Neurocomputing 0 0 0 (2018) 1–11
Contents lists available at ScienceDirect
Neurocomputing
journal homepage: www.elsevier.com/locate/neucom
Kernel
group
sparse
representation
classifier
via
structural
and
non-convex
constraints
Jianwei
Zheng
a,b,
Hong
Qiu
a,
Weiguo
Sheng
c,
Xi
Yang
a,∗,
Hongchuan
Yu
baSchoolofComputerScienceandTechnology,ZhejiangUniversityofTechnology,288LiuheRoad,Hangzhou,Zhejiang,China bNationalCentreforComputerAnimation,BournemouthUniversity,BournemouthBH125BB,UK
cInstituteofServiceEngineering,HangzhouNormalUniversity,2318YuhangtangRoad,Hangzhou,Zhejiang,China
a
r
t
i
c
l
e
i
n
f
o
Articlehistory: Received17October2016 Revised24January2018 Accepted12March2018 Availableonlinexxx CommunicatedbyIvorTsang Keywords: Sparserepresentation Localityconstraint Groupsparse Kerneltrick Non-convexpenaltya
b
s
t
r
a
c
t
Inthispaper,weproposeanewclassifiernamedkernelgroupsparserepresentationviastructuraland non-convexconstraints(KGSRSN)forimagerecognition.Thenewapproachintegratesbothgroup spar-sityandstructurelocalityinthekernelfeaturespaceandthenpenaltiesanon-convex functiontothe representationcoefficients.On the one hand,bymapping thetraining samples intothe kernel space, the so-called norm normalization problemwill be naturally alleviated. On the other hand,an inter-valfortheparameterofpenaltyfunctionisprovidedtopromotemoresparsitywithoutsacrificingthe uniquenessofthesolution androbustnessofconvexoptimization.Ourmethodiscomputationally effi-cientduetotheutilizationoftheAlternatingDirectionMethodofMultipliers(ADMM)and Majorization-Minimization(MM).Experimentalresultsonthreereal-worldbenchmarkdatasets,i.e.,ARfacedatabase, PIEfacedatabaseandMNISThandwrittendigits database,demonstratethatKGSRSNcanachievemore discriminativesparsecoefficients,anditoutperformsmanystate-of-the-artapproachesforclassification withrespecttobothrecognitionratesandrunningtime.
© 2018ElsevierB.V.Allrightsreserved.
1. Introduction
Image Classification (IC) is a fundamental and quintessential taskin patternrecognition andcomputer vision duetoits broad applicationsinhuman-computerinteractionandsecurity monitor-ing. Exploration to improve upon the accuracy and efficiency of IC approacheshasbeena remarkableresearch focus.Deep learn-ing, asoneof thepopulartechniques,has achievedgreatsuccess due tothe factsthat it is able tolearn extremely powerful hier-archicalnonlinearrepresentationsoftheinputs[1].However,deep learningbasedmethodsrequiremassivetrainingsamples,whichis difficulttofulfillinmanypracticalapplicationsandcomputational platforms.Alternatively,themethodsviasmallnumberoftraining samplesareusuallyadoptedinmanyspecificscenarios.
Recently, sparse representation (SR)has become a very active topicinsignal processingandimage classification community.So far, it has been successfully applied in many practical problems such asinformationevaluation[2],featureextraction[3,4],visual tracking[5,6],etc.Undertheassumptionthatnaturalimagecanbe generally represented by structural primitives, SR-based classifier
∗ Correspondingauthor.
E-mailaddress:[email protected] (X.Yang).
(SRC)[7] aimstoreconstructaqueryimageusingasmallsetof el-ementsparsimoniouslychosenoutofanover-completedictionary, andclassifiesthequeryimageintotheclasswhichresultsthe min-imalreconstructionerror.Inaddition,sparseconstraints(l1-norm) notonlyleadtotheuniquesolutionofrepresentationcoefficients, butalsohelptostudytheactualsignalstructure.Indeed,most sig-nals admit decompositionover a reducedset ofsignalsfrom the sameclassandthatwillbenefitthesubsequentclassificationtask. SRChas shown its promise in IC problems andhas received re-markableattention.
Somescholarsinquiredintothereasonabilityofsparse regular-izationforIC[8,9].Zhangetal.[8] arguedthatitwasunnecessary to enforce sparsity constraint on linear regression problem, and asserted it was the collaboration mechanism that makes SRC outperform nearest neighborbased algorithms, suchasNN, INNC [10], etc. Correspondingly, they proposed a new classification scheme,namely collaborative representation classifier (CRC). CRC has significantly less computational cost than SRC but leads to verycompetitiveclassificationresults.BothofSRCandCRCfollow areasonableassumption thatthe subspacesof eachobjectiveare independentofeachother.However,thisassumptionisnotalways held in general image distribution. This may lead to undesirable consequencesthatsomequerysamplesarerepresentedbyimages from other subjects. To cope with this issue and introduce the https://doi.org/10.1016/j.neucom.2018.03.035
0925-2312/© 2018 Elsevier B.V. All rights reserved.
Neuro-essential structure information embedded in the dictionary, Ma-jumdaretal.[11] proposed group sparseclassification (GSC)that solvestheregressionprobleminangroupway.Underthe assump-tion that the signals can be approximated by a union of a few subspaces,GSCselectscertaingroupstorepresentthetestsample byusingl2,1-norm regularization.Similarly, Huangetal.[12] also applied the group sparse coding to images classification, where eachtestsampleisrepresentedbytheminimumnumberofblocks. Both the theoretical analysis and the experimental results have showed the promising performance of GSC, outperforming both SRCandCRC.Morerecently,ithasbeenverifiedthattheproperty oflocality preservation is moreimportant for a classifier [13,14]. As a result, many regression-based works have been proposed, suchasintegratingthedatalocalityintotheconstraintsofl1-norm [15,16], l2-norm [17,18] or group norm [19,20], for improvement. Moreover, Tang, et al. [21] pointed out that directly involving locality constraint in [19] may disrupt the group structure of sparsecoefficients.Theyfurtherproposedaweightedgroupsparse representation based on classification (WGSC) by involving the influenceofthesimilaritybetweenquerysampleandeachclass.
Despite the successfulimplementation of regression-based al-gorithms in IC, there still exist the following limitations: (a) As a resultof the linear characteristics, they obtain weak classifica-tion result with uniform distribution properties, which is called normnormalizationprobleminthispaper.(b)Therisingchallenge isto seek forfeasible convex regularizations. However, it is well knownthatnon-convexapproachesmayyieldmorecompact solu-tionswithafixedresidualenergy.Todealwiththefirstlimitation, manyattemptsaretointroducedifferentmetricrepresentationsto fittheunderlyingstructureofsamples.Yangetal.[22] proposeda nuclearnorm basedmatrix regression(NMR) forIC, whichholds more structural information and performs better in the scenar-iosof block-corrupted samples.However, it still suffers fromthe normnormalizationproblem[23].Someotherworksresortto ker-neltricktoconvertlinearalgorithmsintononlinearforms,suchas KernelSRC(KSRC)[24,25],KernelCRC (KCRC)[17] andKernelGSC (KGSC)[13,26,27].Theseapproaches map theoriginal data intoa high-dimensionalfeature spaceby usinga nonlinearkernel func-tion, and then perform linear optimization in the feature space withthe inner products.It hasbeenproved that kerneltrickcan capturemorenonlinear structureoftheoriginal dataandits per-formanceisbetterthanthelinearmethods.Forthesecond limita-tion,non-convexpenaltyfunctionsareemployed,suchasthelpor l2,ppseudo-normwithp<1[28–30].
