18
An Experimental Analysis on Information
Hiding using Data Mining
Naveen Kumari
1, Tarun Dalal
2 1M.Tech. Student (CSE Dept.), CBS Group of Institutions Jhajjar, Haryana 2
Asstt. Prof., CSE Dept.), CBS Group of Institutions Jhajjar, Haryana
ABSTRACT
Sometimes companies involved in the similar business are often willing to cooperate each other so that they can perform data mining to extract knowledge from combined datasets. Generally the main objective behind such kind of data mining is mutual gain of all involved parties. But the company dataset contains private or sensitive data. Therefore companies may want certain strategic or private data called sensitive patterns not to be published in the database. Therefore, before the database is released for sharing, some sensitive patterns have to be hidden in the database because of privacy or security concerns. To solve this problem, sensitive-knowledge-hiding (association rules hiding) problem has been discussed in the research community working on security and knowledge discovery. The aim of these algorithms is to extract as much as non sensitive knowledge from the collaborative databases as possible while protecting sensitive information.
In this paper, an efficient algorithm using data mining approach to protect sensitive information has been designed and proved.
Keywords: information, hiding, data mining, sensitive, privacy.
INTRODUCTION
The amount of data kept in computer files is growing at a phenomenal rate. The data mining field offers to discover unknown information. Data mining is often defined as the process of discovering meaningful, new correlation patterns and trends through non-trivial extraction of implicit, previously unknown information from the large amount of data stored in repositories, using pattern recognition as well as statistical and mathematical techniques. An SQL query is usually stated or written to retrieve specific data, while data miners might not even be exactly sure of what they require.
Whether data is personal or corporate data, data mining offers the potential to reveal what others regard as sensitive (private). In some cases, it may be of mutual benefit for two parties (even competitors) to share their data for an analysis task. However, they would like to ensure their own data remains private. In other words, there is a need to protect sensitive knowledge during a data mining process. This problem is called Privacy-Preserving Data Mining (PPDM).
Most organizations may be very clear about what constitutes examples of sensitive knowledge. What is challenging is to identify what is non-sensitive knowledge because there are many inference channels available to adversaries. It may be possible that making some knowledge public (because perceived as not sensitive), allows an adversary to infer sensitive knowledge. In fact, part of the challenge is to identify the largest set of non-sensitive knowledge that can be disclosed under all inference channels. However, what complicates matters further is that knowledge may be statements with possibility of truth, certainty or confidence. Thus, the only possible avenue is to ensure that the adversary will learn the statements with very little certainty.
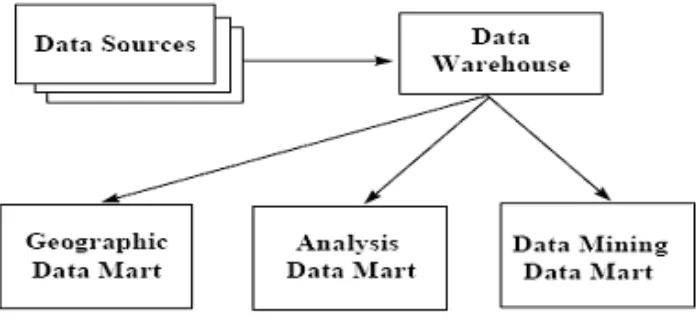
19 Figure 1: Data Warehouse and its Relations with Other Streams
Knowledge Discovery in Database
Nowadays, computers are used widely in different areas. Fast, reliable and unlimited secondary storage provides a perfect environment for the users to collect and store large amounts of the data. Computers are also used to extract the useful information from the mass of data. This is the knowledge discovery in database (KDD) or data mining.
The knowledge discovery in database (KDD) is defined as the process of nontrivial extraction of implicit, previously unknown and potentially useful information from data in databases. Fayyad et. al suggested that the KDD process can be divided into several steps, as shown in Figure 2. The whole KDD steps include selection, preprocessing, transformation, data mining and the interpretation or evaluation. The researchers are focused on the data mining process, as it is the application of algorithms for extracting patterns from the data, which is not a trivial task.
20 There are two important principles in frequent itemset mining:
Monotonicity Principle: Let J, I be two itemsets where J is subset of I , the support of I will be at most as high as the support of J.
Apriori Property: All nonempty subsets of a frequent itemset must also be frequent. These properties have been widely used in improving the efficiency of algorithms by pruning those “infrequent” branches in time so to narrow the search space.
RESULTS ANALYSIS AND DISCUSSION
The basic design of the entire image retrieval concept is prepared. in this chapter the proposed model implementation is demonstrated. Therefore the required tools and techniques, implemented and referenced classes and the implemented GUI is described in detail.
