C o n c e p t c l u s t e r i n g a n d k n o w l e d g e i n t e g r a t i o n f r o m a
c h i l d r e n ' s dict i o n a r y
C a r o l i n e B a r r i ; ~ r e a n ( I I , ¥ e d l ' o p o w i c h
S c h o o l o f ( k ) n q m t i n g S(:iencc, S i ] n ( m l,'rascr U l l i v c r s i t y l ~ u r n a b y , l~C, ( ; n . n a d a , V 5 A 1S6
ba.rric're,l)Ol)OWi(;ll(@(:s.stTu.(;a
A b s t r a c t
Knowledge structures called C o n c e l ) t (?lustering Knowledge (]raphs ( C C K G s ) are introduced along with a process for their construction from a machine read- able dictionary. C(3K(]s contain multi- ple concepts interrelated through multi- l)le semantic relations together forming a semantic d u s t e r represented by a con-. ceptual graph. '1'he knowledge acquisi- tion is performed on a children's first dic- tionary. T h e concepts inw)lved are gen- eral and typical of a daily l i d conw'a'sa- lion. A collection of conceptual clusters together can lbrm the basis of a lexi- cal knowledge base, where each C'(,'l((.~ contains a limited n n m b e r of highly con- nected words giving usefid information a b o u t a particular domain or situation.
it Introduction
When constructing a l,exieal Knowledge Ilase
(1,KB) useful for N a t u r a l l,anguage Processing, the source of information from which knowledge is acquired and the structuring of this informa- tion within the LKB are two key issues. Ma- chine Readable Dictionaries (MIH)s) are a good sour(:e of lexical information and have been shown to be al)plical)le to the task of I,KII COllStruction (l)ola.n ct al., 1993; Calzolari, t992; Copestake, [990; Wilks et al., 1989; Byrd et al., 1987). Often though, a localist approaeh is adopted whereby the words are kept in alphabetical order with some representation of their definitions in the form of a t e m p l a t e or feature structure. F, flbrt in find- lug cormections between words is seen in work on a u t o m a t i c extraction of sem~mtic relations Dora MRI)s (Ahlswede and Evens, 1988; Alshawi, 1989; Montemagrfi and Vandorwende, 19!32). Addition- ally, effort in finding words t h a t are close seman- tically is seen by the current interest in statisti- cal techniques for word clustering, looking at (-o- occurrences of words in text corpora or dictionar- ies (Church and IIanks, 1989; Wilks et al., 1989;
Brown et al., 11992; l'ereira et al., 11995).
Inspired by research in the. areas of semantic relations, semantic distance, concept clustering, and using ( , o n c e I tual (Ji a l hs (Sowa, 1984) as our knowledge representation, we introduce (;oncept (?lustering I{nowledge G r a p h s ( C C K G s ) . Each (JCKG will start as a Conceptual G r a p h represen- tation of a trigger word and will expaud following a search algorit, hm to incorporate related words and ibrm a C'oncept Cn,s(,er. T h e concept chls- tcr in itself is interesting for tasks such as word disambiguation, but the C(~K(] will give more to that cluster. It will give the relations between the words, m a k i n g the graph in some aspects similar to a script (Schank and Abelson, 11975). llowever, a C C K ( I is generated automaticMly and does not rely on prin,itives but on an unlimited n u m b e r of c o n c e l ) t s , showing objects, persons, and actions interacting with each other. This interaction will be set, within a lmrtieular domain, and the trig- ger word should be a key word of the domain to represent. 11' t h a t process would be done for the whole dictionary, we would obtain an l,l( II divided into multiple clusters of words, each represented by a CCK(]. Then during text processing fin: ex- ample, a portion of text could be analyzed using the a p p r o p r i a t e C C K ( ] to lind implicit relations and hell) understanding the text.
