DOI: Abstr decis differ tweet tweet Diric proje Prim Keyw 1. IN T tende term usua using cease Late demo was Jana demo Nove along the 5 were canc depo norm T the unaw medi upsu faced phas T to th forum U.S. emer 08th Nare curre high excit : http://dx.doi.
A PRAG
BAS
Sreenidhiract: Demoneti
sion to phase o rent sentiments ts related to de ts are downloa chlet Allocation ect the clear view
e Minister’s spe
words: Demone
NTRODUCTI
The currency er and is dec med as demon ally appears to g its counter ed the curren r, India on 1 onetization ph
the decision ata Party and onetized bank ember 2016. g with the Go 500 and 1,000 e given a per celled currency osit them into ms.
The decision citizens in wareness of th ia, both print urge in express
d by them and se.
Twitter – a po he public wher ms. Apart fro Election, P rged as widely
November, endra Modi a ency notes o hest denomina ted twitter u
.org/10.26483/
Interna
GMATIC
SED ON
Doddi S Departmen Institute of Sc Hyderabaisation move ha out the two mo s among the var emonetisation m aded, preproces
n (LDA) is con w of the citizen eech addressed
etisation; Topic
ION
note of a na lared as ceas netisation. The
o counter the i rfeits. The In
cy notes 1,00 6 January 19 hase of 1,000 imposed by t its coalition. knotes of 500 The premie overnor, RBI, 0 rupee notes riod of fifty d
y notes to new their account
of demonetiz India and e he people. It w
t and televisi sing the publi d the advantag
opular social m re the topics o om many oth okemonGo, t y expressed g 2016, the P announced th of rupees 500
ations in Indi sers took to
/ijarcs.v9i1.527
Volu
ational Jou
Av
TEXT M
TOPIC M
Srilathant of CSE cience and Te ad, India
as been the mos ost high valued rious sects of th move and the s ssed to remove nstructed. The ns’ and especial to the nation o
Model; Twitter
ation that was ed in lieu of e need of the ill-effects face ndian Governm 00 and 10,000 978 also witne
0, 5,000 and 1 the then rulin
Indian govern and 1000 rup r of the Ind
has taken the as legal tende days to eithe w Rs.500 and ts in banks w
zation caused elsewhere as was largely ref on. The inter c opinions ab ges of the pos
media giant, g of significance her topics like the demoneti global topic. O
Prime Minist e daring deci 0 and 1000 ia, till then. P
social media
71
ume 9, No.
urnal of Ad
C
vailable On
MINING A
MODEL A
chnology
st trending topic d denomination he people in the speech contents
the noise like LDA model au lly the public le
n new year eve
r; Text mining;
s used as a le f its substitut e demonetizat
ed by a nation ment has ear 0 rupees in 19 essed the sec 10,000 rupees ng governmen
nment had ag pees right from dian Governm e decision to c er and the peo r exchange th Rs.2000 note with the stipula
a furore am s it caught flected among
rnet also saw out the hardsh st demonetizat
gave the platfo e are discussed e Rio Olymp ization was a On the evening er of India ision to ban
which were Post speech, a to opine th
1, January
dvanced Re
CASE STUD
nline at ww
ANALYSI
AND TW
c on the twitter ns of Rupees 5 e society. It cau s that were deli re-tweets, ana utomatically di eaders’ opinions ent, although few
Latent Dirichle egal e is tion n in rlier 946. ond s. It t of gain m 8 ment curb ople heir s or ated ong the the w an hips tion orm d in pics, also g of Mr. the the the heir vie wh exc imp we goi the aff the As hou con con exp con Th pre col dis sec twi 2. L net var wit pla me ser ma con wil twe
y-February
esearch in C
DY
ww.ijarcs.in
IS OF DE
WITTER C
Sreenidh
during the rece 500 and 1000 c used sensation ivered by the p alyzed using fre
scovered the m s on this move. w opined the be
et Allocation
ews. Most of ho faced th
changing thei pacted billion ere stranded c ing berserk. M e normal pub fected sects lik eir views abou s such, Indian
urs, and mill ntinues to rev ns of the curr perts as well nversation on In this paper he section II eprocessing.
llected and are scusses the an ction V, conc
itter data.
