6
All Rights Reserved © 2012 IJARCSEE
Handwritten Script recognition using Soft
Computing
Akhilesh Pandey1, Sunita Singh2, Rajiv Kumar3, Amod Tiwari4
Abstract-Today, handwritten script recognition is challenging part in the computer science. It is important to know a script used in writing. Script recognitions have many important applications like automatic transcription of multilingual documents, searching document image, script sorting. Proposed work emphasis on the “block level technique” where script recognition recognizes the script of the given document in a mixture of various script documents. There has an important role of computational field like artificial intelligence, expect system. Feature extraction technique is an important step in Script recognition. In this project, we have used combined approach of Discrete Cosine Transform (DCT) and discrete wavelets Transform (DWT) for feature extraction and neural network (feed forward back propagation) classifier for classification and recognition purpose. Human mind can easily trace handwritten script so there have we use Artificial intelligence in which we use classifier neural network. The proposed system has been experimented on three handwritten scripts Hindi, English and Urdu. Our database contains 961 handwritten samples, written in three scripts. Every script (Hindi, English and Urdu) contains 320 samples (160 samples are written in small font and another 160 samples are in large font).
Keywords: Multi-script documents, handwritten script, Discrete Cosine Transform, Wavelets, neural network classifier.
1. INTRODUCTION
Today, many researchers have been done to recognize multi script recognition. But the problem of interchanging data between human beings and computing machines is a challenging one. Even in present, many algorithms have been proposed by many researchers so-that these multi script (Hindi, English, Urdu) can be easily recognize. But the efficiency of these algorithms is not satisfactory. Multi-script document is a document in that contains text information in more than one script. Handwritten script
reorganization is a complex text with following reasons-complexity in preprocessing, reasons-complexity in feature extraction, complexity in classification, sensitivity of the
scheme tothe variation in handwritten text in documents
like font size, font style and document skew and the performance of the scheme. Many researchers have been done to solve handwritten Multi Script recognition problem in related areas such as Image Processing, Pattern Recognition, Artificial Intelligence, and cognitive science etc. Further researches are being done to improve accuracy and efficiency. Recognition of Offline Handwritten Multi Scripts is a goal of many research efforts in the pattern recognition field and A survey of offline cursive script word recognition is presented in [1]. The survey is classified into three section-in first introduction about automatic recognition of handwriting and official regional scripts in India. The nine regional scripts are contain and then categorized into four subgroups based on their similarity and evolution information.OCR work is done on Indian scripts reported in [2] in which contain a benchmark database. Many techniques have been applied for recognition of handwritten Multi Scripts but still it is the case of less efficiency and accuracy of recognition. Artificial Intelligence concepts like neural networks are used to perform the work as human mind can do. This explores the idea of how humans recognize text in general and are used to develop machines that simulated this process. Developing these intelligent machines for recognizing Multi Scripts is not an easy task; this is because a Multi Script can be written in different ways. Also there are so many imperfections and variation of handwriting such as alignment, noise and angles, which make handwritten Multi Script recognition difficult to implement with a machine. . Existing script identification depends on the different feature extraction like DCT and DWT presented in [3].the OCR technique is applied on the devanagri script on [4] paper. In [5] paper metadata describing the
text in paragraph, page and line level. Tools to extract
paragraphs from pages, segment paragraphs into lines have also been developed. two approaches for Amharic word recognition in unconstrained handwritten text using
7
All Rights Reserved © 2012 IJARCSEE
models from combined features of constituent characters and in the
second method HMMs of constituent characters are concatenated to form word model. In [7] paper offline arbiclFarsi handwritten recognition algorithm on a subset of Farsi name is proposed. There have use RBF neural network and combination of GA and K-Means clustering algorithm. The [8] paper is works on street name recognition on Indian language. we know that some street name contain two or more than words so it is concatenate that’s word and create in a single word. Hence, in this paper, we present a multiple feature based approach that
combinesDiscrete Cosine Transform (DCT) and Wavelet
based frequency contents for three Indian scripts including English, Hindi and Urdu. The classification is done using feed forward back propagation neural network classifier. The experiments are carried out on the database at block level.
II. BACKGROUND INFORMATION
Multi Script recognition is a process, which associates various script objects (words) drawn on an image, i.e., Multi Script recognition techniques associate a word identity with the image of a Multi Script. Mainly, Multi Script recognition machine takes the raw data that further implements the process of preprocessing of any recognition system.
On the basis of that data acquisition process, Script recognition can be categorized into following two parts: -
1. Online Script Recognition 2. Offline Script Recognition
Off-line handwriting recognition refers to the process of recognizing words that have been scanned from a paper and are stored digitally in grey scale format. After being stored, it is conventional to perform further processing to allow recognition scheme. In case of online handwritten script recognition, the handwriting is captured and stored in digital form via different means. Usually, a special pen is used in conjunction with an electronic surface. As the pen moves across the surface, the two- dimensional coordinates of successive points are represented as a function of time and are stored in order [1]. It is generally accepted that the on-line method of recognizing handwritten text has achieved better results than its off-line counterpart. This may be attributed to the fact that more information may be captured in the on-line case
such as the direction, speed and the order of strokes of the handwriting.
