Nonparallel Hyperplanes Support Vector Machine for
Multi-class Classification
Xuchan Ju
1,2, Yingjie Tian
2,3∗, Dalian Liu
4, and Zhiquan Qi
2,31 School of Mathematical Sciences, University of Chinese Academy of Sciences, Beijing, China 2 Research Center on Fictitious Economy & Data Science, CAS, Beijing, China
3 Key Laboratory of Big Data Mining and Knowledge management, CAS, Beijing, China
4 Department of Basic Course Teaching, Beijing Union University, Beijing, China
Abstract
In this paper, we proposed a nonparallel hyperplanes classifier for multi-class classification, termed as NHCMC. This method inherits the idea of multiple birth support vector ma-chine(MBSVM), that is the ”max” decision criterion instead of the ”min” one, but it has the incomparable advantages than MBSVM. First, the optimization problems in NHCMC can be solved efficiently by sequential minimization optimization (SMO) without needing to com-pute the large inverses matrices before training as SVMs usually do; Second, kernel trick can be applied directly to NHCMC, which is superior to existing MBSVM. Experimental results on lots of data sets show the efficiency of our method in multi-class classification accuracy.
Keywords: multi-class classification, support vector machine, nonparallel, quadratic programming, kernel function
1
Introduction
Support vector machines(SVMs) are proposed by Vapnik and his co-workers[1, 18, 19]for classi-fication, regression, or other problems. SVMs depend on the principle of maximum margin, dual theory and kernel trick to be so successful. The well-known algorithm sequential minimization optimization (SMO) can be applied and solve the problem efficiently.
Recently, twin support vector machine(TWSVM)[4, 9] which works faster than conventional SVC has been successfully proposed. It seeks two nonparallel proximal hyperplanes such that each hyperplane is closest to one of two classes and as far as possible from the other class. TWSVMs have been studied extensively[11, 8, 10, 14].
∗Corresponding author
Volume 51, 2015, Pages 1574–1582
ICCS 2015 International Conference On Computational Science
1574 Selection and peer-review under responsibility of the Scientific Programme Committee of ICCS 2015 c
Although TWSVMs only solve two smaller QPPs, they have to compute the inverse of matrices, it is in practice intractable or even impossible for a large data set by the classical methods. Moreover, for the nonlinear case, TWSVMs consider the kernel-generated surfaces instead of hyperplanes and construct extra two different primal problems, i.e., they have to solve two problems for linear case and two other problems for nonlinear case separately. In order to avoid these drawbacks above, some nonparallel hyperplanes classifiers has been proposed[6, 16, 15].
For the multi-class classification problem, a new multi-class classifier, termed as multiple birth support vector machine (MBSVM), has been proposed[20]. In this classifier, it seeks K hyperplanes by solving k quadratic programming problems(QPPs). The QPPs are developed as the k-th class are as far as the k-th hyperplane while the rest points are proximal to the k-th hyperplane. A new point is assigned to the class label depending on which of the K hyperplanes it lies farthest to. Based on this trick, the size of each QPP in MBSVM has much lower complexity and faster than the existing multi-class SVMs. However, these QPPs have to compute the inverse of matrices and they have to solve different problems for linear case and nonlinear case.
In this paper, we develop nonparallel hyperplanes classifier for multi-class classification with this trick while it can avoid drawbacks in MBSVM. Moreover, SMO can be applied and solve the problem efficiently.
The paper is organized as follows. Section 2 briefly dwells on the standard C-SVC, TWSVM and NHC. Section 3 proposes our NHCMC. Section 4 deals with experimental results and Section 5 contains concluding remarks.
2
Background
In this section, we introduce the standard C-SVC, TWSVM and NHC briefly.
2.1
C
-SVC
Consider the binary classification problem with the training set
T ={(x1, y1),· · ·,(xl, yl)} ∈(Rn× Y)l, (1) where xi ∈Rn, yi ∈ Y ={1,−1}, i = 1,· · · , l, standard C-SVC formulates the problem as a convex quadratic programming problem (QPP)
min w,b,ξ 1 2w 2+Cl i=1 ξi, s. t. yi((w·xi) +b)1−ξi, i= 1,· · ·, l, ξi0, i= 1,· · · , l, (2)
where ξ= (ξ1,· · ·, ξl), andC > 0 is a penalty parameter. For this primal problem,C-SVC solves its Lagrangian dual problem
min α 1 2 l i=1 l j=1 αiαjyiyjK(xi, xj)− l i=1 αi, s. t. l i=1 yiαi= 0, 0αiC, i= 1,· · · , l, (3)
where K(x, x) is the kernel function, which is also a convex QPP and then constructs the decision function.
