Contents lists available at ScienceDirect
Signal
Processing
journal homepage: www.elsevier.com/locate/sigpro
Low-resolution
facial
expression
recognition:
A
filter
learning
perspective
Yan Yan
a, Zizhao Zhang
b, Si Chen
c, Hanzi Wang
a,∗aFujianKeyLaboratoryofSensingandComputingforSmartCity,SchoolofInformatics,XiamenUniversity,Fujian,China bDepartmentofComputerInformationandScienceEngineering,UniversityofFlorida,Florida,USA
cSchoolofComputerandInformationEngineering,XiamenUniversityofTechnology,Fujian,China
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Received23April2019 Revised28October2019 Accepted9November2019 Availableonline12November2019
Keywords:
Filterdesign Subspacelearning Imagerepresentation Low-resolution
Facialexpressionrecognition
a
b
s
t
r
a
c
t
Automaticfacial expressionrecognitionhasattractedincreasingattention foravarietyofapplications. However, the problem of low-resolution generally causes the performance degradation of facial ex-pressionrecognitionmethods under real-lifeenvironments. Inthispaper, weproposetoperform low-resolution facial expression recognitionfromthe filter learningperspective. More specifically, anovel imagefilterbasedsubspacelearning(IFSL)methodisdevelopedtoderiveaneffectivefacialimage rep-resentation.TheproposedIFSLmethodmainly includesthreesteps:Firstly,weembedtheimagefilter learningintotheoptimizationprocessoflineardiscriminantanalysis(LDA).Byoptimizingthecost func-tionofLDA,asetofdiscriminativeimage filters(DIFs) correspondingtodifferent facialexpressionsis learned.Secondly,theimagesfilteredbythelearnedDIFsareaddedtogethertogeneratethecombined images.Finally,aregressionlearningtechniqueisleveragedforsubspacelearning,wherean expression-awaretransformationmatrixisobtainedusingthecombinedimages.Basedonthetransformationmatrix, IFSLeffectivelyremovesirrelevantinformationwhilepreservingusefulinformationinthefacialimages. Experimentalresultsonseveralfacialexpressiondatasets,includingCK+,MMI,JAFFE,SFEWandRAF-DB, showthesuperiorperformanceoftheproposedIFSLmethodforlow-resolutionfacialexpression recog-nition,comparedwithseveralstate-of-the-artmethods.
© 2019ElsevierB.V.Allrightsreserved.
1. Introduction
Duringthepastfewdecades,automaticfacialexpression recog-nition has attracted extensive attention in computer vision and pattern recognition. It plays an important role in a variety of applications, including human computer interaction (HCI), data-drivenanimation [1–5].Despitesignificantprogress,facial expres-sionrecognitionisstilladifficulttask,duetothevariationscaused by pose, illumination,andsoon.One criticalproblemthat isnot well solved is low-resolution (LR). In real-life environments, the resolutionoffacialimagescapturedbyanordinarycameramaybe low.TheLR facialimagesusuallylacksufficientvisualinformation to extract informative features, thus leading to the performance degradation of facial expression recognition methods [6]. There-fore,effectivelydistinguishingdifferentfacialexpressionsbasedon theLRfacialimagesisverychallengingbutmeaningfulfor practi-caltasks.
∗ Correspondingauthor.
E-mailaddresses:[email protected](Y. Yan),[email protected]fl.edu(Z.Zhang),
[email protected](S. Chen),[email protected](H. Wang).
Todeal withthe problemof LR facial expression recognition, existing methods mainly focus on two aspects: (1) face super-resolution (SR)[7,8],and (2) facial image representation [6,9,10]. The firstaspect usually adopts two criteriato performSR: pixel-levelvisualfidelityandimage-levelfaceidentitypreservation.The secondaspectaimstoextractthecompactanddiscriminative fea-turerepresentation.Inthispaper,wemainlystudythesecond as-pect.
SRmethodsaimtoconstructahigh-resolution(HR)imagefrom thecorresponding LRimage[11].Theoretically,byapplyingtheSR methodson the LRfacial imagesto constructHR images,the re-constructedimages can be usedforfacial expression recognition. However,thecomputational complexityofexisting SRmethods is usuallyhighandtheseSRmethodscannot guaranteethat the re-sultingHRfacialimagesareoptimalforrecognition[12].
Facialimage representationalsoplays a criticalrole forLR fa-cialexpressionrecognition.Themethodsofrepresentingfacial ex-pressionimagescanberoughlycategorizedintogeometric feature-basedmethods [13]andappearance-basedmethods[14]. Geomet-ric feature-basedmethods detectsalient facialfeature pointsand characterizethevariationsofthesepoints,whichcanachievegood https://doi.org/10.1016/j.sigpro.2019.107370
performanceon actionunit recognition[15].However, precise lo-calizationoffacial featurepointsisnot atrivialtaskforLRfacial images.Appearance-basedmethodsrepresentthevariationsof fa-cialappearance based on the whole face orspecific regions ina facialimage.Thiskindofmethodsusuallyattemptstoextract dis-criminativefeatures infacial imagestodistinguishdifferentfacial expressions.
The appearance-based methods can be further classified into handcrafted feature-basedmethods [16–18] andfeature learning-basedmethods [19–21].Representative handcrafted feature-based methods include local binary patterns (LBP) [16], Haar-like fea-tures[17] andGabor-wavelet features [18]. However, these man-uallydesignedfeatures maynot effectivelyhandlethe challenges causedbythenon-linearfacialappearancevariationsdueto differ-entposes,occlusionsandetc.Morerecently,featurelearning-based methods,suchasauto-encoder[19]andconvolutionalneural net-works(CNNs)[20,21],haveattractedmuch attention.Zhangetal. [19]presentaspatiallycoherentfeature-learningmethodfor pose-invariantfacialexpressionrecognition.Theycombinethe learning-based features and the corresponding geometry features to con-struct robust features. Xie andHu [20] propose a deep compre-hensivemultipatchesaggregationCNNsmethod,whichconsistsof twoCNNbranchestorespectivelyextracttheholisticfeaturesand local features, to solve the problemof facial expression recogni-tion.Lietal.[21]presentthe CNNwithan attentionmechanism (ACNN)forfacialexpressionrecognitioninthepresence of occlu-sions.Thesemethodsshowtheexcellentabilitytoextractthe dis-criminativerepresentationfromtherawdata.
Psychologistshaveshownthatthecrucialfeaturesfor recogniz-ingfacial expressions areusually distributedaround salientfacial featurepoints,suchasmouth,noseandeyes[1].Thevariationsof thesalientfacialfeaturepointsaretheusefulinformationforfacial expression recognition. In contrast, the facial identities of differ-entpersons arethe irrelevant information,whichshould be sup-pressed or removed (althoughsuch information is important for identifyingaperson) forthetaskoffacialexpression recognition. Inparticular, theinformation inthe LR facialimages isrelatively limited.Therefore,theirrelevantinformationmaysignificantly de-creasetheperformanceofLRfacial expressionrecognition. There-fore,howtoextractthediscriminativefacialimage representation fromthelimitedinformationiscritical.
Inthispaper,weproposetoperformLRfacialexpression recog-nitionfromthefilterlearningperspective,whereanoveland effec-tivefacial image representationisdeveloped forfacialexpression recognition.Theprocessofconstructingthefacialimage represen-tationforLRfacialexpressionrecognitioncanbeconsideredasthe process of suppressingirrelevant information(e.g., facial identity differences),whileenhancingthevaluableinformation(e.g., wrin-kledeyebrow, smiling mouthand other features that are critical fordiscriminatingdifferentexpressions)infacialimages.
More specifically, we propose a novel image filterbased sub-space learning (IFSL) method to achieve an effective image rep-resentationfor LR facial expression recognition. In particular, we learn a discriminative image filter (DIF), based on the two-class lineardiscriminant analysis(LDA) technique[22], todiscriminate anon-neural expressionfromtheneutralexpression.The learned DIFextracts discriminativeinformationbymappingthefacial im-agestoa subspacewheretheintra-classvariationsareminimized andtheinter-classvariationsaremaximized. Therefore,theDIF is abletofindsubtle variationsof facialexpression amongdifferent LRfacialimages.WhenasetoflearnedDIFs(correspondingto dif-ferent expressions) is applied to a multi-class classification task (e.g., facial expression recognition in this paper), we propose to usearegressionlearningtechnique(i.e.,thelinearridgeregression (LRR)technique[23])to derivea newfacialimage representation withhighdiscriminability,basedonthefilteredimagesratherthan
the original images.As aresult, an expression-aware transforma-tion matrix that encodes the expression information isobtained. ThisstrategyextendstheclassificationabilityoftheDIFfrom two-classtomulti-classclassification.