In this paper, group sparsity with data locality, kernel trick, andthenon-convexregularizationarefurtherexplored,andajoint regression-basedapproach, named kernel group sparse represen-tationvia structural and non-convexconstraint (KGSRSN) is pro-posed. The advantage of integrating all these properties is that more structural information embedded in the dictionary can be captured and then a more discriminative representation can be achieved.Comparedtotherelatedworks,thispaper
(1)Investigatestheroleofnormnormalizationstep,illuminates the reason for better performance with unit l2-norm data, andsolvesthisproblembytheaidofkerneltrick;
(2)presentsaformulationofthegroupsparsecodingasa con-vex optimizationproblemthough definedin termsof non-convexconstraint;
(3)derivesan efficientiterativeapproach,usingthealternating directionmethodofmultipliers (ADMM)andmajorization– minimization(MM),whichmonotonicallydecreasesthecost function.
The rest of this paper is organized as follows. The previous worksare introducedinSection 2.Section3 explainsthe reasons whythe kernel trick can improve classification performance and
then presentsour KGSRSN method. Section 4 reports the experi-ment resultson two popular face datasets andthe MNIST hand-writtendataset.OurconclusionsaregiveninSection5.
2. Relatedworks
Suppose that we have c classes of subjects, and let X=
[X1,X2,...,Xc]∈Rm×nbethesetoftrainingsamples,whereXi= [xi1,xi2,...,xini]∈Rm×ni isthesubsetofthetrainingsamplesfrom subjecti,xij representsthejthtrainingsamplefromtheithclass, niisthenumberoftrainingsamplesinclassi,n=
c i=1
niisthetotal samplesizeandy∈Rmrepresentsatestsample.
All representation type algorithms have similar principle, i.e. they are premised on over-complete dictionary, all the training samples are distributed in certain subspace. In other words, the testsampleycanberepresentedasalinearcombinationofX
y=X1
θ
1+X2θ
2+· · · +Xcθ
c=x11
θ
11+x12θ
12+· · · +xcncθ
cnc =Xθ
(1)
where
θ
=[θ
11,θ
12,...,θ
cnc]∈Rnisacoefficientvectorcorresponding toX.Therefore,thesparsesolutionofEq.(1) canberecovered asmin
θ
||
ψ
−Zθ
||
2
2+
λ
f(
||
η
θ
||
p)
(2)wheremeans element-wisemultiplication,
η
∈Rn isthelocality weights,ψ
andZarethetransformationofthetestsampleandthe trainingsamples,respectively,f(||θ
||p)leadstothepenaltyfunction witha lp-norm constrainedvariable, andλ
>0 is a trade-off pa-rameter.Empirically,alargerλ
leadstoasparsersolution. Accord-ingtothevariationofZ,η
andp,(2) canbe turnedintodifferent sparse representationalgorithms.When (2) is minimized, we ob-taintheresultingcoefficientvectorθ
∗.Letδi
(θ
∗)beavectorwhose onlynonzeroentriesareassociatedwithclassi.Thentheclass la-belofycanbedecidedaskthatgivestheminimumreconstruction error,i.e.,k=argmin
i
||
ψ
−Zδ
i(
θ
∗
)
||
2 (3)
2.1. Linearrepresentationclassification
TheclassicalSR-basedapproachesaredevelopedwithdifferent settingofpenalty functionsfandnormconstraintsp,byutilizing
ψ
=y,Z=X directlyandhavingnoconsiderationofweights con-straint(η
=1n).For f being the absolute function and p=1, (2) turns to the classicalSRC[7].Itscoding coefficients
θ
is sparseunderl1-norm constraintandover-complete dictionary. Suppose thetest sampley belongs to the ith subject, then all the coding coefficientswill shrinktobezeroexcept
θi
.Forfbeingthesquarefunctionandp=2,then(2) becomesthe classical CRC [8]. While the importance of sparsity is much em-phasized inSRC, Zhang et, al.[8] argued that the successofSRC isattributedto collaborativemechanismratherthansparsity. Fur-thermore,CRC hassignificantly lesscomplexitythanSRCbyusing l2-minimization. It is noteworthythat CRC is not sparse since its codingcoefficientwillnottendtoabsolutezero.
SRCandCRCare allunsupervisedlearningalgorithms, they ig-norethelabelinformationduringmodelestablishment.GSCselects afewgroupstorepresentthequerysamplebyusingl2,1-norm reg-ularizer. Setting p=2, 1 and still with the absolute function f, it uses l1-normin inter-classsampleswhile usingl2-norm in intra-class samples. Previous studies indicate that the recognition rate ofGSCissuperiortothatofSRCandCRC [12],butitsefficiencyis inferiortotheclosedsolutionofCRC.
J.Zhengetal./Neurocomputing000(2018)1–11 3
2.2. Weightedrepresentationclassification
As describedabove,SRC, CRCandGSCconstructthe classifica-tionmodelrespectivelybysparsity,collaborationandsupervision. Theyignorethelocalitystructureofthetrainingsamples.Recently, scholarshaveproposedmanylocalitypreservingmethods.Similar to the classicalones, weightedrepresentationapproachesinvolve the considerationsof
η
while keepingother termsconsistently.η
measurestheEuclideandistancebetweenthetestsamplesandthe trainingsamplesasη
i j=exp(
xi j−y22/σ
2)
(4) whereηij
denotes the jth weights fromthe ithclass, andσ
is a scalarparameter.TheweightedextensionsofSRC,CRCandGSCareweightedSRC (WSRC) [15,16], weightedCRC (WCRC) [17,18], andlocality group sparse representation(LGSR) [19], respectively. These approaches makethecodingcoefficientofremotesamplesshrinktozerowhile neighbor samples obtain larger coding coefficient, which means that they have the properties of locality and noise-resistance. In addition, WGSC [21] turns the regularization term of (2) to be
c
i=1ri
||
ηi
θi
||
2, which further include the weight factor ri for betterholdingthegroupstructure.2.3. Kernelrepresentationclassification
Kernel-basedmethodsadoptthekerneltricktomap the origi-naldataintoahigh-dimensionalfeaturespacebyusinganimplicit nonlinearmappingfunction,andthenperformlinearprocessingin this high-dimensional space with inner products. Particularly, as forSRC, CRC, andGSC,their kernelversions holdthesame regu-larizationtermbutwithyandXbeimplicitlymapped.
