Statistics and Data Mining
A B M Shawkat Ali
1
PowerPoint permissions
Cengage Learning Australia hereby permits the usage and posting of our copyright controlled PowerPoint slide content for all courses wherein the associated text has been adopted. PowerPoint slides may be placed on course management systems that operate under a controlled environment (accessed restricted to enrolled students, instructors and content administrators). Cengage Learning
Objectives
On completion of this lecture you should know:
• What is Data Mining and how does it related with Statistics?
• The basic ramifications of Data Mining
• KDD, Data Query and Data Mining
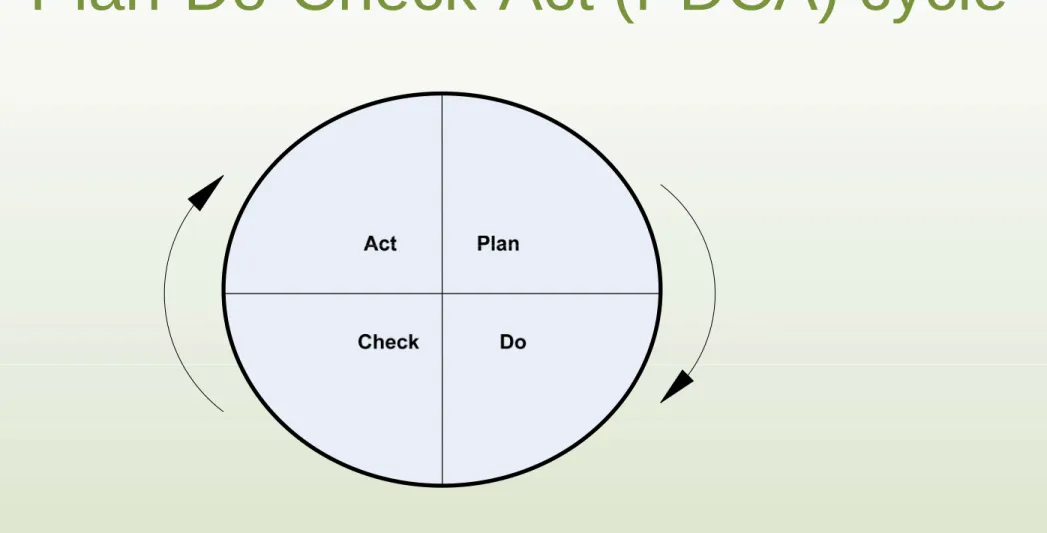
• Basic understanding of PDCA cycle
• Current applications of Data Mining
Data mining: A definition
Ask yourself:
What is gold mining?
Data mining (DM)
The process of employing one or more computer learning techniques to automatically analyze and extract
knowledge from data- (Roiger and Geatz, 2003).
Data mining is the nontrivial extraction of implicit,
previously unknown, and potentially useful information from data using machine learning, statistical and
visualization techniques –(Frawley et al., 1992).
Many experts agree that data mining should not be automatic – human intervention and interpretation is essential.
Knowledge discovery in databases
(KDD)
• Data Mining (DM) is one step of the KDD process.
• DM is an information extraction process and KDD is making sense of the information.
• But now no distinction is made between the two.
• The application of the scientific method occurs in DM.
An example
• Example 1.1
A leading Australian supermarket chain employs a data mining expert to analyse local buying
patterns.
Analysis: When a customer buys honey on Friday
or Sunday, they also usually buy bread.
(cont.)
Observation: More people buy honey
and bread together on Friday and Sunday.
Business Benefit: The supermarket chain can use
this information in various ways to increase
revenue. For instance, they can move the bread shelf closer to the honey shelf and make sure that bread and honey are sold at full price during the weekend.
