Technical white paper
HP Big Data Reference
Architecture: A Modern
Approach
HP BDRA with Apollo 2000 System and Apollo 4200 Servers
Table of contents
Executive summary ... 2
Introduction ... 2
Breaking the mold ... 3
Industry trends ... 3
What else does HP see in the future? ... 4
HP approach ... 5
Reference architecture ... 5
Performance ... 9
Proprietary implementations ... 9
Benefits of the HP BDRA solution ... 9
Importance of flexibility in big data architecture ... 10
HP BDRA proof points... 11
Summary – the HP BDRA vision ... 11
Implementation overview ... 12
Executive summary
This paper describes the HP Big Data Reference Architecture (BDRA) solution and outlines how a modern architectural approach to Hadoop provides the basis for consolidating multiple big data projects while, at the same time, enhancing price/performance, density, and agility.
HP BDRA is a modern, flexible architecture for the deployment of big data solutions; it is designed to improve access to big data, rapidly deploy big data solutions, and provide the flexibility needed to optimize the infrastructure in response to the ever-changing requirements in a Hadoop ecosystem.
This reference architecture challenges the conventional wisdom used in current big data solutions, where compute resources are typically co-located with storage resources on a single server node. Hosting big data on a single node can be an issue if a server goes down and the time to redistribute all data to the other nodes could be significant. Instead, HP BDRA utilizes a much more flexible approach that leverages an asymmetric cluster featuring de-coupled tiers of workload-optimized compute and storage nodes in conjunction with modern networking. The result is a big data platform that makes it easier to deploy, use, and scale data management applications.
As customers start to retain the dropped calls, mouse-clicks and other information that was previously discarded, they are adopting the use of single data repositories (also known as data lakes) to capture and store big data for later analysis. Thus, there is a growing need for a scalable, modern architecture for the consolidation, storage, access, and processing of big data. HP BDRA meets this need by offering an extremely flexible platform for the deployment of data lakes, while also providing access to a broad range of applications. Moreover, the HP BDRA tiered architecture allows organizations to grow specific elements of the platform without the chore of having to redistribute data; this architecture allows bringing together different classes of workload-specific compute and storage nodes.
Clearly, big data solutions are evolving from a simple model where each application was deployed on a dedicated cluster of identical nodes. By integrating the significant changes that have occurred in fabrics, storage, container-based resource management, and workload-optimized servers, HP has created the next-generation, data center-friendly, big data cluster. Target audience:This document is intended for HP customers that are investigating the deployment of big data solutions, or those that already have big data deployments in operation and are looking for a modern architecture to consolidate current and future solutions while offering the widest support for big data tools.
Document purpose: This white paper outlines HP Big Data Reference Architecture (BDRA) and introduces new developments in compute and storage node tiering to enhance system flexibility and performance.
Introduction
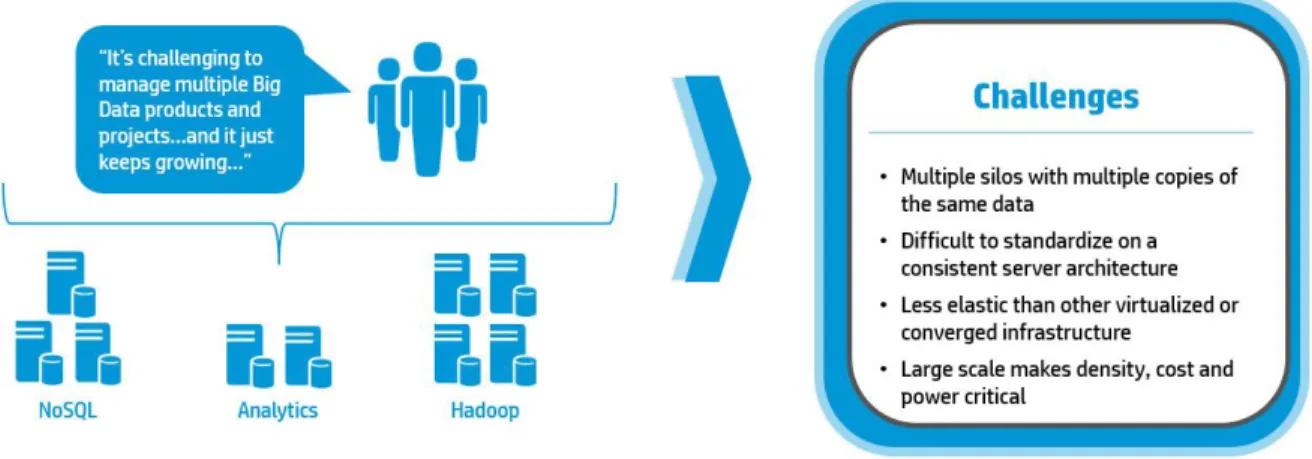
