ContentslistsavailableatScienceDirect
Neurocomputing
journalhomepage: www.elsevier.com/locate/neucom
Brief
papers
Instance
search
based
on
weakly
supervised
feature
learning
Jie
Lin,
Yu
Zhan,
Wan-Lei
Zhao
∗FujianKeyLaboratoryofSensingandComputingforSmartCity,SchoolofInformationScienceandEngineering,XiamenUniversity,Xiamen361005Fujian, China
a
r
t
i
c
l
e
i
n
f
o
Articlehistory: Received14June2019 Revised17October2019 Accepted29November2019 AvailableonlinexxxCommunicatedbyDr.XinmeiTian
Keywords:
Instancesearch
Convolutionalneuralnetwork Weaklysupervisedlearning
a
b
s
t
r
a
c
t
Instance search has been conventionally addressed as an image retrieval issue. In the existing solutions, traditional hand-crafted features and global deep features have been widely adopted. Unfortunately, since the features are not directly derived from the exact area of an instance in an image, satisfactory perfor- mance from most of them is undesirable. In this paper, a compact instance level feature representation is proposed. The scheme basically consists of two convolutional neural network (CNN) pipelines. One is designed for localizing potential instances from an image, while another is trained to learn object-aware weights to produce distinctive features. The sensitivity to the unknown categories, the distinctiveness to different instances, and most importantly, the capability of localizing an instance in an image are all carefully considered in the feature design. Moreover, both pipelines only require image level annotations, which makes the framework feasible for large-scale image collections with variety of instances. To the best of our knowledge, this is the first piece of work that builds the instance level representation based on weakly supervised object detection.
© 2019 Elsevier B.V. All rights reserved.
1. Introduction
Instance search is a retrieval task that allows users to launch aquerywithspecifiedvisualinstanceinanimage.Itrequiresthe system to returnthe images/videosas well asthe location (usu-ally givenasa boundingbox), where thespecified instance isin presence. In comparisonto conventional image search, it reflects better the real needs frompractice. Forinstance,a typical query could be a bagwornby a woman on ashopping website,a per-son in the streetview or a logo on a bottle, etc. Instance search alsofacilitates thetasksuch asimage hyper-linking[1],inwhich imagesare hyper-linkedtoeach othervia theinstancessharedin common.Inthestate-of-the-arts,duetothelackofinstancelevel feature representation, this issue has been addressedby the ap-proaches thatare originally designedforcontent-basedimage re-trieval [2–7]. Most of the features are built eitheron the image leveloronthesub-regionleveldespitetheyarehand-crafted fea-turesortraineddeepfeatures.
In thelast decade,instance searchhas beentreatedasa sub-image retrieval task.The solutionto theinstance searchis domi-natedbyhand-craftedlocalfeaturessuchasscaleinvariantfeature transform(SIFT)[8]andspeeded-uprobustfeatures(SURF)[9],etc.
∗ Correspondingauthor.
E-mailaddress: [email protected](W.-L.Zhao).
Thesefeaturesareextractedfromsaliencyregionsofimages.They are usually invariant to basic geometric transformations such as scalingandrotation.Theinstancesearchisthereforeaddressedas apoint-to-pointfeaturematchingproblembetweenthequeryand candidateimages.Althoughencouragingresultsareachieved[10], thelatent difficulties arehard to overcome.First ofall, there are usually several hundreds to several thousands local features ex-tracted from one image. The computation cost of point-to-point matchingwould be prohibitively highgiventhere aremillions of images to be compared. Although this issue has been alleviated bytheencoding schemessuchasbag-of-visualword(BoVW)[11], vectoroflocallyaggregateddescriptors(VLAD)[12]andFisher vec-tor(FV) [13], thefeatures fromdifferent instancesare embedded intoone vector, whichmakes theinstance levelcomparisonhard toachieve or simplyimpossible. Inaddition, image localfeatures are vulnerable to object deformation and out-planerotation that arewidelyobservedintherealworld.
Inrecentyears,duetothe greatsuccessofconvolutional neu-ralnetworks(CNNs)inmanycomputervisiontaskssuchasimage classification [14–16], object detection [17–19] and instance seg-mentation[20,21],CNNshavebeengraduallyintroducedtoimage retrieval[22–27].Inthecommonpracticeofrecentresearch,CNNs are trained to be more sensitive to object regions [23,25,26,28]. Duringthe featureextraction,higher weights areassignedto ob-jectsregionsonthefeaturemaps.Suchthat resultingfeaturesare more representative for the latent objects in an image. Unfortu-nately, thistype of feature representationonly produces a single https://doi.org/10.1016/j.neucom.2019.11.029
0925-2312/© 2019 Elsevier B.V. All rights reserved.
vector for one image. Features from different objects are simply mixedup.
In the recent literature, several attempts have been made to produceinstancelevelrepresentationviadeeplearningframework. Approachespresentedin[24,29]areabletoproduceinstancelevel featurerepresentationbypoolingfeaturesfromthedetectedobject region. Although satisfactory performance is achieved, the train-ingofthenetworkrequiresobjectlevelorpixellevelannotations, whichare too expensive to be deployedin the real applications. Inaddition,thestrongrelianceonthevisualcategoryannotations also makes the CNNs only sensitive to known classes. While in practice,theinstancerepresentationisrequiredto besensitiveto theknownaswellastheunknowncategories1,giventhefactthat onecannotrestrictthequeryinstancestotheannotatedcategories only.