LITERATUR
Twitter, is a tworking serv rious subjects thin the 140 c acing the # in essage or at t rvice, hashtag akes it easier ntent or theme ll defer each eets collected
y 2018
Computer
nfo
EMONET
COMMUN
Shirish Departm hi Institute of Hyderaent months. Ind currency notes in the whole co premier of the
equency analys most relevant to The most of th enefits of demo
the opinions he challenges
ir cancelled n ns of Indians,
cashless and Many others, lic and the b ke foreign nat ut the demon ns tweeted 6. lions more in verberate with rency ban. Th l as the com Indian Demo r, the section I I is focused In this secti e readied for t nalysis and the
clusions are m
RE SURVEY
a micro-blogg vice, for com s. The users characters. Us n front of a w
the end [1]. I (#) is a type for users to e or event dis
message that d are to be pre
Science
ISSN NTISATION
NICATIO
a Kakarla
ment of CSE Science and T abad, India
dian governmen . This decision ountry. In this p country. The si sis and a topic opics. Further c he topics were r onetisation.
expressed w s and sever notes to new
in the harsh w the usual eco who were dir banking secto tionals and org netization effe
.5 lakhs twee n the followi
h their belief he scale of th mmon people onetization eff
II presents the d on data c ion the signi the investigati e findings der made from th
Y
ging online pl mmunicating a can tweet a sers use and word either in
In Twitter or of metadata t
find messag scussed. Searc
t has been ta eprocessed an
No. 0976-569
N MOVE
ONS
Technology
nt had taken a su n was observed
paper, we consi ignificant numb model using L clustering is do related to critici
were of the In re discomfor
notes. The m ways as the p onomic ecosy rectly affected r or the indir ganizations sp ect on the Tw ets within nex ng days. Tw fs on the pros
ese debates b driving a g fects on Twitte Literature Su ollection and ificant tweets ion. The sectio rived thereaft he findings o
latform and s and discussin about any su create hashtag
the main text r any social m
tag or label w es with a spe ching for a ha agged with it nd analyzed fu
to de analy T text in a facil mod the u an un havin mini num work Unig Pach Sem (LDA struc any word T rang Ram of th that topic A. I (LDA Blei non-appr text Ever form relat the l word frequ parti unstr the f class are t show B. N i) discr base then ii (w1,
sequ ii = {w iv distr T
erive a seman ysis is perform Topic models
mining to dis a collection itates the iden dels [3] are pri
unstructured c nstructured da ng web page ing techniques mber of topic
ked out and el grams (MU) hinko Allocat mantic Indexin A), which as ctures on the given topic t ds or its synon Topic model t e of areas inc mage et al. [4]
he mathematic allow the use cs in the collec
Latent Diri
n this paper, A) as one of t et al. [2][3]. -supervised tec roach. The LD
corpus by d ry document c m of groups, w
ed words. The latent semanti ds of the cor uently occurri icularly useful ructured and n first things tha sifying the wo the subjects. wn in Fig. 1.
Notation and
). A word w rete data. For
d vector. If w wi=1 and wj =
i). A documen w2, w3, . . .
uence. ii). A corpus i w1, w2 ,w3, . . .
v). A topic z ibution over th
Topic model
ntic conclusio med by using a [2][3] are a ty scover the abs of document ntification of t imary tools to content. As the
ata, differs fro es, citation ne s does not pro modeling te laborately dev model, Laten tion Model ng (PLSI) and
ssists in unco contextual in to be analyze nyms/substitut techniques ar cluding recent . The outcom cal models and er to draw con cted informati
ichlet Allocati
, we use the the topic mode
The LDA m chnique with DA is used fo discovering la conceals few la whereas each
e key approach ically structur rpus. This is ing group of l in the given no idea how th
at one can do ords in the cor The pictorial
d Terminology
{1, 2, 3,. . cleaner notati w takes on the =0 for all j ≠i. nt is a sequenc . , wN), wher
is a collection , wM}.
z {1, 2, 3 he vocabulary
is a partic
on on the tren any of the top ype of statistic stract "topics"
ts, called co the patterns in o identify laten e social media om some stan etwork, etc, t ovide appropr echniques tha veloped are na
nt Semantic (PAM), Prob d Latent Diri overing the nformation. G ed, one may tes to be repea re therefore h t work on Tw mes are represe d the clusters nclusions of t ion.
ion
e Latent Diri els. This was model [3] is co probabilistic a or modeling la atent hidden atent semantic group is a co h used in the L red informatio
performed by words in the n situation wh he data are int o is to generat rpus and to ge l representatio
y
. , V} is the m ion, w is a V-d i th element in
.