Insummary,we presentanovelimage representationmethod bytakingadvantageofthediscriminativeimage filterandthe re-gressionlearningtechnique.
Thepreliminaryversionsofthisworkwerereportedin[24,25]. However, we have made severalsignificant extensions compared withthepreviousversions.Thenewcontributionsinclude:
• We provide a general formulation of the image filter learn-ing, where the image filtercan take different forms (such as element-wise product, linear transform and convolution) as longasitisdifferentiable.
• Wereformulate theoriginal methodanddevelopa more gen-eral framework for image filter based subspace learning. We also offer more mathematical details and motivations of the proposedmethodforfacialexpressionrecognition.
• Weconductextensiveexperimentsonbothin-the-lab datasets andin-the-wilddatasetstodemonstratetheeffectivenessofthe proposedmethodforLRfacialexpressionrecognition.
The remainder of this paper is organized as follows. In Section2,wereview relatedwork. InSection3,weintroducethe detailsoftheproposedIFSLmethod.InSection4,weevaluatethe performanceofIFSLandcompareIFSLwithseveralstate-of-the-art methodson variousfacialexpression recognitiondatasets.Finally, theconclusionisdrawninSection5.
2. Relatedwork
ThissectionreviewsrelatedworkinLRfacialexpression recog-nition. Firstly, the recently developed methods on face super-resolution and LR recognition are introduced in Section 2.1. Then, some facial image representationmethods are reviewed in Section 2.2.Finally,some filterlearningmethodsare discussedin Section2.3.
2.1. Facesuper-resolutionandlow-resolutionrecognition
Traditional methods for handling the LR facial images aim to generatehigh-resolution (HR)facialimages,basedonwhichfacial expression recognition can be performed. These methods can be roughlyclassifiedintotwocategories:genericsuper-resolution(SR) methods[7],andclass-specificSRmethods(alsocalledface hallu-cination)[8].
Generic SRmethods take advantage of thepriors that ubiqui-tously exist in natural images without relying on the face class information. For instance, Guet al. [26] develop a convolutional sparse coding method for image SR instead of the conventional patch-basedmethods.Dongetal.[7]usetheCNNstolearna non-linear mapping function between LR and HR images based on a large-scaleimagedataset.
Ontheotherhand,facehallucinationmethodsexploitthe sta-tisticalinformationoffacesandtheyusuallyachievebetterresults than genericSR methodsforfacial expressionrecognition orface recognition. For example, Ma et al. [27] use multiple local con-straintslearned fromexemplarfacial imagestoperform face hal-lucination.Wangetal.[28]proposetoapplytheglobalconstraints betweenLR andHR facial images,andthen hallucinate HR facial imagesbasedontheeigen-transformation.However,theoutputHR facialimagesmaysufferfromghostingartifacts.Notethat, gener-ativeadversarialnetworks(GANs) [29]can generatefacialimages with sharp details due to the discriminative networks. However, thegeneratedimagesareonly similartoone anotherintheclass domain butthey are differentin the appearancedomain [30].In
general, the computationalcomplexityof thesefacehallucination methodsisusuallyhigh.
Except for the above SR methods, some methods have been specifically developed for LR facial expression recognition/face recognition. These methods aim to extract resolution-insensitive features[6]orlearncross-resolutiontransformations[31–34].
For example,Khan et al.[6] propose a novel feature descrip-tor PLBP(Pyramid ofLBP) forLR facialexpression recognition.In fact, LR face recognition has achieved significant progress in the past few years. Renet al.[31] propose a coupled kernel embed-ding(CKE)methodforfeatureextractionwithitsapplicationtoLR face recognition. Jiang etal. [32] develop a coupled discriminant multi-manifold analysis (CDMMA)for LR face recognition.By ex-ploiting theneighborhood informationandlocal geometric struc-tureof themanifold, CDMMAlearnstwo mappings to projectLR andHRimagestoaunifieddiscriminativefeaturespace.Xingand Wang[33]developcouplemanifolddiscriminantanalysiswith bi-partitegraphembedding (CMDA_BGE)tosolvetheproblemofLR face recognition. Chu et al.[34] propose a cluster-based regular-ized simultaneous discriminant analysis (C-RSDA) method for LR face recognition with single sample per person. Note that these LR face recognition methods usually match the LR probe faces against the HR gallery images. In this paper, we concentrate on themoregeneralsettings,whereboththetrainingandtestimages areLR.
2.2. Facialimagerepresentation
Automaticfacialexpression recognitionusuallyconsistsoftwo main steps: feature extractionand facial expression classification [1].Featureextractionextracts generativeordiscriminative repre-sentationsfromrawfacialimagestoeffectivelyrepresentthefacial images.Generally,currentmethodsforrepresentingfacial expres-sionimagescanbe dividedintogeometricfeature-basedmethods [13]andappearance-basedmethods[9,16,17,35].Inthispaper,we mainlyreviewtheappearance-basedmethods.
The representative appearance-based methods, including lo-cal binarypatterns (LBP) [6,16,36,37], Haar-like features [17] and Gabor-wavelet features [18], have been successfully applied into facial expression analysis. Specifically, several LBP-basedvariants, such as m-LBP (representing salient micro-patterns in facial im-ages) [36] and Boost-LBP (using a boosting algorithm to learn the most discriminative LBP histograms) [37], are proposed and achievethestate-of-the-artperformance. Classicalsubspace learn-ing methods, such as lineardiscriminant analysis (LDA)[38] and principle componentanalysis(PCA)[39],are alsowidelyused for featureextraction.
Theabovemethodsconsiderthefacialimageasawhole with-outspecificallyemphasizingtheimportantroleofsalientfacial fea-turepoints.Actually,somelocalfacialregions(e.g.,eyes,eyebrows and mouths) contain critical information for expression recogni-tion,sincedifferentexpressionsaccompanythevariationsin differ-entlocalfacialregions.Inrecentyears,some methods[9,35]have beenproposed toanalyze non-holisticfacial images.Forinstance, Zhongetal.[35] proposea multi-tasksparse learningframework toexplorediscriminativeinformationinlocalfacialregionsfor dif-ferentiatingdifferent expressions, andsuggest that differentlocal facialregions shouldbeassignedwithdifferentweights.Theyuse LBP to partition the facial imagesinto isometric non-overlapping regions,wheretherelationshipamongdifferentlocalfacialregions isexploited. Experimentalresults in[35]show that themost im-portantlocalfacialregionsforrecognizingtheexpressionsarethe eyes,eyebrows,noseandmouths.
Recently, deeplearning hasachievedoutstanding performance in a variety of computer vision tasks, including facial expression recognition[20,21,40–44].Forexample,Xieetal.[40]proposethe
deep attentive multi-path CNN (DAM-CNN) method, which not onlyautomaticallylocatestheexpression-relatedregions,butalso generatesaneffectivefacialexpressionrepresentation.LiandDeng [41] develop a deep locality-preserving CNN (DLP-CNN) method forunconstrained facialexpressionrecognition,whichusesanew locality-preservinglosslayerfordeeplearning. Moreover,they in-troduce a newreal-world facial expression dataset (i.e., RAF-DB) captured from the Internet. In [42], a deep emotion-conditional adaption network (ECAN) method forunsupervised cross-dataset facialexpressionrecognitionisdeveloped.
Recently,the video-based facialexpression recognitionhas re-ceived great interest. Compared with a static image, a video se-quence not only contains the spatial appearance, but also pro-videsfacialmotions.Guptaetal.[45]developascaleinvariant ar-chitecture for generatingillumination invariant deep motion fea-tures for video-based facial expression recognition. Alam et al. [46]proposeabiologicallyinspiredsparse-deepsimultaneous cur-rent network (S-DSRN) for robust facial expression recognition. S-DSRN makes use of the weight sharing technique in the hid-denrecurrentlayerstoreducethenumberofnetworkparameters, wherethesimultaneousrecurrencyoffersefficientcontroloverthe depth ofthe model. Chen etal. [47]combine a new feature de-scriptorcalledhistogramoforientedgradientsfromthree orthog-onal planes (HOG-TOP) and a new geometric feature descriptor to respectively extract dynamic textures and facial configuration changes for video-based facial expression recognition. Moreover, theaudiomodalityisalsoconsideredforrecognition.