A. Handwritten Multi Script Recognition
Handwritten Multi Script Recognition (HMSR) is an area of pattern recognition that has been the subject of considerable research since last some decades. There are too many applications in Indian offices such as bank, sales-tax, railway, etc. are used English, Hindi and Urdu languages. Many forms and applications are filled in these languages and sometimes those forms have to be scanned directly. If there is no standard HMSR system, then image is directly captivated and there is no option for editing those documents. Handwritten script recognition (HSR) is a process of automatic computer recognition of scripts in optically scanned and digitized pages of text. The main objective of an HMSR system is to recognize multi script, which are in the form of digital images, without any human intervention. This is done by searching a match between the features extracted from the given script’s image and the library of image models.
B. Pre-processing
In HMSR, typical preprocessing operations include 1. Binarization
2. Noise reduction 3. Skew detection
The main objectives of Pre-processing methods are:-
In preprocessing technique we perform 2
operation
Binarization:-transform colored image in to black
& white image
img= im2double(rgb2gray(imread(’coins.png’)));
Thinning:-Morphological operations on binary
images. Thinning is a morphological operation that is used to remove selected foreground pixels from binary images.
img= bwmorph(img,'thin');
8
All Rights Reserved © 2012 IJARCSEE
Figure 1: Block Diagram of Script Identification
Figure 2: Script Sample of English Language
Figure 3: Script Sample of Hindi Language
Figure 4: Script Sample of Urdu Language
Figure 5: Combined Sample of multi script
C. Segmentation
It is an operation that seeks to disintegrate an image of sequence of Scripts into sub images of individual symbols. The utility of conventional systems script segmentation play the main requirement. Different methods used can be classified based on the type of text and strategy being followed like straight segmentation
method, recognition-based segmentation and cut
classification method. In order to achieve broad utility, it is important that a segmentation method have the following properties:
1. Capture perceptually important groupings, which often ruminating global aspects of the image. Two central issues those are provided precise scriptizations of what are perceptually important, and to be able to specify what a given segmentation technique does. There should be precise definitions of the properties of a resulting segmentation, in order to better understand the method as well as to alleviate the comparison of different approaches.
2. In order to be of practical use, segmentation methods that runs at several frames per second can be used in video processing applications.
D. Feature extraction
Every Script has features, which play a big role in pattern recognition. English, Hindi and Urdu Scripts have many particular features. Feature extraction describes the relevant shape information contained in a pattern so that the task of classifying the pattern is made easy by a formal procedure. Feature extraction stage in HMSR system analyses these Script segment and selects a set of features that can be used to uniquely identify in the script segment. Mainly, this stage is heart of HMSR system because the expected output depends on these features. Feature extraction is the name given to a family of procedures for measuring the relevant shape information contained in a pattern so that the task of classifying the pattern is made easy by a formal procedure. Among the different design issues involved in building a recognizing system, perhaps the most significant one is the selection of set of features.
9
All Rights Reserved © 2012 IJARCSEE
such as the mean square error or the inter pattern distance difference whereas feature extraction criteria for classification aim to increase class reparability as possible calculated for exploratory data projections are not necessarily the optimum features of the image.
III. REPRESENTATION OF SCRIPT FEATURES
After extracting the features, the data should be represented in one of two ways, either as a boundary or as a complete region. When the focus is on external shape script such as corners and modulations then boundary
representation is appropriate. While regional
representation is appropriate when the focus is on internal properties such as textures or skeleton shape. In some applications like script recognition these representations coexist, which often require algorithm based on boundary shape as well as skeletons and other internal properties.
a. b.
c. d.
e. f.
g.
Figure 6. a. Original Cropped Image of English Script b. Black & White Image c. Invert color d. Clear componenet clear border e. Applying thining f. DCT form g. DWT form of English Script
a. b.
c. d.
e. f.
g.
Figure 7. a. Original Cropped Image of Hindi Script b. Black & White Image c. Invert color d. Clear component clear border e. Applying thinning f. DCT form g. DWT form of Hindi Script
a. b.
10
All Rights Reserved © 2012 IJARCSEE
e. f.
g.
Figure 8. a. Original Cropped Image of Urdu Script b. Black & White Image c. Invert color d. Clear component clear border e. Applying thinning f. DCT form g. DWT form of Urdu Script
III. RESULTS
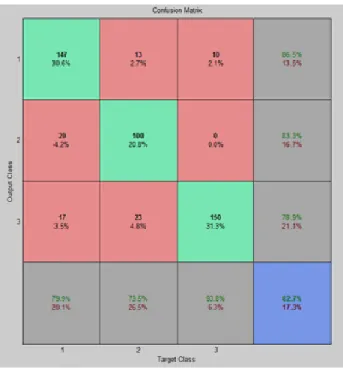
The sets of handwritten scripts are made. The data set was partitioned into two parts. The first one is used for training the system and the second one for testing. For each script, features were computed and stored for training the network. Three network layers, i.e. one input layer, one hidden layer and one output layer are taken. If number of neurons in the hidden layer is increased, then a problem of allocation of required memory is occurred. By that recognitions rate we find out the 82.70% accurate result in all three script. Here we use 50-50 set for the training and testing purpose.
