Research Article
a
June
2018
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-8, Issue-6)
An Ethical Approach of Big Data & Machine Learning
Using Innovation of Python
Prof. (Dr.) R. K. Bathla
Professor in Computer Science & Engineering at Madhav University, Rajasthan, India
e-mail- [email protected]
Prof. (Dr.) Jitender Nath Srivastva
Vice-Chancellor, Manav Bharti University, Solan, Himachal Pradesh, India e-mail- [email protected]
Abstract: Big Data has gained much concentration from the academic world and the IT industry. In the digital and computing world, in order is generated and collected at a rate that rapidly exceeds the boundary range. Currently, over 2 billion people world wide are connected to the Internet, and over 5 billion individuals own mobile phones. By 2020, 50 billion devices are expected to be connected to the Internet. At this point, predicted data production will be 44 times greater than that in 2009. As information is transferred and shared at light speed on optic fiber and wireless networks, the volume of data and the speed of market growth increase. However, the fast growth rate of such large data generates numerous challenges, such as the rapid growth of data, transfer speed, diverse data, and security. Nonetheless, Big Data is still in its infancy stage, and the domain has not been reviewed in general. Hence, this study comprehensively surveys and classifies the various attributes of Big Data, including its nature, definitions, rapid growth rate, volume, management, analysis, and security. Cloud computing has opened up new opportunities for testing departments. New technology and social connectivity trends are creating a perfect storm of opportunity, enabling cloud to transform internal operations, Customer relationships and industry value chains. To ensure high quality of cloud applications under development, developer must perform testing to examine the quality and accuracy whatever they design. Business users are drawn to clouds simplified, self- service experience and new service capabilities. In this research paper, we address a testing environmental architecture with valuable key benefits, to perform execution of test cases and used testing methodologies to enhance quality of cloud applications.
Keywords: Big data, Data analytics, Data management, Big data-as-a-service, Analytics-as-a-service, Business intelligence Lease, Storage cloud computing, Cost-benefit analysis model.
I. INTRODUCTION
The Internet saturation continuously increases, as more and more people browse the Web, use email and social network applications to converse with each other or access wireless multimedia services, such as mobile TV. Moreover, several demanding mobile network services are now available, which require increased data rates for specific operations, such as device storage synchronization to cloud computing servers or high resolution video. The access to such a global information and communication infrastructure along with the advances in digital sensors and storage have created very large amounts of data, such as Internet, sensor, streaming or mobile device data. Additionally, data analysis is the basis for investigations in many fields of knowledge, such as science, engineering or management. Unlike web-based big data, location data is an essential component of mobile big data, which are harnessed to optimize and personalize mobile services. Hence, an era where data storage and computing become utilities that are ubiquitously available is now introduced. Furthermore, algorithms have been developed to connect data sets and enable more sophisticated analysis. Since innovations in data architecture are on our doorstep, the ‗big data‘ paradigm refers to very large and complex data sets (i.e., petabytes and hex bytes of data) that traditional data processing systems are inadequate to capture, store and analyze, seeking to glean intelligence from data and translate it into competitive advantage. As a result, big data needs more computing power and storage provided by cloud computing platforms. In this context, cloud providers, such as IBM, Google, Amazon and Microsoft, provide network-accessible storage priced by the gigabyte-month and computing cycles priced by the CPU-hour.
II. BIG DATA: BACKGROUND AND ARCHITECTURE
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
analytics in parallel across a distributed cluster. Batch-processing models, such as Map Reduce, enable the data management, mixture and processing from numerous sources. Many big data solutions in the market exploit external information from a range of sources (e.g., social networks) for modeling and sentiment analysis, such as the IBM Social Media Analytics Software as a Service solution. Cloud providers have already begun to establish new data centers for hosting social networking, business, media content or scientific applications and services. In this direction, the selection of the data warehouse technology depends on several factors, such as the volume of data, the speed with which the data is needed or the kind of analysis to be performed. Conceptual big data warehouse architecture is presented. Another significant challenge is the delivery of big data capabilities through the cloud. The adoption of big data-as-a-service (BDaaS) business models enables the effective storage and management of very large data sets and data processing from an outside provider, as well as the exploitation of a full range of analytics capabilities (i.e., data and predictive analytics or business intelligence are provided as service-based applications in the cloud). In this context, Zheng et al. critically review the service-generated big data and big data-as-a-service the proposal of an infrastructure to provide functionality for managing and analyzing different types of service-generated big data. A big data-as-a-service framework has been also employed to provide big data services and data analytics results to users, enhance efficiency and reduce cost.