Today’s data centers are typically based on a converged infrastructure featuring a number of servers and server blades accessing shared storage over a storage array network (SAN). In such environments, the need to build dedicated servers to run particular applications has disappeared. However, with the explosive growth of big data, the Hadoop platform is becoming widely adopted as the standard solution for the distributed storage and processing of big data. Since it is often cost-prohibitive to deploy shared storage that is fast enough for big data, organizations are often forced to build a dedicated Hadoop cluster at the edge of the data center; then another; then perhaps an HBase cluster, a Spark cluster, and so on. Each cluster utilizes different technologies and different storage types; each typically has three copies of big data. The current paradigm for big data products like Hadoop, Cassandra, and Spark insists that performance in a Hadoop cluster is optimal when work is taken to the data, resulting in nodes featuring Direct-Attached Storage (DAS), where compute and storage resources are co-located on the same node. In this environment, data sharing between clusters is constrained by network bandwidth, while individual cluster growth is limited by the necessity to repartition data and distribute it to new disks.
Thus, many of the benefits of a traditional converged architecture are lost in today’s Hadoop cluster implementations. You cannot scale compute and storage resources separately; and it is no longer practical for multiple systems to share the same data.
Figure 1. IT infrastructure must evolve to handle the demands of big data
In essence, Hadoop creates a batch-processing environment for big data that runs in parallel across hundreds of servers, with associated (federated) products restructuring raw data to create case-sets for further analysis. Thus, a conventional data center might require clusters for tools such as HP Vertica, Apache Cassandra, Apache HBase, SAP HANA, or SAS in addition to one or more Hadoop clusters. Rather than a neat, tidy converged infrastructure, organizations are cobbling together multiple silos of big data, resulting in a relatively inflexible environment where it may take days – and
repartitioning – to move data from one silo to another. Since multiple tools are required in the analytic cycle, the inability to share the same copy of the data or move data in a timely manner becomes an issue, while manageability is also a significant concern.
Furthermore, there is no one optimal server configuration for big data processing; each product in the Hadoop federation of big data solutions has a different server profile and different workload needs. In practice, optimal compute/storage ratios typically vary from the accepted one spindle-per-core; indeed, many Hadoop workloads perform better with additional compute power and fewer spindles. Other workloads require a large amount of memory, while still others would benefit from accelerators such as Graphics Processing Units (GPUs) or Field-Programmable Gate Arrays (FPGAs).
Breaking the mold
Hadoop implementations have developed their own paradigms. To avoid the overhead associated with shipping data to and from storage arrays over a SAN, current Hadoop clusters typically use DAS, with an emphasis on taking the work to the data; that is, co-locating compute and storage on the same node. Such an implementation made sense when only 1GbE was available to connect compute and storage nodes; however, today’s networks can easily accommodate the required storage traffic. It is no longer imperative to minimize data motion.
In parallel with advances being made in fabric and server technologies, Hadoop itself is developing, with workloads now tending to fall into one of the following two categories:
• Applications that crunch data
• Applications that store and access data
As such, it is difficult to build a single node that can accommodate both workloads optimally.
Thus, HP has challenged entrenched assumptions and determined that the ideal Hadoop cluster is asymmetric; that is, compute and storage nodes have been de-coupled and are connected via high-speed Ethernet. Storage is directly attached, with all storage nodes exposed to the same view of the data; compute nodes are workload-optimized.
Industry trends
HP’s efforts to challenge convention and re-imagine the Hadoop cluster did not happen in a vacuum. Industry trends have been pointing in the same direction. Apache Hadoop has evolved consistently with client needs. Beginning with Hadoop 2.6, there were significant internal changes to the storage layer, called Heterogeneous Storage. Accordingly, the terms Tiered and Hierarchical are not considered descriptive enough for the changes that have been made.
