International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
523
Pattern Mining Techniques of Data Mining
Vijay Subhash Patil
1, Prof. Neeta A. Deshpande
2PG Student, Department of Computer Engineering, MCOERC, Nashik, Maharashtra, India. Associate Professor, department of Computer Engineering, MCOERC, Nashik, Maharashtra, India.
Abstract— Frequent patterns are patterns that appear in a
data set frequently. This method searches for recurring relationship in a given data set. Several techniques have been proposed to improve the performance of frequent pattern mining algorithms. This paper presents revision of different frequent mining techniques including Apriori based algorithms, association rule based, Cp tree, and FP growth. A brief description of each technique has been provided. In the earlier, different frequent pattern mining techniques are compared based on various parameters of importance. We have studied different techniques for frequent pattern mining proposed by different researchers and scientists. Each technique has its own merits and demerits. Performance of particular technique depends on input data and available resources. These techniques are found in many applications such as market basket approach, including applications in marketing and e-commerce, classification, clustering, web mining, bio-informatics and finance.
Keywords— Data Mining, Frequent Patterns, Knowledge Discovery, Pattern Mining, Information Retrieval.
I. INTRODUCTION
Data mining refers to extracting or ―mining‖ knowledge from large amounts of data. Frequent pattern mining has been a focused theme in data mining research for previous decades. Abundant literature has been dedicated to this research and tremendous progress has been made. The literature has been ranging from appropriate and scalable algorithms for frequent itemset mining in transaction databases to numerous researchers, such as sequential pattern mining[1], structural pattern mining[2], correlation mining, associative classification[3], and frequent pattern-based clustering, as well as their wide applications. In this paper, we provide overall description of the current status of frequent pattern mining and discussed a few appropriate research directions. We consider that frequent pattern mining research has substantially broadened the scope of data analysis and will have deep impact on data mining methodologies and applications in the long run. However, there are still some types of challenging research issues that need to be solved before frequent pattern mining can claim a cornerstone approach in data mining applications.
This paper performs a high-level overview of frequent pattern mining methods, extensions and applications. With a rich body of literature on this theme, we organize our discussion into different techniques. Data mining has been applied in the areas such as loan/credit card approval predict good customers based on old customers (Banking),
identify those who are likely to leave for a
competitor(Customer relationship management), Fraud detection (telecommunications, financial transactions), identify likely responders to promotions (Targeted marketing) etc. The algorithm based on Apriori[4] and FP-tree[2] applied on association rule mining is most useful to discover frequent pattern.
Remainder of this paper is organized as follows. Section 2 gives the short discussion on data mining, KDD process and challenges involved in it. Section 3 gives the brief overview of recent work made in Frequent Pattern Mining (FPM) and also presents comparison of recent FPM methods followed by conclusion in section 4.
II. DATA MINING AND KNOWLEDGE DISCOVERY
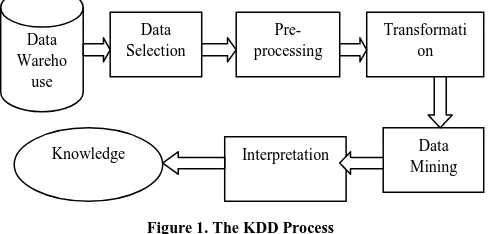
Data mining, also popularly referred to as knowledge discovery from data (KDD), is the automated or convenient extraction of patterns representing knowledge implicitly stored or captured in large databases, data warehouses, the Web, other massive information repositories, or data streams. Knowledge discovery as a process is depicted in Figure 1 and consists of an iterative sequence of the following steps:
1. Data cleaning- To remove noise and inconsistent data.
2. Data integration- Where multiple data sources may be
combined.
3. Data selection - Where data relevant to the analysis task are retrieved from the database.
4. Data transformation - Where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations, for instance.
5. Data mining - An essential process where intelligent methods are applied in order to extract data patterns. 6. Pattern evaluation - To identify the truly interesting
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
524 7.Knowledge presentation - Where visualization and
knowledge representation techniques are used to present the mined knowledge to the user.