Our source of knowledge is the Americ~m iter- itage First I)ictionary t which contains 1800 en- tries aml is designed for children of age six to eight. lit is m a d e for yom~g l)eople learning the structure and the basic w)cabulary of their language. In comparison, an adult's dictiouary is more of a ref erence tool which assumes knowledge of a large basic vocabulary, while a learner's dictionary as- sumes at limited vocabulary but still some very sophisticated concepts. Using a children's dictio- nary allows us to restrict our vocabulary, but still work on general knowledge a b o u t day to day (:Oil-- cel)tS and actions.
transformation steps from the definitions into con- ceptual graphs, then we elaborate on the integra- tion process, and finally, we close with a discus- sion.
2
Transforming definitions
Our definitions m a y contain up to three general types of information, as shown in the examples in Figure 1.
• d e s c r i p t i o n : This contains genus/differentia
information. Such information is frequently
used for noun taxonomy construction (Byrd et al., 1987; Klavans et al., 1990; Barri~re and Popowich, To appear August 1996).
• general k n o w l e d g e or usage: This gives in- formation useflfl in daily life, like how to use an object, what it is made of, what it looks llke, etc.
• specific e x a m p l e : This presents a typical situ- ation using the word defined and it involves spe- cific persons and actions.
C e r e a l is a kind of food. [description]
Many c e r e a l s are made from corn, wheat, or rice. [usage] Most people eat c e r e a l with milk in a bowl. [usage]
Asia is what is left after something burns. [usage] It is a soft gray powder. [description]
[image:2.596.316.512.227.354.2]Ray watched his father clean the a s h e s out of the fireplace. [example]
Figure 1: Example of definitions
The information given by the description and general knowledge will be used to perform the knowledge integration proposed in section 3. The specific examples are excluded as they tend to in- volve specific concepts not always deeply related to the word defined.
Our processing of the definitions results in the construction of a special type of conceptual graph which we call a
temporary graph.
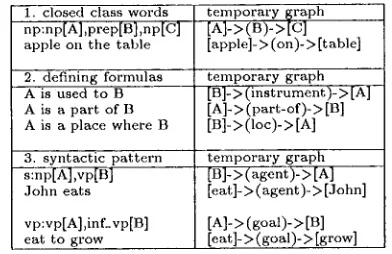
The set of rela- tions used in t e m p o r a r y graphs come from three sources. Table 1 shows some examples for each type.1. the set of closed class words, ex:
of, to, in, and;
2. relations extracted via defining formulas ex:
part-
of, made-of, instrument;
defining formulas cor- respond to phrasal patterns that occur often through the dictionary suggesting particular se- mantic relations (ix. A is a part of B) (Ahlswede and Evens, 1988; Dolan et al., 1993).3. the relations that are extracted from the syntac- tic structure of a sentence, ex:
subject, object,
goal, attribute, modifier.
As some relations are defined using the closed class words, and m a n y of those words are ambigu- ous, the resulting graph will itself be ambiguous. This is the main reason for calling our graphs
temporary as
we assume a conceptual graph, the ultimate goal of our translation process, shouldcontain a restricted set of well-defined and non-
ambiguous semantic relations. For example,
by
can be a relation of manner
(by chewing),
time(by noon)
or place(by the door).
By keeping the preposition itself within the t e m p o r a r y graph, we delay the ambiguity resolution process until we have gathered more information and we even hopefully avoid the decision process as the ambi- guity might later be resolved by the integration process itself.1. closed class words temporary I~raph np:np[A],prep[Bl,np[C ] [A]->(B)->[C] apple on the table [apple]->(on)->[table]
2. defining formulas A i s used to B A i s a part of B A is a place where B
3. syntactic pattern s:np[A],vp[B] John eats
vp:vp[A],inf_vp[B] eat to grow
temporary graph [B]- > (instrument )- > [A] [A]-> (part-of)-> [B] [Bl->(loc)->[A]
temporary graph [B]-> (agent)-> [h] [eat]- > (agent)- > [John]
[A]-> (goal)-> [B]
[e at]- > ( goal)- > [grow]
Table 1: Examples of relations found in sentences and their corresponding t e m p o r a r y graphs
3
Knowledge integration
This section describes how given a trigger word, we perform a series of forward and backward searches in the dictionary to build a C C K G con- taining useful information pertaining to the trig- ger word and to closely related words. The pri- m a r y building blocks for the C C K G are the tem- porary graphs built from the dictionary definitions of those words using our transformation process mentioned in the previous section. Those tem- porary graphs express similar or related ideas in different ways and with different levels of detail. As we will try to put all this information together into one large graph, we must first find what in- formation the various t e m p o r a r y graphs have in common and then join them around this c o m m o n knowledge.