With Heterogeneous Storage, the DataNode exposes the types and usage statistics for each individual storage to the NameNode. This change allows NameNode to choose not just a target DataNode when placing replicas, but also the specific storage type on each target DataNode. Since different storage types have different performance metrics in terms of throughput, latency and cost, this new capability benefits the total optimization and cost efficiency of the system.
YARN and labels
Most of today’s data management tools are using Hadoop as a common denominator, taking advantage of its high-speed, low-latency access to Hadoop Distributed File System (HDFS) data. Indeed, HDFS is becoming central to big data by providing a framework for high-aggregate bandwidth across a large cluster, exposing every compute node to the same copy of the data.
However, earlier implementations of Hadoop had issues in the areas of agility and resource utilization. These were alleviated in 2012 with the introduction of Hadoop’s YARN,1 which is designed to better manage and schedule cluster resources. YARN utilizes robust containers that specify the particular resources an application has the rights to use (that is, subsets of memory, CPU, and network bandwidth). Clearly seeing the benefits of this enhancement to Hadoop, many vendors have made their applications YARN-compliant; as a result, users can create containers for many of their big data jobs and, in effect, treat HDFS as a dropbox for their data.
The traditional Hadoop approach allows data to be shared, collated, and processed; however, compute resources are partitioned horizontally, in that every application runs on a slice of the resources available on every node. Since some workloads do not scale well and others would benefit from dedicated nodes, HP felt that resource management would be more effective if compute resources were partitioned vertically, allowing users to direct jobs to nodes that are optimized for or dedicated to particular workloads. Thus, for example, Hadoop MapReduce jobs could be directed to general-purpose nodes; Hive jobs to low-power nodes; and Storm jobs to nodes featuring accelerators. To support vertical partitioning, HP developed and tested the concept of herds, which are groups of similarly configured compute nodes, each featuring a different type of work-optimization technology. HP was able to direct jobs to the desired herds and achieve outstanding throughput and resource utilization.
HP’s prototyping of the herd approach then fed into labels, a similar concept developed by Hortonworks for inclusion in the Hadoop trunk. Hadoop labels can be used to assign a job to a particular pool of servers simply by denoting the appropriate label. This intelligent scheduling replaces the earlier paradigm where you had to manually place a virtual machine. The introduction of features like YARN labels allows you to extend control beyond the Hadoop cluster; for example, HBase can now run in a YARN container in which you specify compute nodes that have been optimized to accelerate the workload. In effect, containerization has created an operating system for the optimization of parallel workloads.
Tiered storage
Rather than relying on proprietary SAN storage, Hadoop has been built around the concept of using Software-Defined Storage (SDS), whereby lightweight distributed file systems support commoditized physical storage. For example, file-based transfers typically utilize Hadoop Distributed File System (HDFS), while object-file-based transfers could utilize Ceph. In another key advance, Hadoop now supports storage-tiering based on workload requirements. Thus, depending on the particular workload, storage can be implemented using SSDs, HDDs, in-memory storage, or, for archival purposes, object stores.
What else does HP see in the future?
HP sees many technological advances that will impact the newly-imagined Hadoop cluster. These advances include: • Self-contained clusters – HP believes the data center will evolve from implementations based on two-socket servers to
self-contained clusters with built-in fabric.
• More east-west cluster traffic – East-west traffic across the cluster will increase dramatically as fabric is built directly into the server. First-generation implementations will be based on copper connectors; future implementations will use photonics. With the resulting increase in bandwidth in the Hadoop cluster, switching intelligence will also increase. • More workload optimization – There will be a shift from general-purpose technologies to workload optimization, since
workload-optimized nodes will yield much greater performance, density, and power efficiency than traditional nodes for particular workloads. Products such as specialized CPUs and GPUs will create opportunities for HP and partners to create compute nodes that are better optimized for particular workloads. For example, server-on-chip (SOC) technology is already available; dark silicon is under development.
