Privacy risks in the use of Big Data
technologies
Governmental protection and tool analysis
Borja Robert Thoma
S1311220
March 21st 2016
MSc. Crisis & Security Management
Leiden University - Faculty of Governance and Global Affairs
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical or photocopying, recording, or otherwise,
This thesis would not have been materialized had it not been for a number of people.
First of all, I would like to thank my girlfriend Ante Fokkema for her love and support. She pulled me through some difficult times and
motivated me on numerous occasions.
Secondly, I thank Dr. Joery Mathhys for his guidance and advice during the entire research project.
A big thank you goes to Fam. Fokkema who so kindly and without reserve gave me encouragement and consultation whenever I
needed it.
Executive summary
With the global digitalization, an increase in the use of data will lead to different ways in which the policy- and decision-making process is being realized. Governments who intend to modernize the way in which they apply these streams of data, will only be able to legitimize their efforts if the privacy and fundamental rights of the population are adequately secured and protected. Therefore, in order to make the most advantageous use of sensitive data, a comprehensive legislation and norms regarding privacy are required.
The combination of the aspects mentioned in the first paragraph i.e. digitalization, government instruments and privacy appear in the implementation of the LSP in the Netherlands. The case of the LSP provides a comprehensive demonstration of the difficulties the Dutch government has experienced in realizing their attempts to modernize the healthcare sector. The Dutch government attempted to push through a policy that allowed the implementation of a system that required disputable technologies which can be linked to the concept of Big Data. This thesis argues that the applied technologies can contribute to the risk of privacy infringement. By applying certain tools, the Dutch government can adopt certain measures to push through their policy goals. The choices that are being made by the Dutch government regarding this case, can have conflicting results when it comes to the privacy of individuals that are making use of this system.
In order to address this issue, this research has been divided into five chapters. First of all, the research in this thesis will provide a global background on the emergence of the digitalized exchange of data, providing a concrete example and the privacy issues concerned with the developments. Secondly, the theoretical framework of the core aspects needed to answer the research question will emphasise on the Big Data technologies, the available instruments to governments and the fundamental rights regarding privacy. The third chapter will provide the methodology of this thesis in which the design of the research will be displayed, the research methods will be justified and the operationalization in order to validate the research methods. The fourth chapter will facilitate the analysis of the research in which the legal framework will provide the legislative foundations on which the LSP is based. It will also provide an overview of the current policy, the impact of the Big Data technologies and the government instruments on privacy. Finally, chapter five will provide the conclusion of the research in which the main research question will be answered and the expectations will be contemplated against the main results. In the discussion that follows, the acquired new insights will be translated into suggestions for policy solutions and further research.
Table of Contents
Executive summary ... 4
List of Acronyms ... 7
List of Figures ... 8
List of Tables ... 8
Chapter 1: Introduction ... 9
I. The birth of global data exchange ... 9
II. Origin - Google Flu Trends ... 9
III. Privacy issues ... 10
IV. Research question ... 11
V. Thesis structure ... 12
VI. Purpose and Relevance ... 12
Chapter 2: Theoretical Framework ... 14
I. Big data in the modern world ... 14
II. Privacy and the protection of personal data ... 20
III. Public policy instruments ... 24
Chapter 3: Methodology ... 32
I. Research design ... 32
II. Justification of research methods ... 34
III. Case study design ... 35
IV. Data collection ... 36
V. Operationalisation ... 37
VI. Summary... 43
Chapter 4: Analysis ... 43
I. Legal framework ... 43
II. Impact of big data technologies ... 51
III. Assessment of applied government instruments ... 57
IV. Impact of applied government tools ... 63
Chapter 5: Conclusion ... 66
I. Answering the research question ... 66
II. What has this thesis pointed out? ... 66
III. Expectations vs results ... 69
IV. New insights + Suggestions ... 70
V. Limitations of the research ... 71
References ... 72
List of Acronyms
Acronym *Translation Original definition
CERN European Council for Nuclear Research Conseil Européen pour la Recherche Nucléaire
MESH Modeling Environment for Software and
Hardware
UCLA University of California, Los Angeles
SRI Stanford Research Institute
NATO Nodality, Authority,Treasure,Organization
EDW Enterprise data warehouse
NLP Natural Language Processing
WBP Personal Data Protection Act Wet Bescherming Persoonsgegevens WPR Personal Data Files Act Wet Persoonregistraties
CBP Personal Data Protection Commission College Bescherming Persoonsgegevens
PMC Private Military Company
EHCI European Health Consumer Index
VWS Ministry of Health, Welfare and Sport Ministerie van Volksgezondheid, Welzijn en Sport
NEN Dutch Norm/standards (Institute) Nederlandse Norm (Instituut) CIBG Central Information point for Healthcare
Professions
Centraal Informatiepunt Beroepen Gezondheidszorg
RIVM National Institute for Public Health and Environment
Rijksinstituut voor Volksgezondheid en Milieu
SCP Social and Cultural Planning Agency Sociaal en Cultureel Planbureau NICTIZ The National ICT Institute in Healthcare Nationaal ICT Instituut in de Zorg VZVZ Association of healthcare providers for
healthcare communication
Vereniging van zorgaanbieders voor zorgcommunicatie
KNMG the Royal Dutch Medical Society De Koninklijke Nederlandsche Maatschappij tot bevordering der Geneeskunst
LHV National GP Association Landelijke Huisartsen Vereniging LSP National Switch Point Landelijk Schakel Punt
MIT Massachusetts Institute of Technology
Wgbo The Medical Treatment Contracts Act Wet op de geneeskundige behandelingsovereenkomst EPD Electronic Patient File Electronisch Patienten Dossier NPCF National Patient and Consumer
Federation
Nederlandse Patiënten Consumenten Federatie
AORTA Architecture, Design, Realisation, Quality Testing and Acceptation
Architecturen, O-ntwerp, Realisatie, Toetsen van kwaliteit, Acceptatie).
ZSP Healthcare Service Providers Zorg Service Providers GBZ Qualified Healthcare Information System Goed Beheerd Zorgsysteem ZIM Central Reference Index Zorg Informatie Makelaar
HL7v3 Health Level 7 version 3 Standard
RIM Reference Information Model
UZI Unique identification number for healthcare providers
Unieke Zorgverlener Identificatienummer
BSN Citizen Service Number Burger Service Nummer
SBV-Z Sectorial Message Supply – Healthcare Sectorale Berichten Voorziening – Zorg
VPN Virtual Private Network
PPI Personal Identifiable Information
XIS Healthcare Information System Zorginformatie systeem
GZN Well-managed healthcare network Goed Beheerde Zorgnetwerken ICPC International Classification of Primary
Care
Internationale code voor eerstelijns zorg
RVZ The Council for Public Health and Healthcare
Raad voor Volksgezondheid en Zorg
OZIS Foundation for the cooperation between information systems
Open Zorg Informatie Systeem
*Some acronyms have been translated from their original language to English
List of Figures
Figure 1. Overview of technologies for big data by Thomas Davenport ... Error! Bookmark not defined.