In thiswork, motivatedby the recentadvances of theweakly supervised object detection methods [30–33], a novel instance levelfeaturerepresentationisproposed.Inoursolution,two con-volutionalneuralnetworkpipelinesareintegrated.Oneisdesigned tolocalizethevisualinstancesfromimages,anotherisdesignedto derivefeaturesfromtheregionssuppliedbythefirstpipeline.Both pipelinesrequireonlytheimagelevelannotations.Theadvantages ofsuchdesignareatleasttwofolds.
• Inthefirstpipeline,theboundingboxesofthevisualinstances are produced with the weak guidance of class information, which makes it still sensitive to instances of unknown cate-gories.
• In thesecond pipeline,the trainednetworkis ableto capture thedissimilaritybetweendifferentvisualobjects.Suchthatthe producedfeaturesremaindiscriminativetoeachothereventhe correspondinginstancesarefromthesamecategory.
The reminderof thispaperis organizedasfollows.The works relatedto visual objectdetection are reviewed in Section 2. Our solutiontothe weaklysupervisedinstancesearch ispresented in Section3.Theperformance evaluationaboutourmethodin com-parisontothe state-of-the-artmethodsis presentedinSection 4. Section5concludesthepaper.
2. Relatedwork
Instance-wise feature representation is preferred over global featureininstancesearchtasksinceitrequiresinstancelevel com-parisonandlocalization.Visualobjectdetectionthereforebecomes thekeystepintheinstancelevelfeaturedesign.Inthissection,the fullysupervisedandweaklysupervisedobjectdetection,whichare themostrelevanttoourwork,arereviewed.
In general, there are two popular deep learning frameworks in fully supervised object detection. One is two-stage detection framework. It first produces a set of region proposals and then refine them by CNNs. Region convolutional neural network (R-CNN)[34],FastR-CNN[17]andFasterR-CNN[18]arethe represen-tativemethodsinthiscategory.Anotheroneisone-stagedetection framework, which gets increasingly popular in recent years. The representativemethods are You Look OnlyOnce(YOLO) [35] and singleshotmultibox detector(SSD) [36].They are more efficient over two-stagemethods since no proposal generation step is in-volved.Generally,two-stagemethodsoutperformone-stage meth-odsin termsof detectionaccuracy. Encouraging performance has beenobservedwhenfullysupervisedobjectdetectionorinstance segmentation is adopted for instance level feature representa-tion [24,29].Nevertheless, the object level or pixel level annota-tions are required forthe training, which is tooexpensive to be
1Theyarenotinanyoftheannotatedclasses.
tractableinthelarge-scalecontext.Inaddition,thetrainedmodel becomesinsensitivetounknownclasses.
Asaresult, weaklysupervisedobjectdetection(WSOD),which onlyrequiresimage levelannotations,ispreferred. Thereare sev-eralpopularWSODmethods[30–33] inrecentliterature. Theyall followthepipelineofmultipleinstancelearning(MIL)[37].Inthe pipeline, an image is taken asa bagof proposals. Eachproposal in the image is fed to the networks to check whether it keeps anvisual objectthatisofthesamecategoryasimageclass label. The disadvantage of MIL is that the detected boundingbox may not cover a complete latent object. In order to alleviate this is-sue,methodin[33]refinesseveralbranchesofinstanceclassifiers online based on the outputs of previous branches. According to themethod,theproposalsareproducedonrawimages,whilethe proposal refinement is undertaken on the feature maps instead. Thisinconsistencyaffectsprecisionoftherefinedproposals.Apart fromMIL,therearesomeproposal-freemethodsbyminingonthe salientregionsfromdeepfeaturemapsandclassactivationmaps. In[38],anadversarialcomplementarylearningmethodisproposed todiscovernewandcomplementaryobjectregionsbyerasingthe discoveredregionsfromthedeepfeaturemapsgradually.However thismethodfailswhenmorethanoneobjectsfromthesame cat-egoryare in presencewithin an image. Methodfrom [39] boosts the performance ofobject detectionby mining on theclass acti-vation map, which roughly reflects theobject region. Inorder to enhancethelocalizationaccuracy,methodin[40]adoptsboththe re-training and re-localizationsteps duringthe training. Unfortu-nately, extra training set withthe object level annotations is re-quired.
Due to the latent issues of one way or another in the ex-isting methods, aforementioned WSOD pipelines cannot be di-rectlyadopted forinstancesearchtask.Inour design,twoWSOD pipelines,namely proposalclusteringlearning(PCL) [33]andsoft proposalnetwork(SPN)[39]aretailoredtofittingintoourinstance featurerepresentation.Namely, PCLisadoptedmainly toproduce boundingboxesforthelatentobjectsofknownandunknown cat-egories.ItsperformanceisfurtherenhancedbyreplacingSelective Search[41]withEdgeBoxes[42]forobjectproposalgeneration.In addition,in orderto avoidbackgroundinterference,SPN is intro-ducedto assign object-awareweights on boundingboxes to pro-duceamorediscriminativeinstancefeaturerepresentation.
3. Theproposedmethod
In this section, we firstly introduce the overall framework of the proposed method in Section 3.1. Thereafter the instance lo-calization whichis basedon weakly supervisedlearningmethod, is given in Section 3.2. With the object bounding boxes sup-plied by the localization pipeline,the CNN pipeline designedfor feature map weighting and feature extraction is introduced in Section3.3.