2.2
TWSVM
Consider the binary classification problem with the training set
T ={(x1,+1),· · · ,(xp,+1),(xp+1,−1),· · ·,(xp+q,−1)}, (4) wherexi ∈ Rn, i = 1,· · ·, p+q. Let A = (x1,· · ·, xp)T ∈ Rp×n B = (xp+1,· · · , xp+q)T ∈ Rq×nand l = p+q. For linear classification problem, TWSVM seeks a pair of nonparallel
hyperplanes
(w+·x) +b+= 0 and (w−·x) +b−= 0. (5)
by solving two smaller QPPS min w+,b+,ξ− 1 2(Aw++e+b+) T(Aw ++e+b+) +c1eT−ξ−, s.t. −(Bw++e−b+) +ξ−e−, ξ−0, (6) and min w−,b−,ξ+ 1 2(Bw−+e−b−) T(Bw −+e−b−) +c2eT+ξ+, s.t. (Aw−+e+b−) +ξ+e+, ξ+0, (7)
whereci, i= 1,2 are penalty parameters. e+ ande− are vectors of ones of appropriate dimen-sions.For nonlinear classification problem, two kernel-generated surfaces instead of hyperplanes are considered and two other primal problems are constructed.
2.3
NHC
For training set(4), NHC constructs two QPPs as follows. min w+,b+,ξ− 1 2c3(w+ 2+b2 +) + 1 2η T +η++c1eT−ξ−, s.t. Aw++e+b+=η+, −(Bw++e−b+) +ξ−e−, ξ−0, (8)
and min w−,b−,ξ+ 1 2c4(w− 2+b2 −) +12ηT−η−+c2eT+ξ+, s.t. Bw−+e−b−=η−, (Aw−+e+b−) +ξ+e+, ξ+0, (9)
where ci, i = 1,2,3,4 are penalty parameters. e+ and e− are vectors of ones of appropriate dimensions. Their dual forms can be written as follows.
max λ,α − 1 2(λ TαT) ˆQ(λT αT)T+c 3eT−α, s.t. 0αc1e−, (10) where ˆ Q= AAT+c 3I ABT BAT BBT +E, (11) and max θ,γ − 1 2(θ TγT) ˜Q(θTγT)T+c 4eT+γ, s.t. 0γc2e+, (12) where ˜ Q= BBT+c 4I BAT ABT AAT +E, (13)
and I is an identity matrix ofq×q, E is a matrix of l×l with all entries equal to one. For nonlinear classification problem, kernel function can be added directly.
3
Nonparallel hyperplanes classifier for multi-class
classi-fication(NHCMC)
Consider the multiple classification problem with the training set:
T ={(x1, y1),· · · ,(xl, yl)}, (14) wherexi∈Rn, i= 1,· · · , l, yi∈ {1,· · ·, K}is the corresponding pattern ofxi.
For multiple classification, we seekK nonparallel hyperplanes:
(wk·x) +bk = 0, k= 1,· · ·, K (15) For convenience, we denote the number of each class of the training set (14) as lk and the points belonging tok-th class asAk∈Rlk×n,k= 1,· · ·, K. Besides, we define the matrix
Bk= [A1,· · · , Ak−1, Ak+1,· · ·, Ak] (16)
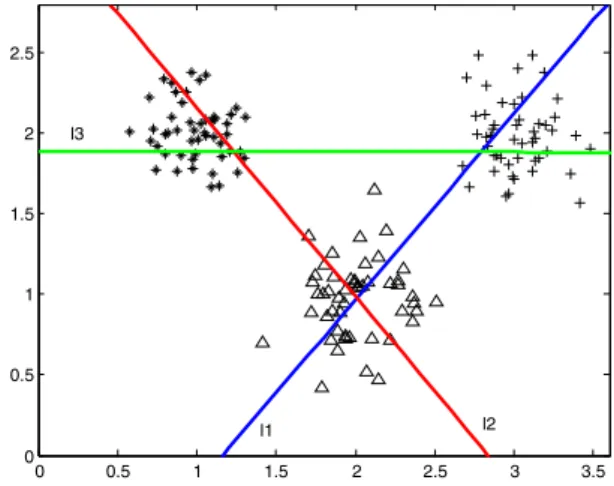
0 0.5 1 1.5 2 2.5 3 3.5 0 0.5 1 1.5 2 2.5 l1 l2 l3
Figure 1: A toy example learned by the linear NHCMC
3.1
Linear case
3.1.1 The Primal Problem
We seek to constructknonparallel hyperplanes (15) by solving the following convex quadratic programming problems(QPPs): min wk,bk,ηk,ξk 1 2C1wk 2+1 2η kηk+C2ek2ξk, s.t. Bkwk+ek1bk =ηk, (Akwk+ek2bk) +ξk ek2 ξk 0, (17)
where ηk ∈R(l−lk)is a variable and ξk is a slack variable. ek1∈R(l−lk)and ek2∈Rlk are the vectors of ones. C10 andC20 are penalty parameter.