Figure 2. Sluice representing the flow and filtering of Big Data... Error! Bookmark not defined.
Figure 3. Graphic reproduction of research design applied to Dutch healthcare. ... 32
Figure 4. Visualization basic principles for dealing with medical data. ... 43
Figure 5. Graphic summary of Legal framework ... 51
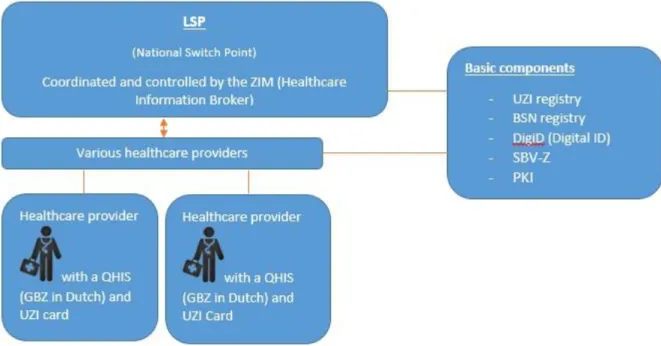
Figure 6. LSP network as provided by NICTIZ ... 53
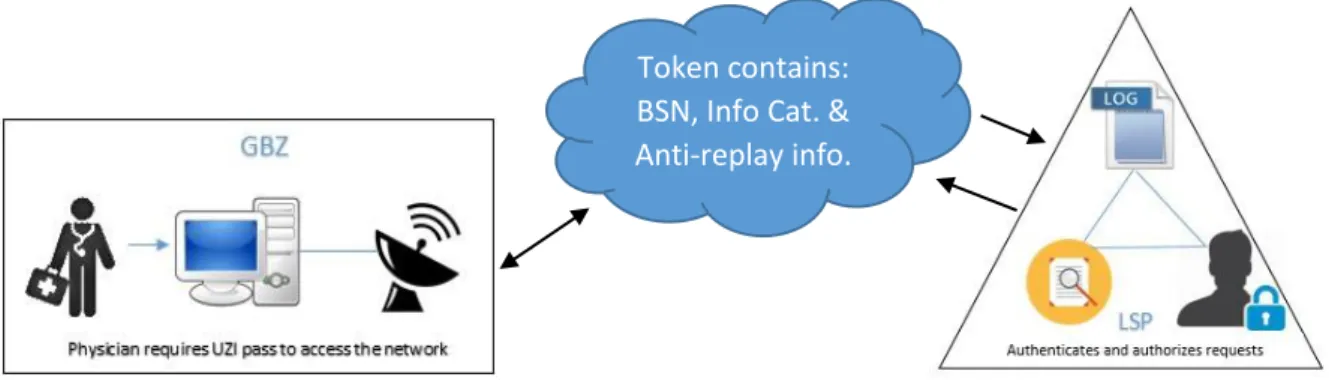
Figure 7. Indication of token data structure. ... 54
Figure 8. Visualization of an XIS... 55
List of Tables
Table 1. Six Sources of Evidence: Strengths and Weaknesses (Yin, 2009). ... 36Chapter 1: Introduction
I.
The birth of global data exchange
On March 12th 1989, Tim Berners-Lee, a British scientist at CERN, proposed the idea of “MESH”
to his management. Exactly 25 years later, his proposal is now globally known as the World Wide Web (WWW) or in short, the Web. He initially created the web as a way to automatically share information between the researchers at CERN but also for scientists in universities and institutes around the world.
The concept of the Internet had already been established in 1969 as a network for linking research centres at UCLA and SRI. The internet made it possible for multiple separate networks to be joined together into a hub of networks. The communication was thus also limited to the networks that were interconnected within the hub. Tim Berners-Lee’s World Wide Web provided a solution to the limits of communication in this closed and proprietary system. The web made it possible for everyone in the world to interconnect using the internet. In 1993, the company CERN made the World Wide Web available in the public domain through a freely available web server, a basic browser and large amount of code. By doing so, the web was now able to flourish and expand globally. Digitalized information could now be shared and retrieved in the entire world. With this new open platform for an infinite number of applications and services, the future of the internet was established.
With the creation of the internet it was now possible that if someone wanted to find a document, there was a big chance that it would be available on the internet. This availability of data described the internet as “the Web of data” (Berners-Lee, 2014) which allowed users to share and alter and use the digital data at will. It also meant the birth of the term Big Data. The concept of Big Data is primarily characterized by the indication of its size. The meaning of the word “Big” in Big Data refers to the number of independent data sources which each have the potential to interact and are thus inconsistent and unpredictable combinations. Which, in turn, makes it very hard to be managed by standard data management techniques. In sum, Big Data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process the data within a tolerable elapsed time (Snijders, Matzat & Reips, 2012).
II.
Origin - Google Flu Trends
1- Data analysis produces uncannily accurate results.
2- Every single data point can be captured, making old statistical sampling techniques obsolete.
3- It is passé to fret about what causes what, because statistical correlation tells us what we need to know.
4- Scientific or statistical models aren’t needed because “with enough data, the numbers speak for themselves”
In his article, Harford refers to the information, which is retrieved from these type of web searches, as “found data”. The problem with this type of data is that, when correlations are being made, it easily leads to oversimplifications of ways to understand people’s lives. The Google Flu Trend team did not bother to develop a hypothesis about which search terms might actually be correlated with the disease itself. They did not try to figure out what exactly caused what. “They were merely finding statistical patterns in the data. They cared about correlation rather than causation” (Harford, 2014). In order to make sense of the information we gather and to come to the right conclusions, we need to make sense of the dichotomy between correlation and causation. The dichotomy between correlation and causation is that causation can be correlation led, that is, causal factors may remain hidden or unknown and only come to light after being revealed by the regression analysis of correlative data. Having said this, Google Flu Trends analysis of the correlations it made between the found data might have resulted in successes at first, but the reliability of the Google Flu Trend tool remained fragile. One reason for their failure was that the information on the internet concerning the flu could be easily influenced. Increasing media reports triggered people to search for flu symptoms on the internet even if they were healthy and thus influencing the accuracy of the Google Flu Trend analysis. The predications Google made with their Flu Trends analysis could have worked if they were made in a stable environment. The fact that we live in an ever changing world implies that we need to keep looking if the causation in the correlations we make is adequate.
