International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)97
Parallel Computing: High Performance
P.Durgaprasad
Asst.Prof, CSE, Sri Sarada college, JNTUH
Abstract— This paper elucidates the importance of parallel computing in various areas like processors design, systems design. Parallel computing plays a vital role in computer architecture where the architect considers the computation as a crucial thing. The change to parallel microprocessors is a milestone in the history of computing. And this paper also aimed to present how parallel computing supports for the performance.
Keywords— Computer architecture, Computing, Parallel Computing, Serial computing , Runtime.
I. INTRODUCTION
Parallel Computing is evolved from serial computing that attempts to emulate what has always been the state of affairs in natural World. We can say many complex irrelevant events happening at the same time. For instance; planetary movements, Automobile assembly, Galaxy formation, Weather and Ocean patterns.
Historically, it is considered to be ―the high end of computing‖ and has been used to model difficult scientific, computational and engineering problems.
Different applications will present different tradeoffs between performance and energy consumption. For example, many real-time tasks (e.g., viewing a DVD movie on a laptop) have a fixed performance requirement for which we seek the lowest energy implementation. Desktop processors usually seek the highest performance under a maximum power constraint. Note that the design with the lowest energy per operation might not give the highest performance under a power constraint, if the design cannot complete tasks fast enough to exhaust the available power budget.
A large number of parallel machine models have been proposed. Some of the widely accepted models are: 1) fixed connection machines, 2) shared memory models, 3) the Boolean circuit model, and 4) the parallel comparison trees [1].
In the randomized version of these models, each processor is capable of making independent coin flips in addition to the computations allowed by the corresponding deterministic version. The time complexity of a parallel machine is a function of its input size.
Serial and Parallel Computing
Traditionally, software has been written for serial
computation:
To be run on a single computer having a single Central Processing Unit (CPU).
A problem is broken into a discrete series of instructions.
Instructions are executed one after another.
Only one instruction may execute at any moment in time.
Parallel computing is the simultaneous use of multiple compute resources to solve a computational problem:
To be run using multiple CPUs.
A problem is broken into discrete parts that can be solved concurrently.
Each part is further broken down to a series of instructions.
Instructions from each part execute simultaneously on different CPUs
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)98
Intel believes that the increase in demand for computing will come from processing the massive amounts of information available in the ―Era of Tera‖. [Dubey 2005] Intel classifies the computation into three categories: Recognition, Mining, and Synthesis, abbreviated as RMS. Recognition is a form of machine learning, where computers examine data and construct mathematical models of that data. Once the computers construct the models, Mining searches the web to find instances of that model. Synthesis refers to the creation of new models, such as in graphics.In the development of many modern technologies, such as steel manufacturing, we can observe that there were prolonged periods during which bigger equated to better. These periods of development are easy to identify: The demonstration of one tour de force of engineering is only superseded by an even greater one. Due to diminishing economies of scale or other economic factors, the development of these technologies inevitably hit an inflection point that forever changed the course of development. We believe that the development of general-purpose microprocessors is hitting just such an inflection point.
There are two critical forces shaping software development today. One is the popular adoption of Parallel Computing and the other is the trend toward Service Oriented Architecture. Both ideas have existed for quite a while, but the current technology of CMT(Chip Multi-Threading) processor designs, horizontally scaled systems, near zero latency interconnects and new web service standards are all accelerating both ideas into the main stream and are becoming adopted everywhere. It is quite easy to predict that most desktop machines or even laptops will be powered by multi-core or CMT processors over the next few years.[4] A more intriguing and important issue is whether the current state of software development is sufficient to produce good quality parallel applications for the new computing machines.
II. RELATED WORK
A system for the categorization of the system architectures of computers was introduced by Flynn (1972). It is still valid today and cited in every book about parallel computing.
It will also be presented here, expanded by a description of the architectures actually in use today.
Single Instruction - Single Data (SISD)
The most simple type of computer performs one instruction (such as reading from memory, addition of two values) per cycle, with only one set of data or operand (in case of the examples a memory address or a pair of numbers). Such a system is called a scalar computer.
Single Instruction - Multiple Data (SIMD)
The scalar computer of the previous section performs one instruction on one data set only. With numerical computations, we often handle larger data sets on which the same operation (the same instruction) has to be performed. A computer that performs one instruction on several data sets is called a vector computer.
Multiple Instruction - Multiple Data (MIMD)
Up to this point, we only considered systems that process just one instruction per cycle. This applies to all computers containing only one processing core (with multi-core CPUs, single-CPU systems can have more than one processing core, making them MIMD systems). Combining several processing cores or processors (no matter if scalar or vector processors) yields a computer that can process several instructions and data sets per cycle. All high performance computers belong to this category, and with the advent of multi-core CPUs, soon all computers will. MIMD systems can be further subdivided, mostly based on their memory architecture.[2]
Parallelism will substantially increase through the use of dual/multi-core chips in the future!
Parallel computing is entering every days life: Dual-core based system (Workstation, Laptop, etc…)
Basic design concepts for parallel computers:-
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)99
B. Distributed memory systems:Multiple processors/ compute nodes are connected via a network. Each processor has its own address space/memory, e.g. GBit Clusters with Xeon/Opteron based servers. [3]
Parallel Computer Memory Architectures:
Shared Memory Architecture
Fig 1. Shared Memory Architecture
All processors access all memory as a single global address space.
Parallel Computer Memory Architectures:
[image:3.612.327.565.204.421.2]Distributed Memory
Fig 2. Distributed Memory
Each processor has its own memory.
Is scalable, no overhead for cache coherency. Programmer is responsible for many details of communication between processors.
