International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
A Novel Content-Based Document Information Retrieval
Technique
Dr. Poonam Yadav
Assistant Professor, D.A.V College of Engineering & Technology, Kanina, Haryana 123027, India
Abstract— It is difficult to acquire the relevant information on the web due to the rapid progression of excess information. Under this circumstance, it is essential to develop a reliable Information Retrieval (IR) system. As per the traditional web servers, the required information can only be extracted from the title or small explanation. Accordingly, this paper proposes the IR process using CBDIR system, which can extract the information from the actual content of the document. Initially, the required keywords are extracted from document using the Latent Dirichlet Allocation (LDA) model. In fact, the fundamental benefit of the proposed method is its effectiveness, flexibility and high speed. Here the information transmitted from the server to client is JavaScript Object Notation (JSON) format. Further, the usage of NoSQL database system with B-tree based indexing and inverted indexing can enhance the speed of IR system. Moreover, it compares the performance of the proposed CBDIR system with the conventional IR system and proves its superior performance. The system can be highly adaptable in real-time applications.
Keywords—Information Retrieval, LDA, Content, document, CBDIR
I. INTRODUCTION
Nowadays, diverse fields of computer science have been used the IR system [27] [26]. Since there is a vast quantity of information available to retrieve, IR plays a significant role in this field [38]. In general, the IR system is linked to most of the traditional web services [25] [36]. The files related to presentation or documents can be uploaded with their title and explanation. Hence, the users can extract the required information by searching through the title or explanation [24] [28] of the content introduced with IR system. However, the operation and reliability of the IR system are limited. Though the information can only search from the title or the respective explanation, it is supposed to have the specific keyword convenient for extracting the document [39]. Moreover, the title or the explanation is not incorporated with more data for the user to search the required content [37]. The presence of certain information of the content, title, and some information can solve the existing limitation.
To overwhelm this challenge, this paper adopts the CBDIR system. The main benefit of the CBDIR system is
Apart from those advantages, its main feature lies in its ability to provide fast communication with broadly used web floor through the standard JSON format. Here, LDA- based framework is used to extract the exact keyword from the respective content. Further, it compares the performance of the proposed CBDIR system with the conventional IR systems.Information retrieval is facilitated by advanced compression techniques [32] [33] and modern data transmission technologies [31]. Since the heuristic methods are promising in many applications [34] [35]. As the proposed method extracts the keyword, it can obtain the actual content. Thus the presence of actual content, title or the explanation makes the proposed method, a better algorithm for the users depending on reliable IR system. In addition, the proposed CBDIR system is more suitable for real-time applications [29] [30] with convenient speed. In fact, the utilization of inverted indexing and B-tree based indexing can enhance the speed of the system.
II. LITERATURE REVIEW
In fact, various researchers have been analyzed the content-based information retrieval system. Based on their contributions, this system is applicable in several domains like images [22] [21], music [23] and documents [20]. As this paper are concerning on the document section, this section provides the review based on the retrieval of information from documents. Based on [19] and [18], the effective performance of CBDIR system can be accomplished only by modeling the data with two types of topic model. LDA and Probabilistic Latent Semantic Indexing (pLSI) are those topic models. A productive topic model called LDA plays a prominent role as it has been widely adopted in diverse domains. Various researchers have provided the evaluation of topic modelling in the field of IR system. For instance, one of those includes the usage of LDA for ad-hoc IR system [17] [16]. Since the performance of LDA in [17] [16] is seemed to be better. This paper adopts the LDA as the topic model.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
Further, in 2007, Gabrilovich and Markovitch [14] have used the combination of inverted indexing and explicit semantic analysis to show the required passage from Wikipedia. Moreover, in 1979, Comer [13] has provided the explanations associated with B-tree indexing. In 2012, Von and Datta [12] had used the indexing method to exhibit the retrieval process in NoSQL database. Even more, Wei et al. [11] have operated the NoSQL database to replace with Relational Database Management System (RDBMS). Hence effective and efficient IR systems have been achieved through the usage of techniques mentioned above. The current research utilizes the NoSQL database and modifies the inverted indexing and B-tree based indexing models.