III.
Privacy issues
“Technology is neither good nor bad; nor is it neutral…technology’s interaction with the social ecology is such that technical developments frequently have environmental, social, and human consequences that go far beyond the immediate purposes of the technical devices and practices themselves” (Kranzberg, 1986)
Melvin Kranzberg indicates yet another attribute of the big data technology. The consequences of the interaction of the technology that is used to mine, gather and store big data often have social and human consequences. One of the consequences of big data is its tendency to be hard to delete, making privacy a common concern. The following citation indicates how the use of big data can lead to privacy issues.
It is cases like these that emphasize the issues with the mining, collecting and storing of big data. The dilemma with the privacy issues in big data is that there is no concrete instance that can be point at and be declared as damaging to an individual. These ethical implications are still difficult to understand in the big data phenomenon. Another example of misunderstanding the correlation in a big data is the case of the two British teens that were arrested on terror charges concerning their Twitter jokes (Hartley-Parkinson, 2012). Their public tweet was taken out of context and analysed in a way they could never have imagined. This breach of privacy emphasizes the ethical dilemma in modern day society. But also governments struggle to act ethical in their online data collection which also indicates the importance of accountability.
In light of these privacy infringements, one of the main areas in which privacy issues have emerged due to the increasing technological possibilities, such as the big data phenomenon, is the healthcare sector. In a sector where doctor-patient confidentiality plays such an important aspect, the increasing use of big data balances on the fine line between added customer value and privacy infringement. This is where governments should step in to monitor and regulate the situation.
IV.
Research question
As the previous sub-chapters indicate, history shows that a lot has happened in the IT world that has led to the birth of global data exchange. Many technological innovations have led to new possibilities we could only dream about or were displayed in ideological futuristic movies. The birth of Big Data has triggered many of these innovations. However, technological innovation often goes hand in hand with sociological issues. In the field of big data, this is particularly the case. Based on these social and policy related issues, this master thesis will focus on the following research question:
To what extent do the different government instruments impact the quality of healthcare information protection taking into account the use of big data technologies in the healthcare sector in the Netherlands?
In order to answer the main research question, we need to break it down and distinguish the various sub-questions that can be formulated. The main research question emphasizes one of the issues that play an important role when dealing with big data technologies, namely privacy breaches. Based on this observation, the first sub-question that can be formulated is the following:
How is the current policy on privacy set up and what are its effects in the healthcare sector?
Many individuals complain about privacy infringement issues when the topic of big data comes along. By looking at the issues patients and doctors have with a theme like big data, we can establish the core issues we need to find a solution for. The societal issues that these privacy breaches bring along result in the need for civilians to be able to protect themselves against these infringements. This is where the government gets involved. The next question that will then present itself is:
By formulating this second sub-question, this thesis looks at what role the government plays and which privacy policy it can provide in the protection of its civilians. The research that will be conducted to answer this sub-question will look at the NATO-model that was developed by Christopher Hood. Hood’s model proposes that every policy tool uses one of the four categories of resources available to governments. This governing of resources will be the main analyses of how the government can use its instruments in order to guard public privacy from the use of big data in the healthcare sector. Once this is researched, this thesis will need to look at the correlation between the government’s applied instruments and the infringement by big data. This research also introduces the last sub-question of this thesis.
Which government tools have been used and how have they impacted the quality of healthcare information protection?
In order to answer this sub-question, this thesis will look at court cases, reports and other legal publications which indicate that the breaches on one’s privacy have indeed been the result of big data technologies. Also, this last question incorporates the first and second sub-question which emphasize on the infringement of big data on an individual’s privacy and the instruments the government can apply to protect them. Based on the analyses and research of these three sub-questions, an adequate answer can be given to the main research question of this thesis. The following sub-chapter will provide an outline on how the abovementioned research will be conducted.
V.
Thesis structure
The first chapter introduces the subject of global data exchange and how it has led to the creation of Big Data. It also introduces the reader to one of the main concerns that surround the theme, namely privacy in the healthcare sector. Ultimately, chapter 1 builds up to proposing the research question and sub-question which will form the basis for this master thesis. The second chapter provides the reader with a theoretical oversight of the thesis in which the concepts and theories concerning big data and privacy infringement will be analysed. After that, the theory concerning the instruments that the government can implement will be elaborated upon. In the third chapter the methodology of this thesis will be set out, including the research design, data sources and operationalization. This chapter will describe the methods that will be used to for this research. In chapter 4 the legal framework and current regulatory policy, will be analysed which will answer the proposed sub-questions in chapter 1. Chapter 5 will conclude the impact of infringement and the ways in which big data has negatively affected the privacy of individuals in the healthcare sector. It will also provide recommendations for further research. The data for this research will come from the analysis of court cases, reports and publications.
VI.
Purpose and Relevance
Academic Purpose
In the field of cyber security, big data is one of the fastest growing themes we are currently witnessing. The abundance of information that is now available comes with its ethical issues concerning the mining, gathering and storing of this new set of data. As an effect, social scientists are struggling with this ethical shift in structure that defines the morality of using these techniques.
“Much of social science ethics focuses on rights and responsibilities toward the individual human participant. Big data as a technique does not accommodate this well.” (Fairfield & Shtein, 2014)
This inherently affects the element of privacy in the healthcare sector. In this field, the academic purpose lies in the broad scale of methods that can be applied by the Dutch government to protect this basic human right.
Societal Relevance
According to Eijkman and Weggeman, providing safety and security has always been a core task of the state (Eijkman & Weggeman, 2013). Long before the emergence of big data, the traditional focus of social science has been on physical harms protecting individuals. In the past decades a major shift has occurred from this traditional focus to what we can now distinguish as the information society. The IBM Community Development Foundation has given the following definition for this phenomenon:
“A society characterized by a high level of information intensity in the everyday life of most citizens, in most organizations and workplaces; by the use of common or compatible technology for a wide range of personal, social, educational and business activities, and by the ability to transmit, receive and exchange digital data rapidly between places irrespective of distance.” (IBM Community Development Foundation, 1997)
Chapter 2: Theoretical Framework
This chapter will set out the theoretical framework of this thesis. By providing this framework, the reader will be introduced to the existing literature and theories that can be found on the subjects of big data, privacy and public policy instruments. The main concepts and key elements will be set out in order for the reader to form an adequate academic background which will help the reader understand the general direction of the research.
I.