Inthekernelspace,
ψ
andZ areexpressedasφ
(y) and(
X)
,respectively,where
φ
(·)denotesthemappingfunctionandrep-resentsitsmatrixform.Thus,(2) canberewrittenas
min
θ
φ(
y)
−(
X)
θ
2
2+
λ
f(
θ
p)
(5)wheretheweightconstraintistemporarilyignored,i.e.set
η
=1n. Sinceφ
isunknown,(5) canbereformulatedbysomekernel func-tionsas||
φ
(
y)
−(
X)
θ
||
2 2+λ
f(
||
θ
||
p)
=(
φ
(
y)
−(
X)
θ)
T(
φ(
y)
−(
X)
θ)
+λ
f(
||
θ
||
p)
=k(
y,y)
+θ
TKθ
−2k(
•,y)
Tθ
+λ
f(
||
θ
||
p)
(6)where K=
(
X)
T(
X)
∈Rn×n is a symmetric positive semi-definite kernel matrix.ki j=k(
xi,xj)
is thegiven kernelfunction, and k(
•,y)
=[k(
x1,y)
,...,k(
xn,y)
]=(
X)
Tφ
(
y)
. There are some commonlyusedkernelfunctions,i.e.,thelinearkernel,polynomial kernelaswellasthemostfrequentlyusedGaussiankernelthatis definedask
(
xi,xj)
=exp(
−||
xi−xj||
22/2σ
2)
(7) whereσ
isatunableparameter.Integrating (7) and (4) into (2) can lead to kernel weighted version of SR-based approaches, such as Kernel WCRC (KWCRC) [17].Literature[17] and[24] demonstratethattheperformanceof kernelweightedrepresentationclassificationissuperiortothatof otherrepresentationtypeclassificationempirically.
3. Kernelgroupsparserepresentationclassifierviastructural andnon-convexconstraints
Toimprovethe weightedgroup constraintandfurtherenforce itinthekernelspace,anewnon-convexpenaltyfunctionandthe kerneltrickisadoptedtopresentajoint-sparsitySR-basedmethod,
namelykernelgroup sparserepresentationclassifier viastructural andnon-convexconstraints(KGSRSN).InKGSRSN,thelocality met-ricsare measured in the kernel space, thus the nonlinear struc-tureofinputsampleswouldbebetterexplored.Inthissection,we firstexplaintherelationshipbetweendatanormalizationand sam-ple selection, andthen present the kernel-based methodto deal withthenormnormalizationproblem.Second,wechoseaspecific non-convex constraint in parametric form, so that the complete objectivefunctionwouldbestrictly convex.Finally,wederive the optimization algorithm according to the principle of ADMM and MM.
3.1. Thenormnormalizationproblem
InthepracticalICproblems,somenormalizationsteps,suchas meannormalization[31] ornormnormalization[23],always con-ductedinadvance.Thesestepscanregulatethedistributionof in-putdataandenhancethenumericalstabilityofclassifiers,butthe consequencehasnotbeen analyzedintheory andempirically. By aconcreteexample,weinvestigatetheimpactofnorm normaliza-tiononsparserepresentationalgorithmsinthissection.
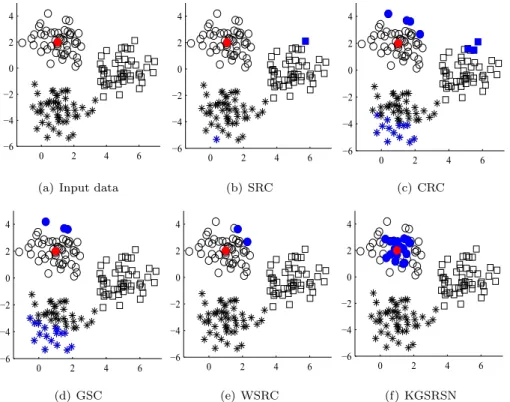
Consider the samples in Fig. 1(a) as an example, where the datasetconsistsof 150pointsfrom threeclasses. allof them are givenbystandard Gaussian distributionandwithoutany normal-ization.We choose thered dot (1, 2) asthetest sample andthe othersastrainingsamples.FromFig.1(b)and1(c),itcanbe seen thatthe selectedsamplesforrepresentingthe reddot mainly in-volves the ones from different classes, which indicates that the sparse representation has no discriminalityin thiscase. We call thisphenomenon asthenormnormalizationproblem.Thereason isthatthedatapointsinthedatasetmayhavedifferentl2-norm (orl1-norm),sothesparserepresentationofonepointmaybe in-clinedto selectthe data withlarger l2-norm ifpossible. Forthis dataset, the l2-norm of round samples, square samples and star samples,respectivelyrangefrom0.433to17.668,13.194to48.659 and 3.494 to 31.602. It is concluded that the l2-norm of square samplesandstarsamplesissignificantlyhigherthanthatofround samples.Thusthesparserepresentationofthereddotmaybe in-clinedtoselectthesquare pointsandstarpoints. InFig.1(b),the selectedsampleswithnonzerocoefficientsofSRCaremarkedwith onebluesquareandonebluestar,nottherightrounddata.It vio-latesthebasicideaofSRCthatistorepresentaquerysampleasan intra-class sparse linearcombinationof thetraining samples.For CRC andGSC,we choose the15%largestelementsoftheir repre-sentationcoefficientsforoutput,sincetheyarenotsparseinstrict significance.Although the effective samples ofCRC involve three differentkinds ofinput data, the majorityis thesquare andstar pointsinFig.1(c). InFig.1(d),GSC eliminatessquare samples by groupconstraint,butthenumberofstarpointsisstillmuchmore thanthatofroundpoints. InFig.1(e),WSRCrepresentsthequery sampleasan intra-classsparselinearcombinationofthetraining samplesbenefitingfromthepropertyoflocality.However,the se-lected representationsamples are relativelywith largerl2-norms, thenormnormalizationproblemstillexists.
To illustrate the importance of l2-norm, we further take the two-dimensionalcaseasan example.Suppose thatthere aretwo classesX1=[x1,x2,x3]andX2=[x4,x5,x6]whicharenormalized to have unit l2-norm anddistributed on a unit sphere in Fig. 2. Herex1isregardedasatestsamplewhiletherestastraining sam-ples. Denote q1 as thejunction of the linelinking x2 to x3 with theline linking x1 to the origin, anddenote b1 asthe Euclidean distancefromq1 totheorigin.Similarly,denoteq2asthejunction ofthelinelinking x2 to x4 withthe linelinkingx1 totheorigin, anddenoteb2 asthedistancefromq2 to theorigin.Assumethat
0 2 4 6 −6 −4 −2 0 2 4
(a) Input data
0 2 4 6 −6 −4 −2 0 2 4 (b) SRC 0 2 4 6 −6 −4 −2 0 2 4 (c) CRC 0 2 4 6 −6 −4 −2 0 2 4 (d) GSC 0 2 4 6 −6 −4 −2 0 2 4 (e) WSRC 0 2 4 6 −6 −4 −2 0 2 4 (f) KGSRSN
Fig.1. Representationresultsofsomenon-normalizeddatafromtypicalSR-basedmethods.(Forinterpretationofthereferencestocolorinthisfigurelegend,thereaderis referredtothewebversionofthisarticle.)
