Defensibility
Who should read this paper
The Veritas™ eDiscovery Platform facilitates a quality
control workflow that incorporates statistically sound
sampling practices developed in conjunction with expert
statisticians, leading enterprises, law firms, and legal
service providers. As legal professionals approach
a case using predictive coding, linear review, or a
combination, this patent-pending sampling technology
and workflow from Veritas makes it easy for reviewers
to ensure the defensibility of the review process.
Introduction. . . .3
Measuring review accuracy . . . .3
Challenges with existing approaches . . . .6
The Veritas Solution . . . .7
Introduction
Numerous technologies and practices have been developed over the last decade to address the challenges of electronic discovery. Among them are more targeted collection tools, intelligent data culling, and early case assessments which have made this process more manageable and cost-effective. However, document review remains expensive whether organizations perform it in-house, through an outside law firm, or a service provider. Predictive coding is an exciting technological development in electronic discovery because it has the potential to reduce review time and cost while simultaneously improving review accuracy.
Despite the widespread misconception that linear review is the electronic discovery process “gold standard,” exhaustive manual review is surprisingly inaccurate, considering its high cost. Academic research on legal review as part of the TREC Legal Track has shown linear review is often only 40-60 percent accurate.1 Predictive coding technology involves an iterative process that senior attorneys follow to train software on review criteria, creating a mathematical model that predictive coding software uses to generate “predictions” of how the remaining documents would otherwise be tagged if reviewed by an experienced attorney. Studies show that predictive coding can achieve much higher levels of accuracy at a fraction of the time and cost.2
While many believe recent court cases such as Da Silva Moore v. Publicis Groupe provide initial judicial acceptance of for using predictive coding more widely, this and other recent cases also provide some cautionary lessons. Perhaps most importantly, since the accuracy of predictive coding can depend on a number of factors—such as the number and quality of training iterations—it is not sufficient to use academic studies as evidence that predictive coding is accurate. Parties using predictive coding should be prepared to measure review accuracy in a statistically sound manner to demonstrate their results for every case. Given the disagreements over the use of predictive coding in these early cases, the key question for many electronic discovery practitioners is how to measure review accuracy in a cost-effective and defensible way.
Measuring review accuracy
Academic studies that measure review accuracy rely on statistical random sampling, a well-accepted method for
estimating the characteristics of a large population. Sampling is routinely used in many domains including opinion polling and product quality control. The underlying principle is that by measuring the characteristics of a small random sample, one can project those same characteristics across a much larger population with a known degree of error. For instance, in an election “46 percent of voters plan to vote for Candidate A with a margin of error of +/- three percent.”
While manufacturers commonly use sampling to ensure the quality of products coming off an assembly line, until now it was rarely used in electronic discovery for measuring the quality of document review, or even the results of predictive coding. However, as predictive coding becomes more widely adopted for electronic discovery, it will be increasingly important to demonstrate the results of the review process in a scientific way. According to Judge Peck of the Southern District of New York, if predictive coding is challenged, parties should be prepared to discuss “whether it produced responsive documents with reasonably high Recall and high Precision.”3
Before diving into sampling, parties should first understand the metrics used to measure accuracy in electronic discovery: Recall, Precision, and F-measure.
Using the right metrics
For most people, the most intuitive method for measuring predictive coding accuracy may be simply calculating the
percentage of documents predicted correctly. If 80 out of 100 documents are correctly predicted, the accuracy would be 80 percent. One of the standard methods of calculating a test score is to calculate the number of questions answered correctly, divide it by total number of questions on the test and multiply the resulting number by 100 to get a percentage value.
This is not an ideal way to measure accuracy in electronic discovery, which is an exercise in finding as many responsive documents, not simply categorizing all documents correctly. For example, let’s assume there are 50,000 documents in a case and each has been reviewed by attorneys and predictive coding software, resulting in the human-software comparison chart shown below.
Table 1: Comparison of human review decisions with software predictions of responsiveness.
Based on this chart, one could calculate that out of 50,000 total documents, the software predicted 42,000 documents (sum of row #1 and #3) correctly and therefore its accuracy is 84 percent (42,000/50,000). However, analyzing the chart closely reveals a very different picture. The results of human review shows there are 8,000 total responsive documents (sum of row #1 and #2) but the software found only 2,000 of those (row #1), meaning software was able to find only 25 percent of truly responsive documents. This measure is called Recall.4
Also, of 4,000 documents the software predicted to be responsive (sum of row #1 and #4), only 2,000 are actually responsive (row #1), meaning software is right only 50 percent of the times when it predicts a document responsive. This measure is called Precision.5
Why is Recall only 25 percent and Precision only 50 percent when the software’s predictions are right 84 percent of the time? That’s because the software did very well at predicting non-responsive documents. Based on the human review, there are 42,000 non-responsive documents (sum of row #3 and #4), of which the software found 40,000 correctly, meaning it is right 95 percent (40,000/42,000) of time when it predicts a document to be non-responsive. While the software is right only 50 percent of the time when predicting a document responsive, it is right 95 percent of the time when predicting a document non-responsive, driving up the percentage of correct predictions across all documents to 84 percent.