2.3.Filterlearning
Filterlearning-basedmethodsarewidelyappliedtomany com-putervisiontasks,suchasfacerecognition[48,49],visualtracking [50],objectdetection[51],duetotheir highgeneralization ability androbustness. Forexample, Yanetal. [49]propose an effective correlation filter bank methodto extract features for face recog-nition.Henriquesetal.[50] proposetousethekernelcorrelation filtermethodforfastvisualtracking.Generallyspeaking,thefilter isdesignedtosuppressnoisysignalsandamplifyusefulsignalsso thatthediscriminabilityoffilteredsignalscanbeenhanced.
It is worthy pointing out that Gabor-wavelet [18] and LBP [16,36]canalsobeconsidered asthespecialformsoffilter. How-ever,thesefilters aremanually designedwithoutusingthe learn-ing technique. Incontrast, ourproposed discriminative image fil-ter is learnedvia the objectivefunction ofLDA withmaximizing discriminability.Inaddition,therecentpopularCNNs-based meth-ods [3,52]use theconvolutional filters toobtain rich representa-tions for accurate facial expression recognition and these meth-ods have achieved superior performance. The parameters of the convolutionalfilterscanbeeffectivelylearnedbasedonthe back-propagationtechnique. Nevertheless,theCNNs-basedmethods re-quirethe relativelyHRimagesastheinputto extracthierarchical representations, whichcan make thesemethods difficult to han-dle the LR facial expression recognition problem [52]. Note that theseCNNs-basedmethodsusuallyrequirealargeamountof train-ingdata.Butcurrentfacial expressiondatasetstypicallycontaina small number of labelled samples. Therefore, cross-corpus train-ing [42] or transfer learningtechniques [53] (which take advan-tage of the extra available training data) can be used to effec-tively deal with facial expression recognition with limited train-ing data. In this paper, we aim to solve the problem of lim-ited training data from the image filtering perspective. The pro-posedmethodisa goodalternativefordealingwithLR facial ex-pression recognitionusinglimitedtrainingdata.Experimental re-sultsonmultiplepublicfacialexpressiondatasetsverifythe excel-lentperformance oftheproposed methodforLRfacial expression recognition.
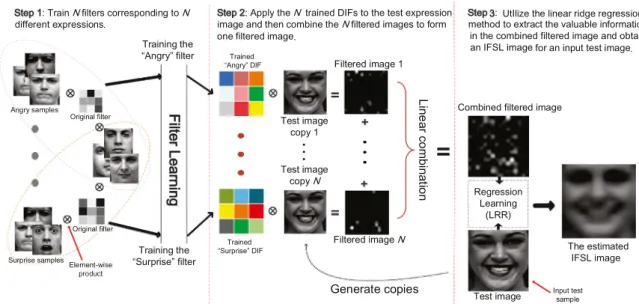
Fig.1. TheframeworkoftheproposedIFSLmethod.
3. Imagefilterbasedsubspacelearning
The proposed image filter based subspace learning (IFSL) methodcontainsthreesteps.Inthefirststep,weembedthe pro-cessofdiscriminativeimagefilter(DIF)learningintothe optimiza-tionoftwo-classLDA.Inthesecondstep,welinearlycombinethe filtered images generated by the learned DIFs. In the third step, based on the combined results, we propose to use a regression learningapproachtoperformfeatureextraction.Theoverall frame-workoftheproposedIFSLisshowninFig.1.
The discriminative image filter learning is introduced in Sections3.1,andthedetailsoftheoptimizationprocedureare de-scribed in Sections 3.2. The details of the second and the third stepsarediscussedinSection3.3.Thecompletealgorithmisgiven inSection3.4.
3.1.Discriminativeimagefilterlearning
Forthetaskoffacialexpressionrecognition,thesignificant dis-criminativeinformationmainlyliesinthelocalfacialregionssuch astheeyes,eyebrows,noseandmouths.Theselocalfacialregions havedifferentinfluence onrecognizingdifferentexpressions (e.g., lipsrise ina happy expression face; eyebrows wrinklein an an-gryexpression face; a mouthwidely opens andeyebrows rise in asurpriseexpressionface). Thelocalfacialregions likeeyebrows, mouths and ajina contain more discriminative information than theregions like cheekstoidentify theangry expression. Inother words,theseregions playanimportantrole indiscriminating dif-ferentexpressions. Therefore,theobjectiveofan imagefilteristo simultaneouslyemphasizediscriminativeinformationinthecrucial localfacialregionswhilesuppressingirrelevantinformationinthe otherfacialregions.
Avarietyoffilterfunctionscanbeused.Forexample,t
• Element-wise product: f
(
λ
1,p)
=λ
1p, where represents the dot product operator;λ
1 is the filter function in Rd; p is a facial image represented asa d-dimensional column vec-tor.Therefore,eachelementλ
1idecidestheintensityoftheith pixelpiinafacialimagethatpassesthrough.• Lineartransform: f
(
λ
2,p)
=λ
2p,whereλ
2∈Rd×disthe trans-formationmatrix.• Convolution: f
(
λ
3,p)
=λ
3∗p, where ∗ denotes the convolu-tionoperatorandλ
3∈Rd istheconvolutionalkernel.Given a filter function
λ
(defined as one of the above-mentionedthreefunctions)andaninputmatrixP=[p1,...,pn]∈Rd×nconsistingofnfacialimages,wecanobtaintheoutputmatrix as,
f
(
λ
,P)
=[f(
λ
,p1)
,...,f(
λ
,pn)
]=[x1,...,xn], (1)
andwe define X=[x1,...,xn]. Here,X∈Rd×n contains nfiltered facialimages,andeachfilteredfacialimageisad-dimensional col-umnvector.
Generallyspeaking,weexpectthatthelearnedimagefilterhas thediscriminativeability toextract theusefulinformationfor fa-cialexpressionrecognition.Inotherwords,thefilteredimages cor-respondingto differentexpressions should be moreseparablefor subsequent classification. Therefore, in order to learn a discrimi-native image filter (DIF), we propose to take advantage of linear discriminantanalysis(LDA)duringthetrainingprocess.
LDA[22]isapopularsubspaceanalysismethodwhichprojects high-dimensionalsamples to an optimaldiscriminative subspace, wheretheprojectedsamplesare well-separated.Itcaneffectively extract the information from samples and compress the dimen-sionalityofsamplesthroughasupervisedlearningstrategy.LDAis originallyproposed tohandletwo-classclassificationproblems.In fact,LDAcanalsobe extendedtohandlemulti-classclassification problems(wheretheinter-classmatrixisthesumofthepairwise scatter matrix ofanytwo differentclasses). However, multi-class LDA suffers from the problem of unbalanced pairwise distances (i.e.,thedistanceoftwodifferentclassesmaybemuchsmalleror largerthanthatbetweenanothertwodifferentclasses),whichmay significantlydegradetheperformanceinfacialexpression recogni-tion[54,55].Therefore,we mainlyfocus ontwo-class LDAinthis paper.
Next we give the detailed steps of embedding the DIF learn-ingintotheoptimizationprocessofLDA.LDAattemptstoseekfor an optimallineartransformation tominimizethe intra-class vari-ance (characterizedby an intra-classcovarianceSW) aswellasto maximize the inter-classvariance (characterizedby an inter-class covariance SB). In our method, we use the facial images with a neutral expression,denoted as P1, and those witha non-neutral expression (e.g., angry,disgust, fear, happy, surprise, or sad), de-notedas P2, asthe inputsfor trainingthe two-class LDAmodel.