NETBEANS IDE 6.7.1
Net Beans Integrate Development Environment (IDE) is a modular, standards-based IDE, inscribed in the Java encoding skill. The Net Beans project consists of an open source IDE inscribed in the Java encoding skill and an application platform, which can be recycled as a standard structure to construct any sympathetic of application. Comparison with other algorithms
I have also compared my work with some earlier popular data sanitization algorithms like ISL [paper no 25] , DSR [paper no 25 ] and Hiding sensitive association rule by using count variable[paper no 24 ] . Let’s take a example to compare this algorithm with my approach,
ISL
In order to hide an association rule, ISL increases the support of left hand side so that the support and confidence of the rule to be smaller than pre-specified minimum support and minimum confidence. To decrease the confidence of a rule, we can either (1) increase the support of X, i.e., the left hand side of the rule, but not support of X U Y, or (2) decrease the support of the itemset X U Y. For the second case, if we only decrease the support of Y, the right hand side of the rule, it would reduce the confidence faster than simply reducing the support of X U Y. To decrease support of an item, we will modify one item at a time in a selected transaction by changing from 1 to 0 and from 0 to 1 to increase the support.
Input: a source database D, a min_support,
a min_confidence, a set of hidden items X
Output: a transformed database D’, where rules containing X on LHS will be hidden
1. Find large 1-item sets from D;
2. For each hidden item x subset of X
3. If x is not a large 1-itemset, then X := X -{x} ;
4. If H is empty, then EXIT;// no AR contains X in LHS
5. Find large 2-itemsets from D;
6. For each x subset of X {
21 8. Compute confidence of rule U, where U is a rule like x → h ;
9. If confidence(U) < min_conf, then
10. Go to next large 2-itemset;
11. Else { //Increase Support of LHS
12. Find TL = { t in D | t does not support U} ;
13. Sort TL in ascending order by the number of
Items;
14. While { confidence(U) >= min_conf and TL is not empty) { 15. Choose the first transaction t from TL;
16. Modify t to support x, the LHS(U);
17. Compute support and confidence of U;
18. Remove and save the first transaction t from TL;
19. }; // end While 20. }; // end if
21. If TL is empty, then { 22. Can not hide x → h; 23. Restore D;
24. Go to next large-2 itemset; 25. } // end if TL is empty
26. } //end of for each large 2-itemset 27. Remove x from X;
28. } // end of for each x
29. Output updated D, as the transformed D’;
We can see that simple by ISL algorithm if we want to hide D and B, we check it by modifying the transaction T2 from B to BD (i.e. from 0100 to 0101) we can not hide the rule D à A.
Count Variable
In this approach, they are not editing or disturbing the given database of transactions directly(as it is generally done in· previous works) rather we are performing the same task indirectly bye modifying the some new introduced terms associated with database transactions and association rules. These new terms are Mconfidence (modified confidence), Msupport (modified support) and Hiding counter. Our algorithm use some modified definition of support and confidence so that it would hide any desired sensitive association rule without any side effect. Actually we are using the same method (as previously used method) of getting association rules but they are modifying the definitions of support and confidence.
In this approach they are computing confidence and support as follows
Confidence(X->Y)= (X U Y)/(X+ counter of rule) Support(X->Y)= (X U Y)/(N+ counter of rule)
22 MCT(minimum specified confidence threshold),rule X- >Y is hidden i.e. it will not be discovered through data mining algorithm.
Input :
1: A source database D.
2: MST (Minimum Support Threshold). 3: MCT (Minimum Confidence Threshold). 4: A set of sensitive items X.
5: A set of initialization variables for all rules(which are initially set to zero).
6: Confidence(X->Y)= (X U Y)/(X+ counter of rule) Support(X->Y)= (X U Y)/(N+ counter of rule)
Process:
To hide the an association rule containing sensitive element X on LHS, our algorithm repeatedly increases the hiding counter of that rule until confidence goes below a minimum specified threshold confidence (MCT).As the confidence of that rule goes below MCT (minimum specified confidence threshold),rule is hidden i.e. it will not be discovered through data mining algorithm.