3.1. Overallframework
AsdiscussedinSection 1,theexistinginstancelevel represen-tationsrequireeitherobjectlevelorpixellevelannotationsforthe training set, which makes it hardly feasible in real scenarios. In contrasttotheseworks,inourdesigninstancelevelfeature repre-sentationis produced via weakly supervised learning. It only re-quires image level class labels for the training set. In addition, since the bounding box (usually given as a rectangle) does not coverthe exactshape ofanobject,direct featureextractionfrom withinthe regionmayintroducethenoisesfromthebackground. Toaddressthisissue,aspatialweightingnetworkisintroducedto generateobject-awareweights forfeatures extractedfromthe re-fined proposals. The framework of our method basicallyconsists
Image conv
feature map Proposal conv feature map SPP layer Two fc layers Proposal features U S P V Multi-label classification loss VGG16 ROI pooling feature1 feature2 . . . feature1 feature2 . . . query database rank-list rois Image features SPN conv conv FC PCL
conv1-2 conv2-1 conv2-2 fuse
EdgeBox
Coarse proposals
VGG16
retrieval
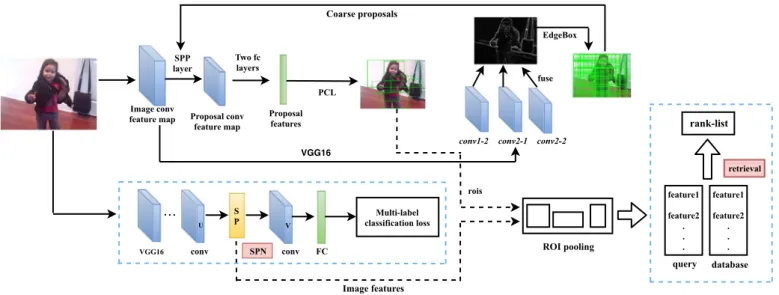
Fig.1. Theframeworkofweaklysupervisedinstancelevelfeaturelearning.Theupperflowshowstheinstancelocalizationprocedure,wherecoarseproposalsaregenerated withedgeinformationfromshallowconvolutionlayersofVGG-16.TheimageanditscoarseproposalsarethereforefedintoaPCL [33]streamtoobtainrefinedproposals. Theflowonthelowersideisthepipelineforassigningobject-awareweightsonthefeaturemapsofconvolutionallayers.Thefirstpartisnothingmorethanasoftproposal network[39](insidethebluedashedbox).ThenfeatureforeachinstanceisproducedbyROIpoolingfromtheproposalssuppliedbytheupperflowontheweightedfeature mapofSPN.
of two CNNpipelines. Oneis trainedto produce boundingboxes forallthelatentinstancesinanimage,whileanotheristrainedto learntheobject-awareweightsforfeatures.Theinstancelevel fea-tureisfinally producedby regionofinterest(ROI)pooling[17]on theweightedfeaturemapswiththeboundingboxesprovidedfrom the first pipeline. The overall framework is shown inFig. 1. The firstpipelineisoriginallydesignedforobjectdetection[33],while thesecondpipelineisoriginallyadoptedtodiscovermore discrim-inative visual evidenceinimages [39].The backbonenetwork for both is VGG-16[15].Considerable modifications have beenmade onbothtofitthemintoourtask,whicharedetailedinthe follow-ingsections.
3.2. Instancelocalization
Inordertobuildinstancelevelfeaturerepresentation,itis crit-ical to localize each latent instance by a bounding box. In our framework,thefeatureextractionforanindividualinstancemainly reliesonitsboundingbox.Theboundingboxisthereforeexpected tocoverthediscoveredinstanceaspreciselyaspossible.Inour de-sign, edgeinformationfromshallowconvolutional(conv)layersis exploited to generatehundreds of object-like proposals by Edge-Boxes.However, itdemands highcomputationalcosttoextractall theproposalfeaturesofoneimagetomatchwiththequery,which isunaffordableforlargescaledatasets.Tothisend,aproposal clus-tering learning method which helps to cluster the proposals re-latedtooneinstancetogether,isusedinourinstancelocalization pipeline.
For the convenience of following discussion, the feature map fromaconvlayerisrepresentedasF∈RC×W×H,whereC,WandH
are thechannelnumber,widthandheight ofthefeaturemap re-spectively.Theresponsemapofthefeaturemapisrepresentedas R∈RW×H.Foreachlayer,theresponsemapisderivedfromits
cor-respondingfeaturemapbytakingaverageoverthechannel dimen-sion,which isgivenby Eq.(1).rij andfcij inEq.(1)are elements
in RandF, respectively.Edgeboxes procedureproduces proposals based on the input edge response map which is represented as Redge∈RW×H.Afterfurtherresizingtheresponsemapstothesize
of original image, the edge response map is generated by taking
average againover theseresponse maps.In our design, response mapsfromconv1-2, conv2-1andconv2-2of VGG-16areaveraged toproducetheedgeresponsemap(showninEqn.2).
ri j= 1 C C c=1 fci j
(
i=1,...,W and j=1,...,H)
(1) Redge= 13
(
Rconv1-2+Rconv2-1+Rconv2-2)
(2)TheparametersofthefirstfourconvlayersarefromImageNet pre-trainedmodel andtheir gradients willno longer be updated in the later training procedure. Since the categories of training datasetwillnotaffectthepreviousfourconvlayers,theyaremore likelytobesensitivetounknowncategories.Notethatconv1-1and deeperlayersarenotchosensincetheyhaveeitherhighresponse toalmostall theimageregions orhaveresponse onlytoinstance regionsofknowncategories.
Considering the high computational cost on hundreds of proposals for each image, a proposal clustering learning (PCL)[33]methodisintroducedtorefinethegeneratedproposals. ItconsistsofabasicMILstreamandtwoinstanceclassifier refine-mentstreams.Thewholepipelineisoptimizedbyminimizing the image classification errors.Foreach stream, proposalclustersare generatedaccordingtotheproposalclassificationscores.The cur-rentstreamprovides proposalclassification scoresassupervisions forthe next stream. After the PCL processing, the object related proposals are refined while the objects belonging to background are filtered.The examplesof proposals producedby our instance localizationpipelineareshowedasFig.2.Asshowninthefigure, the proposed method is able to cover most ofthe objects in an imageofbothknownandunknowncategories.Sinceitonlyrelies on feature maps of shallow layers, the localization is also very efficient.