Thecostfunctionoftwo-classLDAisdefinedas, L
(
X1,X2)
=ω
TS B(
X1,X2)
ω
ω
TS W(
X1,X2)
ω
, (2)where Xi=f
(
λ
,Pi)
, i=1, 2.ω
∈Rd is thelineartransformation vector.Theinter-classcovarianceSBisdefinedas:SB
(
X1,X2)
=(
m1−m2)(
m1−m2)
T, (3) andtheintra-classcovarianceSW isdefinedas:SW
(
X1,X2)
=(
X1−M1)(
X1−M1)
T+(
X2−M2)(
X2−M2)
T, (4) wherethecolumnvectormiisthemeanofXi(i=1, 2)inRd.The matrixMiincludesncopiesofmi.Theoptimal
ω
∗canthenbecomputedas[23],ω
∗=argmax ωω
TS B(
X1,X2)
ω
ω
TS W(
X1,X2)
ω
=SW(
X1,X2)
−1(
m2−m1)
. (5)In two-class LDA, the linear transformation vector
ω
has a closed-formformulation.During the training process, the objective of the DIF learning istoobtainan optimalDIF
λ
embeddedinthecost function,and thisproblemcanbesolved basedonthegradientdescent (which willbediscussedinthefollowingsubsection).Morespecifically,by incorporating a DIF intothe cost function ofLDA, we can obtain thefollowingobjectivefunction,i.e.,O
(
λ
)
=−ln L(
X1,X2)
+ 1 2Ctr(
λ
Tλ
)
=−ln Lf(
λ
,P1)
,f(
λ
,P2)
+1 2Ctr(
λ
Tλ
)
, (6)wheretr(
λ
Tλ
)isa regularizationtermwhichenhancesthe gener-alizationcapabilityandrobustnessofthelearnedfilter.C(≥0)isa scalarparameter.Therefore,weaimtoobtaintheoptimalDIF,such thatλ
∗=argminλ O
(
λ
)
. (7)3.2. Discriminativeimagefilteroptimization
TheminimizationprobleminEq.(7)canbesolvedviathe gra-dientdescenttechnique[56],sincebothfandLinO(
λ
)are differ-entiable.Itisworthypointingoutthatineachiteration,the calcu-lationofω
∗showninEq.(5)isdynamicallyupdatedforcomputing∂
ω
∗/∂
λ
inL.ThederivationdetailsforoptimizingO(λ
)areshown asfollows.The partialderivative ofO(
λ
) withrespecttoλj
(orλi
,jifλ
is the transformationmatrix) iscomputed. Inthefollowing, weuseλj
for simplification without loss of generality. Thus, the partial derivativecanbewrittenas:∂
O(
λ
)
∂λ
j =− ∂ ∂λjL(
f(
λ
,P1)
,f(
λ
,P2))
LF(
λ
,P1)
,f(
λ
,P2)
+Cλ
j. (8)ThecostfunctionofLDAisdifferentiable,andwehave:
∂
L∂λ
j = ∂ ∂λj(
ω
∗TS Bω
∗)
ω
∗TS Wω
∗ −ω
∗TSBω
ˆ∗(
ω
∗TS Wω
∗)
2∂
∂λ
j(
ω
∗TS Wω
∗)
, (9) where∂
∂λ
j(
ω
∗TS Wω
)
=∂
ω
∗∂λ
j T(
SWω
∗)
+ω
∗T∂
SW∂λ
jω
∗+S W∂
ω
∗∂λ
j , (10)andthederivationof
∂
(
ω
∗TSBω
∗)
/∂
λj
issimilartotherightitem ofEq.(10).Thepartial derivativeof
ω
∗ withrespecttoλj
is calculatedin eachiteration:∂
ω
∗∂λ
j =∂
∂λ
j SW−1(
m2−m1)
=−SW−1∂
∂λ
j SW S−W1(
m2−m1)
+SW−1∂
∂λ
j(
m2−m1)
. (11)Accordingto Eq.(3) andEq.(4),we can compute
∂
SW/∂λj
as follows:∂
SW∂λ
j =∂
∂λ
j(
X1−M1)(
X1−M1)
T +∂
∂λ
j(
X2−M2)(
X2−M2)
T , (12)andsimilarly,
∂
SB/∂λj
iscomputedasfollows:∂
SB∂λ
j =∂
∂λ
j(
m2−m1)(
m2−m1)
T . (13)Finally,thepartialderivativeofXwithrespectto
λj
isobtained bycomputingthe partialderivative ofeachcolumnofX with re-specttoλj
,thatis,∂
X∂λ
j =∂
f(
λ
,P)
∂λ
j =∂
f(
λ
,p1)
∂λ
j ,...,∂
f(
λ
,pn)
∂λ
j . (14)Thepartialderivativeoffwithrespectto
λj
canbederived ac-cordingtodifferentformsoffilters.Forexample,forthe element-wiseproduct,∂
f/∂λj
=sjp,wheresjisavectorwhereonlythe value of the jth entry is 1 and the rest are zero. For the linear transformation,∂
f/∂λi
,j=Ejp,whereEjisad×dmatrix consist-ingofallzerosexceptforthe(i,j)thentry,whichis1.It is worth pointing out that the optimization problem (i.e., Eq.(6)) of the proposed method is formulated by taking advan-tage ofthe Fisher criteria used inthe conventional LDA method. However,theproposedmethodandLDAaresignificantlydifferent. Firstly,LDAobtainstheprojectionmatrixwithaclosed-form solu-tion.Incontrast,theproposedmethodobtainsthefilters(cantake the forms of element-wiseproduct, linear transform or convolu-tion) in an iterativemanner. Secondly,the objective ofLDA is to obtaintheoptimalprojectionmatrix(i.e.,winEq.(2)),whilethat oftheproposedmethodtriestoobtainthefilters(i.e.,
λ
inEq.(2)). Inotherwords,theproposedmethodisnotequivalenttoLDAeven ifthelineartransformisused.3.3.Linearcombinationandregressionlearning
In this paper, each DIF is designed to discriminate a specific (non-neural)facialexpressionfromtheneuralexpression,whichis atwo-classclassificationproblem.SupposethatthereareN differ-entexpressions,NDIFs(denotedas
{
λ
i}
Ni=1)willbetrained.Given animagepwithanunknownexpression,weaimtofigureoutthe expressionbasedontheoutputsofDIFs.Here,we denotetheDIF (correspondingtotheexpressionlabeloftheimage p) asλ
+1 and theother(
N−1)
DIFsas{
λ
−i}
Ni=2.
Toidentify the expression ofa test image, one simpleway is tofirstly train N expression-dependent classifiers(using the one-vs-allstrategy), whereeach classifier istrained to discriminatea non-neural expression from the other expressions based on the outputs of one DIF. Then, the facial expression corresponding to the classifier giving the highest probability output is identified.
However,suchawayisnot reliablesincethecorrelationbetween different expressions is not considered and the recognition re-sultsmay be inaccurate when two expressions share similar ap-pearancevariations.In other words,foratest image, theoutputs ofthesixclassifiers(corresponding todifferent imagefilters) are not discriminative enough for selecting the correct image filter. Besides, unbalanced data distribution may lead to the classifier overfittingtothe majorityclass(note thatthe one-vs-allstrategy isused).
In thispaper, wesolve the above problemby usingthe strat-egy of linearcombination and regressionlearning. The steps are briefly given as follows. Firstly, a set of DIFs (
{
λ
i}
Ni=1) is applied to the input image p so as to obtain the N filtered images, de-finedas{
si}
Ni=1. Notethat onlyone filtered image (corresponding tothetest expression)isenhanced whiletheother N−1 filtered imagesare suppressed.Inother words,theenhancedimage, gen-eratedby f
(
λ
+1,p)
, contains usefulinformation forclassification, while the suppressed images,generated by f(
λ
−i,p)
,i=2,...,N,containirrelevantinformationforclassification.Allthefiltered im-agesare linearlycombined togeneratethecombined image. Sec-ondly,based ontheobservation thatthe correlationbetweenthe filteredimage(i.e., f
(
λ
+1,p)
)andtheinputimagepishigherthan thosebetweenthe filteredimages(i.e., f(
λ
−i,p)
,i=2,...,N) and theinput imagep, wepropose touse aregressionlearning tech-nique to yield an effective representation for the combined im-age (which generates a new image representation for the input imagep).LinearCombinationWefirstlinearlycombine
{
si}
Ni=1 to gener-ateacombinedfilteredimagess,and
s= N i=1 si = f
(
λ
+1,p)
+ N i=2 f(
λ
−i,p)
, (15)Note that the weights corresponding to different filtered im-ages are all set to 1. Therefore, given n training images P= [p1,p2,...,pn]∈Rd×n containing different expression facial im-ages,N×nfilteredimagesare generated,whicharelinearly com-binedasfollows: S= N i=1 f
(
λ
i,P)
, (16)whereS=[s1,s2,...,sn]∈Rd×n containsn linearly combined fil-teredimages.Different fromtheDIFlearning, thecomputationof Sis general and notclass-specific.Eachsi
(
i=1,...,n)
consistsof an enhanced filteredimages(corresponding tothe expression la-belofpi)and(
N−1)
suppressedfilteredimages.Theinformation inthesuppressedfilteredimagescanbeconsideredasnoisesthat shouldberemovedwithoutaffectingthevaluableexpression infor-mationintheenhancedfilteredimages.Regression learningToextract theusefulinformation and re-movethe irrelevant informationin S,we propose to take advan-tage of the linear ridge regression (LRR) method, where we ob-tainanewrepresentationfortheinputimage.Mathematically,LRR solvesthefollowingoptimizationproblem,
min
G
P−GTS
2+
β
GTI
2, (17)
where I is a diagonal matrix (which is usually the identity ma-trix);
GTI2istheregularizationterm,andβ
istheregularization parameter;Gisatransformationmatrix,whichprojectsthe com-binedfilteredimages inSonto anew space(i.e.,generatingnew imagerepresentations);·denotestheFrobeniusnorm.Theclosed-formsolutionofEq.(17)canbewrittenas: G∗=
(
SST+β
I)
−1SPT. (18)The optimal transformation matrix G∗ is expression-aware, sinceitencodesexpression information,whichnot onlyimproves the capabilityofdistinguishing different expressions,but also re-ducestheinfluenceoffacialidentitydifferences.