Big data in the modern world
The rise of digital and mobile communication has made the world become more connected, networked, and traceable and has typically lead to the availability of such large scale data sets (Snijders, et all, 2012). In the modern world, we have seen the arrival of Big Data but governments and companies do not know what to do with it, how to analyse it, how to make more revenues or to cut expenses by using Big Data. In this case the word “Big” refers to the complexity rather than the volume of the datasets. The stream of data that flows in daily life ranging from telephones to credit cards, trains to airplanes, televisions to computers, infrastructure of cities to factories and more, is so massive and fast that one might identified it as the Big Data revolution. But, however, it is not the massive amount of data that is revolutionary. “The big data revolution is that now we can do something with the data.” (Shaw, 2014). The Big Data revolution has given birth to new ways of connecting datasets and have in turn generated new insights. Seeing the patterns in the visualization of the data requires a creativity which humans can do far better than computers. Visualizing the datasets often proves to be indispensable to the process of creating knowledge. For example, by using the tools and new ways of linking the datasets, correlations can now be made between two completely different fields of study like economy and medicine. The Institute for Quantitative Social Science (IQSS) at Harvard University, is another remarkable example of how Big Data has had a relevant impact on the modern world. The institute has been characterized as an agglomeration of expertise for projects from different disciplines. Its aim is to solve the problems in human society. In practice this translates to the following process. A qualitative expert in his or her respective field invites a statistical researcher who has no specifically detailed knowledge of that field. The statistical researcher comes in and by using modern data analysis, adds massive insight and value to the field. The key aspect in this form of data analysis is the quantification of adequate amounts of information. When this happens, modern statistical methods will outperform individuals or groups of people in most of the cases.
In the article “Critical Questions for Big Data”, Danah Boyd and Kate Crawford define Big Data as a cultural, technological, and scholarly phenomenon that rests on the interplay of:
1) Technology: maximizing computation power and algorithmic accuracy to gather, analyse, link, and compare large data sets.
2) Analysis: drawing on large data sets to identify patterns in order to make economic, social, technical, and legal claims.
In order to make sense of the importance of big data in the modern world, an analysis has been made on the basis of the book: Big Data at Work: Dispelling the Myths, Uncovering the Opportunities by Thomas Davenport (2014). According to Davenport, the importance of big data can be analysed by looking at four components of how big data works within an organization. These components are, the success, the change, the technology and the analytics which are concerned with Big Data.
Component 1 - Success
In order to succeed with big data, Davenport developed a model for how to build analytical capabilities within an organization. This model, called the DELTA model, can be characterized by the following five fundamental aspects of succeeding with big data: Data, Enterprise, Leadership, Targets and Analysts. Coincidentally the Greek letter for DELTA stands
for change in an equation.
Figure 1. DELTA model by Thomas Davenport
The data aspect in this model is obviously one of the most important factors, if you want a big data project to succeed. The reason for this is because the focus of a big data project lies in the capturing, processing and integration of the data so that it can be analysed.
The second aspect in this model takes an enterprise focus. This translates to the sharing of data, technology and people across the company in order to reach your analytical goals. Especially in large companies, the integration of big data with more traditional analytics will lead to more enterprise coordination. The reason for this is because big data is not a separate part of the company, there are no big data departments. “Analytics on big data have to coexist with analytics on other types of data” (Davenport, 2014).
The third aspect takes analytical leadership into consideration. Just as in traditional analytics, leadership plays an important part in the successful realization of a big data project. Davenport argues that there are three key leadership traits for big data:
1) A willingness to sponsor experimental activity with data on a large scale. The willingness factor, for taking an interest and thus experimenting with big data, eliminates barriers to the implementation of innovative ideas and offerings.
2) A degree of patience. With the vast amounts of data coming in, it may take several years before its value is known. Leaders of big data should therefore be patient with the data before there is any sense of a payoff.
The fourth aspect deals with the targets for big data. This implies that organizations need to determine where they are going to apply big data and analytics within their businesses. When a company exploits the possibilities of big data, new services and products may arise from it. This change requires big data initiative targeting with product development and strategy processes. Therefore, targeting clear choices is a necessary process.
“Data analysis always takes place in the context of business strategy and decisions. As such data scientists have to understand what business problems they are solving and how their work advances the company's goals.” (Barker, 2014).
The fifth and final aspect of the DELTA model incorporates the human side of big data. This aspect is referred to as “A cadre of Analysts” in figure 1. Davenport (2014) argues that in order to be a successful data scientist, you need to have a combination of technical and analytical skills. This has been well substantiated in a quote from Songkick CTO Dan Quine in ZDNet magazine.
"We believe skills and creativity are at least as important as the pure technical skills for data scientists,” (Barker, 2014)
There are, however, two more key factors to consider when an organization wants to succeed with a big data project. The DELTA-model indicates the various aspects on how an organization can build the analytical capabilities. However, in order to be able to apply and maintain those analytical capabilities, organizations should also consider the following traits which indicate that the organization is likely to succeed with a big data project. Davenport (2014) calls this, the culture and embedding of big data. For a big data culture, Davenport points out fives attributes that successful organizations should have. These are;
1) Impatience with the status quo, and a sense of urgency. 2) A strong focus on innovation and exploration
3) Belief in technology as a source of disruption 4) A culture of commitment
5) Non-hierarchical and meritocratic organization
The other trait that Davenport emphasizes, is embedding big data into operational and decision processes. The process of extracting data from a big flow of information has been facilitated by big data technologies into a timely and efficient fashion. However, it is still important that there is human supervision or review which can override the recommended actions from such automated systems.
Component 2- Change
The second component Davenport points out is, how big data can change your organization. The technologies that are needed to implement big data in an organization is already available today. The problems that many organizations face and the reason why they have not included big data in their business yet, lies in the unfamiliarity with the impact it may have on their organization.
Based on this statement, we can see that in order to build and deploy innovations, a clear vision and determination is needed to take on big data in an organization. Organizations will have to be able to collect a considerable amount of data, provide room and resources for IT development, integrate systems and existing data, and the development of an analytical model.
Figure 2. Historical industry use of data and analytics by Thomas Davenport
Data disadvantaged Underachievers Overachievers
Health-care organizations Traditional banks Consumer products
B2B firms Telecom Insurance
Industrial products Media and entertainment Online
Retail Travel and transport
Electric utilities Credit cards
In figure 2, Thomas Davenport distinguishes three industries which were ahead of others when it comes to understanding their businesses and customer relationships. Davenport (2014) clearly categorizes the data disadvantaged industries from the underachievers and the overachievers.
The data overachievers are the leaders when it comes traditional data structured analytics. The companies classified as overachievers were the ones who were in consumer-oriented industries with a lot of data to process. The data disadvantaged industries include those organizations that were analytically impaired because they did not have much data to begin with and if they did, the data was not well structured. An example of a data disadvantaged industry are health-care organizations. The providers of health-care services used to store their medical record data as text-based notes about the patients. With the digitalization of the industry, a large part of these medical records turned into electronic medical records. Therefore, one of the reasons why the health-care industry is classified as data disadvantaged is because there did not yet exist a widespread data set of electronic medical records and half of those existing records consisted out of unstructured text. The industries classified as underachievers are simply not using their data effectively to benefit their customers or themselves.
