Available online:
http://edupediapublications.org/journals/index.php/IJR/
P a g e | 6 8 2 Abstract: The businesses used sharing data the place theyhave to make a contribution or they share regular interest. As per growing trade tendencies and highest used of cloud computing, the new method evolved in new stage of progress toward cloud enabled procedure. In this method based on peer to peer approach develop data sharing service in shared network. This procedure is the combo of cloud computing, databases and peer to peer based technologies in this paper, we gift expanded BestPeer, a system which give flexible data sharing services for the industrial network functions in the cloud based on BestPeer a peer-to-peer (P2P) based data administration platform. Through Combining cloud computing, database, and P2P technology, improved BestPeer achieves its query processing efficiency in a pay-as-you-go manner. We overview improved BestPeer on Amazon EC2 Cloud platform.
Key Words : Peer-to-peer systems, cloud computing, MapReduce, query processing, index
I. INTRODUCTION
A manufacturer creates its own website and shares a part of its business data with others which include give chain networks equivalent to provider, manufacturer, and retailer who co-operate with every other to obtain their ambitions similar to industry planning, decreasing construction cost, constructing business systems and marketing options. Settling on proper data sharing platform may be very main challenge for sharing network. Mostly, centralized data similar to data warehouse is used for data sharing, which extracts data from the internal construction methods (e.g., ERP) of each manufacturer for following querying. Without a doubt this data warehouse having some defciency akin to , First, the percentage data network desires to scope as much as support hundreds of thousands of contributors. Second, firms need to completely alter the access control rule to examine which business partners can see which part of their shared data. Most of them failed to overcome such trouble.
At final to broaden the revenue; firms may just alternate their industry partners. For this reason, the participants may become a member of and go away the share networks at get to the bottom of . This obstacle can't be handled by physical data warehouse, to overcome such crisis this designs the system for Shared network for data sharing. This approach is the blend of cloud computing, databases and peer to look situated technologies. This procedure offers the effciency as pay as you go method. To address the aforementioned issues, this paper grants BestPeer++, a cloud enabled data sharing platform designed for company network applications. Through integrating cloud computing, database, and peer-to-peer (P2P) technologies, BestPeer++ achieves its question processing effciency and is a promising technique for company network purposes, with the following exceptional aspects. BestPeer++ is deployed as a provider within the cloud. To type a corporate network, businesses conveniently register their websites with the BestPeer++ service provider, launch BestPeer++ occasions within the cloud and fnally export data to these occasions for sharing. BestPeer++ adopts the payas -you-go business model popularized through cloud computing [9]. The complete cost of ownership is thus notably diminished due to the fact that firms don't have got to buy any hardware/application in advance. Rather, they pay for what they use in terms of BestPeer++ illustration’s hours and storage capability. BestPeer++ extends the position-based
access controlfor the inherent distributed
atmosphere of corporate networks. Through an online console interface, organizations can quite simply confgure their access control policies and preclude undesired business partners to entry their shared data. BestPeer++ employs P2P technology to retrieve data between industry partners. BestPeer++ situations are prepared as a structured P2P overlay community named BATON. The data
A Peer-To-Peer based Large-Scale Data processing Using MapReduce
A lle A n il
M.Tech, Software Engineering
Balaji In s titu te o f Tech n o lo g y & Scien ce,W aran g al. Sy ed A b d u l M o eed
Assistant Professor, Department of CSE
Available online:
http://edupediapublications.org/journals/index.php/IJR/
P a g e | 6 8 3 are indexed via the desk title, column title and datavariety for effcient retrieval. BestPeer++ employs a hybrid design for reaching high performance question processing. The most important workload of a company network is simple, low overhead queries. Such queries in most cases simplest involve querying an extraordinarily small number of business partners and can also be processed in brief time. Best-Peer++ is in general optimized for these queries. For infrequent time drinking analytical duties, we furnish an interface for exporting the data from best- Peer++ to Hadoop and allow clients to research these data making use of Map.