Number of
documents Human decision Software prediction Description
2,000 Responsive Responsive Agreements: Human and software agree on responsiveness 6,000 Responsive Not-Responsive Disagreements: Human and software disagree on responsiveness 40,000 Not-Responsive Not-Responsive Agreements: Human and software agree on non-responsiveness 2,000 Not-Responsive Responsive Disagreements: Human and software disagree on
non-responsiveness
4. Recall is the number or percentage of truly responsive documents identified within a defined document population that is identified as responsive. In other words, Recall is a measure of completeness.
During electronic discovery, the objective is to make a reasonable effort to identify as many responsive documents, while at the same time minimizing the number of non-responsive documents which are produced. The example above illustrates that the “percentage of correct predictions across all documents” metric may paint an inaccurate view of the number of responsive documents found or missed by the software. This is especially true when most of the documents in a case are non-responsive which happen to be the most common scenario in electronic discovery. Therefore, most academics use Recall and Precision to measure the accuracy of review since the electronic discovery process is an exercise in maximizing both of these metrics.
One of the drawbacks of relying solely on Recall and Precision is that electronic discovery practitioners often have to make tradeoffs which increases one metric while decreasing the other. For instance, in some cases using broader search criteria will yield more responsive documents which raises Recall, but at the same time will increase the number of non-responsive items as well which will decrease Precision. This can make it challenging to gauge whether a set of Recall and Precision numbers is better or more accurate than a corresponding set of Recall and Precision measures for another case or even the same case.
The F1 or F-measure is a statistical metric that is used to measure predictive coding accuracy and evaluate these trade-offs.6 While it is not an arithmetic average of Recall and Precision, F-measure can generally be thought of as a balance between these two numbers. In the above example, if one plugs in 25 percent Recall and 50 percent Precision into a calculator, the resulting F-measure is 33.3 percent. Comparing the F-measure provides reviewers with an objective standard by which to assess review accuracy. When academic studies reference the accuracy of linear review versus predictive coding, they are usually referring to F-measure.
What is a good Recall, Precision, or F-measure?
There is no standard measure that indicates when a review team has achieved an accurate result. Courts have left it up to the parties involved in discovery to agree to a reasonable percentage based on the time, cost, and risk tradeoffs. When using predictive coding, achieving higher accuracy generally requires higher costs to review more documents as part of the iterative training process. One viewpoint is that once reviewers using predictive coding on a case reach a level of accuracy equal to or greater to their best efforts using linear review the court and opposing party should find this sufficient. Other organizations may seek to reach 80 percent or even 90 percent Recall on high risk maters but perhaps only 60 percent or 70 percent Recall for other matters.
Using sampling to measure accuracy cost-effectively
If a review team performed linear review in parallel with predictive coding, it would be fairly straightforward to populate Table 1 and calculate the Recall, Precision, and F-measure of the case. However, the goal of predictive coding is to reduce review cost by reducing the manual effort spent on review. This problem is not unique to electronic discovery. An automotive assembly plant produces thousands of cars each day and all of them need to meet certain safety and quality standards. It would be impractical to perform a crash test on all of these vehicles to ensure they were safe for customers.
Acceptance testing was developed to address the challenges of measuring product quality, which relies on measuring the quality of a few units from a statistically random sample. Mathematically, as long as the sample size is statistically valid and items are chosen randomly, the sample represents the characteristics of the larger population with a known margin of error. Whether companies are manufacturing products like cars or bullets where the stakes for product quality are very high, or performing document review where the stakes can be equally high, random sampling provides a way to test accuracy cost-effectively.
In order to test the accuracy of predictive coding using sampling, review teams calculate the appropriate sample size required for accuracy testing based on criteria such as the population size and desired margin of error. Documents are selected at random and set aside in a control set. Once reviewed by the review team and the predictive coding engine, Recall, Precision, and F-measure can be calculated. For example, if the results show that the predictive coding has achieved a Precision of 80 percent with a margin of error of +/-three percent, then mathematically these results can be applied to the population of documents in the entire case. This approach allows reviewers to measure accuracy in a reliable and cost-effective way.
Challenges with existing approaches
As discussed earlier, a sample size must be statistically-valid in order to apply the results from sampling to the entire population. First generation predictive coding solutions have relied on basic statistical calculators for determining sample size. These calculators typically use just three inputs for determining sample size: population, confidence level, and margin of error, and overlooking other factors that are rarely needed to calculate sample size. While these calculators often work in many different domains, there are situations where they are inappropriate due to the type of data being measured. In fact, these simple calculators often do not work for electronic discovery data sets.
Basic sample size calculators assume that the characteristic being measured is the majority of the population. In car manufacturing, cars that meet the quality standards are typically the majority of the cars being tested. That means the sample size suggested by a basic sample size calculator is valid for quality testing. In electronic discovery, however, the characteristic being measured is responsive documents. In most matters, responsive documents are not the majority of documents and often they comprise only a small percentage of documents in the case. A case with a low percentage of responsive documents is a case with “low yield” and a basic calculator will not work.