[image:2.612.48.292.265.382.2]Steps 1 to 4 are different forms of data preprocessing, where the data are prepared for mining. From a database perspective on knowledge discovery, efficiency and scalability are key issues in the implementation of data mining systems. Having a large amount of redundant data may slow down or confuse the knowledge discovery process.
Figure 1. The KDD Process
Data Mining aims at clustering, Association Rules, Functional Dependencies, Data Summarization, Web Application, Image Retrieval, etc. Some of the challenges to the use of the data mining methodologies include the following:
• Scalability problem involved in extremely large
heterogeneous databases spread over multiple files. Data may be in different disks or across the web in different geographical locations and combining such data in a single very large file may be infeasible. • To improve prediction accuracy we need to evaluate
features and reduce datasets dimensionally.
• To handle dynamic changes in data we need to choose
appropriate metrics and evaluation techniques. • Integration of user interaction and knowledge domain.
• Quantitative estimation of performance.
• Efficient incorporation of soft computing tools. Data mining supports knowledge discovery by finding hidden patterns and associations, constructing analytical models, performing classification and prediction, and presenting the mining results using visualization tools. The subject of KDD has evolved, and continues to evolve, from the intersection of research from such fields as databases, Machine learning, pattern recognition, statistics, artificial intelligence, reasoning with uncertainties, knowledge acquisition for expert systems, data visualization, machine discovery, and high-performance computing.
KDD systems incorporate theories, algorithms, and methods from all these fields.
In general, we nominate yourself that knowledge discovery would be most effective if one could develop an environment for human-centered, exploratory mining of data, that is, where the human user is allowed to play a key role in the process.
III. VARIOUS FREQUENT PATTERN MINING TECHNIQUES
In the section we covered the basics of itemset mining. Most pertinent to this paper, three major classes of itemsets were introduced:
1.A frequent itemset is simply a set of items occurring a number of times with certain percentage.
2.A closed itemset is set of items which is as large as it can possibly be without losing any transactions.
3.A maximal frequent itemset is a frequent itemset which is not contained in another frequent itemset.
Unlike closed itemsets, maximal itemsets do not mean anything about transactions.
A. Association Rule Mining:
Association rule mining was proposed by Agrawal et al [3] to understand the relationship among items transactions or market baskets. For instance, if a customer buys cheese, what is the chance that he/she buys butter at the same time? This data may be useful for decision makers to determine strategies in a store. More formally, given a set I = {I1, I2,…, In} of items (e.g. mango, onion and knife, in a supermarket). The database contains a number of transactions. Each transaction ‗ t‘ is a binary vector with t[k]=1 if t bought item I[k] and t[k]=0 otherwise(e.g. {1, 0, 0, 1, 0}). An association rule is of the form X ÎIj, where X is a set of some items in I, and Ij is a single item not in X (e.g. {Tomato, knife} Î Plate). A transaction t satisfies X if for all items I k in X, t[k] = 1. The support for a rule XÎIj is the fraction of transactions that satisfy the union of X and Ij A rule X Î Ij has confidence c% if and only if c% of transactions that satisfy X also satisfy Ij.
Confidence (P→Q) = Probability (Q/P) =
The most common form of association rules is implication rule which is in the form of A→B, where A I, B I and A B = Ф. The support of the rule A→B is equal to the percentage of transactions in I containing A→B. The confidence of the rule A→B is equal to the percentage of transactions in D containing A also containing B. The mining process of association rule can be divided into two steps.
Data Wareho
use
Data Selection
Pre-processing
Transformati on
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
525 1. Generation of frequent item sets: It generates all sets of
items that have support greater than a certain threshold, called min support.
2. Generation of Rule association: The frequent item sets, generate all association rules that have confidence greater than a certain threshold called min confidence.
Association rule mining plays an important role in the literature of data mining. It may face many challenges for the development of efficient and effective methods. After taking a closer look, we find that the application of association rules requires much more investigations in order to aid in more specific targets. We may see a trend towards the study of applications of association rules. Apriori and FP-growth algorithms are used in mining association rules.