In order to illustrate the primal problem of NHCMC, we generated an artificial two-dimensional three-class dataset. The geometric interpretation of above problem with x∈ R2 is shown in Figure 1,where minimizes the sum of the squared distance from the hyperplanes of K−1 classes, that is all classes except for those of thek−th class, and the points of thek−th class are far from the its hyperplane. Take the ”*” class in Figure 1 as an example. We hope the hyperplane of the ”*” classl1is far from the ”*” points and closest the ”+” and triangular points. In order to minimize misclassification, the points of the k−th class are at distance 1 from the hyperplane, and we minimize the sum of error variables with soft margin lost. The differences between multiple birth support vector machine(MBSVM)[20] and NHCMC are that we introduce a regularization term to implement structural risk minimization(SRM) principle and a variable is introduced to make a term of objective function to be constraints. These changes have many positive effects on original NHCMC.
3.1.2 The Dual Problem
In order to get the solutions of problem (17), we need to derive its dual problem. The Lagrangian of the problem (17) is given by
L(wk, bk, ηk, ξk, α, β, λ) =1 2C1wk 2+1 2η kηk +C2ek2ξk+λ(Bkwk+ek1bk−ηk) −α(A kwk+ek2bk+ξk−ek2)−βξk, (18)
whereα= (α1,· · ·, αlk),β = (β1,· · · , βlk),λ= (λ1,· · · , λl−lk)are the Lagrange multiplier vectors. The Karush-Kuhn-Tucker (KKT) conditions[13] forwk, bk, ηk, ξk andα, β, λare given by ∇wkL=C1wk+Bkλ−Akα= 0, (19) ∇bkL=ek1λ−ek2α= 0, (20) ∇ηkL=ηk−λ= 0, (21) ∇ξkL=C2ek2−α−β= 0, (22) Bkwk+ek1bk=ηk, (23) (Akwk+ek2bk) +ξkek2, ξk0 (24) α((A kwk+ek2bk) +ξk) = 0, βξk= 0 (25) α0, β0 (26)
Sinceβ0, from (22) we have
0αC2ek2. (27)
And from (19), we have
wk =−C1 1(B
kλ−Akα), (28)
Then putting (28) and (21) into the Lagrangian and using (19)∼(26), we obtain the dual problem of problem (17) min ˆ π 1 2πˆ Λˆˆπ+ ˆκπ,ˆ s.t.e k1λ−ek2α= 0, ˆ C1ˆπCˆ2, (29) where ˆ π = (λ, α), (30) ˆ κ = (0,−C1ek2), (31) ˆ C1 = (−∞ek1,0), (32) ˆ C2 = (+∞ek1, C2ek2), (33) ˆ Λ = ˆ Q1 Qˆ2 −Qˆ 2 Qˆ3 (34)
ˆ Q1 = BkBk +C1I, (35) ˆ Q2 = BkAk, (36) ˆ Q3 = AkAk, (37)
whereI is an identity matrix.
After getting the solution of the problem (29), we can obtain wk∗ and b∗k with (19) and (23). A new pointx∈Rn is assigned to classk(k∈1,· · ·, K), depending on which of theK hyperplanes given by (15) it lies farthest to. The decision function is defined as
f(x) = arg max k=1,···,K |(w∗ k·x) +b∗k| ||w∗ k|| , (38) where| · |is the prependicular distance of pointxfrom the hyperplane (wk·x) +bk = 0, k = 1,· · ·, K.
