Thomas Zink University of Konstanz [email protected]
Abstract. Viruses, Worms and Trojan Horses, the malware zoo is grow-ing every day. Hackers and Crackers try to penetrate computer systems, either for fun or for commercial benefit. Zombie-like creatures called Bots attack in the 10’s of thousands. Computer intrusions cause monetary as well as prestige losses. Countermeasures surely have to be taken, so a look on current technology and future outlines seems advisable.
1
Introduction
Though the average losses per company due to computer intrusion have con-stantly decreased since 2002 [1] there is no need to relax. New types of attacks can be observed and the times when intrusions have been a mean to identify software bugs are gone. Today most attacks are targetted towards criminal and commercial purposes like fraud, blackmailing and espionage.
For these reasons awareness towards computer security has increased in the last few years and the market for computer security related software and services keeps growing. Some techniques are well established and well known, like fire-walling and virus scanning. But true challenge lies in Intrusion Detection. A lot of research goes into Intrusion Detection Systems (IDS) since most techniques available today are slow in terms of reaction and prone to high false-positive rates.
An IDS basically serves the following purposes: – Detect and identify an attack.
– Traceback the source of the attack.
Ideally these functions should work completely automatical, i.e. without human interaction, and in real-time. But this is still fiction, especially the traceback of an attack proves to be quite a strain. IDS uses two types of techniques:
– Signature Detection
Identifies known attacks by matching events to signatures. – Anomaly Detection
Uses statistical and machine learning methods to detect anomal events. Can potentially detect new kinds of attacks but is prone to high false-positive rates. Anomaly detection is not covered in this paper.
In the following sections we will take a deeper look into how an IDS can detect and identify an attack by using string matching algorithms, how the source of an attack can be traced back and finally what possibilities exist to detect worms.
Konstanzer Online-Publikations-System (KOPS) URL: http://nbn-resolving.de/urn:nbn:de:bsz:352-175988
address these issues. 2.1 Aho-Corasick
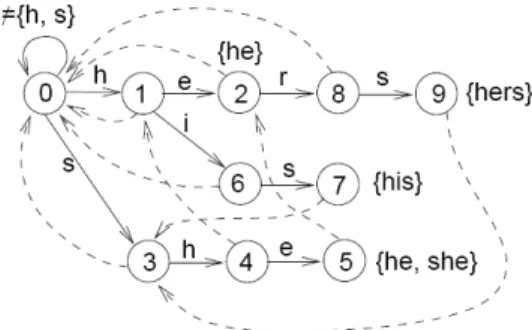
The Aho-Corasick algorithm builds a trie on the characters of all key strings that should be found. To find all key strings in one pass over the payload, it precomputes failure pointers that point from already recognized characters to all possible suffixes. Thus if a failure occurs the trie follows the failure pointers to the next character if it is recognized. Fig.1 and Fig.2 show the two phases of building an Aho-Corasick trie using the example key strings{he, she, his, hers} 1. As can easily be seen all key strings can be found with one pass over the
Fig. 1.Build an Aho Corasick trie
search string (the packet payload). On a miss (the read string is not recognized) traversing the trie starts anew, on a failure (the next character is not part of a key string already read) the trie follows the failure pointer to identify the new string.
Basically the Aho-Corasick trie forms a state machine with transitions resem-bling the characters read. Thus it is also known as an Aho-Corasick automaton. It is efficient in space consumption, since the trie is already compressed, and in complexity. It provides linear search time. A drawback is the large number of failure pointers that can arise.
1
Fig. 2.Precompute failure pointers
2.2 Boyer Moore
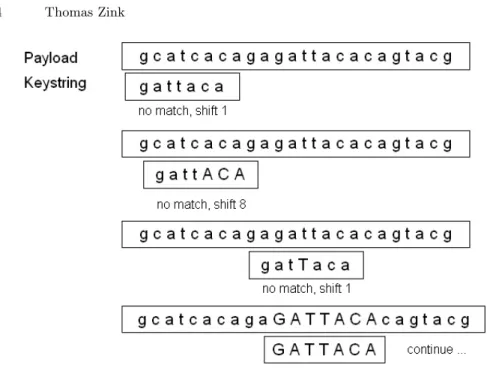
The Boyer Moore algorithm is one of the most efficient string matching algo-rithms available because it actually can find matches in sub-linear search time. It scans the key string from left to right. On a miss the key string is shifted a precomputed number of characters to the right, until a match of the current character occurs. Then the next character not yet matched is considered. Since the length of the key string and the position of the current character are known, the number of characters on which no match of the key string can occur can be computed. Fig.3 shows an example. Character matches are depicted by upper case characters. What should become clear by inspecting the example is that the algorithm can find exact string matches in sub-linear search time. There is one downside, however, searching for multiple key strings in the payload is inefficient. Also, each keystring has to be stored in its entirety.
