Knowledge Discovery for Mining Patterns in
Spatio-Temporal Databases
Upasna Singh, G.C. Nandi
Indian Institute of Information Technology, Allahabad. {upasnasingh, gcnandi}@iiita.ac.in
Phone No’s: 91-9897120059,91-9415235176
Abstract: Knowledge discovery in spatio-temporal databases demands the development of challenging techniques to mine patterns that take into account the semantics and structural aspects of large databases (terabytes of data). Our investigation provides a new methodology to mine temporal patterns using FP (Frequent Pattern) growth algorithm that detects frequent pattern among various attributes of such databases. We have developed and implemented our method over different spatio-temporal datasets and achieved encouraging results which have been discussed in the study.
I INTRODUCTION
One of the most challenging and rigorous task of data mining is to discover knowledge for multi-relational attributes of spatio-temporal databases. Recently, there have been many researches going on to deal with such databases [1],[2],[3], but very few of them provide the quality to enhance their scope in knowledge discovery. Recent research shows that spatial data mining can be considered as multi-dimensional equivalent of temporal data mining, since temporal data mining focuses on the discovery of relationships among the events that may be ordered in time [4]. It also demonstrates that the ordered events form sequence and only those temporal rules are of interest that respects the order of events on time axis. According to Roddick, when the rules are based on order of sequence, it is termed as sequence mining, and if there is some pattern occurs in that sequence, then the mining of
such pattern is called pattern mining. Despite of mining differences, the fundamental goal remained unsolved and our objective is to discover knowledge in those databases. One of the most adaptive ways to discover knowledge is to generate association rules among various spatial attributes [5],[6],[7].
According to Agarwal in [8], association rule mining is one of the major task to discover knowledge in order to find all strong association rules that satisfy minimum support and minimum confidence threshold. It uses the concept of support and confidence. If we have an association of the form A→B, the support of the rule is given as P(AUB) and its confidence is given as P(B/A). A spatio-temporal association rule contains spatio-temporal predicate in the antecedent or consequent of the rule [9]. Many challenges have come across while mining spatio-temporal databases since dealing with the interaction of space and time is complicated by the fact that they have different sementics [10],[11].To deal with such databases, we have suggested to use some fast algorithm that have a capability to mine patterns from terabytes of data. One such algorithm which is found to be most efficient for mining patterns in large datasets is FP Growth algorithm [12]. This algorithm adopts a divide-and-conquer approach to decompose mining tasks and databases and uses a pattern fragment growth method to avoid the costly process of candidate generation and testing used by Apriori [13],[14].
using FP Growth algorithm. Section III briefly explains the implementation of the proposed method. Section IV gives the performance analysis through experimental results obtained after applying the framework in spatio-temporal and non-spatio-temporal datasets. Section V concludes overall objective of the paper.
II METHODOLOGY
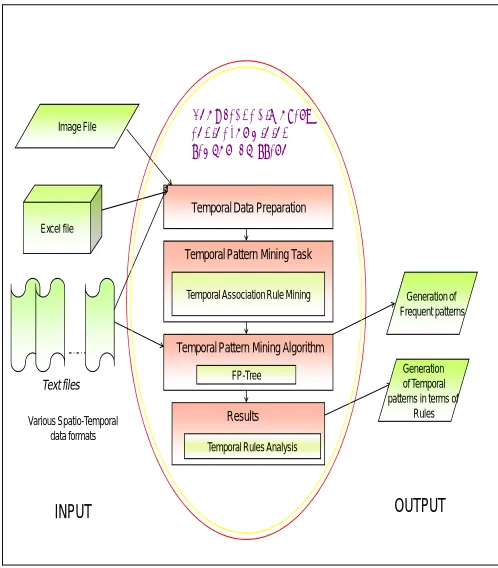
We are proposing a new methodology shown in Fig. 1 to deal with spatio-temporal databases that provides the framework to follow the major phases of KDD(Knowledge Discovery in Databases) in order to generate frequent patterns by using one of the fastest algorithm of data mining, FP Growth algorithm. For our methodology, the algorithm is generating temporal patterns and then those patterns are used for generating temporal association rules.