Example:
Amazon.com
purchase
suggestion
Amazon.com increased
sales by 15%, using
data/text mining generated
Plan-Do-Check-Act (PDCA) cycle
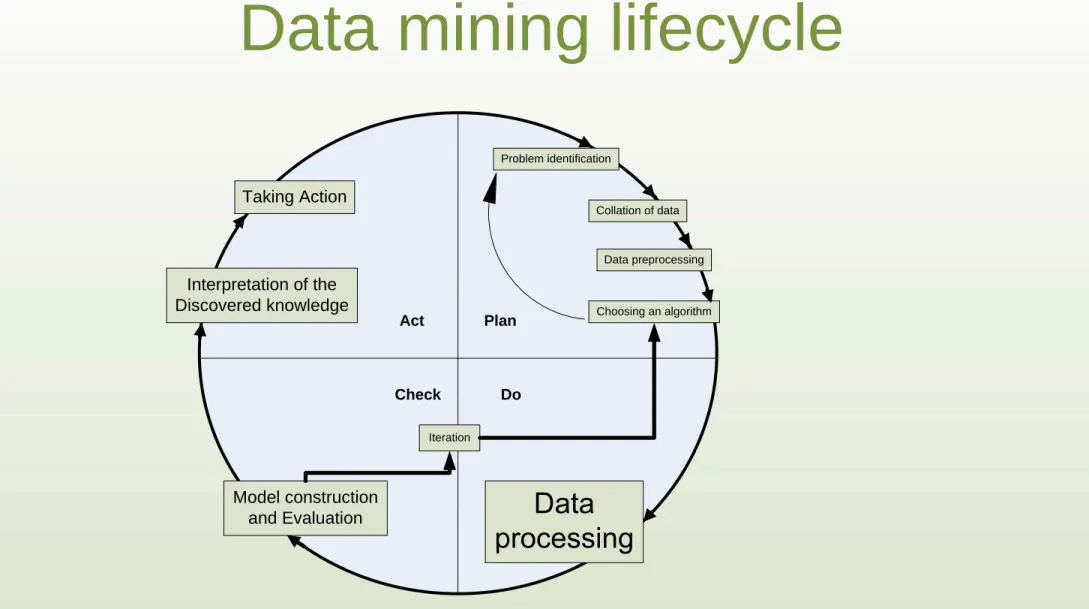
Data mining lifecycle
Act Plan Check Do Problem identification Collation of data Data preprocessing Choosing an algorithm Model construction and Evaluation Interpretation of the Discovered knowledge Taking Action IterationData
mining
and
It’s
branches
Statistics: “The model is king” (Hand) Data Mining: “The data is king”
Statistics
vs.
Data
Mining:
Concepts
Feature Statistics Data Mining
Type of Problem Well structured Unstructured / Semi-structured
Inference Role Explicit inference plays
great role in any analysis
No explicit inference Objective of the Analysis
and Data Collection
First – objective
formulation, and then - data collection
Data rarely collected for objective of the analysis/modeling
Size of data set Data set is small and
hopefully homogeneous
Data set is large and data set is heterogeneous
Paradigm/Approach Theory-based (deductive) Synergy of theory-based and
heuristic-based approaches (inductive)
Signal-to-Noise Ratio STNR > 3 0 < STNR <= 3
Type of Analysis Confirmative Explorative
Statistics
vs.
Data
Mining:
Regression
Modeling
Feature Statistics Data Mining
Number of inputs Small Large
Type of inputs Interval scaled and categorical with
small number of categories
(percentage of categorical variables is small)
Any mixture of interval scaled, categorical, and text variables
Multicollinearity Wide range of degree of
multicollinearity with intolerance to multicollinearity
Severe multicollinearity is always there, tolerance to multicollinearity Distributional assumptions, homoscedasticity, outliers, missing values Intolerance to distributional assumption violation, homoscedasticity,
Outliers/leverage points, missing values
Tolerance to distributional assumption violation,
outliers/leverage points, and missing values
Type of model Linear / linear / Parametric /
Non-Parametric in low dimensional X-space (intolerance to
uncharacterizable non-linearities)
Non-linear and non-parametric in high
dimensional X-space with
tolerance to uncharacterizable non-linearities
Steps of DM:
Problem identification
• The problem should be meaningful.
• We also need to set the level of expectation for the solution, say 80% or 98% satisfaction.
• Without business understanding and
requirements, useful data mining cannot be done.
Collation of data:
• The problem definition provides us with the scope of relevant data.
• A data mining technique may require millions and often billions of cases of data.
• However, typically, a data mining technique is applied to a few hundred or a few thousand instances of data.
Data preprocessing:
Is dependent on the source:
• If the data comes from a data warehouse, no pre-processing of data is usually required because the warehouse data has already been filtered, cleaned and missing values taken care of.
