DOI : 10.32628/CSEIT172140
Using Topic Modelling Approach for Discovery of Anomalous
Cluster in High Dimensional Discrete Data
Gajanan Patle1, Ajinkya S. Gujarkar2, Ektaa Meshram1
1Assistant Professor, Department of Computer Science & Engineering, Abha-Gaikwad Patil College of
Engineering, Nagpur, Maharashtra, India
2PG Scholar, Department of Computer Science & Engineering, Abha-Gaikwad Patil College of Engineering,
Nagpur, Maharashtra, India
ABSTRACT
In the area of various research, anomaly detection is an imperative issue. Anomaly is the example that
does not affirm to the normal conduct. It can allude as anomaly, exemptions, shock and so forth.
Anomalies can be meant continuous element, for example, misrepresentation detection, and digital
interruption and so on. Numerous sorts of anomaly detection methods have been proposed yet that
lone fit for recognizing singular anomalies. In this paper we proposed ATD algorithm to identify
cluster of anomalies. Singular anomaly detection strategy neglects to identify atypical example that
display on striking subset of fluctuate high dimensional component space. Our proposed algorithm
comprises of two stages. To begin with is the preparation advance in which we learn BTM as our
invalid model M0 to create all document in test set. Second is the detection stage in which we used
document-bootstrapping algorithm for clustering of hopeful documents (S) in the test set.
Keywords : ATD, BTM, hopeful documents,
Biterm Topic ModelingI. INTRODUCTION
Promotion strategies commonly recognize singular example anomalies. In this work, nevertheless, we center around distinguishing irregular examples displayed by atypical gatherings (clusters) of tests. A bizarre cluster is an arrangement of information tests, which show comparative examples of a normality. Not every one of the examples in such a cluster may be exceptionally atypical without anyone else's input, but rather, when thought about overall, the cluster exhibits an unmistakable example, which is fundamentally unique in relation to expected (typical)
Sometimes, no earlier information about typical conduct is accessible, and the objective is to identify anomalies (exceptions) in a solitary informational index comprising of ordinary and perhaps strange occasions, with no comment of which tests are ordinary. All the more ordinarily, and as we expect here, there is an accumulation of typical information which adequately portrays ordinary conduct. In the preparation stage, we utilize this information to manufacture an (invalid) demonstrate. At that point, in the detection stage, this model is utilized as a source of perspective to help distinguish (conceivable) clusters of strange examples in an alternate (test group) informational collection. Our proposed structure has huge applications in an assortment of spaces. For example, consider an open vault of logical or business related articles. An organization may attempt to post articles on this archive to advance its items or administrations. Nonetheless, to abstain from being effectively recognized by ordinary notice blocker benefits, the articles are composed such that they coordinate the typical articles on that store in frame and substance. Just a little piece of these publicizing articles advances the organization's administrations. For this situation, we can distinguish that organization's invasion by recognizing clusters of such articles.
With a specific end goal to do as such, we first utilize a sub-gathering of typical articles from that storehouse as our preparation set to take in the ordinary topics (invalid model). At that point, utilizing that invalid model, our algorithm recognizes clusters of such publicizing articles inside the full storehouse, the peculiar topic of each cluster (the item or administration they advance), and the catchphrases speaking to that topic.
Some other conceivably essential utilizations of our system are:
• Recognizing comparable examples in malware and spyware (that were transferred to an open programming instrument archive)
• To distinguish wellsprings of assaults; contemplating examples of anomalies in purchaser conduct to find developing customer patterns;
• Finding shared examples of expense evasion to uncover provisos in the law;
• Identifying sorted out vindictive exercises in web-based social networking.
II. LITERATURE SURVEY
In [2] author proposed equivalence measure thought to be ideal for finding comparability between the match of substance gives an account of the introduce of quintessence or nonattendance of features available in content records. In any case, while in the meantime researching the SMTP closeness estimation it is found that the example of estimating similarity between the consolidate of practically identical files is not secured. The objective of this work is to include this opening and propose a minor change to make the SMTP an aggregate likeness estimation system for data revelation as per the other standard equivalence methodologies.
event following, and substance recuperation, et cetera.
There is no single mostly relevant or nonexclusive special case detection approach. From the past delineations, creators have associated a wide combination of methodology covering the full exhibit of verifiable, neural and machine learning systems. Creator have attempted to give a wide case of current techniques however plainly, we can't depict all systems in a singular paper [4].
