Research Article
a
November
2017
Science and Software EngineeringISSN: 2277-128X (Volume-7, Issue-11)
Handling Imbalance Data in Reduce task of MapReduce in
Cloud Environment
Chetana Tukkoji
Asst Professor, Dept of CSE, Gitam University, Bangalore, Karnataka, India
Dr. Seetharam K
Professor, Dept of CSE, N. M. A. M, Institute of Technology, Nitte, Karnataka, India
Abstract: There is a growing need for an ad-hoc analysis of extremely large data sets, especially at web based companies where innovation critically depends on being able to analyze terabytes of data collected every day. Parallel database products, over a solution, but are usually prohibitively ex-pensive at this scale. But, most of the people who analyze data are called procedural programmers. The success of the more procedural map-reduce programming model and its associated scalable implementations on commodity hardware (low cost), is evidence of the above. However, the map-reduce paradigm is too low-level and rigid, and leads to a great deal of custom user code that is hard to maintain, and reuse. The map reduce is an effective tool for parallel data processing. One significant issue in practical map reduce application is the data skew. The imbalance of the amount of the data assigned to each tasks to take much longer to finish than the others. Now we need to propose a framework, to solve the data skew problem to reduce side application in the map reduce. It usage a innovative sampling of the data input accurate approximation to the distribution of the intermediate data by sampling only small fraction of the intermediate data. It does not contain the any type of the data to prevent the overlap between the maps and reduce stages.
Keywords: Data skew, MapReduce
I. INTRODUCTION
Map Reduce is emerging as an important programming model for large-scale data- parallel applications such as web indexing, data mining, and scientific simulation. Hadoop is an open-source framework for implementing Map Reduce programming for wide data and is often used for short jobs where low response time is critical. Hadoop’s performance is closely related to its task manager, which implicitly assumes that cluster nodes are homogeneous and tasks make progress linearly and uses these assumptions to decide when to speculatively re-execute tasks that appear to be stragglers.
The completion of the job in the hadoop depends on the slowest running task in the job. If one task significantly running task in the job. If one task is significantly longer to finish than others. It can delay the progress of entire jobs. The struggler can occur in the various region. It can delay the progress of the entire jobs. The struggler can be happen from the various region like among which data skew is an important one. The data skew refers to the imbalance in the amount of work required to process such data.
II. OBJECTIVE
We need to implement the method for general user defined Map reduce programs. The method has better approximation to the distribution of the intermediate data.
The framework can adjust the work load allocation and deliver improved performance even in the absence of
data skew when the performance underlying computing platform.
We need to implement the innovative approach to balance the load among the reduce tasks which supports the
split of large key when application semantics permit.
We need to implement a system in the Hadoop and evaluate the performance for the some popular
applications.
The performance of the developing system is higher than the other and also it will improve the results in job
execution time to a factor 4.
III. EXISTING SYSTEM
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 168-173
occurs when some nodes are assigned more data than others. Computations of data skew, more generally, results when some nodes take longer to process their data input than other nodes and can occur even in the absence of data skew the runtime of many scientific tasks depends on the data values themselves rather than simply the data size.
Advantage
These histograms were also shown earlier to be optimal for join selectivity estimation, thus establishing their universality.
Disadvantage
Theoretical results don’t meet the boundary of experimental results
IV. LITERATURE SURVEY [1]. Map Reduce: Simplified Data Processing on Large Clusters
Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines. The run-time system takes care of the details of partitioning the input data, scheduling the program's execution across a set of machines, handling machine failures, and managing the required inter-machine communication. This allows end users without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system. Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many terabytes of data on thousands of machines. Programmers and the system easy to use: hundreds of MapReduce programs have been implemented and upwards of one thousand MapReduce jobs are executed on Google's clusters every day.
[2]. Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks
The nodes provided by the application developer are quite simple and are usually written as sequential programs with no thread creation or locking. Concurrency arises from Dryad scheduling nodes to run simultaneously on multiple computers or on multiple CPU cores within a computer system. The application can discover the size and placement of data at run time, and modify the graph as the computation progresses to make efficient use of the available resources. Author is designed to scale up from powerful multi-core single computers, through small clusters of computers, to data centers with thousands of computers[12][13]. The Dryad execution engine handles all the most difficult problems of creating a large distributed, concurrent application: scheduling the use of computers and their CPUs, recovering from communication or computer failures and transporting data between different nodes.