BasedonG∗,theprojectedimagesareobtainedas:
Y=G∗TS, (19)
where Y is definedas the IFSL images. Each projected image yn inY containsusefulinformationfor its corresponding expression label inpn, which can be used forclassification. yn and pn have thesamedimension.
Note that the least squares(LS) methodis also a popular re-gression learning technique. However, compared with LRR used in the proposed method, LS encounters the following problems. Firstly, LS is effective only if the independent variables are not well-correlated. However, the characteristics of facial expressions are usuallywell-correlated [57], whichcangreatly affectthe per-formance of LS. Secondly, the variance estimation of LS may be large when the number of samples used is small. Thus, the re-sultsobtainedbyLSbecomeunreliablewhenalimitednumberof trainingsamplesare used.Thirdly,supposethat S∈Rd×n consists ofnd-dimensionalfeature samplesobtainedbythe above proce-dures.SST becomesasingularmatrixifn<d,andthustheresults obtainedby LScan beoverfitted. Incontrast,LRR[23] effectively solves theseproblemsbyadding aregularization termto balance the deviation [55]. Therefore,the useful information inS can be successfullypreservedwhileirrelevant informationisremovedby usingLRR.
The objective of regression learning step is to learn an expression-awaretransformationmatrix(i.e.,G∗).BasedonG∗,we are ableto obtaina newsubspace, wheretheinformation inthe enhancedimagesispreservedwhilethatinthesuppressedimages isremoved.Suchawaynotonlyimprovesthecapabilityof distin-guishingdifferentexpressions,butalsoreducestheinfluenceof fa-cialidentitydifferences.Asaresult,foranarbitraryimage,wecan obtain an image representation encoding effective expression in-formationbyprojectingthecombinedfilteredimageontothenew subspace.
In summary, the advantages ofcombining linear combination andregressionlearningaretwo-fold.1)Wecaneffectivelyimprove the discriminative capability for facial expression recognition by alleviating the influence of the distracting factors (such as facial identity).2) Forthe test stage, we do not need to decide which image filterto be used.Instead, we combinethe filteredoutputs andprojectthemontoa subspacetoobtain thefacialimage rep-resentationbyusingG∗.
3.4. Thecompletealgorithm
Intheprevious subsections,wehavedevelopedallingredients fortheLRfacialexpressionrecognitionmethod.Nowweputthem together to describe a complete algorithm for facial expression recognition.
TheoveralltrainingstageoftheproposedIFSLmethodis sum-marized in Algorithm 1, which returns a set of DIFs
{
λ
i}
Ni=1, an expression-aware transformation matrix G∗, and a classification model
. The test stage is straightforward. Specifically, given a test image, IFSL firstly uses a set of DIFs
{
λ
i}
Ni=1 to generate N filtered images. After linearly combiningthese N filtered images, thetransformationmatrixG∗ isused toobtainthecorresponding IFSL image (i.e.,a new image representationfor the test image). Thefinalclassificationresultisperformedbyapplyingthetrained model
.
Algorithm1:ThetrainingstageoftheproposedIFSLmethod. Input: A set of training images P=[p1,p2,...,pn]∈Rd×n, with the neutral expression set Pn andN non-neutral ex-pressionset
{
Pi}
Ni=1;themaximumnumberofiterations
τ
; Output:{
λ
i}
Ni=1,G∗,and.
fori=1,...,Ndo
Randomlyinitialize
λ
(i0);SelectPnandPiastheinputsofEq.(7); t=0;
while(t<
τ
)DoCompute
ω
∗accordingtoEq.(5); Compute ∂O(λ(t) i ) ∂λ(t)
i
followingEq.(8)toEq.(14); Update
λ
(it) using the conjugate gradient descent technique;t=t+1; endwhile
Obtain anoptimal image filter
λ
i corresponding tothe ithexpression;endfor
Combine theimages filteredusing thelearnedDIFs
{
λ
i}
Ni=1 toobtainSbyEq.(16);Compute an expression-aware transformationmatrix G∗ by Eq.(18);
ObtaintheprojectedimagesYaccordingtoEq.(19); Obtainafacialexpression classifier
usingY,andthe cor-respondinglabelsusingthetrainingdata.
3.5. Discussions
Firstly,themainadvantageoftheproposedIFSLmethodisthat irrelevantoruselessexpressioninformationcanbesignificantly re-moved,whiletheusefulinformationforLRfacialexpression recog-nitioncanbeeffectivelypreserved.TheproposedIFSLmethod con-tainstwokeyelementsthatcontributetotheoverallperformance andeffectiveness.(1)Imagefiltering.Adiscriminativeimage filter (DIF) is learned to distinguish a non-neural expression from the neural expression (by optimizing the cost function of LDA). The image filteredby thelearnedDIFcontainsthecriticalinformation for discriminatingthe non-neural expression. (2)Subspace
learn-ing.An expression-aware transformationmatrix islearnedto en-codetheexpressioninformationandremovetheidentity informa-tion(byusingthe linearridge regressiontechnique).Fig.2shows thevisualizationofdifferentfacialexpressionimagesandthe cor-respondingIFSLimages.WecanseethatthesimilaritiesoftheIFSL imagesobtainedbytheproposedmethodarehigherthanthoseof therawimagesforeachofthesixexpressions.Theirrelevant infor-mation(e.g.,facialidentitydifference)issuppressedandthe valu-able expression information around facial keypoints is preserved intheobtainedIFSLimages.Therefore,thepreservedinformation intheIFSLimagesbearshighdiscriminabilityforfacialexpression recognition.
Secondly,thereasonswhytheproposedIFSLmethodcanbe ap-pliedto LR facialexpression recognitionare two-fold:(1) TheLR facialimagesusuallycontainnoisesduetothevariationscausedby illumination,poseanddegradationinresolution[58].Thelearned DIFs can effectively remove noises while preserving useful in-formation in LR facial images. (2) The proposed IFSL method is a holistic recognition method, which performs subspace learning based on the whole facial appearances of LR images. Compared withthelocalrecognitionmethods,theholisticrecognition meth-odsarelesssensitivetotheimageresolution[1–3].
Finally,it isworth noting that thereare some potential prob-lems,whentheproposedmethodisappliedtoHRfacialexpression recognition.Firstly, it is difficult forthe image filter to learn the goodparametersforrecognizingHRfacialimages,whenthe num-beroftrainingsamplesislimited.Thisisbecausethatthenumber ofparametersofimagefilterisrelativelylargeforHRfacialimages. Secondly,theproposed imagefilterbecomesmoresensitivetothe misalignmentproblemforHR facialimages.Thirdly,theproposed methodsuffersfromhighcomputationalcomplexityifthesizesof imagesarelarge(seeSection4.3formoredetails).
4. Experimentalresults
Inthissection,extensiveexperimentsareconductedtoevaluate theperformance ofthe proposed IFSLmethod.In Section4.1,we demonstratethediscriminabilityoftheDIFonasyntheticdataset. InSection4.2,wefirstlyintroduceseveralpopularfacialexpression datasets,andevaluatetheperformanceofdifferentfilterfunctions. Moreover,wediscusstheinfluenceofdifferentimagesizesonthe performance of IFSL. Then, we evaluate the performance of IFSL on the facial expression datasets, and compareIFSL with several
Fig.2. Visualizationofsixtypesoffacialexpressionimages(1st and3rd rows)andthecorrespondingIFSLimages(2nd and4th rows).Here,theelement-wiseproductfilter functionisused.