To help us build this C C K G and perform our integration process, we assume two main knowl- edge structures are available, a concept hierarchy and a relation hierarchy, and we assume the exis- tance of some graph operations. The concept hi- erarchy concentrates on nouns and verbs as they account for three quarters of the dictionary def- initions. It has been constructed automatically according to the techniques described in (Barri~re and Popowich, To appear August 1996). The re- lation hierarchy was constructed manually. A rich hierarchical structure between the set of relations is essential to the graph matching operations we use for the integration phase.
m a t c h i n g operations defined in (Sowa, 1984). The t, wo operations we will need are the maximal com- mon subgraph algorithm and the maximal join al- gorithm.
3.1. M a x i m a l c o m m o n s u b g r a p h
T h e m a x i m a l c o m m o n subgraph between two graphs consists of finding a subgraph of tile first graph t h a t is isomorphic to a subgraph of the see- ond graph. In our case, we cannot often expect to find two graphs t h a t contain an identical subgral)h with the exact s a m e relations and concepts. Ideas cart be expressed in m a n y ways and we therefore need a more relaxed m a t c h i n g schema. We de- scribe a few elements of this "relaxation" process and illustrate t h e m by an example in Figure 2.
(1) J o h n m a k e s a nice d r a w i n g on a piece of p a p e r with the pen. [make]- > ( s u b ) - > [ J o h n ]
- > ( o b j ) - > [ d r a w i n g ] - > ( n i t ) - >[nice] - >(on)- >[piece]- >(or)- > [ p a p e r ] - > ( w i t h ) - > [ p e n ]
(2) J o h n uses the big crayon t o d r a w rapidly on the p a p e r . [(haw]- > ( s u b ) - > [ J o h n l
- > ( o n ) - > [ p a p e r ] - > ( i n s t . . . t)- > [crayon] - > ( m a n n e r ) - >[rapidly]
M A X I M A l , C O M M O N S U B G R A P n : [ m a k e ( d r a w ) ] - > ( s u b ) - > [ J o h n ]
- > ( o b j ) - > [ d r a w i n g ]
- > ( o n ) - > [ p i e c e ] - > ( o f ) - > [ p a p e r ] - > ( i n s t r u m e n t ) - >[label-11
~ m e t h o d
l~elation s u b s u m p t i o n P r e d i c t a b l e m e a n i n g Mdft n e l a t i o n t r~nsitivity
g r a p h l ] g r a p h 2
pell cr~yoll
with i n s t r u m e n t
d r a w i n g dr~w
piece of p a p e r p ~ p e r
M A X I M A L J O I N :
[ m a k e ( d r a w ) ] - > ( s u b ) - > [ J o h n ]
- > ( o b j ) - > [drawing]- > ( a r t ) - >[nice] - > ( o . ) - > [piece]- >(of)- > [ p a p e r l - > ( i n s t . . . t)->[l~b¢l-1] - > ( . . . )->[rapidly]
Figure 2: E x a m p l e of "relaxed" m a x i m a l c o m m o n sui)graph and m a x i m a l join algorithms
S e m a n t i c d i s t a n c e b e t w e e n c o n c e p t s . In the m a x i m a l c o m m o n subgraph algorithm pro- posed by (Sow% :1984), two concepts (C1,CY) could be m a t c h e d if one s n b s u m e d the other in the concept hierarchy. We can relax t h a t criteria to m a t c h two concepts when a third concept C which subsumes C1 and C2 has a high enough de- gree of informativeness (Resnik, 1995). T h e con- cept hierarchy can be useful in m a n y cases, but it is generated from the dictionary and might not be complete enough to find all similar concepts.