ce of N words re wn is the
of M docume
3, . . . , K} y of V words.
cular groups
nding topic. T pic models.
cal model used that may app orpus. This a n a corpus. To nt text pattern
a content, larg dard text dom the standard t riate outcomes at were recen amely, Mixture Indexing (L babilistic Lat ichlet Allocat hidden seman Given a corpus
expect particu ated often. helpful in a w witter, done by ented in the fo of similar wo the trending s
ichlet Allocat first proposed onsidered to b and the statist arge unstructu
semantic top c structures in ollection of in LDA is to ext on in the form
y identifying corpus. LDA here the corpu
terrelated. One te a near idea enerate the top on of LDA [5
most basic uni dimensional u n the vocabul
s denoted by W nth word in
ents denoted b
is a probabi
of words The d in pear also opic ns in gely main text s. A ntly e of SI), tent tion ntic s of ular wide y D. orm ords sub-tion d by be a tical ured pics. n the nter-tract m of the A is us is e of a by pics 5] is it of unit-ary, W = the y D ility that com and zN)
doc C. cer bas con and lea wh a c as doc ana 3. D twi tot pos min Th I I d mmonly occu d thus can be ) denotes the
cument.
Figure
Where K - tota
k - top
D - tota
d - per
N - tot should Zd,n - pe
Wd,n- ob
- d
Generative
In order to d rtain model o sically input ntaining the w d remained ex ads to docum here each term collection, wit
term-docume cument-term alyzed as follo
DATA AND
The input da itter social ne al of ten thou sted in the tw nister address he civilians an
I. Decide what II. For each do a) Decide w document,
b) For each w i. Cho ii. Giv
(ge
ur collectively understand as e sequence of
1. Graphical R
al number of t pic distribution
al number of d r document pr tal number of
be Nd)
er-word topic bserved word dirichlet param
e Process of L
derive topics f of how docu tted with th words. The ord xchangeable w ments’ repres m is indexed w
th its correspo ent matrix (a matrix). LDA ows:
METHODO
ata for this stu etwork using t
usand tweets witter commu sed the nation nd the public
t words are lik ocument in the what proportio
word, oose a topic,
ven this top enerated in ste
in text docum s “topics” and
f topics acro
Representatio
topics n over the voc documents roportions f words in do
assignment d
meters
LDA
from a corpus uments are g he collection der of the wo with contextu sentation as with respectiv onding frequen and sometime A’s generative LOGY
udy have bee the handler: # have been c unication, soo
n on the dem figures had to kely appear fo e corpus, ons of topics s
pic, choose ep I).
ments in a co d z = (z1 , z2 ,
ss all words
n of LDA
cabulary
ocument (in fa
s one has to h generated. LD
n of docum ords is insignif ual synonyms.
the bag-of-w e document w ncy. This is te es also referre e model [5] ca
en pooled from #demonetisatio collected that on after the p monetisation m o accept this m or each topic.
should be in t
with the mixed emotions and were reflected well in the virtual social communications. With this unexpected and immediate decision by the beaurocrats, came the newly framed regulations which have taken the nation by surprise in understanding these new guidelines and following them in the nook and corner of the Indian landscapes.
For the purpose of gathering the tweets, the API Authentication of R studio tool [6] is used. R Studio is a tool for statistical data modeling and widely used by data miners to study and analyze the large scale datasets. In this study of tweets related to demonetisation move, text mining is done using the following libraries like “tm”, “twitter”, “topic models”, wordcloud etc. After collection of the tweets, the cleansing is done for removing nonesse-ntial characters such as web addresses, punctuation marks, hashtags, retweets, user handles, html links, time stamps, numbers and special characters, etc. Post cleanup a corpus of tweets devoid of unneeded data is obtained.
The efficacy of cleansing (pre-processing) procedure used is observed by plotting the word cloud. The frequently appearing terms in the tweets in the preprocessed corpus can be viewed in the wordcloud shown in the Fig. 2.
