Implementing High Performance Lexical
Analyzer using CELL Broadband Engine
Processor
P.J.SATHISH KUMAR *
Department Of Information Technology
Vel Tech Multi Tech Dr.Rangarajan Dr.Sakunthala Engineering College/Anna University Chennai, Avadi, Chennai-600062, Tamil Nadu, India.
M.RAJESH KNANNA, H.SHINE, S.ARUN
Department Of Information Technology
Vel Tech Multi Tech Dr.Rangarajan Dr.Sakunthala Engineering College/Anna University Chennai, Avadi, Chennai-600062, Tamil Nadu, India.
[email protected], [email protected], [email protected]
Abstract
The lexical analyzer is the first phase of the compiler and commonly the most time consuming. The compilation of large programs is still far from optimized in today’s compilers. With modern processors moving more towards improving parallelization and multithreading, it has become impossible for performance gains in older compilers as technology advances. Any multicore architecture relies on improving parallelism than on improving single core performance. A compiler that is completely parallel and optimized is yet to be developed and would require significant effort to create. On careful analysis we find that the performance of a compiler is majorly affected by the lexical analyzer’s scanning and tokenizing phases. This effort is directed towards the creation of a completely parallelized lexical analyzer designed to run on the Cell/B.E. processor that utilizes its multicore functionalities to achieve high performance gains in a compiler. Each SPE reads a block of data from the input and tokenizes them independently. To prevent dependence of SPE’s, a scheme for dynamically extending static block-limits is incorporated. Each SPE is given a range which it initially scans and then finalizes its input buffer to a set of complete tokens from the range dynamically. This ensures parallelization of the SPE’s independently and dynamically, with the PPE scheduling load for each SPE. The initially static assignment of the code blocks is made dynamic as soon as one SPE commits. This aids SPE load distribution and balancing. The PPE maintains the output buffer until all SPE’s of a single stage commit and move to the next stage before being written out to the file, to maintain order of execution. The approach can be extended easily to other multicore architectures as well. Tokenization is performed by high-speed string searching, with the keyword dictionary of the language, using Aho-Corasick algorithm.
Keywords Regular Expressions, Multi-core, Cell Processor, Aho-Corasick algorithm, Lexical Analyzer, Parallel Programming, Pattern matching, Compilers.
1. INTRODUCTION
2. TOKENIZER AND EXACT SET MATCHING PROBLEM
A lexical scanner [2] (scanner, for short) is piece of a software that recognizes matches of regular expressions within an input stream of symbols. We call a rule set the set of regular expressions that the scanner recognizes. When multiple overlapping substrings of the input match one or more regular expressions, only the longest of the leftmost match is accepted. All other matches that overlap it are discarded. Each regular expression in the rule set may have a semantic action that the scanner executes when the expression is matched. The same substring may match multiple rules. In flex, the first rule specified wins, and others are discarded. Scanners carry out diverse functions depending on their semantic actions. A tokenizer is a scanner whose semantic actions divide the text of an input document into words. In the Exact Set Matching Problem we locate occurrences of any pattern of a set P = {P1,…, Pk}, in target T[1,…,m]. Let n = ∑i=1to k |Pk| . Aho-Corasick algorithm (AC) is a classic solution to exact set matching. It works in time O(n + m + z), where z is number of pattern occurrences in target T which has m patterns. This algorithm is based on a refinement of a keyword tree, where a keyword tree (or a trie) for a set of patterns P is a rooted tree K such that
[1] Each edge of K is labeled by a character.
[2] Any two edges out of a node have different labels. [3] Define the label of a node v as the concatenation of edge. [4] Labels on the path from the root to v, and denote it by L(v). [5] For each Pi Є P there’s a node v with L(v) = P, and
[6] The label L(v) of any leaf v equals some Pi Є P.
3. CELL BROADBAND ENGINE ARCHITECTURE
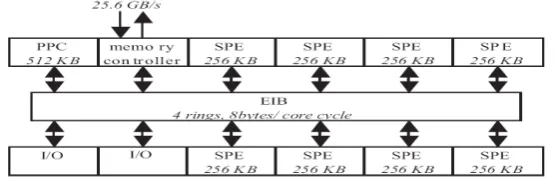
The Cell Broadband Engine (Cell/B.E.) processor [3,5] is a heterogeneous multi-core chip that is significantly different from conventional multiprocessor or multi-core architectures. It consists of a traditional microprocessor (the PPE) that controls eight SIMD co-processing units called synergistic processor elements (SPEs), a high speed memory controller, and a high bandwidth bus interface (termed the element interconnect bus, or EIB), all integrated on a single chip. Fig. 1 gives an architectural overview of the Cell/B.E. processor. The PPE runs the operating system and coordinates the SPEs. It is a 64-bit PowerPC core with a vector multimedia extension (VMX) unit, 32 KByte L1 PowerPC Processing Element(PPE) instruction and data caches, and a 512 KByte L2 cache. The PPE is a dual issue, in-order execution design, with two way simultaneous multithreading. Ideally, all the computation should be partitioned among the SPEs, and the PPE only handles the control flow. Each SPE consists of a synergistic processor unit (SPU) and a memory flow controller (MFC). The MFC includes a DMA controller, a memory management unit (MMU), a bus interface unit, and an atomic unit for synchronization with other SPUs and the PPE. [11,12]
Fig. 1. Cell Broadband Engine Architecture
The MFC supports naturally aligned transfers of 1,2,4, or 8 bytes, or a multiple of 16 bytes to a maximum of 16 KBytes. DMA list commands can request a list of up to 2,048 DMA transfers using a single MFC DMA command. Peak performance is achievable when both the effective address and the local storage address are 128 bytes aligned and the transfer is an even multiple of 128 bytes. In the Cell/B.E., each SPE can have up to 16 outstanding DMAs, for a total of 128 across the chip, allowing unprecedented levels of parallelism in on-chip communication.