3.3.Featureextraction
Althoughthe boundingboxes that are produced by theabove instancelocalization pipelinecoverthe instances (of both known and unknown categories) well, the feature maps from the first Pleasecitethisarticleas:J.Lin,Y.ZhanandW.-L.Zhao,Instancesearchbasedonweaklysupervisedfeaturelearning,Neurocomputing,
Fig.2. Theexamplesofproposalsobtainedbyourinstancelocalizationpipeline.Asshowninthefigure,therearemanyobjectsthatareneverseeninthetrainingcategories.
pipeline are not suitable for instance feature representation. Ac-cording to our observation, since the features from the first pipelinearetrainedtobeonthesemanticlevel,thedifferences be-tweeninstancesofthesamecategoryarelargelylost.Inaddition, one could not expect the boundingboxes produced fromweakly supervisedmethod are as precise asthose from fully supervised one.As theconsequence,features extracteddirectly fromregions detectedbythefirstpipelinemaybemixedwithnoisesfromthe backgroundorneighboringobjects.
To addressthis issue,aspatialweighting network named soft proposalnetwork (SPN)[39] is adopted togenerate object-aware weights for instance level features separately. SPN is basically a modification over VGG-16, in which the Soft Proposal (SP) is plugged into the last conv layer. The SP module learns an ob-jectnessmapwhichreflectsthedissimilarityofeachobjectregion fromtheirsurroundings byagraphpropagationalgorithm. There-fore,in theobjectnessmap, theobject regionwillbe highlighted whilethebackgroundonewillbesuppressed.Intheforward prop-agation,Hadamard product is performedto combinethe object-ness map with the feature map from the next conv layer. Then intheback-propagationprocedure,thegradientisapportionedby theparameters oftheobjectnessmap. Astheresults,all theconv layersofSPNareenhancedby theobject-awareweights fromthe objectnessmap. Most importantly,SPN only requiresimage level annotationsfortraining.Inourdesign,thefeaturemapsfromSPN areROIpooledbasedontheboundingboxesproducedbythefirst pipeline.Thisfinally leadstoa compactfeature representationof equalsizeforinstancefromeachboundingbox.IntheSection4.3, ablationanalysisisconductedtoshowthelayerandthe combina-tionoflayersofSPNfromwhichthefeaturesarethebestsuitable forinstance search. The resulting features are l2-normalized and
Cosinedistanceisadoptedinthecomparison.
4. Experiments
Inthissection,theperformanceofinstancesearchbasedonthe proposedfeaturerepresentationisstudiedontwoinstancesearch datasets.The briefon the evaluationdataset andthe experiment setupsare introduced inSection 4.1. The ablation analysis about ourmethodispresentedinSection4.2.The featureselectiontest about our method is presented in Section 4.3. The performance comparisonstoseveralstate-of-the-artmethodsontwoevaluation benchmarksarepresentedinSection4.4.
4.1. Datasetsandexperimentsetup
The performance of the proposed method is studied on two challenging datasets, namely Instance-160 [29] and INSTRE [43]. Instance-160is derived from160 video sequences originally used for visual tracking evaluation. There are 160 individual instance queries. There are 12,045 images in the reference set. INSTRE is builtbycollectingimagesofvariouscategories.The 200instances rangefromobjectssuch asbuildings,commonobjects,sculptures to logos. There are 28,543 images in total.Following the evalua-tion protocol in [44], 1250 images in the dataset are treated as queries,andtherestaregivenas27,293referenceimages.Forboth datasets,the boundingboxes ofthequeryinstances are provided inadvance.
Performance isevaluated withmean AveragePrecision(mAP). Representative feature representations of both conventional and CNN-based are considered in our comparison. BoVW [11] and BoVW with Hamming embedding (BoVW+HE) [45] are based on SIFT. The considered image-level deep features are bags of lo-cal convolutionalfeatures (BLCF)[27],BLCFwithsaliency weight-ing (BLCF-SalGAN) [27], regional of maximum activation of con-volutions (R-MAC) [23], cross dimensional weighting scheme (CroW) [25] and features from weighted Class Activation Map (CAM) [26]. Their features are extracted from pre-trained CNNs. Our method is also compared to two fully-supervised methods, both of which produce instance-level features. They are Deepvi-sion[24] andFCISwithdeformable convolutionandResNeXt-101 (FCIS+XD) [29]. Deepvision extracts instance-level features from proposalsproducedbyFaster-RCNN[18].Features forFCIS+XD are extracted from a fully convolutional neural network [21] that is augmentedforbothinstancesegmentationandinstancesearch.
The networksin our framework are implementedby PyTorch. All ofour experimentsare pulled out onan Nvidia TitanX GPU. Ournetworks aretrained withimage level annotations.They are pre-trainedon ImageNetandfine-tuned on MicrosoftCOCO2014 dataset[46].
4.2. Configurationtest
In the first experiment, ablation analysis is conducted with five different runs. We mainly study the effectiveness of the in-stancelocalization,thecontributionofedgeinformationtothe lo-calization andthe impact of weight assignment on our instance
Table1
Performance evaluation of different enhancement schemes in our method on Instance-160andINSTRE,thefeaturedimensionisfixedto 512.