B. Apriori Principle Based Mining:
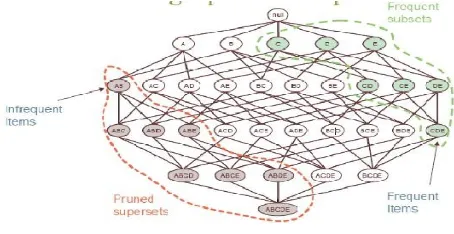
The Apriori principle calculates the probability of an item presented in a frequent itemset, given that another item or items is also present i.e. A subset of a frequent itemset must be frequent. E.g., if {biscuits, milk, nuts} is frequent, {biscuits, milk} must be. The Apriori is an influential algorithm for frequent item sets mining for Boolean association rules [3]. The Apriori method is Proposed by Agrawal & Srikant 1994[5]. It is a similar level-wise algorithm by Mannila et al. 1994[6]. Figure 2 illustates the working of Apriori principle. We may define
[image:3.612.57.284.532.649.2]Apriori Property: A subset of frequent itemset must be frequent. Join Operation: To find Lk , a set of candidate k-itemsets is generated by joining Lk-1 with itself. To find the frequent itemsets: the sets of items that have minimum support. A subset of a frequent itemset must also be a frequent itemset i.e., if {AB} is a frequent itemset, both {A} and {B} should be a frequent itemset.
Figure 2. Illustrating Apriori principle
Apriori Algorithm:
: Candidate itemset of size k.
: Frequent itemset of size k.
: {frequent items};
For (k=1; != Ф;k++) do begin
=Candidates generated from
For each transaction t in database do Increment the count of all candidates in that are contained in t
=candidates in with min_support
End Return .
Find frequent itemsets with cardinality from 1 to k (k-itemset) in iterations.Now Uses the frequent itemsets to generate association rules. According to Apriori property, All the subsets of a frequent itemset must also be frequent. We can determine that four latter candidates cannot possibly be frequent.
For example, let us take {I1, I2, I3}. The 2-item subsets of it are {I1, I2}, {I1, I3} & {I2, I3}. Since all 2-item subsets of {I1, I2, I3} are members of L2, We will keep {I1, I2, I3} in C3.
Let us take another example of {I2, I3, I5} which shows how the pruning is performed. The 2-item subsets are {I2, I3}, {I2, I5} & {I3, I5}. But {I3, I5} is not a member of L2 and hence it is not frequent violating Apriori Property. Thus We will have to remove {I2, I3, I5} from C3. Therefore, C3 = {{I1, I2, I3}, {I1, I2, I5}} after checking for all members of result of Join operation for Pruning. Now, the transactions in D are scanned in order to determine L3, consisting of those candidates 3-itemsets in C3 having minimum support.
At the end of each scan, transactions that are potentially useful are used for the next iteration. A technique called scan reduction uses candidate 2 item sets to generate subsequent candidate item sets. If all intermediate data can be held in the main memory, once scanning is required to generate all candidate frequent item sets. Another scanned data is required to verify whether the candidate frequent item sets are frequent or not.
C. FP-Growth Method:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
526 Frequent Pattern tree is used to design a compact data structure for the efficient frequent pattern mining.
Let the transaction database DB and the minimum support threshold be 3 (i.e., ξ = 3).A unique data structure can be designed based on the following observations: Since only the frequent items will play a role in the frequent-pattern mining, it is necessary to perform one scan of transaction database DB to identify the set of frequent items (with frequency count obtained as a by-product).
If the set of frequent items of each transaction can be stored in some compact structure, it may be possible to avoid repeatedly scanning the original transaction database. If multiple transactions share a set of frequent items, it might be possible to merge the shared sets with the number of occurrences registered account. It is easy to check whether two sets are identical if the frequent items in all of the transactions are listed according to a fixed order.
FP-tree is one of best approach to discover frequent pattern to overcome the drawback of the apriori algorithm. It requires only two passes of processing. One pass is required for ordering and structuring frequent items other pass is for inserting those frequent items in the tree. FP-tree as better performance than Apriori as reduce database scan. FP-growth method compresses a large database into a compact Frequent-Pattern tree (FP-tree) structure which is highly condensed, but complete for frequent pattern mining. This method avoids costly database scans. Following are the simple steps taken to perform pattern mining as, Scan DB once, find frequent 1-itemset (single item pattern). Order of frequent items is in descending order of their frequency. Scan DB again, construct FP-tree.