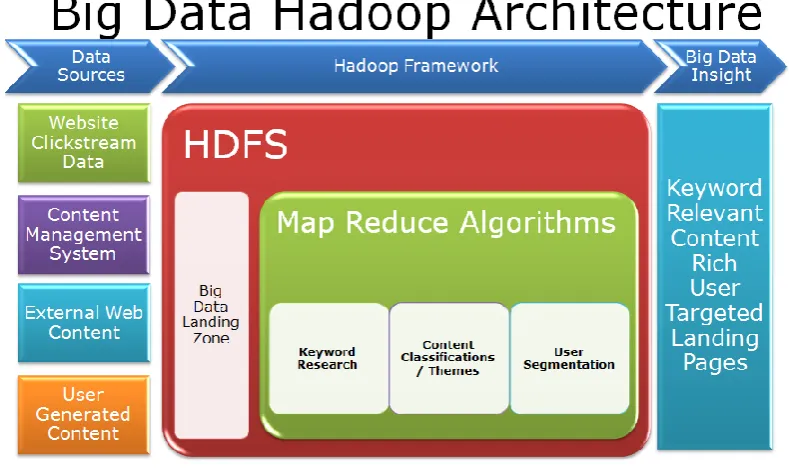
Fig. 1 A conceptual big data warehouse architecture
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9 A. Volume of Big Data
The volume of Big Data is classically large. However, it does not require a certain amount of petabytes. The increase in the volume of various data records is naturally managed by purchasing additional online storage; however, the relative value of each data point decreases in proportion to aspects such as age, type, quantity, and richness. Thus, such expenditure is unreasonable (Doug, 212). The following two subsections detail the volume of Big Data in relation to the rapid growth of data and the development rate of hard disk drives (HDDs). It also examines Big Data in the current environment of enterprises and technologies.
B. Rapid Growth of Data
The data type that increases most rapidly is shapeless data. This data type is characterized by ―human information‖ such as high-definition videos, movies, photos, scientific simulations, financial transactions, phone records, genomic datasets, seismic images, geospatial maps, e-mail, tweets, Face book data, call-center conversations, mobile phone calls, website clicks, documents, sensor data, telemetry, medical records and images, climatology and weather records, log files, and text. According to Computer World, unstructured information may account for more than 70% to 80%of all data in organizations. These data, which mostly originate from social media, constitute 80% of the data worldwide and account for 90% of Big Data. Currently, 84% of IT managers process unstructured data, and this percentage is expected to drop by 44% in the near future. Most shapeless data are not modeled, are random, and are difficult to analyze. For many organizations, appropriate strategies must be developed to manage such data. Table 1 describes the rapid production of data in various organizations further. According to Industrial Development Corporation (IDC) and EMC Corporation, the amount of data generated in 2020 will be 44 times greater [40 zetta bytes (ZB)] than in 2009. This rate of increase is expected to persist at 50% to 60% annually. To store the increased amount of data, HDDs must have large storage capacities. Therefore, the following section investigates the development rate of HDDs C. Development Rate of Hard Disk Drives (HDDs).
The demand for digital storage is highly elastic. It cannot be completely met and is controlled only by budgets and management capability and capacity. Goda et al. (2002) and discuss the history of storage devices, starting with magnetic tapes and disks and optical, solid-state, and electromechanical devices. Prior to the digital revolution, information was predominantly stored in analogue videotapes according to the available bits. As of 2007, however, most data are stored in HDDs (52%), followed by optical storage (28%) and digital tapes (roughly 11%). Paper-based storage has dwindled 0.33% in 1986 to 0.007% in 2007, although its capacity has steadily increased (from 8.7 optimally compressed PB to 19.4 optimally compressed PB). Figure 2 depicts the rapid development of HDDs worldwide.