Fig.2. Theillustrationofnormnormalizationproblem.
x1canbedenotedas x1= 1 b1
(
q1)
= 1 b1(
θ
2 x2+θ
3x3)
=[x1,x2,...,x6][0,θ
b2 1 ,θ
3 b1 ,...,0]Twhere
θ
2 andθ
3 aresome positivenumbers satisfyingθ
2 +θ
3= 1. For SRC, x1=[X1X2]θ
and||
θ
||
1 = 1/b1. Similarly, if x1 can be represented as a linear combination of x2 and x4 byθ
= [0,θ
2/b2,0,θ
2/b2,0,0]T, then x1=[X1X2]θ
and||
θ
||
1 = 1/b2. From Fig. 2, it can be observed that b1>b2, hence ||θ
||1<θ
||1, whichmakesSRCselectx2 andx3 astherepresentationsamples. Inother words,whenall sampleshavethesamel2-norm,the lin-earrepresentationofatestdatawillbedeclinedtoselectneighbor pointsfromthesameclass,whichleadstothepropertyof discrim-inabilityunder the well-known assumption that intra-class sam-plesalwaysagglomeratedcloserthaninter-classsamples. Further-more,triangledatainFig.2 arenormalizedtohaveunit l1-norm. Itisobviousthatthispretreatmentcanalsoregulatethestructure ofinput data,buttheoutput dataall lie on one line[32], whichmakes q1 andq2 overlap to a single point (the yellow star), i.e., b1=b2.Therefore,l1-normhaslessdiscriminalitythanl2-norm. 3.2. Theproposedmethod
Foranydatapoint x, wehave
||
φ
(
x)
||
22=k
(
x,x)
=1 from(7), so the data pointφ
(x) naturally haveunit l2-norm. Since kernel trickcan makethe datapointsinhigh-dimensionalfeaturespace linearlyseparable, the kernel-basedsparse representation ofdata canbeareasonablestrategytosolvethenormnormalization prob-lem.From Fig.1(f),we canseethat KGSRSN obtainsthe accurate representationdatathatdistributesaroundthetestsamples.For the penalty function on the other hand, many works involved lp-norm regularizer for more compact representation. However, thisnon-convex constraintgenerallysuffers frommany numerical problems such as suboptimal local solutions, slow convergencerate,andsomeinitializationissues.Inthissection,we introduce a new penalty function formore accurate data recon-struction, while maintaining convexity ofthe total cost function. Forthispurpose,thelogarithmicpenalty[33],
f
(
x)
= log(
1+a|
x|
)
a (8)
isadopted,wherea>0isascalarparameter.
Integrate(2),(7),and (8) intoWGSC, thecost function ofour KGSRSNis min θ 1 2
||
φ(
y)
−(
X)
θ
||
2 2+λ
c i=1 ri log(
1+a||
diθi
||
2)
a (9)wherediislocalitymetric,whoseentrydij measuresthedistance betweenyandtrainingsamplexijinthekernelspaceas
di j=
||
φ(
xi j)
−φ
(
y)
||
22=
φ
(
xi j)
Tφ
(
xi j)
−2φ
(
xi j)
Tφ
(
y)
+φ
(
y)
Tφ
(
y)
=2−2k
(
xi j,y)
J.Zhengetal./Neurocomputing000(2018)1–11 5
ri is the group weight to indicate how well Xi can represent
y.Asmallerridenoteslargerprobability ofybelongingtotheith class.BylearningfromtheideaofLRC[34],ricanbedefinedas
ri=
||
φ(
y)
−(
Xi)
θ
i∗||
22 =1−2ki(
•,y)
Tθ
i∗+θ
∗i T Kiθ
∗iθ
∗ i =argmin||
φ(
y)
−(
Xi)
θ
i||
22=K−i1ki(
•,y)
(11)where Ki =
(
Xi)
T(
Xi)
∈Rni×ni is the ith kernel matrix, ki(
•,y)
=(
Xi)
Tφ
(
y)
isthekernelvectorbetweenyandthe train-ingsamplesfromtheithclass.Similaras(3),thefinaldecisionrulecanbeformulatedas k=argmin i
||
φ(
y)
−(
Xi)
δ
i(
θ
∗)
||
2 =1−2ki(
•,y)
Tθ
∗i +θ
i∗ T Kiθ
∗i (12)i.e.,theclasslabelofyisdecidedastheclasswhichgivesthe min-imumresidualerrorinthekernelfeaturespace.
Notice that the chosen kernel needs to satisfy k
(
x,y)
=c for avoidingnormnormalizationproblem,wherecisaconstant.This can be satisfied when itis an isotropic kernel k(
x,y)
=k(
x,y)
orany normalizedkernelk
(
x,y)
=k(
x,y)
/(
k(
x,x)
1/2×k(
y,y)
1/2)
. Inthispaper,weadopttheGaussiankernelinourexperiments. 3.3. OptimizationalgorithmAlthough some well-known algorithms, such as Homotopy [35] andsparse projections [36], have been deliberatively devel-opedforSR-basedapproaches,theycannotbeuseddirectlyforour method since it integratesboth locality group sparsityand non-convexpenaltyinthekernelspace.Wederiveouroptimization al-gorithm jointly under the framework of ADMM [37,38] and MM [39,40]. Theformer isefficient formostconvexcoding problems, andthelater replaces sometough problemsby simplerones. For convenience, we introduce matrix D=diag([d1, d2,. . .,dc]
)
∈Rn×n anddefineβ
=Dθ
. Then ourKGSRSN algorithm canbe rewritten as min β 1 2||
φ(
y)
−(
X)
D −1β
||
2 2+λ
c i=1 ri log(
1+a||
βi
||
2)
a =min β 1 2β
T˜ Kβ
−β
Tk˜(
•,y)
+λ
c i=1 ri log(
1+a||
βi
||
2)
a (13)Tosolve(13),wefirstdefinetheaugmentedLagrangianfunctionas Lρ
(
β
,z,μ)
=1 2β
T˜ Kβ
−β
T˜ k(
•,y)
+λ
c i=1 ri log(
1+a||
zi||
2)
a +μ
T(
β
−z)
+ρ
2β
−z 2 2 (14)where
μ
istheLagrangemultiplierandρ
> 0isapenalty param-eter.Solving(14) isequivalenttotracingthesolutions(β
∗,z∗,μ
∗) ofthesaddle-pointproblem[38]:L
(
β
∗,z∗,μ)
≤L(
β
∗,z∗,μ
∗)
≤L(
β
,z,μ
∗)
(15)Withthecomputed(orinitialized)vectorzkand
μ
k,by apply-ingtheADMMiterativeschemeto(15),theupdateofeachvariable goesasβ
k+1 ←argmin β L(
β
,z k,μ
k)
(16a) zk+1←argmin z L(
β
k+1 ,z,μ
k)
(16b)μ
k+1←μ
k+ρ
(
β
k+1 −zk+1)
(16c)Fixingzkand
μ
k,thesubproblemforβ
k+1canberewrittenas
β
k+1 ←argmin β 1 2β
T˜ Kβ
−β
T˜ k(
•,y)
+ρ
2β
−z k+μ
kρ
22 (17)wheretheconstanttermshavebeenomitted.Thefirst-order opti-mality conditionsofquadratic minimization problem(17) lead to
β
k+1=
(
K˜+ρ
I)
−1(
k˜(
•,y)
+ρ
zk−μ
k)
(18) Fixingβ
k+1 andμ
k,theupdateofzk+1isgivenbyminimizing thefollowingsubproblem:zk+1←argmin z
ρ
2z−β
k+1 −μ
kρ
22+λ
c i=1 ri log(
1+a||
zi||
2)
a (19)Solving subproblem (19) is difficult due to the involving of group constraint and non-convex logarithmic penalty. We use the MM procedure to derive a method minimizing (19). Firstly, Proposition 1 is presented tospecify a majorizerof the logarith-micfunction.