In this paper [6], creator has proposed an utilization of Hidden Markov Model (HMM) in control card deception detection. The differing strides in control card trade getting ready are addressed as the concealed stochastic methodology of a HMM. They have used the extents of trade aggregate as the observation pictures, while the sorts of thing have been believed to be states of the HMM. We have proposed a strategy for finding the spending profile of cardholders, and furthermore use of this data in picking the estimation of recognition pictures and beginning evaluation of the model parameters. It has furthermore been cleared up how the HMM can perceive whether a moving toward trade is phony or not.
EFD [7] is an authority system playing out a task for which there is no ace, and to which quantifiable strategies are inapplicable. No one has ever investigated considerable masses of cases for potential distortion, and deficient positive cases are (yet) available for true or neural framework learning procedures. Plan targets of this investigation were to begin with, to join open data unequivocally to play out the errand. Second, to pass on perceived potential cases in an area that would empower the Investigative Consultants to take a gander at purposes of premium viably; and third, to keep up a key separation from exceptionally selected philosophies
and reinforce development as cognizance of the endeavour advanced.
Creator show a payload-based anomaly identifier [8], we call PAYL, for interference detection. PAYL models the run of the mill application payload of framework development in a very modified, unsupervised and uncommonly productive shape. They at first figure in the midst of a planning stage a profile byte repeat course and their standard deviation of the application payload spilling to a lone host and port. By then use Mahalanobis isolate in the midst of the detection stage to determine the comparability of new data against the pre-prepared profile. The discoverer contemplates this measure against an edge and delivers a prepared when the partition of the new information outperforms this edge.
Here creator proposes [9] an approach that plans to find the most exemption clusters of tests by reviewing a harsh joint p-regard (joint significance) for each candidate bundle. Our technique sufficiently picks and uses the most discriminative features (by picking a subset of the pairwise incorporate tests) to choose the clusters of atypical cases in a given bunch. We differentiated our approach and methods that usage the p-estimations of individual illustrations however without gathering, and with the one-class SVM, which uses the component vector clearly. We watched that, in perceiving Zeus among Web, our p-regard packing count, when used with low most prominent test orders, outmaneuvers the attempted alternative systems, which all settle on discrete detection decisions for every illustration, and which all usage each one of the features (tests).
III. PROPOSED SYSTEM
• deciding the best current competitor strange cluster.
• Deciding if this applicant cluster is odd.
Note that we do not assume that any irregular clusters really exist in the test information. In this paper, we propose measurable tests to achieve both these means; i.e., to figure out which tests essentially have a place with the best current cluster competitor and to test whether the hopeful shows a factually noteworthy level of a commonality in respect to the invalid model.
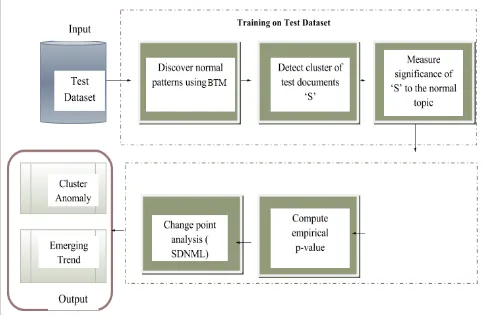
Fig. 1 System Block graph
We pick BTM over PTM as the topic display for our ATD algorithm for various reasons. To begin with, in light of the fact that PTM commonly accomplishes preferred speculation exactness over LDA and it consequently gauges the quantity of ordinary topics, dissimilar to LDA, which requires this number to be set by a utilization. Note that model request choice is a pivotal advance in abnormal topic revelation. In particular, since noteworthiness of any atypical topic will be estimated concerning the invalid model (ordinary topics), either under or over fitting the invalid can prompt bogus disclosure of odd clusters due, individually, to restricted displaying power or to poor speculation. Additionally, BTM, dissimilar to PTM, recognizes a profoundly meager arrangement of topic-particular (notable) words for every topic.
This makes PTM a characteristic fit for our ATD algorithm as we expect that the strange topics show on a low dimensional subspace of the full word space. BTM, with its scanty topic portrayal, is required to have an innate execution advantage over PTM, which utilizes every one of the words in the lexicon to characterize topics. Truth be told, this is bolstered by our trial brings about the continuation.
A similarity measure namely, similarity measure for text processing (SMTP) for knowledge discovery on text collection. The proposed measure considered the three cases for similarity measurements between the pairs of documents. These cases are based on absence and presence of features in the pair of text documents. The first case covers the features appearing in both of the documents, second case covers the features appears in only one document and the third case covers the features appears in none of the documents.