• Hyperscaling – Replacing the earlier model of scale-up architectures and expensive software licenses, organizations are expected to take advantage of the ability of Hadoop and other new-generation products to scale-out. Hyperscaling will be achieved in a much denser environment through inexpensive, low-power, scale-out servers (for example, an HP Moonshot System already delivers a self-contained 45-node cluster). While you may need more servers to run a particular job, there will be a huge reduction in power requirements.
• Deep Learning – There is increased interest in Deep Learning, whereby algorithms are used to make sense of data such as text, images, and sound. In conjunction with artificial neural networks (that is, networks that are inspired by the central nervous systems of the animal world), Deep Learning should enhance the analysis of big data. Systems will be able to recognize items of interest and identify relationships without the need for specific models or programming.
Big data and supercomputing will come together. For example, no-frills hardware solutions designed for high-performance computing (HPC), such as the HP Apollo 2000 System, can be deployed in the same rack as other compute nodes to serve purely as number-crunchers for workloads such as Apache Spark.
HP approach
Many of the design choices for a traditional Hadoop infrastructure – an architecture where compute is very closely tied to storage, as shown in Figure 2 – were driven by technologies that were available at the time. Now, however, these choices are limiting the capabilities of Hadoop and inhibiting potential performance gains from newer hardware technologies and enhancements to Hadoop itself.
Figure 2. The conventional wisdom is that compute and storage must be co-located
HP has attacked those paradigms, demonstrating that decoupling the compute and storage components of the Hadoop cluster creates an extremely fast, asymmetric big data solution, as shown in Figure 3.
Figure 3. HP has de-coupled compute and storage, creating an asymmetric cluster
This solution is further enhanced by deploying workload-optimized servers and utilizing the latest features in Hadoop, such as YARN, storage-tiering, and the ability to assign jobs to specific workload-optimized resources.
Reference architecture
HP has created HP BDRA, a reference architecture for big data, which is shown in Figure 4. This dense, converged solution can facilitate the consolidation of multiple pools of data, allowing Hadoop, Vertica, Spark and other big data technologies to share a common pool of data. The flexibility to adapt to future workloads has been built into the design.
This converged design features an asymmetric cluster where compute and storage resources are deployed on separate tiers. Storage is direct-attached; specialized SAN technologies are not used. Workloads and storage can be directed to optimized nodes. Interconnects are standard Ethernet; protocols between compute and storage are native Hadoop, such as HDFS and HBase.
HP BDRA serves as a proof of concept and has been benchmarked to demonstrate substantially improved
price/performance – along with significantly increased density – compared with a traditional Hadoop architecture. For example, HP has demonstrated that storage nodes in HP BDRA actually perform better now that they have been decoupled and are dedicated to running HDFS, without any Java or MapReduce overhead. Moreover, because modern Ethernet fabrics
are capable of delivering more bandwidth than a server’s storage subsystem, network traffic between tiers does not create a bottleneck. Indeed, testing indicated that read I/Os increased by as much as 30% in an HP BDRA configuration compared with a conventional Hadoop cluster.
Figure 4. HP Big Data Reference Architecture, changing the economics of work distribution in big data
The HP BDRA design is anchored by the following HP technologies: • Storage nodes
– HP Apollo 4200 Gen9 Servers make up the HDFS storage layer, providing a single repository for big data. – HP Apollo 4510 System provides optional ultra-dense storage capacity and performance. Note that the HP Apollo
4510 is recommended as an optional server, not a replacement, to provide backup and archival storage for big data. • Compute nodes
– HP Moonshot System with HP ProLiant m710/m710p Server Cartridges delivers a scalable, high-density layer for compute tasks and provides a framework for workload-optimization.
– HP Apollo 2000 System with HP ProLiant XL170r Gen9 Servers that deliver dual-processor performance, while taking advantage of the Apollo 2000 System’s density and configuration flexibility.
Notes
HP Apollo 4200 Gen9 Servers or HP ProLiant SL4540 Gen8 Servers may be used as storage nodes in the HP BDRA. HP ProLiant m710/m710p Server Cartridges or HP ProLiant XL170r Gen9 Servers may be used as compute nodes in the HP BDRA.