II. RELA TED W ORKS
To enhance the usability of conventional peer to peer techniques database communities have proposed a series of PDBMS (Peer-to-Peer Database manage system) through integrating the database procedures into the P2P methods. There are a lot of methods proposed in an effort to effectually approach enormous scale data which has explained under: [1] S. Wu and J. Li have proposed “Just-in-Time Query Retrieval over Partially Indexed Data on Structured P2P Overlays” Proc. ACM SIGMOD Int’l Conf. Management of data (SIGMOD ’08), pp. 279-290, 2008.
It's a Peer-to-Peer based system that helps to Index the chosen content for effective Search. It is not like traditional approache that indexes all data and PISCES identifies a subset of tuples to index centered on some criteria. An extra most important addition to it is a coarse-grained range index which is used to facilitate the processing of queries that can't be thoroughly answered by the tuple-level index. The important challenge is it in all likelihood requires excessive renovation cost to keep the structure.
[2] K.-L. Tan and A. Zhou provided “PeerDB: A P2P-based procedure for disbursed data Sharing,” Proc. Nineteenth Int’l Conf. Information Eng., pp. 633-644, 2003. PeerDB is a peer to look established database administration method which employs expertise retrieval technique to check columns of one of a kind tables. The fundamental obstacle of unstructured PDBMS is that there is no
warranty for the data retrieval performance and it provides negative pleasant of effect.
[3] S. Jiang and B.C. Ooi have proposed “distributed online Aggregation,” Proc. VLDB Endowment, vol. 2, no. 1, pp. 443- 454, 2009. In this paper, the on- line aggregation procedure multiplied to a distributed context the place sites are maintained in distributed Hash table (DHT) network. Disbursed online Aggregation (DOA)
scheme works iteratively and produces
approximate aggregate answers as follows: In each and every generation small set of random samples are fetched from the data web sites and disbursed to the processing sites. At every processing website, regional mixture is computed based on the previously allocated samples. At a coordinator website online, these regional aggregates are combined into a worldwide aggregate for extra processing. [4] A. Lakshman and A. Pilchin “Dynamo: Amazon’s extremely to be had Key-worth retailer” Proc. Twenty first ACM SIGOPS Symp .Working systems principles (SOSP ’07), pp.
205-220, 2007. This paper presents the
implementation of Dynamo, which is a particularly available key-price storage system that some of Amazon’s core offerings use to furnish an continually-on experience. The fundamental factor right here is that it makes large use of utility-assisted conflict decision and object versioning in a manner that presents a novel interface for builders to make use.
III. SYSTEM A RCHITECTURE
Available online:
http://edupediapublications.org/journals/index.php/IJR/
P a g e | 6 8 4 BestPeer is situated on our decade's research onP2P database approach, and offers an accelerate data processing engine and a extra bendy portability via the approval of MapReduce
framework and software-as-a-service(SaaS)
paradigm.
Fig.1: The Extended BestPeer network deployed on Amazon Cloud Offering
In evaluate to the “Hadoop Connector” strategy employed via many MPP investigative database vendor, extended BestPeer makes use of Hadoop as the parallelization layer to make feasible its common query processing, with each and every node walking a database social gathering.[5] consolidate predictable database query processing and MapReduce into a single platform notably reduces TCO, do away with performance bottleneck from each mechanism, and allows for for richer analytics by means of expenditure of exclusive data forms.
Moreover, improved BestPeer’s mixed structure and supple schema capabilities diminish the complexities related to rising analytic use cases –
including graph analysis, clustering, and
classification – whilst drastically developing show and extent. Explicitly, increased BestPeer is installation as a provider in the cloud. To kind a corporate network, businesses register with the web site accelerated BestPeer service provider, provoke improved BestPeer instances in the cloud and at last export data to these circumstances for sharing. Increased BestPeer adopt the pay-as-you-go industry model popularized by cloud computing.