Fig.3. ExperimentalresultsbyapplyingthelearnedDIFtoasyntheticdataset.Thefirstrowpresentsarandomlygeneratedsyntheticdataset,showing10positivesamples inthelefthalfpartand10negativesamplesintherighthalfpart.Thesecondtothefourthrowsrespectivelyshowtheunfilteredimages,thecorrespondingfilteredimages andthetrainedfilters.FilterIistrainedwhenDissetto50whilefilterIIistrainedwhenDissetto150.
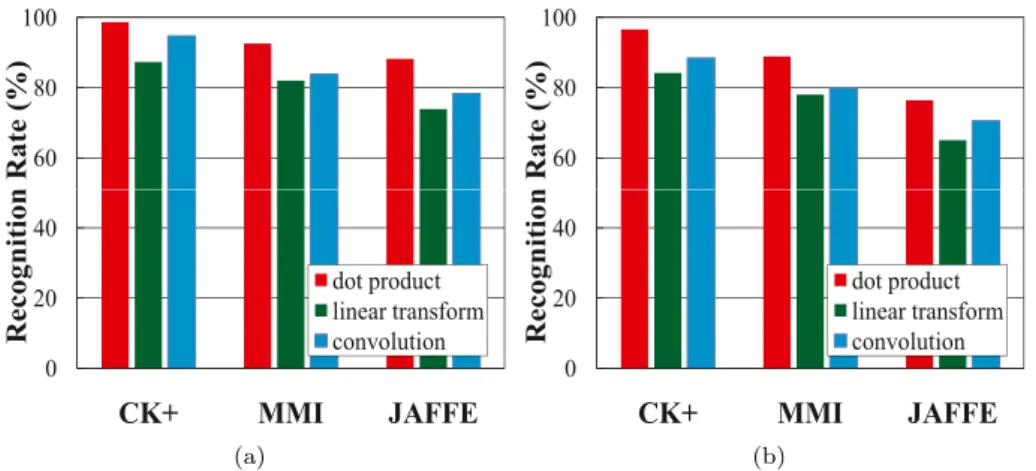
Fig.4. RecognitionresultsobtainedbytheproposedIFSLmethodwithdifferentfilterfunctionsonthethreefacialexpressiondatasets.(a)Therecognitionratesobtainedby IFSLwithSVM(b)TherecognitionratesobtainedbyIFSLwithk-NN.
state-of-the-artmethods.InSection4.3,weanalyzethelimitations oftheproposedmethod.
Toshow the influenceofa classifieron theproposed method, weusetwoclassifiers(i.e.,SVMandk-NN)forcomparison:(1)The supportvectormachine(SVM)classifierhasbeenproposedasone ofthemostpopular classifiersto dealwiththe taskoffacial ex-pression recognition [57]. SVM uses a kernel function to project samplestoahigh-dimensionalspace.Popular kernelsinclude lin-ear,polynomial,andradialbasis functions(RBF).Toavoid overfit-ting, we use the linear kernel in the following experiments. (2) Thek-nearestneighbor(k-NN)classifierisregardedasthesimplest instance-basedclassifier[23].Asampleisclassifiedbya majority voteofits k nearestneighbors.We setthevalue ofk to3 inthe followingexperiments.
4.1.Experimentsonasyntheticdataset
Inthisexperiment,wevalidate thediscriminabilityofthe pro-posedDIF(theelement-wiseproductfilterisemployed)byusinga syntheticdataset,wherewevisuallydemonstratethatthelearned DIFcaneffectivelyextractdiscriminativeinformation.Wegenerate a syntheticdataset consistingof one positive class andone neg-ativeclass.Note that herewe do notuse thelinear combination step and the regression learning step (described in Section 3.3), sincethisisatwo-classclassificationtask.
More specifically, thesynthetic datasetiscomprised ofD (the valueofDissetto50and150,respectively)syntheticsamples, in-cludingD/2positivesamplesandD/2negativesamples.Thepatch size ofeach synthetic sampleis 16×16(thus d=256). Foreach positivesample, wegenerateahorizontalwhitelineatarandom positioncrossingfromtheleftsidetotherightside,whilesucha linedoesnotexistforthenegativesamples,asillustratedinFig.4.
Bothnegativeandpositivesamplesarecontaminatedbyrandomly generatedwhitenoises.TheDIFisthentrainedusingallthe sam-ples. Therefore,thesyntheticdataset isusedto evaluatewhether the learned DIF can suppress the useless information (i.e.,white noises)in thepositive sampleswhile preservingtheuseful infor-mation(i.e.,horizontalwhitelines).
Fig. 3 also showsthe experimental results obtainedby using the proposed DIF on the synthetic dataset. We can observe that the noises in the positive samples are successfully suppressed by thelearnedDIFandthewhitelinesare well preserved. More-over,thefilteringperformance obtainedby DIF(whenD=150)is better thanthat obtainedby DIF (when D=50),since the noises inthefilteredpositivesampleswhenD=150aremuchlessthan thosewhenD=50.Moreover,thepositivehorizontallinesare ef-fectivelypreservedwhenD=150.However,theselinesareslightly suppressed whenD=50because thelimitednumber ofsamples is used. Ingeneral, the learnedDIF can effectivelyextract useful informationwhile atthe same time filteringout irrelevant infor-mationforclassification.
4.2. Experimentsonfacialexpressionrecognition
Inthissection,weextensivelydemonstratetheperformanceof theproposedIFSLforfacialexpressionrecognition.
4.2.1. Facialexpressiondatasets
Weevaluatetheperformanceoftheproposedmethodonboth in-the-lab facial expression datasets (including CK+, JAFFE and MMI) and in-the-wild facial expression datasets (including SFEW [62] and RAF-DB [42]). A brief introduction of these datasets is givenasfollows.
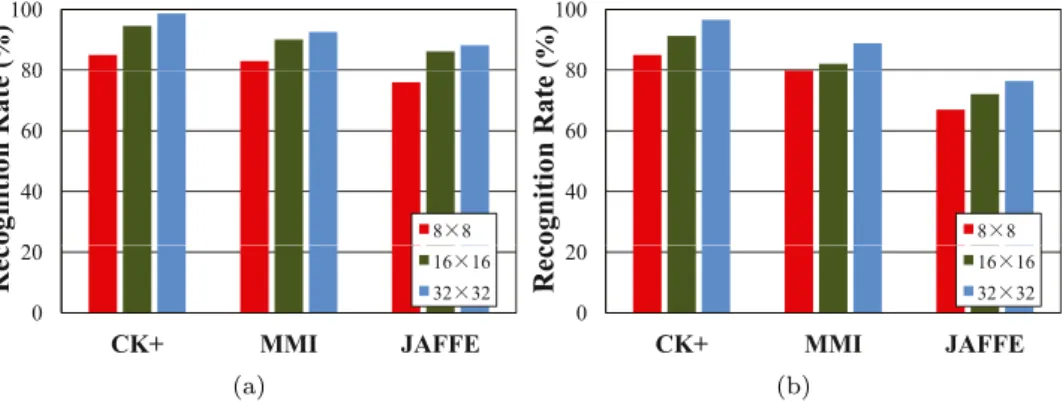
Fig.5. RecognitionresultsobtainedbytheproposedIFSLmethodwithdifferentimagesizesonthethreefacialexpressiondatasets.(a)Therecognitionratesobtainedby IFSLwithSVM(b)TherecognitionratesobtainedbyIFSLwithk-NN.