Proposition1. Thefunctionqdefinedby q
(
x,v
)
= x2 2v
(
1+av
)
+ log(
1+av
)
a −v
2(
1+av
)
(20)isamajorizerofthelogarithmicfunctionexceptforv=0,i.e., q
(
x,v
)
≥log(
1+ax)
a ,
∀
x∈R,v
∈R\{
0}
(21a)q
(
v
,v
)
=log(
1+av
)
a ,
∀
v
∈R\{
0}
(21b)Proof. (21b) canbeverifiedbyasimplesubstitution.For(21a), us-ingTalorsexpansion,weget
log
(
1+ax)
a = log(
1+av
)
a +(
x−v
)
(
1+av
)
− a(
x−v
)
2 2(
1+av
0)
2 (22)forv0betweenvandx.Sincea>0,wehave log
(
1+ax)
a ≤ log(
1+av
)
a +(
x−v
)
(
1+av
)
(23)Usingx≤x2/2
v
+v
/2,wefurtherget log(
1+ax)
a ≤ x2 2v
(
1+av
)
+ log(
1+av
)
a −v
2(
1+av
)
=q(
x,v
)
(24)whichcompletestheproof.
FromProposition1,thetotalfunction Q
(
z,zk)
=ρ
2z−β
k+1 −μ
kρ
22+λ
2 c i=1 ri zi22 zk i2(
1+azki2)
+C = c i=1ρ
2zi−β
k+1 i −μ
k iρ
22+λ
rizi22 2zk i2(
1+azki2)
+C (25)is a majorization surrogate function of subproblem (19) with C beinga constant termindependent of z. We then can obtain all
zk+1 i ,i=1,...,c,asfollows: zk+1 i =
ρ
+λ
ri zk i2(
1+azki2)
−1ρ
β
k+1 i +μ
ki (26) ThedetailsofourKGSRSNaregiveninAlgorithm1.Algorithm1 KGSRSN. Input:D,K,k
(
•,y)
,r,λ
,a,ρ
,ε
1,andε
2. Initializez=μ
=0,io=ii=0. Repeat 1.io=io+1. 2.Updateβ
by(18) Repeat 3.Initializez=β
+μ
/ρ
. 4.ii=ii+1. 5.Updatezj, j=1,2,...,c,by(26).Untilthevalueofsubploblem(19)satisfiesthat(norm(cost(ii )-cost(ii−1))/norm(cost(ii
))
<ε
26.Update
μ
by(16c).Untilnorm(
β
−z)
<ε
1Output:
θ
∗=D−1β
.3.4.Convergenceandcomplexityanalysis
The convergence properties of ADMM have been exten-sively studied [22,37,38]. Following the ideas of Ref. [38], Proposition 2 holds under the assumption that the functions of (16a) and(16b) areclosed,proper,andconvex.
Proposition2([38]). TheADMMiteratessatisfythat
(1)Residual convergence.
β
k−zk→0 as k→∞, i.e., the iterates approachfeasibility.(2)Objectiveconvergence.Thecostfunction(13) oftheiterates ap-proachestheoptimalvalue.
(3)Dualvariable convergence.
μ
k→μ
∗as k→∞,whereμ
∗ isadualoptimalpoint.
Withthefactthattheclosednessandpropernessofourcost func-tion(13) are clear,we further need to make sure that all the sub-problemsbeconvex andhaveconvergentsolutions. Itisevidentthat subproblem(17) isstrictlyconvexandwithclosed-formsolution(18) , theremainingissueforusis toprovetheconvexityandconvergence ofsubproblem(19) .Aboveall,weintroduceProposition 3 toassertthe conditionforconvexity.
Proposition3. Subproblem(19) isstrictlyconvexunderthecondition that
0<a<
λ
maxρ
(
ri
)
(27)Proof.Foranyv≥0,definefunctiong:R→Rwithparametera>0 as
g
(
v
)
=ρ
2v
2+
λ
r f(
v
)
(28)Sincethelogarithmicfunction f(v) iscontinuousandtwice differ-entiableforv≥0,theconvexityofgcanbeensured byapositive secondderivativeonv≥0.Thisleadstothecondition
g
(
v
)
=ρ
+λ
r f(
v
)
>0⇒ f(
v
)
>−ρ
/(
λ
r)
(29)Moreover,since f
(
v
)
=−a/(
1+av
)
2,andthe minimum second-orderderivativeof f(v) residesin f(
0)
=−a, wecan obtainthat−a>−
ρ
/(
λ
r)
⇒a<ρ
/(
λ
r)
(30)Basedontheconvexityof
x2,g(x2) isalsostrictlyconvex. By expandinganddecomposing(19) intoρ
2z−β
k+1 −μ
kρ
22+λ
c i=1 ri log(
1+azi2)
a =ρ
2z 2 2−ρ
2zTβ
k+1 +μ
ρ
k +λ
c i=1 ri log(
1+azi2)
a +C = c i=1 g(
zi2)
−ρ
2z Tβ
k+1 +μ
ρ
k +C, (31)we can see that it is a linear combination of g(
zi2), a con-vex termzT(
β
k+1+
μ
k/ρ
)
, anda constant termC.Hence, (19) is strictlyconvexwithcondition(27).To analyzethe convergence of zsubproblem, we first charac-terize a
δ
stronglyconvexity ofthesurrogate function Q(z,zk) in (25) asProposition 4. Then by the important property shownin Lemma1[40],wegiveconvergenceresultsforsubproblemzasin Proposition5.Proposition4. Thesurrogatefunction Q(z,zk) in (25) is
δ
strongly convex,i.e.,functionQ(
z,zk)
−0.5δ
||
z||
22isconvex,where
δ
>0. Theproofisomittedheresinceitsderivationisverysimilarasthe proofofProposition 3 .Lemma1[40]. LetJ(x):Rn→Rbea
δ
stronglyconvexfunction,andx∗ be theminimizer ofJ(x), theninequality 0.5
δ
||
x−x∗||
2 2≤J(
x)
− J(
x∗)
holdsforanyx∈Rn.Proposition 5. Denote J(z) as subproblem (19) , let
{
zk}
∞k=1 be the generatedsequencebytheinnerloopofAlgorithm 1 withanyinitial
z0,thenwehave:
(1) The sequence
{
J(
zk)
}
∞k=0 is monotonically non-increasing and convergent;
(2) The property limk→∞
||
zk−zk+1||
22=0 holds for the corre-spondingsequence{
zk}
∞k=0.