[3]. A Study of Skew in MapReduce Applications
Highly variable task runtime in MapReduce applications. This paper describes the various causes and manifestations of data skew as observed in real world Hadoop applications. Runtime task distributions from these applications demonstrate the presence and negative impact of data skew on performance behavior. Here We discuss about best practices reffered for avoiding such behavior and their limitations. MapReduce has proven itself as a powerful and cost effective approach for large parallel data analytics[7]. A MapReduce job runs in two main phases: map and reduce phase. In each of these phases, a subset of the input data is processed by distributed tasks in a cluster of computers. When a map completes its task, then the reduce tasks are notified to pull newly available data.
[4]. Estimation of Query-Result Distribution and its Application in Parallel-Join Load Balancing.
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 168-173
[5]. Efficient outer join data skew handling in parallel DBMS(PDBMS)
Large enterprises have been relying on parallel database management systems (PDBMS) to process their ever-increasing data volume and complex queries. The scalability and performance of a Parallel DBMS comes from load balancing on all nodes in the system. Skewed data processing will significantly slow down query response time and degrade the overall system performance. Business intelligence techniques are used by enterprises that frequently generate a large number of outer joins and require high performance from the underlying database systems[9]. Although wast research has been done on handling skewed data processing for inner joins in Parallel DBMS, still there is no known research on data skew handling for parallel outer joins. This paper proposes a simple and efficient way of outer join algorithm called Outer Join Skew Optimization. This technique is used to improve the performance and scalability of parallel outer joins. Experimental results show that OJSO algorithm significantly speeds up query elapsed time in the presence of data skew.
V. PROPOSED SYSTEM
We represent a system that has ability to implement the framework in order to solve data skew for general applications. The MapReduce framework has been adopted by us to implement framework using is Hadoop software.
The main goals of developing framework are listed below:
Transparency: Data skew mitigation should be transparent to the users who don’t need to know any sampling and partitioner details.
Parallelism: It should be capable enough to preserve the parallelism of the original MapReduce framework at a possible extent. This precludes any pre-run sampling of the input data and overlaps the map and the reduce stages as much as possible.
Accuracy: Its sampling method should sustain abilities to fetch a reasonably accurate estimate of the input data distribution by sampling only a small fraction of the data.
Propose Technique
Sampling and Partitioning
Chunk Index for Partitioning
Splitting Large Cluster
Heterogeneous Environment
THE NOVEL ALGORITHM
Estimate Intermediate Data Distribution
Advantages:
Data skew mitigation is important in improving MapReduce performance.
System should support large cluster split and its adjustment for heterogeneous environments
We can handle not only the data skew, but also the reducer skew.
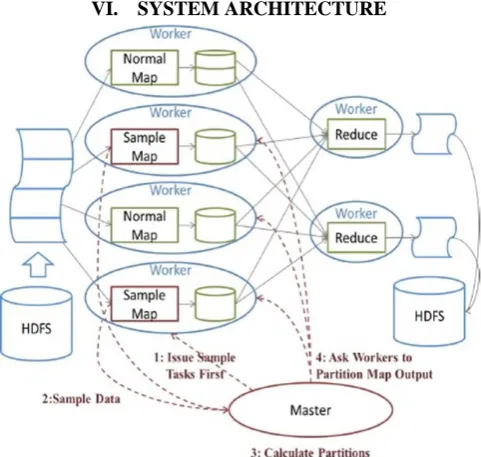
VI. SYSTEM ARCHITECTURE
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 168-173
The architecture of our system is shown in Figure 1. Data skew mitigation consists of the following steps: A small percentage of the original map tasks are selected as the sample tasks.
Sample tasks collect statistics on the intermediate data during normal map processing and send to the master. The master collects all the sample information to derive an estimate of the data distribution, makes the
partition decision and notifies the worker nodes.
Upon receipt of the partition decision, the working nodes need to partition the intermediate data generated by the sample tasks.
Reduce tasks can be immediately after the partition decision is ready.
VII. ARCHITECTURE DESIGN
A.Sampling and Partitioning Based on Chunk Index
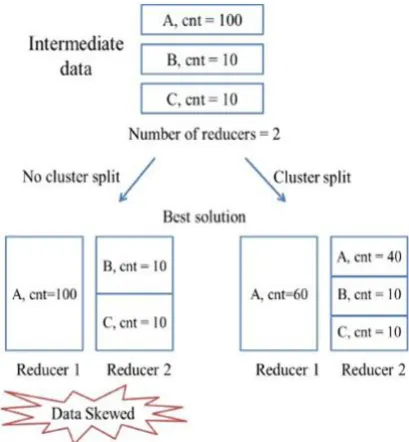
Figure 2. Generate partition list
Since data skew is difficult to solve if the input distribution is unknown, a natural thought is to examine the data before deciding the partition.