Dataset Method Top-10 Top-20 Top-50 Top-100 All Instance-160 SPN 0.142 0.223 0.340 0.380 0.422 PCL 0.167 0.271 0.412 0.460 0.509 PCL∗ 0.169 0.276 0.429 0.485 0.539 PCL+SPN 0.183 0.303 0.474 0.537 0.596 PCL∗+SPN 0.177 0.297 0.476 0.541 0.603 INSTRE SPN – – – – 0.077 PCL – – – – 0.243 PCL∗ – – – – 0.328 PCL+SPN – – – – 0.256 PCL∗+SPN – – – – 0.415
search task.The features produced by the spatialweighting net-work named SPN are treated as the comparison baseline. These SPNfeaturesareproducedbyROIpoolingwiththeproposals pro-duced by SPN itself. Features extractedfrom proposals produced by original PCL and the one from enhanced PCL (given as PCL∗) are alsostudied. Inaddition,the features fromSPNfeaturemaps whilebeingROI pooledwithproposalsproducedby PCLare stud-ied,whichisgivenas“PCL+SPN”.OurfeaturesareROIpooledfrom theweightedfeaturemapsfromSPNwiththeproposalsproduced byPCL∗,whichisgivenas“PCL∗+SPN”.Featuresforabovefive con-figurations are extracted from the conv5-3 layer of VGG-16. The PCAwhiteningisnotadoptedinanyoftheaboveconfigurations.
Theevaluationisinlinewiththeprotocolofeachbenchmark. Following [29],the performance on Instance-160 is measured by mAPattop-k,wherekvariesfrom10to100.AsshownonTable1, PCL+SPNoutperformsSPNby0.174and0.179onInstance-160and INSTRE respectively. Thisbasically indicatesthe instance localiza-tion plays an important role for feature representation. Further-more,considerableimprovement isobservedfromPCL∗ overPCL. Similar trendisobserved whencomparing PCL∗+SPN toPCL+SPN. This confirms our choice of shallow conv layers as the input to EdgeBoxesforboundingboxestimation.Italsoshowstheabilityof discoveringunknowncategoryiscriticaltoboostthesearch perfor-mance. Thesuperiorities ofPCL+SPNoverPCLandPCL∗+SPNover PCL∗ demonstrate the weight assignment on the feature mapsis helpful.Duetothesuperiorperformance,features fromPCL∗+SPN
Table2
PerformancecomparisononInstance-160.
Method Dim. Top-10 Top-20 Top-50 Top-100 All BoVW[11] 65,536 0.106 0.165 0.248 0.281 0.314 BoVW+HE [45] 65,536 0.148 0.236 0.355 0.403 0.438 BLCF [27] 336 0.046 0.076 0.126 0.167 0.227 BLCF-SalGAN [27] 336 0.063 0.105 0.175 0.214 0.278 R-MAC[23] 512 0.101 0.164 0.268 0.307 0.358 CroW [25] 512 0.073 0.130 0.239 0.284 0.338 Deepvision [24] 512 0.194 0.328 0.541 0.666 0.731 FCIS+XD [29] 1536 0.211 0.356 0.575 0.659 0.724 Ours 1024 0.211 0.358 0.578 0.660 0.722 Table3
Performancecomparisonon40queriesofInstance-160whereheavybackground changesareinpresent.
Method Dim. Top-10 Top-20 Top-50 Top-100 All Deepvision [24] 512 0.193 0.298 0.464 0.559 0.589 FCIS+XD [29] 1536 0.262 0.430 0.647 0.698 0.737
Ours 1024 0.239 0.363 0.517 0.569 0.610
are adoptedasthe standard configuration forour methodin the restofourexperiments.
4.3.Featureselection
Theoretically speaking,thefeature mapsfromeach conv layer could be used to derive the instance level features under our framework. However, as witnessed by many studies, the perfor-mancevariesconsiderablyforthe features derived fromdifferent layers.Inthisablationanalysis, westudytheperformanceof fea-turesderivedfromdifferentconvlayers.Suchthat wetrytoseek thebestrepresentationforthedetectedinstances.Namely,features derivedfromconv2-1to conv5-3layers ofVGG-16andtwolayers ofSP module are tested. The experimentresults on Instance-160 andINSTREareshowninFig.3.
As seen from the figure, features from intermediate layers show relatively good performance, which shares similar ob-servation as [29]. In order to enhance the performance, the combinationsof features fromdifferent layers are alsotried. The single-layer features we select to concatenate is based on the consideration of both their distinctiveness and dimensionalities.
Fig.3. Performancesofdeepfeaturesextractedfromdifferentconvlayersanddifferentfeatureconcatenationways,wherethe(a)showstheperformanceonInstance-160, the(b)showstheperformanceonINSTRE.Theprevious13barsrepresentsingle-layerfeaturesandthelater2barsrepresentmulti-layerfeatures.C2_1,128donatesthefirst convlayerinsecondconvgroupofVGG-16withthefeaturedimensionis128.sp1andsp2donatethetwolayersinSPmodule.
Fig.4. Top-10resultsoffoursamplequeriesfromINSTREandInstance-160.ThefirsttworowsarefromINSTRE,thethirdandfourthrowsarefromInstance-160.Imagesof thefirstcolumnarethequeries.Therestimagesinonerowarethereturnedresults(rankedfromlefttoright).Thedetectedboundingboxesarealsoshown.
Table4
PerformancecomparisononINSTRE.
Method Off-the-shelf Dim. All Deepvision [24] No. 512 0.197 FCIS+XD[29] No. 1536 0.067 CroW [25] Yes 512 0.416 CAM [26] Yes 512 0.325 R-MAC [23] Yes 512 0.523 BLCF [27] Yes 336 0.636 BLCF-SalGAN [27] Yes 336 0.698 Ours No. 1024 0.575
According to the results on the two benchmarks, we find the best combination comes from conv5-1 and conv5-2. Moreover, according to our off-the-shelf test, concatenating features from morelayersisnothelpfulortheimprovementisminor.Therefore our feature is produced from the combination of features from conv5-1andconv5-2intherestofexperiments.
