SHERLEKAR, RIDDHIMAN. Fog Computing Provisioned Data Distribution for Smart Manufacturing: Design & Implementation (Under the direction of Drs. Paul H. Cohen and Binil Starly).
With Industrial automation gaining its pace, the upsurge in the number of “Intelligent” manufacturing machines is unprecedented. The Manufacturers are gradually starting to transform their shop-floors into an integrated network of Cyber-Physical Systems, also known as “Smart factories.” Additionally, the technical breakthroughs in domains of Cloud Computing, Internet of
Implementation
by
Riddhiman Sherlekar
A thesis submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the degree of
Master of Science
Industrial Engineering
Raleigh, North Carolina 2019
APPROVED BY:
_______________________________ _______________________________ Dr. Paul H. Cohen Dr. Binil Starly
Committee Co-Chair Committee Co-Chair
DEDICATION
This work is dedicated to
my Late grandmother Smt. Snehal Vijay Wagh, my mother, Mrs. Vineeta Sherlekar
and
my father, Mr. Rajesh Sherlekar,
BIOGRAPHY
Riddhiman Sherlekar was born on March 14th, 1995 in Indore, India. He earned his Bachelors in Petroleum Engineering from Pandit Deendayal Petroleum University, Gandhinagar, India in 2017. He further decided to pursue a Master’s degree in Industrial Engineering at North Carolina State
ACKNOWLEDGMENTS
First and foremost, I would sincerely like to express my deepest gratitude to Dr. Binil Starly without whose trust, guidance, patience, and advising this work would have been incomplete. He believed in me more than I believed in myself, which motivated me every day to learn more and work hard. I would also like to thank my Co-advisor, Dr. Paul H. Cohen, for his guidance and funding the research. My journey would be incomplete without the support, constant motivation and appreciation from Dr. Behnam Kia (CEO, InfinityGates) who helped me to expand my knowledge in the area of Artificial Intelligence, Software Engineering and guided me to use the same for my research. I would also like to mention Justin Lancaster for his help with IT and Amy Roosje for administrative support.
Secondly, I would also like to thank Mr. Rob Tahamtan (Lenovo DCG, Morrisville) for providing the industry viewpoint to my research and guiding me professionally.
Thirdly, I would like to thank my colleagues Bandeep Singh Dua and Harsh Mehta for their valuable suggestions and company without whom the journey would be incomplete.
TABLE OF CONTENTS
LIST OF TABLES ... viii
LIST OF FIGURES ... ix
LIST OF TERMINOLOGY ... xi
Chapter 1: Introduction ... 1
1.1 Background ... 2
1.2 Problem Scenario ... 3
1.3 Research Objectives ... 5
1.4 Thesis Outline ... 6
Chapter 2: Literature Review ... 7
2.1 Communication Protocols and Frameworks for Industry 4.0 ... 7
2.1.1 TCP & Web Sockets ... 7
2.1.2 XML / JSON ... 8
2.1.3 HTTP/REST ... 8
2.1.4 MTConnect ... 8
2.1.5 Publish Subscribe Messaging System ... 9
2.1.6 Apache Kafka & Apache Zookeeper ... 9
2.2 Data Distribution in Manufacturing Systems ... 10
2.3 Cloud Manufacturing ... 11
2.3.1 Limitations of Cloud Manufacturing ... 13
2.4 Overview of Fog Computing ... 14
2.4.1 Characteristics of Fog Computing ... 16
2.5 Fog Computing in Manufacturing ... 20
Chapter 3: The System Architecture and Characteristics ... 22
3.1 Overview of the System Architecture ... 22
3.2 Physical Layer Asset ... 22
3.3 The Network Layer ... 24
3.4 The Cloud Layer ... 25
Chapter 4: Implementation of the Fog Computing for Smart Manufacturing and Performance Results ... 27
4.1 Edge Design and Implementation ... 27
4.2 Edge to Fog Communication ... 30
4.3 Fog Design and Implementation ... 31
4.3.1 Fog Node deployed in a Physical Server ... 32
4.3.2 Fog Node deployed in a Docker Container... 32
4.3.3 Application architecture at the Fog Node ... 34
4.4 Evaluation of Data distribution methods ... 36
4.4.1 Data Distribution using Python Ingestion Engine with the Physical Server. ………....36
4.4.2 Data Distribution using Python Ingestion Engine with the Docker-based Containerization Approach ... 37
4.4.3 Data Distribution using Apache Kafka with Fog Node deployed on Physical Server & in a Docker container ... 39
4.5 Cloud Design and Implementation ... 41
Chapter 5: Discussion and Future Work ... 45
5.1 Discussion ... 45
5.2 Future Work ... 46
REFERENCES ... 49
LIST OF TABLES
Table 4.1 Performance Evaluation of the Fog Node in Physical Server………...37 Table 4.2 Performance Evaluation of the Fog Node in Docker container………….………...38 Table 4.3 The average time taken to consume messaged in both Fog Node
LIST OF FIGURES
Figure 2.1 The Operating principle of Cloud Manufacturing………...12
Figure 3.1 The Edge Layer Design and Architecture………..….……23
Figure 4.1 The MTConnect Data Flow………27
Figure 4.2 Machine Process Data Representation on Local NC State Server……..…….…...28
Figure 4.3 The XML representation of the MTConnect data……..……….…28
Figure 4.4 MTConnect data stored in the Local ERP database………29
Figure 4.5 Various parts from a CAD repository……….…30
Figure 4.6 Docker Compose architecture………. ...33
Figure 4.7 Application architecture at the Fog Node……….………..34
Figure 4.8 Data storage format in the Fog Database……….………...35
Figure 4.9 A graph showing the performance of the Fog node when deployed in a Physical server………..………….37
Figure 4.10 A graph showing the performance of the Fog node when deployed in a Docker container…...38
Figure 4.11 A graph showing the time taken by the machine data to produce to a Kafka broker………...39
Figure 4.12 The graph showing consumer lag in case of node failure when the Fog node is deployed in a Physical Server……….………...40
Figure 4.13 The graph showing consumer lag in case of node failure when the Fog node is deployed in a Docker container………..…....41
LIST OF TERMINOLOGY
CAD Computer-aided design CPS Cyber-Physical Systems DDS Data Distribution System ERP Enterprise Resource Planning HDFS Hadoop Distributed File System IaaS Infrastructure-as-a-Service IoT Internet of Things
IIoT Industrial Internet of Things JSON JavaScript Object Notation KPI Key Performance Indicators
MQTT Message Queue Telemetry Transport OEE Overall Equipment Efficiency
PaaS Platform-as-a-Service
RFID Radio-frequency identification SaaS Software-as-a-Service
SME Small and Medium Enterprises SOA Service-oriented architecture SSL Secure Sockets Layer
CHAPTER 1 INTRODUCTION
The manufacturing shop floors are heading towards sweeping digitization and taking giant leaps towards the integration of their IT infrastructure, and shop floors, this shift in operation is being considered as a revolution as has been termed as Industry 4.0. The term ‘Industry 4.0’ emerged during the Hannover Conference in 2011 and mainly represents the current trend of automation technologies in the manufacturing industry, which involve the blend of cutting-edge technologies such as the Cloud Computing, Internet of Things (IoT) and Cyber-Physical Systems (CPS) [1].