III. CBDIRSYSTEM MODEL
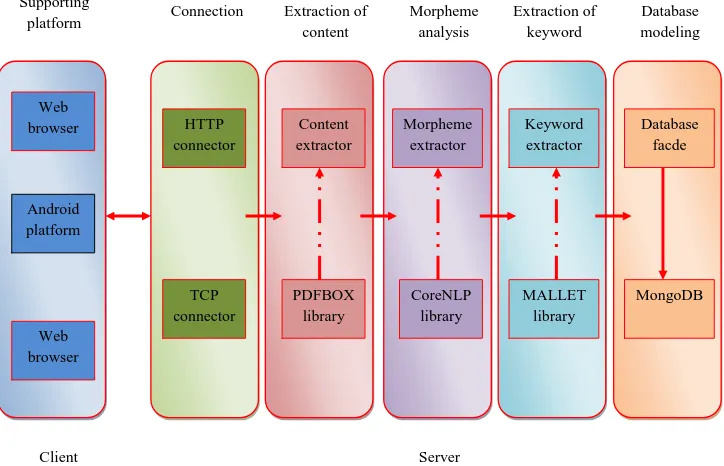
The proposed IR system by CBDIR is operated on the basis of actual contents of the data uploaded by the users. The format of the respective document is in DOC, PPT, or PDF. In fact, the Adobe systems develop the PDF whereas the Microsoft MS Office develops the PPT or DOC. The overall architecture of the proposed CBDIR system is shown in Fig. 1. Here, the transmitter side and the receiver side are termed as the client and the server respectively.
The client transmits the title and the small explanation associated with the content and the respective document to the server. The platform used by the client should be a web browser, Apache Tomcat, etc. Moreover, the server side must use the proposed CBDIR system to retrieve the required information.
Thus the information that the client transmitted to the server is retrieved by the server side using the CBDIR system. Further, the database scheme for the IR system is formulated at the server side. In fact, the CBDIR system is adopted based on five steps.
Provide the connection
Extraction of content
Morpheme Analysis
Extraction of keyword
Modeling of database
Thus the initial step of the CBDIR system relies on the formation of the link between the client and the server. Then the required content is extracted from the document, and the morpheme analysis also captures a group of elements in the content. Further, it is essential to produce the exact keyword that is fitting with all the morphemes and constructs the database scheme using the database modeling with the extracted keyword.
Supporting
platform Connection Extraction of content
Morpheme analysis
Extraction of keyword
Database modeling
Web browser
Android platform
Web browser
HTTP connector
TCP connector
Content extractor
PDFBOX library
Morpheme extractor
CoreNLP library
Keyword extractor
MALLET library
Database facde
MongoDB
[image:2.612.126.488.427.660.2]Client Server
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
IV. METHODOLOGY
A. Connection
In the initial step, there is a link provided between the client and the server. Here, the proposed CBDIR system is used at the server side to where the information is needed to retrieve. The information includes the title, small explanation and the respective document uploaded by the user is sent to the client to the server. As mentioned earlier, the server is CBDIR system which response to the client regarding the transmitted data. A pre-defined protocol such as HTTP or TCP is used to build up the connection between the client and the server. In general, the format of the transmitted data should be in JSON, which is considered as the public standard format convenient for conveying data between the client and the server [10]. The format which is independent of the platform and data format is the main benefit of JSON. In general, JSON format is accessible in diverse categories of platforms and computing languages. It can directly provide the basic information of the content such as its title, small explanation, ID of the respective content, ID of the user and the content of the record. Moreover, the appropriate connection is provided based on the clients’ system.