2.3 Approximate String Matching
In some applications finding similar strings instead of exact strings is needed. This is equal to a string search using wildcards, so e.g. instead of searching for the string perl.exe one could search for p?rl.exe which would also find
perl.exeas well asparl.exe.
Basically two mechanisms exist that are based on two different ideas on how to handle character substitutions or insertions.
Substitution Error. The substitution error allows replacements of one or more characters in the key search string. So instead of searching the whole key string only certain character positions are considered. The substitution error method can not find character insertions or deletions.
Resemblence. Using resemblance the similarity of two strings is measured by dividing the number of characters they have in common by the length of the longer string. Formally this equals the division of intersection by union.
Fig. 3.Boyer Moore algorithm
Resemblance can therefore handle character insertions and deletions. However, a problem is that character positions are not taken into account. So the two strings perl.exeand lexe.rpehave resemblance one. Clearly this is not what we want. To overcome this problem order or position numbers can be introduced.
3
IP Traceback
Probably one of the most challenging problems regarding computer security is the IP traceback problem. Today tracing the source of an attack is done manually by studying log files and calling a chain of ISPs until the router that first routed the packet(s) in question is identified. Of course, this is a lot of waste of human resources and clearly pathfinding could also be done in hard- and software. However, this manual example shows us, how IP traceback in general works. Every packet has a specific path through the net, aka traffic signature. By identifying routers along the path, the source, or at least the source network can be determined even if the attacker spoofed his IP address. Some approaches to this method follow.
3.1 Probabilistic Marking
The naive approach would be to have every router in the path place it’s unique router id into the packets header. Clearly this would bring a lot overhead and the header would grow in size the longer the path gets. Since most attacks like SYN
flooding consist of hundreds of packets at least it is possible to shift the path computation to the end system and only have one router at a time place it’s id into the packet’s header. Every router in the path generates a random number, if it is below a certain probability it places it’s unique router id into the header overwriting a previously set id. Over time all routers will have written their id to some packets and the end system can compute the path. This approach is known asnode sampling. One problem is that a very large number of packets is needed to ensure that the end system gets all router ids. Another problem is, that an attacker can mask the path by placeing fake ids into all packets sent. To overcome these problems an extension can be made known asedge sampling. Here, instead of only using one router id, a tuple of two consecutive router ids and hop count is placed in the packet header. Edge sampling works as follows:
1. router generates random number n and checks against probability p 2. if (n <p) then write triple (id, -, 0) where ’-’ means that the next hop must
be determined and 0 is the hop count h 3. if (n>p & h = 0) then write (, id, 1) 4. if (n>p & h>0) then increment h
Fig. 4.Edge sampling for path computation
The end system then sorts the samples on frequency and distance and can then compute the path. With edge sampling the victim still needs a large number of packets but much less than with node sampling. Fig.4 shows how edge sampling works 2.
3.2 Logging
Probability marking is nice but not the answer to everything. It can not traceback attacks with few or even only one packet like the teardrop or land attack. To
2
3.3 Bloom Filters
Bloom filters make use of the observation that a packet log query for a specific packet is a set membership equality query very similar to equality queries used in database management systems. Equality queries can very efficiently be done using hash tables. Bloom filters thus keep a bitmap of size m = aN, where N is the number of elements to keep and a is some arbitrary multiplier usually greater than 2. Then each packet is hashed using k independant hash functions to determine k bit positions in the bitmap. These bits are set to 1. If two packets hash to the same bit position, the bit remains set. On a query, the packet in question is hashed using the same k hash functions to find the bit positions. If all k bits are set, then the packet has most likely been routed by the router. Notice the use of ’most likely’. Bloom filters reduce the number of bits needed to store a packet but thus allow false-positives. However, the probability is pretty small and even if false-positives occur this would only yield to some wrong router querying it’s neighbors. Bloom filters efficiently reduce memory consumption and thus speed up log query time. In addition they can easily be implemented in hardware (as done in the SPIE system, see [3] for further details).