4.4.Comparisontostate-of-the-arts
In this section, the performance of our method is studied in comparison to several representative works such as BoVW [11], BoVW+HE[45],R-MAC[23],BLCF[27],CAM[26],CroW[25], Deep-vision [24] and FCIS+XD [29]. The evaluation is conducted on Instance-160andINSTRE. The evaluationis inline withthe pro-tocol of each benchmark. Following several other works [24,27], featuresextractedfromourmethodarel2-normalized,followedby
PCAwhiteningandasecond round ofl2-normalization.Forthose
methodsthatcannotreturnboundingboxes,their mAPsare mea-suredonimagelevel.
TheperformanceonInstance-160isshownonTable2.Asseen fromthe table, Deepvision, FCIS+XD and ourmethod show rela-tively superiorperformance. Among them,FCIS+XD demonstrates similarperformance trendasours.Incontrast,conventional hand-craftedfeatures (e.g.,BoVW andBoVW+HE)and globaldeep fea-tures(e.g.,BLCF,R-MACandCrow)showconsiderablylower perfor-mance.EventhoughFCIS+XDandDeepvisionarecompetitivewith ours,the trainingconditions forthem are demanding. While our methodonlyrequiresimage-levelclasslabelsforthetrainingset.
Another disadvantage of Deepvision is that it still relies on globaldeepfeature.Itactuallyundertakestwo-stagesearch.Onthe
firststage,thedeepglobalfeatures2areadoptedtosearchoverthe entireimageset.Onthesecondround,thefeaturesfromquery in-stancearecomparedtotheinstancelevelfeaturesfromtop-ranked candidatesofthefirststagesearch.Asaresult,instanceswith con-siderablebackground variationsmaybe missedonthe firststage search.
Anotherexperiment on asubset ofInstance-160 confirmsour observation.In thissubset, instances whose backgrounds are un-derseverevariationsareselected.Onthissubset,itiseasytosee theadvantageofinstancelevelrepresentationoverthosefeatures derived fromthe whole image. Asshown onTable 3,the perfor-manceofDeepvisondropsalotcomparedtopreviousresultonthe entireInstance-160dataset.This basicallyindicates that instance-levelfeatures showbetter distinctivenessoverglobalfeatures. Al-thoughFCIS+XDachievesthebestperformanceonthisdataset,the trainingconditionsaretoodemandingtobeundertakenfor large-scaletasks.Comparedtoexistingsolutions,ourmethodachievesa goodtrade-off betweentheperformanceandthetrainingcost.
TheperformanceonINSTREisshownonTable4.Ourmethodis onlynext toBLCFandBLCF-SalGAN.Notice that thesetwo meth-odsproducefeaturesonimagelevelandareunabletolocalize in-stances from theretrieved images. BothDeepvision andFCIS+XD show considerable performance degradation on INSTRE, in con-trasttotheir highperformanceonInstance-160.Theperformance degradationis mainlyduetotheir insensitivity tounknown cate-gories.Onthecontrary,BLCF,BLCF-SalGANandR-MACshow com-petitive performance on INSTRE while poor performance is ob-served on Instance-160.Thisbasically indicates that their feature representationsarenotrobusttothescenarioswhereinstancesare embeddedinthecomplexbackground.Overall,ourmethodshows stableperformanceacrosstwochallengingevaluationbenchmarks. On the one hand, it shows that our method is capable of iden-tifying unknown categories. On the other hand, it also indicates ourfeaturerepresentationremainsdistinctivedespiteofthesevere variationsininstanceappearanceortheinterferencefromcomplex backgrounds.
Fig.4furthershowssearchsamplesfromourmethod. Interest-ingly,wefindthatourmethodhastheabilitytoidentifyunknown categories.Forinstance,STARBUCK logoandthecartooncharacter “Spongebob”, whichare not in our trainingcategories havebeen successfullyidentified. In addition, thefeature description is
ficiently robust that gets thequery instancewell-matchedto the candidate instances even under severe geometric variations. Our methodalsoshowsencouragingperformanceonnon-rigidobjects asdemonstratedonthelasttworows.
5. Conclusion
Inthispaper,afeaturerepresentationschemethat isdesigned forinstancesearchhasbeenpresented.Differentfrommany exist-ing instancesearch schemes,thefeature isbuiltgenuinelyon in-stancelevelandobject-awareweightsareassignedontheregions oftheobjectsresidingin.Thisleadstothedistinctivefeature rep-resentationaswell aspreciseinstancelocalization.Moreover,this feature is trainedbased on a weakly supervised objectdetection network, whichonly requiresimage levelannotations andis less reliantonknowncategorylabels.Itthereforeturnsout tobe sen-sitive tolatentinstances ofknownandunknown categoriesinan image.Stableandsuperiorperformancehasbeenobservedontwo challengingevaluationbenchmarks.
DeclarationofCompetingInterest
Theauthorsdeclarethattheyhavenoknowncompeting finan-cialinterestsorpersonalrelationshipsthatcouldhaveappearedto influencetheworkreportedinthispaper.
Acknowledgments
Thisworkissupported byNationalNaturalScienceFoundation of China undergrants 61572408 andgrants ofXiamen University 0630-ZK1083.
References
[1] W.-L.Zhao,H.Jegou,G.Guillaume,Sim-min-hash:anefficientmatching tech-niqueforlinkinglargeimagecollections,in:ProceedingsoftheACM Interna-tionalConferenceonMultimedia,ACM,2013,pp.577–580.