High-speed networking separates compute nodes and storage nodes, creating an asymmetric architecture that allows each tier to be scaled individually; there is no commitment to a particular CPU/storage ratio. Since big data is no longer co-located with storage, Hadoop does need to achieve node locality. However, rack locality works in exactly the same way as in a traditional converged infrastructure; that is, as long as you scale within a rack, overall scalability is not affected.
With compute and storage de-coupled, you can again enjoy many of the advantages of a traditional converged system. For example, you can scale compute and storage independently, simply by adding compute nodes or storage nodes. Testing carried out by HP indicates that most workloads respond almost linearly to additional compute resources.
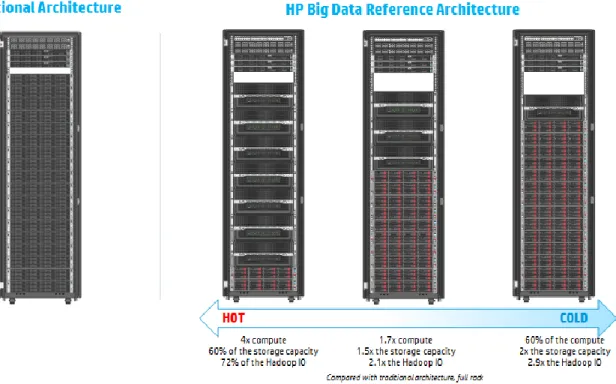
Depending on solutions tailored in response to specific needs, an organization can choose from a range of possible solutions (as shown in Figure 5), from a hot configuration featuring a large number of compute nodes and relatively small storage, to a cold configuration with a large amount of storage and relatively few compute resources.
Figure 5. Independent scaling of compute and storage
Within the HP BDRA solution, YARN-compliant tools such as HBase and Apache Spark can directly utilize HDFS storage. Other tools (such as SAP HANA, which requires a four-socket server2) are not good candidates for YARN; however, such applications can achieve high-performance access to the same data via appropriate connectors.
More information on key components of the HP BDRA solution is provided below. Storage nodes
The solution utilizes HP Apollo 4200 Gen9 servers for storage and recommends the HP Apollo 4510 System as an optional server for backup and archiving.
HP Apollo 4200 Gen9
Implemented using HP Apollo 4200 Gen9 servers, the storage tier in HP BDRA delivers the following key features: • Provides a density-optimized server storage solution designed to fit into traditional rack data centers today • Provides flexibility, allowing the customer to deploy storage nodes in units of one
• Offers Leadership storage capacity
• Allows certain work (such as filtering) to be pushed down to the storage node, removing pressure from workload servers • Provides the right balance of performance and cost-efficiency
Storage nodes deliver enterprise-level features and functionality, with an open source approach. HP Apollo 4510
The ultra-dense HP Apollo 4510 system stores up to 544TB per system. HP Apollo 4510 is recommended as
backup/archival because in the unlikely event of a server failure, one can have up to 544TB of data per server that needs to be redistributed across the cluster. Having Apollo 4510 configured in a separate “archival” HDFS storage tier will contain the redistribution process in that tier, resulting in minimal impact to the default HDFS storage tier.
Using an HP Apollo 4510 system to back up and archive the Hadoop system delivers the following key features: • Optimized Big Data workloads
• Hyperscale storage capacity and performance
• Fits up to 68 Large Form Factor (LFF) hot plug drives in a 4U chassis • Up to 544TB per system
• Built-in intelligence and automation • iLO 4 switch management
• Predictive re-build
Ultra-dense HP Apollo 4510 delivers hyperscale storage capacity at a lower cost compared to traditional Hadoop 2U servers.
Compute nodes
The compute tier of the HP BDRA will be very dense. HP has validated solutions using the Moonshot 1500 Chassis with the newest Moonshot server cartridges, as well as other solutions using the Apollo 2000 System with the latest server trays. Both the innovations of the Moonshot System or the newest developments with the Apollo 2000 System are recommended for handling the high density of the compute tier for the HP BDRA.