Traditional programming models which work with Cloud Manufacturing are inefficient when it comes to working with high throughput and latency sensitive data distribution within a Smart Manufacturing environment. Also, the Industry 4.0 revolution is not only limited to manufacturing data sources which generate data of a specific kind. To tackle this heterogeneity and distributed nature of advanced manufacturing, modern big data tools, and scalable computing platforms are required. Further, Industry 4.0 equips the manufacturer with real-time information sharing and collection from the manufacturing resources. The Industry 4.0 revolution has led to a stronger control over manufacturing assets, flexible process control, and a more data-centric approach to the manufactures for the decision-making process.
1.1 Background
The number of devices which will be connected to the internet, ranging from simple devices to state-of-the-art manufacturing machines in-built with the flexible manufacturing systems is burgeoning at an exponential rate. This increase in the number of devices is accompanied by a gigantic stream of data from these devices, which is highly essential, and if used wisely, it can metamorphosis the current manufacturing workflows. In the present scenario, the small and medium manufacturers are not well equipped to use this data because of intricate software platforms and capital investments associated with these platforms or services. Besides, the control over the data, data privacy and security are also a significant cause of angst among the manufacturers.
by leveraging the power of Fog Computing (an extension to Cloud Computing), the Industrial Internet of Things and computing nodes equipped with storage and networking capabilities. According to us, the Fog Computing paradigm can be beneficial in solving the current problems and limitation of Cloud Manufacturing by proposing a layered architecture to support different application in a smart manufacturing environment.
The augmentation in the level of decentralization leads to increase privacy in a Fog Computing architecture. Each Fog Computing architecture can be unique and can have their special implementation in terms of tools used, software frameworks, security, and privacy. To summarize, Fog computing increases data privacy as the number of channels through which the data travels are enormous and mostly hidden from the client.
1.2 Problem Scenario
The underlying concept of Fog Computing is to offload the computing and data aggregating tasks to a network of distributed computing nodes which are located physically closer to the Cloud data centers. Doing so would resolve the latency and data bottleneck issues which the current Cloud Manufacturing is facing. According to us, Fog Computing is necessary to modify the existing paradigm to expedite the digital transformation under the Industry 4.0 revolution. Several challenges will arise when a large number of interconnected devices, manufacturing resources are on centralized computing infrastructure. Consequently, the phenomenon of Industry 4.0 could be slowed down. This section will further delineate the research objectives of the thesis.
Cloud is witnessing a decline. Moreover, a significant chunk of the edge devices or the data sources in the smart manufacturing environment are systems on chip IoT devices which communicate via lightweight protocols like MTConnect [4], ZigBee [5], and OPC/UA [6]. Therefore, the first problem is the need to build a robust data pipeline for these data streams using gateway devices for processing and to distribute the data.
Problem 2: Data Privacy and Ownership: A focal area of concern when it comes to data sharing and exchange over different networks is the privacy and control over the data generated from the manufacturing resources. A manufacturer might be interested in sharing only a particular portion of his nonproprietary data. Our architecture allows certain types of data (Machine data, JSON metadata of CAD models) to be shared on a read-only basis with distributed, fiduciary computing nodes while maintaining the ownership and control in the hands of the manufacturer which would significantly help the manufacturers to make data-driven decisions from the massive data and concomitantly, avoid the formation of data silos.
1.3 Research Objectives
This thesis aims to address the research problems discussed in the previous subsection. The focus of the research is to develop a data distribution architecture for a smart manufacturing environment which permits the manufacturers to share their different types of data with a network of geographically distributed fiduciary nodes and consequently the architecture facilitates the High performance Cloud to serve the clients in a way that maintains the ownership over the data, concurrently.
Research Objective 1: To develop a fault-tolerant, scalable, and robust middleware for
manufacturing machines, which would allow the exchange of high-volume data with distributed fiduciary nodes (Fog Nodes).
In the first scenario, we demonstrate an architecture which is used to pipeline the high throughput data from the machines and other data from remote manufacturing resources using Apache Kafka. Secondly, we show how this data can be aggregated in-house by the manufacturer, and only specific data views can be transferred to NoSQL databases which are the backend of the stack which exposes this data via secured API only to the middleware deployed on the High-Performance Cloud.
Research Objective 2: To demonstrate the use and benefits of containerization approach for Fog Node deployment in a smart manufacturing environment
1.4 Thesis Outline
CHAPTER 2 LITERATURE REVIEW
This chapter will review the communication protocols and various technologies that are used for data transfer and exchange within a Cyber-Physical system. Section 2.1 is dedicated to the communication protocols and Big Data tools, which form an integral part of the proposed architecture. The following section, covers the literature and previous works on Cloud manufacturing with the following sub-section describing the limitations of Cloud Manufacturing in the current scenario. Section 2.3 gives an overview of the concept of Fog Computing and is followed by the characteristics of Fog Computing delineated by literature and architectures proposed, respectively. The final section reviews the previous work done in Fog Computing pertinent to manufacturing.
2.1 Communication Protocols and Frameworks for Industry 4.0
Communication protocols and technology is the cornerstone of any Industry 4.0 architecture. In this section, the communication protocols, security protocols, relevant Big data tools for data streaming, and other industry standards will be discussed.
2.1.1 TCP (Transmission Control Protocol) & Web Sockets
The TCP or the Transmission Control Protocol is of high importance in the IoT environment. Being a connection-oriented protocol, TCP keeps track of packets and retransmission mechanism is also available in case of a packet loss. Moreover, TCP is versatile as it can be used along with AMQP, MQTT, and most importantly, with the REST architecture [7].
data. Web Sockets are widely used to send the data from a server to a client but are not favorable for devices with low computing capabilities [8].
2.1.2 XML / JSON
The Extensible Markup Language provides a standard method to encode the documents which allow them to be machine-readable and human-readable for data exchange over the internet. Moreover, XML is also being used nowadays for representing arbitrary data objects [9].
JSON or JavaScript Object Notation is used to represent data in key-value pairs and also serialized data. As the data representation is arbitrary in the IoT landscape, the two most common data formats are XML and JSON. As a result, in a broader context, these two formats form the backbone of IIoT communication even though JSON is considered as a standard format for IoT as it is more lightweight and compatible with REST architectures.
2.1.3 HTTP/REST
The Internet heavily relies on the REST or the Representational State Transfer architecture, which relies on the HTTP. The REST is a software-oriented architecture which provides a high level of interoperability between computing systems over the Cloud. These services allow clients to get access to textual representations with the use of "stateless" operations. A stateless protocol is not needed to store the information about the status of a user when multiple requests are handled. The communication is established with the fog layer commonly using the REST HTTP protocol, which provides more flexibility to developers for building applications to serve clients. A set of operations allowed by the HTTP are GET, PUT, POST, and DELETE.
2.1.4 MTConnect
MTConnect protocol is primarily used for machine monitoring and analysis of the data generated during the machining process. MTConnect is an open-source protocol which provides an XML based backend format. There are two components, namely the MTConnect agent and the MTConnect adapter. Data is retrieved by the MTConnect adapter and the adapter further supplies this data to the MTConnect agent. The agent further maintains this data in a TCP server and provides a REST interface, meaning that the data can be retrieved via HTTP request-reply, which allows the data to be consumed by multiple clients locally.
2.1.5 Publish/Subscribe Messaging System
The Publish / Subscribe messaging system is a software architecture in which the data sources which generate the messages do not directly send them to the receivers or the subscribers but instead classify them into separate topics. The Publish/Subscribe model is heavily used in the micro-services architectures, and a vital feature of the Publish/Subscribe model is that decouples applications which in turn improves the scalability and performance of the system. The producers do not produce messages for the consumers, and similarly, the consumers express their intent by subscribing to the topics rather than directly consuming the messages from the producer.