With the emergence of big data the industries, which have been underachieving or have been disadvantaged in their use of data and analytics, can now take advantage of the innovations that have taken place and improve their business and industry. They will, however, need to adapt their business attitude and behaviour in order to succeed. In the health care industry, for example, the emergence of a large stream of electronic data will provide a more structured data set from hospitals, general practitioners and other type of medical clinics. These medical records that were previously stored only has text-based documents, such as notes from general practitioners and nurses, can now be captured and classified through the use of natural language processing technology. Another benefit of big data in the healthcare sector is the medical claims that insurance companies have. Through the use of big data these medical claims can now be combined and integrated with the information from healthcare providers.
The stream of data in healthcare is endless. There are already huge amounts of data available through the use of a model called connected health. It uses technology to provide healthcare remotely by delivering patient healthcare outside the hospital or doctor’s office, which is also referred to as remote monitoring. Another great example of the change that big data facilitates, is the available data from quantified self-devices. The quantified self is a way of personal monitoring with which the data that is generated every day in the human body, can be turned to information and knowledge about how your body works. Information such as sleep patterns, blood pressure and physical activity can provide meaningful insights into a patient’s health. It is obvious that this type of data is very much sought-after by doctors and hospitals. As we can derive from the emergence of big data, there are many opportunities that will transform the future of industries.
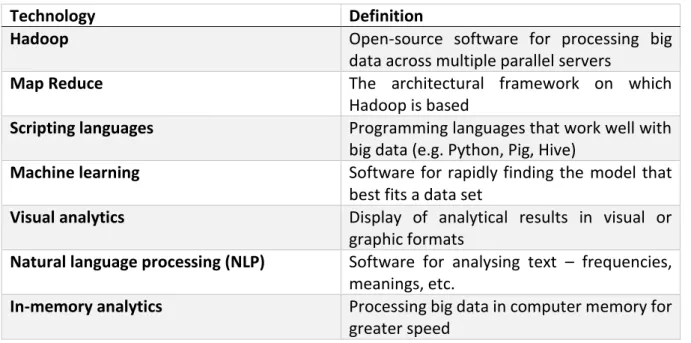
Component 3- Technology
The third component that Davenport sets out is the technology that is used for big data. It is, in the end, the technology that makes the management and analysis of big data possible. As the previous chapters have indicated, the new thing about big data is that the information comes in large volumes and unstructured formats. With big data technologies, we are able to process and analyse textual, video and audio content with which we can create models to optimize, structure and predict the data. This was almost impossible to do with traditional database software.
Figure 3. Overview of technologies for big data by Thomas Davenport.
Technology Definition
Hadoop Opensource software for processing big data across multiple parallel servers
Map Reduce The architectural framework on which Hadoop is based
Scripting languages Programming languages that work well with big data (e.g. Python, Pig, Hive)
Machine learning Software for rapidly finding the model that best fits a data set
Visual analytics Display of analytical results in visual or graphic formats
Natural language processing (NLP) Software for analysing text – frequencies, meanings, etc.
In-memory analytics Processing big data in computer memory for greater speed
change with big data technologies is that previously the data was stored in a data warehouse. A data warehouse is an analysis pool where various data sets address a variety of purposes and topics. As previously mentioned, big data can be explained as a fast flowing river of endless information. This stream of information would very soon fill up the data warehouses of traditional analytics. Therefore, technologies such as Hadoop are necessary to store a large amount of data for a short time, analyse the data, and then let it drain away. A good example is the working of a sluice, “sluis” in Dutch. On the one side you have the flowing river of water which fills up the sluice. In the case of big data the flowing river of water represents information from web logs, documents and PDF’s, images and videos, and social media etc. on which your company/boat depends/floats. The sluice then briefly fills up with water/information. This can represent the data warehouse filling up with information for analysis. After filtering out the surplus of water/information, your company can continue its course.
Davenport (2014) refers to this approach as the data management approach which is different from the original enterprise data warehouse (EDW) approach used in traditional analytics. This new approach does, however, not replace traditional analytics but supplements its usage in order to deal with big data. Another key aspect where the new technology differs from the traditional one is the involvement of machine learning, which has been mentioned in figure 3. Before the big data movement, the traditional approach to statistical analysis was based on hypothesis which the analyst would test to see if it would fit with the data. With machine learning, also known as automated modeling (Davenport, 2014), a number of different models are tested with the data to see which one fits the best.
“The benefit of machine learning is that it can very quickly generate models to explain and predict relationships in fast-moving data” (Davenport, 2014).
However, the problem with machine learning is that it finds variables that are important in the model but the correlation with the data is difficult to understand. That is where the concept of analytics comes in.
Component 4- Analytics
do this, is by analysing speech-to-text data from call centre recordings, also known as natural language processing (NLP). Analytics is, however, not a new concept. In order to understand how analytics have changed with big data, we need to look at its historical context. Davenport (2014) distinguishes three eras of analytical orientation which he indicates as analytics 1.0, analytics 2.0, and analytics 3.0. The first era of analytics was oriented towards large enterprises which gathered small amounts of structured data in order to make adequate internal decisions. The type of analytics that was used was more of a descriptive type which based its results from reports on the past also known as reporting. The second era of analytics was largely applied by start-up companies who wanted to work on new products. They had large and unstructured sources of data which they gather from open sources. This large stream of open source information was given the term big data. This is the era where analysts were given the new name of data scientists. Their work was regarded as a more predictive type of analysis because they created models based on past data to predict the future. The third era Davenport mentions is analytics 3.0 which is a combination of the best aspects of the first two eras. It combines the traditional analytics from the first era with the big data movement from the second era. This makes analytics 3.0 accessible to any industry in the data-driven economy. The characteristics in this third era emphasize on prescriptive analytics, creating models to specify optimal behaviours and actions. There are, however, also risks involved with these models. By embedding analytics into key processes, it creates a high level of operational benefits for organizations. However, high-quality planning and execution become a very critical point on the agenda. The consequences of wrong data and analytics could cause e.g. an automated car, Google car, to crash, which will nullify the trust that has been created in prescriptive analytics.
As abovementioned, the use of big data can provide us with new and better insights in the healthcare sector. Data of high-quality is increasingly in demand so that patients can make better choices regarding their healthcare plans and their healthcare providers. It also provides a more cost effective clinical care in which the quality of health care services can be assessed. The possibilities are endless and range from the monitoring of fraud and abuse in the healthcare system to the effective research of the causes, prevention and treatment of injuries and diseases. The benefits of a systematic collection of a broad range of personal data can, however, have severe consequences regarding citizen’s personal privacy (Gostin, 1997).
