International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012)96
Advanced Knowledge Extraction from WebPages using
Natural Language Processing
Suman Raina Bhat
1, Amiya Kumar Tripathy
2, Dominic George
3, Rivin Jose
4, Raul Pinto
5Don Bosco Institute of Technology, Mumbai, India 400070
1[email protected] 2[email protected]
3[email protected] 4[email protected] 5[email protected]
Abstract—Information on the World Wide Web has been added at an unprecedented rate. This disorganization has led to limitations in accessing in data. The time required in finding useful data has increased since the amount of web pages of lesser significance has also increased exponentially. Through Advanced Knowledge Extraction from WebPages using Natural Language Processing (AKEWNLP), the effective time required to find useful information can be significantly lowered. With ever increasing data on the World Wide Web, AKEWNLP can provide a sustainable option for making optimum use of Data Resources.
Keywords— Knowledge Extraction, Web mining, Intelligent Search, Knowledge extraction, Natural Language Processing.
I. INTRODUCTION
Internet is a massive source of knowledge, but the disordered organizational form of knowledge seriously obstacle the reuse and sharing of the knowledge, the widely
distributed Web applications can not achieve
interoperability [4, 11, 12]. In the face of massive Web data, it is not a wise approach that conversion and use of artificial structured and formal. Therefore it is necessary to design and develop a web page system that can automatically extract information. Text messaging is the most important part of the Web page, so information extracted is that extracted the text pages [4, 12]. From a large number of pages to extract the information they need to carry out re-organization and utilization [4].
Extraction of information aimed at providing people more effective information acquisition means to cope with a serious challenge which the information explosion brought about [13, 14]. The automatic extraction of information web page version in order to satisfy the reasonableness and timeliness of the integration of information resources involve many technologies, such as pre-processing the page, algorithms to the text document information extraction, analyzing and then extracting data as well as discovering the useful information [4].
The Internet is composed of billions of pages data accounting to astronomically large amounts of data. A bulk of the data cannot be useful in its raw form. Hence there is a gap between availability and usability of data. The Aim of a Knowledge acquire system is to create a filtration module which differentiates between useful data and unwanted noise.
Extraction of information aimed at providing people more effective information acquisition means to cope with a serious challenge which the information explosion brought about. Web information extraction is the process, which extract a specific category of information from the Web page and make it into the structured data, and then write into the database to supply user queries.
Therefore it is necessary to design and develop a web page system that can automatically extract information. Text messaging is the most important part of the Web page, so information extracted is that extracted the text pages. From a large number of pages to extract the information they need to carry out re-organization and utilization.
The presents scenario of Internet search usage is the accessing a search engine followed by entering query. The search engine returns a list of probable desired results based on the page ranking mechanism adopted by the search engine and does not necessarily be in line with the requirements of the user. Individually the user has to be redirected to several pages and has to manually filter out information that’s beneficial from the rest. This process is both time consuming and inefficient.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012)97
Apart from this the proposed system it can able to improve the relative speed and efficiency of the knowledge extraction process, which in turn will make it possible to be used in search engines to give better search results for user searches and other database oriented system where frequent searches are required.
II. METHODOLOGY &DESIGN OF PROPOSED SYSTEM
In this project we propose the combination of multiple paradigms: Human Compute Interaction, Natural Language Processing, Logic & Ontology and Network Services for building distributed systems and knowledge representation. In the present scenario a widely accepted prediction is that computing will move to the background, weaving itself into the fabric of our everyday living spaces and projecting the human user into the foreground. If this prediction is to come true, then next generation computing, which one can call human computing, should be about anticipatory user interfaces that should be human-centered, built for humans based on human models [2, 10]. It should surpass the traditional keyboard and mouse to include natural, human-like interactive functions including understanding natural language processing and emulating certain human behaviours.
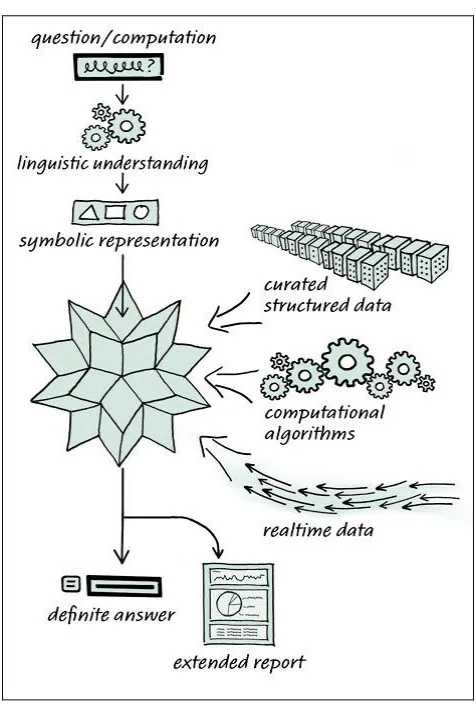
Taking into account techniques, it can be stated as follows: initially the relevant page source files, being in line with key words should be stored in the communication process the, files should be scanned and matched one by one to extract important information in the users’ significance, later accumulate and sort out information apt, and then present a perfect knowledge construction. After the analysis of the keywords the appropriate webpage can be extracted by using its URL which can also be used for future references (Figure 1).