In the e x a m p l e of Figure 2, when using tile con- cept hierarchy to establish the similarity between
pen and crayon, we find that; one is a subclass of lool and the other of wax, both then are sub- stoned by the general concept something. We have
reached the root of the noun tree in the concept hi- erarchy and this would give a similarity of 0 based on the informativeness notion.
We extend the s u b s u m p t i o n notion to the graphs. Iustead of finding a concept t h a t sub- sulnes two concepts, we will try finding a c o m m o n subgraph t h a t subsumes the g r a p h representation of both concepts. In our example, pen and crayon
have a c o m m o n s u b g r a p h [write]->(inst)->~. The notion of semantic distance can be seen as the in- formativeness of the subsuming graph. T h e re- suiting m a x i m a l comlnon snbgraph as shown in Figure 2 contains the concept label-1. This label is associated to a covert category ~s presented in (Barri~re and Popowich, To a p p e a r August 1996). We carl u p d a t e tile concept hierarchy and add this label-1 as a subclass of something and a superclass of pen and crayon. It expresses a concept of "writ- ing i n s t r u m e n t " .
t
R e l a t i o n s u b s m n p t i o n . Since we have a re- lation hierarchy in addition to our concept hier- archy, we can similarly use s u b s u m p t i o n to m a t c h two relations. In i,'igure 2, with is subsumed by in-
strument, and by lnapping them, we disantbiguate
wilh from corresponding to another semantic rela- tion, such as possession or accompaniment. This is a case where an arnbiguons preposition left in the t e m p o r a r y graph is resolved by the integration process.
P r e d i c t a b l e m e a n i n g s h i f t . A set of lexical implication rules were developed by (Ostler and Atkins, 1992) for relating word senses. Based on them, we are developing a set of graph match- ing rules. Figure 2 exemplifies one of theln where two graphs containing the s a m e word (or m o r p h o - logically related), here draw and drawing, used as different parts of speech can be related.
R e l a t i o n t r a n s i t i v i t y . Some relations, like
part-of, in, from can be transitive. For example, we can m a p a graph t h a t contains a concept A in a certain relation to concept B onto another graph where concept A is in the s a m e relation with a part
or a piece of B as exemplified in Figure 2. Tran- sitivity in relations is in itself a challenging area of study (Cruse, 1986) and we have only begun to explore it.
3.2 M a x i m a l j o i n
[image:3.596.54.273.296.545.2]isting concepts, as well as bringing new relations between existing concepts.
3.3 I n t e g r a t i o n p r o c e s s
Given the concept hierarchy, relation hierarchy and graph m a t c h i n g operations, we now describe the two m a j o r steps required to integrate all the t e m p o r a r y graphs into a C C K G .
T R I G G E R . P H A S E . Start with a central word, a keyword for the subject of interest t h a t becomes the trigger word. T h e t e m p o r a r y graph built from the trigger word forms the initial C C K G . To expand its meaning, we want to look at the i m p o r t a n t concepts involved and use their respective t e m p o r a r y graphs to extend our initial graph. We deem words in the definition to be im- p o r t a n t if they have a large semantic weight.
2.'he semantic weight of a word or its informa- tiveness can be related to its frequency (l~esnik, 1995). Itere, we calculate the n u m b e r of occur- rence of each word within the definitions of nouns and verbs in our dictionary. T h e most frequent word "a" occurs 2600 times a m o n g a total of 38000 word occurrences. Only 1% of the words occur more t h a n 130 times, 5% occur more than 30 times but over 60% occur less than 5 times.