[2] A.Gordo,J.Almazan,J.Revaud,D.Larlus,End-to-endlearningofdeepvisual representationsforimageretrieval,Int.J.Comput.Vis.124(2)(2017)237–254.
[3] A.Babenko,V.Lempitsky,Aggregatinglocaldeepfeaturesforimageretrieval, in:ProceedingsoftheIEEEInternationalConferenceonComputerVision,2015, pp.1269–1277.
[4] M.Tzelepi,A.Tefas,Deepconvolutionallearningforcontentbasedimage re-trieval,Neurocomputing275(2018)2467–2478.
[5] C.Bai,L.Huang,X.Pan,J.Zheng,S.Chen,Optimizationofdeepconvolutional neuralnetworkfor largescaleimageretrieval,Neurocomputing303(2018) 60–67.
[6] Y.Li,X.Kong,H. Fu,Q.Tian,Aggregatinghierarchicalbinary activationsfor imageretrieval,Neurocomputing314(2018)65–77.
[7] Y.Li,Z.Miao,J.Wang,Y.Zhang,Nonlinearembeddingneuralcodesforvisual instanceretrieval,Neurocomputing275(2018)1275–1281.
[8] D.G.Lowe, Distinctive imagefeaturesfrom scale-invariantkeypoints, Int.J. Comput.Vis.60(2)(2004)91–110.
[9] H.Bay,T.Tuytelaars,L.VanGool,SURF:Speededuprobustfeatures,in: Pro-ceedingsofthe EuropeanConference on Computer Vision, Springer,2006, pp.404–417.
[10] S.S.C.-Z.Zhu,H.J¸Egou,NIIteam:query-adaptiveasymmetricaldissimilarities forinstancesearch,in:ProceedingsoftheTRECVID2013workshop, Gaithers-burg,USA,2013,pp.1705–1712.
[11] J.Sivic,A.Zisserman,Videogoogle:atextretrievalapproachtoobject match-inginvideos,in:ProceedingsoftheIEEEInternationalConferenceon Com-puterVision,2003,pp.1470–1477.
[12] H. Jégou, M.Douze, C.Schmid, P.Pérez, Aggregatinglocaldescriptors into acompactimagerepresentation,in:Proceedingsofthe IEEEConferenceon ComputerVisionandPatternRecognition,2010,pp.3304–3311.
[13] F.Perronnin,J.Sánchez,T.Mensink,Improvingthefisherkernelforlarge-scale imageclassification,in:ProceedingsoftheEuropeanConferenceonComputer Vision,2010,pp.143–156.
[14] A.Krizhevsky,I.Sutskever,G.E.Hinton,Imagenetclassificationwithdeep con-volutionalneuralnetworks,in:ProceedingsoftheAdvancesinNeural Infor-mationProcessingSystems,2012,pp.1097–1105.
[15] K.Simonyan,A.Zisserman,Verydeepconvolutionalnetworksforlarge-scale imagerecognition,arXiv:1409.1556(2014).
[16] S.Yu,S.Jia,C.Xu,Convolutionalneuralnetworksforhyperspectralimage clas-sification,Neurocomputing219(2017)88–98.
[17] R.Girshick,FastR-CNN,in:ProceedingsoftheIEEEInternationalConference onComputerVision,2015,pp.1440–1448.
[18] S.Ren,K.He,R.Girshick,J.Sun,FasterR-CNN:towardsreal-timeobject detec-tionwithregionproposalnetworks,in:ProceedingsoftheAdvancesinNeural InformationProcessingSystems,2015,pp.91–99.
[19] T.Zhang,L.-Y.Hao,G.Guo,Afeature enrichingobjectdetection framework withweaksegmentationloss,Neurocomputing335(2019)72–80.
[20] K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask R-CNN, in: Proceedings ofthe IEEE International Conference on Computer Vision,2017, pp.2961– 2969.
[21] Y.Li,H.Qi,J.Dai,X.Ji,Y.Wei,Fullyconvolutionalinstance-awaresemantic segmentation,in:ProceedingsoftheIEEEConferenceonComputerVisionand PatternRecognition,2017,pp.2359–2367.
[22] A.S.Razavian,J.Sullivan,S.Carlsson,A.Maki,Visualinstanceretrievalwith deep convolutional networks,ITETrans. MediaTechnol. Appl.4(3)(2016) 251–258.
[23]G. Tolias, R. Sicre,H. Jégou, Particular object retrievalwith integral max-poolingofCNNactivations,arXiv:1511.05879(2015).
[24] A.Salvador,X.Giró-iNieto,F.Marqués,S. Satoh,Faster R-CNNfeaturesfor instancesearch,in:ProceedingsoftheIEEEConferenceonComputerVision andPatternRecognitionWorkshops,2016,pp.9–16.
[25] Y.Kalantidis,C.Mellina,S.Osindero,Cross-dimensionalweightingfor aggre-gateddeepconvolutionalfeatures,in:ProceedingsoftheEuropeanConference onComputerVision,Springer,2016,pp.685–701.
[26]A.Jimenez,J.M.Alvarez,X.Giro-iNieto,Class-weightedconvolutionalfeatures forvisualinstancesearch,arXiv:1707.02581(2017).
[27] E.Mohedano,K.McGuinness,X.Giró-iNieto,N.E.O’Connor,Saliencyweighted convolutionalfeaturesforinstancesearch,in:ProceedingsoftheInternational ConferenceonContent-BasedMultimediaIndexing(CBMI),IEEE,2018,pp.1–6.