Moonshot 1500 Chassis
The features of the Moonshot 1500 Chassis include:
• Key components (power, cooling, and fabric management) shared by all cartridges, reducing requirements for energy, cabling, and space, while reducing complexity
• Redundant design hosting up to 45 individually-serviceable hot-plug cartridges and two network switches, all within a 4.3U footprint
• Chassis connected to network switches via six Direct Attach Copper (DAC) cables, each at 40GbE ProLiant m710 or m710p server cartridges can be selected to provide an ultra-dense compute layer. Apollo r2000 series chassis with ProLiant XL170r Gen9 servers
HP ProLiant XL170r Gen9 servers provide an optional compute node. The ProLiant XL170r provides flexibility and performance, with up to four independent hot-pluggable server nodes in a standard 2U chassis. The servers are available with a wide variety of processor, memory and storage configurations, allowing for greater workload optimization. Each server connects to network switches via Direct Attach Copper (DAC) cable, each at 40GbE.
Networking
While HP BDRA is a reference architecture rather than a rigidly-configured appliance, HP recommends the networking products described in this section, which were utilized in the proof-of-concept.
Networking in the HP BDRA solution is provided by a pair of Top of Rack (ToR) HP FlexFabric 5930 Switches configured via HP Intelligent Resilient Framework (IRF), which extends the switches and provides a layer of networking redundancy. An additional HP 5900 Switch provides connectivity to HP Integrated Lights-Out (HP iLO) management ports, which run at less than 1GbE.
Moonshot System chassis are each equipped with dual 45-port switches for 10GbE internal networking, as well as four 40GbE uplinks.
The HP Apollo 4200 System, HP SL4540 and Apollo 4510 System are connected to the high-performance ToR switches via a pair of 40GbE connections.
All cabling between storage and compute tiers is DAC. YARN
YARN is a key Hadoop feature that may be characterized as a large-scale, distributed operating system for big data applications. It decouples MapReduce’s resource management and scheduling capabilities from the data processing components, allowing Hadoop to support more varied processing approaches and a broader array of data management applications.
The concept of labels was a later addition to YARN, allowing compute nodes to be grouped. Now, when you submit a job through YARN, you can flag the job to run on a particular group by including the appropriate label name.
Benefits of the label feature include the following:
• Direct your job to nodes that are optimized for the particular workload • Accommodate applications that do not scale by providing dedicated resources • Utilize dedicated nodes, rather than relying on container isolation
• Isolate resources for individual departments within the organization
Performance
HP has conducted a broad range of tests to characterize the performance of an HP BDRA solution. Figure 6 shows the results of DFSIOe, a worst-case Hadoop job that writes a large amount of data to storage.
In Figure 6, baseline write performance for three servers with local storage is shown in red. When the same three servers were deployed as storage nodes in an HP BDRA configuration, write performance (shown in blue) scaled up significantly as the number of compute nodes increased, demonstrating the benefits of de-coupling storage from compute resources.
Figure 6. Worst-case write test comparison
Proprietary implementations
Competitors have created proprietary big data architecture solutions. However, these typically use traditional shared SAN storage, which tends to be expensive and ties you to the particular vendor. Moreover, tools like Apache HBase, Parquet, and OCFile are tightly coupled to HDFS and may not be well-hosted on a proprietary array.
Benefits of the HP BDRA solution
While the most obvious benefits of the HP BDRA solution center on density and price/performance, other benefits include: • Elasticity – The HP BDRA has been designed to be as flexible as needed. For more information, please refer to the
Importance of flexibility in big data architecture section of this white paper.
– Compute nodes can be allocated very flexibly without redistributing data; for example, based on time-of-day or even a single job.
– You are no longer committed to yesterday’s CPU/storage ratios; now, you have much more flexibility in design and cost.
– You only need to grow your system in areas that are needed.
– YARN-compliant workloads access big data directly via HDFS; other workloads can access the same data via appropriate connectors.
• Consolidation – HP BDRA is based on HDFS, which has enough performance and can scale to large enough capacities to be the single source for big data within any organization. You can consolidate the various pools of data currently being used in your big data projects into a single, central repository.
• Workload-optimization – There is no one go-to software for big data; instead there is a federation of data management tools. After selecting the appropriate tool for your requirements, you can then run your job using the compute node that is best optimized for the workload, such as a low-power Moonshot cartridge or a compute-intense cartridge.
• Enhanced capacity management
– Compute nodes can be provisioned on the fly.
– Storage nodes are a smaller subset of the cluster and, as such, are less costly to overprovision.