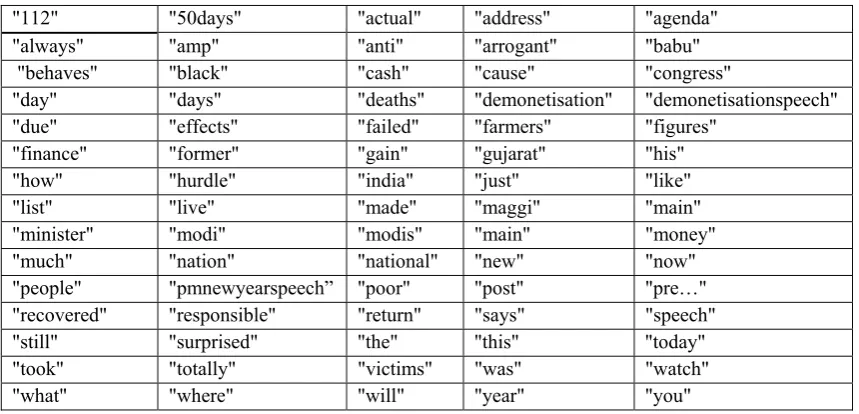
[image:3.595.325.546.112.277.2]Post this, a term-document matrix is created depicting the most tweeted words upfront. Here, some of the top most frequent key terms are shown in the Table 1 in a row wise manner.
Figure 2. Plot of Word Cloud for the Demonetisation Move Tweets
Table 1. Frequent Key Terms Appearing in Tweets Related to Demonetisation Move
"112" "50days" "actual" "address" "agenda" "always" "amp" "anti" "arrogant" "babu" "behaves" "black" "cash" "cause" "congress"
"day" "days" "deaths" "demonetisation" "demonetisationspeech" "due" "effects" "failed" "farmers" "figures"
"finance" "former" "gain" "gujarat" "his" "how" "hurdle" "india" "just" "like" "list" "live" "made" "maggi" "main"
"minister" "modi" "modis" "main" "money" "much" "nation" "national" "new" "now" "people" "pmnewyearspeech” "poor" "post" "pre…" "recovered" "responsible" "return" "says" "speech" "still" "surprised" "the" "this" "today" "took" "totally" "victims" "was" "watch" "what" "where" "will" "year" "you"
4. ANALYSIS AND FINDINGS
Term Document Matrix creation helped in finding term’s frequency and association between terms using correlation. This had been helpful in conducting hierarchical clustering analysis using Ward method.
The widely popular technique used in the text corpus mining is the cluster analysis. Out of the numerous techniques used for clustering, the hierarchical clustering is the most used one and is done here using the Ward’s method. Although a dendrogram is outputted and shown in the Fig. 3, which is suitable for browsing, it usually suffers from efficiency problems. This is due to the fact that it does not provide complete analysis as some of indexed words do not help in further analysis and no major value addition is guaranteed towards topic modeling. In the dendrogram the right most cluster having the words (modi, amp, new, year, modispeech, and will) is considered insignificant and ignored. The remaining clusters with the bag-of-words in
each make sense and the same resulted in the frequency analysis.
Latent Dirichlet Allocation (LDA) as taken as one of the topic modeling techniques. For proceeding, a document-term matrix is created by removing the sparse document-terms with the threshold value set at 0.98, and parameters: row sums greater than zero and selection of ten topics.
Identification of frequent terms in the tweets, highlights the some of the keywords based on frequency and a look at the some of the top words (shown in the Table 1) will be related to Prime Minister Narendra Modi speech addressed the nation on new year event.
To further enhance the analysis and understanding, topic models using Latent Dirichlet Allocation (Gibbs Method) was conducted on the corpus of documents. The LDA topic model was run with 10 topics as criteria and the output was highlighted in the Table 2.
[image:3.595.56.486.346.553.2]Topic 1
"demonet isation"
"india"
"his"
"people"
"was"
"modi"
"speech"
"says"
"modispe ech"
"amp"
"pmnewy earspeech "actual"
"agenda"
"the"
"cause"
Figur
Table 2.