3.2
Nonlinear case
Now we extend the linear NHCMC to the nonlinear case. Totally different with the existing MBSVM, we do not need to consider the extra kernel-generated surfaces since only inner prod-ucts appear in the dual problems (29), so the kernel functions can be applied directly in the problems and the linear NHCMC is easily extended to the nonlinear multiple classifier.
min ˆ π 1 2ˆπ Λˆˆπ+ ˆκπ,ˆ s.t.e k1λ−ek2α= 0, ˆ C1πˆCˆ2, (39) where ˆ π = (λ, α), (40) ˆ κ = (0,−C1ek2), (41) ˆ C1 = (−∞ek1,0), (42) ˆ C2 = (+∞ek1, C2ek2), (43) ˆ Λ = ˆ Q1 Qˆ2 −Qˆ 2 Qˆ3 (44) ˆ Q1 = K(Bk, Bk) +C1I, (45) ˆ Q2 = K(Bk, Ak), (46) ˆ Q3 = K(Ak, Ak), (47)
whereIis an identity matrix andK(·,·) is the kernel function. The corresponding conclusions are similar with the linear case except that the inner product (x·x) is taken instead of the
4
Numerical experiments
In this section, in order to validate the performance of our NHCMC, we compare it with one-versus-rest(l-v-r) method[12], one-versus-one(l-v-l) method[17], directed acyclic graph SVM(DAGSVM)[5], the multi-class SVM(M-SVM)[3], crammer and singer(C&S) method[7] and MBSVM[20] on several publicly available benchmark datasets, some of which are used in [20]. NHCMC is implemented in MATLAB 2010 on a PC with an Intel Core I5 processor and 2 GB RAM.
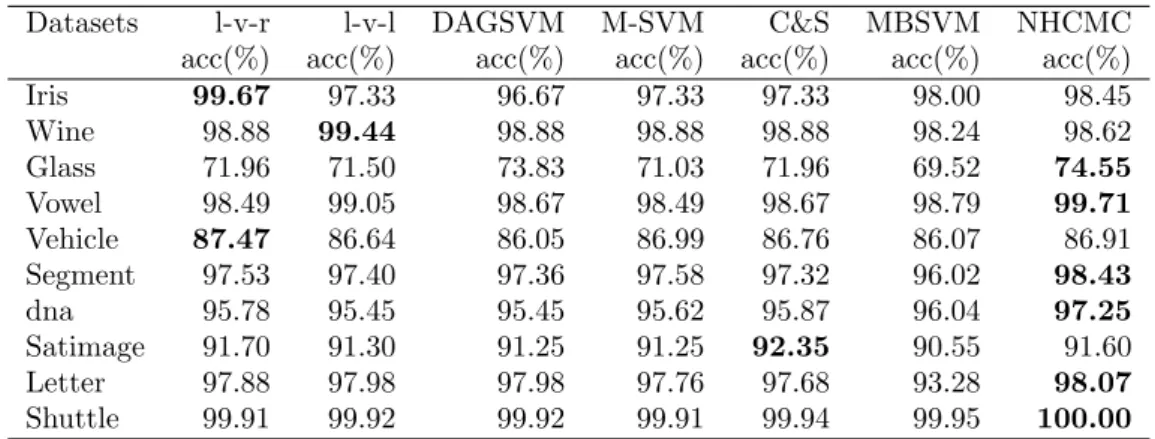
All samples were scaled such that the features locate in [0,1] before training. For the first seven datasets, the RBF kernelK(x, x) = exp(−x−σx2) is applied and for the latter three datasets, the rectangular kernel[2] K(x, ET) with E typically of size 10% of E is used. The parameters are tuned for best classification accuracy in the range 2−8 to 212. Table 1 lists the average tenfold cross-validation results of these methods to the first six datasets and the average fourfold cross-validation results of these methods to the latter four datasets in term of accuracy. The results of the former six methods come from [20].
5
Conclusion
In this paper, we have proposed a nonparallel hyperplanes classifier for multiple classification. The idea of NHCMC approximates to MBSVM, that is the ”max” decision criterion instead of the ”min” one, but NHCMC has incomparable advantages. First, we do not need to compute the large inverses matrices before training which is inevitable in MBSVM, and furthermore the optimization problems in NHCMC can be solved efficiently by SMO. Second, totally different with MBSVM, kernel trick can be applied directly to NHC. Experimental results show the efficiency of our method in classification accuracy. Therefore this novel method could be a promising approach and worth of further study in this field.
Acknowledgment
This work has been partially supported by grants from National Natural Science Foundation of China (No.11271361, No.61472390, No.71331005), Major International (Regional) Joint Re-search Project (No.71110107026), “New Start” Academic ReRe-search Project of Beijing Union University (No. ZK10201409) and the Ministry of water resources special funds for scientific research on public causes (No.201301094).
References
[1] C. Cortes and V. N. Vapnik. Support-vector networks. Machine Learning, 20(3):273–297, 1995. [2] Fung G and Mangasarian OL. Proximal support vector machine classifiers. In: 7th International
proceedings on knowledge discovery and data mining, pages 77–86, 2001.