D. ECLAT Algorithm:
The Eclat algorithm is used to perform itemset mining. Zaki et al 2000 [8] used éclat algorithm for exploring vertical data format. The idea for the eclat algorithm is to use tid set intersections to compute the support of a candidate itemset avoiding the generation of subsets that does not exist in the prefix tree Units.
Algorithm:
The Eclat algorithm is recursively defined. Initially it uses all the single items with their tid sets. In each recursive call, the function Intersect Tid sets verifies each
item set-tidset pair with all the others
pairs to generate new candidates . If the
new candidate is frequent, it is added to the set . Then,
recursively, it finds all the frequent item sets in the branch. The algorithm searches in a Depth First Search manner to find all the frequent sets.
Eclat takes a depth-first search and adopts a vertical layout to represent databases, during which each item is pictured by a group of dealings IDs (called a tidset) whose transactions contain the item. It's tough to utilize the
downward closure property like in Apriori.
However, tidsets has a plus that there's no would
like for count support, the support of associate itemset is that the size of the tidset representing it. the most operation of Eclat is intersecting tidsets, therefore the dimensions of
tidsets is one among main factors affecting the time
period and memory usage of Eclat. The
larger tidsets are,the longer and memory are required. Zaki proposed a new vertical data representation, called Diffset, and introduced dEclat, an Eclat-based algorithm using diffset. Instead of using tidsets, they use the difference of tidsets (called diffsets). Using diffsets has reduced considerably the set size representing itemsets and thus operations on sets are much faster. dEclat had been shown to achieve significant improvements in performance as well as memory usage over Eclat, especially on dense databases. However, when the dataset is sparse, diffset loses its advantage over tidset. Therefore, Zaki suggested using tidset format at the start for sparse databases and then switching to diffset format later when a switching condition is met. Eclat is based on two main steps: 1) candidate generation and 2) pruning. In the candidate generation step,
each k-itemset candidate is generated from two
frequent and then its support is
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
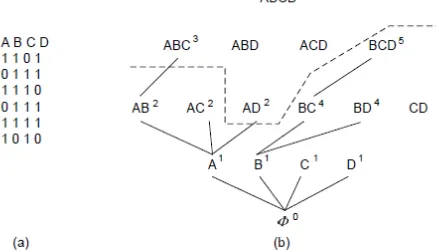
[image:5.612.56.297.131.294.2]527 Figure 3. Search tree on item base {a, b ,c, d, e}
Following the depth-first-search of Eclat we will pick the prefix and we can generate an equivalence class with item sets {ab, ac, ad, ae} which are all 2-itemsets containing. In this sub tree, we pick the prefix {ab} and the equivalence class we get consists of item sets {abc ,abd, abe}.We can see that each node in the tree is a prefix of an equivalence class with item sets right below it. It could be seen that Eclat does not fully exploit the downward closure property because of its depth-first search.
E. Mining Closed & Maximal Itemsets:
Mining closed and maximal itemsets uses vertical bitmap representation method that extracts the information by ANDing the columns. This method has better scalability & interoperability. Mining maximal frequent item sets is one of the most fundamental problems in data mining.
Figure 4. Bitmap representation of depth first search
Burdick et al [9] extend the idea in Depth Project and give an algorithm called Mafia to mine maximal frequent item sets. Similar to Depth Project, their method also uses a bitmap representation, where the count of an Item set is based on the column in the bitmap (the bitmap is called \vertical bitmap"). As an example, in Figure 4 (a), the bit vectors for items B, C, and D are 111110, 011111, and 110110, respectively. To get the bit vectors for any item set, we only need to apply the bit vector and-operation on the bit vectors of the items in the item set. From above example, the bit vector for item set BC is 111110 011111, which equals 011110, while the bitmap for item set BCD can be calculated from the bitmaps of BC and D, i.e., 011110 110110, which is 010110. The count of an item set is the number of 1's in its bit vector. Mafia is a depth algorithm. The testing order is indicated by the number on the top-right side of the item sets. Besides subset infrequency pruning and superset frequency pruning, some other pruning techniques are also used in Mafia. As an example, the support of an item set X, Y equals the support of X, if and only if XY = X this is the case if the bit vector for Y has a 1 in every position that the bit vector for X has 1. The last condition is easy to test. This allows us to conclude without counting that X, Y also is frequent. The technique is called Parent Equivalence Pruning.
