figure 3: Test Set Options for data mining
3.
RESULT AND DISCUSSION
Table 2 represents the rank of DBMS topics. To generate the result, attribute selection ranker, and class attribute evaluation was utilized together with the J48 algorithm C Table 1: Sample Data
Data integration
Data modeling
Data architecture
Data storage
Database query languages Highly
Competent
Highly Competent
Highly Competent
Highly Competent
Highly Competent Uncertain Competent Competent Competent Competent
Competent Competent Uncertain Uncertain Competent
Competent Competent Competent Competent Competent
Competent Competent Competent Competent Competent
Competent Competent Competent Competent Competent
Uncertain Competent Uncertain Uncertain Competent
3458
O.25 – M2 to identify the ranking of the attribute according to its percentage. Rank 1, in the list is (Data Architecture, Data Modeling, and Data Integration with (38.10%)) respectively, rank 2 (Semantics Model with (33.33%)), Rank 3 (Data Storage, Network Model, and Concepts and Fundamentals of Data Management with (30.95%)), Rank 4 (Managing the Database Environment with (28.57%)), Rank 5 (Dimensional Models, Logical Database, and Flat Files with (26.67%)), rank 6 (Data Masking and Use of graphical vs. textual representations of database structures with (26.19%)), rank 7 (Object-relational Databases and Relational Model (19.05%)), rank 8 (Special –purpose Databases with (18.57%)), rank 9 (Archiving with (16.19%)), rank 10 (Object Databases and Semantic Web with (9.52%)), position 11 (Database Query Languages and Metadata with (4.76%)) and lastly rank 12 (Data Encryption with (3.33%)). Having identified the rank of the twenty-three attributes, allocation of teaching hours per topic/attributes are vital in streamlining the DBMS course syllabus that will enhance the student competency. Nevertheless, identifying the issues in DBMS based on percentage and ranking does not repay that the first topic shall be granted more time compared to the other. Also, there is a rank that topics/attribute has the same number percent. Hence to distinguish the critical topic in the DBMS that enhances the student competency in the database, the J48 algorithm was carried out. As shown in Table 3, the J48 algorithm was able to classify instances with an accuracy rate (97.619%). The kappa statistics with a reliability test of (95.99%) supports the result in table 3. Landis and Koch proposed the following as standards for strength of agreement for the kappa coefficient: ≤0=poor, .01–.20=slight, .21–.40=fair, .41–.60=moderate, .61–.80=substantial, and .81–1=almost perfect (McHugh, 2012). It means that the two instances (correctly classified and incorrectly classified) attributes agree on the result of the level of student competency in DBMS (Wongpakaran, 2013). Moreover, figure 4 shows the decision tree model for DBMS topics. It expresses that data storage, data interpretation, and data modeling are the significant areas in the DBMS that can aid the students in becoming competent in Database Management System as generated by the J48 algorithm. It indicates that the higher node in the tree represents the most critical topic in DBMS. Data storage, as located on top of the tree, causes the split that will define the student as highly competent or not competent. According to Techopedia (2019), data storage is a term used for archiving data in electromagnetic or other forms such as a computer or device. Different types of data storage play different functions in a technology environment. In addition to hard data storage, new options such as cloud computing as remote storage can revolutionize the ways that users contact data. A cloud computing is the ability to access a myriad of computing resources via the Internet. It is composed of hardware, storage, and network interfaces that provide the means through which users can access from a cloud server that is independent of locations (Yang, 2012; Arora, 2013). IT students should possess a well-versed knowledge of information storage on how to preserve the data safely in the virtual environment to avoid the onward mishap of data loss, and data integrity is not compromised. Additionally, data integration means the procedure of mixing engineering and business processes employed to incorporate data
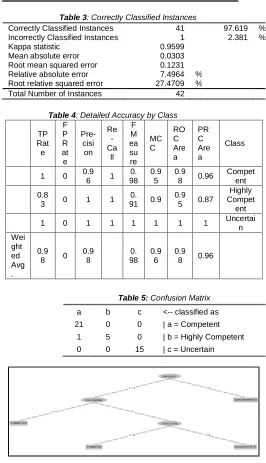
sources and extract meaningful and valuable data. A complete data integration solution delivers a trusted report from several sources to support a line of the work-ready data pipeline for Data Ops (IBM, 2019). Moreover, according to Calvanese (2009) data integration supports three elements (global schema, the sources, and the mapping) were the primary goal is to provide the user with an illustration of the databases residing at any sources Thus, the global schema implicitly provides a reconciled view of all data, which can be queried by the user. The use of other business intelligence models such as data mining, data analytics, and data warehouse should be integrated into the curriculum as it is helpful in the query process of the data. Also, data modeling, according to E. Johnson (2008), is a technical process that involves understanding