2.1.6 Apache Kafka & Apache Zookeeper
The key components of Apache Kafka are namely:
• Producer: A Kafka Producer is an application which acts as a Data Source [10]. Producers
can publish their data to topics at their will and are also responsible for the management of partitions within topics.
• Consumer: A Kafka Consumer can be an application or a database which consume
messages by subscribing to particular topics. A particular partition of the topic is consumed by the consumer, and Kafka also has built-in functionality of consumer groups, which makes it more scalable than other data streaming platforms.
• Broker: A Kafka broker is a server, and the Kafka producers who publish the data to the
topics are within the broker. A Kafka broker is a part of the Kafka cluster and is coordinated by Apache Zookeeper.
• Topic: A Kafka topic consist of multiple partitions, and brokers are the entity which
persists the topics. Kafka consumers read the data from Topics. A Kafka topic is a data structure which is persisted on the broker’s disk. The messages are stored in the format of
byte arrays which are further organized into Topics. A key functionality provided Apache Kafka is that the messages are retained and persisted longer than other queue based models. Apache Zookeeper [12] is a high-performance software service to maintain coordination between distributed applications. Zookeeper is required to run Apache Kafka as it maintains the synchronization, configuration, and naming of the Kafka brokers.
2.2 Data Distribution in Manufacturing Systems
within the systems to anchor the massive flux of data which generates in a highly distributed and decentralized cyber-physical system. Data management and reliable communication protocols are the real essences of successful architecture. One of the initial works [13], proposed a control system based decentralized architecture on managing the dynamic requests in a modular manufacturing environment. The literature identified significant issues which occur during traditional manufacturing and how it fails when the complexity of system integration increases. The authors proposed an architecture using the DDS protocol, which allows industrial robots and manufacturing entities to communicate with each other in a flexible manufacturing environment. A similar approach for flexible automation was proposed by the authors in [14], which introduced a real-time, platform independent system using DDS and a case study involving a modular fixturing system. Ungurean and Gaitan [15] discussed the interoperability of Data Distribution Service with a SCADA system. The architecture used in the paper by the authors is based on the OPC protocol, which uses a DDS middleware to distribute the data and establish communication with the SCADA systems. The essence of all the proposed architectures is the different communication protocols which ensure efficient communication between the manufacturing systems.
2.3 Cloud Manufacturing
digital transformation. The new paradigm of Cloud Manufacturing has shifted the conventional manufacturing from the production-based models to service-based models using modern IT solutions like Cloud Computing and the Internet of things [17]. This paradigm shift now enables manufacturers to operate their shop floors more efficiently coupled with an intelligent abstraction to allow data to analytics and distribution of manufacturing resources. Furthermore, on-demand production capabilities and rapid product customization requires a high degree of agility, Fundamentally, Cloud Manufacturing is based on the Service-oriented Architecture is a pay-per-use model with low cost, reliable computing resources for the manufacturers which is a considerable incentive for SME’s who seek to join the Industry 4.0 revolution and use it for a trust-based resource sharing model.
Figure 2.1 The Operating Principle of Cloud Manufacturing (Ning et al. [18])
A significant advantage of Cloud Manufacturing is that it provided an intermediate layer of
abstraction between the manufacturing resource and trusted users who are interested in accessing
the information generated by the manufacturing resource or a part of it. This enables the
manufacturers to share their resources and design in a more collaborative manner [17].
the Cloud has significantly reduced the capital investments required for IT infrastructure and hardware. Manufacturers have duly leveraged the pay-per-use model by outsourcing the time and cost spent on setting and managing the IT resources.
Cloud Services being highly scalable, have helped the manufacturers to make the vital product data efficiently available to interested parties. For a manufacturing business to thrive, Cloud Manufacturing has also brought about independence within the manufacturers, and it also helped the manufacturers to concentrate more on their area of expertise, which contributes highly towards organizational efficiency. Further, the time to market is also significantly reduced using Cloud Manufacturing as serving the clients. Cloud Manufacturing also has disadvantages when it comes to several factors. A significant reason for concern is the computational performance, which will be an issue as several smart machines and old legacy machines will be connected in an IT environment. The connection loss is also a matter of concern because cloud manufacturing relies on a single communication channel. A significant disadvantage of Cloud Manufacturing is that a lot of private data and information about the manufacturing resources is given right away to the Cloud rendering it as a single point of failure. This centralization is a huge demoralization for the small and medium manufacturing for whom their data is an asset of prime importance.
A possible solution to solve the issues mentioned above, which also forms the basis of this thesis is Fog Computing, which will be described in the upcoming sections.
2.3.1 Limitations of Cloud Manufacturing
The amount of data generated by the MT Connect protocol is tremendous, and when the number of machines is scaled, the current cloud computing technologies will not suffice to handle the data streams. Additionally, the massive data will cause network bottlenecks leading to latency and bandwidth issues for applications as this would largely depend on the distance between the physical location of manufacturing resource and the Cloud datacenter. Authors in [19] have investigated the performance of Cloud computing against data types and found a considerable difference in performance with a corresponding increase in the precision of floating point numbers. Since the data generated in the smart manufacturing environment are of considerably higher precision, transferring a massive amount of data may cause a deterioration in computing performance. Moreover, as the distance between the data source and the Cloud data center increases, the network cost increases, which is an overhead to the small and medium scale manufacturers. Besides, another major cause of concern is the data integrity issues which occurs because of centralized data storage and sharing of resources for multiple users [20]. Lastly, the manufacturers tend to get locked with the Cloud service providers, and as the volume of data increases, the migration of data also gets more stringent and cumbersome.
The limitations mentioned above can be tackled by "Fog Computing," which is explained in the following sections.
2.4 Overview of Fog Computing
by Cisco [21] in the year 2014. Fog Computing is defined as an augmentation to the existing cloud computing paradigm which involves concepts of distributed computing which brings the intelligence closer to the edge by introducing an intermediate layer of geographically distributed nodes with computing, storage and networking capabilities between the IoT enabled devices and the high-performance cloud. It can be perceived as a scenario where an enormous number of heterogeneous, wide-ranging, and decentralized devices communicate with each other through the network to perform storage and processing tasks without an active intercession of third parties. The resources are distributed through a network of fiduciary nodes which do not have a conflict of interest with the stakeholders who share the data. A key feature of Fog Computing is that it offloads the computation to the distributed nodes and thereby improving the performance of latency-sensitive applications [22]. Fog Computing being of distributed nature is of a great benefit to the manufacturers as it distributes the information which may be required for low latency applications, e.g. if an employee or a designer is interested in a data of the particular client and currently not on premise. The successful implementation of with the large-scale network of sensors which stream real-time data under the Industrial Internet of Things, Fog Computing enables the manufacturers to store his/her data at storage locations which he trusts and concomitantly make use of his data through analytics. Cloud Storage accompanied by Fog Computing is one of the most optimal
system architecture of Fog computing. The OpenFog [24] reference architecture white paper. The following section will describe the characteristics of Fog Computing in detail.
2.4.1 Characteristics of Fog Computing
For infrastructure to be called as a Fog computing architecture, there are a few characteristics which must be followed. IBM described Fog Computing as “The term Fog computing, or Edge computing means that rather than hosting and working from a centralized cloud, Fog systems operate on network ends. It is a term for placing some processes and resources at the edge of the cloud, instead of establishing channels for cloud storage and utilization.” [25].