A. System Components
The four core modules used for implementation of the system are Human Computer Interaction (HCI), Natural Language processing (NLP), Network Services and Logic and Ontology. The combination of these major components helps the system to epistemologically analyze any given user query and enables the system to understand the meaning of the query as accurately as possible so as to bridge the gap between the user query and the systems understanding about the submitted query. Now bridging the gap involves creating an interface or mediation between the natural knowledge of the user and the analytical execution power of the computers.
HCI: helps in reduces the communication barrier
[image:2.612.325.563.254.611.2]between the user and the system by use of interactive and ergonomic interfaces for interaction with the system. NLP is the key module of the all as it is the part which helps to breakdown the complex user queries into meaningful and non redundant token, such as parts of speech, removal of tags etc. Logic and Ontology helps to establish relation between various user keywords which are processed using Natural Language processor. Network services is used for real-time acquire of knowledge.
Figure 1. System structure
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012) [image:3.612.50.287.130.344.2]98
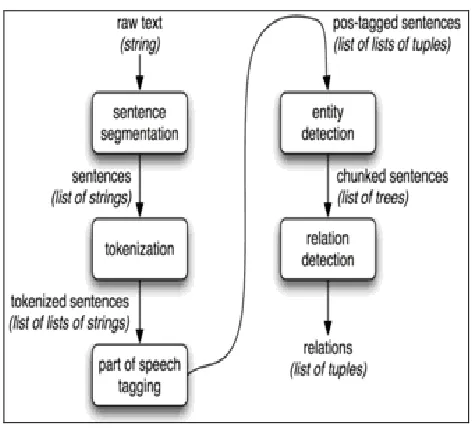
Figure 2. System Flow of NLP in the system
NLP: The simplest processing just removes stop words and uses statistical approaches. Natural language processing is the process of using linguistic analysis to infer meaning from human-written text that could be extracted using the individual word meanings [10]. The main theme of using NLP is that the system would be able to paraphrase an input text, translate the text into another language and draw inferences from the text. Generic NLP implementation in the system is shown in Figure 2, which shows the implementation principles for NLP. It mainly involves segmentation of raw text into sentences, followed by tokenization of sentences into tokens as input for search. Then implementations of parts of speech/text are tagged and further processing is done for search oriented purposes.
Logic and Ontology: This concept/technique is used to evaluate the relations and bonds between various queries and the classification of the domain to which they belong to [1]. By using this model the knowledge which is extracted by the system for the user can be designated a domain and further deep search and information can be gathered which in turn can be used in future to provide the users with more accurate and efficient results and redundancies can be removed up to a very high satisfaction level.
Network Services: Network services are used in coalition with other three core modules to improve the performance of the system and to provide the user with up-to-date knowledge and also to improve text and knowledge mining to keep the knowledge database updated.
Goals of Network Services in this system are for live updates to updated services, analysis & comparison of knowledge base with current data to verify and remove redundancy, provide user a possibility to search for more information online, integrate the system with latest plug-ins and add-on services, etc.
B. Tools and Techniques used
Following are some of the technologies and frameworks used for implementing some modules and the technologies used for implementation of queries and knowledge database.
PHP: PHP is the hypertext processor used for interface and webpage design purposes. Furthermore it is also used to connect the frontend to the databases for query processing.
MySQL: MySQL is a relational database management system (RDBMS) that runs as a server providing multi-user access to a number of databases
Apache: The Apache HTTP Server is web server software notable for playing a key role World Wide Web. Apache supports a variety of features, many implemented as compiled modules which extend the core functionality. These can range from server-side programming language support to authentication schemes. Some common language interfaces support Perl, Python, and PHP.
MontyLingua: MontyLingua is a natural language processing toolkit. It is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for both the Python and Java programming languages. It is enriched with common sense knowledge about the everyday world from Open Mind Common Sense. From English sentences, it extracts subject/verb/object tuples, extracts adjectives, noun phrases and verb phrases, and extracts people's names, places, events, dates and times, and other semantic information. The functions carried out by MontyLingua are: text parsing tokenize sentences, tokenize words, parts of speech tagging and chunk parsing [15].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012)99
III. SYSTEM IMPLEMENTATION
The function implementation of proposed prototype system using tools (discussed in earlier section) is addressed in this section as follows.