Ordering the dictionary words in terms of de- creasing n u m b e r of occurrences, the top 10% of these words account for 75% of word occurrences. For our current investigation, we propose this as the division between semantically significant words, and semantically insignificant ones. So a word from the dictionary is deemed to be seman- tically significant if it occurs less than 17 times. Note t h a t constraining the n u m b e r of semanti- cally significant words is i m p o r t a n t in limiting the exploration process tbr constructing the concept cluster, as we shall soon see.
T r i g g e r f o r w a r d : Find the semantically signif- icant words fi'om the C C K G , and join their respective t e m p o r a r y graphs to the initial C C K G .
T r i g g e r b a c k w a r d : Find all the words in the dictionary t h a t use the trigger word in their definition and join their respective t e m p o r a r y graphs to the C C K G .
Instead of a single trigger word, we now have a cluster of words t h a t are related through the C C K G . Those words ,form the concept cluster.
E X P A N S I O N P H A S E . We try finding words in the dictionary containing m a n y concepts iden- tical to the ones already present in the C C K G but perhaps interacting through different relations al- lowing us to create additional links within the set of concepts present in the C C K G . Our goal is to create a more interconnected graph rather t h a n sprouting f r o m a particular concept. For this rea- son, we establish a graph m a t c h i n g threshold to
decide whether we will join a new graph to the C C K G being built. We set this threshold empir- ically: the m a x i m a l c o m m o n s u b g r a p h between the C C K G and the new t e m p o r a r y graph m u s t contain at least three concepts connected through two relations.
E x p a n s i o n f o r w a r d : For each semantically significant word in the C C K G , not already part of the concept cluster, find the maxi- mal c o m m o n subgraph between its t e m p o r a r y graph and the C C K G . If m a t c h i n g surpasses the graph m a t c h i n g threshold, perform inte- gration ( m a x i m a l join operation) and add the word in the concept cluster. Continue for- ward until no changes are made.
E x p a n s i o n b a c k w a r d : Find words in the dic- tionary whose definitions contain the seman- tically significant words f r o m the concept cluster. For each possible new word, find the m a x i m a l c o m m o n s u b g r a p h between its t e m p o r a r y graph and the C C K G . Again, if m a t c h i n g is over the graph m a t c h i n g thresh- old, perform integration and add the word to the concept cluster. Continue until no changes are made.
We can set a limit to the n u m b e r of steps in the expansion phase to ensure its termination. Ilow- ever in practice, M'ter two or three steps forward or backward, the m a x i m a l c o m m o n subgraphs be- tween the new graphs and C C K G do not exceed the graph m a t c h i n g threshold and thus are not added to the cluster, t e r m i n a t i n g the expansion. 3.4 E x a m p l e o f i n t e g r a t i o n
Figure 3 shows the starting point of an integra- tion process with the trigger word ( T W ) lelter, its definition, its t e m p o r a r y graph ( T G ) , the concept cluster (CC) containing only the trigger word, and the C C K G being the s a m e as the t e m p o r a r y graph. Then we show the trigger forward phase. T h e n u m b e r of occurences (NOte) of each word present in the definition of letter is given. Us- ing the criteria described in the previous section, only the word message is a semantically significant word (SSW). We then see the definition of mes- sage, the new concept cluster and the resulting C C K G .
T h e trigger backward phase, would incorporate the t e m p o r a r y graphs for address, mail, post office
and stamp. T h e expansion forward phase would
further add the t e m p o r a r y graphs for the seman- tically significant words: {send, package} dur- ing the first step and then would t e r m i n a t e with the second step as no more semantically signifi- cant words not yet explored have a m a x i m a l com- m o n subgraph with the C C K G t h a t exceeds the graph m a t c h i n g threshold. T h e expansion back- ward would finally add the t e m p o r a r y graphs for
The resulting cluster is: {letter, message, ad- dress, mail, post office, stamp, send, package, card, note}. The resulting CCKG shows the in- teraction between those concepts which smnma- rizes general knowledge about lnow we use those concepts together in a da.ily conversation: we go to the post office to mail letters, or packages; we write letters, notes and cards to send to peoI)le through the mail, etc. Ilaving such clusters and such knowledge of the relationship between words as part of our lexical knowledge base can be useflfl to understand or even generate a text containing the concepts involved in the cluster.