The extended Cohn-Kanade (CK+) facial expression dataset1, which is an extended version ofthe previous Cohn-Kanade (CK) dataset, consistsof 593short videosfrom 123 subjectswith dif-ferentagesunderuniformillumination[59].Allvideosvaryin du-ration(i.e.,from10to 60frames)andstartfromthefirst neutral frametothelastframewithapeakexpression.TheMMIdataset2 includesmorethan43subjects,whoexpressfacialemotions non-uniformly and spontaneously. 213 video sequences in MMI have beenlabeledwithsixbasicexpressions,wheresomesubjectswear hats,hoods,orglasses.TheJAFFEdataset3 isanexpressiondataset consisting of 219 images from 10 Japanese subjects who are fe-male [60]. There are three or four images foreach subject with each expression.TheStatic FacialExpressions intheWild(SFEW) dataset4 is collected by selecting static framesfrom Acted Facial Expressions in theWild(AFEW) [63].The SFEWdataset contains 95 subjectswithunconstrained facial expressions (suchas differ-ent poses, ages). RAF-DB5 is a large-scale dataset captured from the Internet. This dataset contains about30,000facial imagesof thousands ofsubjectsannotatedwithbasicor compound expres-sions by 40 trainedhuman labelers. Inour experiment, only im-ageswithbasicfacialexpressionsareused.Intotal,thereare1007 differentfacial expression imagesselectedfromCK+,606images selected from MMI, 219 images selected fromJAFFE, 663 images selectedfromSFEW,and15,339imagesselectedfromRAF-DB.
In all experiments,six basic non-neutral expressions and one neutral expression are selected from each of the three datasets. The sixbasicnon-neutralexpressions includeangry,disgust, fear, happy,surprise,andsadexpressions,whicharerespectively abbre-viated asAn,Di, Fe,Ha, Su, andSa inthispaper. Thus N=6 for thefollowingexperiments.
Following[37],foreach imageinthedataset,we firstly manu-allylocatetheeyepositionandcropa110×150patchcoveringthe facialregion.Then,themanuallycroppedfacialimagesareresized to the size of 32×32 (i.e., d=1024) andconverted to the gray-scale images.Weconduct the 10-foldcross-validation onall sub-jectstoevaluatetheperformanceoftheproposedmethod,asdone in[30].The trainingsetisused totrain thesixDIFs correspond-ing tothesixexpressions andlearnthetransformationmatrixG∗ in Eq. (18). Their corresponding IFSL images are used to train a classifier.Theneutralexpressiontrainingimagesaresharedduring thetrainingprocessofthesixDIFs.Fortheparametersettings,we empirically setC=0.1in Eq.(6). The value ofthe regularization parameter
β
issetto2.0. 1http://www.pitt.edu/∼emotion/ck-spread.htm 2http://www.mmifacedb.com 3http://www.kasrl.org/jaffe.html 4https://cs.anu.edu.au/few/emotiw2015.html 5http://www.whdeng.cn/RAF/model1.htmlWereporttherecognitionratesobtainedbytheproposed IFSL on each ofthe six expressions andthe average recognition rates usingeitherSVMork-NN.
4.2.2. Influenceofdifferentfilterfunctions
As we mentionpreviously (see Section 3.1), a variety offilter functionscanbe usedinthe optimizationprocessofLDA. Inthis section, we evaluate the performance of IFSL with different fil-terfunctions, includingtheelement-wiseproduct(also calleddot product),lineartransformandconvolutionfunctions.Here,weuse thethree in-the-lab facial expression datasets in thisexperiment forperformanceevaluation.
Theperformance obtainedbytheproposed IFSLwithdifferent filterfunctionsisshowninFig.4,wheretheresultsobtainedusing theSVMclassifier are givenin Fig.4(a)andthoseobtainedusing thek-NNclassifierareshowninFig.4(b).Wecanobservethatthe proposed IFSL with the dot product filter function achieves bet-ter performance than that withthe other two filterfunctions on allthethreedatasets.TheproposedIFSLwiththelineartransform achieves the worst results among the three filterfunctions. This ismainlybecausethat thedot productfiltercandirectlyhavean influence onthe pixel-level valuesin the facial image, while the othertwofilterfunctionsoperateonthewholefacialimage. There-fore,the directchangeofpixel-levelvaluesseems tobemore ef-fectiveforfacialexpressionrecognitionsincethenumberof train-ingsamplesislimited. Inotherwords,thediscriminativelocal fa-cialregionscanbeenhancedandtheirrelevantlocalfacialregions are suppressed by using the dot product filter. Furthermore, the recognitionratesobtainedbyIFSLusingSVMarehigherthanthose obtainedbyIFSLusingk-NN.
Therefore,inthefollowingexperiments,wewillchoosethedot productfilterasthefilterfunctionoftheproposedIFSLmethod. 4.2.3. Influenceofdifferentimagesizes
Inthissection, we evaluate the performance ofIFSL with dif-ferent image sizes, including 8×8, 16×16 and32×32. We also usethethreein-the-labfacialexpressiondatasetsforperformance evaluation.
Theperformance obtainedbytheproposed IFSLwithdifferent image sizesis shownin Fig. 5,where the resultsobtained using the SVM classifier are given in Fig. 5(a) and those obtained us-ingthek-NNclassifierareshowninFig.5(b).Wecanobservethat theproposedIFSLwiththeimagesizeof32×32achievesthebest recognitionrates,while IFSLwiththe image sizeof 8×8obtains theworstresultsonthethreedatasets.Thehighertheimage reso-lutionis,thebettertherecognitionperformance is.Thisismainly dueto the fact that the proposed ISFL method can be beneficial fromexploitingmoreinformationinthehigher-resolutionimages.
Fig.6. Recognitionresultsobtainedbytheproposedmethodwithtwodifferentclassifiersonthethreefacialexpressiondatasets.(a)Therecognitionrateforsixdifferent expressionsobtainedbyIFSLwithSVM(b)TherecognitionrateforsixdifferentexpressionsobtainedbyIFSLwithk-NN.(c):Theaveragerecognitionratesobtainedbythe proposedIFSLusingeitherSVMork-NNonthethreedatasets.
Furthermore,therecognitionratesobtainedbyIFSLusingSVMare higherthanthoseobtainedbyIFSLusingk-NN.
4.2.4. Performanceoftheproposedmethod
Inthefollowingexperiments,we showtheperformanceofthe proposedIFSL methodtohandlethetaskofmulti-classfacial ex-pressionrecognition.
Table 1showstheconfusion matrixobtainedby theproposed IFSL using the SVM classifier on the CK+ dataset. IFSL achieves good performance on all the expressions. However, we can also observethat some samplescorresponding to the sadanddisgust expressions are misclassifiedasthe angry expression. This is be-causethatboththedisgustandsadexpressionshavethewrinkled eyebrows, andthey share some similarities to the angry expres-sion.Moreover,thesubjectswiththesadordisgustexpressionsdo nothaveobviousmotionsaroundthemoutharea,whichalsoleads to the incorrect classification of these two expressions for some samples.
We alsoshow theclassificationresultsforeach expression ob-tainedby the proposed method using theSVM andk-NN classi-fiersonallthedatasetsinamorecompactwayinFig.4.Fromthe classificationresultsforthebestexpressionsonthethreedatasets withSVM(seeFig.4(a)),IFSLachievesthetoprecognitionrateson thehappyexpressionwhileitobtainstheworstresultsonthesad expression.These results can alsobe observed when using k-NN (seeFig.4(b)).Thisisbecausethatthehappyexpressionhasvery obvious appearance variations around the mouth area compared withthe other expressions. In contrast, the sad expression does nothavesignificantappearancevariationsaroundthesalientfacial featurepoints. Actually, similar observationshave beendiscussed insomeotherworks[9,37].Wealsoobservethatthesadandfear expressionssometimesshowsimilarappearanceforthesubjectsin thethreefacial expressiondatasets. Thus,IFSL cannot accurately discriminatethesetwo expressions forsome subjects.As we can seein Fig. 4(c), IFSL with eitherSVM ork-NN achieves the best
Table1
TheconfusionmatrixobtainedbyIFSLwithSVMonthe CK+dataset.Thebestresultsareboldfaced.
(%) An Di Fe Ha Su Sa An 97.01 2.99 0 0 0 0 Di 2.27 96.59 0 1.14 0 0 Fe 0 0 100 0 0 0 Ha 0 0 0 100 0 0 Su 0 0 0 0 100 0 Sa 2.5 0 0 0 0 97.5
performance ontheCK+dataset.ThisisbecauseCK+isthe sim-plestandthelargestdatasetamongthesethreedatasets.However, IFSL achieves the worst performance on the JAFFE dataset, since thenumberofthetrainingsamplesislimited.