Our anomalous topic revelation algorithm comprises of two primary parts: First, in the preparation step, we learn BTM as our null model M0, with M its evaluated number of topics. The null speculation is that all documents in the test set were produced by the invalid model. Second, in the detection stage, under the elective theory, we set that a cluster of documents in the test set may contain an extra topic.
IV. IMPLEMENTATION DETAILS
In the Proposed framework, the data extricated records are pre-handled and Term Frequency –
Inverse Document Frequency procedure is utilized to figure recurrence weight. At that point, the records are positioned. The EM Clustering Algorithm is utilized to group the comparative reports.
1) Data Pre-Processing
Numerous words are not instructive and in this manner superfluous are expel from the record portrayal. (e.g.) the, an, an, and, there, their, is, was, were, the place, and so on. These word commonly around 400 to 500. It is utilized to enhance the proficiency and potential issues of evacuating stop words.
b. Stemming
Decreasing words from their root frame. A report may contain a few events of words like fish, fishes and fishers. Favourable position of stemming is to enhance the adequacy to coordinate comparable words. Lessen ordering size to brushing words with same roots may diminish ordering size as much as 40-half. Watchman calculation is utilized to stem the words.
Porter Stemming Algorithm:
Stage 1: Gets free of plurals and - ed or - ing additions
Stage 2: Turns terminal y to I when there is another vowel in the stem
Stage 3: Maps twofold postfixes to single ones: - ization, - ational, and so forth.
Stage 4: Deals with postfixes, - full, - ness and so on. Stage 5: Takes off - subterranean insect, - ence, and so on.
Stage 6: Removes a last - e
2) Document Indexing
The Extracted content reports are changed over into Boolean weighting by utilizing the ordering method of Term Frequency – Inverse Document Frequency.
TF– IDF is the result of two insights, term Frequency and Inverse Document Frequency. The term Frequency tf (t, d), the least difficult decision is to utilize the crude recurrence of a term in a report,
i.e. the circumstances that term t happens in archive d. The crude recurrence of t by f (t, d), at that point the basic tf conspire is tf (t, d) = f (t, d). Different conceivable outcomes incorporate
• Boolean "frequencies": tf (t, d) = 1 if t happens in d and 0 generally;
• Logarithmically scaled recurrence: tf (t, d) = log (f (t, d) + 1);
• Augmented recurrence, to keep a predisposition towards longer records
tf (t, d) = 0.5+ 0.5 ×𝑓𝑡 (𝑡,𝑑)max{𝑓𝑤,𝑑 :𝑤𝜖𝑑}
The Inverse Document Frequency is a measure of whether the term is normal or uncommon over all archives. It is gotten by separating the aggregate number of archives by the quantity of reports containing the term, and after that taking the logarithm of that remainder.
Id (t, D) = log|𝐷|| 𝑑𝜖𝐷∶𝑡𝜖𝑑 |
• |D|: cardinality of D, or the aggregate number of records in the corpus
• | {⋳𝐷:𝑡⋳𝑑}|: number of records where the term t shows up. In the event that the term is not in the corpus, this will prompt a division-by-zero. It is accordingly normal to modify the equation to 1+| {⋳𝐷:𝑡⋳𝑑}|
• Scientifically the base of the log work does not make a difference and constitutes a steady multiplicative factor towards the general outcome. At that point TF– IDF is computed as
tf – idf (t, d, D) = tf (t, d) × idf (t, D)
3) Similarity Measure for Text Processing
attributes are needy the information. There is no pre-decided measure that is appropriate for a wide range of clustering issues. The thickness based clustering algorithms, as DB Scan, rely upon the calculation of likeness. The closeness is only likeness esteem. Likeness measure speak to the closeness between representative depictions of two items into single numeric esteem.
a. Metric
To ensure as a metric, a measure must fulfill four conditions. Give x and y a chance to be any two articles. The items x and y are available in a set. The separation between the two items is given by d(x,y). The accompanying are four conditions:
1. The separation between two focuses must be at least zero than zero.
2. The separation between two articles must be zero iff the two items are precisely the same.
3. Separation ought to be symmetric, that is, the separation from x to y is same as the separation from y to x.
4. The measure should dependably fulfill the triangle imbalance.
b. Euclidean Distance
It is the distance between two focuses. Euclidean separation is generally utilized as a part of clustering issues. Since Euclidean fulfills all the four conditions it is considered as a genuine metric. The K-means algorithm utilizes Euclidean separation as a default remove measure.