III. BIG DATA MANAGEMENT
The architecture of Big Data must be synchronized with the support infrastructure of the organization. To date, all of the data used by organizations are stagnant. Data is increasingly sourced from various fields that are disorganized and messy, such as information from machines or sensors and large sources of public and private data. Previously, most companies were unable to either capture or store these data, and available tools could not manage the data in a reasonable amount of time. However, the new Big Data technology improves performance, facilitates innovation in the products and services of business models, and provides decision making support [8, 48]. Big Data technology aims to minimize hardware and processing costs and to verify the value of Big Data before committing significant company resources. Properly managed Big Data are accessible, reliable, secure, and manageable. Hence, Big Data applications can be applied in various complex scientific disciplines (either single or interdisciplinary), including atmospheric science, a stronomy, medicine, biology, genomics, and biogeochemistry. In the following section, we briefly discuss data management tools and propose a new data life cycle that uses the technologies and terminologies of Big Data.
IV. MACHINE LEARNING
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
the problem or don‘t have enough computing power to properly model the problem. For these problems we need statistics. For example, the motivation of humans is a problem that is currently too difficult to model.
A. Machine Learning Will Be More Important in the Future
In the last half of the twentieth century the majority of the workforce in the developed world has moved from manual labor to what is known as knowledge work. The clear definitions of ―move this from here to there‖ and ―put a hole in this‖ are gone. Things are much more ambiguous now; job assignments such as ―maximize profits,‖ ―minimize risk,‖ and ―find the best marketing strategy‖ are all too common. The fire hose of information available to us from the World Wide Web makes the jobs of knowledge workers even harder. Making sense of all the data with our job in mind is becoming a more essential skill, as Hal Varian, chief economist at Google.
B. Collect Data
You could collect the samples by scraping a website and extracting data, or you could get information from an RSS feed or an API. You could have a device collect wind speed measurements and send them to you, or blood glucose levels, or anything you can measure. The number of options is endless. To save some time and effort, you could use publicly available data.
C. Prepare the Input Data
Once you have this data, you need to make sure it‘s in a useable format. The format we‘ll be using in this book is the Python list. We‘ll talk about Python more in a little bit, and lists are reviewed in appendix A. The benefit of having this standard format is that you can mix and match algorithms and data sources.
D. Train the Algorithm
This is where the machine learning takes place. This step and the next step are where the ―core‖ algorithms lie, depending on the algorithm. You feed the algorithm good clean data from the first two steps and extract knowledge or information. This knowledge you often store in a format that‘s readily useable by a machine for the next two steps. In the case of unsupervised learning, there‘s no training step because you don‘t have a target value. Everything is used in the next step.
E. Test the Algorithm.
This is where the information learned in the previous step is putto use. When you‘re evaluating an algorithm, you‘ll test it to see how well it does. In the case of supervised learning, you have some known values you can use to evaluate the algorithm. In unsupervised learning, you may have to use some other metrics to evaluate the success. In either case, if you‘re not satisfied.
V. WHY PYTHON?
Python is a great language for machine learning for a large number of reasons. First, Python has clear syntax. Second, it makes text manipulation extremely easy. A large number of people and organizations use Python, so there‘s ample development and documentation.
A. Executable Pseudo-Code
The clear syntax of Python has earned it the name executable pseudo-code. The default install of Python already carries high-level data types like lists, tuples, dictionaries, sets, queues, and so on, which you don‘t have to program in yourself. These high-level data types make abstract concepts easy to implement. (See appendix A for a full description of Python, the data types, and how to install it.) With Python, you can program in any style you‘re familiar with: object-oriented, procedural, functional, and so on. With Python it‘s easy to process and manipulate text, which makes it ideal for processing non-numeric data. You can get by in Python with little to no regular expression usage. There are a number of libraries for using Python to access web pages, and the intuitive text manipulation makes it easy to extract data from HTML.