and mapping business information in logical objects that can result in eventually in database storage. IT students should develop a database plan through the use of three primary data type model, such as a conceptual data model, a logical data model, and a physical data model. It is vital to do data modeling and create an entity-relationship diagram (ERD) to ensure well defined relational databases. Hence, as presented in the model, if the student shows less competency in data storage with (<=40), but reveals higher skill in data integration with (>3.0), and shows less ability in data modeling with (<3.0) student will demonstrate Uncertain competency. Smithson (2008) and Bar-Anan (2009) define uncertainty as referring to the absence of clarity or lack of information as to how, when, what, and why the situation occurs. It establishes that students become uncertain of the topics in (data storage, data integration, and data modeling), perhaps because of the ambiguity and lucidness of the problem, which may affect the competency of the student. Hence, if the student possesses less skill in data storage with (<=4.0), but possess higher expertise in data integration and data modeling with (> 3.0) the student will demonstrate Competent result. According to the definition of Cambridge Dictionary (2019), competent means the ability to have the skills or knowledge to do something that primary meets the standard. It represents that students demonstrate basic knowledge or interpretation of the topic in data storage, data integration, and data modeling, in which the student can execute a task that involves the three issues. Moreover, the result is supported by the decision tree model the effect found in table 4 complete accuracy by class and table 5 confusion matrix, and it illustrates that the Precision level of (97.7%) accuracy rate of the model, as it correctly classified the students depicted in Confusion matrix the level of competency. Nonetheless, as seen in the ROC (receiving operating characteristics), high accuracy for each class Competent (97.6%), highly competent (95.1%), and Uncertain (100%).
4.
CONCLUSION AND RECOMMENDATION
3459
support and enhance the competency level of the student in DBMS. In this case, Data Storage, Data Integration, and Data Model are the crucial topics in DBMS that should be allocated more teaching hours in the course syllabus of DBMS. However, advanced items like data mining, data warehouse, and data analytics to analyses should in redesigning the DBMS course syllabus be included and recommended as these topics are beneficial in analyzing large databases and reveal the hidden information. Additionally, the other researcher utilized the data mining technique as a useful tool in making a predictive model from large databases.
Table 2: Attribute Ranking
Evaluator: weka.attributeSelection.ClassifierAttributeEval-execution-slot 1 –B
weka.classifier.trees.J48 -F 5 -T 0.01 -R 1 -E DEFAULT -- -C 0.25 -M 2
Search: weka.attributeSelection.Ranker T -1.7976931348623157E308 -N -1
Relation:
ForJ48-weka.filters.unsupervised.attribute.Remove-R20-25 Instances: 42
Attributes: 23
=== Attribute Selection on all input data ===
Search Method: Attribute ranking
Attribute Evaluator (supervised, Class (nominal): 23 Remarks): Classifier feature evaluator
Using Wrapper Subset Evaluator
Learning scheme: weka.classifiers.trees.J48 Scheme options: C 0.25 -M 2
Subset evaluation: classification accuracy Number of folds for accuracy estimation: 5
Ranked attributes: Rank
0.3810 4 Data architecture
1 0.3810 3 Data modeling
0.3810 2 Data integration
0.3333 19 Semantic models 2
0.3095 5 Data storage
3 0.3095 15 Network model
0.3095 1 Concepts and fundamentals of data management
0.2857 7 Managing the
database environment 4 0.2667 12 Dimensional
models
5 0.2667 14 Logical
databases
0.2667 13 Flat files
0.2619 22 Data masking 6
0.2619 11 Use of graphical vs. textual representations of database structures
0.1905 17 Object-relational
databases
0.1905 18 Relational model 7
0.1857 10 Special-purpose
databases 8
8
0.1619 20 Archiving 9
0.0952 16 Object
databases 10
0.0952 9 Semantic Web
0.0476 6 Database query
languages
0.0476 8 Metadata 11
0.0333 21 Data encryption 12
Selected attributes:
4,3,2,19,5,15,1,7,12,14,13,22,11,17,18,10,20,16,9,6,8,21 : 22
Table 3: Correctly Classified Instances
Correctly Classified Instances 41 97.619 % Incorrectly Classified Instances 1 2.381 %
Kappa statistic 0.9599
Mean absolute error 0.0303 Root mean squared error 0.1231 Relative absolute error 7.4964 %
Root relative squared error 27.4709 %
Total Number of Instances 42
Table 4: Detailed Accuracy by Class
TP Rat e F P R at e Pre- cisi on Re - Ca ll F M ea su re MC C RO C Are a PR C Are a Class
1 0 0.9 6 1
0. 98
0.9 5
0.9 8 0.96
Compet ent
0.8
3 0 1 1
0. 91 0.9
0.9 5 0.87
Highly Compet ent
1 0 1 1 1 1 1 1 Uncertai
n Wei ght ed Avg . 0.9 8 0
0.9 8 0. 98 0.9 6 0.9 8 0.96
Figure 3: Decision Tree Model for Database Management
Systems Topics
5. REFERENCES
Table 5: Confusion Matrix
a b c <-- classified as 21 0 0 | a = Competent
3460
[1]. Algarni, A. (2016). Data Mining in Education. International Journal of Advanced Computer Science and Applications.