• Faster time-to-solution
Processing big data typically requires the use of multiple data management tools. If these tools are deployed on their own Hadoop clusters with their own – often fragmented – copies of the data, time-to-solution can be lengthy. With HP BDRA, data is unfragmented, consolidated in a single data lake; and tools access the same data via YARN or a connector. Thus, there is more time spent on analysis, less on shipping data; time-to-solution is typically faster.
Importance of flexibility in big data architecture
Dynamic expansionSince data sets are getting larger and larger, any big data solution deployed today must be designed to accommodate future growth. Inevitably, demands on your compute and storage tiers will grow – but not necessarily at the same rates. You should not become locked into a solution that forces you to expand both compute and storage resources at the same time. In HP BDRA, compute and storage tiers are no longer tied together, allowing you to scale a particular tier whenever needed, without incurring unnecessary costs, and without having to redistribute data.
Elimination of divergent data sources
Many organizations include groups that each take a different approach to big data. Typically this results in the creation of multiple copies of the data, residing in multiple locations; and data management applications may have to straddle multiple clusters. Having the same data replicated many times leads to management overhead and, often, fragmentation when independent copies diverge from the original.
Consolidating data and providing shared access allows HP BDRA to eliminate data divergence, reduce the need to move data, and enhance time-to-solution.
Rapidly evolving Hadoop ecosystem and tools
Designing HP BDRA around HDFS as a core technology provides a common, open-source framework that is able to support a rapidly evolving ecosystem. Since it offers a standard mechanism for accessing compute and storage, HP BDRA can become the focal point for big data today and in the future, supporting data management tools like Hadoop, Spark, HBase, Impala, Hive, Pig, R, and Storm.
By focusing on providing a central repository for big data and embracing features like YARN labels, this solution provides access to the data either directly or via a connector, thus making it the ideal platform for enterprise applications today and tomorrow.
Importance of open-source implementation
One of the key benefits of HP BDRA is its standards-based, open-source implementation, which helps HP and other vendors engineer the Hadoop trunk to work with this HP solution. For example, vendors can leverage their unique features and/or technologies to create plug-ins for Hadoop; in turn, such plug-ins can be used to optimize HP BDRA workloads.
For example, Mellanox has created a plug-in that can accelerate the Hadoop shuffle operation via hardware acceleration on their network interface card (NIC) product. This NIC technology is being incorporated onto a Moonshot cartridge in order to optimize workloads that benefit from low latency.
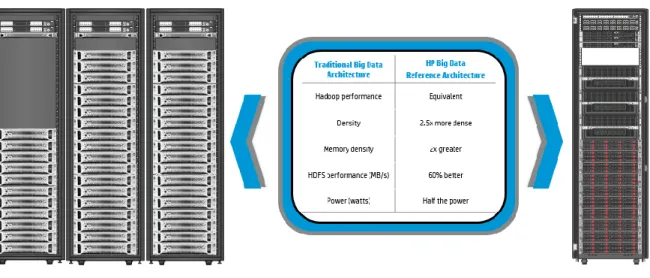
HP BDRA proof points
The HP BDRA solution is a re-imagined architecture for Hadoop. Figure 7 compares traditional and HP BDRA configurations that both deliver the same Hadoop performance.
Figure 7. Traditional architecture compared with a modern HP BDRA solution
Power consumption
As expected, using the latest compute and storage nodes in HP BDRA reduces power consumption and, thus, Total Cost of Ownership (TCO). Reduced power consumption also provides a significant advantage in cost/compute and cost/storage compared with the traditional architecture.
Overall footprint
By using the latest ultra-dense server technology from HP, the HP BDRA solution delivers equivalent Hadoop performance in significantly less rack space, reducing floor-space requirements in the data center.
Summary – the HP BDRA vision
The explosive growth of big data within organizations often results in multiple projects being deployed, each overseen by a different department. This approach results in data fragmentation and a proliferation of technologies, all of which need to be supported by IT organizations.
