2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
A Multi-view Facial Expression Recognition Method Based on
Discriminative Shared Gaussian Process Latent Variable Model
Jun HE, Zhong-wen HE
*and Yue LIU
College of Information and Engineering, Nanchang University, Nanchang, 330031, China
*Corresponding author
Keywords: Multi-view facial expression recognition, Incremental update parallel cascade of linear
regression, Discriminative shared gaussian process latent variable model.
Abstract. The traditional multi-view facial expression recognition method is adopted view-specific classifier to recognition view-specific sample. This approach ignores the fact that different views of a facial expression are just different manifestations of the same facial expression. To address this, a multi-view facial expression recognition method based on Discriminative Shared Gaussian Process Latent Variable Model is proposed. Firstly this method extraction Incremental Update Parallel Cascade of Linear Regression feature, then its uses PCA to select the feature, finally adopts Discriminative Shared Gaussian Process Latent Variable Model to recognition Multi-view facial expression. The experiment carried on CMU-PIE database and LFPW database show the effectiveness of our method.
Introduction
Human emotion recognition [1] has attracted significant research attention because of its usefulness in many applications, such as Human Computer Interaction. Facial expression recognition has been extensively studied in controlled environment where the persons are relatively still facial expressions in a nearly frontal pose [2]. And also, mostly facial expression datasets is frontal pose [3] [4]. However, many real-world applications relate to human computer interactions, in which people tend to move their head while being recorded. Furthermore, depending on the camera position, facial images can be taken from different views. For this reasons, there is an ever-growing need for perform multi-view facial expression recognition.
To date, only a few shape features extraction that deal with multi-view facial expression have been proposed. Most notable example are Active Appearance Models (AAM) [5] and Robust Discriminative Response Map Fitting with Constrained Local Model [6]. Without exception, these methods rely on a static generic model that is built completely on off-line training data and needs a lot of time. To address this, we proposed a multi-view facial expression recognition method based on Discriminative Shared Gaussian Process Latent Variable Model. Firstly, we used Incremental Update Parallel Cascade of Linear Regression to extraction facial expression shape feature, and then we use PCA to select the feature, finally adopts Discriminative Shared Gaussian Process Latent Variable Model to recognition Multi-view facial expression. The experiment carried on CMU-PIE database and LFPW database show the effectiveness of our method.
The remainder of the paper is organized as follows. In section 2, we present the theoretical background of the Discriminative Shared Gaussian Process Latent Variable Model (DS-GPLVM). Section 3 describes the experimental results. Finally, in section 4 we conclude the paper.
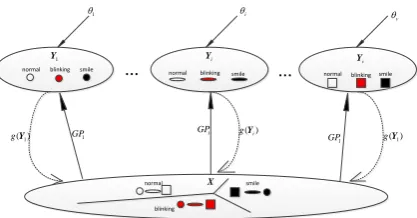
Discriminative Shared Gaussian Process Latent Variable Model
normal smile normal smile normal smile normal smile 1 Y v Y i Y ... ... 1 GP 1 ( )
gY GPi g( )Yi
1 ( ) gY 1 GP 1
i
[image:2.595.194.403.74.183.2]v X blinking blinking blinking blinking
Figure 1. Discriminative shared gaussian process latent variable model.
In this model, we assume that we have V views facial expression pictures, and Y{Y(1),...,Y( )V} is represented corresponding facial expression features, where each view is represented with a high-dimension observation space ( ) ( ) ( )
1
[ ,..., ] , 1,...,
v v v T N D
N R v V
Y y y , and N , D are the number of facial expression pictures and the dimension of the observation view facial expression features, respectively. We seek to find a low-dimension shared manifold [ 1,..., N]T RN q
X x x ,
where q D is the dimension of the manifold that generates all V views simultaneously. Formally, using the Shared Gaussian Process (GPs) framework, we can get the joint likelihood of
V views as
(1) (1) ( ) ( )
( | , s) ( | , )... ( V | , V )
p Y X pY X pY X (1) where the likelihood of the observed data from the view v, given the manifold, is
( )
( ) 1 ( ) 1 ( ) ( )
(2 )
1
( | , ) exp( (( ) ( ) ))
2
D ND v
v v v V v T
p tr
K
Y X K Y Y (2)
where (1) ( )
{ ,..., v}
s
is the kernel matrix. In order to obtained posterior distribution of the manifold
( , | ) ( | , ) ( )
p X Y pY X p X (3) We need to define p( )X . To define a discriminative shared-space prior for multi-view facial expression shape features learning, we generalize the Gaussian Markov Random Field prior. To address this, we need construct the view-specific weight matrices ( )
( 1,..., )
v
v V
w . Specially, the elements of the weight matrix are obtained by applying the Radial Basis Function Kernel to the data from each view as
( ) ( )
( ) exp ( ) ,
0 .