Topic 2 T
"nation"
"money"
"what"
"how"
"much"
"black"
"50days"
"recovere d"
"figures"
"gain"
"where"
"effects"
"day"
"list"
"speech"
re 3. Data Vis
. Results of To
Topic 3 T
"demoneti sation"
"cash"
"congress" "
"effects"
"failed"
"return" "
"days"
"still" "
"modispee ch"
"
"much" "
"watch" "
"figures"
"new" "
"anti"
"day" "t
sualization usi
opic models u
Topic 4 Top
"post" "l
"just" "t
"money" "a
"black" "nat
"made" "gu
agenda" "alw
"took" "m
minister " "hu "finance
" "fo
"deviate d" "m
"actual" "beh
"amp" "pe
"pre…" "sp
"will" "n
demone tisation" "g
ing Hierarchi
using Latent D
pic 5 Topi
like" "demsatio
this" "mo
anti" "say
tional" "peo
ujarat" "ind
ways" "liv
main" earsp"pmn " urdle" "farm
rmer" "effe
maggi" "spee
haves" "cong " eople" "da
peech" "wi
new" "day
gain" "ye
cal Clustering
Dirichlet Alloc
ic 6 Topic
oneti
on" "will
odi" "modisech"
ys" "today
ople" "addre
dia" "watch
ve" "demon isation newy
peech "
"modi
mers" "live
ects" "congr"
ech" "days
gress
" "natio ay" "black
ill" "says
ys" "due
ar" "forme
g and Ward M
cation (Gibbs
7 Topic 8
l" "demoneisation"
spe
" "the"
y" "speech"
ss" "day"
h" earspeech"pmnewy
net
n" "farmers is" "modi"
" "post"
ess "what"
s" "amp"
n" "just"
k" "recover d" s" "says"
" "return"
er" "took"
Method
Method)
Topic 9
et "modi"
"you"
" "deaths"
"list" y
h "responsible"
s" "112"
"totally"
"arrogant "
"cause"
"babu"
"victims" re "india"
"congress " " "demonetisation"
"took"
Topic 10
"demonet isation"
"amp"
"new"
"year"
"due"
"farmers"
"post"
"will"
"list"
"today"
"deaths"
"says"
"agenda"
"days"
Topic 1 can be classified as related to PM Modi's new year speech had actual agenda of demonetisation in India.
Topic 2 relates to PM Modi’s new year speech where are the figures of demonetization, how much of black money was recovered ,what did the nation gain after demonetisation.
Topic 3 relates to demonetisation effects failed to watch cash figures return congress days that like this.
Topic 4 can be related to PM Modi deviated from actual agenda of black money and demonetisation, just took over the post of finance minister and made pre-budget speech.
Topic 5 opines that the people of Gujarat in their speech are anti-national and always behaves as the main hurdle.
Topic 6 related to demonetization in India effects people and formers in the coming days of the year.
Topic 7 related to Modi will address the nation today on demonetisation and black money, watch speech live.
Topic 8 related to post Modi’s speech on demonetisation what was recovered and what farmers took to return.
Topic 9 related to Modi, you are totally arrogant and responsible for the victims list of 112 deaths in India that demonetisation took, says congress.
Topic 10 did not provide any better contextual meaning and hence ignored.
The correct and relevant topics from the document corpus are generated from tweets’ data and are automatically enlisted using Gibbs method under LDA Modeling.
5. CONCLUSION
Tweets under the demonetisation twitter handler are downloaded using API authentication and the corpus is preprocessed. A word cloud is plotted, and visualization using hierarchical clustering is performed for discovering the most relevant topics. The topic modeling involving Latent Dirichlet Allocation using Gibbs method is done to uncover the most relevant topics.
The most of the topics were related to PM Modi's new year speech had actual agenda of demonetisation in India, where are the figures of demonetization, how much of black money was recovered ,what did the nation gain after demonetisation, demonetisation effects failed to watch cash figures return congress days that like this, PM Modi deviated from actual agenda of black money and demonetisation, just took over the post of finance minister and made pre-budget speech, opines that the people of gujarat in their speech are anti-national and always behaves as the main hurdle, demonetization in India effects people and formers in the coming days of the year, Modi will address the nation today on demonetisation and black money, watch speech live, post Modi’s speech on demonetisation what was recovered and what farmers took to return, Modi, you are totally arrogant and responsible for the victims list of 112 deaths in India that demonetisation took, says congress.
From the above discussion and analysis, the LDA can be seen as the best method for topic modeling in order to automatically discover topics and trends in such large scale twitter datasets.
REFERENCES
[1] Hashtag: https://en.wikipedia.org/wiki/Hashtag
[2] Blei, David, "Probabilistic Topic Models". Communications of the ACM. 55 (4): PP:77–84. doi:10.1145/2133806.2133826 , 2012.
[3] D. Blei and J. Lafferty. Topic Models. Text Mining: Theory and Applications, 2009.
[4] D. Ramage, S. Dumais, and D. Liebling. Characterizing Microblogs with Topic Models. In International AAAI Conference on Weblogs and Social Media, 2010.
[5] David M. Ble, Andrew Y. Ng, and Michael I. Jordan, Latent Dirichlet Allocation, Journal of Machine Learning Research 3, 993-1022, 2003.