Scripts No. of samples
Train/test Recognition result
Hindi 373
English 369
Urdu 320 481/480 82.70%
Table 1. Result of Multiple classifiers
Table 2. Confusion Matrix
REFERENCE
[1]Nabin Sharma. With Co-Authored with U. Pal, and R. Jayadevan, ”Handwriting recognition in Indian regional scripts: A survey of offline techniques”
[2]ram sarkar, nibaran das, subhadip basu, mahantapas kundu, mita nasipuri and dipak kumar basu,” cmaterdb1: a database of unconstrained handwritten bangla and bangla-english mixed script document image”, international journal on document analysis and recognition Volume 15, number 1 (2012), 71-83, doi: 10.1007/s10032-011-0148-6, 2012.
[3]G. G. Rajput and Anita H. B.,”Handwritten Script Recognition using DCT and Wavelet Features at Block Level”,2010.
[4]Jayadevan, R. Pune Inst. of Comput. Technol., Pune, India Kolhe, S.R. ; Patil, P.M. ; Pal, U.,”Offline Recognition of Devanagari Script: A Survey”, Volume: 41 , Issue: 6,Product Type: Journals & Magazines,2011.
[5] AlKhateeb, J.H.,”A new approach for off-line handwritten Arabic word recognition using KNN classifier”,18-19 Nov. 2009.
[6]Assabie, Y.,’HMM-Based Handwritten Amharic Word Recognition with Feature Concatenation”, Document Analysis and Recognition, ICDAR '09. 10th International Conference, 2009.
11
All Rights Reserved © 2012 IJARCSEE network and genetic algorithm ”,Intelligent Computing and Intelligent
Systems (ICIS),IEEE International Conference on 2010.
[8]Pal, U.,Roy, R.K., Kimura, F.,”Handwritten street name recognition for Indian postal automation”, Document Analysis and Recognition (ICDAR), International Conference on 2011.
[9] Liangrui Peng, Changsong Liu, Xiaoqing Ding, Hua Wang, "Multilingual document recognition research and its application in China," dial, pp.126-132, Second International Conference on Document Image Analysis for Libraries (DIAL'06), 2006.
[10] U. Pal and B. Chaudhuri. Automatic identification of English, Chinese, Arabic, Devnagari and Bangla script line. In International Conference on Document Analysis and Recognition, pages 790-794, 2001.
[11]u.bhattacharya,T.K Das,A.Datta,S.K.Parui,B.B Chaudhuri,”A hybrid scheme for hand printed numeral recognition based on a self- organizing network and MPL Classifiers,Int.J.Pattern Recognitoin Artificial Intelligence”.16(2002) 845-864.
[12]K. H. Aparna, V. Subramaniam, M. Kasirajan, G. V. Prakash, V. S. Chakravarthy and S. Madhvanath, “Online handwrting recognition for Tamil”, in the Proceedings of 9th International Workshop on Frontiers in Handwriting Recognition(IWFHR), pp. 438-443, 2004.
[13]C. V. Lakshmi and C. Patvardhan, “A high accuracy OCR system for printed Telugu text”, in the Proceedings of Conference on Convergent Technologies for Asia-Pacific Region (TENCON 2003), Vol. 2, pp. 725-729, 2003.
[14]Lei Han, Jue Zhong, Arkady Voloshin, Image analysis and data processing of time series fringe pattern of PCBs by using moiré interferometry,in: Proceedings of HDP’04, 2004, pp. 141–145.
[15]Ping Zhong, Chenjie Song, Nian Luo, Method of extracting high-resolution digital moiré fringe in warpage measurement, Physical and Failure Analysis of Integrated Circuits, IPFA, 2009, pp. 527–530.
[16]V. Ablavsky and M.R. Stevens, “Automatic Feature Selection with Applications to Script Identification of Degraded Documents,” Proc. Int’l Conf. Document Analysis & Recognition, Edinburgh, pp.750-754, Aug. 2003.
[17] [2] D.Dhanya, A.G Ramakrishnan and Peeta Basa pati, “Script identification in printed bilingual documents,” Sadhana, vol. 27, part-1, pp. 73-82, 2002.
AUTHORS PROFILE:
Akhilesh Pandey is an Asst. Professor in department of computer science and engineering Shridhar University, Pilani. He did his MCA from IGNOU in 2002 and after that he worked as a faculty member in different engineering college. After that he acquired his M. Tech. (CSE) at Sharda University, Gr. Noida, India., His area of Interest is Pattern Recognition and neural network.
Sunita singh done her B.Tech. (CSE) from Lord Krishna College, Gaziyabad and done her M.tech from sharda university, Gr. Noida, India. She is a member of our team and work on the MATLAB. Her programming is very excellent. Her area of interest is the Image processing.
Rajiv Kumar is an Assistant Professor at School of Engineering & Technology, Sharda University, Greater Noida,India. He acquired his Master of
Technology degree in Information Technology from Bengal Engineering College, Shibpur(DU), West Bengal. His main interest area is Image Processing, Pattern recognition,Neural Networks.