if and
v v
i j
i j
v v
ij
i j c c
W t
otherwise
y y
(4)
where yi( )v is the i-th sample in Yv, ciis the class label, and t( )v is the kernel width in Yv. Then, the graph Laplacian for view v is L( )v D( )v W( )v , where D( )v is a diagonal matrix with
( )
( )v v
ii j ij
D
W . Because the graph Laplacians from different views vary in their scale, we use thenormalized graph Laplacian, defined as ( ) ( ) 1 2 ( ) ( ) 1 2
( ) ( )
v v v v
N
L D L D . Subsequently, we define the joint Laplacian as
(1) (2) ( )
...
V
N N N
L L L L E (5)
1
( )
1
1
( ) ( | ) exp ( )]
2
V V
v T
v q
p p tr
V Z
X X Y X LX (6)
In which Zqis a normalization constant and 0 is a scaling parameter. The discriminative
share-space prior aims at maximizing the class separation in the manifold learned from data from all the views. Put (1), (6) into (3) and maximize the likelihood function is the required manifold. Just like the discriminative Gaussian Process latent variables model, we also need to learn the back-mappings from the observed spaces to the manifold. Another role of these back-mappings is to constrain the learning of the shared manifold by acting as additional regularizers in the model, enforcing the data that are close in the observation space to be close on the manifold. This cannot be attained by the discriminative prior introduced above as it ensures the opposite – that the data close on the manifold are close in the observation space. Therefore, we define V sets of constraints that enforce separate inverse mappings from each view to the shared space. We refer to these as independent back-projections (IBP), and they are given by
( ) ( ) ( ) ( )
( v , v ) bcv v
g
X Y A K A (7)
where the elements of ( )v bc
K are given by ( , ) exp( 2) 2
bc i m i m
k y y y y with being the inverse
width of the kernel. Note that for a single view, the model can be re-parameterized to obtain X as a function of the back-mapping parameters. Then, classification of the target facial expression is accomplished by using a single classifier (we used the k-NN classifier) trained directly in the learned shared space.
Experiments
In this paper, we evaluate the performance of the multi-view facial expression recognition method based on Discriminative Shared Gaussian Process Latent Variable Model. The experiment carried on CMU-PIE database [7] and LFPW database [8]. In section 3.1, we evaluate the effectiveness of the multi-view facial expression recognition method based on Discriminative Shared Gaussian Process Latent Variable Model. In section 3.2, we evaluate the effectiveness of the Incremental Update Parallel Cascade of Linear Regression shape feature extraction method.
Multi-View Facial Expression Recognition Method on CMU-PIE dataset
Figure 2. Incremental update parallel cascade of linear regression on CMU-PIE dataset.
(a)Negative log-likelihood and Augmented Lagrangian(IBP-constrain)
(b)Norm of back projections( IBP-constrain)
(c)change of latent space (d)the mean classification rate, as a function of the number of ADM cycles
0 2 4 6 8 10 12 14 16 103.704
103.706 103.708 103.71 103.712
Number of ADM cycle
C o s t fu nc ti o n Negative log-likelihood Augmented Lagrangian
0 2 4 6 8 10 12 14 16 0 0.02 0.04 0.06 0.08 0.1 0.12
Number of ADM cycle
C h a n g e o f la te n t s pa c e
0 2 4 6 8 10 12 14 16 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0.22
Number of ADM cycle
N o rm o f b a ck p ro je cti o n s
IBP View 1 IBP View 2 IBP View 3 IBP View 4 IBP View 5 IBP View 6
0 2 4 6 8 10 12 14 16 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1
Number of ADM cycle
[image:4.595.104.495.216.303.2]C la s s if ic a ti o n R ata IBP View1 IBP View2 IBP View3 IBP View4 IBP View5 IBP View6
Figure 3. Discriminative shared gaussian process latent variable model results in CMU-PIE.