II.
Privacy and the protection of personal data
“Information about our searches, browsing history, social relationships, medical history, and so forth is collected and shared with advertisers, researchers, and government agencies” (Narayanan& Shmatikov, 2010).
The emergence of communication technologies, but also information technologies, has led to an increasing ease with which personal data can travel across the globe. In the abovementioned sub-chapter, the possibilities these new technologies offer have been introduced and identified. However, they have also created a whole new set of challenges.
These challenges raise a number of problems in data protection and privacy issues. One of these challenges can be found in the use of big data techniques with which profiles can be prepared and the behaviour of individuals, and groups of individuals, can be predicted. The big data technology involved in these processes compiles the data and then analyses the personal data which has been collected from various online sources. By doing so, the data collected from many different sources can reveal information about the habits and interests of individuals. In order for this data to not directly reveal all the information about the analysed individuals, the data is being “anonymised”. According to the Privacy Technology Focus Group, data anonymization is the "technology that converts clear text data into a non-human readable and irreversible form, including but not limited to pre-image resistant hashes (e.g., one-way hashes) and encryption techniques in which the decryption key has been discarded." (U.S. Department of Justice, 2006).
There are, however, strategies which are designed to mine the anonymous data. This data mining strategy is called, “de-anonymization”. This is done is by cross-referencing the anonymous data with other data sources. New big data technologies have made this an easy and fast process. Once the anonymous data is cross-referenced, it is linked to various other data sources. For this process, any information that distinguishes one source of data from another data source, is applicable for de-anonymization.
Jeff Bezos of Amazon is known for saying, “we never throw away data,” simply because it is difficult to know when it may become important for a product or service offering down the road. (Davenport, 2014)
Before going into the various available strategies for combating privacy infringement, a closer look needs to be taken at the established legal concepts regarding our privacy.
To explain the legal concepts I will start with the most broadly defined regulations concerning our privacy, which is set out in article 12 of the Universal Declaration of Human Rights, and continue in a top-down approach to the more international and national legal frameworks regarding the concept of privacy.
“No one shall be subjected to arbitrary interference with his privacy, family, home or correspondence, nor to attacks upon his honour and reputation. Everyone has the right to the protection of the law against such interference or attacks.” (UDHR, art.12)
and regulated by law. This desire to safeguard personal information requires a regulation of privacy and private information. This may lead to concerns because in the digital form, personal data can easily cross borders and thus creates tensions between national regulations on what the correct and most adequate way to handle privacy data actually is. State regulation stops at national geographic borders but digital data can flow easily from one country into another which may create regulatory problems on what is accepted and not with regard to sharing personal information and privacy. These differences in regulations may become problematic when countries face a cross-border spill over.
“Regulatory spill over occurs when the impact of regulation is not limited to the origination jurisdiction. Unilateral national Internet regulations may affect both the Internet activities of users in other jurisdictions as well as the regulatory approach of other nations” (Movius & Krup, 2009)
These regulatory spill overs can lead to confusion and inefficiencies for the countries and companies involved as well as the public (Movius & Krup, 2009). It is, therefore, important that general European directives are created. One of these directives is the privacy policy set out in the European Union. This directive, indicated as directive 95/46/EC, forms a regulatory framework which aims to create a balance between “...a high level of protection for the privacy of individuals and the free movement of personal data within the European Union” (European Parliament, Council of the European Union, 1995). The main objective of directive 95/46/EC, is that all the Member States of the European Union shall protect the fundamental rights and freedoms of the people and in particular their right to privacy, with respect to the processing of personal data. In the case of directive 95/46/EC, the processing of personal data applies to both automated and non-automated systems. This means that the directive applies to both computer database systems as well as traditional paper files. However, the processing of data is only permitted by law if it corresponds with the following criteria, set out in the European Parliament and Council Directive 95/46/EC of 1995. These criteria are:
The data subject has unambiguously given his consent.
Processing is necessary for the performance of a contract to which the data subject is party.
Processing is necessary for compliance with a legal obligation to which the controller is subject.
Processing is necessary to protect the vital interests of the data subject.
Processing is necessary for the performance of a task carried out in the public interest or in the exercise of official authority vested in the controller or in a third party.
Besides these criteria, there are number of principles that must be met in order for the processing of data to be lawful. The “principles of data quality”, as referred to in Directive 95/46/EC, include the fair and lawful process of personal data which has been collected for a previously specified, explicit and legitimate purpose. Furthermore, a data processing activity is only relevant when the collected data is adequate, relevant and not excessive, accurate and, where necessary, kept up to date. The stored data may not be stored longer than it needs to and may only be stored for the purpose or purposes for which they have been collected.
In order to comply with the principles of data quality, there are special categories with which one needs to comply. There are a number of categories which prohibit the process of personal data. For example, it is not allowed to reveal racial or ethnic origin, political opinions, religious or philosophical beliefs or trade-union membership, of the subject in question. It is also forbidden to reveal data concerning the health or sex life of the subject. However, there are a few exceptions where the processing of the abovementioned categories is allowed. A good case in point is the protection of vital interests of the data subject. Other exceptions include necessary data processing for the purposes of preventive medicine and medical diagnosis (European Parliament, Council of the European Union, 1995).
However, when it comes to the person in question, he or she has the following rights which he or she can exercise. First of all the data subject has the “right to obtain information”. The person, company, or institution that processes the data (also known as the controller), must provide the person whose data are processed with specific information relating to the controller. This information includes the identity of the controller, the purposes of processing, the recipients of the data results etc. The second right the data subject has is the “right of access” to the processing results. The individual subject to the processing of his or hers data, should have the right to obtain information from the data controller. The third and final right of the person whose data are processed is the “right to object” to the processing of data. By exercising this right, the individual can object, on legitimate grounds, to the processing of data relating to him or her. The individual also has the right to object, on request and free of charge, to the processing of personal data that the controller anticipates being processed for the purpose of direct marketing. Finally, the data subject should be informed by the controller before personal data are disclosed to third parties for the purpose of direct marketing. By being timely informed about the disclosure of his or her personal data, the controller expressly offers the individual the right to object to the disclosure of the data.