The Euclidean distance of the two documents is characterized as
(1)
D is a set, which contains m text documents; D = {d1,
d2….dm} I = 1, 2…m There are n words among m text
documents.
di = {wi1, wi2,….wij,….. win}
i = 1, 2, m, j = 1, 2, n.
Now, Consider a document d with m highlights w1,
w2 . . . wm be spoken to as an m-dimensional vector,
i.e., d. In the event that wi, 1 ≤ I ≤ m, is absent in the
document then di 0. Something else, di>0. The accompanying properties among different ones are attractive for a comparability measure between two documents.
The nonattendance or nearness of a component is important than the distinction between two esteems related with a present element. Here we think about two highlights wi and wj and two documents d1 and d2.
Let wi does not show up in d1 but rather it does shows up in d2, at that point wi have no association with d1 while it has some association with d2. In the event that case d1 and d2 are disparate as far as wi. Also, if wj shows up in both document d1 and d2 then wj has some association with d1 and d2 all the while. Here for this situation d1 and d2 are like some degree as far as wj. For the over two cases it is sensible to state that wi conveys more weight than wj in deciding the likeness degree between documents d1 and d2.
The closeness degree increment when the contrast between two esteems (that are non zero) of a particular element diminishes. For instance the closeness that is included with d13 = 2 and d23 = 15 ought to be littler than that required with d13 = 2 and d23 = 4.
Two documents are thought to be minimum like each other if none of the highlights have non-zero esteems in the two documents.
Likeness measure ought to be symmetric. The similitude degree amongst d1 and d2 ought to be same as that amongst d2 and d1. The standard deviation of the element is considered for its contribution to the similitude between two documents highlight with a better spread offers more inclusion than the comparability amongst d1 and d2.
In light of the properties talked about, a likeness measure, called Similarity Measure for Text Processing, for two documents d1 = <d11, d12, d13 ... ,d1m> and d2 = <d21, d22, d22 ... , d2m> characterizes a capacity F as follows[18]:
(2) At that point the comparability measure, SSMTP, for d1and d2 is
(3)
This measure thinks about after cases:
• The element that we are thinking about ought to be available in both the documents,
• The component we are thinking about ought to be available in just a single of the document, and
• The component we are thinking about ought to be available in none of the documents.
V. RESULT ANALYSIS
Following are Results generated during the implementation of the system.
This section presents the comparison results of system.
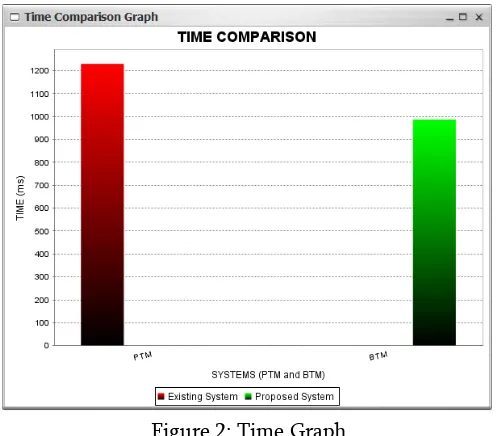
Figure 2: Time Graph
Figure 2 shows the Time graph of system and Figure 3 shows memory graph of proposed system where green color indicates proposed system red color indicates used existing System. X axis shows system and Y-axis shows time in ms.
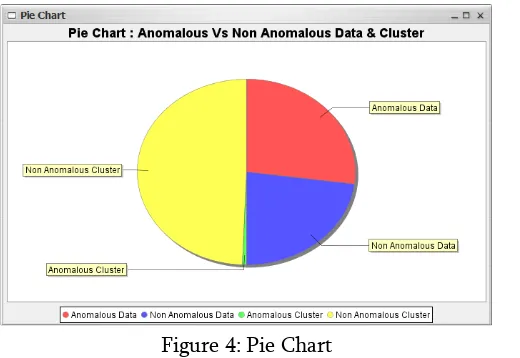
Figure 4: Pie Chart
Figure 4 shows Pie chart for anomalous versus non-anomalous data and cluster. Yellow is non-non-anomalous cluster green color indicates anomalous cluster and blue non-anomalous data and red indicate anomalous data.