[2]. Ali, M. M. (2013). Role of data mining in education sector. International Journal of Computer Science and Mobile Computing, 2(4), 374-383.
[3]. Arora, R. P. (2013). Secure user data in cloud computing using encryption algorithms. International journal of engineering research and applications, 3(4), 1922-1926.
[4]. Baker, R. S. (2010). Data mining for education. International encyclopedia of education, 7(3), 112-118.
[5]. Bar-Anan, Y. W. (2009). The feeling of uncertainty intensifies affective reactions. Emotion, 9(1), 123. [6]. Calvanese, D. D. (2009). Conceptual modeling for
data integration. In In Conceptual Modeling: Foundations and Applications (pp. (pp. 173-197)). Berlin, Heidelberg: Springer.
[7]. Cambridge Dictionary. (2019). https://dictionary.cambridge.org/us/dictionary/englis h/competent. Retrieved from https://dictionary.cambridge.org:
https://dictionary.cambridge.org/us/dictionary/englis h/competent
[8]. E. Johnson, J. J. (2008). A Developer’s Guide to Data Modeling. Addison-Wesley.
[9]. Han, J. H. (2011). Survey on NoSQL database. In 2011 6th international conference on pervasive computing and applications (pp. 363-366). IEEE. [10]. Hsia, T.-C. S.-J.-C. (2008). Course planning of
extension education to meet market demand by using data mining techniques–an example of Chinkuo technology university in Taiwan. Expert Systems with Applications, 34(1), 596-602.
[11]. IBM. (2019, September 15). https://www.ibm.com/analytics/data-integration. Retrieved from https://www.ibm.com: https://www.ibm.com/analytics/data-integration [12]. Koh, H. C. (2011). Data mining applications in
healthcare. Journal of healthcare information management, 19(2), 65.
[13]. McHugh, M. L. (2012). Interrater reliability: the kappa statistic. Biochemia medica:, 22(3), 276-282. [14]. Patil, T. R. (2013). Performance analysis of Naive Bayes and J48 classification algorithm for data classification. International journal of computer science and applications,, 6(2), 256-261.
[15]. Rouse, M. (n.d.). Database Management Sysstem (DBMS). Retrieved from TechTarger: https://searchsqlserver.techtarget.com/definition/da tabase-management-system
[16]. Smithson, M. (2008). Psychology’s ambivalent view of uncertainty. Uncertainty and risk: Multidisciplinary perspectives,. Retrieved from http://citeseerx.ist.psu.edu:
http://citeseerx.ist.psu.edu/viewdoc/download?doi= 10.1.1.543.8199&rep=rep1&type=pdf
[17]. Techopedia. (2019). https://www.techopedia.com/definition/23342/data-storage. Retrieved from https://www.techopedia.com:
https://www.techopedia.com/definition/23342/data-storage
[18].Transformation, D. (2019, September 16). https://digitaltransformationpro.com/data-mining-steps/. Retrieved from https://digitaltransformationpro.com:
https://digitaltransformationpro.com/data-mining-steps/
[19].Wongpakaran, N. W. (2013). A comparison of Cohen’s Kappa and Gwet’s AC1 when calculating inter-rater reliability coefficients: a study conducted with personality disorder samples. BMC medical research methodology, 13(1), 61.