For frequent itemset A, if there exists no item B such that every transaction containing A also contains B, then A is a frequent closed pattern. In other words, frequent itemset A is closed if there is no item B, not already in A, that always accompanies A in all transactions where A occurs. Closed itemsets are concise representation of frequent patterns. This can generate all frequent patterns with their support from frequent closed ones which helps to reduce number of patterns and rules in the extracting information from the given transactional dataset.
[image:5.612.61.279.512.638.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
[image:6.612.87.239.126.287.2]528
Figure 5. Maximal vs closed itemsets.
F. CP Tree:
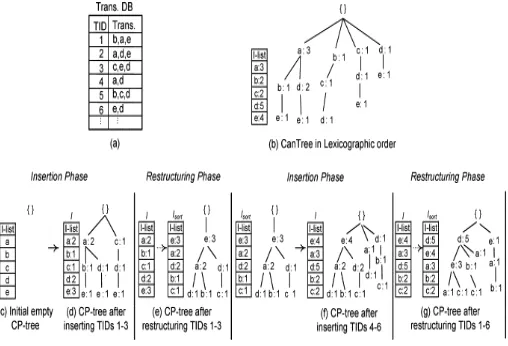
CP tree is also known as compact pattern tree that captures database information with one scan and provides the same mining performance as the FP growth method. The CP-tree [10] introduces the concept of dynamic tree restructuring to produce a highly compact frequency-descending tree structure at runtime.
This CP-tree method retains all items regardless of whether they are frequent or not in a tree structure. Since the CP-tree maintains the complete information for DB in a highly compact frequency-descending manner, it is quite easy to discover transactions to delete and or update, and insert new transactions into the tree. Thus, when adding new transactions into the tree, the transaction should be inserted according to current-list order. Consequently, by using the tree restructuring operation the final compact tree can have a higher count value at the uppermost portion of the tree.
CP-tree construction mainly consists of two phases:
(i) Insertion phase: firstly it scans transaction(s), and inserts them into the tree according to the current item order of I-list then updates the frequency count of respective items in the I-list (I-list maintains the current frequency value of each item).
(ii) Restructuring phase: Secondly this phase rearranges the I-list according to frequency-descending order of items and restructures the tree nodes according to this newly rearranged I-list.
These two phases are dynamically executed in alternate fashion, starting with the insertion phase by scanning and inserting the first part of DB, and finishing with the restructuring phase at the end of DB.
[image:6.612.325.579.462.635.2]Another objective of the periodic tree restructuring technique is to construct a frequency-descending tree with reduced overall restructuring cost. The construction of a CP-tree starts with an insertion phase. As shown in the figure 6 The first insertion phase begins by inserting the first transaction b, a, e into the tree in a lexicographical item order Since the tree will be restructured after every three transactions, the first insertion phase ends here and the first restructuring phase starts immediately. Since items so far are not inserted in frequency-descending order, the CP-tree at this stage is like a frequency-independent tree with a lexicographical item order. To rearrange the tree structure, first, the item order of the I-list is rearranged in frequency-descending order, and then the tree is restructured according to the new I-list item order. It can be noted that items having a higher count value are arranged at the upper most portion of the tree; therefore, the CP-tree at this stage is a frequency-descending tree offering higher prefix sharing among patterns in tree nodes. The first restructuring phase terminates when the full process of I-list rearrangement and tree restructuring is completed. The CP-tree construction will enter into the next insertion phase, thereafter. The CP-tree repeats this procedure until all transactions of a database are inserted into a tree. The CP-tree improves the possibility of prefix sharing among all the patterns in DB with one DB scan. Thus, more frequently occurring items are more likely to be shared and thus they are arranged closer to the root of the CP-tree.