4. HIGH PERFORMANCE LEXICAL ANALYZER
4.1 Dynamic Block Splitting Algorithm
In order to enable parallel tokenization by the SPEs, incorporate the dynamic block splitting algorithm to determine dynamic block limits using a static block size as shown in the fig 2. The block-size is determined by the PPE based on the size of the input source code. The delimiter used by the algorithm is the newline character. The PPE calculates the size of a single block based on the actual size of the input file. This block-size is sent to each SPE, where the actual block limits are determined. The initial block limits are set by moving the pointer from the starting of the static block to the next nearest complete token demarcated by the newline character. This is based on the fact that the tokens in C language can’t extend for multiple lines across many new line characters. A similar process extends upper block limits to the next nearest token on the static blocks to upper block limit. This causes the formation of the dynamic block which contains only complete tokens. This dynamic block is then parsed by each SPE to form complete tokens and is entered into the output file.
Fig. 2 Dynamic block splitting algorithm
For the given example the block size is given to be 100 and the initial pointer processed is represented by the thin arrow. Subsequently the following thin arrow is placed 100 characters apart. These are the lower and upper static limits for the static block. The algorithm used enables the SPE to traverse the input file from the initial static limits to the next new line character. The thick arrows on the file represent the new upper and lower pointers which correspond to the dynamic block created from the old static block. An important point to note is the variation of the dynamic-block-size to the static block-size. This difference is directly proportional to the workload difference between each SPE. A large variation in this could result in one SPE working much more than the others. It is to be noted in this example that the static block-size and the dynamic block-size do not vary widely. This is more pronounced in case of larger block-size. Thus larger programs would utilize resources more evenly than smaller ones.
4.2 Tokenizer with Aho-Corasick String Matching
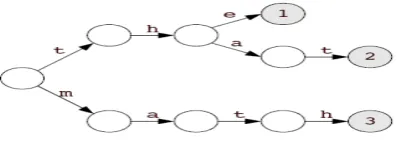
Fig. 3 The trie corresponding to example dictionary {the, that, math}
Consider a search for the string math in this trie. From the starting state the traversal would first lead to the node following the transition from the start state through the edge with m. This is followed by transitions from the subsequent states for the input character a, t and h. Since this leads us to a finite numbered state 3, we can declare the input string to be in the given dictionary. This search algorithm is highly efficient when the searching involves a large number of repeated searches on the same set of words.
Since we have a large set of keywords in any given language, it is necessary for us to repeatedly match the input strings to see if they are keywords of the given language. Thus the Aho-Corasick algorithm serves the primary purpose of keyword recognition in our lexical analyzer.
4.3 Parallel Algorithm
4.3.1 ppu algorithm
SPE_COUNT := Read no. of SPES;
BLOCK_SIZE := Calc_Block_Size ( File_len):
STATUS := False;
START: SPE[0] ->Thread (BLOCK_SIZE,SPE_ID,STATUS); /* invoke SPE-0 and pass block size
PPE_JOIN ( SPE[0] ); and SPE-ID as parameters... */
for ( i :=1 ; i< SPE_COUNT;i++) // invoke other SPEs...
{
START: SPE[ i ] -> Thread(BLOCK_SIZE,SPE_ID,START_PTR);
}
STATUS := True;
START : SPE[0] -> Thread (BLOCK_SIZE,SPE_ID,STATUS);
For ( i :=0;i<SPE_COUNT;i++);
{
PPE_JOIN (SPE [i]);
}
4.3.2 Comment removal spu algorithm
LIMIT := 7 * BLOCK_SIZE;
COUNTER := 0;
If(!STATUS)
{
while( COUNTER <LIMIT)
{
File_Write( "INTER.OUT");
COUNTER ++;
}
RETURN;
}
else
{
while( !FEOF (src_file))
{
Remove_Comments();
File_Write("INTER.OUT");
}
RETURN;
}
4.3.3 Tokenizer spu algorithm
FOWARD_PTR := Set_Pointer(START_PTR,0 );
BACKWARD_PTR:= Set_Pointer(START_PTR+BLOCK_SIZE,1);
File_Read("INTER.OUT");
Tokenize(FORWARD_PTR,BACKWARD_PTR);
File_Write("SPE_ID.txt");
RETURN;
}
5. PARALLELIZATION AND CONTROL FLOW
The overall process and control flow of the parallelized and synchronized lexical analyzer is shown in the figure 4 implemented by using cell sdk 3.1 simulator. The PPE initiates a comment line removal mechanism that removes all multiline and single line comments from the source code. The SPE dedicated for this purpose runs separately for the first n*7 characters where n is the block-size. Then the other SPE’s are also initiated and start tokenizing from their static block-sizes. This is to ensure that no comments are processed by any of the SPE’s during their first cycle. This assurance is extended throughout the lexical analysis because of the fact that all SPE’s that process tokens take much more time than the comment line processing SPE.