One of the foundation works which presented an overview of the term “Fog Computing” was published by Bonomi et al. [26] which highlighted the importance of Fog computing in critical Internet of things applications such as Smart grids and cities.
The salient characteristics of Fog Computing paradigm, which makes it appropriate to use for IIoT applications for a smart manufacturing environment are:
Geographical Distribution: In a Smart Manufacturing environment, data will be generated both in-house and via sources which could be distributed geographically or spread across the factory floors. Fog computing typically performs well; the scheme of deployment is distributed compared to the more centralized nature of the Cloud Computing. The number of connected machine tools, 3D printers is on the rise, and pressing concern of the small and medium scale manufacturers is the data privacy and control which tends to be hampered when the data is sent over to the Cloud which is a highly centralized resource. Besides, a large chunk of the information is a high-dimensional time-series data which makes it “Big Data,” and this compounds the challenges which the Cloud let alone cannot deal with [29].
Extensive Sensor Network: Sensors are the backbone of the Industrial Internet of Things. An extensive network of sensors is generally used to gather information and data from manufacturing machines. These sensors are mounted on machines or are inbuilt within smart machines with a primary aim of gathering data related to temperature, spindle movements during cutting operations on CNC machines, detecting significant events while a machine is under an operational state. The old legacy manufacturing machines are also being connected with RFID sensors or Wireless sensor networks. Moreover, the gateway devices such as routers, switches, wireless gateways enable an efficient of data transfer from the gateway devices. Also, the monitoring of manufacturing resources inherently requires a network of sensors and distributed storage and computing services, which can be leveraged through the Fog Computing paradigm [30].
network continuum. Fog computing being distributed in nature supports the connection of various devices and enables a smoother flow of data from these devices.
High Virtualization: The term virtualization is defined as the abstraction of physical resources from a computing node. Both the Cloud computing and Fog computing techniques use virtualization, but since the latter being more distributed, has a higher degree of virtualization. The Fog Computing comprises of many smaller distributed computing nodes which can be both virtualized. Fog Computing permits a high degree of virtualization because of which a single computing node can serve multiple clients (multi-tenancy) who are particularly interested in data about the manufacturing resource. Decentralized and Distributed Nature: Fog computing has been identified as one of the most promising computing paradigms when it comes to the decentralized and distributed nature of computing infrastructure. Fog Computing offers a broader spread geographically along with a low latency environment.
2.4.2 Architecture of Fog Computing
The concept of Fog Computing is built upon the fundamental idea of distributed computing where the data collection and processing is offloaded to the federated nodes in contrast to Cloud computing, which is largely centralized. A Fog Node is a physical device or a virtualized computing instance with storage and networking capabilities. The term “Fog Node,” which is the quintessential part of the Fog Computing architectures, has an open interpretation. A Fog Node can be a set of embedded devices, switches, routers [33], gateways, single board computers, smartphones but a required and common characteristic, in general, is the presence compute, storage and networking capabilities. A difference between the definition occurs because cloud computing is highly centralized, so a description of cloud node is required. Fog nodes can be connected to both the devices which are only data producers and the devices which are intelligent and can perform data filtering, wrangling operations (computing capabilities) on the device itself. The issue of data privacy and trust in a cloud computing environment and how fog improves the current situation was mentioned by Vaquero and Rodero-Merino [34]. The Small and Medium manufacturers are apprehensive of exposing their data and giving control over their data to a centralized resource like a cloud. Fog tackles this issue with ease as it allows applications to run independently of a centralized authority [35].
three-layered Fog computing architecture and the cloud computing architecture on energy consumption and latency. Besides, authors in [37], [38] and [39] have discussed fog computing architectures pertinent to use cases in the healthcare domain.
2.5 Fog Computing in Manufacturing
This section will detail the connection of Fog Computing and Manufacturing. Firstly, the need of Fog Computing in the domain of Smart Manufacturing will be next section which will be followed by the challenges faced during the implementation of Fog Computing architectures in the realm of the Fog Computing will be presented.
A framework for machine health-monitoring using the Fog Computing approach was proposed by Wu et al. [40] to perform predictive analytics using Machine learning algorithms and High-performance computing services. The authors used the generic three-layer architecture, but a significant focus was on the supervised machine learning approach. A manufacturing inspection system which used deep convolutional networks was presented by authors where the computational tasks were offloaded to Fog Nodes within the architecture [41].
A novel model for experimental load estimation was presented by authors in [42] who evaluated the performance of their architecture based on the design principles of Industry 4.0. A graph-based approach for modeling and analysis of a Cyber-Physical system was presented in [43] in which they found a random-network like the behavior of a CPS system in a Fog Computing environment. A cost-effective combination approach which used MQTT protocol with Fog gateway devices was proposed, which aimed to decrease the energy consumption in a Fog based scheme by Peralta et al. [44].
As the Industry 4.0 revolution has been gaining traction lately, the manufacturers have started the
unstructured, and semi-structured), which is generated by various manufacturing entities such as
robots, machines, CAD processes will replenish the conventional SQL storage databases.
CHAPTER 3
THE SYSTEM ARCHITECTURE
In this chapter, the first section will give an overview of the System architecture, which was implemented in the research thesis. The structure of the chapter follows just as the IoT platforms are designed for most of the projects. Secondly, the characteristics of the layered architecture of the proposed design will be discussed starting with the Physical layer, followed by the Fog Layer and then the Cloud layer.
3.1 Overview of the System Architecture
The System architecture is made up of the Physical Layer, which consists of the IoT enabled devices, the Networking Layer and lastly, the Cloud layer. The generic three-layered system architecture as described by authors in [45] classifies the IoT architecture into a hierarchical and distributed architecture. From the Industry 4.0 perspective, the architecture may consist of the Physical layer, the Fog Layer and the Cloud Layer.
3.2 The Physical Asset Layer
University while the Mazak Integrex I-100ST machine has the inbuilt MTConnect agent. The data is made available at the NCSU network via an XML format [46].
Besides, the physical asset layer also contains the computing resources which provide the data generated during a CAD modeling process. This data includes the STL files, STEP files, JPEG images of the CAD model, and the most critical JSON metadata, which consists of the features of the model. Moreover, the JSON metadata is highly useful as this will be made available to the clients through IoT applications.
Figure 3.1 The Edge Layer Design and Architecture
The devices within the Physical Layer require a secure gateway through which they can communicate with a Fog Node. A fundamental design principle of this architecture is that the manufacturer can control what data is shared with the Fog Node at this stage. The first level of control is established at this stage when a Python adapter performs two tasks – 1) sends the data to the manufacturers ERP's database which has no further connection with the Fog Nodes and 2) filters the data and sends on the
• The manufacturing resources present in this layer can be owned by the small & medium
manufacturers who want to share their data but do not want to give away their control over their data.