These abovementioned rights, which have been set out in the European Parliament and Council Directive 95/46/EC of 24 October 1995, also give every individual the right to a judicial remedy for any breach of the rights regarding data processing. These rights have been guaranteed, thanks to Directive 95/46/EC, by the national law of the involved Member State.
everything in between. The WBP entered into force in 2001 in the Netherlands and comprises general legal rules to protect the privacy of citizens. This meant that the Netherlands met the EU data protection Directive’s requirements to bring the Dutch national legislation in line with Directive 95/46/EC of October 1995. This act replaced the Data Protection Act or “Wet persoonregistraties” (WPR) of 1989. The main difference between these two acts, lies in the expansion of the scope of application. The WBP sets requirements on the entire processing chain which includes the collecting, recording, storing, altering, linking and consulting of personal data as well as disclosing personal data to third parties and the erasure or destruction of personal. The WPR, in contrast, mainly regulated the requirements with regard to the so-called “personal data registrations” data (Co-operation Group Audit Strategy, 2001).
The newly formed WBP has two main points of view on the protection of data. One being the legal approach, and the second being the general approach. These approaches have been summarized in the Privacy Audit Framework, (Co-operation Group Audit Strategy, 2001).
Legal:
The collection of personal data takes place for specified, explicit and legitimate purposes, for example with the consent of the data subject or on the basis of a legal obligation. Further processing of personal data must be compatible with the original purpose; personal data should be relevant, not excessive, adequate and accurate.
General:
Processing of personal data offers safeguards that the right personal data are available for the right purpose, on the right grounds, for the right people at the right time.
In the Netherlands, the CBP is competent to investigate the way in which the current privacy law is implemented in the processing of personal data. Therefore, the CBP has been appointed to supervise the compliance of the WBP with the European Directive.
The emergence of electronic data banks in healthcare has raised another issue: each citizen’s right to privacy compared with the collective benefit to society when critical data on quality assurance and scientific research are shared by an array of network users. (Gostin, 1997)
III.
Public policy instruments
The previous sub-chapter has provided an overview of the main privacy laws in the European Union and in the Netherlands. In this chapter, the main concepts and theories regarding the implementation of the requirements formulated in international and national laws, will be set out. In order to guarantee the rights of citizens and employees in an adequate way, a proper system of general processing measures and procedures must be created. This system needs to take into account the specific protective measures necessary for processing personal data. Therefore, a well-balanced policy, which aims at protecting privacy, must take an important place in the management cycle.
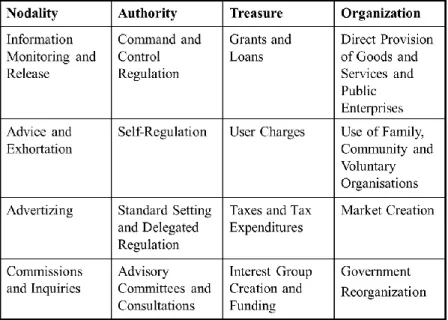
various policy tools they can apply in order to come to an adequate policy which ensures optimal privacy protection. These policy tools are also known as policy instruments and governing instruments. They are the actual means that governments use to implement specific policies. Policy options that emerge from the initial policy formulation stage, therefore, will not only specify if governments should act on a policy issue, but also how to best address the problem and implement a solution (Howlett, Ramesh & Perl, 2009). There is a large variety of instruments available to policy-makers. One way to determine which policy style a government should incorporate is by creating a taxonomy of the policy instruments. This classification of concepts and instruments helps policy-makers to understand the basic strategies and types of instruments required to identify the resources that governments work with (Howlett, Ramesh & Perl, 2009). One simple, yet strong classification, known as the ‘NATO model’, was developed by Christopher Hood. With this model, Hood suggested that all policy instruments used one of four categories of governing resources. He argued that governments confront public problems through the use of information in their possession as a central policy actor (nodality), their legal powers (authority), their money (treasure), or the formal organizations available to them (organizations). Together, these make out the four pillars in the ‘NATO model’ (Howlett, Ramesh & Perl, 2009).
Figure 3. Christopher Hood’s ‘NATO model’ . Howlett, M., Ramesh, M. & Perl, A., (2009)
These resources can be used by governments to influence or even manipulate policy actors and thus monitor society and alter its behaviour. Hood’s ‘NATO model’ provides governments with an overview on how to govern their resources. This is set out in a classification scheme which shows a basic taxonomy of instruments found in each category. These tools or instruments have been categorized by two main objectives. First, Hood looked at which of the resources the main instrument relied upon for its effectiveness. Second, he looked at whether the instrument is designed to effect or detect changes in a policy environment.
Nodality
The first resource governments can apply, involves the use of information-based resources. The tools in this category work because of the nodal position governments take in public policy systems and sub-systems. One of the tools in the nodality pillar is the use of ‘Information Monitoring and Release’. A concrete example is the organization of public information campaigns. By disseminating information through public service advertising, individuals and firms can draw their own conclusions and act upon them how they best seem fit without obligating them to respond in a specific way. This way of information collection and distribution can only, effectively, work if there are specific freedom of information or access to information laws. According to Terence Qualter, such legislation is usually accompanied by privacy acts and official secrets acts, which balance open access with restrictions on the release of some types of information, the exact content of which varies from country to country (Howlett, Ramesh & Perl, 2009). In order for public information campaigns to have an effect on policy, governments must also be able to calculate the impact of data on societal actors.
The second instrument in the nodality pillar is the use of ‘advice and exhortation’. Unlike disseminating information through public campaigns and hoping that public behaviour will change to a desired manner, this resource makes use of public effort in order to influence society’s behaviours and preferences. In practice, this form of government instrument can be found in public advertisements that promote healthy lifestyles or economic water management. Other forms of exhortation involve consultations between government officials and financial industries or labour representatives in order to modify target group behaviour.
A third instrument that governments can apply is making use of benchmarking and performance indicators also referred to as ‘advertising’. This tool enables structured comparison and, when successful, enhances the opportunity for policy learning by presenting relevant information in ways that can generate policy insight (Howlett, Ramesh & Perl, 2009). It can also provide insights in the problems addressed by public agencies, by sharing information on performances of e.g. labour market policies. These insights can be obtained because of the standardization of benchmarks which promotes co-ordination of policies across jurisdictions.
The fourth and last instrument in this pillar applies ‘commissions and inquiries’ in order to gather information about a certain issue or in order to postpone having to make a decision. These temporary bodies exist in order to deal with a particularly troubling policy problem, by combining specialized academic research and general public input, in order to come to a potential solution.
Authority
The second resource governments can apply, makes use of ‘Authority-based Policy Instruments’.
This tool is also known as a ‘rule-making’ or ‘command-and-control regulation’. Regulations are often written and declared legal by civil servants whom have been given the authority to enable legislation. After the regulation has been written and promulgated, they are administered by a specific government department or a special government agency. Regulations can be targeted at economic or social issues. Traditionally, regulations were based on economic issues, such as price indications, production, distribution and consumption. Regulations based on social issues try to control matters such as health, safety, and societal behaviour such as civil rights (Howlett, Ramesh & Perl, 2009). In today’s society, where the supply and demand of new technological developments influences the norms and standards of business ethics, governments can implement certain measures in order to preserve the public’s physical and moral well-being. Howlett, Ramesh and Perl (2009) demonstrate five advantages of regulation as a policy instrument.