[28] B.Zhou,A.Khosla,A.Lapedriza,A.Oliva,A.Torralba,Learningdeepfeatures fordiscriminativelocalization,in:ProceedingsoftheIEEEConferenceon Com-puterVisionandPatternRecognition,2016,pp.2921–2929.
[29]Y.Zhan,W.-L.Zhao,Instancesearchviainstancelevelsegmentationand fea-turerepresentation,arXiv:1806.03576(2018).
[30] W.Ren,K.Huang,D.Tao,T.Tan,Weaklysupervisedlargescaleobject local-izationwithmultipleinstancelearningandbagsplitting,IEEETrans.Pattern Anal.Mach.Intell.38(2)(2015)405–416.
[31] R.G.Cinbis,J.Verbeek,C.Schmid,Weaklysupervisedobjectlocalizationwith multi-foldmultipleinstancelearning,IEEETrans.PatternAnal.Mach.Intell.39 (1)(2016)189–203.
[32] H.Bilen,A.Vedaldi,Weaklysuperviseddeepdetectionnetworks,in: Proceed-ingsoftheIEEEConferenceonComputerVisionandPatternRecognition,2016, pp.2846–2854.
[33] P.Tang,X.Wang,S.Bai,W.Shen,X.Bai,W.Liu,A.L.Yuille,PCL:proposal clus-terlearningforweaklysupervisedobjectdetection,IEEETrans.PatternAnal. Mach.Intell.(2018).
[34] R. Girshick,J. Donahue, T.Darrell,J. Malik,Richfeature hierarchiesfor ac-curateobject detection and semantic segmentation,in:Proceedings ofthe IEEEconferenceoncomputervisionandpatternrecognition,2014,pp.580– 587.
[35] J.Redmon,S.Divvala,R.Girshick,A.Farhadi,Youonlylookonce:Unified, re-al-timeobjectdetection,in:ProceedingsoftheIEEEconferenceoncomputer visionandpatternrecognition,2016,pp.779–788.
[36] W.Liu,D.Anguelov,D.Erhan,C.Szegedy,S.Reed,C.-Y.Fu,A.C.Berg,SSD: Singleshotmultiboxdetector,in:ProceedingsoftheEuropeanconferenceon computervision,Springer,2016,pp.21–37.
[37] O. Maron,T. Lozano-Pérez, Aframework for multiple-instance learning,in: ProceedingsoftheAdvancesinNeuralInformationProcessingSystems,1998, pp.570–576.
[38] X. Zhang, Y. Wei, J. Feng, Y. Yang, T.S. Huang, Adversarialcomplementary learningforweaklysupervisedobjectlocalization,in:ProceedingsoftheIEEE Conference on Computer Visionand Pattern Recognition, 2018, pp. 1325– 1334.
[39] Y.Zhu,Y.Zhou,Q.Ye,Q.Qiu,J.Jiao,Softproposalnetworksforweakly super-visedobjectlocalization,in:ProceedingsoftheIEEEInternationalConference onComputerVision,2017,pp.1841–1850.
[40] M. Shi, V. Ferrari, Weakly supervised object localization using size esti-mates,in:ProceedingsoftheEuropeanConferenceonComputerVision,2016, pp.105–121.
[41] J.R.Uijlings,K.E.VanDeSande,T.Gevers,A.W.Smeulders,Selectivesearchfor objectrecognition,Int.J.Comput.Vis.104(2)(2013)154–171.
[42] C.L.Zitnick, P.Dollár, Edgeboxes:locating objectproposalsfromedges, in: ProceedingsoftheEuropeanConferenceonComputerVision,Springer,2014, pp.391–405.
[43] S.Wang,S.Jiang,INSTRE:anewbenchmarkforinstance-levelobjectretrieval andrecognition,ACMTrans.Multimed.Comput.Commun.Appl.(TOMM)11 (3)(2015)37.
[44] A.Iscen,G. Tolias,Y. Avrithis, T.Furon, O.Chum,Efficientdiffusion on re-gionmanifolds:recoveringsmallobjectswithcompactCNNrepresentations, in:ProceedingsoftheIEEEConferenceonComputerVisionandPattern Recog-nition,2017,pp.2077–2086.
[45] H.Jegou,M.Douze,C.Schmid,Hammingembeddingandweakgeometric con-sistencyforlargescaleimagesearch,in:ProceedingsoftheEuropean Confer-enceonComputerVision,2008,pp.304–317.
[46] T.-Y.Lin,M.Maire,S.Belongie,J.Hays,P.Perona,D.Ramanan,P.Dollár,C.L. Zit-nick,MicrosoftCOCO:commonobjectsincontext,in:Proceedingsofthe Eu-ropeanConferenceonComputerVision,Springer,2014,pp.740–755.
JieLinreceivedherBachelordegreeofComputerScience fromFuzhou University,Chinain2017. Sheiscurrently agraduatestudentatDepartmentofComputerScience, XiamenUniversity.Herresearchinterestiscontent-based imageretrievalandinstancesearch.
YuZhanreceivedhisMasterdegreeofComputerScience fromXiamen University,Chinain2019.He iscurrently anAlgorithmEngineerinAibeeGroup.Hisresearch inter-estisvisualobjectdetection,imageretrievalandmachine learning.
Wan-LeiZhaoreceived hisPh.DdegreefromCity Uni-versityofHongKong in2010.He receivedM.Eng.and B.Eng.degreesinDepartment ofComputerScienceand EngineeringfromYunnanUniversityin2006and2002 re-spectively.HecurrentlyworkswithXiamenUniversityas anassociateprofessor,China.BeforejoiningXiamen Uni-versity,hewas aPostdoctoralScholarinINRIA,France. Hisresearchinterestsincludemultimediainformation re-trievalandvideoprocessing.