• In our architecture, we have evaluated the data distribution between the IoT enabled
manufacturing machines and the Fog Nodes. 3.3 The Network Layer
The Network Layer is the layer of the highest importance in the entire system architecture. This layer consists of physically computing nodes, which are geographically distributed or virtualized instances of physical resources. Techniques such as Data Virtualization can be used within the Networking Layer to integrate data from various sources into the Fog Nodes [47]. This abstraction layer further acts as a controller of hardware resources and enables multi-tenancy within the fog nodes [48]. On the contrary, Fog may have its own set of complete applications (like the cloud) where the cloud may act as a facilitator to access the applications running on the fog node. The nodes which communicate with this layer are responsible for transmitting the collected data via an IoT gateway device which can be a router, switch or via wireless communication enabling device.
the machines and Fog nodes is also important. The secure channel which we used for data transfer in this thesis was achieved through the use of Apache Kafka. Apache Kafka is a distributed messaging system which follows the publish-subscribe pattern and is capable of handling a high stream of data. The data is published via the Kafka architecture in the form of messages. This robust architecture also provides a mechanism to persist data on disk and even a separate mechanism for replication of messages on other nodes in a cluster. To maintain the synchronization, another Big Data tool, Apache Zookeeper is used.
The virtualization technique is the foundation behind the Cloud computing model. As mentioned earlier, the cloud layer can also be virtually deployed. The two most common techniques of virtualization are the complete virtualization and the containerization technique, which will be described in the following sections.
Complete Virtualization: The virtualization is the phenomenon which creates virtual replicas of physical resources by performing the hardware level abstraction. The physical resources constrict the number of virtual instances which can be run on a server on that particular device.
Containerization: Containers tend to consume only a small amount of physical resources. The containerization performs Operating system-level virtualization, and moreover, the containers are lightweight. Containers have access to the host kernel and isolate the virtual environment completely. In summary, by splitting the operating system between the container and the host, the containers only require the resources to run a particular application form the host machine.
3.4 The Cloud Layer
is the uppermost layer with High-Performance Computing nodes and Datacenters. The Cloud Layer is part of the architecture, where long-term analytics, such as predictive maintenance and other compute-intensive operations, can be executed. The Cloud layer is designed to communicate with the Fog Nodes and has three integral components:
a) The cloud Front-end: The Cloud Front end is the main application which is exposed to the Public over the Internet. The Front-end serves the clients and provides with the analyzed data which has been aggregated from Fog Nodes.
b) The Fog-Cloud middleware: The Fog-cloud middleware is an essential part of the stack which maintains the registry of the Fog nodes and metadata about the location and other characteristics of the Fog Node. The middleware has access to the request objects made at the cloud and using the metadata information from the registry; it directs the request to appropriate Fog Nodes. The request-response cycles are under the control of the middleware, and it is the job of the middleware to respond to requests by fetching data from appropriate Fog Nodes.
CHAPTER 4
IMPLEMENTATION OF THE FOG COMPUTING FOR SMART MANUFACTURING AND PERFORMANCE RESULTS
In this section, the implementation of the research, right from the IoT enabled machine tools and other manufacturing resources to the Fog Node, the Cloud Node and the Application Programming Interface will be discussed at length. The first part of this chapter discusses the design of the Edge Layer, followed by the design of the Fog Layer and lastly the Cloud layer design is presented. In the end, the results of the overall performance architecture with different implementations of the Fog node will be discussed.
4.1 Edge Design and Implementation
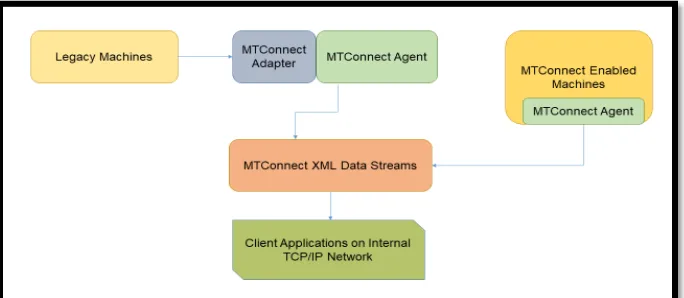
The design objective of the Edge Layer is to exchange the data securely and, in a fault-tolerant manner with the computing nodes present in the Fog Layer. The Edge Layer in our implementation consists of the CNC Machines which are either old legacy machines and have been connected by a network of sensors and a single board computer to transmit data to a local server by the MTConnect protocol or the “smart machines” which have the built-in MTConnect
agent and Adapter [49]. The data flow architecture in both types of machines is shown in Figure below.
Both the MTConnect Agent and the MTConnect Adapter are pieces of software written in C++ and work hand-in-hand to allow the machines to communicate with the Internet. These devices transmit data to a local NC State server in the XML format with the help of HTTP protocol as shown in Figure 4.2. Additionally, MTConnect provides a RESTful interface which makes the data in the XML format accessible to multiple clients locally.
Figure 4.2 Machine Process Data Representation on Local NC State Server
A Python program which parses the XML tags of the data available in REST format is deployed on the computing node which is in the Edge Layer which also stores the data into a SQL database. This python program consists of multiple stored procedures which run continuously and stored the parsed data into tables Figure of a PostgreSQL database hosted virtually on AWS Cloud, which acts as the ERP database system.
The Edge Layer can also consist of the manufacturing resources consisting of CAD and design data, which is stored on another Cloud or Document Store such as Google Drive. In the current scenario, a plethora of data generated during the manufacturing process, such as 3D printing, is siloed and not easily accessible over the Internet. Besides, the majority of these repositories are in different geographical locations, which further adds to the issue of data siloing. These decentralized CAD repositories allow limited access to clients and designers to CAD models and pertinent data which can be used in modeling applications. Additionally, the small and medium scale manufacturers can leverage the power of the proposed architecture to showcase their
engineering and modeling capabilities. A Python program which reads the data from the CAD repositories and shares the non-proprietary data with the Fog Nodes are deployed at the end of the manufacturing resource.
Figure 4.5 Various parts from a CAD repository
4.2 Edge to Fog Communication
Fog Node while in the second approach we use the web sockets in combination with a robust, fault-tolerant data streaming platform (Apache Kafka) for data exchange. The performance of both the methods and its effect on different Fog node implementations will be discussed in the subsequent sections.
The manufacturing machines use lightweight communication protocols like MTConnect or OPC/UA, which are not powerful to support compute-intensive applications. The reason for choosing Apache Kafka over MQTT is the ease of handling massive amounts of data in batches which is generated by the IoT enabled manufacturing machines.
A key point of weighing Apache Kafka over other distributed messaging systems is that it allows the data broadcast to multiple consumers which is quintessential for our architecture as this will enable manufacturers or the owner of the manufacturing resources to share data with numerous Fog Nodes and moreover, the fog nodes of their choice. Another advantage of using Apache Kafka is its easy and smooth integration with other applications, unlike other tools which are platform specific. The high fault tolerant nature of Apache Kafka is achieved by the help of another tool, which is known as Apache Zookeeper. Zookeeper is mainly responsible for maintaining the synchronization across the Kafka brokers within the Kafka cluster.
4.3 Fog Design and Implementation
data streams. A significant advantage of Apache Kafka is that in case of failure is that once the node is back again, the data is not lost and can be consumed from the beginning as the consumer reads the data right from the beginning of the offset. Furthermore, the data published to Apache Kafka is immutable.
For the implementation of Fog Nodes, we have compared and contrasted two approaches, namely the Virtualization approach and the Containerization approach.
4.3.1 Fog Node deployed in a Physical Server
The first approach of the implementation of a Fog Node was performed using a Physical Server at NC State University to simulate the hardware level abstraction as performed in virtualization. A virtualization is a software-based approach which is used to create a virtual resource by performing a hardware level abstraction of the physical resources present at a different physical location. Virtualization approach is not preferred in a resource-constrained environment. The application developed using the NodeJS and Express framework is deployed on the Physical Server, which acts like a Fog Node.