S ' I ' A l l . ' I ' I N G P O I N ' F :
T W : l e t t e r
D e f : A l e t t e r is a m e s s a g e y o u w r i t e on p a p e r , T G : s a m e a s C C K G
C O : { l e t t e r }
C C K G : [write]- > (obj)- > [message(let ter)]
- > ( s u b j ) - > [ p e r . . . . :you]
- > (on)- > [>q,e,'l
T l l . I G G EtI~ I!'O I t W A I/.D :
N O t e s : y o u : 2 8 0 , p a p e r : 4 2 , w r i t e : 3 1 , m e s s a g e : 7
S S W s : m e s s a g e
l_)ef: A l n ( ' . s s a g e is a g r o u p o f w o r d s t h a t is s e n t
l'l'Olll ()lie p e r s o n t o ; ~ . I l o t h e l ' .
M a n y p e o p l e s e n d n m s s a g e s t h r o u g h t h e m a i l . ( ; C : { l e t t e r , m e s s a g e }
C C K G :
[ w o r d : g r o u p ( m e s s a g e ( l e t t e r ) ) ]
<@~bj) <-[write]- > (sub)- > [person:you]
- > (o,)- > [l,~per] <-(obj)<-[ ... 11->(.~.bj)->[pe~" ... y]
- > ( f r o l / l ) - > [pe . . . ] - > ( t o ) - > [I .. . . t h e r ]
-> (through)->[mail I
Fignre 3: iDigger forward from letter.
4 D i s c u s s i o n
'l'lu:ough this paper, we showed the multiple steps leading us to tile building of Concept Clustering Knowledge Graphs (CCKGs). Those knowledge structm:es arc built within the Lexical Knowl- edge Base (LKB), integrating lnultiple parts of the I,Kt~ around a particular concept to form a clus.- ter and express the multiple relations among the words in that cluster. The C C K G s could be either permanent or t e m p o r a r y structures depending on the. applicatkm using the LKB. For example, for a text understanding tusk, we can build before hand the CCKGs corresponding to one or multiple key- words from the text. Once built, the C C K G s will help us in our comprehension and disambiguation of the text.
By using the American lh;ritage First l)ictio- nary a~s our source of lexical information, we were able to restrict our vocabulary to result ill a project of reasonable size, dealing with general knowledge about (lay to day concepts and actions.
The ideas explored using this dictionary can be ex- tended to other dictionaries as well, but the task might becorne more complex as the defilfitions in adult's dictionaries are not as clear and usage ori- ented. In fact, an LKB lmilt fl'om a children's dictionary could be seen as a starting point from which we could extend our acquisition of knowl- edge using text corpora or other dictionaries. Cer- tainly, if we euvisage applications trying to under- stand children's stories or help in child education, a corpora of texts for children would be a good source of information to extend our LKB.
The graph operations (maximM commou sub- graph and maximal join) defined on conceptual graphs, anti adapted here, play an i m p o r t a n t role in our integration process toward a final CCKG. Graph matching was also suggested as an alterna- tiw; to taxonomic search when trying to establish semantic similarity between concepts. As well, by putting a threshohl on the graph matching pro- cess, we were able to limit the expansion of our clustering, as we can decide and justify the incor- poration of a new concept into a particular cluster. Many aspects of the concept clustering and knowledge integration processes have already been implemented and it will soon be possible to test the techniques on different trigger words using dif- ferent thresholds to see how they effect the quality of the clusters.
(~lustering is often seen as a statistical opera- tion that puts together words "somehow" related. ltere, we give a meaning to their clustering, we tint[ and show the connections between concepts, and by doing so, we build more than a cluster oF words. We build a knowledge graph where the concepts interact with each other giving i m p e l taut implicit information that will be useful for Natural Language Processing tusks.