4.2.5. Comparisonwiththestate-of-the-artmethods
We compare the proposed IFSL with several state-of-the-art methods. These methods include PCA [38], multi-class LDA [38], m-LBP [36], Boosted-LBP [37], PLBP [6], CSPL [35], HMFF [61], SalientPatch [9], CS-APL [64], MSCNN [65], pACNN [21], gACNN [21],DLP-CNN[41],andDAM-CNN[40].Thechoiceofthese com-peting methods is based on the following reasons: 1) PCA and multi-classLDAarethetwowidely-usedsubspacelearning meth-ods forfacial expression recognition. We usethese two methods asthebaseline.2)TheLBP-basedmethods(i.e.,m-LBP,Boosted-LBP andPLBP) are regarded asthepowerful feature extraction meth-ods which achieve the state-of-the-art performance. 3) Salient-Patch, CSPL and CS-APL are proposed to address part-based im-age representation and they effectively extract expression infor-mation in local facial regions, which is similar to the proposed method.4)HMFFusesasubspaceanalysismethodbasedona hier-archicalfeatureextractionframework,whichalsoaimstoenhance the discriminability of different expressions. 5) MSCNN, pACNN, gACNN,DLP-CNNandDAM-CNNaretherepresentativeCNN-based facial expressionrecognition methods.MSCNN can effectively ex-tractspatialfeaturesunderthesupervisionofrecognitionand ver-ificationsignals.pACNN,gACNNadopttheattentionmechanismin CNN.DLP-CNNemploysthedeeplocality-preservingfeature learn-ing for FER. DAM-CNN designs a deep multi-path convolutional neuralnetworkbytakingadvantageofsalientregionattention.For all the competingmethods, we use the default parameters from therespectivepapers.
ComparisonresultsontheCK+datasetTable2comparesthe proposed IFSL method with the state-of-the-art methods on the CK+dataset.We canseethatthe proposedIFSLmethodachieves thebest recognitionrate, andsignificantlyoutperforms the tradi-tionalfeaturelearningmethods(suchasGSPL,HMFF,SalientPatch) ontheCK+dataset.ThePCAandmulti-classLDAachievepoor per-formanceon theCK+dataset.Thisis mainlybecausethelearned subspace obtained by either PCA or multi-class LDA is not dis-criminativeto distinguish differentfacial expressions. The perfor-manceobtainedbyIFSLwithSVMisbetterthanthatobtainedby IFSL withk-NNin termsof theaverage recognition performance. Moreover, compared withsome competing methods, such as m-LBP,Boost-LBP,GSPL andMSCNN,IFSLwiththesimplek-NN clas-sifierachievespromisingperformance. As wementionpreviously, k-NNmakesaclassificationdecisionbyusingthemajorityvoteof
Table2
Comparisonresultsobtainedbyallthe com-peting methods on the CK+ dataset. The bestresultsareboldfaced.
Methods Accuracy(%) PCA(k-NN) 43.8 PCA(SVM) 47.3 multi-classLDA(k-NN) 84.7 multi-classLDA(SVM) 87.1 m-LBP[36] 88.4 Boost-LBP[37] 91.1 PLBP[6] 95.2 GSPL[35] 89.9 HMFF[61] 96.1 SalientPatch[9] 94.0 CS-APL[64] 98.6 MSCNN[65] 95.5 pACNN[21] 97.0 gACNN[21] 96.4 DAM-CNN[40] 95.9 IFSL(SVM) 98.7 IFSL(k-NN) 96.6 Table3
Comparisonresultsobtainedbyallthe competing methodsontheMMIdataset.Thebestresultsare boldfaced.
Methods Accuracy(%)
PCA(k-NN) 65.6
PCA(SVM) 67.9
multi-classLDA(k-NN) 68.3multi-classLDA
(SVM) 71.0 Boost-LBP[37] 86.9 PLBP[6] 91.0 GSPL[35] 73.5 MSCNN[65] 77.1 pACNN[21] 70.4 gACNN[21] 69.0 DLP-CNN[41] 78.5 IFSL(SVM) 92.6 IFSL(k-NN) 88.9
its knearest neighbors,whichindicates thatintra-class variations are small and inter-class variations are large in the transformed subspaceobtainedbyIFSL.Inotherwords,thedistributionsofthe samplescorresponding todifferentexpressions arewell-separated inthesubspaceobtainedbytheproposedIFSLmethod.Compared withtheCNN-basedmethods(suchasMSCNN,pACNN,gACNNand DAM-CNN), the proposed IFSL still achieves better performance, when onlylimitedtrainingdata areavailable. Therefore,the pro-posedmethodcan effectivelyextract thediscriminativeand com-pactfeaturesfromtheLRfacialimages.
Comparison results on the MMI dataset Table 3 shows the comparison results obtained by the proposed IFSL method and some state-of-the-art methods on the MMI dataset. MMI is a well-known challenging facial expression dataset due to non-uniformlyposed expressions andvarious headdressing. The pro-posed method with SVM obtains higher accuracy than PLBP [6], anditachievesmuchbetterperformancethanGSPL[35].PLBPuses the images withthe size of110×150 and GSPL uses theimages withthesizeof95×95.Theimageresolutions usedinthesetwo methods are much larger thanthe image resolution used inIFSL (i.e., 32×32). From Table 3, we can see that PCA obtains much worserecognitionratethanmulti-classLDA.Thisisbecause multi-classLDAeffectivelyreducesthewithin-classscatterwhile enlarg-ingthebetween-classscatter.However,multi-classLDAisnotable todiscriminatetheclassesclosetoeachothersincelargeclass dis-tances are often overemphasized duringtraining. In contrast,the
Table4
Comparisonresultsobtainedbyallthe com-petingmethodsonthe JAFFE dataset.The bestresultsareboldfaced.
Methods Accuracy(%) PCA(k-NN) 52.4 PCA(SVM) 55.6 multi-classLDA(k-NN) 62.7 multi-classLDA(SVM) 64.4 Boost-LBP[37] 82.0 MSCNN[65] 85.1 DAM-CAM[40] 99.3 IFSL(SVM) 88.2 IFSL(k-NN) 76.4 Table5
Comparisonresultsobtainedbyallthe com-petingmethodsonthe SFEWdataset.The bestresultsareboldfaced.
Methods Accuracy(%) PCA(k-NN) 23.4 PCA(SVM) 28.1 multi-classLDA(k-NN) 34.9 multi-classLDA(SVM) 39.3 MSCNN[65] 47.9 gACNN[21] 51.7 pACNN[21] 49.8 DLP-CNN[41] 51.1 IFSL(SVM) 46.5 IFSL(k-NN) 43.2
proposedIFSLmethodbenefitsfromtheclassspecificfilter learn-ing andlinearridge regression techniques,which can distinguish a specific facial expression from the neutral expression and ex-tractdiscriminativeexpressioninformationfromthe facialimage, respectively. IFSL also achieves better performance than MSCNN, whichshowstheeffectivenessoftheproposed methodforLR fa-cialexpressionrecognition.ThemainreasonisthatMSCNNsuffers fromtheproblemofinsufficienttrainingdata.pACNN,GACNNand DAM-CNNachievesworseresultsthantheproposedmethodinthe MMIdatasets.Thisismainly becausethatthesemethods usethe CNNmodeltrainedonother datasets forfeatureextraction with-outfine-tuning.
Comparisonresults on the JAFFE datasetTable 4 shows the comparison results obtained by the proposed IFSL method and some state-of-the-art methods on the JAFFE dataset. The perfor-manceofonlyfewexistingmethodsisevaluatedonJAFFE,sinceit isasmalldataset.IFSLachievesrelativelyloweraccuracyonJAFFE thanthatonMMIandCK+.Similarly,Boost-LBPalsoachievesthe worst performance on JAFFE, compared withits performance on theother two datasets.This observationis especially obviousfor multi-classLDAandPCA.ThisismainlybecauseJAFFE hasa very smallnumber ofsamples fortraining, which causesthat the ob-tainedfacial expression features are less effective.Notethat IFSL achievesworse performance than DAM-CAM.The main reason is that DAM-CAM fine-tunes the VGG model training on a large-scale dataset. Moreover, the input image size of DAM-CAM (i.e., 224×224)ismuch largerthan that ofIFSL(i.e.,32×32). In con-trast, IFSL learns the parameters of DIF by only using the small trainingset.
ComparisonresultsontheSFEWdatasetTable5comparesthe proposedIFSLmethodwithseveralstate-of-the-artmethodsonthe SFEWdataset.Amongallthecompetingmethods,gACNNand DLP-CNNrespectivelyachievethebestandsecondperformance (51.7% and51.1%, respectively), whichare better than theproposed IFSL withSVMbyamoderatemargin(5.2%and4.6%,respectively).This