There are two common ways to do this. One approach is to launch some pre-run jobs which examine the data, collect the distribution statistics, and then decide an appropriate partition[10].
The drawback of this approach is that the real job cannot start until those pre-run jobs finish. The Hadoop range practitioner belongs to this category and as we will see in the experiments later, it can increase the job execution time significantly. The other approach is to integrate the sampling into the normal map process and generate the distribution statistics after all map until the partition decision is made, this approach cannot take advantage of parallel processing between the map and the reduce phases. By using this sparse index, we can decrease the partition time by an order of magnitude[11].
B. Splitting Large Cluster
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 168-173
Figure 3 states that the original MapReduce framework requires that a cluster (i.e., all tuples sharing the same key) be processed by a particular reducer.
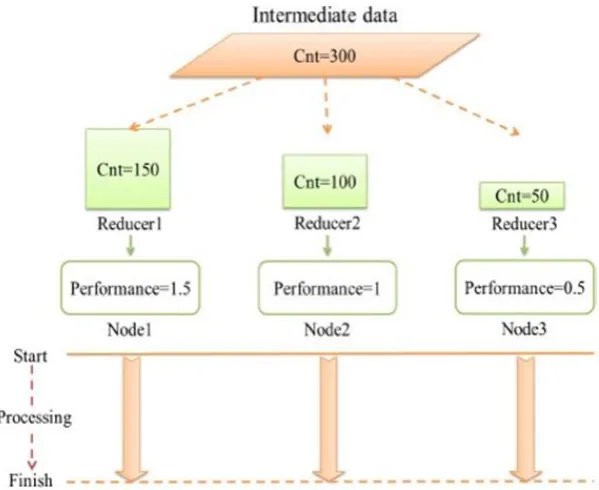
C. Heterogeneous environment
Figure 4: Data partitioning in heterogeneous environment
VIII. CONCLUSION
Data skew mitigation is important in improving MapReduce performance. This paper has presented a system that implements a set of innovative skew mitigation strategies in an existing MapReduce system. One unique feature of developing this framework is to support of large cluster split and its adjustment for heterogeneous environments. In some sense, we can handle not only the data skew, but also the reducer skew (i.e., variation in the performance of reducer nodes). Performance evaluation in both synthetic and real workloads demonstrates that the resulting performance improvement is significant and that the overhead is minimal and negligible even in the absence of skew.
REFERENCES
[1] J. Dean and S. Ghemawat, “Mapreduce: simplified data processing on large clusters,” Commun. ACM, vol. 51,
January 2008.
[2] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly, “Dryad:distributed data- parallel programs from sequential building blocks,” in SIGOPS/ EuroSys European Conference on Computer Systems (EuroSys), 2007.
[3] Y. Kwon, M. Balazinska, and B. Howe, et. al“A study of skew in mapreduce applications,” in Proc. of the Open
Cirrus Summit, 2011.
[4] V. Poosala and Y. E. Ioannidis, “Estimation of query-result distribution and its application in parallel-join load balancing,” in Proc. of the International Conference on Very Large Data Bases (VLDB), 1996
[5] Ding Xiang-wu; Hu Rui “Research on distributed data skew join algorithm based on VGFR model Conference”
2016.
[6] Tzu-Chi Huang; Kuo-Chih Chu et.al “Smart Partitioning Mechanism for Dealing with Intermediate Data Skew
in Reduce Task on Cloud Computing”, in IEEE(AINA), 2017.
[7] M. Jenifer; B. Bharathi et al.“Survey on the solution of data skew in big data” Online International Conference
on Green Engineering and Technologies, 2016.
[8] Tzu-Chi Huang; Kuo-Chih Chu et. al “Idempotent Task Cache System for Handling Intermediate Data Skew in
MapReduce on Cloud Computing” International Computer Symposium (ICS), 2016
[9] Zhuo Tang; Wen Ma; Kenli Li; Keqin Li "A Data Skew Oriented Reduce Placement Algorithm Based on Sampling” 2016
[10] Qi Chen; Jinyu Yao; Zhen Xiao “LIBRA: Lightweight Data Skew Mitigation in MapReduce” IEEE
ISSN(E): 2277-128X, ISSN(P): 2277-6451, pp. 168-173
[11] Maeva Antoine; Fabrice Huet “Dealing with Skewed Data in Structured Overlays Using Variable Hash
Functions”15th International Conference on Parallel and Distributed Computing, Applications and Technologies, 2014.
[12] Zhihong Liu; Qi Zhang et al “ DREAMS: Dynamic resource allocation for MapReduce with data skew” 2015
IFIP/IEEE International Symposium on Integrated Network Management (IM), 2015