1. The information needed to establish regulation is often less compared to other tools. 2. When a certain activity is deemed entirely undesirable, such as child pornography, it is
easier to establish regulations prohibiting the possession of such products than to come up with ways of encouraging the production and distribution of less disturbing material.
3. Regulations allow for better co-ordination of government efforts and planning because of their greater predictability.
4. Their predictability makes them a more suitable instrument in times of crisis when an immediate response is needed or desired.
5. Regulations may be less costly than other instruments, such as subsidies or tax incentives.
Howlett, Ramesh and Perl (2009) also demonstrate three disadvantages of regulations.
1. Both technical and non-technical regulations are set politically which can therefore misshape voluntary or private-sector activities and can promote economic inefficiencies.
2. Regulations can sometimes hold back innovation and technological progress because of the market security they provide to existing companies and the limited opportunities for experimentation they allow.
3. Regulations are often inflexible and do not permit the consideration of individual circumstances, resulting in decisions and outcomes not intended by the regulation.
Over the years, the idea that government regulation was solely aimed at and executed in the interest of the public disappeared. At the same time, it gave birth to widespread deregulation efforts. Reasons for this change in public opinion varied from the lack of enthusiasm by regulators for regulatory controls, to the pressure that unsatisfied stockholders put on management in order to discard regulation.
although it seems that non-government related organizations or actors regulate themselves, they often do so with some form of government permission. This permission can occur in a direct or indirect manner which allows governments to hold back from exercising a more intimidating regulation. This form of delegated regulation allows the creation of standards in the private sector which represent governmental consent to the private rules. The advantage of this method is that governments save a lot of costs because the non-governmental actors pay for the creation and administration of these voluntary standards. The downside of self-regulation is the risk of additional costs due to ineffective and/or inefficient administration of the self-implemented standards. These additional costs to society would then have to be picked up by the government.
The third instrument in this category, makes use of ‘Advisory Committees’. These committees are made up of representatives selected by the government and can either be formal or informal and for temporary or permanent procedures. The selected representatives receive special rights within the process. The permanent committees are created in order to provide advice to governments on specific long-term issues. The temporary committees are created to: ‘’provide a venue for organized and unorganized interests to present their views and analyses on pressing contemporary problems, or to frame or reframe issues in such a way that they can be dealt with by governments’’ (Howlett, Ramesh and Perl, 2009).
Treasure
The third category makes use of ‘Treasure-based Policy Instruments’. This category mainly relies on the financial means governments have and their capacity to adequately raise and spend funds. The reason why governments apply these type of instruments is because of the encouragement or discouragement they put on private actors in order to follow their wishes. Even though the final choice is left to the private actors themselves, the financial aid provided by the government has an influence on the taken decision.
The second and third treasure-based policy instruments can be combined under the subject of financial disincentives. The two policy instruments that governments can apply, make innovative use of a tax. The first is the so-called ‘User Charge’. This instrument is applied by governments in order to discourage a certain behaviour by imposing a price on that behaviour. This financial penalty is, thus, often used to control a product or decision which has higher societal costs than its private cost. The second instrument makes use of ‘Taxes’ which are normally aimed at raising revenues for government expenses. When governments impose this legal compulsory payment to a person or an organization, by taxing a certain service or activity, they discourage that service or activity by making it more expensive. This policy instrument is almost similar to a “user charge”. The main difference between the two instruments is that taxes are imposed as a mandatory payment to the government whereas a user charge represents a voluntary exchange. E.g. when the government increases taxation on cigarettes, they probably do so with the intention to stimulate healthier behaviour. Now smokers have the choice to either pay the user charge or stop smoking. This choice is not represented in “regular” taxes. These compulsory payments rely on the coercive powers of the government. The distinction between the two instruments is important in order for citizens to be able to hold their governments accountable. On the one side you have user charges which are meant to provide positive work and which try to save incentives. On the other side taxes do not provide positive work and do not save incentives. In either case, the most important thing is that when governments set their prices, either by taxes or user charges, it reflects the social costs and benefits of the services they provide.
The fourth instrument in this category incorporates ‘Interest groups’ as a policy instrument. In order to build social capacity for governmental ideas or to gain better information on social needs and desires, governments often provide funding for the creation of interest groups. After all, it is in the interest of governments to create a well-organized interest group. The reason for this is that well-organized interest groups are able to exercise decisive influence in any policy debate and can thus be used as an active policy force. The funding of these interest groups seems to be based on the influence governments want them to exert. This behaviour is noticeable when governments fund private-sector actors with e.g. favourable taxes or corporate donations. The results is that these private actors will then be more likely to cooperate with the government and support their policy goals. Another method to use interest groups as a policy instrument is by giving them more rights in certain sectors and recognizing them as a special representation in the specific sector they work in. By doing so, the government gives these interest groups a sort of monopoly of the representation in their sector, which is indirectly controlled by government, and thus benefits governmental policy.
Organisation
The first instrument in this category applies ‘Direct Provision’ of goods and services. The concept of direct provision entails that governments perform the task of delivering goods and services directly from government employees, which are funded from the public treasury, to the public. According to Howlett, Ramesh and Perl (2009) direct provision offers three main advantages;
1. It is easy to establish because of its low information requirements.
2. The large size of public agencies involved in direct provision enables them to enlist established resources, skills, and information to offer cost-effective project delivery. 3. It avoids many problems associated with indirect provision that can lead governments
to pay more attention to enforcing terms of grants and contracts than to results.
Under the policy instrument of direct provision, one of its advantages is the use of public enterprises. These are organizations or agencies which are partially or fully owned by the government but are still to some extent autonomous from the government. In order to classify as a public enterprise, 51 percent of these organisations should be owned by the government. By doing so, governments have control over the management of the organization. As part of the organization-based policy instrument, Howlett, Ramesh and Perl (2009) point out that governments have four main advantages from the use of public enterprises.
1. They are an efficient economic development tool when the private sector does not provide the goods or services needed because of insufficient revenue gained from that specific activity.
2. Public enterprises are easier to launch because there is a much lower information threshold-information and insights you need to succeed-than required because the government can act directly through the enterprise it owns.
3. Public enterprises can simplify public management of a policy domain if extensive regulation already exists because they already comply with government aims.
4. Profits from public enterprises can be directly added to the public treasury and therefore support public expenditures in other areas.