The total cost of possession is consequently greatly summary at the same time companies do not have to purchase any hardware/software in transfer on. The accelerated BestPeer service provider elastically develop up the going for walks
illustration and makes them continuously to be had. For occasional sustained analytical duties, we furnish an border for exporting the data from extended BestPeer to Hadoop and allow users to
investigate those data making use of
MapReduce.[3] extended BestPeer additionally inherit its predecessor's quality variety equivalent to support for semi-computerized schema mapping and data mapping, good-organized dispersed query processing, successful process load balancing and different functionalities that a corporate network requires. By using combining cloud computing, database, and peer-to-peer (P2P) technologies[8].
A. Co mp o n en t o f Pro p o s e Sy s tem Extended BestPeer, a cloud enabled evolution of BestPeer.In the final stage of its progress, exetended BestPeer is extended with dispens ed access control, a couple of types of indexes, and pay-as-you-go question processing for provide elastic data sharing offerings in the cloud.[6] The application accessories of extended BestPeer are separated into two elements: core and adapter. The structure is shown in fig.1. The core comprises all the knowledge sharing functionalities and is deliberate to be platform independent.
A lg orithm In p u t: Querry Q
Ou tp u t: Querry configurationon a specific querry engine.
TableSet S←TableParser (Q); Cost Cmin←MAX_VALUE; QuerryPlan Target ← null; Querry PlanSet QS←Ø; Foreach Table T€S do {
GraphSet GS=GraphGen(T); }
Foreach Graph G €GS do {
Querry Plan P1=P2PlanGen(G); Querry Plan P2=MapredPlanGen(G); QS=QS {P1};
QS=QS {P2}; }
Available online:
http://edupediapublications.org/journals/index.php/IJR/
P a g e | 6 8 5 Target=P;return Target;
The adapter includes one abstract adapter which defines the elastic transportation service interface and a collection of actual adapter components which implement such an interface through APIs offered by means of precise cloud service providers (e.g., Amazon). To acquire portability we developed “two level” design. With correct adapters, accelerated BestPeer may also be portable to any cloud environments (public and personal) and even non-cloud environment (e.g., on-premise data middle). We've implemented an adapter for Amazon cloud platform. In what follows, we first gift this adapter after which describe the core
accessories[6]. Exceptionally, highlights of
extended BestPeer are:
A )A mazon Cloud Ad ap ter: The main procedure of increased BestPeer is to use committed database servers to store data for each and every bussiness and arrange those database servers by means of P2P network for data sharing. The Amazon Cloud Adapter provides an elastic hardware infrastructure for multiplied BestPeer to function on by means of utilising Amazon Cloud services.
B)Th e in creas ed Bes tPeer Co re : The elevated BestPeer core contains all platform-unbiased logic, including query processing and P2P overlay. It runs on prime of adapter and consists of two program add-ons: bootstrap peer and natural peer.
• The bootstrap peer is run by way of the accelerated BestPeer service provider and most important functionality is to control the expanded BestPeer network of bootstrap peer.
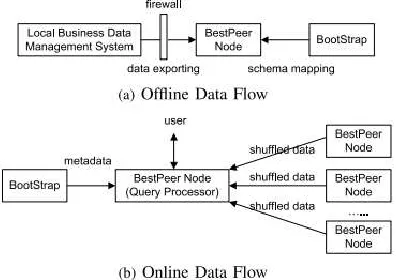
• The natural peer program having 5 components such as schema mapping, data loader, data indexer, access manipulate and query executor. As shown in Fig.2, it define two data flows inside the normal peer as an offline data go with the flow and a web-based data flow. The data are extract periodically through an data loader from the industry creation procedure to the ordinary peer illustration in offline data drift.
Fig. 2. Data Flow in BestPeer++.
Available online:
http://edupediapublications.org/journals/index.php/IJR/
P a g e | 6 8 6 every benchmark question three instances and filethe normal execution time.