4.3.2 Fog Node deployed in a Docker Container
virtualization are comparatively much higher than those required for containerization. The lower computing requirements and quick deployment of containers make the implementation of Fog Node easier and gives more elasticity to Fog Computing platforms.
The NodeJS Express API, which was deployed on the physical server, was dockerized into a Docker container by adding a “Dockerfile.” “A Dockerfile is a text document that contains all commands a user could call on the command line to assemble an image” [50]. The application
is assembled, and a Docker image is built, which can be further deployed in the Docker Hub repository which makes the app available globally. For dockerizing the app, docker-compose tool was used to run the multi-container app since the application deployed on the Physical had two components, namely the MongoDB and NodeJS. The official Docker images (mongo [51] and node [52]) were pulled to run the app in a Docker container.
4.3.3 Application Architecture at the Fog Node
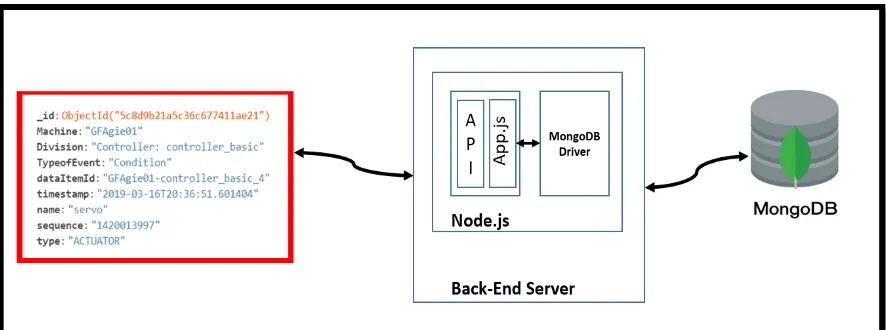
The application deployment at the Fog Node was done using the NodeJS and Express framework. The backend of the application is the MongoDB NoSQL database, which is the sink for data consumed by the Fog Nodes from Kafka brokers by subscribing to various topics.
Figure 4.7 Application architecture at the Fog Node
Figure 4.8 Data storage format in the Fog Database
A particular Fog Node can subscribe to several edge devices which are close to its vicinity by subscribing to specific topics, and the data published to Kafka is immutable. The Kafka sinks (MongoDB databases) are the backend in our stack which exposes the data via an API exclusively to the Fog-Cloud middleware. The Express framework is used for building web applications on top of the NodeJS. The main advantage of using Node is that it is built over Chrome’s V8 engine
and allows the user to use JavaScript for server-side programming.
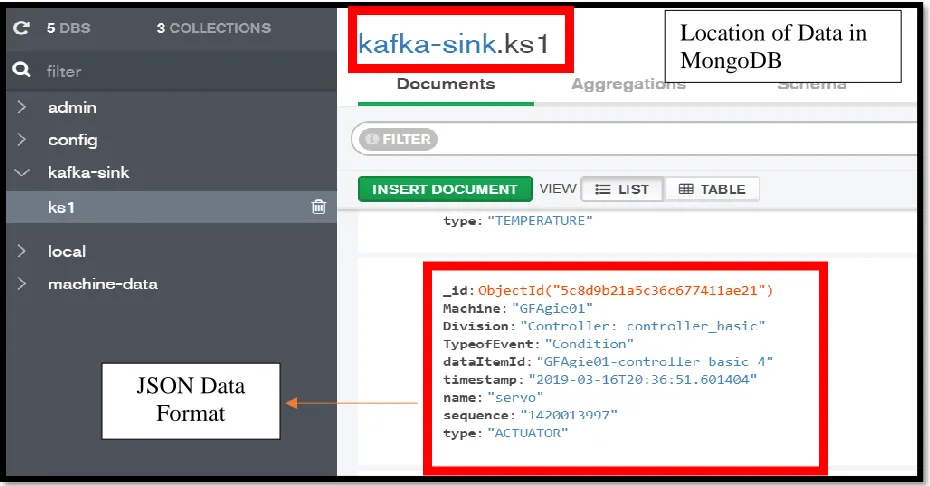
The Fog application deployed on the Fog Node can be smoothly integrated with other application and networks. This application uses the REST protocol since the data format in both the database, which is a NoSQL database, and the API is consistent. The data is exposed by the RESTful API running on the Fog node and can be accessed by anyone in only a read-only format, i.e., only GET requests can be sent to the data which is exposed by an API endpoint and expressed in JSON
Location of Data in MongoDB
format and made available to the client via an HTTP web browser. This API endpoint is masked and only accessible to the Cloud Middleware, which direct client requests to appropriate fog node. 4.4 Evaluation of Data Distribution Methods
This section evaluates the results and computation performance of the data distribution using the Apache Kafka and the conventional methods of data distribution using custom-built ingestion engines using software adapters as discussed in like those mentioned in literature [49] , [54].
4.4.1 Data Distribution using Python Ingestion Engine with the Physical Server
Figure 4.9 A graph showing the performance of the Fog node when deployed in a Physical server
Table 4.1 Performance Evaluation of the Fog Node in Physical Server
Task Time 15 minutes
Total Messages transferred 194568 Total number of iterations 804
MongoDB Insert time 1.1193 ms
Standard Deviation 0.5354
Average Message Size 242.6 Bytes
4.4.2 Data Distribution using Python Ingestion Engine with the Docker-based Containerization Approach
Figure 4.10 A graph showing the performance of the Fog node when deployed in a Docker container
Table 4.2 Performance Evaluation of the Fog Node in a Docker container
Task Time 15 minutes
Total Messages transferred 279994 Total number of iterations 1577
MongoDB insert time 0.5706 ms
Standard Deviation 0.3616
Average Message Size 220.8 Bytes
4.4.3 Data Distribution using Apache Kafka with Fog Node deployed on Physical Server & in a Docker container
In this approach, we implemented the data distribution architecture using a robust, fault-tolerant data streaming platform (Apache Kafka). The data distribution has two components when streaming data with Apache Kafka. Firstly, the data is published to a broker, and secondly, the data is consumed by the Kafka consumer from the broker. The time to produce by the manufacturing resource to the Kafka remains the same, but the time to consume the published messages from the broker varies according to the type of implementation of Fog nodes. This approach deals with the case when the Fog Node is deployed in a Physical Server.
Figure 4.11 A snapshot showing the time taken by the machine data to produce to a Kafka broker
Table 4.3 The average time taken to consume messaged in both Fog Node implementations
Fog Node in a Physical Server Fog Node in a Docker container
4.1503 ms 5.1453 ms
Figure 4.13 The graph showing consumer lag in case of node failure when the Fog node is deployed in a Docker container
4.5 Cloud Design and Implementation
middleware embedded in the application. The cloud hosts the User interface, which serves clients, designers, and other parties interested in the data generated by manufacturing resources.
Figure 4.14 The Web application deployed at the Cloud Node
Figure 4.15 Web Page showing the availability of data streams from different geographical locations
Figure 4.16 The data made available to the user at the Cloud end
4.6 Overall Performance of the architecture
to respond to a request which was made on the Cloud while the response was made from the Fog Node. The main application is hosted over the High-performance Cloud, which presents the clients with a User interface displaying the options for information about specific manufacturing resources. When a request is made over the Cloud, it is further transferred to the middleware, which also gets the response from the Fog Nodes and returns it to the Cloud.
Both the implementations are investigated in terms of performance of the architecture. Firstly, the performance of the overall architecture was observed when the Fog Node was deployed in a Physical server while in the second case, Fog Node was deployed in a Docker container.