In these situations, the margin of error increases beyond what is predicted by a basic sampling calculator. As a result, the accuracy measures from sampling are not useful to show results to the court or opposing counsel because the margin of error can be in the double digits. To understand this, let’s look at a real-life example.
Assume we are tasked with estimating the number of 7’ tall individuals in the U.S. We know intuitively that the vast majority of population is not 7’ tall, and there are very few people this tall. A basic statistical calculator would suggest a sample size of 2401 given the input of 312 million population size, 95 percent confidence-level, and 2 percent margin of error. However, it is very likely that in the randomly selected 2401 individuals, none is 7’ tall. But, since the sample is assumed to be statistically-valid, one could project the results on the U.S. population and conclude that there are no 7’ tall individuals in the country, which we know is not the case. Thus, the margin of error on the projections in this case is 100 percent, dramatically increasing from 2 percent (specified at the time of creating the sample). Many legal teams would find it difficult to show to the court that Recall is between 0 and 80 percent.
In order to confidently use sampling in situations with high stakes such as electronic discovery, it is necessary to look at all of the variables which can impact sample size and margin of error.
The Veritas™ Solution
Working with expert statisticians at Stanford and electronic discovery practitioners at leading enterprises, law firms, and service providers, the Veritas™ eDiscovery Platform, was developed to deliver a robust set of review quality control capabilities. This Veritas solution provides an easy-to-use, built-in sampling workflow to verify review accuracy, whether performed using linear review, predictive coding, or a combination of the two. Taking into account all factors that make sampling statistically sound, the eDiscovery Platform provides reviewers with the ability to leverage sampling without a background in statistics or the need to hire a statistician for each case.
Key benefits of review quality control include:
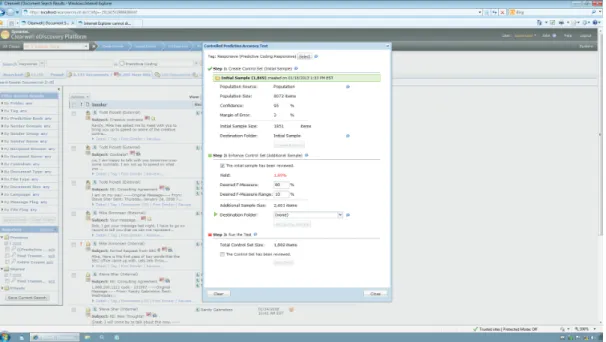
• Advanced Sampling—Using a two-step patent pending approach to sampling, the eDiscovery Platform automatically calculates the statistically valid sample size taking into account all variables that impact sampling, including yield and desired F-measure. This capability goes beyond basic sample size calculators to ensure the results meet the defensibility requirements of electronic discovery.
• Random document selection—The eDiscovery Platform automatically selects documents randomly from across the case based on the unique sample size required for accuracy testing. This takes the guesswork out of picking documents used to test predictive coding or linear review accuracy.
• Automatic accuracy calculation—Once review teams login and tag documents in the control set, the eDiscovery Platform automatically calculates accuracy metrics including Recall, Precision, and F-measure. Tracking accuracy also allows reviewers to estimate the cost of achieving higher accuracy.
• Reporting for third parties—Once accuracy has been established using the review quality control capabilities of the eDiscovery Platform, review teams can export reports detailing all steps used in testing accuracy and associated
With a real-time view on predictive coding accuracy, legal teams can make informed decisions to improve the accuracy of review and have confidence in the results of their review process. Having visibility into the accuracy of review and the cost of achieving higher levels of accuracy also enables organizations to make informed arguments for proportionality.
Conclusion
While predictive coding is a promising technology to address the time and cost of electronic discovery, recent cases demonstrate the need to measure review accuracy by following statistically sound sampling practices. There are a number of sampling nuances that can derail even the most prepared legal teams, making it challenging to ensure the defensibility of review without hiring a third-party expert. Veritas has worked with statisticians and practitioners to develop an easy to use quality control workflow that incorporates statistical sampling best practices. Using the Review Quality Control capabilities of the eDiscovery Platform, review teams can measure review accuracy, whether they use linear review, predictive coding, or in a combination of the two. The Veritas sampling tools help ensure the highest degree of defensibility, allowing legal teams to experience the cost, time and accuracy benefits of predictive coding while having confidence in the results.
About Veritas Technologies Corporation
Veritas Technologies Corporation enables organizations to harness the power of their information, with solutions designed to serve the world’s largest and most complex heterogeneous environments. Veritas works with 86 percent of Fortune 500 companies today, improving data availability and revealing insights to drive competitive advantage.
For specific country offices and contact numbers, please visit our website.
Veritas World Headquarters 500 East Middlefield Road Mountain View, CA 94043 +1 (650) 933 1000 www.veritas.com
© 2015 Veritas Technologies Corporation. All rights reserved. Veritas and the Veritas Logo are trademarks or registered trademarks of Veritas Technologies Corporation or its affiliates in the U.S. And other countries. Other names may be trademarks of their respective owners.