B. What Python Has That Other Languages Don’t Have
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
and C. The problem with these languages is that it takes a lot of code to get simple things done. First, you have to typecast variables, and then with Java it seems that you have to write setters and getters every time you sneeze. Don‘t forget sub classing. You have to subclass methods even if you aren‘t going to use them. At the end of the day, you have written a lot of code—sometimes tedious code—to do simple things. This isn‘t the case with Python. Python is clean, concise, and easy to read. Python is easy for nonprogrammers to pick up. Java and C aren‘t so easy to pick up and much less concise than Python.
Fig.2 Comparison of Speed Factor with Matlab
C. Drawbacks
The only real drawback of Python is that it‘s not as fast as Java or C. You can, however, call C-compiled programs from Python. This gives you the best of both worlds and allows you to incrementally develop a program. If you experiment with an idea in Python and decide it‘s something you want to pursue in a production system, it will be easy to make that transition. If the program is built in a modular fashion, you could first get it up and running in Python and the n to improve speed start building portions of the code in C. The Boost C++ library makes this easy to do. Other tools such as Cython and PyPy allow you write typed versions of Python with performance gains over regular Python.
D. Python Features
Following are some of the important features of python which makes it a perfect fit for rapid application development.
Python is interpreted language so the program does not need to be compiled. Interpreter parses the program code and generates the output.
Python is dynamically typed, so the variables types are defined automatically.
Python is strongly typed. So the developers need to cast the type manually.
Less code and more use makes it more acceptable.
Python is portable, extendable and scalable.
E. Limitations of Python
Although Python has lot of positive sides, but it also has some limitations as it exists in all the languages. Let us have a brief look at those cons:
Python does not have proper multi-processor support
Lack of commercial support
Does not have good pre-packaged solutions
Lack of good documentation
Database layer is a bit old fashioned, although work is going on in this area.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
VI. EXAMPLE OF COMMAND LINE SCRIPT
import urllib2 import urllib import json
url = "http://ajax.googleapis.com/ajax/services/search/web?v=1.0&"
query = raw_input("What do you want to search for ? >> ")
query = urllib.urlencode( {'q' : query } )
response = urllib2.urlopen (url + query ).read()
data = json.loads ( response )
results = data [ 'responseData' ] [ 'results' ]
for result in results: title = result['title'] url = result['url'] print ( title + '; ' + url )
Fig:3 Beneficial of Python for Big Data Analytics
A. Experimental Code -Text Adventure Game
#TEXT ADVENTURE GAME
#the menu function: def menu(list, question): for entry in list:
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
return input(question) - 1
#Give the computer some basic information about the room: items = ["pot plant","painting","vase","lampshade","shoe","door"]
#The key is in the vase (or entry number 2 in the list above): keylocation = 2
#You haven't found the key: keyfound = 0
loop = 1
#Give some introductary text:
print "Last night you went to sleep in the comfort of your own home."
print "Now, you find yourself locked in a room. You don't know how" print "you got there, or what time it is. In the room you can see" print len(items), "things:"
for x in items: print x print ""
print "The door is locked. Could there be a key somewhere?"
#Get your menu working, and the program running until you find the key: while loop == 1:
choice = menu(items,"What do you want to inspect? ") if choice == 0:
if choice == keylocation:
print "You found a small key in the pot plant."
print "" keyfound = 1 else:
print "You found nothing in the pot plant." print ""
elif choice == 1:
if choice == keylocation:
print "You found a small key behind the painting." print ""
keyfound = 1 else:
print "You found nothing behind the painting." print ""
elif choice == 2:
if choice == keylocation:
print "You found a small key in the vase." print ""
keyfound = 1 else:
print "You found nothing in the vase."
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
if choice == keylocation:
print "You found a small key in the lampshade." print ""
keyfound = 1 else:
print "You found nothing in the lampshade." print ""
elif choice == 4:
if choice == keylocation:
print "You found a small key in the shoe." print ""
keyfound = 1 else:
print "You found nothing in the shoe." print ""
elif choice == 5: if keyfound == 1: loop = 0
print "You put in the key, turn it, and hear a click"
print "" else:
print "The door is locked, you need to find a key." print ""
# Remember that a backslash continues # the code on the next line
print "Light floods into the room as \ you open the door to your freedom."