[3] Weston J and Watkins C. Multi-class support vector machines. CSD-TR-98-04 royal holloway, University of London, Egham, UK, 1998.
[4] Jayadeva, R.Khemchandani, and S.Chandra. Twin support vector machines for pattern classifica-tion. IEEE Transaction on Pattern Analysis and Machine Intelligence, 2007.
[5] Platt JC, Cristianini N, and Shawe-Taylor J. Large margin dags for multiclass classification.Adv Neural Inf Process Syst, 12:547–553, 2000.
Datasets l-v-r l-v-l DAGSVM M-SVM C&S MBSVM NHCMC
acc(%) acc(%) acc(%) acc(%) acc(%) acc(%) acc(%)
Iris 99.67 97.33 96.67 97.33 97.33 98.00 98.45 Wine 98.88 99.44 98.88 98.88 98.88 98.24 98.62 Glass 71.96 71.50 73.83 71.03 71.96 69.52 74.55 Vowel 98.49 99.05 98.67 98.49 98.67 98.79 99.71 Vehicle 87.47 86.64 86.05 86.99 86.76 86.07 86.91 Segment 97.53 97.40 97.36 97.58 97.32 96.02 98.43 dna 95.78 95.45 95.45 95.62 95.87 96.04 97.25 Satimage 91.70 91.30 91.25 91.25 92.35 90.55 91.60 Letter 97.88 97.98 97.98 97.76 97.68 93.28 98.07 Shuttle 99.91 99.92 99.92 99.91 99.94 99.95 100.00
Table 1: Average results of the benchmark datasets
[6] Xu Chan Ju and Ying Jie Tian. Efficient implementation of nonparallel hyperplanes classifier.
International Conferences on Web Intelligence, pages 5–9, 2012.
[7] Crammer K and Singer Y. On the algorithmic implementation of multiclass kernel-based vector machines. J Mach Learn Res, 2:265–292, 2002.
[8] R. Khemchandani, R.K. Jayadeva, and S. Chandra. Optimal kernel selection in twin support vector machines. Pattern Recognit. Lett., 3:1:77–88, 2009.
[9] M. A. Kumar and M. Gopal. Least squares twin support vector machines for pattern classication.
Expert Systems withApplication, May 2007.
[10] M.A. Kumar and M. Gopal. Least squares twin support vector machines for pattern classification.
Expert Syst. Appl., 36:4:7535–7543, May 2009.
[11] M.A. Kumar and M. Gopal. Application of smoothing technique on twin support vector machines.
Pattern Recognit. Lett., 29:13:1842–1848, Oct. 2008.
[12] Bottou L, Cortes C, Denker JS, Drucher H, Guyon I, Jackel LD, LeCun Y, M¨uuller UA, Sackinger E, Simard P, and Vapnik V. Comparison of classifier methods: a case study in handwriting digit recognition. IAPR (eds) Proceedings of the international conference on pattern recognition, IEEE Computer Society Press, pages 77–82, 1994.
[13] O.L. Mangasarian. Nonlinear programming. Philadelphia, PA:SIAM, 1994.
[14] X. Peng. Tsvr: An efficient twin support vector machine for regression.Neural Networks, 23:3:365– 372, 2010.
[15] Yingjie Tian, Xuchan Ju, Zhiquan Qi, and Yong Shi. Improved twin support vector machine.
SCIENCE CHINA Mathematics, 2:417–432, 2014.
[16] Yingjie Tian, Zhiquan Qi, Xuchan Ju, Yong Shi, and Xiaohui Liu. Nonparallel support vector ma-chines for pattern classification. IEEE TRANSACTIONS ON CYBERNETICS, DOI 10.1109/T-CYB.2013.2279167, 2013.
[17] Krebel U. Pairwise classification and support vector machines. In: Scholkopf B, Burges CJC, Smola AJ (eds) Advances in Kernel methods: support vector learning, MIT Press, Cambridge, MA, pages 255–268, 1999.
[18] V. N. Vapnik. The Nature of Statistical Learning Theory. New York: Springer, 1996. [19] V. N. Vapnik. Statistical Learning Theory. New York: John Wiley and Sons, 1998.
[20] Zhi-Xia Yang, Yuan-Hai Shao, and Xiang-Sun Zhang. Multiple birth support vector machine for multi-class classification. Neural Computing and Applications, 22:Issue 1 Supplement: 153–161, 2013.