• For transactional data, it needs to be organised and cleaned such that a data mining technique can be readily applied.
• The data has to be made consistent across sources. For example, in one database male and female may be represented as M and F, and in another database it may be
represented as 1 and 0. Such anomalies have to be removed and any representation has to be made uniform.
Algorithm selection:
• Now-a-days quite a good number of data mining algorithms are available for public use.
• In general, parametric algorithms are relatively more suited for the data mining task. This
involves choosing the optimal parameters to receive the best solution.
Data processing:
• This may involve data normalisation, data transformation or data integration.
• Some algorithms cannot work with categorical data, some cannot work with numerical data, and yet, some others cannot work with either unless the values meet certain criteria.
• Another important part of this task is data
splitting, which is about deciding which part of data is to be used for model building (training data) and which part for model testing (test data).
• This step is identified as data preparation in CRISP-DM
.
Model construction and evaluation:
• Model evaluation or testing is an important step for maximising the amount of information that can be extracted from the dataset.
• If we see the model performances to be
unacceptable, we follow the iterative path of choosing a different data mining algorithm or having a different set of features from the
dataset.
Discovering knowledge:
• Final stage of DM.
• Verify the quality of knowledge.
Taking action:
• We may act based on the discovered knowledge, which could bring rewards.
• Taking action can simply mean applying the model to new instances.
• This step is identified as deployment in CRISP-DM.
Types of knowledge
• Shallow knowledge: It is simply what makes up a computers response. For example, we may
learn that Australian Stock Exchange generally follows the lead of Wall Street, but we wouldn't necessarily know why.
• Deep knowledge: It is the underlying reason behind such relationships. For example, which gene is responsible for diabetics.
Cross-Industry Standard Process for Data Mining (CRISP-DM): • Business Understanding • Data understanding • Data Preparation • Modelling • Evaluation • Deployment (cont.) 27
We identified 8 steps considering all possible applications of data mining including business sector. These 8 steps have been described
within the framework of PDCA (Plan-Do-Check- Act) cycle highlighting the highly iterative aspect of the process.
Data query versus data mining
Data Query
• A list of customers who used MasterCard to buy medicine from a pharmacy.
• A list of employees who will reach retiring age next year.
• A list of residents in a locality who became diabetic before reaching the age of 50.
• Find all customers who have purchased diapers.
Data Mining
• Develop a profile of MasterCard holders who will take advantage of the forthcoming sale promotion of the pharmacy.
• Develop a list of employees, who are likely to avail themselves of the voluntary early
retirement scheme when they reach the retiring age.
• Construct some rules about the lifestyle of residents of a locality which may reduce the occurrence of diabetes at an early age.
• Find all items which are frequently purchased with diapers.
The learning process
• What is Learning?
It’s a process to gather knowledge.
Four Levels of Learning:
31
• Facts - simple truths
• Concepts - relationships
• Procedures - algorithms
Types of learning
• Supervised Learning:
Learning with the help of a supervisor
Example 1.2
In a biomedical study, medical records for a
set of healthy patients and a set of patients with heart disease have been collected.
• The data mining technique to this study would be to learn what combination of attributes –
obesity, high-cholesterol, smoking habit, etc. – characterises patients with heart disease and distinguishes them from healthy patients.
Types of learning (cont.)
Obesity High-Cholesterol … Smoker Class Patient 1 Yes … NoYes … Yes Sick
… … … … …
Patient m No … No Healthy
Types of learning (cont.)
Unsupervised Learning
• Learning without a supervisor
Example 1.3
A credit card company wants to promote credit card insurance.
Types of learning (cont.)
Home Insurance Life insurance … Income rangePerson 1 Yes Yes … 50-60K
… … …
Person m Yes No … 40-50K
Reinforcement Learning
• Leaning from incidence
Example 1.4
Some players have trouble arriving on time to the practice match.
To lift the team spirit coach orders all the players to run 5 extra laps in the stadium. The coach claims that this application had to be given only once a year.
The history of data mining
• 1700-1939: First Generation of Data Mining. It wasbased on Statistics.