5 A c k n o w l e d g m e n t s
i['his research was supported by the Institute for Robotics and Intelligent Systems. The autlnors would like to thank the a n o n y m o u s referees for their comments and suggestions, and Petr Kubon for his m a n y comments on the paper.
R e f e r e n c e s
T. Ahlswede and M. Evens. 1988. Generating a relational lexicon from a machine-readable dic-
tionary. International JowrnM of Lexicography,
1l(3):214 237.
II. A]shawi. 1989. Analysing tile dictionary def-
inil.ions. In 1~. Boguraev and T. llriscoe, ed-
itors, Compulalional Lexicography for Natural
Language Processing, chapter 7, pages 153-170.
Long,nan (]reap IlK l,imited.
dren's dictionary. In Proceedings of Euralex'96,
GSteborg, Sweden.
P. Brown, V.J. Della Pietra, P.V. deSouza, J.C. Lai, and I{.L. Mercer. 1992. Class-based n- grain models of natural language. Computa-
tional Linguistics, 18(4):467-480.
R.J. Byrd, N. Calzolari, M. Chodorow, J. Kla- vans, M. Neff, and O. Rizk. 1987. Tools and methods for computational lexieology. Compu-
tational Linguistics, 13(3-4):219-240.
N. Calzolari. 1992. Acquiring and representing se- mantic information in a lexical knowledge base. In J. Pustejovsky and S. Bergler, editors, Lex- ical Semantics and Knowledge Representation
: First SIGLEX Workshop, chapter 16, pages
235-244. Springer-Verlag.
K. Church and P. Hanks. 1989. Word associa- tion norms, mutual information and lexicogra- phy. In Proceedings of the 27lh Annual meeting of the Association for Computational Linguis-
tics, pages 76-83, Vancouver, BC.
A.A. Copestake. 1990. An approach to building the hierarchical element of a lexical knowledge base from a machine readable dictionary, in
Proceedings of the Workshop on Inheritance in Natural Language Processing, 7'ilburg.
D.A. Cruse. 1986. Lexical Semantics. Cambridge University Press.
W. Dolan, L. Vanderwende, and S. D. Richard- son. 1993. Automatically deriving structured knowledge bases from on-line dictionaries. In
The First Conference of the Pacific Associa-
tion for Computational Linguistics, pages 5-14,
IIarbour Center, Campus of SFU, Vancouver, April.
J. Klavans, M. S. Chodorow, and N. Wacholder. 1990. From dictionary to knowledge base via taxonomy. In P~vceedings of the 6th Annual Conference of the UW Centre for the New OED:
Electronic Text Research, pages 110-132.
S. Montemagni and L. Vanderwende. 1992. Struc- tural patterns vs. string patterns for extract- ing semantic information from dictionaries. In
Proc. of the 14 o~ COLING, pages 546-552,
Nantes, France.
N. Ostler and B.T.S. Atkins. 1992. Predictable meaning shift: Some linguistic properties of lexical implication rules. In J. Pustejovsky and S. Bergler, editors, Lexical Semantics and Knowledge Representation : First S[GLEX
Workshop, chapter 7, pages 87-100. Springer-
Verlag.
17. Pereira, N. Tishby, and L. Lee. 1995. Distri- butional clustering of english words. In Proc. of
the 33 th A CL, Cambridge,MA.
P. Resnik. 1995. Using information content to evaluate semantic similarity in a taxonomy. In
Proc. of the 14 th IJCAL volume 1, pages 448-
453, Montreal, Canada.
R. Schank and FL. Abelson. 1975. Scripts, plans and knowledge. In Advance papers 4th Intl. Joint Conf. Artificial Intelligence.
J. Sowa. 1984. Conceptual Structures in Mind
and Machines. Addison-Wesley.
Y. Wilks, D. Fass, G-M Guo, J. McDonald, T. Plate, and B. Slator. 1989. A tractable ma- chine dictionary as a resource for computational semantics. In Bran Boguraev and Ted Briseoe, editors, Computational Lexicography for Natu-
ral Language Processing, chapter 9, pages 193-