Proof. Recall Proposition 4,the surrogatefunction Q(z, zk) is a
δ
stronglyconvexmajorizerofJ(z)atzk,andzk+1 istheglobal min-imizerofQ(z,zk).Thusforanyk≥0wecanwrite:J
(
zk+1)
≤Q(
zk+1,zk)
≤Q(
zk,zk)
=J(
zk)
(32) which reveals the monotonically non-increasing property of se-quence{
J(
zk)
}
∞k=0. Notice that
{
J(
z k)
}
∞k=0 is bounded frombelow withzero,henceconvergent.
Lemma1 withQ(z,zk)inplace ofJ(x) andzk+1 inplace ofx∗
yields
δ
2||
z−zk+1
||
22≤Q
(
z,zk)
−Q(
zk+1,zk)
,∀
z∈Rn,k≥0. (33) Furthermore,(33) withzksubstitutingforzleadstoδ
2||
zk−zk+1
||
22≤Q
(
zk,zk)
−Q(
zk+1,zk)
≤J(
zk)
−J(
zk+1)
(34) Summingtheinequalities(34) overk,wethenobtain∞ k=0
||
zk−zk+1||
2 2≤ 2δ
∞ k=0(
J(
zk)
−J(
zk+1))
=2δ
(
J(
z0)
−J∗)
(35)where J∗ is the limit of the convergent sequence
{
J(
zk)
}
∞k=0 (the firststatementofProposition 5).Since that
{
J(
zk)
}
∞k=0 isa mono-tonicallynon-increasingsequenceand
δ
>0,thelasttermof(35) is afinitenon-negativenumber,whichprovestheconvergenceofthe firsttermandverifiesthepropertylimk→∞||
zk−zk+1||
22=0.J.Zhengetal./Neurocomputing000(2018)1–11 7
(a) MNIST (b) AR (c) PIE
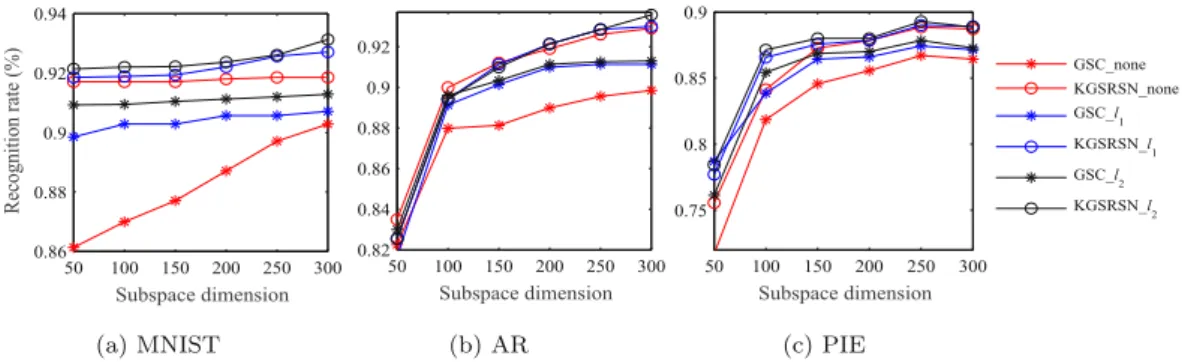
Fig.3. TherecognitionrateofGSCandKGSRSNunderdifferentnormnormalization.
ForthecomputationalcomplexityofAlgorithm1,itisclearto see that the main running time lies in updating
β
andz. Since(
K˜+ρ
I)
−1 can be computed in advance and cached offline, the complexityofperforming (18) isO(n2).Besides,withthefactthat eacchzi,i=1,...,c,canbeupdatedinparallelasin(26),thenthe complexity of z subproblem costs O(iicni). Therefore, the overall time complexityofAlgorithm1 isO(
io(
n2+iicn2i))
.Inour experi-ments,KGSRSN alwaysreachestheconvergencecondition(wesetε
1=ε
2=1e−3)withii≤10andio≤30.4. Experimentalanalysis
4.1. Datasetsandexperimentalsettings
(1) Datasets. Three real-world benchmark datasets, i.e., MNIST handwritten digits database, AR and PIE face databases, are used for evaluation. ForAR database, we use a subset [17] including100individualsforatotalof700trainingand 700testingimagesof60×43pixels.ThePIE database con-tains41368faceimagescollectedfrom68subjects.In accor-dancewithARdatabase,weselect700trainingsamplesand 700testsamplesatrandominourexperiments.ForMNIST database, we randomly select 50 training images for each ofthe 10digits fromthe trainingsetand70from thetest set. All imagesin PIE andMNIST are manually cropped to 28 × 28pixels.
(2) Formofinputdata.Ourexperimentsareconductedon orig-inal gray-valued pixels and subspace projections. For the original pixels, each image is concatenatedby its columns, and then all samples are arranged in a tandem array. For subspaceprojectionsamples,dimensionreductionmethods, including principal component analysis (PCA) and iterative nearest neighbors linear projections (INNLP)[10], are used for feature extraction.We set the regularization parameter ofINNLPtobe0.05permanently.
(3) Competing methods. The selected competing classifiers in-clude linear algorithms SRC [7], CRC [8], and GSC [12], weightedalgorithmsWSRC[16],WCRC[17],andWGSC[21], kernel-based algorithms KSRC [24], KCRC [17], KGSC [27], and KWCRC [17]. In addition, the performance of KGSRSN is also comparedwith other classical algorithms, including INNC[10],NMR[22] andKINNC[10].Intheimplementation, we adopt 5-fold cross validation to confirm optimal value of the regularization parameters. For arbitrary classifica-tion algorithms, we search
λ
from{
1e−6,1e−5,...,1e0}
,and select the highest average recognition rate as the ul-timate model parameters in different feature dimension. Withoutspecialdeclaration,inourmethodweset
ρ
=1and a=0.9ρ
/(λ
max(ri)).4.2.Thebehaviorofnormalizationandnon-convexpenalty
As described in Section 3.1, different normalization of input dataaffectsthe performance ofSR-basedapproaches.Inthis sec-tion,wetakeGSCandKGSRSNasexamplestoevaluatethe recog-nition rate versus different norm normalization on MNIST, AR and PIE databases in Fig. 3. PCA is used for feature extraction. Fig. 3 showsthe recognition rateof GSC varies greatly with the change of norm normalization, where its gap reaches 2–6% un-der different subspace dimensions. Among them, GSC-l2 reaches the highest recognition rate with l2-norm while GSC−none
per-forms poorest. Besides, KGSRSN takes advantage of kernel trick to overcomethe normalizationproblem describedin Section 3.1, so its recognition rate changes less (about 1%) under different datasets and different subspace dimensions. Overall, the experi-mentalresultsinFig.3.agreewellwiththetheoreticalanalysisin Section 3.1. Inthe following experiments,we adoptl2-norm nor-malizationforbetterrecognitionrateoflinearalgorithms.