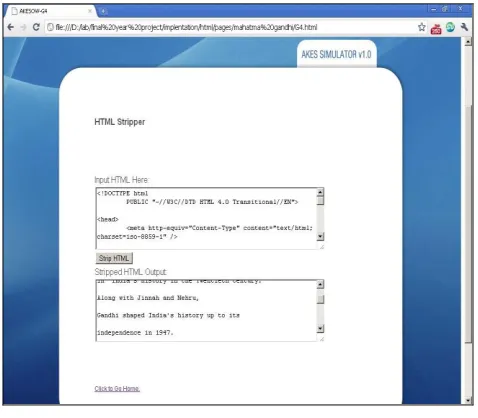
[image:4.612.336.570.134.249.2]HTML Stripper is used to remove the html tags from the webpage’s which are to be searched and processed for knowledge extraction. This is the preliminary stage in the system where pre-processing of the required pages is carried out (Figure 3).
Figure 3. HTML stripper
Thus it can be seen that the tags are removed before NLP processing which helps in reducing the time required for further processing. Html stripper works on the principle of identification and elimination of the tags. Identification of tags is a simple process since each tag has an opener and a closer. It works by storing the tags in an array and each tag is compared with others to find the closing tag. Once matching closing tag is found both the tags are removed.
[image:4.612.47.286.259.468.2]For further improvement of the algorithm it has been used various operations such as postfix, prefix etc. so that tags are remove strictly orderly manner. Also comments in the source code can also be scanned and removed using html stripper. Removing comments and notes helps a lot in removing redundant information from search point of view. Thus html stripper helps in removing unwanted tags, comments and other redundant data from the WebPages selected and thus performs a pre processing on them before they are being passed to MontyLingua NLP parser.
Figure 4. MontyLingua Interface for entering Query for NLP.
MontyLingua is used for Natural Language Processing of the stripped text from html pages (Figure 4). NLP involves finding parts of speeches, relation between the words and understanding the meaning of the sentences. MontyLingua was also used for the job of generating a summary of huge chunks of sentences which improves the quality of results by restricting redundant words and sentences which are irrelevant to the searched text and the result to be generated.
Figure 5. Extracted parts of speech and condensed summary of a query.
MontyLingua uses an inbuilt lexicon and a grammar model for analyzing and tagging parts of speech. MontyLingua was configured for various languages using lexicons and grammar rules for those languages. MontyLingua was performed NLP in two stages, once for the entered search term which enhances and improves the understanding of the search term from computer point of view (Figure 5).
[image:4.612.325.560.396.503.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012)100
[image:5.612.48.285.238.428.2]Human like search and analysis is similar to a person reading a book or paragraph to find answer for a question. Answers found by humans are often based on relationship between various components in the questions and tries to find the most appropriate answer rather than matching the keywords in query with the ones present in the book or the textual content, similar kind if experiment has been carried out through MontyLingua.
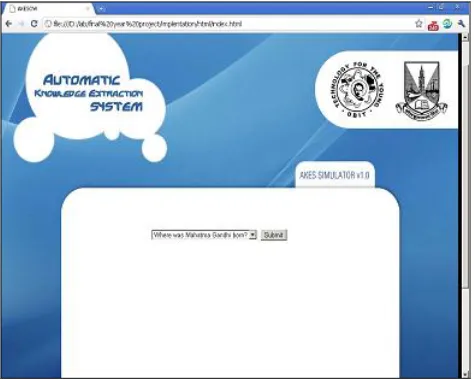
Figure 6. Homepage of accepting user search key and query
The homepage or the main interface of AKEWNLP consist of various user selections such as search, address search and other categorical search which may be implemented. Here we have implemented using html pages. Once entering the main page users are required to enter the search terms in the search box and press the submit button (Figure 6). Once the term is entered and search is initiated the system performs natural language processing on the terms and finds out the meaning of the term. It also tries to relate the relationship between various search terms and tries to create a logical and ontological relationship among them.
MontyLingua takes the search terms as input and performs various operations on them and establishes relationship between them. Now all the search terms were used and search was performed and various websites relating to the search terms are found. The ordering of WebPages was done on basis of page rank.
After the WebPages were selected, the pages were then passed through html parser which removes the unwanted tags form the WebPages and extracts only the text from them.
Now these extracted texts are passed through MontyLingua which further processes and summarizes the potential result texts from the extracted WebPages. Now the summarized results was be used to display the user the results of the search.
[image:5.612.324.561.329.499.2]Figure 7 shows the resultant page in the form of display screen. This screen shows the user entered query first to make sure that the result is for the query submitted by the user. Below this query indicator is the answer to the query which is often a single term or a textual well explained answer rather than a set of web links as found in common search engines. Apart from this the result page also shows the results for user entered query as well as other information such as relevant pages and their URL and page rank along with short abstract of the part from where the result of query is obtained.
Figure 7. Result display.