B. Extraction of Content
This step extracts the required data from the transmitted document. Here, it mostly uses the document in PDF files. Moreover, an open source library PDFBOX is adopted to capture the required content from the document. In fact, Apache offers the PDFBOX library [9].
C. Morpheme Analysis
Morpheme analysis is a method that is used to extract the relevant morphemes from the extracted content. It is performed by tokenizing the content into morphemes. Mostly, morphemes in terms of verbs or nouns are extracted from the content. Since the verb and noun offer the relevant sense of the content, the other morphemes can be eliminated. The openly accessible CoreNLP library is used as a morphological analyzer by the CBDIR system [8]. Furthermore, the information like URLs, e-mail and other special characters are avoided during the pre-processing stage. The lexical section is obtained by tokenizing the required sentence. In addition, it converts the verb or noun into lemma.
D. Extraction of Keyword
In this section, it extracts the exact keyword from the Morphemes such as verb or noun. Here, it uses the LDA modeling to take the keyword.
In general, LDA is one of the renowned topic modeling methods among the different conventional modeling. Here it uses MALLET library for LDA, which is a publically available library. The fundamental benefit of the LDA method is its high processing speed of the documents on time. In addition, it can alo be adaptable in real-time applications to extract the required topic from the document. Although the keyword is already present in the title and the small description that is defined by the user, the LDA modeling is applied only to the document body content.
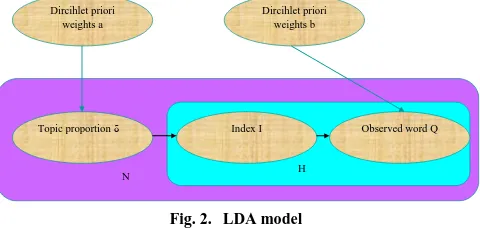
LDA model: LDA is defined as ―the generative probability model that assumes several topics allocated under Dirichelt distribution in a specific document.‖ The
graphical representation associated with the extraction pattern using LDA is shown in Fig. 2. Here it extracts the relevant keyword from the extracted noun or verb of the document. In fact, the highly significant keyword is the word that holds high weights in the captured topics. There are different parameters available in LDA as shown in Fig. 2. Here, the number of documents is represented as Nand the number of rare keywords in the documents is denotes asH. The morpheme analyzer provides the verb or noun where its total count should attainN. Moreover, the observed word is denoted as Qand the index related to the
assigned topic is referred to asI. In addition, indicates the topic portion in the document and the Dirichelt priori weights of the words and topic is denoted as aand
brespectively. The total count of the topic should be allotted toT .
Dircihlet priori weights a
Dircihlet priori weights b
Topic proportion δ Index I Observed word Q
[image:3.612.326.566.501.616.2]H N
Fig. 2. LDA model
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
mn T
m
m
n TopicL Q
KeyQ
1
(1)
T
m m m n
a a TopicL
1
(2)
H
j
mj mn mn
word of
word of Q
1 # #
(3)
There are two conditions required to attain those parameters, which is represented in Eq. (4) and Eq. (5).
1
1
T
m
m
TopicL (4)
1 1
H
j mj
Q (5)
The keywords Lare obtained that are arranged in the ascending format ofTopicLm. Further, the extracted keyword is used to evaluate the performance of the proposed system.
E. Modeling of Database
The number of keywords L extracted from the LDA modeling is used for obtaining the database modeling.
The database system called MongoDB based NoSQL is used here. In fact, the MongoDB provides the flexible performance [6] [23], as it can store all kinds of information [4], which further uses the inverted indexing. In fact, a key is extracted from the content, which is considered as a word and the particular key stores the ID of the content. Furthermore, the particular key stores the extracted keyword, and the particular key is used to store and search the document. However, the practical scenario needs more keyword. It uses the B-tree based indexing by MongoDB to overwhelm the limitation. Hence, inverted indexing and B-tree based indexing can be used adopt the IR system even if in the availability of enormous data.