InAlgorithm1,parameteraisusedtodeterminethedegreeof non-convexityforthelogarithmicpenalty.WithProposition3,our experimentsadopta =
τρ
/(
λ
max(ri)),τ
∈{
0.1,0.2,...,0.9}
to en-surethe overall convexity ofthe total cost function. Fig. 4 illus-tratestheroleofparametera.InFig.4 (a),aspecific parametera closerto 0 makes the penalty function closer to the classical l1 -normconstraint. Onthe otherhand,a largerτ
leadstoa deeper degreeofnon-convexity.Fig.4 (b)illustratestherecognitionrateof ourmethodversusvarious choiceofτ
inMNIST,AR,andPIE, re-spectively.We canseethat theperformance ofKGSRSN improves withtheincreasing ofτ
tosome extent. Thisempiricallyverifies thestatementthatmorenon-convexpenaltyleadstoamore com-pactrepresentation.4.3.Recognitionperformance
Inthissection,weconductclassificationonoriginal inputdata andsubspace data,respectively.Thesubspacedimension issetas l={50, 100, 150,200, 250,300}.Tables 1–3 show the recognition ratesandcorresponding dimensionon MNIST,AR,PIE,where the bestresultsarehighlightedinboldandthesecondbestresultsare highlightedinitalics.FromTables1–3,wecanseethat
(1) Considering diverse distribution of practical images, most classifiershavedifferentperformance indifferentinput fea-ture. We cannot guarantee that any classifier has over-whelming superiority, so we attempt to seek out the one thatisrelativelymorestableandmoreeffective.
(2) The recognition rate of INNC and KINNC is clearly lower thanothermethods.TakePIEdatabasewithPCAasexample, theyachieve 61.0%recognitionratewhilethelowest recog-nitionrateofotheralgorithms is64.7%.Itshowsthat near-estneighborbasedalgorithms aresuboptimalfor
classifica-Fig.4. Plotofthepenaltyfunctiondefinedin(8) andtherecognitionresultswithvariousparametervalues. Table1
RecognitionratesversusdifferentdimensionsonMNISTdatabases.
Classifier Input SubspacedimensionsfromPCA SubspacedimensionsfromINNLP
dimension 50 100 150 200 250 300 50 100 150 200 250 300 SRC 91.1 91.0 91.0 91.0 91.0 91.3 91.1 65.7 65.7 65.1 65.3 65.7 65.7 CRC 86.4 87.4 87.1 87.1 87.0 87.0 87.0 63.1 63.3 63.1 62.9 62.9 62.9 GSC 91.6 90.9 91.0 91.1 91.1 91.2 91.3 65.3 66.1 66.0 66.4 66.3 66.3 WSRC 89.7 90.9 90.6 90.4 90.7 91.1 90.9 65.7 64.9 63.6 65.3 65.0 65.1 WCRC 88.0 90.3 90.4 89.9 89.7 89.4 89.4 64.4 63.9 64.3 63.3 63.0 63.0 WGSC 91.6 91.5 91.6 91.6 91.6 91.6 91.6 65.3 66.8 66.8 67.0 67.0 67.3 INNC 91.6 91.6 91.9 91.7 91.7 91.6 91.6 65.6 64.1 66.9 65.0 65.3 65.3 NMR 85.8 87.2 87.2 87.2 87.1 87.1 87.1 63.2 62.2 63.2 63.0 63.0 63.0 KSRC 91.7 91.9 92.3 91.9 91.9 92.0 92.0 66.3 66.6 66.4 67.9 67.4 67.4 KCRC 91.7 91.7 90.6 90.0 89.3 88.3 88.5 66.7 67.9 67.1 67.9 67.3 67.4 KGSC 91.8 91.7 92.1 92.1 92.0 91.8 91.8 66.6 67.8 67.6 67.6 67.6 67.4 KWCRC 91.7 90.1 90.1 90.1 90.3 90.1 90.1 66.7 67.9 67.1 67.9 67.3 67.4 KINNC 91.5 91.4 91.4 91.6 91.4 91.6 91.6 55.4 48.1 42.3 40.1 36.7 36.1 KGSRSN 92.2 92.2 92.4 92.8 92.6 92.6 92.4 66.6 68.4 68.3 68.3 67.9 67.9 Table2
RecognitionratesversusdifferentdimensionsonARdatabase.
Classifier Input SubspacedimensionsfromPCA SubspacedimensionsfromINNLP
dimension 50 100 150 200 250 300 50 100 150 200 250 300 SRC 93.6 76.4 79.4 80.5 81.4 81.6 81.8 90.6 93.3 93.9 94.3 94.4 94.1 CRC 93.0 77.5 87.6 89.6 90.7 91.0 92.6 91.0 94.0 93.9 93.4 93.4 93.1 GSC 94.0 83.0 88.9 90.3 91.1 91.2 91.3 92.1 94.3 94.4 94.3 94.1 94.3 WSRC 92.3 81.7 88.8 90.4 91.7 92.0 92.0 89.6 93.3 95.3 94.6 94.0 93.8 WCRC 93.0 80.8 88.1 89.7 91.3 91.7 92.3 93.4 94.1 94.3 94.4 94.4 94.4 WGSC 94.0 84.0 88.9 90.4 91.3 92.1 92.4 92.3 94.3 94.4 94.4 94.2 94.3 INNC 80.1 73.3 77.3 78.0 78.8 79.0 79.5 88.8 92.6 92.9 93.0 92.9 93.0 NMR 93.2 78.0 88.0 89.0 90.8 91.0 92.4 91.2 93.8 93.6 94.5 93.4 93.2 KSRC 81.9 75.5 78.3 79.4 80.5 80.7 81.3 87.8 92.1 92.3 92.4 92.4 92.4 KCRC 93.3 82.4 88.8 90.4 91.7 91.7 91.8 92.7 93.6 93.9 93.7 93.7 93.6 KGSC 93.8 83.0 88.9 90.6 91.7 91.8 91.8 92.6 94.0 94.0 94.2 94.6 94.4 KWCRC 92.4 78.8 86.0 89.3 91.3 91.0 92.1 85.8 92.4 92.7 92.6 92.7 92.7 KINNC 80.6 74.2 77.4 78.0 79.2 79.9 80.1 83.0 84.9 76.5 75.4 73.1 62.8 KGSRSN 94.2 84.2 90.2 91.3 92.3 92.9 93.6 93.2 93.9 94.7 94.8 94.8 94.8 Table3
RecognitionratesversusdifferentdimensionsonPIEdatabase.