The benchmark is performed on cluster sizes of 10, 20, 50 nodes. For the BestPeer++ system, these nodes are traditional friends. We launch one other committed node as the bootstrap peer. For HadoopDB approach, every launched cluster node acts as a worker node which hosts a Hadoop challenge tracker node and a PostgreSQL database server instance. We additionally use a dedicated node as the Hadoop job tracker node and HDFS identify node. 6.1.2 BestPeer++ Settings The confguration of a BestPeer++ ordinary peer consistsof two elements: the underlying MySQL database server and the BestPeer++ program.
IV. CONCLUSION
This paper define distinguished challenges pose by means of contribution and open-exceeded out data in an inter-businesses environment and planned accelerated BestPeer, a method which provide elastic data sharing services, by Containing cloud
computing, database, and peer-to-peer
technologies. The normal conducted on Amazon EC2 cloud platform shows that our method can powerfully handle common workloads in a corporate network and might transfer near linear question throughput as the quantity of average friends grows. Thus, extended BestPeer is satisfactory resolution for competent data sharing within corporate networks.
REFERENCES
[1] I. Tatarinov, Z.G. Ives, J. Madhavan, A.Y. Halevy, D. Suciu, N.N.Dalvi, X. Dong, Y. Kadiyska, G. Miklau, and P. Mork, “The PiazzaPeer Data Management Project,” SIGMOD Record, vol. 32, no. 3,pp. 47-52, 2003.
[2] W.S. Ng, B.C. Ooi, K.-L. Tan, and A. Zhou, “PeerDB: A P2P-Based System for Distributed Data Sharing,” Proc. 19th Int’l Conf. Data Eng., pp. 633-644,
2003.
[3] R. Huebsch, J.M. Hellerstein, N. Lanham, B.T. Loo, S. Shenker, and I. Stoica, “Querying the Internet with PIER,” Proc. 29th Int’l Conf. Very Large Data Bases, pp. 321-332, 2003.
[4] Saepio Technologies Inc., “The Enterprise Marketing management Strategy Guide,” White Paper, 2010.
[5] S. Wu, J. Li, B.C. Ooi, and K.-L. Tan, “Just-in-Time Query Retrieval over Partially Indexed Data on Structured P2P Overlays,” Proc. ACM SIGMOD Int’l Conf. Management of Data (SIGMOD ’08), pp. 279- 290, 2008.
[6] S. Wu, Q.H. Vu, J. Li, and K.-L. Tan, “Adaptive MultiJoin Query Processing in PDBMS,” Proc. IEEE Int’l Conf. Data Eng. (ICDE ’09), pp. 1239-1242, 2009.
[7] Beng Chin Ooi, Yanfeng Shu, “Relational Data Sharing in Peer-based Data Management Systems.” Kian-Lee Tan Sigmod Record special issue on P2P, 2003.
[8] B.C. Ooi, K.L. Tan, A.Y. Zhou, C.H. Goh, Y.G. Li, C.Y. Liau, B. Ling, W.S. Ng, Y.F. Shu, X.Y. Wang, M. Zhang ” PeerDB: Peering into Personal Databases.” The 2003 ACM SIGMOD Intl. Conf. on Management of Data (Demo). (SIGMOD 2003).
[9] G. Chen, H. T. Vo, S. Wu, B. C. Ooi, T. “A Framework for Supporting DBMS-like Indexes in the Cloud.” Ozsu VLDB 2011.
[10] Sai Wu, Dawei Jiang, Beng Chin Ooi, Kun Lun Wu” Efficient B+-tree Based Indexing for Cloud Data Processing VLDB 2010.
[11] Heng Tao Shen, Yanfeng Shu, and Bei Yu IEEE Trans. Knowl. “Efficient Semantic-Based Content Search in P2P Network.” Data Eng. 16(7): 813-826 (2004)
A u th o r’s Pro file
A lle A n il pursing M.Tech in Software Engineering from Balaji In s titu te o f Tech n o lo g y & Scien ce,W aran g al.
Sy ed Abdul Moeed working as Assistant professor,