V. RESULTS AND DISCUSSIONS
A. Data Description
[image:4.612.87.526.488.693.2]The data used for the CBDIR system experimentation is taken from the Slide Share Search API. The respective data is composed of a title, small explanation and some information of the several documents. Moreover, the file format of the document is PDF, DOC, PPT, etc. There are six categories of representing the data include web scale, software defined, 3D printing, Internet of Things, Advanced Analytics and Computing Everywhere. The number of documents adaptable to each category is shown in Table I, where it uses the document with the English language.
TABLE I
REPRESENTATION OF EACH CATEGORY WITH TOTAL NUMBER OF DOCUMENTS
Category Web
scale
Software defined
3D printing Internet of
Things
Advanced Analytics
Computing anywhere
Number of Documents 14 25 15 18 15 20
TABLE II
REPRESENTATION OF EACH CATEGORY WITH TOTAL NUMBER OF KEYWORDS
Category Web
scale
Software defined
3D printing Internet of
Things
Advanced Analytics
Computing anywhere
Number of Documents 17 24 12 14 14 25
TABLE III
REPRESENTATION OF EACH CATEGORY WITH JACCARD SIMILARITY
Category Web scale Software defined 3D printing Internet of Things Advanced Analytics Computing anywhere
Similarity 0.40 0.69 0.50 0.57 0.53 0.52
TABLE IV
REPRESENTATION OF EACH CATEGORY WITH ITS MEAN F-MEASURE
Category Web scale Software defined 3D printing Internet of Things Advanced Analytics Computing anywhere
Base line 0.33 0.30 0.50 0.27 0.22 0.20
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
B. Keyword Extraction
[image:5.612.349.539.155.288.2] [image:5.612.115.221.231.302.2]The keywords are extracted from the title, small description and other content of the document and the respective details are shown in Table II. The total number of the topic Tis needed to compute, which is done by the LDA model, and the parameter settings are shown in Table V.
TABLE V LDA PARAMETERS
Parameter Value
a 1
b 0.1
T 5
Number of iteration 800
C. Performance Evaluation
The performance evaluation is done by computing the precision, recall, and F-measure and compared with the baseline. The formulation of the precision, recall, and F-measure is shown in Eq. (6), Eq. (7) and Eq. (8), respectively, where Rindicates the relevant document and
Sindicates the retrieved documents.
S S RP (6)
RS R
C (7)
C P
C P F
2 (8)
The performance comparison of F-measure of CBDIR system with the baseline is shown in Table IV. Here, the performance of CBDIR system is 51.51%, 60%, 56%, 85.18%, 62.06% and 90% better than the baseline for web scale, software defined, 3D printing, Internet of Things, Advanced Analytics and Computing anywhere respectively.
[image:5.612.105.286.399.501.2]Further, the performance of each keyword in 3D printing in terms of F-measure, recall, and precision is shown in Table VI, which shows its superior performance.
TABLE VI
PERFORMANCE MEASUREMENT OF SOME KEYWORDS OF 3D PRINTING
Keyword Precision Recall F-measure
Physical structure 0.68 1 0.80
Chennai 1 1 1
Observation 1 0.28 0.43
Television 0.87 0.32 0.91
Printer 0.96 0.87 0.91
Architecture 1 0.84 0.91
3D 1 1 1
Succession 0.74 1 0.85
Manufacturing 0.87 0.92 0.89
Technology 0.52 0.77 0.62
Mean 0.86 0.80 0.83
VI. CONCLUSION
This paper has presented a novel method called CBDIR system to retrieve the information from the actual content of the document. The experiment was carried out for real data, and the current performance was compared with the baseline. For the performance analysis, the measures such as precision, recall, and F- measure were determined for the CBDIR and baseline. The performance evaluation has noticed three benefits from the proposed method. The first benefit was its reliable interaction with any kinds of the client while using the JSON format. Here, MongoDB based NoSQL was used to support different categories of data. The next, benefit was its effective performance in extracting the keywords using LDA model. The main limitation of the traditional techniques is its information retrieval from the title or small description of the content, which is overwhelmed by the proposed CBDIR system that it extracts the information from the actual content of the document. Further, the speed of the proposed method was enhanced by optimizingT. The reliability of the proposed method was validated by comparing with the method without any indexing scheme. Thus the collective performance and speed are superior to the conventional techniques, which is proved by the performance analysis.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
Third, the memory space of the proposed model needs to be increased as high. Thus in future, the speed of LDA will increase and some other models such as explicit semantic analysis [1] and Hierarchical Dirichlet Processes (HDP) [2] will be used as the topic modeling methods.