Classifier Input SubspacedimensionsfromPCA SubspacedimensionsfromINNLP dimension 50 100 150 200 250 300 50 100 150 200 250 300 SRC 89.0 70.7 77.4 78.4 79.6 79.6 80.6 88.6 89.7 90.7 90.4 90.9 91.1 CRC 88.0 64.7 80.1 84.9 85.9 86.4 87.6 88.4 89.4 88.7 89.0 89.1 89.0 GSC 89.0 76.1 85.4 86.9 87.0 87.9 87.3 88.7 89.4 89.6 89.6 89.7 89.9 WSRC 84.7 75.0 83.4 84.7 85.7 86.9 86.4 89.4 89.1 89.6 89.7 89.4 89.6 WCRC 87.9 66.6 79.3 83.6 85.0 85.4 85.3 89.7 89.6 89.7 89.9 90.0 90.1 WGSC 88.5 77.2 85.0 85.4 86.8 87.0 86.9 89.8 89.6 90.0 90.0 90.0 90.2 INNC 61.3 52.9 57.6 59.3 60.6 60.6 61.0 89.9 90.6 91.6 91.3 90.9 91.1 NMR 87.8 65.0 79.6 85.0 85.6 86.4 87.0 88.1 88.9 88.8 89.1 89.1 89.1 KSRC 80.6 72.3 74.1 75.7 76.1 76.4 77.1 88.4 88.9 88.7 88.7 88.1 88.6 KCRC 88.7 79.7 83.9 85.9 87.1 87.7 86.6 88.6 88.7 89.0 89.1 88.4 88.6 KGSC 88.9 76.5 85.4 86.9 87.2 87.9 87.3 89.0 89.4 89.8 88.7 88.1 88.6 KWCRC 89.0 72.6 81.6 84.0 87.3 87.6 87.0 88.6 88.7 89.0 90.0 90.0 90.0 KINNC 43.0 33.6 34.1 33.1 33.1 34.3 35.7 83.3 79.6 82.6 83.0 80.7 79.0 KGSRSN 89.9 80.0 85.1 86.9 87.9 87.9 87.7 90.8 90.7 91.9 91.7 91.6 91.7
J.Zhengetal./Neurocomputing000(2018)1–11 9
Fig.5. Theleanedcoefficientsandreconstructionresidualsoftwofailedsamples,wheretheentriesfromthetruesubjectandthemistakenlyidentifiedsubjectaremarked inredandblue,respectively.(Forinterpretationofthereferencestocolorinthisfigurelegend,thereaderisreferredtothewebversionofthisarticle.)
tioninrealworldapplicationscomparedwiththeSR-based algorithms.
(3) Amongthelinearapproaches,GSCoutperformsSRCandCRC in most scenarios. Specifically, GSC wins 3 bold values in PIE database, which ties with KGSC in the second place. This is attributed to the group constraint with supervised l2,1-norm.Interestingly,theperformanceofthematrix-based method, NMR that is developed for block corruptions, is equally matched with CRC, since that its advantages can-notbetakenintheseGaussianorLaplaciandistributeddata [23].
(4) The performance of linear representation methods can be furtherimprovedbylocalitymetricsandkernelization.From Tables 1–3, it can be seen that the recognition rates of weighted methods and kernel methods are mostly supe-rior.Particularly, whenthedimensionalityofthedatais re-ducedto150byINNLPinARdataset,WSRCachieves95.3% recognitionrate,whichoutperformsallother competing al-gorithms.
(5) By integrating all the merits of group constraint, local-ity metrics, nonlinear mapping, and non-convex penalty, KGSRSN obtains the highestrecognition rates inmost sce-narios. It achieves 92.8%, 94.8%, 91.9% recognition rate in MNIST,AR, PIE,respectively. Noticethat it maynot leadto better performance in practical applications with parts of theseproperties.InARdatabase,manyresultsfromthe ker-nel methods are poorer than those from the linear meth-ods.KGSRSNachievestheappealingperformancebenefiting fromthepropertiesofgroupconstraintandlocalitymetrics inthissituation.Similarly,theperformanceoftheweighted methods inPIE databaseexhibit littleimprovements. How-ever,ourmethodstillperformsbetterwiththepropertiesof groupconstraintandnonlinearmapping.
Tofurther improvetheperformance ofour method,Fig.5 ex-hibitstwo failedtestsinARdatabase. FromFig.5 (a),wecansee thatbothofthesetwosamplesarewithexaggeratedfacial expres-sions,whichmakes themdifficulttobe accuratelyrepresentedby theirintra-classsamples.InFig.5 (b),itisclearthatifweclassify the querysamples tothe class withthelargest coefficients, then both of these two testswill be correctlyidentified. In Fig. 5 (c), the reconstructed residuals fromthe intra-class samplesare very close tothe minimumone. Thus, the failure alsocan be avoided byamajorityvotefromseveralSR-basedmethods.However,these tricks only work forsome special samples, and cannot make an overall improvement.Byintroducingalearnedconvolutional
neu-Table4
Comparisonofrunningtimefor recogniz-ingonequerysample.
Methods elapsedtime(inseconds) MNIST AR PIE SRC 0.163 0.346 0.294 GSC 0.054 0.176 0.130 WGSC 0.062 0.180 0.140 KSRC 0.182 0.255 0.138 KGSC 0.112 0.210 0.142 KWCRC 0.027 0.047 0.051 KGSRSN 0.053 0.064 0.107
ralnetwork [41] asadeepfeatures extractor,we furtherimprove therecognitionrateofKGSRSNto98.5%and98.3%inARandPIE, respectively.Theseresultsareclosetoorevenbetterthanthedeep learningbasedmethods suchasDeepFace[42].Sinceourmethod hasmoreintuitivelearningmechanismsandcanbeindependently appliedwithlimitedsamplesize,ithaswideapplicationprospects.
4.4.Computationefficiency
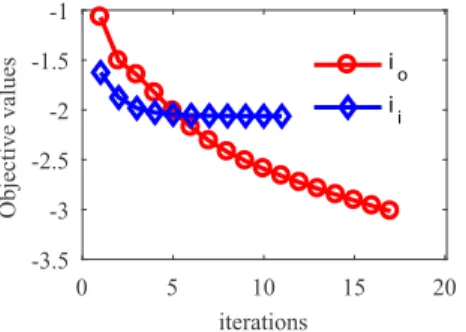
Inthissection,severalexperimentsareconductedtoverifythe efficiencyofKGSRSN incomparisonwithsixalgorithms, i.e.,SRC, GSC,WGSC, KSRC, KGSC andKWCRC. The programming platform iswithIntelCorei5CPU,2.4GHzdual-coreprocessor, 4GBRAM memory,32 bits Win7 operatingsystem andMATLAB 2014.The averageelapse time from10 runs ofrecognizing one original in-putdata foreach algorithm is illustrated inTable 4.We can ob-servethatKWCRCisthemostefficientoneamongallthe compet-ingmethodsduetotheclosed-formsolution.KSRC,whichachieves similaraccuracyasKWCRC,consumesabout3–5timesmoretime than KWCRC for recognizing one query sample. The group con-strained methods, including GSC, WGSC, KGSC, andour KGSRSN, also need iterative computations as SRC in implementation, so theircomputationalefficiencyisrelativelylowerthanKWCRC.Our KGSRSN runs faster than the other group constrained methods. This isattributed to the newly proposed optimization algorithm, whichnotonlyconsumeslittlecosts ineachupdatestep,butalso converges with few loops. Fig. 6 illustrates the convergence of KGSRSN usinga randomlyselected samplefromMNISTdatabase. For the outer loop io, the objective values of our cost function (13) decrease to below1e-3 (in log domain) within twenty iter-ations,andfortheinnerloopii,theconvergenceconditioncanbe satisfiedinaround5–10iterations.