VII. FUTURE SCOPE AND CONCLUSION
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 1-9
sophistication ranges from zero, in the case of automata, to high, when representing intelligent systems. In the context of machine learning and AI, a ‗robot‘ typically refers to the embodied form of AI; robots are physical agents that act in the real world. These physical manifestations might have sensory inputs and abilities powered by machine learning. The field of robotics has also made advances in recent years, as a result of improvements in sensor technologies and materials. As a result, and combined with advances in machine learning, robotic systems contribute to applications such as autonomous vehicles and drones. Potential applications can also be found in areas such as assisted living or city management. These further advances will draw from capabilities created by machine learning, such as computer vision, language processing, and human-machine interaction with the user. ―A further development in the field of machine learning relates to the increased use of virtual agents, or ‗bots‘. The term ‗bot‘ is sometimes used to refer to an autonomous agent deployed in software. Such agents may not have a physical manifestation, but may operate autonomously in the virtual world of the internet‖ Despite the recent attention given to, and hype surrounding, machine learning, fundamental ideas in the field are not so new, with early papers being published over sixty years ago. Within the last decade, even the past five years, the field of machine learning has made revolutionary advances. These advances have been driven in part by the availability of large amounts of data and the accessibility of computing power, but also underpinned by algorithmic advances achieved by revisiting and re-envisioning the simple neural networks put forward in the 1940s and 1950s. Drawing further insights from physiology and neuroscience, artificial neural networks have been created in which hundreds of layers of processing allow systems to perform more complicated tasks. These so-called deep learning techniques have been responsible for some of the more high-profile recent advances in artificial intelligence research.
REFERENCES
[1]. J. M. Borwein and A. S. Lewis, Convex analysis and nonlinear optimization: Theory and examples, CMS books in Mathematics, Canadian Mathematical Society, 2000.
[2] J. Basilico and T. Hofmann, Unifying collaborative and content-based _ltering, Proc. Intl. Conf. Machine Learning (New York, NY), ACM Press, 2004
[3]. Lijuan Cai and T. Hofmann, Hierarchical document categorization with support vector machines, Proceedings of the Thirteenth ACM conference on Information and knowledge management (New York, NY, USA), ACM Press, 2004
[4]. J. D. La_erty, A. McCallum, and F. Pereira, Conditional random _elds: Probabilistic modeling for segmenting and labeling sequence data, Proceedings of International Conference on Machine Learning (San Francisco, CA), vol. 18, Morgan Kaufmann, 2001
[5]. N. Ratli_, J. Bagnell, and M. Zinkevich, Maximum margin planning, International Conference on Machine Learning, July 2006.
[6] IOS Press. (2011). Guidelines on security and privacy in public cloud computing. Journal of E- Governance, 34 149-151. DOI: 10.3233/GOV-2011-0271
[7]. Park, K., Nguyen, M.C., Won, H.: Web-based collaborative big data analytics on big data as a service platform. In: Proceedings of the 2015 17th International Conference on Advanced Communication Technology (ICACT), Seoul, pp. 564–567 (2015)
[8]. Vakintis, I., Panagiotakis, S., Mastorakis, G., Mavromoustakis, C.X.: Evaluation of a Web Crowd-sensing IoT ecosystem providing big data analysis. In: Pop, F., Kołodziej, J., di Martino, B. (eds.) Resource Management for Big Data Platforms and Applications. Studies in Big Data Springer International Publishing, 2017.
[9]. Park, K., Nguyen, M.C., Won, H.: Web-based collaborative big data analytics on big data as a service platform. In: Proceedings of the 2015 17th International Conference on Advanced Communication Technology (ICACT), Seoul, pp. 564–567 (2015)
[10]. Agneeswaran VS, Tonpay P, Tiwary J (2013) Paradigms for realizing machine learning algorithms. Big Data 1(4):207–214