This methodology comprises of following steps 1. Input data can be either an image file,
excel file or a text file.
2. One of the major task of data mining is Association rule mining. If the data is temporal then temporal association rules are generated.
3. After then, FP Growth algorithm is being applied for generating temporal patterns. 4. Now, the temporal patterns are used to
discover knowledge in terms of temporal association rules.
Detailed Description of the Methodology
To deal with spatio-temporal data, we have taken the raw data in any file format such as .txt, .xls, .img etc. In the first phase of our method we took that data as an input and converted it into the format required for FP growth algorithm, i.e. in updated data we have introduced transaction ID to every record and saved it into .txt format. The next phase of the method is to choose pattern mining task. Association rule mining is a well known pattern mining task so we have incorporated it for generating temporal patterns. After that we
applied FP growth algorithm which is considered as temporal pattern mining algorithm to the updated data. In the last phase we get temporal patterns which can be analyzed in the form of temporal association rules to discover the knowledge.
KNOWLEDGE DISCOVERY
ENGINE FOR MINING
TEMPORAL PATTERN
Temporal Data Preparation
Temporal Pattern Mining Task
Temporal Association Rule Mining
Temporal Pattern Mining Algorithm
FP-Tree
Results Image File
Excel file
Text files
Temporal Rules Analysis
Generation of Frequent patterns
Generation of Temporal patterns in terms of
Rules
INPUT OUTPUT
[image:2.612.323.572.149.433.2]Various Spatio-Temporal data formats
Fig. 1 Detailed methodology for discovering knowledge
III IMPLEMENTATION
The proposed methodology is tested on a simple spatio-temporal dataset of Earthquake occurrence data which is taken from United States Geological Survey (USGS). Our goal is to discover the knowledge for earthquake occurrence pattern at a particular instant of time.
A. Data Description
attributes: Year: Lies between 1900-1990, Time of earthquake : 0000-2359, Magnitude (Mag): Lies in interval [6.0,8.0], Latitude (Lat) : Lies in interval [-180,180], Longitude (Long): Lies in interval [-180,180].
Table 1. Sample dataset
Year Time Of
earthquake Mag Lat Long
1900 907 7.8 36.5 133.5
1900 633 8.3 20 -105
1901 29 7.8 -2 -82
1901 923 7.9 40 144
1901 1301 8.39 -22 170
1901 1833 8.2 40 144
1902 735 7.8 -20 -174
1902 939 6.9 40.7 48.6
1902 223 8.2 14 -91
. . . . .
. . . . .
B. Method
For generating frequent temporal pattern we do some slight changes in the dataset as: (1) We divide the time of earthquake into four intervals as:t0,t1,t2,t3 and each interval has following ranges:[0000,6000[,[6000,1200[,[1200,1800[, [1800,2359] respectively. (2) In the similar way we classify Magnitude into four categories as: m0<6, m1є[6,7[, m2є[7,8[ and m3≥8. By updating the database given in Table 1 according to the above mentioned changes, we create a new database in .txt format. After then we applied FP Growth algorithm to that data to achieve the frequent temporal patterns. The basic steps of the algorithm are given as:
FP_Growth( ) {
Take sample database in text format having each record with transaction ID;
Obtain the frequency list of the attribute values; Create L-order list according to the criteria supp_of_att_value ≥ min_supp_threshold;
Create FP-growth tree;
Mine the frequent temporal patterns from FP-growth tree;
}
After following the above algorithm, the temporal patterns are generated as shown in Fig. 2. where the min_supp_threshold = 12. One of the pattern shows that time interval t1 is occurring with m2 in 68 records. It is giving the knowledge that the earthquakes of magnitude category m2 i.e. [7,8[ are mostly occured in time interval t1 i.e. [600,1200[. Another pattern shows that during all the time intervals the earthquakes of category m2 are most happening earthquakes throughout from 1900-1990. In this way we can change the value of min_supp_threshold and discover useful knowledge. This knowledge is in the form of temporal association rules since we are dealing with the attributes having time slots.
t1 : 124
m2 : 68
m3 : 17
m1 : 39
t3 : 89
m2 : 44
m3 : 18
m1 : 27
t2 : 87
m3 : 13
m2 : 47
m1 : 27
t0 : 47
m3 : 14
m2 : 22
1979 : 23
m1 : 12
IV EXPERIMENTAL RESULTS AND DISCUSSIONS
The goal of our study is to discover patterns from large databases. There are generally two categories of datasets: spatio-temporal and non-spatio-temporal datasets. We have applied FP Growth algorithm over both the categories and found it to be scalable in terms of time and space complexities.