HP BDRA shows what is possible for any organization wishing to consolidate their big data efforts and provide access to a range of data management. Whether these tools use YARN or connectors to access the data, the HP BDRA solution can provide a firm foundation. To address modern, ever-increasing demands for high performance compute nodes, this white paper discussed the newest developments with the HP Apollo 2000 System and ProLiant XL170r Gen9 servers to handle the high density of the compute tier for HP BDRA. The HP Apollo 4200 Gen9 Servers provide the next generation in storage with the flexibility to deploy storage nodes in units of one; as a result, the density optimization and configuration flexibility for the HP BDRA vision has never looked better.
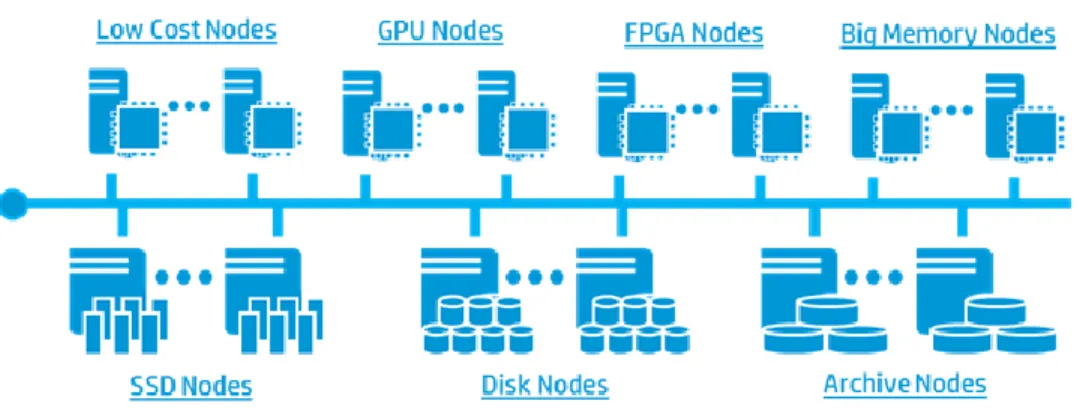
As shown in Figure 8, the reference architecture can be optimized to include multiple compute pools that are managed by YARN labels and multiple storage pools that are managed by Hadoop tiering.
Figure 8. Big Data Reference Architecture architectural vision
Implementation overview
HP is releasing HP BDRA as a reference architecture; however, to assist the customer, HP has created Bills of Materials (BOMs), available in distro-specific reference architecture implementation documents, that allow solutions based on this architecture to be built on-site by HP Technical Services, a VAR (value-added reseller), or the customer. HP BDRA is not an appliance; thus there are many opportunities for customizing a solution to meet your particular needs. For example, you can install the Hadoop distribution of your choice, you could specify additional head nodes, or vary the ratio of compute to storage.
If desired, you can take advantage of an HP Service to image, configure, and test the system on your premises. HP has spent many man-months optimizing and testing configurations for HP BDRA and has captured the information needed to facilitate a rapid deployment.
The first step is to build the cluster, then execute a set of benchmarks to ensure that compute, storage, and networking are all performing as expected. At this point, you can deploy the Hadoop distribution of your choice onto the cluster according to your organization’s standards. Finally, you run additional tests to validate the Hadoop installation.
HP offers services with a range of resources to help you deploy an HP BDRA solution, including the following: • Intellectual property (library of golden images, scripts, benchmarks and key settings)
• HP Data Services Manager (HP DSM), which provides single-pane management and helps you transition to big data • HP Insight Cluster Management Utility, for the provisioning and image management of clusters
• HP Cluster Test, for testing and deployment
Sign up for updates
hp.com/go/getupdated
© Copyright 2014-2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein.
Java is a trademark of Oracle and/or its affiliates.
For more information
Hadoop on HP: hp.com/go/hadoopHP Moonshot System: hp.com/go/moonshot HP ProLiant servers : hp.com/go/ProLiant HP Apollo: hp.com/go/apollo
HP Networking: hp.com/go/networking
HP FlexFabric 5930-32QSFP+ Switch: hp.com/networking/5930 HP A&DM Platform services: hp.com/services/Havenaas Partner websites
Cloudera and HP: cloudera.com/content/cloudera/en/solutions/partner/HP.html Hortonworks and HP: hortonworks.com/partner/hp/
MapR and HP: mapr.com/partners/partner/hp-vertica-delivers-powerful-ansi-sql-analytics-hadoop