Table 4.4 Average response time for both implementations Average response time (25 hits)
Fog Node in a Physical Server 23.50 ms Fog Node in a Docker Container 23.88 ms
CHAPTER 5
DISCUSSION AND FUTURE WORK 5.1 Discussion
Data distribution and exchange are of crucial importance in an Industry 4.0 architecture. As discussed earlier, when the number of connected machines will increase, the Cloud manufacturing paradigm faces more significant challenges ahead. We have presented an architecture that allows IoT enabled manufacturing machines to stream their data to a decentralized and distributed layer consisting of computing nodes which are physically closer to the manufacturing resources and consequently, reduce the network bottlenecks. The architecture is built on the generic three-layered architecture for Fog Computing, and the main focus is on the data streaming between the IoT enabled manufacturing machines and the implementation of intermediate computing nodes with storage and networking capabilities.
results show that the containerization can be preferred for the Fog node deployment as the delay in responding to a request made to the high-performance Cloud is marginal compared to the Fog Node deployed on a Physical Server. Moreover, the containerization technique is suitable for Smart Manufacturing use case as it augments the data privacy and cuts on the bootup latency required for the start of Fog Nodes. Lastly, according to the study, the containerization technique is also more favorable as it supports running applications in a resource-constrained environment, which is crucial for any Industry 4.0 architecture.
While we have proposed an approach for Data distribution between the edge devices and the Fog Nodes, a lot of research in other aspects of the architecture are required to build Fog Computing Platforms. Active input from the manufacturing community is needed on the type of data to be shared and manipulating software adapters custom to their machines. Besides, there are several factors mention in the subsequent section, which influences the success of any Fog Computing platform and should be investigated.
5.2 Future Work
The applications of Fog computing in the field of smart manufacturing is still at the fledgling state. Moreover, the advances in sensor technologies, embedded systems advanced automation, and robotics has led to a generation of the tremendous amount of data which needs to be channeled efficiently to leverage its true potential. Some of the areas of future work which can be done based on the current work are:
• Augmenting the capabilities of the Fog Computing platforms with Artificial
Computing brings the intelligence closer to the devices which speed up the data-driven decision-making process for the manufacturers and the intelligent machines.
• Improved security: A significant area of research lies in the field of security of fog
computing platforms and also securing the cyber-physical systems. The process of processing data locally on remote computing nodes raises concerns over data security. Since the data travels both locally and over a series of disparate communication networks which are difficult to secure by a standardized procedure, more work can be done to secure the communication and data transfer in a fog computing platform.
• Cost considerations of Fog Computing: The effect of introducing the concept of Fog
Computing on operating cost and maintenance cost to the device owners, fog node owners should be investigated more deeply. Although by distributing the computing, storage and networking capabilities among fiduciary nodes lowers the economic burden on a single entity an equitable incentivizing plan is required which provides a quantitative figure to the cost involved in the maintenance and operations of these Fog computing Platforms. • Hierarchy and Management of Fog Nodes: Fog nodes support hierarchical structures,
configurations of different Fog Computing nodes also need to be tested to determine the specific architecture of the Fog Computing platforms for a use case.
• Incorporating Search Engine like capabilities into the architecture: More research is
required to integrate search engine like capabilities into the architecture is the platforms. With advance and faster search capabilities, information retrieval for processes such as process monitoring, on-demand manufacturing will be much smoother compared with the current scenario.
• Integration of Blockchain: A considerable challenge of Fog computing environment is to
REFERENCES
[1] M. Hermann, T. Pentek and B. Otto, "Design Principles for Industrie 4.0 Scenarios," in 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, 2016.
[2] J. Lee and B. ,. K. ,. H. Bagheri, "A Cyber-Physical Systems architecture for Industry," Manufacturing Letters, vol. 3, pp. 18-23, 2015.
[3] M. O. Gokalp, K. Kayabay, M. A. Akyol, P. E. Eren and A. Koçyiğit, ""Big Data for Industry 4.0: A Conceptual Framework"," in International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, 2016.
[4] M. Parto, "A SECURE MTCONNECT COMPATIBLE IOT PLATFORM FOR," Georgia Tech, December ,2017.
[5] M. Tao, X. Hong, C. Qu, J. Zhang and W. Wei, "Fast Access for ZigBee-enabled IoT devices using Rasberry Pi," in 2018 Chinese Control and Decision Conference , Shenyang , China, 2018.
[6] W. Kim and M. Sung, "OPC-UA Communication Framework for PLC-Based Industrial IoT Applications," in 2017 IEEE/ACM Second International Conference on Internet-of-Things Design and Implementation (IoTDI), Pittsburgh, PA, 2017.
[7] J. Dizdarević, F. Carpio, A. Jukan and X. Masip-Bruin, "A Survey of Communication Protocols for Internet of Things," ACM Comput. Survey, vol. 1, no. 1, p. 30, 2019.
[9] Vakali, A., B. Catania and A. Maddalena, "XML data stores: emerging practices," IEEE Internet Computing , vol. 2, no. 9, pp. 62-69, 2005.
[10] "Apache kafka - ADistributed streaming platform," Apache Software Foundation, 2017. [Online]. Available: https://kafka.apache.org/. [Accessed 29 05 2019].
[11] B. Cheng, J. Zhang, G. Hancke and S. Karnouskos, "industrial Cyberphysical Systems : Realizing Cloud-Based Big Data Infrastructures," IEEE Industrial Electronics Magazines, vol. 12, no. 1, pp. 25-35, March 2018.
[12] "What is ZooKeeper?," The Apache Software Foundation , Copyright © 2010-2019 , [Online]. Available: https://zookeeper.apache.org/. [Accessed 8 6 2019].
[13] M. Essers and T. Vanekar, "Evaluating a data distribution service system for dynamic manufacturing : a case study," in 2nd International Conference on System-Integrated Intelligence:Challenges for Product and Production Engineering, 2014.
[14] M. Ryll and S. Ratchev, "Application of the Data Distribution Service for Flexible Manufacturing Automation," International Journal of Industrial and Manufacturing Engineering, vol. 2, no. 5, 2008.
[15] I. Ungurean, N. Gaintan and V. Gaitan, "An IoT architecture for things from Industrial Environment," 2014 10th International Conference on Communications (COMM), pp. 1-4, 2014.
[16] L. Zhang, Y. Luo, F. Tao, B. Li, L. Ren, X. Zhang, H. Guo, Y. Cheng, A. Hu and Y. Liu, "Cloud Manufacturing: A New Manufacturing Paradigm, Enterprise Information
[17] F. Oliver, W. Nicholas, P. Laura, B. Darren, R. Martin and M. Rachel, "Cloud
manufacturing as a sustainable process manufacturing route," Journal of Manufacturing Systems, vol. 47, pp. 53-68, 2018.
[18] F. Ning, W. Zhou, F. Zhang, Q. Yin and X. Ni, ""The architecture of cloud manufacturing and its key technologies research"," in IEEE International Conference on Cloud
Computing and Intelligence Systems, Beijing ,2011, pp. 259-263., 2011.
[19] A. Iosup, S. Ostermann, M. N. Yigitbasi, R. Prodan, T. Fahringer and D. Epema, "Performance Analysis of Cloud Computing Services for Many-Tasks Scientific
Computing," IEEE Transactions on Parallel and Distributed Systems, vol. 22, no. 6, pp. 931-945, June 2011.