4
Worm Detection
In the last few years worms have become famous and drew the attention of pub-lic media. Specimen like Slammer and Sasser infected millions of hosts within seconds, people working in network security companies these days (like the au-thor) remember hours and hours of work to repair the damage done. A quick definition of worm should be made at this point and the difference to viruses pointed out.
A worm uses exploits like buffer overflows to copy itself into memory and then execute it’s own code. It then scans the network for other vulnerable hosts thus exponentially infecting more and more systems. It can spread completely by it-self eating it’s way through the network and getting larger and larger (thus the name worm). A virus on the other hand always infects foreign code. It needs a host file in which it can inject it’s code aka signature. The virus code is not read and executed until the infected file is read into memory, which is usually invoked by the user. Thus in addition to a host file a virus is dependant on user interaction and can not spread by itself. Today malware often uses techniques of
viruses as well as worms. An example malware comes as a mail attachment and after being executed by the user infects the machine and scans the system for email adresses as well as the network for vulnerable hosts. So the borders seem to blur. Nevertheless, when talking about network security one should be aware of the differences of malware types.
Worms spead extremely fast and can do much damage. So worm detection should work in real time and with as minimum of human intervention as possible. Un-fortunately, today the opposite is true. Worm detection is retroactive, ie only after infection already has occured, slow and needs a lot of human interaction. Every worm has to be analysed manually to develop removal and detection tools. However, every worm we know of today has the same significant features that could be used to detect worms prior to infection and completely automatical. These features are:
1. Large volume of identical traffic
Worms produce a large amount of identical packets. 2. Rising infection levels
The number of sources is growing. 3. Random probing
Packets are directed to random hosts or broadcast to random networks. Lots of the destination addresses aren’t used.
Knowing this, it is pretty easy to design a system using already well known mechanisms to detect all of the three worm features in real time and with low memory consumption and reasonable complexity.
– Identify large flows
The packet content and destination port can be used as a valid flow identifier with which it is possible to identify the large flows of identical traffic. – Count the number of sources
Keep small bitmaps to estimate the number of sources on a link. Rising infection levels can then easily be detected.
– Determine random probing
The destination of a packet can be matched against lists of addresses, net-works, prefixes known to be used. These can be stored in bloom filters. As promising as this may sound worm authors being (mostly) intelligent people can easily defeat these methods. They simply can slow down infection rates, introduce random content in the packet payload (this is already done by some authors to defeat anti virus software) and use lists of known IP addresses or networks to reduce the amount of random probing.
5
Discussion
A lot remains to be done regarding network security. Current technology is slow, inadequate and needs much human intervention. Most techniques presented here, like probability marking or bloom filters, require hard/software changes on a
privacy and again the unaware user is the looser. Unfortunately, the unavailabil-ity of efficient and effective securunavailabil-ity systems drives some countries, like germany, to react to rising threats by issuing a number of harsh and unrealistic laws that criminalize a majority of innocent people (including the author). There is a pro-fund need for adequate security systems, their lack not only causes monetary losses but also cause significant changes in daily life. However, life in cyberspace is not much different of that in the real world. So the same rules should apply, and also the same rights should be granted. It would be more beneficial if there was more control of software quality. Cars aren’t released on the streets until they have been thoroughly tested. A car company doesn’t sell a buggy car to later provide a patch that makes the brakes work properly. With software this is common practice.
References
1. CSI/FBI Computer Crime and Security Survey 2006, http://i.cmpnet.com/gocsi/db area/pdfs/fbi/FBI2006.pdf 1
2. Kilpelinen, P., Biosequence Algorithms, lecture at the University of Kuopio, Spring 2005, http://www.cs.uku.fi/˜kilpelai/BSA05/lectures/slides04.pdf 1