Scalability Analysis
A scalability analysis is required for every algorithm in order to test its performance over various dataset. As we have applied FP Growth algorithm over different datasets, due to page limitation we have shown its scalability for two non-spatio temporal datasets: MB dataset, Synthetic dataset and one Spatio-temporal dataset: Elnino dataset. All the datasets are taken from well known UCI machine learning repository.
All the experiments we have performed on Pentium IV machine with 1GB main memory and 80 GB hard disk having MS Windows/NT operating system. FP-growth is implemented using Dev-C++ 4.9.9.2. The time and space shown in the results of scalability analysis for various datasets is the overall time and space required for generating frequent patterns form those datasets.
Non-Spatio Temporal Dataset
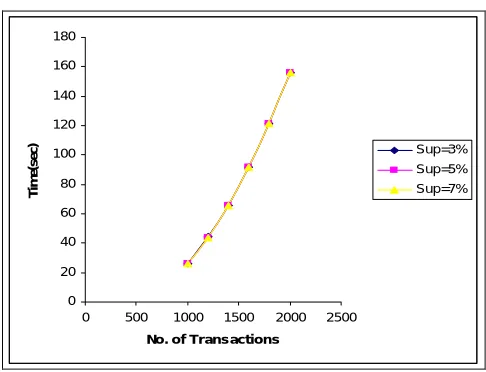
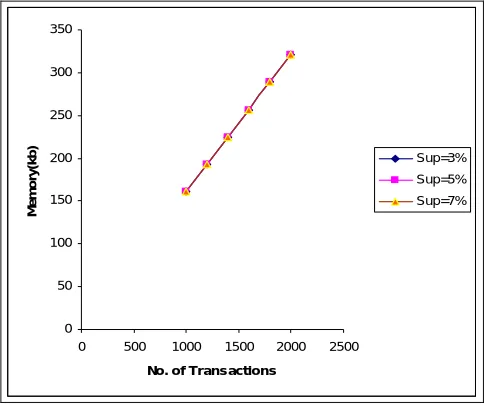
Non-spatio temporal datasets are also partitioned into two categories : Sparse data and Dense data. Fig. 3 and Fig. 4 shows the scalability of FP-growth algorithm w.r.t. time and space respectively for sparse dataset such as MB dataset. Similar analysis is being done for dense dataset such as Synthetic dataset shown in Fig. 5 and Fig. 6 respectively.
0 2 4 6 8 10 12 14
0 20000 40000 60000 80000
No. of Trans actions
Ti
m
e
(s
e
c
) Sup=3%
Sup=5%
Sup=7%
Fig. 3Scalability of FP growth w.r.t. time for MB dataset
0 5000 10000 15000 20000 25000 30000 35000
0 20000 40000 60000 80000
No. of Trans actions
Me
m
o
ry
(k
b
)
Sup=3%
Sup=5%
Sup=7%
Fig. 4Scalability of FP Growth w.r.t. space for MB dataset
0 20 40 60 80 100 120 140 160 180
0 500 1000 1500 2000 2500
No. of Trans actions
T
im
e
(sec
) Sup=3%
Sup=5%
Sup=7%
[image:4.612.323.569.58.238.2] [image:4.612.324.568.267.457.2] [image:4.612.323.566.485.671.2]0 50 100 150 200 250 300 350
0 500 1000 1500 2000 2500
No. of Transactions
Me
m
o
ry
(k
b
)
Sup=3%
Sup=5%
Sup=7%
Fig. 6Scalability of FP Growth w.r.t. Space for Synthetic dataset
Spatio-Temporal Dataset
As the algorithm works well for non-spatio temporal datasets, so we have tested it over one of the famous spatio-temporal dataset of ElNino. We got success in achieving the patterns in that dataset though it is large enough. We have partitioned the whole dataset and apply the algorithm that produced frequent temporal patterns. In further study we will extend the analysis of such patterns in terms of temporal association rules. Scalability of that data w.r.t. time and space is shown in Fig. 7 and Fig. 8 respectively.