IV. OBSERVATION
It has been observed that AKEWNLP has shown significant improvement in performance in terms of quality of results and time taken for execution of query as compared to other traditional knowledge extraction systems. The use of logic and ontology combined with Natural Language Processing has yielded superior results as compared to using heuristic search approaches since the system is better able to understand the meaning of user query rather than just comparing the keywords against WebPages.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 2, February 2012)101
Montylingua has further enhanced the linguistic understanding of what the user is trying to express. Also the display of results as short answers has helped to reduce bandwidth consumption and improve the time required for the user to get the right results.
However it is has been recommended that the users should limit the amount of text used for querying as well as enter the most appropriate search terms which further helps to improve search times and provides better results. During the testing of system it is observed that the system is able to produce correct results at an astounding rate of 89.37%. One can say that the system is performing well considering its premature state of development.
V. CONCLUSION
In this work advanced Knowledge Extraction from WebPages using Natural Language Processing has attempted. The need for such a wealth of knowledge was motivated with examples of the intended use of a quality semantic text analyzer: question-answering systems, topic gusting, opinion extraction, etc. In this proposed system effort has been made to reduce the strain of the acquisition bottleneck by using a semantic analyzer to extract information on an unknown concept from an open corpus (the web), and compile this information into a well formed, new data structure for inclusion in the systems own existing static knowledge resources.
The system has been able to implement all the modules satisfactorily however due to limitations of hardware and available resources of computation it was not possible to harness all the goods and efficiency of the system. In order to be future compatible, the system has kept many open ends which can be used to extend the system using the latest technologies of the time. This system can thus be used as framework for upcoming knowledge oriented systems.
References
[1] Aldea A., Bañares-Alcántara R., Bocio J., Gramajo J., Isern D., Jiménez J., Kokossis A., Moreno A., and Riaño D.: An ontology-based knowledge management platform. In: Workshop on Information Integration on the Web (IIWEB’03) at IJCAI’03, 177-182, 2003.
[2] Maja Pantic, Alex Pentland, Anton Nijholt and Thomas S. Huang (2006), Human computing and machine understanding of human behavior: a survey; Proceedings of the 8th International Conference on Multimodal Interfaces, ICMI 2006, Banff, Alberta, Canada, November2-4, 2006, Pp: 239-248.
[3] H. Alani, S. Kim, D. E. Millard, M. J. Weal, W. Hall, P. H. Lewis, and N. R. Shadbolt. Automatic ontology-based knowledge extraction and tailored biography generation from the web. In IEEE Intelligent Systems, pages 14–21, 2003.
[4] Zhu Junwu, Jiang Yi and Xu Yingying; (2009) Automatic Knowledge Acquire System Oriented to Web Pages, Intelligent Information Technology Application, 2009. IITA 2009. Third International Symposium on , vol.2, no., pp.487-490, 21-22 Nov. 2009.
[5] Ben Shneiderman and Catherine Plaisant (2004). Designing the User Interface: Strategies for Effective Human-Computer Interaction, Pearson Addison Wesley (4th Edition) Pp: 107-111.
[6] Bing Liu,(2006) Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, First Edition, Dec 2006, Springer.
[7] Roberto Poli, Michael Healy and Achilles Kameas (2010); Theory and Applications of Ontology: Computer Applications, Springer, ISBN 978-90-481-8846-8.
[8] Alexander Clark, Chris Fox, and Shalom Lappin (2010); The Handbook of Computational Linguistics and Natural Language Processing, Wiley-Blackwell.
[9] Fakhreddine Karray, Milad Alemzadeh, Jamil Abou Saleh and Mo Nours Arab (2008), Human-Computer Interaction: Overview on State of the Ar; International Journal on Smart sensing and Intelligent systems, Vol. 1, No.1, March 2008.
[10]Yue Chen; "Natural Language Processing in Web data mining," Web Society (SWS), 2010 IEEE 2nd Symposium on , vol., no., pp.388-391, 16-17 Aug. 2010 doi: 10.1109/SWS.2010.5607419
[11]Doorenbos, R., Etzioni, O., and Weld, D. A Scalable Comparison-Shopping Agent for the World-Wide Web, In Proceedings of the First International Conference on Autonomous Agents, 39-48, 1997.
[12]Soderland, S., Fisher, D., Aseltine, J., Lehnerr,W. CRYSTALI: Inducing a Conceptual Dictionary. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, 1314- 1321, 1995.
[13]E. Bloedorn, I. Mani, and T. R. MacMillan. Machine learning of user pro_les: Representational issues. In Proceedings of the Thirteenth National Conference on Arti_cial Intelligence, pages 433{438. AAAI/MIT Press, 1996.
[14]Blum and T. Mitchell. Combining labeled and unlabeled data with cotraining. In proceedings of the 11th Annual Conference on Computational Learning Theory. ACM, 1998.