Figure 6 CP tree insertion and restructuring phase
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
529 G. Sliding Window Method:
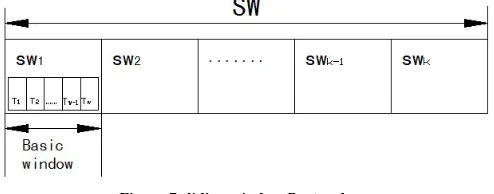
[image:7.612.52.299.276.373.2]Suppose I = {i1,i2,…,in} be a set of all data items, item set X is a subset of complete data items I sub-sets (X , I), some items containing k items are k-item sets. Transaction T is an item set, data stream can be seen as a continuous arriving transaction sequence DS = {T1, T2, ..., TN}. Let T1 be the transactions of earliest arrival time in data stream, TN be the latest arrival transactions in the data stream. Let w represent the fixed size of basic sliding window, that is, there are only w recent transactions in the basic sliding window [11].
Figure 7 sliding window Protocol
Data stream DS can be segmented according to the number W, each w transactions correspond to as a sub-sequence data stream, that the corresponding size (or width) of the basic sliding window is w. The current basic sliding window is represented as: swi={T‘1,T‘2,…,T‘w}, where sw indicates the basic sliding window, i is the current window number of the window (i.e., the i-th basic window). The sliding window SW consists of a continuous series of basic window swi, which denotes as <sw1, sw2,…, swk >,sliding window contains the numbers of the window is the size of the sliding window, denoted by | SW | = k. The size of a sliding window defines the desired life-time of information in a newly generated transaction. a sliding window method is used to find recently frequent itemsets over an online data stream. The recent change of a data stream can be adaptively reflected to the current mining result of the data stream.
IV. CONCLUSION
We have studied several frequent mining techniques used in data mining. Our analysis has showed that every technique is a unique and has equivalent merit and demerit and also compared each technique with one another.
In future we would like to study and evaluate the applications of each technique in the real world scenario. Performance of particular technique depends on input data and available resources. These techniques are found in many applications other than market basket approach, including applications in marketing and e-commerce, classification, clustering, web mining, bio-informatics and finance.
REFERENCES
[1] Agrawal, R. and Srikant, R. 1995. Mining sequential patterns. In Proc. 1995 Int. Conf. Data Engineering (ICDE‘95), Taipei, Taiwan, pp. 3–14.
[2] Pei, J., Han, J., Lu, H., Nishio, S., Tang, S., and Yang, D. 2001. H-Mine: Hyper-structure mining of frequent patterns in large databases. In Proc. 2001 Int. Conf. Data Mining (ICDM‘01), San Jose, CA, pp. 441–448.
[3] Agrawal, R., Imielinski, T., and Swami, A. 1993. Mining association rules between sets of items in large databases.
[4] Goswami D.N. et. al. ―An Algorithm for Frequent Pattern Mining Based On Apriori‖ (IJCSE) International Journal on Computer Science and Engineering Vol. 02, No. 04, 2010, 942-947.
[5] Agrawal, R. and Srikant, R. 1994. Fast algorithms for mining association rules. In Proc. 1994 Int. Conf. Very Large Data Bases (VLDB‘94), Santiago, Chile, pp. 487–499.
[6] Agrawal, R., Mannila, H., Srikant, R., Toivonen, H., and Verkamo, A.I. 1996. Fast discovery of association rules.
[7] Han J, Pei J, Yin Y (2000) Mining frequent patterns without candidate generation. In: Proceeding of the 2000 ACM-SIGMOD international conference on management of data (SIGMOD‘00), Dallas, TX, pp 1– 12.
[8] ZakiMJ(2000) Scalable algorithms for association mining. IEEETransKnowl Data Eng 12:372–390.
[9] Burdick D, Calimlim M, Gehrke J (2001) MAFIA: a maximal frequent itemset algorithm for transactional databases. In: Proceeding of the 2001 international conference on data engineering (ICDE‘01), Heidelberg, Germany, pp 443–452 .
[10] Tanbeer, S. K., Ahmed, C. F., Jeong, B.-S.,& Lee, Y.-K. (2009). Efficient single-pass frequent pattern mining using a prefixtree. Information Sciences, 179(5), 559583.