VI. CONCLUSION
In this paper we proposed ATD algorithm to identify cluster of anomalies. Singular anomaly detection method neglects to identify atypical example that show on remarkable subset of differ high dimensional element space. Our proposed algorithm comprises of two stages. To start with is the preparation venture in which we learn BTM as our invalid model M0 to create all document in test set. Second is the detection stage in which we used document bootstrapping algorithm for clustering of competitor documents (S) in the test set. Besides, as a piece of commitment we center around rise of topics motioned by social viewpoints by finding joins between social clients. Collecting anomaly scores from many clients, we demonstrate that we can recognize developing topics just in light of the answer/say connections in documents. For trial result investigation we utilized live information from The Hindustan Times and The Indian Express. With trial comes about we mean to speak to that the proposed approach can proficiently distinguishes a cluster of anomalies and rising topic in test set.
VII.REFERENCES
[1] Hossein Soleimani, and David J. Miller, “ATD:
Anomalous Topic Discovery in High
Dimensional Discrete Data,” IEEE
TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 2016.
[2] Naresh Kumar Nagwani, “A Comment on A
Similarity Measure for Text Classification and
Clustering,” IEEE TRANSACTIONS ON
KNOWLEDGE AND DATA ENGINEERING, VOL. 27, NO. 9, SEPTEMBER 2015
[3] Xueqi Cheng, Xiaohui Yan, Yanyan Lan, and Jiafeng Guo, BTM: Topic Modeling over Short Texts, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 12, DECEMBER 2014
[4] V. J. Hodge and J. Austin, “A survey of outlier
detection methodologies,” Artificial
Intelligence Review, vol. 22, no. 2, pp. 85–126, 2004.
[5] V. Chandola, A. Banerjee, and V. Kumar,
“Anomaly detection: A survey,” ACM
Computing Surveys (CSUR), vol. 41, no. September, pp. 1–58, 2009.
[6] A. Srivastava and A. Kundu, “Credit card fraud detection using hidden Markov model,” IEEE
Transactions on Dependable and Secure Computing, vol. 5, no. 1, pp. 37–48, 2008. [7] J. Major and D. Riedinger, “EFD: A Hybrid
Knowledge/Statistical- Based System for the
Detection of Fraud,” Journal of Risk and
Insurance, vol. 69, no. 3, pp. 309–324, 2002. [8] K. Wang and S. Stolfo, “Anomalous payload
-based network intrusion detection,” in Recent
Advances in Intrusion Detection, pp. 203– 222, 2004.
[9] F. Kocak, D. Miller, and G. Kesidis, “Detecting
anomalous latent classes in a batch of network
traffic flows,” in Information Sciences and
[10] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent Dirichlet Allocation,” Journal of Machine
Learning Research, vol. 3, pp. 993–1022, 2003. [11] H. Soleimani and D. J. Miller, “Parsimonious
Topic Models with Salient Word Discovery,”
Knowledge and Data Engineering, IEEE Transaction on, vol. 27, pp. 824–837, 2015. [12] L. Xiong, s. P. Barnaba, J. G. Schneider, A.
Connolly, and V. Jake, ´ “Hierarchical
probabilistic models for group anomaly
detection,” in International Conference on
Artificial Intelligence and Statistics, pp. 789–
797, 2011.
[13] L. Xiong, B. Poczos, and J. Schneider, “Group
anomaly detection ´ using flexible genre
models,” in Advances in neural information
processing systems, pp. 1071–1079, 2011. [14] R. Yu, X. He, and Y. Liu, “GLAD : Group
Anomaly Detection in Social Media Analysis,”
in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 372– 381, 2014. [15] K. Muandet and B. Scholkopf, “One-class
support measure ma- ¨ chines for group
anomaly detection,” in 29th Conference on
Uncertainty in Artificial Intelligence, 2013. [16] W. Wong, A. Moore, G. Cooper, and M.
Wagner, “Rule-based anomaly pattern
detection for detecting disease outbreaks,”
2002.
[17] W. Wong, A. Moore, G. Cooper, and M.
Wagner, “Bayesian network anomaly pattern
detection for disease outbreaks,” 2003.
[18] K. Das, J. Schneider, and D. B. Neill, “Anomaly pattern detection in categorical datasets,” 2008
[19] E. McFowland, S. Speakman, and D. Neill, “Fast
generalized subset scan for anomalous pattern
detection,” Journal of Machine Learning
Research, vol. 14, no. 1, pp. 1533–1561, 2013. [20] J. Allan, R. Papka, and V. Lavrenko, “On-line
new event detection and tracking,” 1998.
Cite this article as :