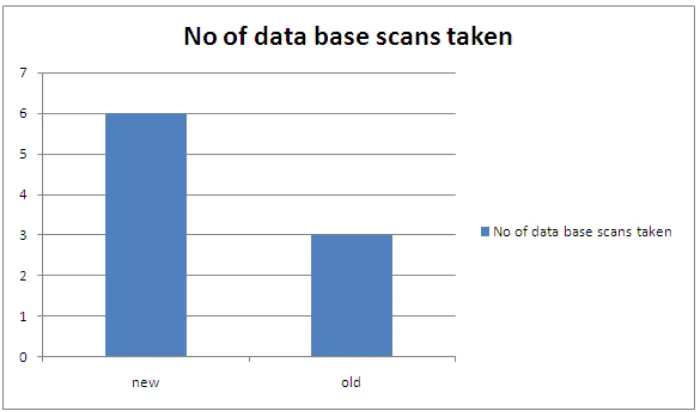
The comparison table is as follows:
Table 1: Comparison of Algorithms
Algorithm No of Rules Pruned No. of Database Scans
Hybrid 6 6
Proposed Algorithm 2 6 3
Advantage of Proposed Technique:
1. Hides sensitive items on both sides left as well as right. 2. Execution time is less in comparison to previous algorithm.
If owner of the data wants to hide a sensitive item in left side as well as in right too. Then in that case the above mentioned algorithm can be updated to hide sensitive items on both sides. The algorithm is as follows:
23 Figure 5: No of data base scans taken by the algorithm
CONCLUSIONS
Privacy-preserving data mining can be applied in different domains. The focus in this paper is on the association rule mining domain. The goal of association rule mining is to find (in databases) all patterns based on some hard thresholds, such as the minimum support and the minimum confidence. The owners of these databases might need to hide some patterns that are of a sensitive nature. The sensitivity and the degree of sensitivity are decided by experts with help from the data owners. Nowadays, determining the most effective way to protect sensitive patterns while not hiding non-sensitive ones as a side effect is a crucial research issue.
REFERENCES
[1]. C. Clifton and D. Marks. Security and privacy implications of data mining. In Workshop on Data Mining and Knowledge Discovery, pages 15–19, Montreal, Canada, February 1996. University of British Columbia, Department of Computer Science.
[2]. Y. Saygin, V. S. Verykios, and A. K. Elmagarmid. Privacy preserving association rule mining. In Z. Yanchun, A. Umar, E. Lim, and M. Shan, editors, Proceedings of the 12th International Workshop on Research Issues in Data Engineering: Engineering E-Commerce/E- Business Systems (RIDE’02), pages 151–158, San Jose, California, USA, February 2002. IEEE Computer Society.
[3]. W. Du and M. J. Atallah. Secure multi-party computation problems and their applications: A review and open problems. In V. Raskin, S. J. Greenwald, B. Timmerman, and D. M. Kienzle, editors, Proceedings of the New Security Paradigms Workshop, pages 13–22, Cloudcroft, New Mexico, USA, September 2001. ACM Press.
[4]. R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between sets of items in large databases. In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 207–216, New York, NY, USA, May 1993. ACM Press.
[5]. M. Atallah, E. Bertino, A. Elmagarmid, M. Ibrahim, and V. Verykios. Disclosure limitation of sensitive rules. In Proceedings of 1999 IEEE Knowledge and Data Engineering Exchange Workshop (KDEX’99 pages 45–52, Chicago, Illinois USA, November 1999. IEEE Computer Society.
[6]. E. Dasseni, V. S. Verykios, A. K. Elmagarmid, and E. Bertino. Hiding association rules by using confidence and support. In I. S. Moskowitz, editor, Proceedings of the 4th Information Hiding Workshop, volume 2137, pages 369–383, Pittsburg, PA, USA, April 2001. Springer Veralg Lecture Notes in Computer Science.
[7]. S. R. M. Oliveira and O. R. Zaiane. Algorithms for balancing privacy and knowledge discovery in association rule mining. In Proceedings of the 7th International Database Engineering and Applications Symposium (IDEAS’03), pages 54–65, Hong Kong, China, July 2003. IEEE Computer Society.
24
[9]. R. Chen, K. Sivakumar, and H. Kargupta. Distributed web mining using bayesian networks from multiple data streams. In N. Cercone, T. Young Lin, and X. Wu, editors, Proceedings of the 2001 IEEE International Conference on Data Mining (ICDM’01), pages 75–82, San Jose, California, USA, November 2001. IEEE Computer Society.
[10]. S. Goldwasser. Multi-party computations: Past and present. In Proceedings of the 16th Annual ACM Symposium on the Principles of Distributed Computing, pages 1–6, Santa Barbara, California, USA, 1997. ACM Press.
[11]. Y. Saygin, V. S. Verykios, and C. Clifton. Using unknowns to prevent discovery of association rules. In ACM SIGMOD Record, volume 30(4), pages 45–54, New York, NY, USA, December 2001. ACM Press.