REFERENCES
[1] O. Egozi, S. Markovitch, and E. Gabrilovich, "Concept-based
information retrieval using explicit semantic analysis," ACM Transactions on Information Systems (TOIS), vol. 29, pp. 8, 2011. [2] Y. W. Teh, M. I. Jordan, M. J. Beal, and D. M. Blei, "Hierarchical
dirichlet processes," Journal of the american statistical association, vol. 101, 2006.
[3] SlideShare Corp. (2006), "SlideShare developer search api,"
Available: http://www.slideshare.net/developers.
[4] K.-P. Lee, H.-G. Kim, and H.-J. Kim, "A social inverted index for social-tagging-based information retrieval," Journal of Information Science, vol. 38, pp. 313-332, 2012.
[5] B. G. Tudorica and C. Bucur, "A comparison between several
NoSQL databases with comments and notes,"Roedunet International Conference (RoEduNet), 2011 10th, pp. 1-5, 2011.
[6] K. Banker, MongoDB in action: Manning Publications Co., 2011.
[7] McCallum, Andrew Kachites, "MALLET: A Machine Learning for
Language Toolkit," Available: http://mallet.cs.umass.edu, 2002.
[8] K. Toutanova, D. Klein, and C. Manning, "Stanford Core NLP," ed:
The Stanford Natural Language Processing Group.
[9] Available: http://nlp. stanford. edu/software/corenlp. shtml.
Accessed, 2013.
[10] D. Crockford, "The application/json media type for javascript object
notation (json)," 2006.
[11] Z. Wei-ping, L. Ming-Xin, and C. Huan, "Using MongoDB to
implement textbook management system instead of MySQL," in Communication Software and Networks (ICCSN), 2011 IEEE 3rd International Conference on, pp. 303-305, 2011.
[12] C. Von der Weth a nd A. Datta, "Multiterm keyword search in NoSQL systems," Internet Computing, IEEE, vol. 16, pp. 34-42, 2012.
[13] D. Comer, "Ubiquitous B-tree," ACM Computing Surveys (CSUR),
vol. 11, pp. 121-137, 1979.
[14] E. Gabrilovich and S. Markovitch, "Computing Semantic
Relatedness Using Wikipedia-based Explicit Semantic Analysis," in IJCAI, 2007, pp. 1606-1611.
[15] J. Zobel, A. Moffat, and R. Sacks-Davis, "An efficient indexing technique for full-text d atabase systems," in PROCEEDINGS O F THE INTERNATIONAL CONFERENCE ON VERY LARGE DATA BASES, pp. 352-352, 1992.
[16] X. Wei and W. B. Croft, "LDA-based document models for ad-hoc
retrieval," in Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 178-185, 2006.
[17] L. Azzopardi, M. Girolami, and C. Van Rijsbergen, "Topic based language models for ad hoc information retrieval," in Neural Networks, 2004. Proceedings. 2004 IEEE International Joint Conference on, pp. 3281-3286, 2004.
[18] D. M. Blei, A. Y. Ng, and M. I. Jordan, "Latent dirichlet allocation," the Journal of machine Learning research, vol. 3, pp. 993-1022, 2003.