[20] M. Armbrust, A. Fox, R. Griffith and A. Joseph, "A View of Cloud Computing," Communications of the ACM, vol. 53, no. 4, pp. 50-58, April 2010.
[21] "Cisco," 2015. [Online]. Available:
https://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/computing-overview.pdf. [Accessed 4 April 2019].
[22] S. Sarkar, S. Chatterjee and S. Misra, ""Assessment of the Suitability of Fog Computing in the Context of Internet of Things"," IEEE Transactions on Cloud Computing, vol. 6, pp. 46-59, 2018.
[23] L. Gonzalez and L. Rodero-Merino, "“Finding your Way in the Fog: Towards a
[24] "OpenFog Consortium OPFRA001.020817," February 2019. [Online]. Available:
https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference_Architecture_2_09_17-FINAL.pdf. [Accessed 04 April 2019].
[25] "IBM," 25 September 2014. [Online]. Available: https://www.ibm.com/blogs/cloud-computing/2014/08/25/fog-computing/. [Accessed 08 April 2019].
[26] F. Bonomi, R. Milito, J. Zhu and S. Addepalli, "Fog Computing and its role in the Internet of Things," Proceedings of the first edition of the MCC workshop on Mobile Cloud
Computing - MCC '12, pp. 13-16, 2012.
[27] S. Sarkar and S. Misra, "Theoritical modelling of fog computing : a green computing paradigm to support IoT applications," IET Networks, vol. 5, pp. 23-29, 2015.
[28] A. Dastjerdi and R. Buyya, "Fog Computing : Helping the Internet of Things Realize Its Potential," Computer, vol. 49, no. 8, pp. 112-116, Aug 2016.
[29] F. Bonomi, R. Milito, P. Natarajan and J. Zhu, "Fog Computing : A Platform for Internet of Things and Analytics," in Big Data and Internet of Things : A Roadmap for Smart
Environment , Springer, 2014, pp. 169-186.
[30] O. Osanaiye, S. Chen, Z. Yan, K. Choo and D. Mqhele, "From Cloud to Fog Computing : A Review and a Conceptual Live VM Migration Framework," IEEE Access, vol. 5, pp. 8284-8300, 2017.
[31] S. Yang, "IoT Stream Processing and Analytics in the Fog," IEEE Communications Magazine, vol. 8, pp. 21-27, 2017.
[33] H. Atlam, R. Walters and G. Wills, "Fog Computing and the Internet of Things : A Review," Big Data and Cogntive Computing, 2018.
[34] L. Vaquero and L. Rodero-Merino, "Finding your Way in the Fog : Towards a Comprehensive Definition of Fog Computing," ACM SIGCOMM Computer Commmunication Review, vol. 44, no. 5, pp. 27-32, October 2014.
[35] V. Moysiadis, P. Sarigiannidis and I. Moscholios, "Towards Distributed Data Management in Fog Computing," Wireless Communications and Mobile Computing, no.
10.1155/2018/7597686, pp. 1-14, 2018.
[36] M. Aazam and E.-n. Huh, "Fog Computing and Smart Gateway Based Communication for Cloud of Things," 2014 IEEE Ninth International Conference on Intelligent Sensors , Sensor Networks and Information Processing (ISSNIP), pp. 1-6, 2014.
[37] C. Nandyala and H.-K. Kim, "From Cloud to Fog and IoT- Based Real -Time U-Healthcare monitoring for Smart Homes and Hospitals," Internation Journal of Smart Homes , vol. 10, no. 2, pp. 187-196, 2016.
[38] Y. Cao, P. Hou, D. Brown, J. Wang and S. Chen, "Distributed Analytics and Edge intelligence : pervasive Health Monitoring at the Era of Fog Computing," Mobidata ' 15 Proceedings of the 2015 Workshop on Mobile Big Data, no. doi
>10.1145/2757384.2757398, pp. 43-48, 2015.
[40] D. Wu, S. ,. Z. ,. L. Liu, J. Terpenny, R. Gao, T. Kurfess and J. Guzzo, "A fog computing-based framework for process monitoring and prognosis in cyber-manufacturing," Journal of Manufacturing Systems, vol. 43, no. 1, pp. 25-34, 2017.
[41] L. Li, K. Ota and M. Dong, "Deep Learning for Smart Industry : Efficient Manufacture inspection System with Fog Computing," IEEE Transactions onIndustrial Informatics, vol. 14, no. 10, pp. 4665-4673, Oct. 2018.
[42] N. Verba, K.-M. Chao, J. Lewandowski, N. Shah and F. Tian, "Modelling Industry 4.0 based fog computing environments for application analyis and deployement," Future Generation Computer Systems, vol. 91, pp. 48-60, february 2019.
[43] N. Verba, K.-M. Chao, A. James and J. ,. F. ,. X. Lewandowski, "Graph Analysis of Fog Computing Systems for Industry 4.0," in The Fourteenth Internation Conference on e-Business Engineering (ICEBE), Shanghai, 2017.
[44] G. Peralta, M. Iglesias-urkia, M. Barcelo, R. Gomez, A. Moran and J. Bilbao, "Fog Computing based efficient IoT scheme for the Industry 4.0," in 2017 IEEE International Workshop of Electronics , Control , Measurement , Signals and their Application to Mechatronics (ECMSM), Donostia-San Sebastian , Spain , 2017.
[45] M. I. Naas, P. R. Parvedy, J. Boukhobza and L. Lemarchand, "IFogStor : An IoT Data Placement Strategy for Fog Infrastructure," in IEEE 1st International Conference on Fog and Edge Computing (ICFEC), Madrid, 2017.
[47] M. M. Hussain and M. S. Beg, "Fog Computing for Internet of Things (IoT) - Aided Smart Grid Architectures," Big Data and cognitive computing , no. 3. 8. 10.3390/bdcc3010008. , 2019.
[48] A. Yousefpour and e. al., "All one needs to know about fog computing and related edge computing paradigms: A complete survey," Journal of System Architecture, no. CoRR abs/1808.05283, 2019.
[49] S. S. Kumar, "A Cloud-Based Middleware Architecture for Connecting Manufacturing Machines to Enable the Digital Thread in Product Lifecycle Management," North Carolina State University , 2017.
[50] "Dockerfile reference," Docker Inc., 2017. [Online]. Available:
https://docs.docker.com/v17.09/engine/reference/builder/#dockerfile-examples. [Accessed 29 5 2019].
[51] "mongo," Docker Inc., 2019. [Online]. Available: https://hub.docker.com/_/mongo. [Accessed 29 5 2019].
[52] "node," Docker Inc, 2019. [Online]. Available: https://hub.docker.com/_/node/. [Accessed 29 5 2019].
[53] H. kahan, "Docker compose with Node.js and MongoDB," Medium Inc., 3 December 2017. [Online]. Available: https://medium.com/@kahana.hagai/docker-compose-with-node-js-and-mongodb-dbdadab5ce0a. [Accessed 05 June 2019].
![Figure 2.1 The Operating Principle of Cloud Manufacturing (Ning et al. [18])](https://thumb-us.123doks.com/thumbv2/123dok_us/1464772.1179471/26.612.86.534.344.482/figure-operating-principle-cloud-manufacturing-ning-et-al.webp)



![Figure 4.6 Docker Compose architecture. Adapted from [53]](https://thumb-us.123doks.com/thumbv2/123dok_us/1464772.1179471/47.612.123.487.406.616/figure-docker-compose-architecture-adapted-from.webp)