When the SPE’s are initialized, they determine the dynamic block-size from the static block-size and the starting pointers passed. Then the tokenization of each block occurs in the corresponding SPE after the creation of the trie corresponding to the keyword dictionary of the language. Each string is tokenized and categorized into the various token groups. The identifiers are maintained separately by the symbol table management system.
The symbol table management system maintains a list of all the identifiers in the program along with the id used for each identifier and the number of occurrences of each identifier in a stack data structure. Each time an SPE identifies an identifier, it searches for a previous entry in the symbol table stack data structure. If a previous entry is found, it increments the occurrences and exits. Else it creates a new entry for the identifier, initiates the occurrences to 1 and adds it to the top of the symbol table stack data structure.
Fig. 4 Control flow of parallelized lexical analyser
6. PERFORMANCE ANALYSIS
Fig. 5 Traditional Lexical Analyzers Vs Parallelized Lexical Analyzer
Fig. 6 Source File Size - 6033 Characters
Though a pass for removing comment lines causes a redundancy in the number of scanned lines, it is offset by the parallelized reading of the source code by the tokenizing SPEs. The first graph shows the space and time requirements for the traditional and parallel lexical analyzer. The other graphs show the difference in execution time on variation of two parameters namely the number of SPEs utilized and the size of input source file to be tokenized.
7. CONCLUSION
resource requirements of the lexical analyser by providing optimized performance in exchange for higher memory requirements. But the use of a common trie constructed from the dictionary in the PPE reduces the memory requirement. It can be extended to construct the syntax trees and intermediate code generator.
REFERENCES
[1] A.V. Aho and M. J. Corasick. Efficient string matching: an aid to bibliographic search. Communications of the ACM, 18(6):333–340,
1975.
[2] V. Paxson. flex – a fast lexical analyzer generator, 1988.
[3] A. Kahle, M. N. Day, H. P. Hofstee, C. R. Johns, T. R. Maeurer, and D. Shippy. Introduction to the Cell Multiprocessor. IBM Journal
of Research and Development, pages 589–604, July/September 2005.
[4] 4.A. D. Thurston. Parsing computer languages with an automaton compiled from a single regular expression. In O. H. Ibarra and H.-C.
Yen, editors, CIAA, volume 4094 of Lecture Notes in Computer Science, pages 285–286. Springer, 2006.
[5] Williams, S., Shalf, J., Oliker, L., Kamil, S., Husbands, P., Yelick, K.: The potential of the Cell processor for scientific computing. In:
CF 2006. Proc.3rd Conference on Computing Frontiers, pp. 9–20. ACM Press, New York (2006
[6] 6.Dictionary Matching Automata The Aho-Corasick Algorithm, 2006
[7] 7.D.P.Scarpazza, O. Villa, and F. Petrini. Peak-performance DFA-based string matching on the Cell processor. In Third Intl.
Workshop on System Management Techniques, Processes, and Services (SMTPS), held in conjunction with IPDPS, Mar. 2007.
[8] 8 D. P. Scarpazza, O. Villa, and F. Petrini. High-Speed String Searching against Large Dictionaries on the Cell/B.E. Processor. In 22nd
IEEE Intl. Parallel & Distributed Processing Symp. (IPDPS’08), Miami, Florida, Apr. 2008.
[9] 9.FIorio and J. V. Lunteren. Fast pattern matching on the Cell Broadband Engine. In 2008 Workshop on Cell Systems and
Applications (WCSA), affiliated with the 2008 Intl. Symp. On Computer Architecture (ISCA’08), Beijing, China, June 2008.
[10] 10. Scheduling complex streaming applications on the Cell Processor, Matthieu Gallet , Mathias Jacquelin , Loris Marchal : LIP
Research Report 2009
[11] 12. Villa, D. Chavarria, and K. Maschhoff. Input-independent, scalable and fast string matching on the Cray XMT. In 23nd IEEE Intl.
Parallel & Distributed Processing Symp. (IPDPS’09), 2009.
[12] 15. Daniele Paolo Scarpazza , Gregory F. Russell, High-performance regular expression scanning on the Cell/B.E. processor,