[19] T. Hofmann, "Probabilistic latent semantic indexing," in Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, pp. 50-57, 1999.
[20] G. Salton and C. Buckley, "Term-weighting approaches in automatic
text retrieval," Information processing & management, vol. 24, pp. 513- 523, 1988.
[21] M. S. Lew, N. Sebe, C. Djeraba, and R. Jain, "Content-based multimedia information retrieval: State of the art and challenges," ACM Transactions on Multimedia Computing, Communications, and Applications (TOMCCAP), vol. 2, pp. 1-19, 2006.
[22] V. N. Gudivada and V. V. Raghavan, "Content based image retrieval
systems," Computer, vol. 28, pp. 18-22, 1995.
[23] M. A. Casey, R. Veltkamp, M. Goto, M. Leman, C. Rhodes, and M.
Slaney, "Content-based music information retrieval: Current directions and future challenges," Proceedings of the IEEE, vol. 96, pp. 668-696, 2008.
[24] C. Zhai and J. Lafferty, "Two-stage language models for information
retrieval," in Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pp. 49-56, 2002.
[25] C. V. Forecast, "Cisco Visual Networking Index: Global Mobile data
Traffic Forecast Update 2009-2014," Cisco Public Information, February, vol. 9, 2010.
[26] W. B. Croft, D. Metzler, and T. Strohman, Search engines:
Information retrieval in practice: Addison-Wesley Reading, 2010. [27] E. Greengrass, "Information retrieval: A survey," 2000.
[28] K. S. S. Rao Yarrapragada and B. Bala Krishna, "Impact of tamanu
oil-diesel blend on combustion, performance and emissions of diesel engine and its prediction methodology",Journal of the Brazilian Society of Mechanical Sciences and Engineering, pp. 1-15,2016.
[29] Rao Yerrapragada. K. S.S, S.N.Ch. Dattu .V, Dr. B.
Balakrishna,"Survey of Uniformity of Pressure Profile in Wind Tunnel by Using Hot Wire Annometer Systems",International Journal of Engineering Research and Applications, vol.4(3), pp. 290-299, 2014.
[30] Kavita Bhatnagar and S. C. Gupta, "Investigating and Modeling the
Effect of Laser Intensity and Nonlinear Regime of the Fiber on the Optical Link", Journal of Optical Communications, 2016.
[31] K Bhatnagar and SC Gupta, "Extending the Neural Model to Study
the Impact of Effective Area of Optical Fiber on Laser Intensity", International Journal of Intelligent Engineering and Systems, vol.10, 2017.
[32] B.S. Sunil Kumar, A.S. Manjunath, S. Christopher, "Improved
entropy encoding for high efficient video coding standard", Alexandria Engineering Journal, In press, corrected proof, November 2016.
[33] BSS Kumar, AS Manjunath, S Christopher," Improvisation in HEVC
Performance by Weighted Entropy Encoding Technique" Data Engineering and Intelligent Computing, 2018.
[34] S Chander, P Vijaya, P Dhyani,"Fractional lion algorithm–an
optimization algorithm for data clustering" ,Journal of computer science, 2016.
[35] S Chander, P Vijaya, P Dhyani ,"DOFL: Kernel Based Directive Operative Fractional Lion Optimisation Algorithm for Data Clustering",International Review on Computers and Software, 2016.
[36] P. Vijaya, Satish Chander,"Fuzzy Integrated Extended Nearest
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 7, July 2017)
[37] Santosh Kumar Ray P. Vijaya, G. Raju, "S-MSE: A Semantic Meta
Search Engine Using Similarity and Reputation Measure", Journal of Theoretical and Applied Information Technology, vol. 60 (2), 2014.
[38] P Yadav and RP Singh, "An Ontology-Based Intelligent Information
Retrieval Method For Document Retrieval", International Journal of Engineering Science, 2012.
[39] P Yadav, RP Singh," OntDR: An ontology-based augmented method
for document retrieval,International Journal of Computer