[image:4.595.69.525.500.566.2]However, in the first step, we select the closet head-pose (C5(View1)) to the training pose by using the Sparse Variational Multi-Class GP Classifier[9]. Once the view is known, we apply the view-specific Sparse Variational Multi-Class GP Classifier to perform facial-expression classification. As we can seen in the table 1, we known that the result of C5(view1) is 85.01%. Similarity, the results of C7(View2), C9(View3), C11(View4), C27(View5), C29(View6) is 67.65%, 89.85%, 65.73%, 71.72%, 63.42%. However, we used the D-GPLVM to classification, the results of the C5(View1), C7(View2), C09(View3), C11(View4), C27(View5), C29(View6) is 85.71%, 76.19%, 72.18%, 75.13%, 83.45%, 82.17%. Table 1 shows average recognition rate of the DS-GPLVM results are better than D-GPLVM and SGPMCC. And also, we use PCA to select 14 dimension features, the results just as shown in the table 2. We have the similar results.
Table 1. Multi-view facial expression recognition method on CMU-PIE dataset (21d).
Method C5(View1
)
C7(View2) C9(View3
)
C11(View4) C27(View5) C29(View6))
[image:4.595.68.524.590.630.2]DS-GPLVM 87.88% 81.82% 75.76% 78.79% 85.86% 84.85% SGPMCC 85.01% 67.67% 89.85% 65.73% 71.72% 63.42% D-GPLVM 85.71% 76.19% 72.18% 75.13% 83.45% 82.17%
Table 2. Multi-view facial expression recognition method on CMU-PIE dataset (14d).
Method C5 (View1) C7(View2) C9(View3) C11(View4) C27(View5) C29(View6) DS-GPLVM 84.62% 83.71% 73.08% 76.92% 93.30% 86.96%
D-GPLVM 80.12% 79.14% 72.13% 71.43% 87.77% 76.92%
Multi-View Facial Expression Recognition Method on LFPW dataset
table 4, we know that DS-GPLVM are better than D-GPLVM. But the DRMF need 14 seconds, and ILPCLR just only need 4 seconds. As we can seem in table 3 and table 4, we know than Classification rate on LFPW dataset for the ILPCLR feature are better than DRMF.
Incremental Update Parallel Cascade of Linear Regression feature Robust Discriminative Response Map Fitting
[image:5.595.200.397.251.291.2]Figure 4. Multi-view facial expression shape feature.
Table 3. Classification rate on LFPW dataset for the ILPCLR feature.
Method left frontal right
DS-GPLVM 66.67% 88.89% 77.78%
D-GPLVM 60.61% 76.92% 71.83%
Table 4. Classification rate on LFPW dataset for the DRMF feature.
Method left frontal right
DS-GPLVM 58.63% 83.92% 73.14%
D-GPLVM 52.17% 79.63% 72.83%
Conclusion
In this paper, we proposed the Multi-View Facial Expression Recognition method based on Discriminative Shared Gaussian Process Latent Variable Model. Firstly extraction Incremental Learning Parallel Cascade of Linear Regression feature, then its uses PCA to select the feature, finally adopts Discriminative Shared Gaussian Process Latent Variable Model to recognition Multi-view facial expression. The experiments show us that our approach is better than traditional multi-view facial expression recognition.
Acknowledgment
This paper was supported by The National Natural Science Fundtion of China with grant number 61463034.
References
[1] Guo Yimo, Zhao Guoying and Pietikainen M. Dynamic Facial Expression Recognition with Atlas Construction and Sparse Representation, IEEE Journals & Magazines (2016) 1077-1992.
[2] Happy, S. L., and A. Routray. Automatic Facial Expression Recognition Using Features of Salient Facial Patches, IEEE Transactions on Affective Computing (2015) 1-12.
[3] Shangfei Wang, Zhilei Liu, Siliang Lv, et al. A Natural Visible and Infrared Facial Expression Database for Expression Recognition and Emotion Inference, IEEE Transactions on Multimedia (2010) 682-691.
[4] O'Toole A J, Harms J, Snow S L, et al. A video database of moving faces and people, Pattern Analysis & Machine Intelligence IEEE Transactions on (2005) 812-816.
[5] Min Shaobo, Wang Xinyi and Su Ya. 3D real-time facial feature points tracking with improved particle filter, 2015 11th International Conference on Natural Computation (2015) 413-418.
[7] Sim T, Baker S, and Bsat M. The CMU Pose, Illumination, and Expression (PIE) database, Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition (2002) 46-51.
[8] Belhumeur P N, Jacobs D W, Kriegman D J, et al. Localizing parts of faces using a consensus of exemplars, IEEE Transactions on Pattern Analysis and Machine Intelligence (2013) 2930-2940.