0 5 10 15 20 25 30
0 20000 40000 60000 80000
Num be r of Tr ans actions
T
im
e
(sec
) SUP= .03%
SUP=.05%
SUP=.1%
[image:5.612.43.289.57.260.2]SUP=.2%
Fig. 7 Scalability of FP Growth w.r.t. time for ElNino dataset
0 5000 10000 15000 20000 25000 30000 35000 40000
0 20000 40000 60000 80000
No. of tr ans actions
M
em
or
y
(K
B
) SUP= .03%
SUP=.05%
SUP=.1% SUP=.2%
Fig. 8Scalability of FP Growth w.r.t. Space for ElNino dataset
V CONCLUSION AND FUTURE SCOPE
Our extensive investigation have presented a new methodology which have used fastest data mining algorithm for mining frequent temporal patterns in spatio-temporal datasets to discover Knowledge from such datasets. Experimental results shows the performance analysis of the algorithm which shows that the algorithm is scalable for various datasets. Future scope of the present study is to develop temporal association rules from the frequent temporal patterns generated after applying our method over various spatio-temporal datasets.
REFERENCES
[1] Shyu, C.R. Klaric, M. Scott, Knowledge Discovery by Mining Association Rules and Temporal-Spatial Information from Large-Scale Geospatial Image Databases , in IEEE International Conference on Geoscience and Remote Sensing Symposium, 2006. IGARSS 2006.
[2] K. Koperski and J. Han. Discovery of spatial association in geographic information databases. In Proceedings of the 4th International Symposium SDD-95, pages 47--66, Portland, ME, USA, 1995.
[image:5.612.322.569.59.228.2] [image:5.612.43.290.507.684.2]System”, In Proceedings of the 2003 ACM
symposium on Applied computing,
pages 445--449, Melbourne, Flourida,2003.
[4] John F. Roddick, Myra Spiliopoulou, “A Bibliography of Temporal, Spatial and Spatio-Temporal Data Mining Research”, ACM SIGKDD, Volume 1, pages 34--38, 1999
[5] J. Mennis, J.W. Liu, Mining association rules in spatio-temporal data, in: Proceedings of the Seventh International Conference on GeoComputation, 2003.
[6] Mennis J, Liu JW, “Mining Association Rules in Spatio-Temporal Data: An Analysis of Urban Socioeconomic and Land Cover Change.” Transactions in GIS, 2005.
[7] Donato Malerba, Francesca A. Lisi, “An ILP method for spatial association rule mining”In Working notes of the First Workshop on Multi-Relational Data Mining,2001.
[8] Agrawal, R., Imielinski, T., and Swami, A. N. 1993, ”Mining association rules between sets of items in large databases”, In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, pages 207-216, 1993
[9] J Mennis, J W Liu, “Mining association rules in spatio-temporal data”, In Proceedings of the 7th International Conference on
GeoComputation, University of Southampton, UK, 2003.
[10] Florian Verhein, Sanjay Chawla, Mining spatio-temporal association rules sources sinks stationary regions and thoroughfares in object mobility databases.” Database Systems for Advanced Applications: 11th International Conference DASFAA 2006 Singapore April 12-15 2006 Proceedings LNCS 3882, pp 187-201. 2006.
[11] Vincent Ng , Stephen Chan , Derek Lau , Cheung Man Ying, Incremental mining for temporal association rules for crime pattern discoveries, Proceedings of the ACM International Conference, Victoria, Australia. pages: 123 – 132, 2007.
[12] Jiawei Han, Jian Pei, Yiwen Yin, "Mining Frequent Patterns without Candidate Generation", Intl. Conference on Management of Data, ACM SIGMOD,2000
[13] Jiawei Han, Micheline Kamber , Book : “Data Mining Concept & Technique”,2001.
[14] Christian Borgelt, “Keeping things