Eras of computing
The most prominent two eras of computing are: sequential and parallel era.In the past decade parallel machines have significant competitors to vector machines in the quest for high performance computing.
The computing era starts with a development in hardware architectures, followed by system software, applications and reaching their saturation point. Every element of computing undergoes three phases: R&D, Commercialization and Commodity
Fig 3. Two eras of computing [8]
III. PARALLEL COMPUTING ASPECTS
In computational field technique which is used for solving the computational tasks by using different type multiple resources simultaneously is called as parallel computing. It breaks down large problem into smaller ones, which are solved concurrently. A system in which two or more parts of single program operate concurrently on multiple processors.
Parallel computing has become dominant paradigm in computer architecture and parallel computers can be classified according to the level at which their hardware supports parallelism. Computational resources may include:
Single computer with multiple processors. Variant no. of computers connected to
network.
[image:3.612.74.253.440.543.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)100
Performance metrics for parallel systems:• To determine best parallel algorithm • Evaluate hardware platforms
• Examine the benefits from parallelism
Serial runtime of a program
– Time elapsed between the beginning and end of execution on a sequential computer
– Usually denoted by TS
Parallel runtime of a program
– Time elapsed from start of the parallel computation to end of execution by the last processing element (PE).
– Usually denoted by TP
Represented by an overhead function (TO)
– Total time spent in solving a problem using ƿ PEs is ƿTP
– Time spent for performing useful work is TS – The remainder is overhead TO given by
TO = ƿ TP- TS ____ [4]
Parallel Programming with the .NET Framework
The .NET Framework 4 includes significant advancements for developers writing parallel and concurrent applications, including Parallel LINQ (PLINQ)[7], the Task Parallel Library (TPL), new thread-safe collections, and a variety of new coordination and synchronization data structures.
Runtime System
A major challenge in developing software for client platforms is hardware diversity. It is untenable to ask software vendors to adapt or optimize their programs for each of these platforms. Instead, we believe it is important to provide an execution environment that attempts to meet the applications goals the best it can given the available resources on the platform. Two key concepts in this statement are worth emphasizing:
1) Application goals: We believe that quality of service (QoS) will be increasingly important on client systems to provide a good user experience.
Many performance-hungry applications can be written so as to provide the best answer that can be computed by a given deadline, and will be written this way to be responsive without jitter and long pauses. We expect applications to be annotated and organized such that a level of output quality can be selected based on the available resources.
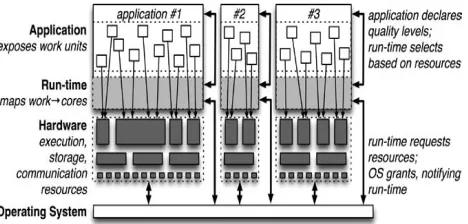
[image:4.612.326.560.476.588.2]2) Available resources: We expect heterogeneity in client platforms. Not only will there be heterogeneity between platforms (different design/price points within a process generation and across process generations), but also within a platform. We expect future platforms to include a variety of cores (a few large cores, optimized for latency, for sequential performance and many small cores, optimized for throughput, for parallel workloads); even when designed to be similar, process variation will endow them with different performance characteristics. Furthermore, the resources that can be applied to each program’s execution may vary over time as applications are launched or complete and due to adaptation of the hardware to physical constraints (e.g., power, temperature, battery life, and aging). The process of trying to maximize utility (the sum of the user benefits of all running programs) given the available resources is an optimization problem. [9,10,11]
Fig 4. The anatomy of a managed execution of a heterogeneous multi-core machine running three parallel applications
IV. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 2, December 2011)101
Many things can be parallelized by programmer and compiler like loops/instruction block, instructions, functions etc. Our strategy of integrated applications and systems research will ensure we have the right test bed for evaluating, refining and ultimately proving our ideas on client parallel programming. The widespread use of parallel computation which requires a software infrastructure that allows programmers to code in a high-level language that abstracts away the complexity of protocols, scheduling, and resource management.References
[1] Randomized Parallel Computation Sanguthevar Rajasekaran Dept. of CISE, Univ. of Florida John H. Reif Dept. of CS, Duke University
[2] An Introduction to Parallel Programming,Tobias Wittwer [3] Parallel Computing,G. Wellein, G. Hager .
[4] "Top500OSchart".Top500.org.
http://www.top500.org/overtime/list/32/os.
[5] Introduction to Parallel Computing, Ananth Grama,2004 [6] Performance metrics: keeping the focus on runtime IEEE,
Sahni, S.; Thanvantri, V.; Florida Univ., Gainesville, FL
[7] Microsoft http://code.msdn.microsoft.com/
[8] Parallel computing at a glance, Jonathan J. Nassi1 & Edward M. Callaway2
[9] L.V. Kale, ―Performance and Productivity in Parallel Programming via Processor Virtualization,‖ Proc. of the First Intl. Workshop on Productivity and Performance in
High-End Computing (at HPCA 10), February 14, 2004.
[10]V. Vardhan, D. Sachs, W. Yuan, A.F. Harris III, S. Adve, D. Jones, R. Kravets, and K. Nahrstedt,‖ GRACE-2: Integrating Fine-Grained Application Adaptations with Global Adaptation for Saving Energy,‖ to appear in the IJES, Special Issue on ―Low-Power Real-Time Embedded Computing.‖ Invited paper. Extended version of a paper in the Workshop on Power Aware Real-Time Computing (PARC), 2005. [11]W. Yuan, K. Nahrstedt, S. Adve, D. Jones, and R. Kravets,
![Fig 3. Two eras of computing [8]](https://thumb-us.123doks.com/thumbv2/123dok_us/8747841.891224/3.612.327.565.204.421/fig-two-eras-of-computing.webp)