• 1940-1989: Second Generation of Data Mining. First introduction of Artificial Intelligence (AI) in Data Mining. • 1960s: Data Mining starts the real journey. The late
1960s saw the introduction of clustering techniques
(Unsupervised Learning ) in the field of Information
Retrieval.
• 1990-onwards: Third Generation of Data Mining. People introduced better techniques by combining Statistics and AI.
Data mining strategies
Classification Example 1.5
A bank wishes to determine the credit risk of a credit card applicant. The application is either approved or rejected.
Cont.
Feature Classification
F1
Association Example 1.6
A leading supermarket chain had 100,000 point-of sale transactions last month. An association rule miner observes that 25,000 of these transactions include both banana and bread and 8,000
transactions include three items – banana, bread and honey.
Clustering
Example 1.7
Clustering could be used by an insurance
company to group important customers according to age, types of policies purchased, duration of
membership, and prior claims history.
Estimation Example 1.8
We are interested in estimating the blood sugar level of a new hospital patient.
Novelty Detection Example 1.8
The heartbeat record of a healthy patient to an untrained eye is either plain noise or full of
features or spikes.
Sequence Detection Example 1.9
Thrombosis is a potential complication of collagen diseases.
Popular data mining techniques
• Function Estimation-Based Algorithms: Neural Networks, Support Vector Machines etc.
• Lazy Learning-Based Algorithms: K-Nearest Neighbors, Lazy Bayesian Rules etc.
• Meta Learning-Based Algorithms: Adaboost, Bagging, and MetaCost etc.
• Probability-Based Algorithms: Naive Bayes, BayesNet etc.
• Tree-Based Algorithms: C4.5, Classification and Regression Tree (CART) and CHAID etc.
Decision
Tree
Yes No Outlook humidity windy Yes Yes No high sunny rainy overcast
Common with insurance agencies and banks. For example, Bank of America.
Common in gambling industry. For example, Harrah’s Entertainment Inc.
Common with large businesses. For example, Wal-Mart.
55
• Banking – loan/credit card approval:
Predict good customers based on old customer profiles.
• Customer relationship management (CRM): Identify those who are likely to leave for a
competitor.
• Targeted marketing:
• Fraud detection – telecommunications, financial transactions:
Identify fraudulent transactions from an online stream of events.
• Manufacturing and production:
Automatically adjust knobs when process parameter changes
• Medicine – disease outcome, effectiveness of treatments:
Analyse patient disease history: find relationship between disease and symptoms.
• Molecular/Pharmaceutical: Identify new drugs.
• Scientific data analysis:
Identify new galaxies by searching for sub clusters.
• Website/store design and promotion:
Find preferences of website/store visitor and modify layout accordingly.
Challenges of data mining
• Size of dataset
• High dimensionality • Over-fitting
• Missing and noisy data • Rapidly changing data • Mixed dataset
• Human intervention and interpretation
Future of data mining
• Credit risk assessment
• Customer relationship management • Attrition of small business customers • Early weather warning
• Stock price forecast
• Quick machinery fault detection • Brain tumor prediction
• These and other such issues are already seeing the introduction of data mining technology in
their solution strategies.
• The long-term prospects are truly exciting. Data mining technology has already opened a new dimension in medical research. For example, a gene data analyst can tell us who has breast cancer and who does not.
Privacy
in
Data
Mining
• Mining of public and government databases is done,
though people have, and continue to raise concerns.
• Wiki quote:
"data mining gives information that would not be
available otherwise. It must be properly interpreted
to be useful. When the data collected involves
individual people, there are many questions
concerning privacy, legality, and ethics."
Prevalence
of
Data
Mining
• Your data is already being mined, whether you like it or not.
• Many web services require that you allow access to your information [for
data mining] in order to use the service.
• Google mines email data in Gmail accounts to present account owners
with ads.
• Facebook requires users to allow access to info from non‐Facebook pages.
Facebook privacy policy:
"We may use information about you that we collect from other sources,
including but not limited to newspapers and Internet sources such as
blogs, instant messaging services and other users of Facebook, to
supplement your profile.
• This allows access to your blog RSS feed (rather innocuous), as well as
Key learning outcomes
• What is Data Mining?
• The basic ramifications of Data mining • KDD, Data Query and Data Mining
• Basic Understanding of PDCA cycle